
本文还有配套的精品资源,点击获取 
简介:本项目演示了如何利用Docker-Composer、Spark、Cassandra、Parquet和SnackFS等BigData技术处理金融数据,特别是在股票市场中的应用。通过使用Docker Compose管理多容器应用,Apache Spark的高效数据处理能力,以及Cassandra的可扩展分布式数据库技术,项目展示了这些工具如何结合起来创建一个强大的数据处理流水线。此外,利用Parquet格式对大数据集进行优化存储与高效读取,并通过SnackFS简化数据存储访问。整个项目以Scala语言编写,展示了如何建立一个可用于股票筛选和市场分析的可扩展BigData平台。 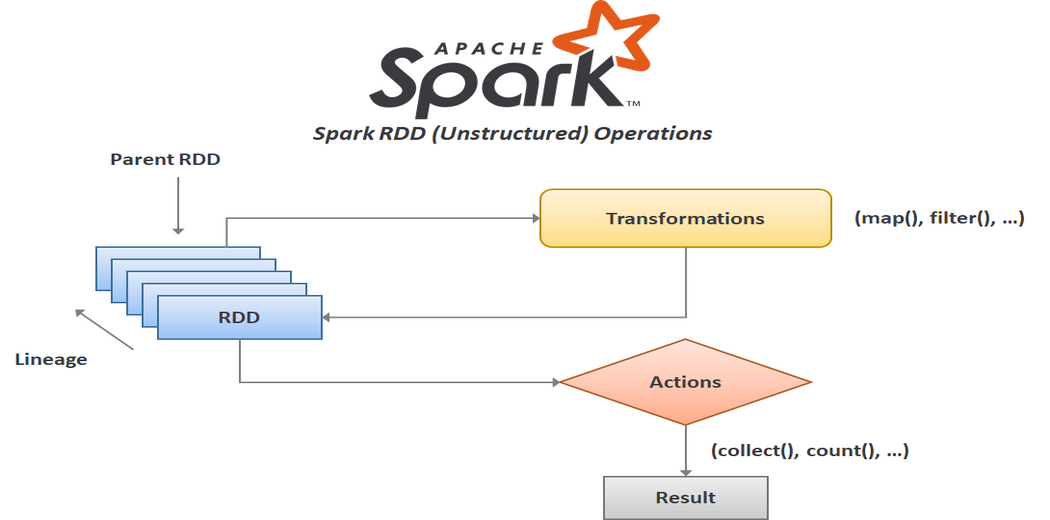
1. stock-screener-demo项目概述
在当今这个信息飞速发展的时代,股票筛选器成为了投资者分析和决策的重要工具。stock-screener-demo项目旨在为金融分析师和投资者提供一个强大的股票筛选平台,它不仅简化了筛选流程,还增强了数据分析的深度和广度。
1.1 项目背景与意义
股票市场充满机遇,同时也伴随高风险。传统的股票筛选方法往往依赖于分析师的经验和直觉,而stock-screener-demo采用先进的算法和数据处理技术,将复杂的数据分析工作自动化,帮助用户更加客观、高效地筛选出具有潜力的股票。
1.2 功能特点
此项目具有以下几个核心特点:
- ** 实时数据接入 ** :通过API接口,实时获取股票市场数据。
- ** 定制化筛选器 ** :提供丰富的筛选条件,如市盈率、市值、股息率等。
- ** 交互式数据展示 ** :利用图表和报表直观展示筛选结果。
- ** 智能分析推荐 ** :基于机器学习算法,为用户提供投资建议。
1.3 技术选型
在stock-screener-demo项目中,我们采用了如下技术栈:
- ** 前端技术 ** :React.js,为用户界面提供响应式和动态交互。
- ** 后端技术 ** :Node.js和Express.js,负责处理业务逻辑和API请求。
- ** 数据分析 ** :Python和Pandas,用于深入的数据分析和挖掘。
- ** 数据存储 ** :MongoDB,存储用户数据和筛选结果。
1.4 项目展望
随着项目的不断完善,我们预期stock-screener-demo将成为金融行业数据分析的有力工具,不仅提升用户体验,更促进了数据驱动的投资决策的普及。此外,通过持续的技术迭代,项目也将为用户带来更多创新功能,助力用户在复杂的金融市场中把握先机。
2. Docker-Composer基础与应用
2.1 Docker-Composer简介
2.1.1 Docker-Composer的作用与优势
Docker-Composer是Docker官方提供的一个工具,主要用于定义和运行多容器Docker应用程序。它通过一个YAML文件来配置应用程序的服务,使得用户可以统一地创建、部署和运行包含多个容器的应用程序。Docker-Composer的主要优势在于其简化了复杂容器应用的创建和管理过程,能够快速启动和停止容器、管理容器间网络和卷的连接等。
2.1.2 Docker-Composer核心概念解读
Docker-Composer涉及的核心概念包括服务(services)、卷(volumes)、网络(networks)等。 - ** 服务(services) ** :定义应用的容器运行的次数。 - ** 卷(volumes) ** :用于在容器和服务之间共享数据。 - ** 网络(networks) ** :服务在其中运行的网络。
2.2 Docker-Composer实践操作
2.2.1 环境搭建与初步配置
为了开始使用Docker-Composer,用户首先需要在其系统上安装Docker以及Docker-Composer。安装完成后,通过编写一个简单的
docker-compose.yml
文件来创建第一个应用。比如以下是一个简单的Web应用的配置文件:
version: '3'
services:
web:
image: nginx:alpine
ports:
- "8000:80"
volumes:
- ./html:/usr/share/nginx/html
该配置定义了一个名为web的服务,它使用
nginx:alpine
镜像,并将本地的8000端口映射到容器的80端口。它还使用卷将本地的
html
目录挂载到容器的
/usr/share/nginx/html
目录下。
2.2.2 Docker-Composer文件编写技巧
编写Docker-Compose文件时,以下是一些常用技巧: - ** 使用环境变量 ** :可以在docker-compose.yml文件中使用
${VARIABLE}
来引用环境变量。 - ** 构建镜像 ** :如果本地没有镜像,可以直接在docker-compose文件中指定Dockerfile来构建镜像。 - ** 多阶段构建 ** :利用Docker 17.05及以上版本支持的多阶段构建,优化镜像大小。 - ** 使用扩展 ** :
extends
字段允许从另一个服务继承配置,便于复用和配置分离。
2.2.3 部署与管理Docker容器集群
部署和管理容器集群涉及到容器的启动、停止、重启以及资源的分配和监控等操作。Docker-Composer提供了简单的命令行工具,允许用户通过一个命令来管理整个应用的生命周期。例如,使用
docker-compose up
命令启动服务,使用
docker-compose down
命令停止服务。
2.3 Docker-Composer进阶应用
2.3.1 复杂应用的编排与部署
在处理复杂的多服务应用时,Docker-Composer提供了强大的编排能力。通过在docker-compose.yml文件中定义多个服务以及服务间的关系,Docker-Composer可以协调这些服务的启动和停止顺序,确保应用的正常运行。
2.3.2 Docker-Composer的网络与存储配置
Docker-Composer允许用户定义自己的网络和存储。这包括创建自定义网络,以隔离服务之间的通信,或者创建持久化卷来保存服务数据。
例如,创建一个桥接网络:
version: '3'
services:
web:
image: nginx:alpine
networks:
- mynetwork
networks:
mynetwork:
driver: bridge
2.3.3 监控与日志管理
监控和日志管理对于容器化应用至关重要。Docker-Composer集成了一些工具来帮助用户监控其容器的状态和收集日志。例如,可以利用Docker内置的日志收集功能,通过
docker-compose logs
命令来查看服务的日志输出。
Docker-Composer通过将容器应用编排到一个或多个容器中,使得开发者可以专注于构建应用程序而不是基础设施的配置。通过这种方式,Docker-Composer提高了开发和运维的效率,实现了容器应用的快速、一致和可靠的交付。
3. Apache Spark的快速数据分析
Apache Spark作为一个强大的大数据处理框架,其快速和高效的性能已经成为数据工程师和数据科学家的最爱。Spark不仅提供了对大规模数据集的快速处理能力,而且它的生态系统还包含了许多用于不同数据处理需求的组件。在本章节中,我们将深入解析Spark的核心架构,实践编程,以及如何进行性能优化和故障排除。
3.1 Spark核心架构解析
3.1.1 Spark运行模型与执行流程
Apache Spark的运行模型基于内存计算机制,相比传统的基于磁盘的数据处理框架,如Hadoop MapReduce,Spark能够显著地提高大数据处理速度。这一性能提升主要归功于其弹性分布式数据集(RDD)的概念,RDD允许数据被缓存内存中,从而进行快速迭代计算。
在执行流程上,Spark作业首先被转换为一个有向无环图(DAG),表示任务执行的各个阶段。然后,DAG调度器将DAG划分为多个阶段,每个阶段是一个任务集合,而任务则会被分配到集群中的不同节点上去执行。
3.1.2 Spark组件功能与协同工作
Spark生态系统包含多种组件,如Spark SQL用于处理结构化数据,Spark Streaming用于处理实时数据流,MLlib用于机器学习和GraphX用于图处理。所有这些组件都能够以高层次的抽象协同工作,简化了复杂数据处理任务的实现。
以Spark Streaming为例,它能够接收实时数据流,并将其切分成一系列小批次(micro-batches)。这些小批次的数据随后由Spark引擎进行处理,用户可以使用Spark的所有功能和API来处理流数据。
3.2 Spark编程实践
3.2.1 Spark SQL与DataFrame的使用
DataFrame是Spark SQL的一个核心概念,它是一个分布式数据集合,提供了丰富的数据操作API。用户可以使用DataFrame API执行各种复杂的数据转换操作。
使用DataFrame的第一步通常是读取数据源(如CSV文件、JSON格式数据等)。以下是一个使用Spark SQL读取JSON格式数据并创建DataFrame的例子:
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
val spark = SparkSession.builder.appName("Spark DataFrame Example").getOrCreate()
val df = spark.read.json("path_to_json_file.json")
df.show()
在这段Scala代码中,我们首先引入了必要的库,并创建了一个SparkSession实例。然后,我们使用
read.json
方法读取了存储在本地的JSON文件,并将其转换成了一个DataFrame实例。最后,使用
show()
方法来展示DataFrame的内容。DataFrame API还提供了多种操作方法,例如
select
,
filter
,
groupBy
, 和
agg
等,用于数据查询和转换。
3.2.2 Spark Streaming的数据流处理
Spark Streaming提供了构建高吞吐量和容错的实时数据流处理程序的能力。数据流被组织成一系列小批次处理,然后这些批次被转换成RDDs进行处理。
以下是一个简单的Spark Streaming程序,它从一个TCP套接字接收数据,并计算每批数据中的单词频率:
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
在这段代码中,我们创建了一个本地StreamingContext,并设置了一个1秒的批次间隔。接着,我们监听本地主机的9999端口接收数据,将接收到的行切分成单词,然后将单词映射为键值对,并使用
reduceByKey
聚合每个单词的出现次数。最后,我们启动了流计算,并等待终止。
3.3 Spark性能优化与故障排除
3.3.1 性能调优实战案例分析
性能调优是确保Spark作业在大数据环境下运行高效的关键步骤。一些常见的性能优化策略包括:
- 数据序列化:使用Kryo序列化可以减少数据对象在内存中的存储大小。
- 并行度:调整Spark作业的并行度来平衡集群资源的利用。
- 内存管理:合理配置内存和缓存参数,如
spark.memory.fraction和spark.executor.memory。
这里是一个使用Kryo序列化的代码示例:
val conf = new SparkConf()
.setAppName("PerformanceTuningExample")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.registerKryoClasses(Array(classOf[YourCustomClass]))
在这个代码块中,我们通过设置
spark.serializer
为
org.apache.spark.serializer.KryoSerializer
来启用Kryo序列化,并通过
registerKryoClasses
方法注册了需要被序列化的自定义类。
3.3.2 Spark常见故障诊断与解决
Spark集群在运行时可能会遇到各种问题,比如性能瓶颈、内存溢出、执行失败等。诊断和解决这些问题通常需要对Spark的任务调度、数据倾斜、资源管理等方面有深入理解。
例如,数据倾斜是导致Spark作业性能下降的常见原因。为了解决这个问题,可以采取如下措施:
- 对关键操作使用随机前缀进行重新分区,以平衡数据分布。
- 使用
mapPartitions来增加任务粒度。 - 为倾斜的数据增加额外的资源或并行执行。
这是一个使用随机前缀重新分区的例子:
df.repartition($"someColumn" + lit(rand()))
在这个代码块中,我们使用
repartition
方法和一个随机数表达式来重新分配DataFrame的分区,这有助于减少数据倾斜。
总结
在本章中,我们对Apache Spark的核心架构进行了深入的探讨,了解了其运行模型、执行流程以及各种组件之间的协同工作方式。通过实战编程,我们展示了如何使用Spark SQL与DataFrame处理结构化数据,以及如何利用Spark Streaming进行实时数据流处理。最后,通过分析性能调优案例和故障诊断方法,我们了解了如何优化Spark作业的性能并解决运行中可能出现的问题。Apache Spark无疑为大数据分析提供了强大的工具集,使得数据分析过程更快、更高效、更易于管理。
4. Cassandra分布式数据库的高可用性和可扩展性
在大数据时代,数据的存储与处理成为企业最为关注的问题之一。Cassandra作为一个高性能、高可用性的分布式数据库,特别适用于大规模数据的存储与快速查询。本章节将深入探索Cassandra分布式数据库的内部机制、集群管理技巧以及高级特性应用,以便读者可以全面掌握Cassandra的核心技术。
4.1 Cassandra架构原理
4.1.1 分布式数据库的设计理念
分布式数据库是为了解决单个服务器无法高效处理大数据量的问题而设计的。其设计理念基于分布式系统的三个原则:分片(Sharding)、复制(Replication)和一致性(Consistency)。Cassandra在这些原则的基础上,又引入了去中心化的架构和最终一致性模型,以达到高可用性和可扩展性的目标。
Cassandra允许数据在多个数据中心内分布存储,以提供跨地域的数据冗余和容灾能力。数据在多个节点之间进行复制,当某个节点发生故障时,其他节点可以接管请求,保证服务的连续性。
4.1.2 Cassandra的数据模型与存储机制
Cassandra的数据模型与传统的关系型数据库模型有较大不同。它采用列族(Column Family)作为数据存储的基本单位,从而使得对于大量列的数据读写更为高效。每个列族可以包含多个列,并且每个列族中的列可以根据需要动态添加,无需预先定义。
在存储机制方面,Cassandra使用了LSM(Log-Structured Merge-tree)树结构来存储数据,这种结构对于写入操作更为友好,可以实现快速写入和批量合并。数据在内存中以SSTable(Sorted String Table)的形式组织,当达到一定的条件时,再将数据刷新到磁盘。
// 示例代码:Cassandra的数据写入操作
// 假设使用Java Driver for Apache Cassandra进行操作
// 这段代码演示了如何将键值对插入到Cassandra数据库中
Cluster cluster = Cluster.builder()
.addContactPoint(new InetSocketAddress("***.*.*.*", 9042))
.build();
Session session = cluster.connect("my_keyspace");
PreparedStatement insertStmt = session.prepare("INSERT INTO cf (key, column1, column2) VALUES (?, ?, ?)");
BoundStatement boundInsert = insertStmt.bind("mykey", "value1", "value2");
session.execute(boundInsert);
执行上述代码前,需要在Cassandra中预先定义好键空间(Keyspace)和表(Table),指定列族和存储策略。
4.2 Cassandra集群管理
4.2.1 集群部署与配置
部署一个Cassandra集群需要进行细致的规划,包括选择合适的硬件资源、设计网络结构以及配置集群参数。通常在生产环境中,一个集群会包含至少3个节点,以支持故障转移和数据复制。
在配置集群时,主要的配置文件是
cassandra.yaml
。其中的关键配置项包括集群名称、监听地址、端口设置、复制策略以及数据存储路径等。此外,还需要配置种子节点(Seed Nodes),用于节点之间的自动发现。
4.2.2 节点添加、删除与负载均衡
随着业务的增长,数据库集群可能需要添加新的节点以提供更高的吞吐量。在Cassandra中,添加新节点相对简单,只需将新节点加入到集群配置文件中,并启动服务即可。
删除节点则相对复杂,需要通过
nodetool
工具先将节点标记为离开状态,然后执行数据清理任务,最后从集群配置文件中移除该节点。
在集群运维过程中,为了提高系统的整体性能,需要对节点进行负载均衡。Cassandra提供了多种策略,比如虚拟节点(VNodes),可以根据节点的性能自动调整数据分片的分配。
// 示例命令:使用nodetool添加和删除节点
// 假设命令行操作
// 添加节点
nodetool -h [existing-node] add [-i new-node-ip-address] [-s]
// 删除节点
nodetool -h [existing-node] decommission
4.3 Cassandra高级特性应用
4.3.1 数据复制与容错机制
Cassandra通过数据复制实现高可用性。在配置复制时,需要指定复制因子(Replication Factor),它决定了数据将会被复制到多少个节点上。复制因子的选择与集群中的节点数量和容错需求相关。
Cassandra的容错机制还包括故障检测和自动修复。当检测到节点失效时,集群会自动启动数据修复过程,将失效节点上的数据复制到其他节点上,确保数据副本的完整性。
4.3.2 读写优化与一致性级别
在读写操作中,Cassandra提供了多种一致性级别,用户可以根据业务需求选择合适的一致性级别来优化读写性能。例如,
ONE
一致性级别仅要求得到一个节点的响应即可返回结果,适用于对延迟不敏感的场景。
读写操作的性能优化不仅仅局限于一致性级别的选择。例如,通过合理配置内存和磁盘的分配,可以减少磁盘I/O操作,从而提升性能。
// 示例代码:设置读写操作的一致性级别
// 使用Cassandra Java Driver进行操作
// 设置一致性级别为ONE
ConsistencyLevel consistencyLevel = ConsistencyLevel.ONE;
BoundStatement boundStatement = statement.setConsistencyLevel(consistencyLevel);
ResultSet resultSet = session.execute(boundStatement);
在实际操作中,还需根据实际的业务场景选择恰当的数据模型、索引策略和查询模式,以达到最佳的读写性能。
通过本章节的介绍,我们对Cassandra的架构原理、集群管理和高级特性应用有了深入的理解。Cassandra作为一个强健的分布式数据库,以其独特的设计满足了大数据处理的高可用性和可扩展性需求。在接下来的章节中,我们将继续探索如何构建大数据金融数据处理流水线,以及如何使用Parquet和Scala来进一步提升数据处理的效率和能力。
5. 构建大数据金融数据处理流水线
随着大数据技术的发展,金融行业对于数据处理的需求愈发强烈。为了高效、安全地处理大量金融数据,构建一个大数据处理流水线显得尤为重要。本章节将重点介绍Parquet列式存储在数据处理中的应用、SnackFS自定义文件系统的角色,以及Scala语言在金融数据分析中的实践。
5.1 Parquet列式存储与数据处理
Parquet是一种面向分析型应用的列式存储格式,其设计目的是减少数据读取量和提升数据处理的效率。接下来我们将深入分析Parquet文件格式,并探讨其在Apache Spark中的应用。
5.1.1 Parquet文件格式详解
Parquet文件格式优化了数据的存储结构,特别适合处理大规模数据集。它通过以下几种方式实现高效率:
- ** 列式存储 ** :只读取需要的列数据,而不是整个记录,减少I/O开销。
- ** 数据压缩 ** :利用数据类型特定的编码和压缩算法,减少存储空间和提高读写速度。
- ** 元数据信息 ** :记录了数据集的统计信息和结构信息,有助于执行高效的查询操作。
5.1.2 Parquet在Spark中的应用与优势
Apache Spark作为一个大数据处理框架,对Parquet格式有着天然的支持。下面是几个关键点:
- ** 读写性能 ** :Spark可以直接读写Parquet格式数据,无需额外的数据转换过程。
- ** 数据压缩 ** :在处理大规模数据集时,Parquet的压缩特性有助于减少内存和磁盘的压力。
- ** 优化查询 ** :Spark SQL可以利用Parquet的列存特性和元数据信息来优化查询计划。
在实际操作中,可以通过以下代码示例来加载一个Parquet文件,并查看其Schema信息:
import org.apache.spark.sql.SparkSession
// 创建SparkSession
val spark = SparkSession.builder()
.appName("Parquet Example")
.master("local[*]")
.getOrCreate()
// 读取Parquet文件
val df = spark.read.parquet("path/to/your/parquet/file")
// 查看Schema
df.printSchema()
// 处理数据
df.select("yourDesiredColumn").show()
// 关闭SparkSession
spark.stop()
5.2 SnackFS自定义文件系统接口
SnackFS是一个自定义文件系统接口,旨在优化大数据环境中的文件系统性能和功能。本节将分析SnackFS架构,并探讨其在大数据环境中的应用。
5.2.1 SnackFS架构与工作原理
SnackFS是一种兼容HDFS的自定义文件系统,它通过以下方式提升性能:
- ** 缓存机制 ** :引入客户端缓存,减少对底层存储系统的访问次数。
- ** 读写优化 ** :通过优化读写策略来提升小文件处理性能。
- ** 扩展性 ** :支持水平扩展,能够处理大量并发请求。
5.2.2 在大数据环境中应用SnackFS
在大数据环境中,SnackFS可以解决一些传统HDFS存在的问题,例如:
- ** 小文件问题 ** :通过优化的读写策略,提高小文件的处理效率。
- ** 扩展性 ** :支持通过增加节点来增强系统吞吐量。
- ** 兼容性 ** :提供与Hadoop生态系统的良好兼容性。
5.3 Scala语言在大数据处理中的应用
Scala语言因其简洁性和强大的功能,在大数据领域非常流行。本节将探讨Scala的基础及其与Spark的集成,以及在金融数据分析中的实践。
5.3.1 Scala基础与Spark的集成
Scala是一种多范式的编程语言,完美地结合了面向对象和函数式编程特性。与Spark的集成使得Scala成为处理大数据的理想选择。下面是几个关键点:
- ** Spark API ** :Spark提供了丰富的Scala API,使得开发工作更加直观和高效。
- ** 类型安全 ** :Scala的类型系统有助于减少运行时错误,提升代码质量。
- ** 集成工具链 ** :Scala可以与SBT、Maven等构建工具无缝集成。
5.3.2 Scala编程在金融数据分析中的实践
Scala在金融数据分析中的应用有以下特点:
- ** 实时数据处理 ** :利用Spark Streaming,Scala可以实现复杂的实时数据处理。
- ** 金融算法实现 ** :Scala简洁的语法有助于快速实现金融数学模型和算法。
- ** 扩展和维护 ** :良好的代码结构和函数式编程特性,方便后续扩展和维护。
在金融数据分析中,可以使用以下Scala代码示例实现一个简单的数据分析流程:
import org.apache.spark.sql.SparkSession
// 创建SparkSession实例
val spark = SparkSession.builder()
.appName("Finance Data Analysis")
.master("local[*]")
.getOrCreate()
// 加载数据集
val transactionsDF = spark.read
.option("header", "true")
.option("inferSchema", "true")
.csv("path/to/finance/transactions.csv")
// 展示数据集的前几行
transactionsDF.show()
// 分析交易数据
val summaryDF = transactionsDF.groupBy("date")
.agg(
sum("amount").alias("total_amount"),
avg("amount").alias("average_amount")
)
// 展示汇总结果
summaryDF.show()
// 关闭SparkSession
spark.stop()
以上代码展示了如何使用Scala读取金融交易数据集,进行分组聚合计算,并展示结果。这仅仅是大数据金融数据处理的一个简单示例,实际应用中需要根据具体的业务需求进行复杂的数据处理和分析。
本文还有配套的精品资源,点击获取
简介:本项目演示了如何利用Docker-Composer、Spark、Cassandra、Parquet和SnackFS等BigData技术处理金融数据,特别是在股票市场中的应用。通过使用Docker Compose管理多容器应用,Apache Spark的高效数据处理能力,以及Cassandra的可扩展分布式数据库技术,项目展示了这些工具如何结合起来创建一个强大的数据处理流水线。此外,利用Parquet格式对大数据集进行优化存储与高效读取,并通过SnackFS简化数据存储访问。整个项目以Scala语言编写,展示了如何建立一个可用于股票筛选和市场分析的可扩展BigData平台。
本文还有配套的精品资源,点击获取
版权归原作者 史愿 所有, 如有侵权,请联系我们删除。