
一、sql的执行过程
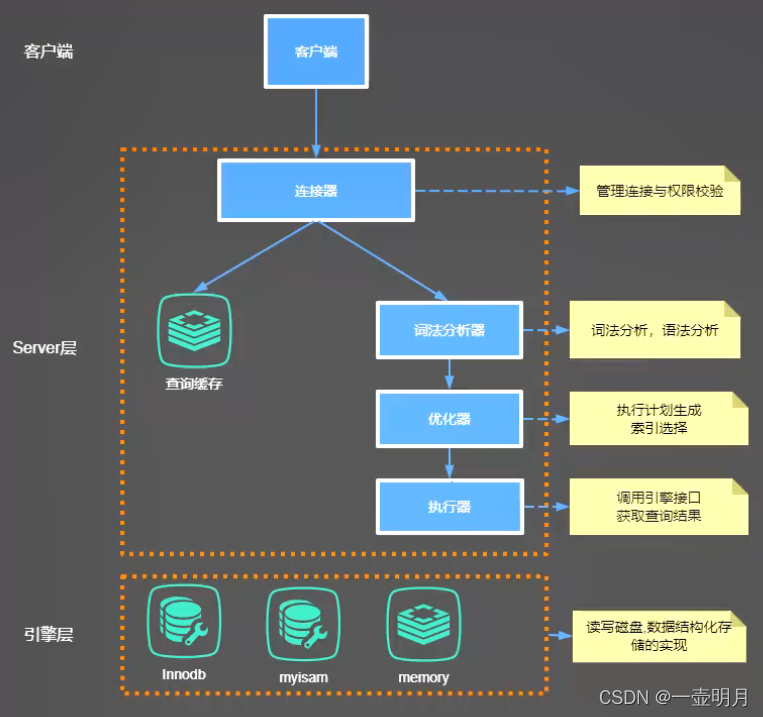
注意:mysql8.0 已经移除了查询缓存的功能

引擎层
引擎的选择是可以针对表级别的,每个表都可以单独设置存储引擎;
最常见两种: InnoDB(默认)、MyISAM
其它:Memory、CSV、Archive
特点:
InnoDB: 支持行锁、表锁、事务;
MyISAM: 支持表锁,不支持行锁,不支持事务;
应用场景:
InnoDB适合:经常更新的表,存在并发读写或者有事务处理的业务系统。
MyISAM适合:应用范围比较小,通常用于只读或以读为主的工作。
扩展
怎么快速向数据库插入 100 万条数据?
我们有一种先用 MyISAM 插入数据,然后修改存储引擎为 InnoDB 的操作。
二、索引
索引存储模型推演
二分查找(Binary Search)
二分查找的一种思想,也叫折半查找,每一次,我们都把候选数据缩小了一半。如果数据已经排过序的话,这种方式效率比较高。
二叉查找树(BST)
(BST Binary Search Tree)
左子树所有的节点都小于父节点,右子树所有的节点都大于父节点。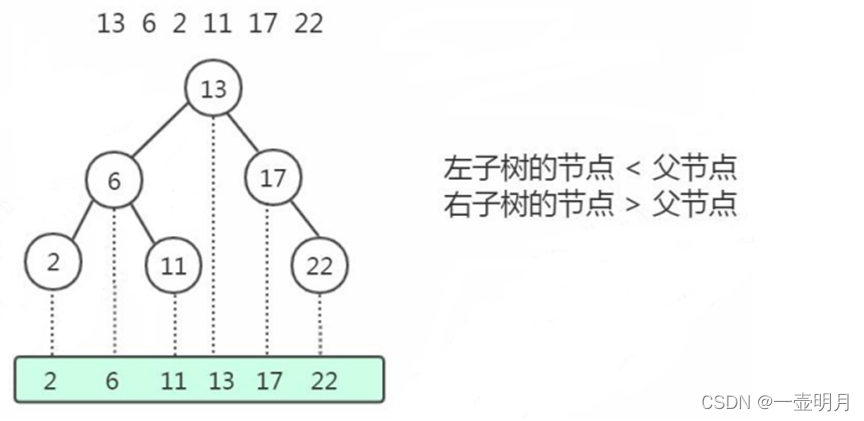
二叉查找树既能够实现快速查找,又能够实现快速插入。但是二叉查找树有一个问题:
树层级会越来越深,效率也不够高;
https://www.cs.usfca.edu/~galles/visualization/BST.html
插入的数据刚好是有序的,2、6、11、13、17、22它会变成链表(我们把这种树叫做“斜树”),这种情况下不能达到加快检索速度的目的,和顺序查找效率是没有区别的。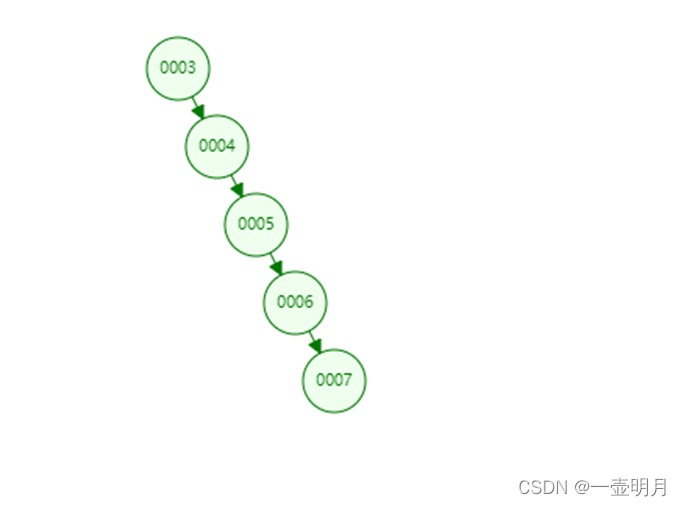
因为左右子树深度差太大,这棵树的左子树根本没有节点——也就是它不够平衡。
所以,我们有没有左右子树深度相差不是那么大,更加平衡的树呢?
平衡二叉树(AVL Tree)
(左旋、右旋)
AVL Trees (Balanced binary search trees)
平衡二叉树的定义:左右子树深度差绝对值不能超过 1。
多路平衡查找树(B-Tree )
(分裂、合并)
注意:之前有看到有很多文章把B树 和 B-tree理解成了两种不同类别的树,其实这两个是同一种树;
B 树在枝节点和叶子节点存储键值、数据地址、节点引用。
比如我们画的这棵树,每个节点存储两个关键字,那么就会有三个指针指向三个子节点。
BTree演示地址: https://www.cs.usfca.edu/~galles/visualization/BTree.html
max Degree限制的是路数,也就是最大子节点数量,所以每个节点的存储的关键字数量会比路数小1;


从这个里面我们也能看到,在更新索引的时候会有大量的索引的结构的调整;
插入数据时,从叶子节点开始添加,往父节点提取,进行分裂和合并操作,直至传递到根节点也满了,就会增加层高,让根节点又回到只存储一个关键字,然后继续这样一直分裂合并下去;
相对比平衡二叉树来说,同样的数据量,这种结构已经能极大的降低层高了;
特点:一个节点存多个关键字,分叉数(路数)永远比关键字数多 1;而且数据和索引关键字放一起;
B+树(B+Tree)
(加强版多路平衡查找树)
B+树是B树的一个升级版,而且更加充分的利用了节点空间;
特点:
1、非叶子节点不存数据,这样使得每个非叶子节点可以保存更多的关键字,树层级更小;
2、叶子节点冗余了所有父节点的关键字,而且只有在叶子节点才会存放数据;
3、分叉路数与关键字数量相等;
# InnoDB 的 B+Tree中(还做了些优化):
4、所有叶子结点,数据页之间是双向链表,每一页内部数据是单向链表;
5、主键索引的叶子结点存数据,辅助索引存的是主键值;
结构图:
InnoDB中,假设每个磁盘块能存储3个键值及指针信息
主键索引: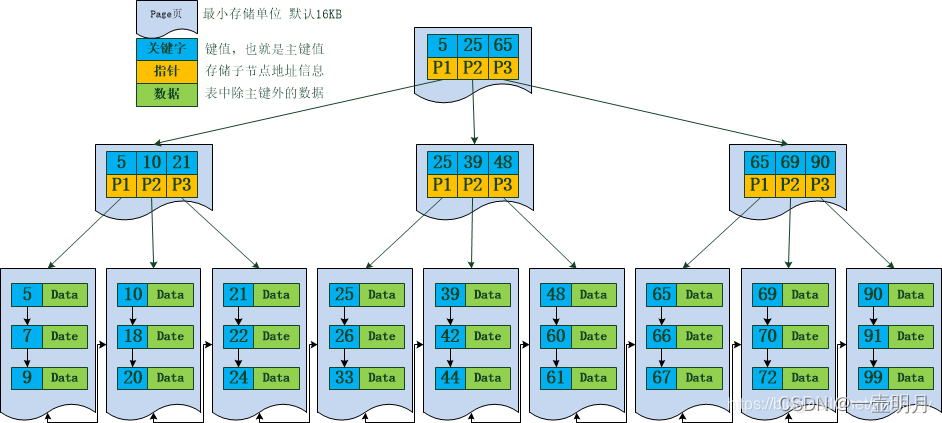
辅助索引:
联合索引(复合索引):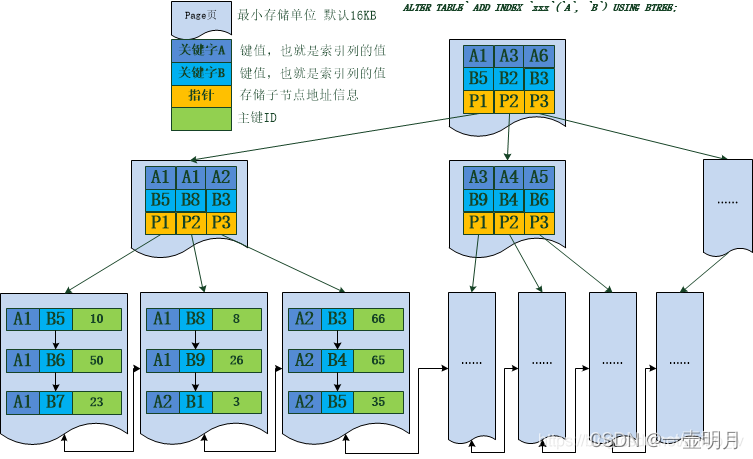
优点:
可能上图数据较少,看不出B+Tree的优点,下面做一个推算:
InnoDB存储引擎中页的大小为16KB,一般表的主键类型为INT(占用4个字节)或BIGINT(占用8个字节),指针类型也一般为4或8个字节,也就是说一个页(B+Tree中的一个节点)中大概存储16KB/(8B+8B)=1K个键值(因为是估值,为方便计算,这里的K取值为〖10〗^3)。
也就是说一个深度为3的 B+Tree 辅助索引可以维护10^3 * 10^3 * 10^3 = 10亿 条记录。
实际情况中每个节点可能不能填充满,因此在数据库中,B+Tree的高度一般都在2~4层。
mysql 的InnoDB存储引擎在设计时是将根节点常驻内存的,也就是说查找某一键值的行记录时最多只需要1~3次磁盘I/O操作。
衍生出来的概念:
从上图可以看出,如果走辅助索引的查询,还只能得到索引字段,和主键,
如果包含了需要查询的字段,这就叫做覆盖索引,
否则还需要通过主键值去主键索引拿到其它字段的数据,这个过程就叫做回表;
注意:索引覆盖,不等于覆盖索引,索引覆盖是指一个select语句,所有的查询条件都走了索引。
所以索引覆盖应该是包含了覆盖索引的;
总结
总体来看,都是采用二分法和数据平衡策略来提升查找速度;
在演变过程中,通过IO磁盘读取数据的原理,进行一步步的演变,让节点的空间更合理的运用起来,从而使树的层级减少,达到快速查找数据的目的;
目前大部分数据库系统及文件系统都采用B-Tree或其变种B+Tree作为索引结构;
- 关于更多索引知识,推荐文章: https://blog.csdn.net/u013967628/article/details/84305511 https://blog.csdn.net/zhibo_lv/article/details/117807830 https://zhuanlan.zhihu.com/p/364295145
索引的各种概念
主键索引
字面意思,就是由主键建立的索引;
扩展:
# mysql,innodb中,如果没有设置主键,会怎么样?
mysql会选择表中一个唯一且不为空的字段作为主键,
否则还是会维护一个默认的,不可见的,长度为6的 row_id 自增值作为主键;
# 如果自增主键ID达到最大值了,会怎么样?
达到最大值后,又会从0开始,所以会导致主键冲突的问题;
如果业务数据量有这么大,可以考虑使用雪花ID;
聚集索引、非聚集索引 (聚簇索引、非聚簇索引 )
叶子节点存所有字段数据,就是聚集索引,比如InnoDB的主键索引;
索引文件和数据文件是分离的,叶子节点只存磁盘地址,就是非聚集索引,比如MyiSAM,以及InnoDB中其他的非主键索引(存的是主键值);
前缀索引
字符串太长会导致索引数据太大,所以可以使用前缀(比如前20个字符)建立索引;
它的查询过程是:使用前缀先过滤出一部分数据,再回表拿到完整的字段值再次进行比较,进一步筛选数据;
覆盖索引、回表
已经在B+Tree 中解释了,这里就不多说了;
页分裂
页分裂,其实就是字面意思那么简单;
如果一页的数据满了,就会申请下一页的磁盘空间,但如果这个时候需要在该页的中间插入数据,那么就会导致页分裂;
扩展点:
# 使用自增主键的好处:
1、在主键索引中,由于主键是自增长的,所以每次插入数据都是追加操作,不会触发页分裂,不涉及到挪动其它数据;
2、另外,主键值越小,那么辅助索引中的叶子结点占用的空间也就小,当然也不能完全最求这个,还是要结合业务来看,可以使用雪花ID,但是不推荐无序的UUID作为主键;
# 哪些情况不用普通自增id
1、容易导致主键重复的场景,比如数据迁移,或者导入数据时,容易出现主键重复异常;
2、考虑到数据库扩展的情况,分库分表也会有主键重复的问题;
所以可以使用雪花ID,既不会重复,在同一节点上也是保持自增的;
最左匹配原则
因为索引是一个排好序的数据结构,聚集索引是多个字段按其字段顺序建立的排序,所以是先匹配到左边的字段,才能去匹配右边的字段;
索引下推
在辅助联合索引中,正常情况是按最左前缀原则,如果开头字段的判断条件是左模糊匹配,那么一般来说就是只能匹配到开头的字段,然后回表,拿到数据后再次过滤其它字段;
-- 举例:-- a表有联合索引: index_name_age_positionselect* form a where name like"Lilei%"and age=10and position="manager";
mysql5.6之前是这样的,5.6就引入了索引下推优化,就是对于这种情况,会直接对联合索引中包含的所有字段先做判断,过滤好了之后再回表,这样就有效的减少了回表次数;
三、事务
事务的ACID属性
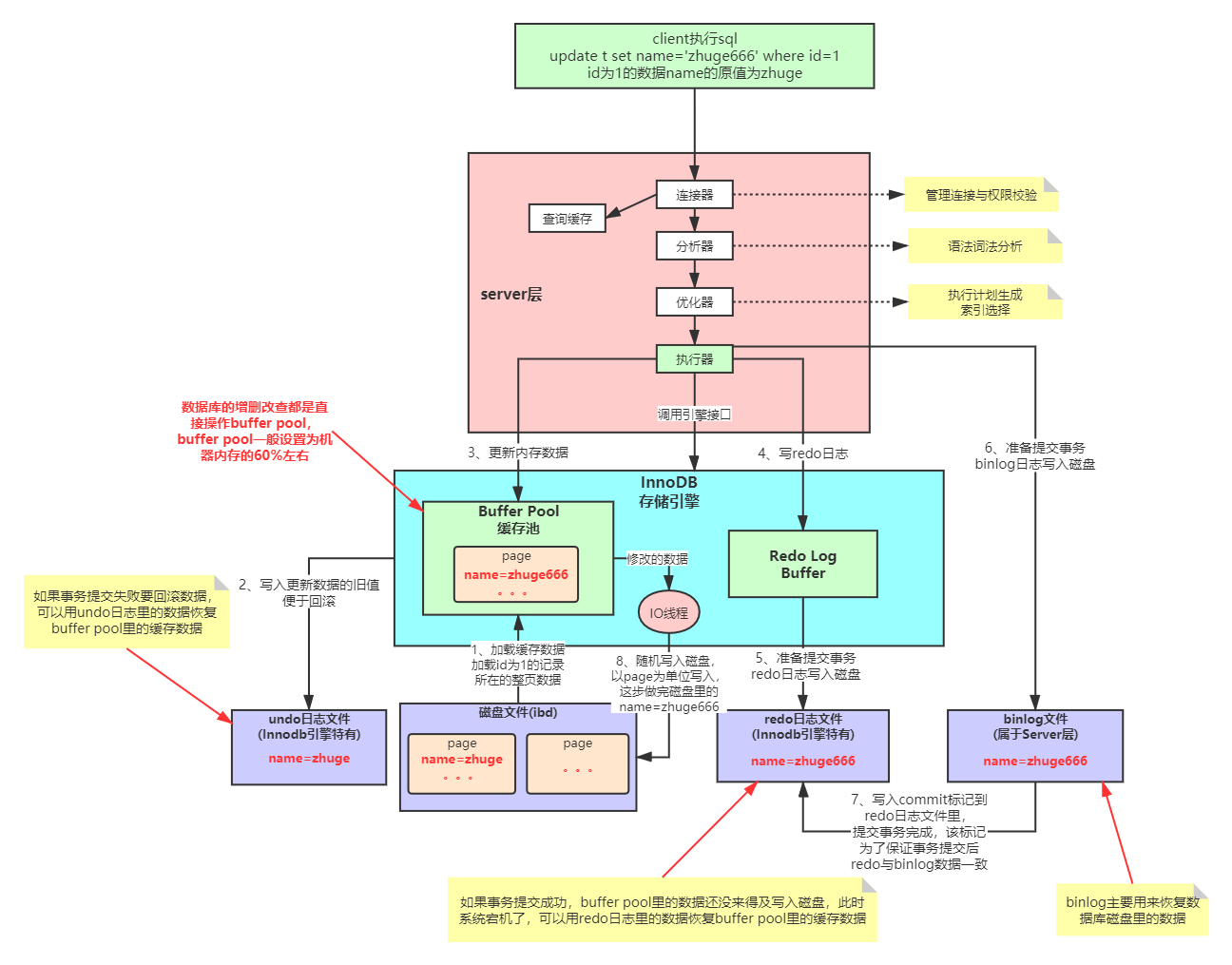
-- 原子性(Atomicity) # 使用 undo log来实现的,如果事务执行过程中出错或者用户执行了rollback,系统通过undo log日志返回事务开始的状态
-- 一致性(Consistent)# 使用 redo log来实现,只要redo log日志持久化了,当系统崩溃,即可通过redo log把数据恢复。
-- 隔离性(Isolation) # 通过锁以及MVCC,使事务相互隔离开。
-- 持久性(Durable) # 通过回滚、恢复,以及并发情况下的隔离性,从而实现一致性。
并发事务带来的问题
-- 脏写: 更新丢失;-- 脏读:读取到了其它事务修改但还没有提交的数据;-- 不可重复读: 同一个事务里先后读取某条数据结果不一致(中途被其他事物修改了);-- 幻读: 读取到了其它事务已提交的新增数据;
事务隔离级别
读未提交:
-- 其它事务修改但未提交,我也可见;-- 导致脏读;
读已提交:
-- 其它事务提交了,我才可见;-- 解决了脏读问题;
可重复读:(mysql默认)
-- 同一条数据先后查询时,结果是一致的;-- 当然,这也会导致其它事务提交的修改,我无法及时得知,比如:另一个事物和我插入同一条数据,我查不到,但是我插入却失败,就像有幻觉一样,所以这就还会有幻读的问题;
可串行化:
-- 强制事务串行,避免了幻读问题;-- 它会在读取的每一行数据上加锁,又会导致大量的锁等待,所以实际生产环境很少用这种隔离级别;
隔离级别脏读不可重复读幻读读未提交(Read uncommitted)√√√读已提交(Read committed)x√√可重复读(Repeatable read)xx√可串行化(Serializable)xxx
Mysql的InnoDB默认的事务隔离级别是可重复读
可重复读的隔离级别下使用了MVCC(multi-version concurrency control)机制,select读取的是快照,但是更新插入删除操作,就是操作的当前版本;
四、sql执行原理
order by 的Using filesort文件排序原理
单路排序:
-- 一次性取出所有字段,在sort buffer中排序,直接返回结果;
双路排序:
如果某一条数据,需要查询的字段总内存过大,则采用此方法:
-- 先将排序字段和id取出来,在sort buffer中排序,然后回表去取数据;-- mysql通过比较系统变量 max_length_for_sort_data(默认1024字节)的大小和需要查询的字段总大小来判断使用那种模式;-- sort buffer默认1M, 如果满了,则会写入临时文件进行归并排序;
Join关联查询的过程
1、确定驱动表与被驱动表:
-- 两表join查询时,mysql会自动选择,数据量小的表为驱动表,大表则是被驱动表;-- left join: 左表为驱动表;-- rigth join:右表为驱动表;2、算法的选择: join查询常见有两种算法:
1、NLJ算法: 嵌套循环连接 Nested-LoopJoin-- 遍历小表,取关联字段值作为条件,去大表中查询数据,将结果拼接后返回;2、BNL算法:基于块的循环连接 Block Nested-LoopJoin-- 先将小表存join_buffer中,然后遍历大表,取关联字段值作为条件,去join_buffer中查询数据,拼接结果返回;-- join_buffer配置项为: join_buffer_size 默认值256K-- 如果join_buffer一次装不下小表,则将小表分段处理,过程同上,最后将结果汇总返回,所以这将会导致大表多次遍历;-- 在被驱动表(大表)的关联字段有索引时,会选择NLJ算法;-- 如果没有索引,那么遍历小表,去查询大表每次都是磁盘全表扫描,效率就会很低,所以此时就会选择第二种算法(BNL算法),在内存中扫描;
五、优化
索引覆盖规则
1、单个字段模糊查询时,最左前缀匹配,才可以走索引; -- like "startWith%"-- 根本原因就是索引是排好了序的,开头的字符确定,才能与索引值比较大小,然后直接通过叶子节点进行区间访问;否则只能挨个判断是否包含该字符串,那么就是全表扫描了;2、联合索引也是最左字段匹配;
-- 要求从最左边的字段开始完全比较(如果是模糊匹配就不行),才能继续下个字段的比较,但是sql语句里面的条件字段的抒写顺序不影响,这个msyql的优化器会给我们优化;3、什么时候明明可以走索引却还是放弃走索引?
-- 符合条件的数据量占比比较大时,因为索引还需要回表查询数据,所以mysql就干脆全表扫描了;-- 字段值的离散度太低,可能也会放弃索引,根本原因同上,因为离散度低很可能出现结果集数据量占比太大;
索引设计原则
1、代码先行,索引后上,基于慢sql做优化;
-- 建立联合索引,尽量覆盖查询条件;2、联合索引尽量覆盖条件,一张表可以建立三两个联合索引,去满足不同的查询场景;
-- 注意,索引越多,查询索引覆盖率越高,但是数据增删改如果涉及到索引字段,还需要同步索引数据,效率降低;所以要结合实际场景把握好这个度;3、不要在小基数字段上建立索引;
-- 也叫数据的离散度太低,可能导致mysql自己放弃走索引,比如del字段,就只有0和1两种值;4、长字符串可以采用前缀索引;
-- 字符串太长会导致索引数据太大,所以可以使用前缀(比如前20个字符)建立索引;-- 它的查询过程是:使用前缀先过滤出一部分数据,再回表拿到完整的字段值再次进行比较,进一步筛选数据;5、where与orderby 冲突时,一般都是优先满足where,走索引筛选出少部分数据,然后再做排序;
优化总结
1、select*-- select * 会多一次表字段查询,但其实效率影响不大,是否应该使用,应该从“字段的不确定性,每次都是查询最新的所有字段”的角度来考虑;2、where 与 orderby-- 后面的条件需要符合索引最左前缀法则,尽量覆盖索引;-- order by如果未覆盖索引,会出现Using filesort3、groupby-- 与 order by 类似, 本质就是先排序后分组,所以,如果不需要排序则可以加上 order by null禁止排序;-- where高于having, 尽量使用where条件;4、in 和 exists-- 原则:遍历小表,效率更高
B表数据量小的时候: select*from A where id in(select id from B); 执行过程:遍历B表,取id值去A表查询;
A表数据量小的时候: select*from A whereexists(select1from B where B.id=A.id ); 执行过程: 遍历A表,取id值去查询B表中是否存在;
5、limit-- limit 10000,10; 查询大表靠后的数据分页时,它要先把符合条件的数据都查出来,然后只取后面10条数据,执行效率非常低,优化:select*fromorder t1 join(select id fromorderlimit10000,10) t2
on(t1.id=t2.id);-- 先通过走索引查询到分页后的10条主键索引值,然后自连接查询6、join-- 给关联字段加索引(准确的说是被驱动表的关联字段),有利于让mysql做json时选择 NLJ 算法;7、count(*)count(*) 与 count(1)-- 效率差不多,count(*)其实并不会取所有字段,这个mysql做了优化,不取值,直接按行累加计数;count(字段) 与 count(id)-- 如果是简单的cout查询,字段有索引,则cont(字段)效率更高,因为二级索引只存索引值和主键id,数据页会比主键索引的数据页更少,IO就会更少,所以会更快;-- 注意:count(字段) 的统计是非空计数(非空值的计数);
版权归原作者 一壶明月 所有, 如有侵权,请联系我们删除。