
⭐️ 本篇博客开始给大家介绍应用层的一个协议——HTTP协议,我会带大家先认识协议,再谈HTTP协议的格式、报头、状态码和方法等相关细节,我还会简单介绍一下在他基础之上扩增一层软件层的协议——HTTPS,它相比HTTP来说,要更安全一些。话不多说,进入今天主要内容~
目录
🌏认识协议
协议是一种“约定”,这种约定是双方都知道的。有了一致的约定,双方才能够正常地进行通信。协议在网络的第一篇博客中也提到过,协议是双方进行通信的基础,在网络通信中存在着各种协议,有了这些协议,网络的通信才能够正常运转。
今天我要用一个例子带大家认识协议——网络计算器。我结合上一篇博客的线程池版本的TCP服务器进行编写这个网络计算器。
大致过程如下:
- 客户端向服务端发送一个请求数据包
- 服务端将请求数据包进行解析,并且进行业务处理,然后返回一个响应数据包给客户端
- 客户端将响应数据包进行解析,得到计算结果
注意: 客户端将请求封装成一个数据包,该过程叫做序列化,服务端将请求数据包进行解析的过程叫做反序列化。目前市面上有json、xml等格式,都可以供程序员进行该操作。
协议定制:
- 请求数据包用一个结构体进行封装,里面有两个操作数和一个操作符
- 响应数据包也用一个结构体进行封装,里面有计算结果和状态码
协议的头文件如下:
/**Protocol.hpp**/#pragmaoncestructrequest{int _num1;int _num2;char _op;request(int num1,int num2,char op):_num1(num1),_num2(num2),_op(op){}};structresponse{int _code;// 0 正常 1 除以0错误 2 操作符选择错误int _result;// 结果response(int code,int result):_code(code),_result(result){}};
客户端填充请求数据包: 客户端需要让用户输入两个操作数和一个操作符,然后填充好请求数据包(序列化),并且调用
send
将请求数据包发送过去,然后
reccv
接受服务端发送过来的响应数据包,并且进行解析(反序列化),分析出状态码和结果即可,代码如下(客户端发起请求部分的代码,服务器创建和上篇博客代码一样):
voidRequest(){
std::string msg;while(1){
request rq(0,0,0);
std::cout <<"Please Enter first num# ";
std::cin >> rq._num1;
std::cout <<"Please Enter second num# ";
std::cin >> rq._num2;
std::cout <<"Please Enter(format:num1(+-*/)num2)# ";
std::cin >> rq._op;send(_sock,&rq,sizeof(rq),0);
response rp(0,0);
ssize_t size =recv(_sock,&rp,sizeof(rp),0);if(size <=0){
std::cerr <<"read error"<< std::endl;exit(-1);}if(rp._code ==1){
std::cout <<"code: "<< rp._code << std::endl;//std::cout << "除零错误" << std::endl;}elseif(rp._code ==2){
std::cout <<"code: "<< rp._code << std::endl;//std::cout << "非法操作符" << std::endl;}else{
std::cout <<"code: "<< rp._code << std::endl;
std::cout <<"result: "<< rp._result << std::endl;}}}
服务端响应: 这里使用了线程池为每个服务端提供服务,这里只需要修改Task中的Run方法即可,也就是修改业务处理的部分,代码如下:
staticvoidService(std::string ip,int port,int sock){while(1){
request rt(0,0,0);
ssize_t size =recv(sock,&rt,sizeof(rt),0);// 阻塞方式读取 if(size >0){// 正常读取size字节的数据
std::cout <<"["<< ip <<"]:["<< port <<"]# "<< rt._num1 << rt._op << rt._num2 <<"=?"<< std::endl;
response rp(0,0);switch(rt._op){case'+':
rp._result = rt._num1 + rt._num2;break;case'-':
rp._result = rt._num1 - rt._num2;break;case'*':
rp._result = rt._num1 * rt._num2;break;case'/':if(rt._num2 ==0){
rp._code =1;}else{
rp._result = rt._num1 / rt._num2;}break;default:
rp._code =2;break;}send(sock,&rp,sizeof(rp),0);}elseif(size ==0){// 对端关闭
std::cout <<"["<< ip <<"]:["<< port <<"]# close"<< std::endl;break;}else{// 出错
std::cerr << sock <<"read error"<< std::endl;break;}}close(sock);
std::cout <<"service done"<< std::endl;}structTask{int _port;
std::string _ip;int _sock;Task(int port, std::string ip,int sock):_port(port),_ip(ip),_sock(sock){}voidRun(){Service(_ip, _port, _sock);}};
代码运行效果如下: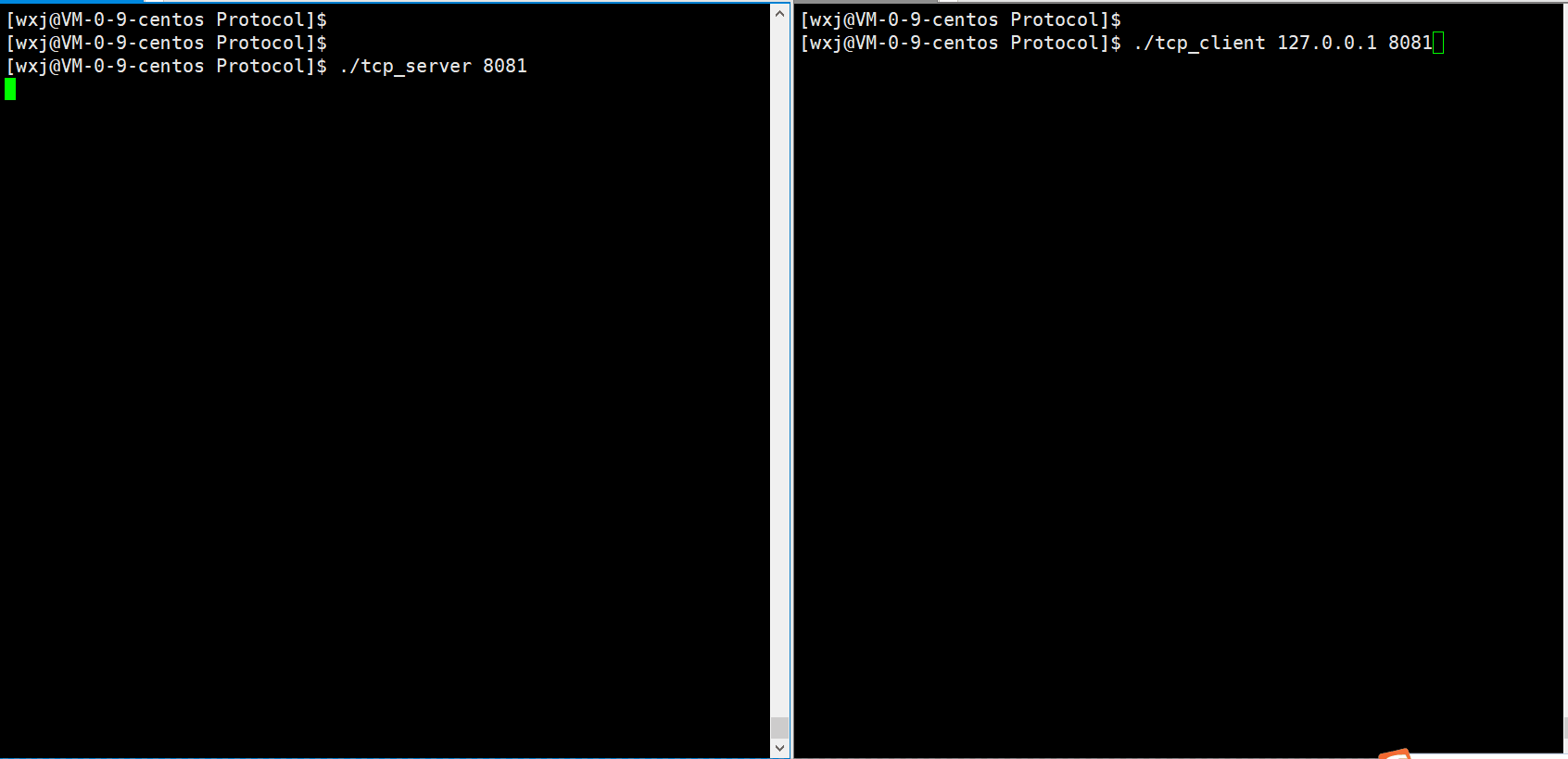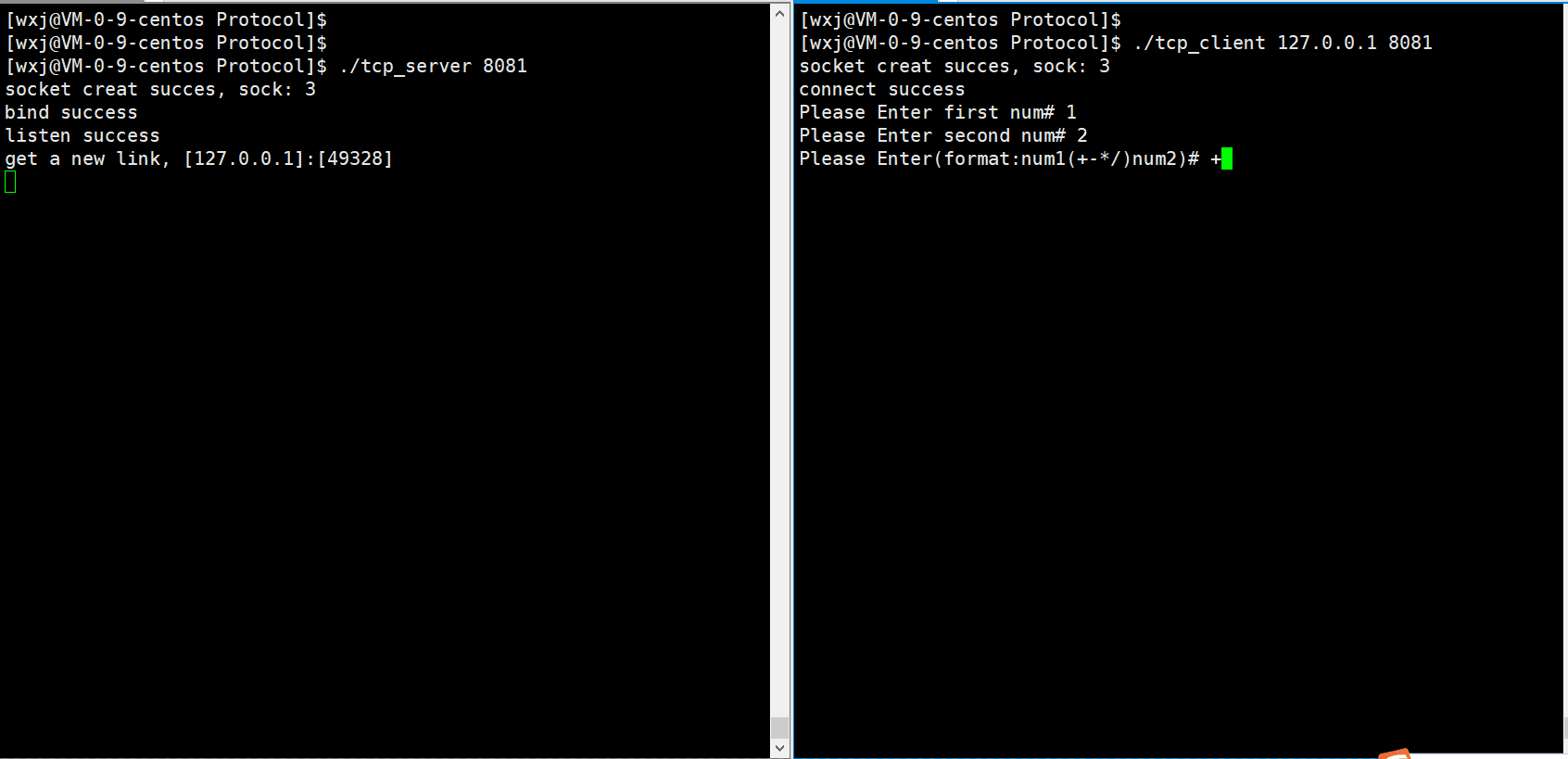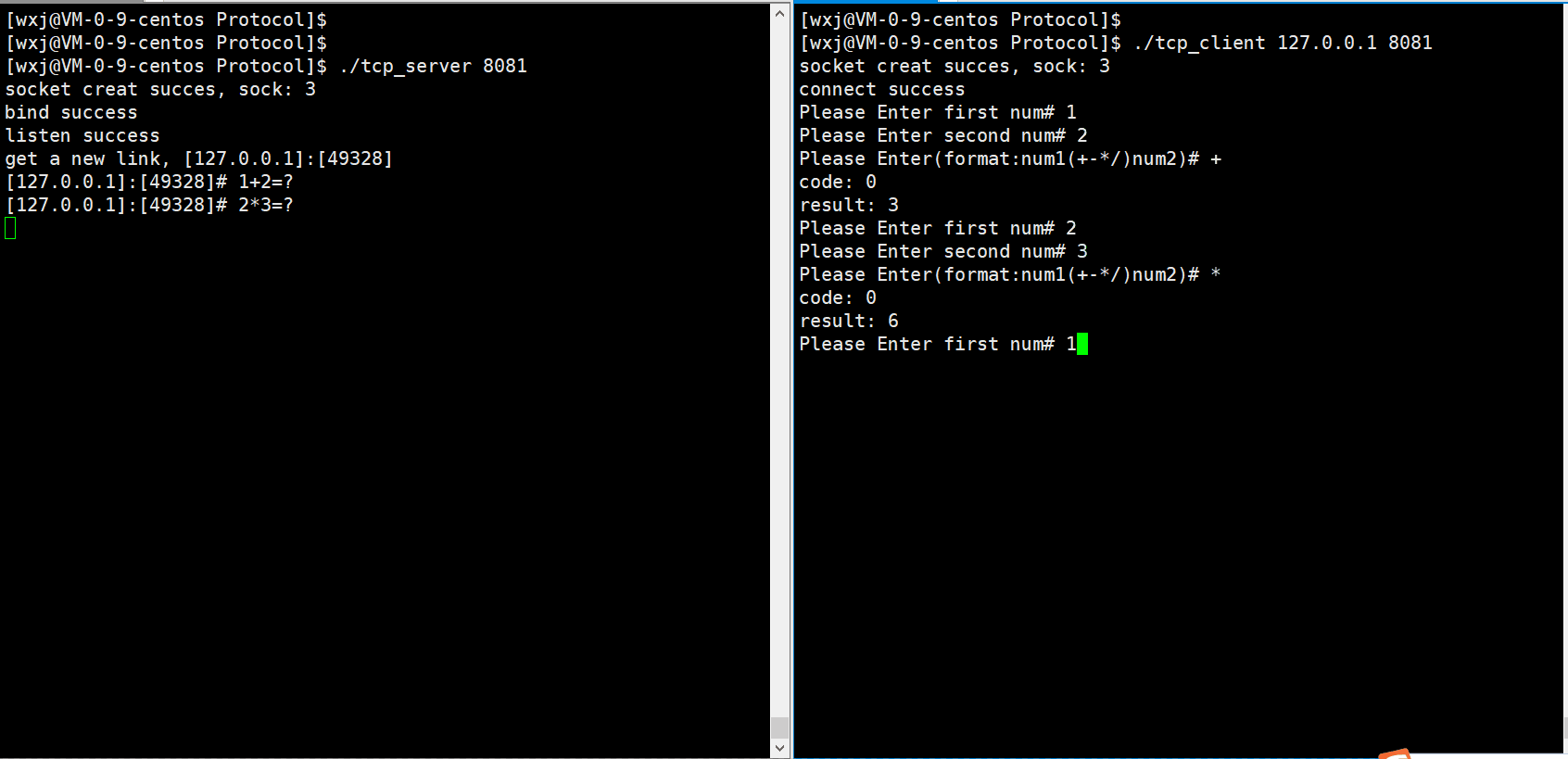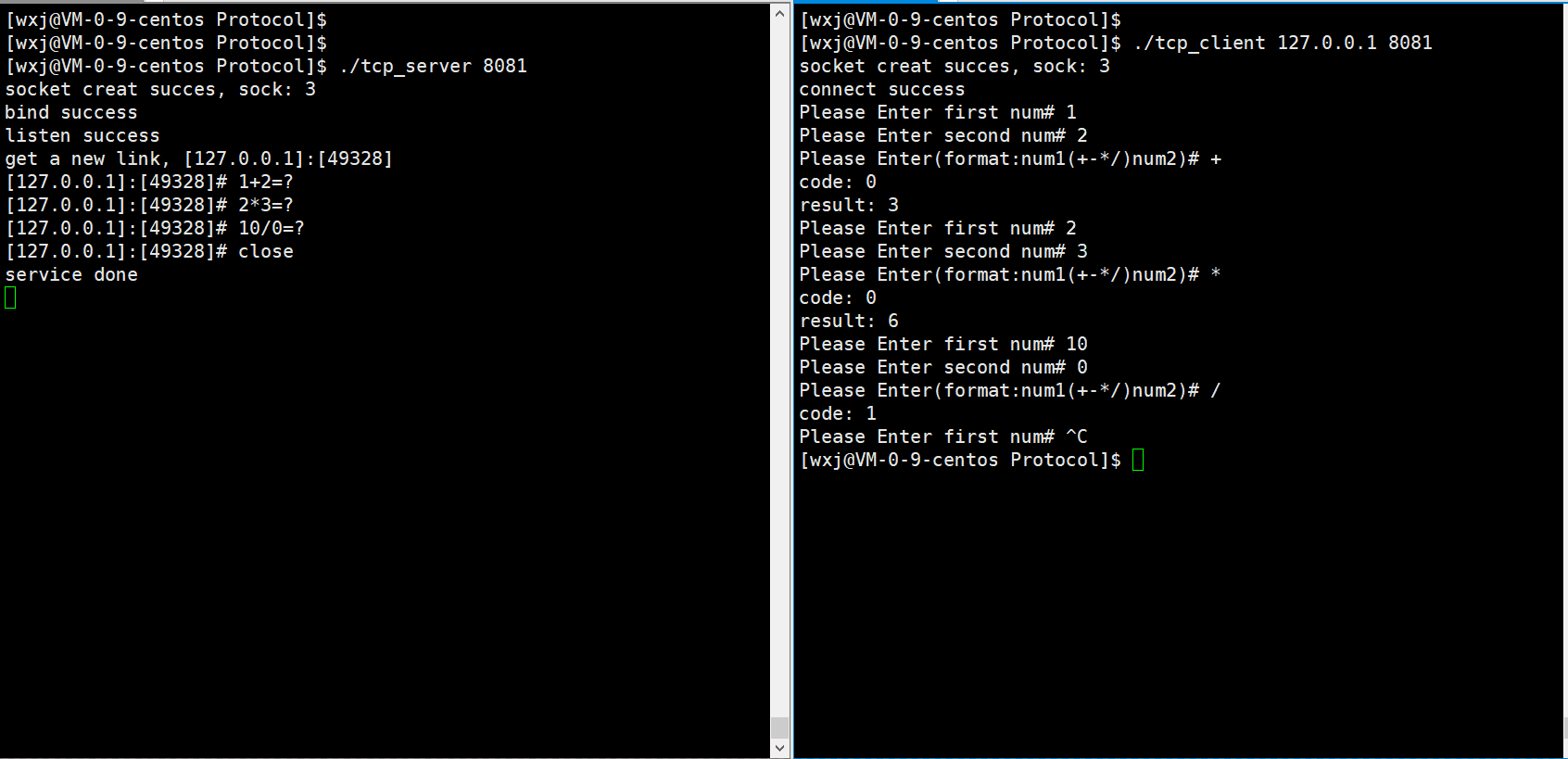
正常运算: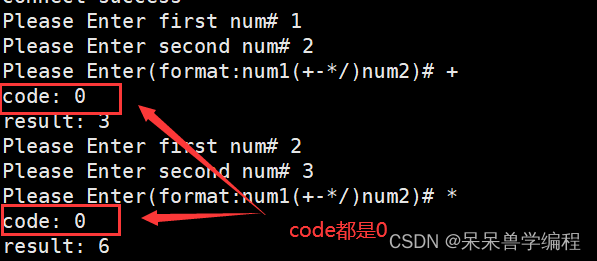
错误处理: 状态码为1,表示发生除0错误
🌏HTTP协议
🌲介绍
HTTP协议是Hyper Text Transfer Protocol(
超文本传输协议
)的缩写,本质是基于TCP协议来进行文本设置完成协议通信。HTTP协议支持客户端——服务端模式,也就是请求与响应模式,且客户端需要以浏览器的方式访问服务端。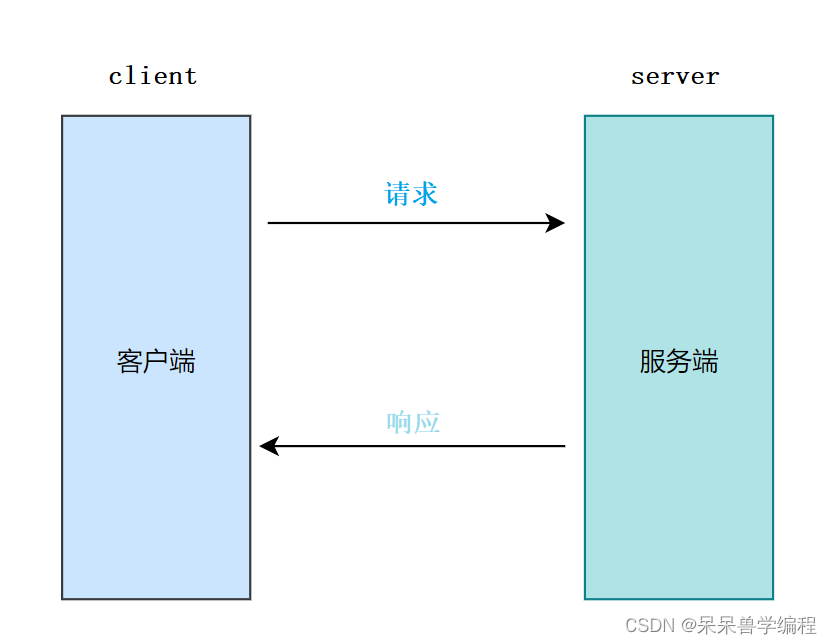
上网的大部分行为就是进行进程间通信,获取信息和发送信息:
- 把服务器资源拿到本地(下载资源、刷视频等)
- 把本地资源推送到服务器(搜索信息)
🌲URL、URI和URN
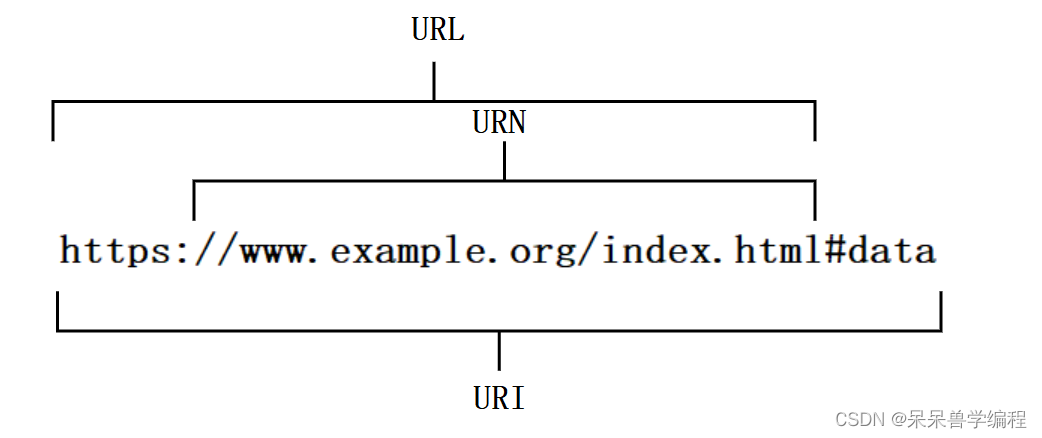
- URI: 统一资源标识符(Uniform Resource Identifier),用来标识资源的唯一性
- URN: 统一资源名称(Uniform Resource Name),用名字标识资源
- URL: 统一资源定位符(Uniform Resource Locator),给互联网上的每一个文件资源都贴上这样一个唯一标签,并且包含了资源位置信息和访问方式浏览器可以通过URL中的文件位置信息找到对应的资源文件。
结构:
- 协议方案名: 发起请求用到的协议
- 登录信息: 登录认证是用的的信息,通常被忽略
- 服务器地址: 访问资源所在的服务器的地址,也就是域名(字符串风格的)
- 端口号: 服务器绑定的端口号
- 文件路径: 访问资源在目标服务器上的位置信息
- 查询字符串: 查询信息
- 片段标识符: 对某些资源信息的描述与补充
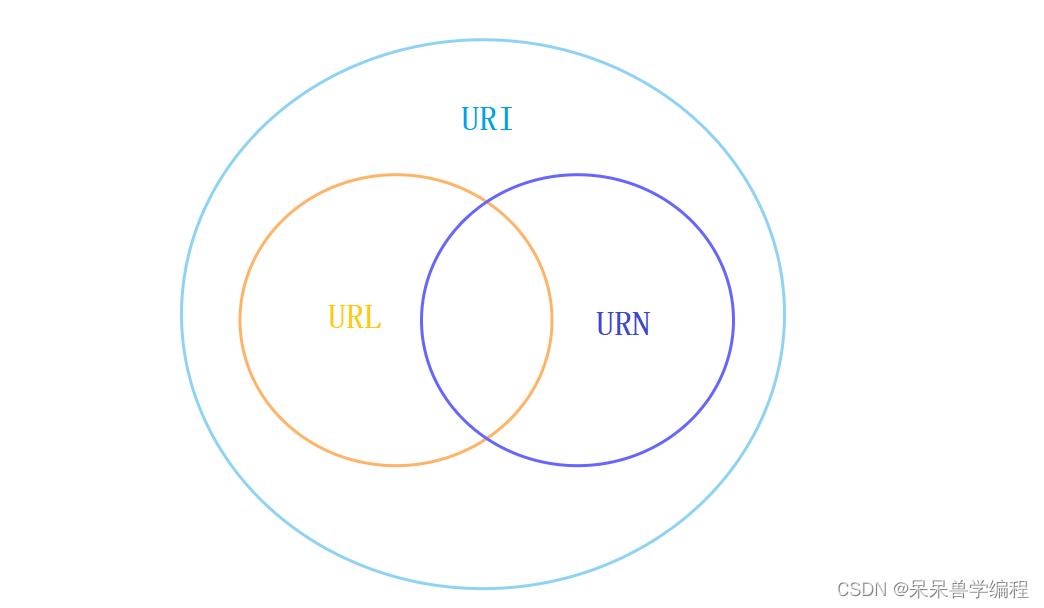
三者关系与区别:
- URL是URI的一种,URL是URI的一种具体表现,包含了资源的位置信息和获取资源的方式
- URN是URI的一种,用特定命名字标识资源,但不包含访问方式。
🌲urlencode和urldecode
urlcode是一种编码方式,urldecode是一种解码方式。在客户端向服务器发起http请求时,为了方便http服务器识别,会将请求进行urlcode编码,同样地httpserver也会对这些字符进行urldecode解码。
编码规则:
- 数字,字母和连字符不作处理
- 中文字符和特殊字符会进行编码
- 要转码的字符会被转为16进制,从右至左取4位,每两位为以为,前面加上%,编码成%XY格式
代码实现如下:
string UrlEncode(const string& szToEncode){
string src = szToEncode;char hex[]="0123456789ABCDEF";
string dst;for(size_t i =0; i < src.size();++i){unsignedchar cc = src[i];if(isascii(cc)){if(cc ==' '){
dst +="%20";}else
dst += cc;}else{unsignedchar c =static_cast<unsignedchar>(src[i]);
dst +='%';
dst += hex[c /16];
dst += hex[c %16];}}return dst;}
string UrlDecode(const string& szToDecode){
string result;int hex =0;for(size_t i =0; i < szToDecode.length();++i){switch(szToDecode[i]){case'+':
result +=' ';break;case'%':if(isxdigit(szToDecode[i +1])&&isxdigit(szToDecode[i +2])){
string hexStr = szToDecode.substr(i +1,2);
hex =strtol(hexStr.c_str(),0,16);//字母和数字[0-9a-zA-Z]、一些特殊符号[$-_.+!*'(),] 、以及某些保留字[$&+,/:;=?@]//可以不经过编码直接用于URLif(!((hex >=48&& hex <=57)||//0-9(hex >=97&& hex <=122)||//a-z(hex >=65&& hex <=90)||//A-Z//一些特殊符号及保留字[$-_.+!*'(),] [$&+,/:;=?@]
hex ==0x21|| hex ==0x24|| hex ==0x26|| hex ==0x27|| hex ==0x28|| hex ==0x29|| hex ==0x2a|| hex ==0x2b|| hex ==0x2c|| hex ==0x2d|| hex ==0x2e|| hex ==0x2f|| hex ==0x3A|| hex ==0x3B|| hex ==0x3D|| hex ==0x3f|| hex ==0x40|| hex ==0x5f)){
result +=char(hex);
i +=2;}else result +='%';}else{
result +='%';}break;default:
result += szToDecode[i];break;}}return result;}
在线工具: https://tool.chinaz.com/tools/urlencode.aspx
🌲HTTP协议格式
🍯请求协议格式
我们可以编写一个简单的基于TCP协议的服务器,并且通过以浏览器作为客户端,对服务器发起请求,并把请求部分打印下来,代码如下:
#include<iostream>#include<unistd.h>#include<fstream>#include<cstring>#include<netinet/in.h>#include<sys/types.h>#include<sys/socket.h>#include<arpa/inet.h>#include<sys/wait.h>#include<string>usingnamespace std;intmain(){// 创建套接字int listen_sock =socket(AF_INET, SOCK_STREAM,0);if(listen_sock <0){
cerr <<"socket creat fail"<< endl;exit(1);}
cout <<"socket creat succes, socket: "<< listen_sock << endl;// 绑定structsockaddr_in local;memset(&local,0,sizeof(local));
local.sin_family = AF_INET;
local.sin_port =htons(8081);
local.sin_addr.s_addr = INADDR_ANY;if(bind(listen_sock,(structsockaddr*)&local,sizeof(local))<0){
cerr <<"bind fail"<< endl;exit(2);}
cout <<"bind success"<< endl;// 将套接字设置为监听状态if(listen(listen_sock,5)<0){
cerr <<"listen fail"<< endl;exit(3);}structsockaddr_in peer;
socklen_t len =sizeof(peer);while(1){// 获取连接int sock =accept(listen_sock,(structsockaddr*)&peer,&len);if(sock <0){
cerr <<"accept error"<< endl;continue;}// 创建子进程if(fork()==0){close(listen_sock);if(fork()>0){exit(-1);}else{// 孙子进程while(1){char buf[1024];
ssize_t size =recv(sock, buf,sizeof(buf),0);if(size >0){
buf[size]=0;
cout <<"#################################### http begin ############################################"<< endl;
cout << buf << endl;
cout <<"#################################### http end ############################################"<< endl;}}elseif(size ==0){
cout <<"close"<< endl;break;}else{
cerr <<"recv error"<< endl;}}close(sock);exit(0);}}close(sock);waitpid(-1,nullptr,0);}return0;}
下面是通过浏览器对我们的服务器发起请求:
请求内容: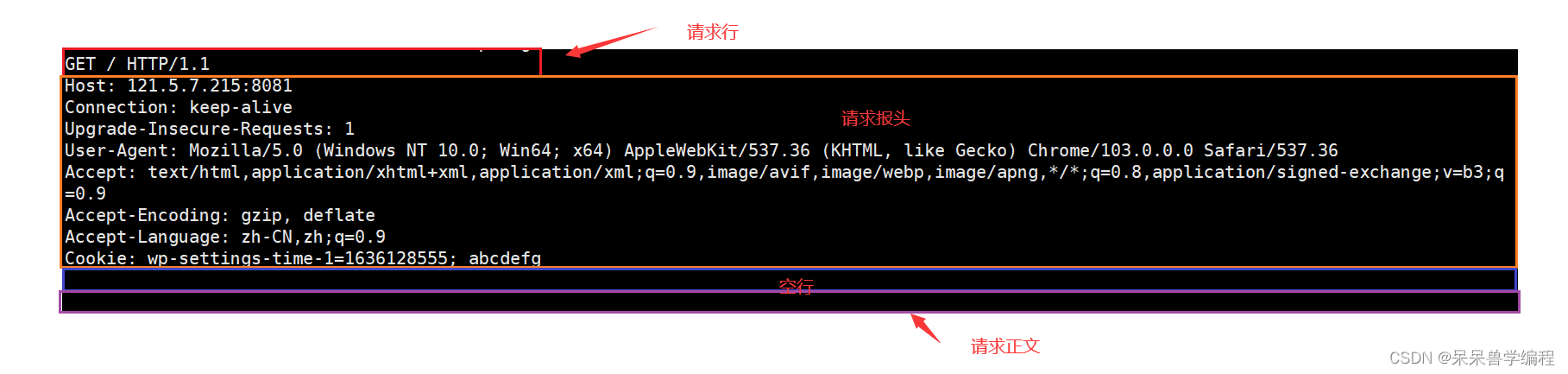
上面是一次请求的内容,大体分为四个部分:请求行、请求报头、空行和请求正文
- 请求行: 请求方法+请求url+http协议版本
- 请求报头: 请求相关属性信息,以
key:value的形式显示,且用空行分隔每一个属性信息 - 空行: 分隔报头和报文
- 请求正文: 允许为空,且如果请求方法为post,请求报头中会有
Content-Length属性字段来标识请求正文的长度
回答几个小问题:
1、HTTP协议如何保证报头和有效载荷分离?
通过空行来分离报头和有效载荷,空行之后都是有效载荷的内容,且一般还会有
Content-Length属性字段来标识正文的长度
2、服务端如何保证自己读取报头完毕?
循环读取,直到读到空行,就说明报头信息读取完毕
🍯响应协议格式
响应的格式如下:
- 响应行: 版本号+状态码+状态码解释
- 响应报头: 响应相关属性信息,以
key:value的形式显示,且用空行分隔每一个属性信息 - 空行: 分隔报头和报文
- 响应正文: html、JSON、XML等格式的文本
为了更好地让大家看到响应的效果,这里再上面的代码的基础上增加一点响应的部分,其中包含两个字段:Content-Type(正文格式,数据类型)和Content-Length(正文长度) 两个字段
这里我们正文返回一个html格式的表单,具体如下:
<!DOCTYPEhtml><htmllang="en"><head><metacharset="UTF-8"><metahttp-equiv="X-UA-Compatible"content="IE=edge"><metaname="viewport"content="width=device-width, initial-scale=1.0"><title>注册页面</title></head><body><!-- 表单域 form 表单域action url 地址 method 提交方式 name 表单名称--><formmethod="POST"name="注册表"action="mysql_cgi"><!-- input type 属性值 --><!-- text 正常显示 password -->
用户名:<inputtype="text"name="username"><br/>
密码:<inputtype="password"name="password"><br/><inputtype=submitvalue="注册"></form></body></html>
这里使用
sendfile
这个接口来发送该文本,该接口可以直接将一个文件的内容拷贝给另一个文件,且在内核中完成该操作,效率极高,介绍如下:
sendfile
功能: 把一个文件描述符的内容拷贝给另一个文件描述符,在内核层完成该操作,不经过用户层,比read和write的效率高
#include<sys/sendfile.h>ssize_tsendfile(int out_fd,int in_fd,off_t*offset,size_t count);参数:
- out_fd: 要被写入的文件描述符
- in_fd: 要被读取的文件描述符
- offset: 偏移量,可以记录读取文件的位置
- count: 要拷贝内容的大小
返回值: 成功返回已经写入的字节数,失败返回-1
在
sendfile
这个接口中,需要填充需要发送多少字节,这里我们发送整个文件,所以这里为了能够获取一个文件大小,这里再介绍一个接口
stat
,具体如下:
stat
功能: 获取文件的属性
#include<sys/types.h>#include<sys/stat.h>#include<unistd.h>intstat(constchar*pathname,structstat*buf);参数:
- pathname: 文件所在路径
- buf: 存储文件属性的
struct stat类型的结构体返回值: 成功返回0,失败返回-1
我们可以通过
stat
获取文件大小,填充
Content-Length
字段,然后通过
sendfile
接口发送html格式的文件到套接字中,具体如下:
// 响应int fd =open("index1.html", O_RDONLY);structstat st;stat("./index1.html",&st);//string status_line = "HTTP/1.1 307 Temporary Redirect";
string status_line ="HTTP/1.1 200 OK\n";// 2.响应报头
string response_header ="Content-Length: "+to_string(st.st_size)+"\n";
response_header +="Content-Type: text/html\n";//response_header += "Set-Cookie: ;\n";//response_header += "location: https://www.qq.com\n";// 3.空行
string blank ="\n";// 4.正文send(sock, status_line.c_str(), status_line.size(),0);send(sock, response_header.c_str(), response_header.size(),0);send(sock, blank.c_str(), blank.size(),0);sendfile(sock, fd,nullptr, st.st_size);close(fd);
这里分别用telnet和Postman做测试:
- telnet
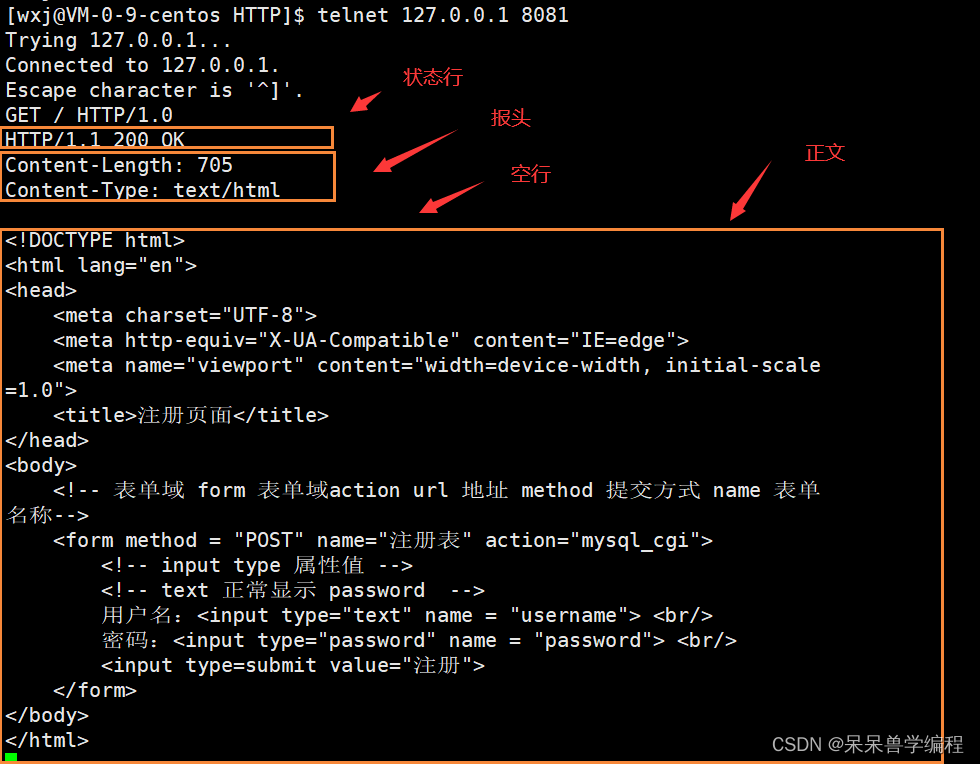
- Postman
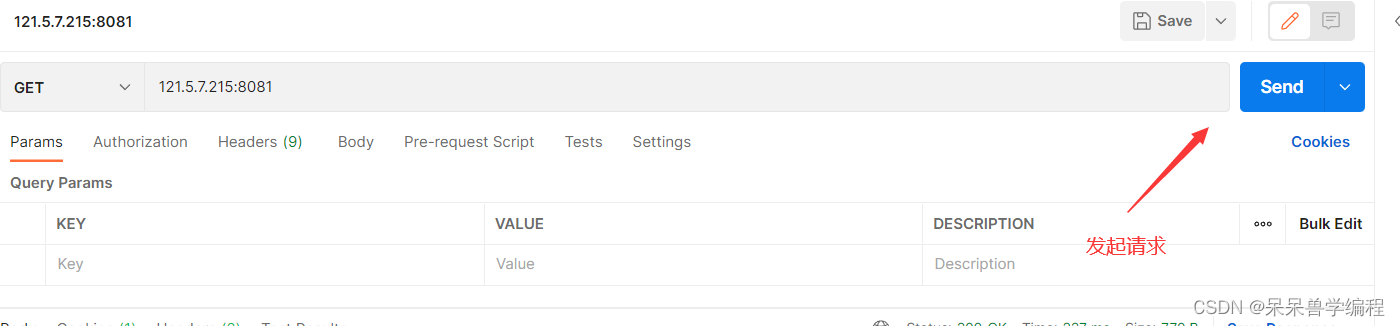

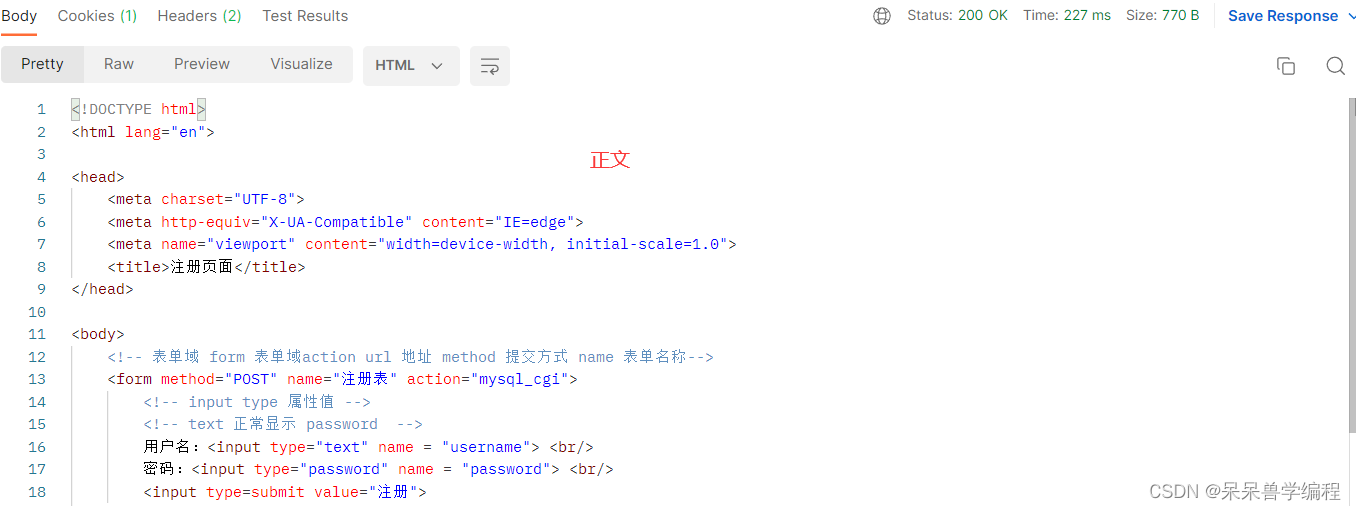
回答几个问题:
- 如何将报头和有效载荷进行分离?
空行分隔有效载荷和报头
- 如何将报文读取完毕?
在读取报头时,将
Contetn-Length属性字段描述的内容记录下来,正文读取
Content-Length大小的内容,就代表将正文读取完毕
🌲HTTP的方法
列举常见的几种:
方法说明支持的HTTP协议版本GET获取资源1.0/1.1POST传输实体主体1.0/1.1PUT传输文件1.0/1.1HEAD获得报文首部1.0/1.1DELETE删除文件1.0/1.1OPTIONS询问支持的方法1.1TRACE追踪路径1.1
说明: HTTP/1.1在HTTP/1.0基础上增加了长连接和缓存处理等内容,HTTP/1.0是基于请求与响应的,每次发送请求都需要重新建立连接,获得响应后关闭连接,而HTTP/1.1是支持长连接,客户端可以通过一个连接向服务器发起多个HTTP请求,上层依次读取请求后还会保持连接。
这里主要介绍两个方法:GET和POST
- GET 可以直接获取资源,还可以上传数据,通过url进行参数的传递(例如:?a=10&b=20)
- POST 上传数据。通过正文进行传参,报头中还会携带
Content-Length字段,说明正文内容大小
🌲HTTP状态码
状态码类别原因1XXInformational(信息性状态码)接收的请求正在处理2XXSuccess(成功状态码)请求正常处理完毕3XXRedirection(重定向状态码)需要进行附加操作完成请求4XXClient Error(客户端错误状态码)服务器无法处理器5XXServer Error(服务端错误状态码)服务器处理请求出错
常见的状态码:
- 200(OK)
- 301(临时重定向)
- 307(永久重定向)
- 403(Forbidden)
- 404(Not Found)
- 504(Bad Gateway)
🌲HTTP常见的报头属性
- Content-Type: 数据类型(常见的text/html)
- Content-Length: 正文的长度
- Host: 客户端请求的资源在哪台主机上的哪一个端口号
- User-Agent: 声明用户的操作系统和浏览器版本信息
- referer: 当前页面是从哪个页面跳转来的
- location: 告诉客户端接下来要访问哪里
- Cookie: 用于在客户端存储少量信息,通常用于实现会话(session)的功能
这里重点介绍一下Cookie,我们都知道,http的几个特性:
- 无连接:HTTP发送请求与响应是不用关心连接的,因为底层的TCP协议已经做好连接
- 无状态:HTTP不会记录双方的状态
我们在浏览器登录一些网站时,要输入账号密码进行登录,由于HTTP是无状态的,所以我们每次访问这些网站都需要重新进行登录,这样就显得有点麻烦,于是一般浏览器都会有一种
Cookie
和
Session
的机制,它可以记录上一次请求的一些信息,包括账号密码等,这个机制是独立于HTTP的,用来保存用户的状态。
Cookie:
以登录某个网站为例,用户第一次在浏览器输入账号和密码并且提交信息向服务器发起认证请求,服务器会核对数据库,认证成功后,会设置Set-Cookie,然后将Set-Cookie响应给浏览器,浏览器会将Set-Cookie的值进行提取,并保存在一个cookie文件中,这样浏览器本地就保存了用户的登录认证信息。(如下)
下一次访问该网站时,浏览器会自动将cookie文件中的内容提取并填充请求报头中的cookie字段,这样服务器端也就自动完成了认证,也就实现了免账号密码登录了。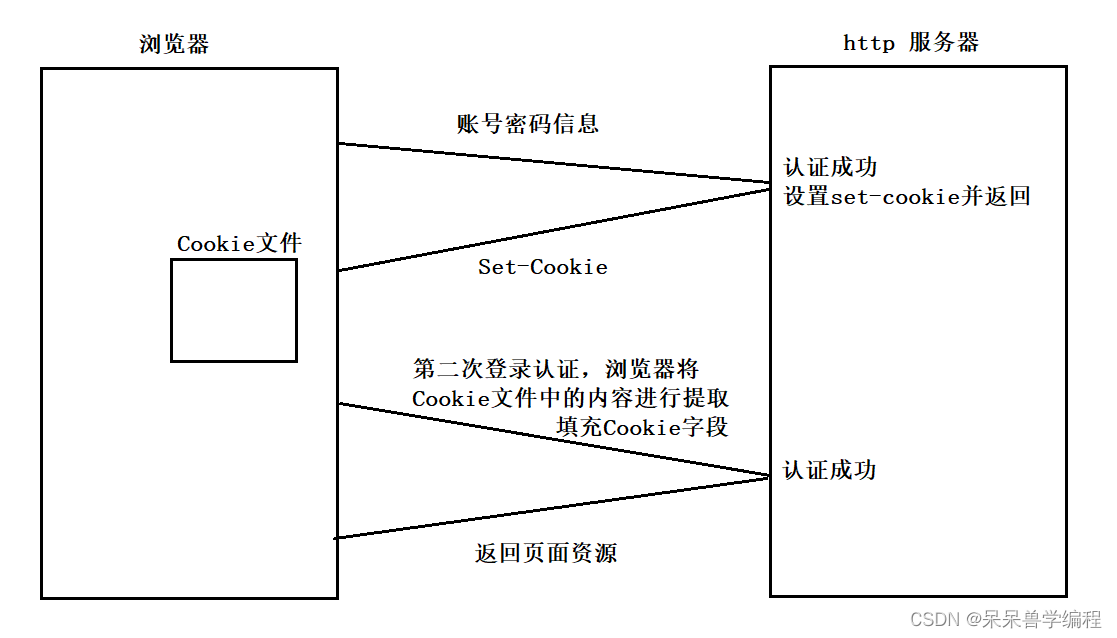
cookie文件分为内存级别和文件级别,前者是浏览器关闭,cookie文件就消失,后者是保存在本地磁盘,可以永久保存。
cookie带来的问题:
cookie文件容易被恶意软件盗取,或者一些非法钓鱼网站获取,这样非法用户就可以拿着我们的cookie文件登录访问我们登陆过的网站,这样就造成了信息泄漏。
cookie和session共同解决:
为了解决cookie文件泄漏的问题,又引进了一种机制——session,cookie与session结合使用,减少了信息泄漏的可能性。具体如下:
在上面的基础上增加了一个session的机制,浏览器第一次想服务端发起请求,服务器会创建一个
Session
将用户的信息进行保存,用来确定用户身份,同时会生成一个
Session ID
,服务器会将这个
Session ID
进行返回,给浏览器,浏览器会将
Session ID
保存在
Cookie
文件中,以后的每一次认证,都是通过
Session ID
来进行的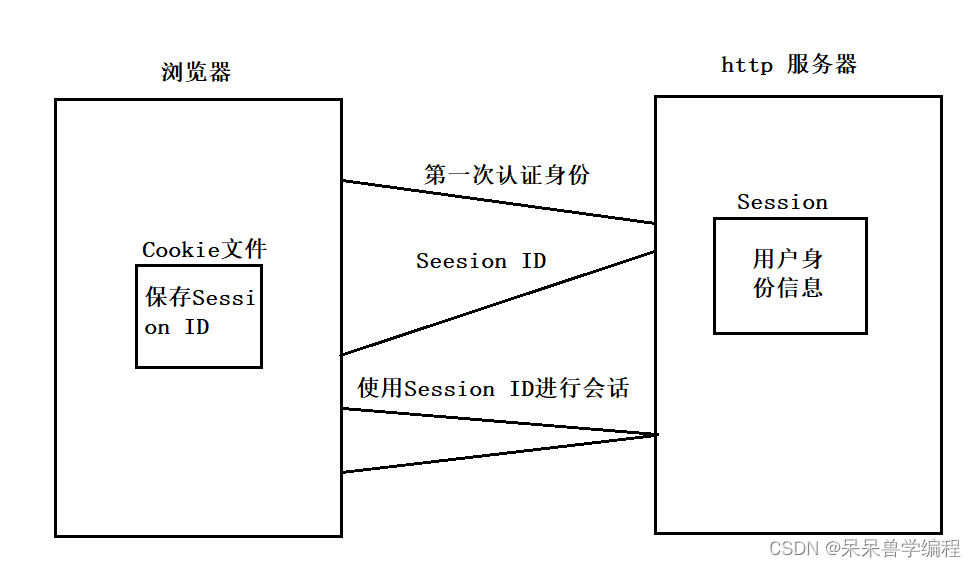
这样,Session通过在服务器端记录信息确定用户身份,Cookie通过在客户端记录信息确定用户身份。当然Session ID也是有时间限制的,Cookie的文件大小也限制在了4K。这样就能够比单纯使用Cookie更安全。
🌏HTTPS
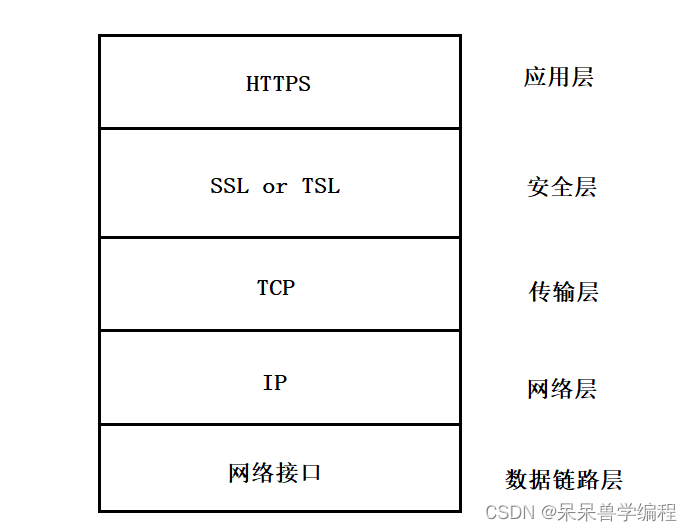
HTTPS是HTTP的安全版本,也叫超文本安全传输,HTTPS会对要传输的数据进行加密,由SSL软件层来提供加密基础,这样HTTPS就比HTTP更安全。可以理解为HTTP+SSL/TSL=HTTPS,SSL和TSL选择一个,SSL(Secure Sockets Layer)协议既安全套接字层协议,TLS(Transport Layer Security)协议即安全传输层协议。
)
HTTP和HTTPS区别:
- HTTP使用明文传输数据,HTTPS是密文传输,中间有一层SSL或TSL进行加密,更安全
- HTTP使用的端口号是80,HTTPS使用的端口号是443
- HTTPS需要申请证书
🌐总结
HTTP协议的全部内容就介绍到这里了,喜欢的话,欢迎点赞、收藏和关注支持~
版权归原作者 呆呆兽学编程 所有, 如有侵权,请联系我们删除。