
第一章 总体需求
1.1.课题背景
近年来,大数据称为热门词汇,大数据分析随着互联网技术的发展愈加深入电商营销之
中,越来越多的电商企业利用大数据分析技术,利用信息化对产业发展营销方向进行确定,
对电子商务行业大数据的特性和背后价值进行深入挖掘,打破传统营销的空间、人群等限制,
在电商场景、渠道客户等各个方面洞察用户的精准营销,从而实现个性化营销与服务等,为
企业发展注入新的活力。而在大数据分析与电商营销的融合过程中,主要是对消费者们的心
理动态特征及行为等方面的分析,把营销与消费者关系作为纽带连接起来,通过得出的有效
数据,对电商营销的整个过程进行实时监控,来优化营销方案与流程,以达到更好的经济效
应。
本文以股票交易背景,针对其用户多、用户地域分布广且在线业务量大的特 点,开发一个关于股票交易信息的大数据看板,用于可实时观测股票交易大数据信息,展示部分重要业绩数据。
1.2.功能需求
本文主要目标是通过实时计算技术、Web 技术构建一个股票交易信息大数据看
a) 订单的已处理速度,单位为“条/秒”;
b) 近 1 分钟与当天累计的总交易金额、交易数量;
c) 近 1 分钟与当天累计的买入、卖出交易量;
d) 近 1 分钟与当天累计的交易金额排名前 10 的股票信息;
e) 近 1 分钟与当天累计的交易量排名前 10 的交易平台;
f) 展示全国各地下单客户的累计数量(按省份),在地图上直观展示;
g) 展示不同股票类型的交易量分布情况;
h) [可选]对单支股票的交易量爆发式增长进行预警:
第二章 方案分析
在课题的测试环境中,订单数据模拟器将模拟实时产生股票交易订单信息,且数据会自动存入 MySQL 数据库相应的表中,因此需要通过对接 MySQL 来同步接收数据并统计保存结果。本文结合实时计算的相关技术,制定了两种方案实现课题需求。
2.1.方案一
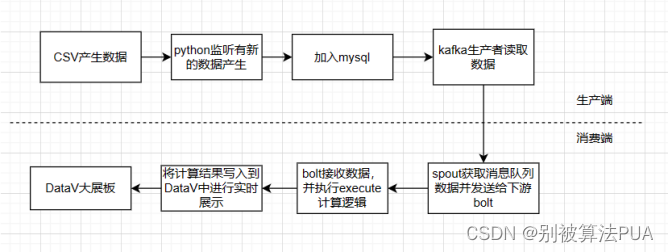
方案一的架构如图 1 所示。由于数据模拟器产生的数据会存入 MySQL,因此选择了 Kaf ka 作为消息中间件,把 MySQL 的数据传入到 Kafka 中,再使用 Storm 作为流计算平台,Orderstock 表的数据进行相关统计,同时将统计结果存储至 Mysql。
网页的部分主要使用 Datav 框架。
该方案的优点是:
采用实时读取 MySQL 的方式对接 Kafka,不需要对数据进行处理操作;
Storm 中仅用一个拓扑就可以实现表的数据统计,结构简单易懂;
Datav 具有操作简单的特点;
该方案的缺点是:
Storm 在实际过程中的吞吐量较低;
Redis 将数据保存至内存中,因此在大数据场景下对机器性能有一定要求
2.2.方案二
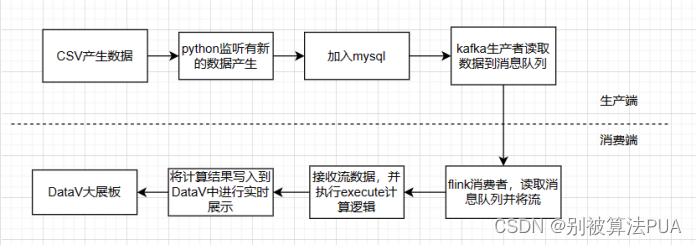
方案二的架构如图 2 所示。实时生产的电商数据传入 MySQL 数据库中,消息中间件 Ka
4fka 通过 MaxWell 读取 MySQL 的数据增量日志 binlog 作为数据生产源,再利用 Flink 流计算平台统计不同表的数据结果存储至 MySQL。而网页部分则采用 Datav 作为开发框架,通过读取 MySQL 中的统计结果传至前端界面.该方案的优点是:
- Maxwell 能够将 MySQL 的日志 binlog 作为数据源,并且以 json 形式输出至 Kafka,
实现实时接收数据增量;
- Flink 对窗口事务的支持较为完善,自带窗口聚合方式实现数据统计;
3.Datav上手简单。
该方案的缺点是:
- Maxwell 只能将 binlog 输出至一个 Topic,因此在消费 Kafka 数据时,需要手动过滤
不同表的日志并统计;
Flink 需要解析 Json 数据,因此对于较为复杂的数据结构,解析过程较为繁琐;
反复连接 MySQL 写入实时数据容易消耗大量时间,导致数据库负载过高,降低运
行效率。
2.3.最终方案
综合上述三种方案分析比较后,可知方案一的架构相对简洁,且在读写效率和方案可行
性方面,方案一都优于其他二者;同时其性能较为稳定,能够满足项目基本需求。因此,本
文最终采用方案一作为讲解的方案。
第三章 总体方案
主要由数据源、消息中间件、流计算系统、实时数据存储和实时数据应用五大板块组成。
数据源为 MySQL,其中 MySQL 不断接收来自订单模拟器传输的数据。消息中间件为 Ka
fka,Kafka 将 MySQL 中的数据依次读取出来,并设置一个主题 TOPIC1,TOPIC1 负责存储 orderstock数据库的订单详情表信息。流计算系统选取的是 Storm,在 Storm 中设置一个拓扑,拓扑中的 OrderSpout订阅 TOPIC1的数据,并将其作为数据源分别发送至 OrderBolt。在 OrderBolt 和 DetailBolt 中,同时设置了一个 JDBC 对象来获取 Java 与 MYsql数据库的连接,把数据的统计结果实时更新至 Datav 中,实现对实时数据的计算。
第四章 单元实现
4.1.数据采集
由于订单数据模拟器会将数据实时发送至 MySQL 数据库中,因此本文选择在 Kafka 生
产者中建立与 MySQL 数据库的连接,将最新的数据依次读取出来,并创建 Orderstock 类存放
Orderstock 表的数据。
创建 Kafka 生产者的配置信息。
Properties props = new Properties();
props.put("bootstrap.servers", "kafka1:9092,kafka2:9093,kafka3:9094");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
String info_js = JSON.toJSONString(info, SerializerFeature.WriteMapNullValue);
**//**打印
System.out.println(info_js);
**//将数据发送至topic**
producer.send(new ProducerRecord<String, String>("bookOrder-7", info_js));
4.2.数据的分发与订阅
Kafka 中的生产者接收来自 MySQL 实时新增的数据,发送至 topic1
主题。本文选择通过 Storm 对接 Kafka 传输的数据,在 OrderSpout 和 DetailSpout 中创
建 Kafka 的消费者,订阅 topic1主题,其中 OrderSpout 负责接收 Ord
er 表数据,DetailSpout 负责接收 Orderstock 表数据,将数据传输到 Bolt 中。
Properties props = new Properties();
props.put("zookeeper.connect","localhost:2181");
props.put("group.id","group");
props.put("zookeeper.session.timeout.ms","4000");
props.put("zookeeper.sync.time.ms","200");
props.put("auto.commit.interval.ms","1000");
props.put("auto.offset.reset","latest");
props.put("bootstrap.servers","localhost:9092,localhost:9093,localhost:9094");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("serializer.class","kafka.serializer.StringEncoder");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
ArrayList<String> topics = new ArrayList<>();
topics.add("bookOrder");
public void nextTuple() {
ConsumerRecords<String, String> consumerRecords = consumer.poll(0);
if(consumerRecords != null){
// System.out.println("DetailSpout**发射数据...");**
*consumerRecords.forEach(record -> collector.emit(new Values(record.value())));
// System.out.println("DetailSpout**发射成功!");**
}*}
4.3.数据的统计与存储
Spout 接收到数据后,需要发送至 Bolt 进行数据统计,其中 OrderSpout 将数据发送至 O
rderBolt,DetailSpout 将数据发送至 DetailBolt。
在 OrderBolt 中,主要的统计项目是:
总交易数量;
上市交易数量;
总交易额;
总买入金额;
总卖出金额;
6.实时买入金额
7.实时卖出金额
8.各个股票的总交易金额
9.各股票的实时交易金额
10.各交易公司的总交易金额
11.各交易公司的实时交易金额
12.各服务类型的总交易金额
13.各服务类型的实时交易金额
14.各省市的总交易金额
15.各省市的实时交易金额
本文主要通过 Mysql 进行数据的实时统计与存储,因此在 OrderBolt 和 DetailBolt 分创建
jdbc 对象获取与 Mysql 数据库的连接,且每接收到一条数据,对 Mysql 中指定 Key 的 value
进行自增或自减操作,实现数据的实时统计。由于不同数据的统计要求不一,需要依据其特
点选用相应的存储模式。具体流程见图所示
try{
write++;
connection = DriverManager.getConnection(dbUrl, username, password);
String sql = "UPDATE tradeCount SET "
+ "trade = ?, "
+ "totalTradeCount = ?, "
+ "totalTradeAmount = ?, "
+ "totalBuyAmount = ?, "
+ "totalSellAmount = ?, "
+ "minuteTradeCount = ?, "
+ "minuteTradeAmount = ?, "
+ "minuteBuyAmount = ?, "
+ "minuteSellAmount = ?, "
+ "guolianTradeVolume = ?, "
+ "tongdaxinTradeVolume = ?, "
+ "changchengTradeVolume = ?, "
+ "guotaijunanTradeVolume = ?, "
+ "yinheTradeVolume = ?, "
+ "tonghuashunTradeVolume = ? "
+ "WHERE id = '股票' ";
preparedStatement = connection.prepareStatement(sql);
String updateSql = "UPDATE tradeCount SET totalTradeAmount = ?, minuteTradeAmount = ?, totalBuyAmount = ?,totalSellAmount = ? WHERE id = ?";
updateStmt = connection.prepareStatement(updateSql);
String Sql = "UPDATE tradeCount SET value= ? WHERE id = ?";
update = connection.prepareStatement(Sql);
String SqlZq = "UPDATE tradeCount SET minuteTradeAmount = ?,platform = ? WHERE id = ?";
updateZq = connection.prepareStatement(SqlZq);
String SqlHy = "UPDATE tradeCount SET totalTradeAmount = ? WHERE id = ?";
updateHy = connection.prepareStatement(SqlHy);
// String[] values = value.split(","); //等待删除,可能会删了它
String stockId = detail.getStock_name(); // 交易类型id
String local = detail.getTrade_place(); //交易地点
String server = detail.getIndustry_type(); //服务类型
long tradeCount = detail.getTrade_volume(); //单次交易数量
double tradePrice = detail.getTrade_price(); //赋值交易价格
double tradeAmount = tradeCount * tradePrice; //交易总价格
// 更新累计值
totalTradeCount.addAndGet(tradeCount2); //累计交易总量
totalTradeAmount.addAndGet((long)tradeAmount2); //累计交易总金额
// 更新近一分钟的值
long currentTime = System.currentTimeMillis();
if (currentTime - lastUpdateTime > 60000) {
minuteTradeCount.set(0); // 分钟贸易计数
minuteTradeAmount.set(0);// 分钟交易额
minuteBuyAmount.set(0);// 分钟购买金额
minuteSellAmount.set(0);// 分钟分钟销售金额
lastUpdateTime = currentTime;
}
trade++;
trade++;
trade++;
trade++;
minuteTradeCount.addAndGet(tradeCount);
minuteTradeAmount.addAndGet((long)tradeAmount2);
minute2tradeAmount.addAndGet((long)tradeAmount2);
minute3tradeAmount.addAndGet((long)tradeAmount2);
minute4tradeAmount.addAndGet((long)tradeAmount2);
minute5tradeAmount.addAndGet((long)tradeAmount2);
// 根据买入或卖出更新相应的值
if (detail.getTrade_type().equals("买入")) {
totalBuyAmount.addAndGet(tradeCount2); //总买入量
minuteBuyAmount.addAndGet(tradeCount2); //分钟买入量
} else if (detail.getTrade_type().equals("卖出")) {
totalSellAmount.addAndGet(tradeCount2); //总卖出量
minuteSellAmount.addAndGet(tradeCount*2); //分钟卖出量
}
long currentTimeZj = System.currentTimeMillis();
if (currentTimeZj - lastUpdateTime > 60000) {
guolianTradeVolume.set(0); // 分钟贸易计数
tongdaxinTradeVolume.set(0);// 分钟交易额
changchengTradeVolume.set(0);// 分钟购买金额
guotaijunanTradeVolume.set(0);// 分钟分钟销售金额
yinheTradeVolume.set(0);// 分钟购买金额
tonghuashunTradeVolume.set(0);// 分钟分钟销售金额
lastUpdateTime = currentTimeZj;
}
Random random = new Random();
int randomNumber = random.nextInt(31) + 60;
//更新券商交易量
if (detail.getTrade_platform().equals("国联证券")) {
guolianTradeVolume.addAndGet(tradeCount*2); //统计数量国联证券
}
else if (detail.getTrade_platform().equals("通达信")) {
tongdaxinTradeVolume.addAndGet(tradeCount*2); //统计数量通达信
}
else if (detail.getTrade_platform().equals("长城证券")) {
changchengTradeVolume.addAndGet(tradeCount*2);//统计数量
}
else if (detail.getTrade_platform().equals("国泰君安证券")) {
guotaijunanTradeVolume.addAndGet(tradeCount*2);//统计数量
}
else if (detail.getTrade_platform().equals("银河证券")) {
yinheTradeVolume.addAndGet(tradeCount*2);//统计数量
}
else if (detail.getTrade_platform().equals("同花顺")) {
tonghuashunTradeVolume.addAndGet(tradeCount*2);//统计数量
}
Map<String, Long> tradeVolumes = new HashMap<>();
tradeVolumes.put("国联证券", guolianTradeVolume.get());
tradeVolumes.put("通达信", tongdaxinTradeVolume.get());
tradeVolumes.put("长城证券", changchengTradeVolume.get());
tradeVolumes.put("国泰君安证券", guotaijunanTradeVolume.get());
tradeVolumes.put("银河证券", yinheTradeVolume.get());
tradeVolumes.put("同花顺", tonghuashunTradeVolume.get());
Map<Long, String> sortedVolumes = new TreeMap<>();
for (Map.Entry<String, Long> entry : tradeVolumes.entrySet()) {
sortedVolumes.put(entry.getValue(), entry.getKey());
}
Long value_zq1 = null;
Long value_zq2 = null;
Long value_zq3 = null;
String platform1 = null;
String platform2 = null;
String platform3 = null;
int count = 0;
for (Map.Entry<Long, String> entry : ((TreeMap<Long, String>) sortedVolumes).descendingMap().entrySet()) {
if (count >= 3) {
break;
}
if (count == 0) {
value_zq1 = entry.getKey();
platform1 = entry.getValue();
} else if (count == 1) {
value_zq2 = entry.getKey();
platform2 = entry.getValue();
} else if (count == 2) {
value_zq3 = entry.getKey();
platform3 = entry.getValue();
}
count++;
}
//更新地图数据
DetailBoltMySql.values v = valueMAP.computeIfAbsent(stockId, k -> new DetailBoltMySql.values());
v.value.addAndGet(tradeCount*3);
//更新各个服务类型的总金额
DetailBoltMySql.servers s = serverMAP.computeIfAbsent(server, k -> new DetailBoltMySql.servers());
s.server.addAndGet((long) tradeAmount*3);
//更新不同股票数据总交易金额
DetailBoltMySql.StockTradeInfo stockTradeInfo = stockTradeInfoMap.computeIfAbsent(stockId, k -> new DetailBoltMySql.StockTradeInfo());
stockTradeInfo.totalTradeAmount.addAndGet((long) tradeAmount*3);
// 更新近一分钟的交易金额
long Time = System.currentTimeMillis();
if (Time - stockTradeInfo.lastUpdateTime > 60000) {
stockTradeInfo.minuteTradeAmount.set(0);
stockTradeInfo.lastUpdateTime = Time;
// trade = 10;
}
stockTradeInfo.minuteTradeAmount.addAndGet((long) tradeAmount);
if (detail.getTrade_type().equals("买入")) {
trade++;
stockTradeInfo.totalBuyAmount.addAndGet(tradeCount);
} else if (detail.getTrade_type().equals("卖出")) {
stockTradeInfo.totalSellAmount.addAndGet(tradeCount);
}
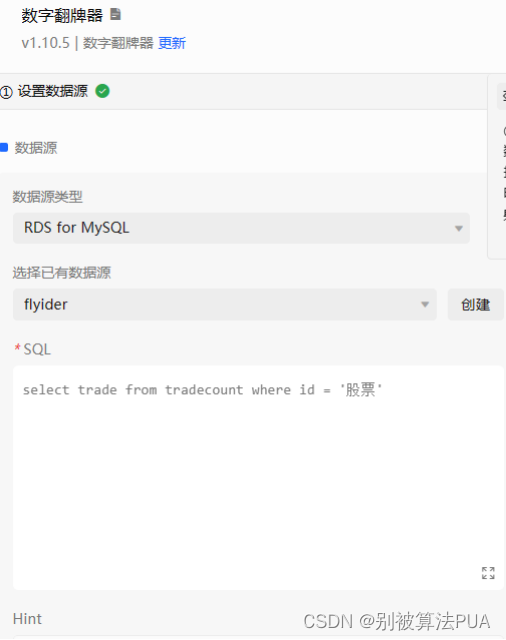
4.4.网页前后端交互
本文主要使用datav 框架实现网页的前后端交互,后端运行服务,读取 mysql 中的数据
统计结果并发送至datav
第五章 功能实现
5.1.使用说明
本文按照方案流程对电商订单数据进行实时展示。首先将 Storm 的项目 jar 包上传虚拟
机集群,运行拓扑;接着启动 Kafka 生产者,将实时增加的 MySQL 数据发送至 Storm 的计算
平台,Storm 中的 Bolt 会将数据统计结果写入 mysql 中。
5.1.1. 启动 Zookeeper、Kafka、Storm
5.1.3. 上交拓扑至 Storm 集群
在基本的环境准备工作完成后,下一步是上传设计的拓扑至 Storm 集群中,这里我们是
将 IDEA 编写的 Storm 程序打成 jar 提交至集群,提交成功后,控制台打印信息。
另外,我们可以在 StormUI 页面查看此时 Topology Summary 已经存在一个名为 mytop 的拓
扑,如图 24 所示,页面会显示其已运行时间及状态,在拓扑内容可查看方案设计中的两个
Spout 和两个 Bolt,并且拓扑中的 Worker 由两个从节点 Slave1 和 Slave2 组成。
5.1.4. 启动订单数据模拟器
如图 27 所示,我们在订单数据模拟器中输入 MySQL 所在的 IP 地址及用户名,点击创
建数据库并开始写入数据。
5.1.5. 运行 Kafka 程序
订单数据成功开始产生后,我们需要启动 IDEA 的 Kafka 程序,程序主要实现了对接 My
SQL 实时数据和将数据发送至 Topic 的功能,运行成功后,可在控制台实时看到接收的订单
数据。
5.2.界面效果
5.2.1. 页面总体效果
页面的总体效果如图所示,页面主要分为七个板块:

功能1—实时展示订单速度

功能2—股票行业分层,含各行业实时金额排序:

功能3—股票交易额排行

功能4—实时平台排名,与平台实时的交易额

功能5—销量最高股票的买入卖出情况

功能6—股票交易总额实时交易额
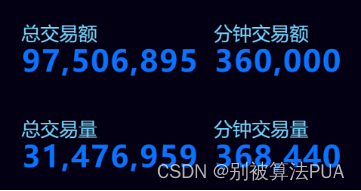
功能7—股票实时交易量总体情况与排行

功能8—股票总交易量总体情况与排行

功能9—全国各地交易次数热力图

第六章 实验设计与结果分析
6.1.项目运行环境
6.1.1. 本地计算机系统配置
表 1 本地计算机系统配置
操作系统:Windows10
软件版本:python2022,idea2022
Doker配置:storm2.5.0(nimbus2.5.0,supervisor2.5.0);Mysql5.7;Kafka:latest;zookeeper:lastest
6.1.2. docker配置
安装 Zookeeper、Kafka、Storm
6.2.结果分析

第七章 项目特色
本项目的特色之处如下:
使用 Storm 作为流计算系统,计算效率稳定;2. 使用 datav 作为实时数据存储,操作简单,
数据库只存放最终数据,所以计算过程放在execute中。
网页实现可在 0.5s 内刷新一次,且能够通过动态的动画展示数据变化;
订单接收速率和订单模拟器产生速率的误差最低能够在 1%以内(见第六章);
数据延迟平均保持在 1 秒以内(见图 39 和图 40);
项目实现了 7 个数据统计模板;
第八章 问题分析
1.拓扑已经上传,但是并没有进行计算:
场景:将csv文件放在本地项目中,测试代码能否跑通,结果拓扑一直都能上传,但是一直没有进行计算


最后找到源码的出处询问原因才知道:拓扑结构提交后是无法读取本地数据的。所以一开始的方向是错误的。
2.依赖冲突:一开始使用的storm是最高版本,在idea中的storm相关依赖都是2.5.0版本,于是报有以下错误:

编辑
最后将依赖的版本逐个降低到2.3.0何1.0.0都能成功运行。
3.在storm中上传jar报,提交拓扑时,找不到jar报中的主类:

编辑
经过进一步的探究,原因是我打包有问题,一开始不清楚该如何打包,我使用的都是传统的打包方式,那种方式只是将java文件编译了一遍放入jar包中,相关的依赖包都没有导入,后来又使用了idea自带的打包方式,也有这种问题。通过查阅maven的相关使用方法系统学习了打包方式,才正确打包。maven的5种打包方式,终有一款适合你1_maven打包-CSDN博客
4.解决打包问题后,又遇到了新的与打包相关的问题:打包的jar包中有一个yaml文件,有storm中原带的同名yaml文件冲突:这时候有两种解决方法,一种是排除掉storm集群中的yaml文件。

编辑
最后的解决方法:最后在pom文件的打包配置中,引入一个组件,用来排除原java项目中的yaml,直接就解决了。

编辑
5.一开始不知道DataV使用的是mysql的时候,是将数据放入redis中,遇到了一个相关问题:
即在本地使用LocalCluster方法运行拓扑,能过正常的将数据写入到redis中,但是一旦将jar包放入到storm集群中,前面的能够全部连通,但是数据无法写入到redis中。

编辑
解决方法:根据报错结果分析,应该是路径问题,但是最终还没解决,发现datav使用的mysql就改用sql没管这个问题了。
1.阿里云的DataV无法实时展示:
在这个时候我的sql里的数据都是在实时变化的,但是Datav数据不能实时变化,有以下两点原因:
在数据库设置中,需要设置数据每秒自动请求:
除此之外,不能使用全局变量去获取数据:
2.在idea中,无法连接到外部的kafka:
无论是直接使用ip还是使用localhost都无法找到外部的idea:


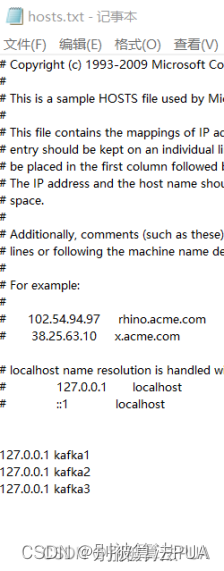
编辑
编辑在后来在host文件中配置了kafka1:172.0.0.1后,发现连接成功:
编辑
配置后发现,无论是使用localhost还是使用kafka1,2,3都可以连接到了。这很奇怪,因为直接使用localhost本质上就是使用172.0.0.1,使用kafka1,2,3也是使用172.0.0.1.但为什么配置以上的内容之后就可以?
3.storm集群搭建问题
使用docker-compose.yaml文件之后,strom无法连接到zookeeper集群:

编辑
这时需要去storm.yaml文件中更改配置文件,手动的将storm与zookeeper连接上

编辑
4.storm集群的搭建出现问题,具体参考:docker-compose搭建storm、zookeeper集群,解决Could not find leader nimbus from seed hosts [localhost]问题-CSDN博客
5.重复读取消息队列中的内容,在将新生产的消息消费完成之后,offset(偏移量)又会到一个之前已经消费过的地方开始继续消费,导致一直能有消息在进行消费:


在配置中,配置以上的内容都发现没有用,仍然有这个问题,之后,借鉴了相关的代码:
第九章 心得体会
完成这次大作业的过程给我带来了许多新鲜的感觉,这是我第一次从真正意义上认识到
大数据专业目前在社会上的实际应用场景。刚开始搭建 Kafka 的部分并没有让我早早地看清
大作业任务的艰巨,直到进行使用 Kafka 对接 MySQL 数据的环节,才让我知道什么是寸步
难行、步履维艰。
在进行到大作业的后半段,从摸索着如何写一个 Storm 程序、如何将 Kafka 的数据再传
入 Storm、如何在 Storm 的 Bolt 中实现对数据的统计等等过程当中,我对于搭建实时计算平
台的流程越来越熟练,越来越清晰,直到结束之际,我已经能根据所搭建的实时计算平台流
畅的画出架构图,并对其中的原理、各组件的功能、操作流程基本了如执掌。如果对这学期
刚开始的我而言,这可能是无法想象的事情,所以当我看到自己实现的大数据看板在不断的
跳动、变化时,内心的成就感油然而生。
在整个项目的开发过程中,除了最后实现它所收获的成就与喜悦,还出现了一堆十分让
我头疼的小插曲。比如,上传 jar 包到 Storm 集群上报错,报错信息的解决方案在网上根本
找不着,所以只能自己一个一个去排除可能的问题。类似这种情况的问题还有很多,有的时
候为了解决一个报错耗费了将近两小时也没找到正确解决的办法,但是在解决这些问题的过
程中,也让我对各个组件功能的了解进一步加深。
版权归原作者 别被算法PUA 所有, 如有侵权,请联系我们删除。