
1、五种连接策略
选择连接策略的核心原则是尽量避免shuffle和sort的操作,因为这些操作性能开销很大,比较吃资源且耗时,所以首选的连接策略是不需要shuffle和sort的hash连接策略。
◦Broadcast Hash Join(BHJ):广播散列连接
◦Shuffle Hash Join(SHJ):洗牌散列连接
◦Shuffle Sort Merge Join(SMJ):洗牌排列合并联系
◦Cartesian Product Join(CPJ):笛卡尔积连接
◦Broadcast Nested Loop Join(BNLJ):广播嵌套循环连接
2、连接影响因素
2.1、连接类型是否为equi-join(等值连接)
等值连接是指一个连接条件中只包含“=”比较的连接,而非等值连接包含除“=”以外的任何比较,如“<、>、>=、<=”,由于非等值连接是对不确定值的范围比较,需要嵌套循环,所以只有CPJ和BMLJ两种连接策略支持非等值连接,对于等值连接,所有连接策略都支持。
2.2、连接策略提示(Join strategy hint)
Spark SQL为开发人员提供了通过连接提示对连接策略选择进行一些控制,共支持4种连接提示(Spark3.0.0版本)。
▪BROADCAST
▪SHUFFLE_MERGE
▪SHUFFLE_HASH
▪SHUFFLE_REPLICATE_NL
使用示例:SELECT
/**+ BROADCAST(table_B) / *
FROM
table_A
INNER JOIN
table_B
ON
table_A.id = table_B.id
2.3、连接数据集的大小(Size of Join relations)
选择连接策略最重要的因素是连接数据集的大小,是否可以选择不需要shuffle和sort的基于hash的连接策略,就取决于连接中涉及的数据集的大小。
3、连接策略优先级
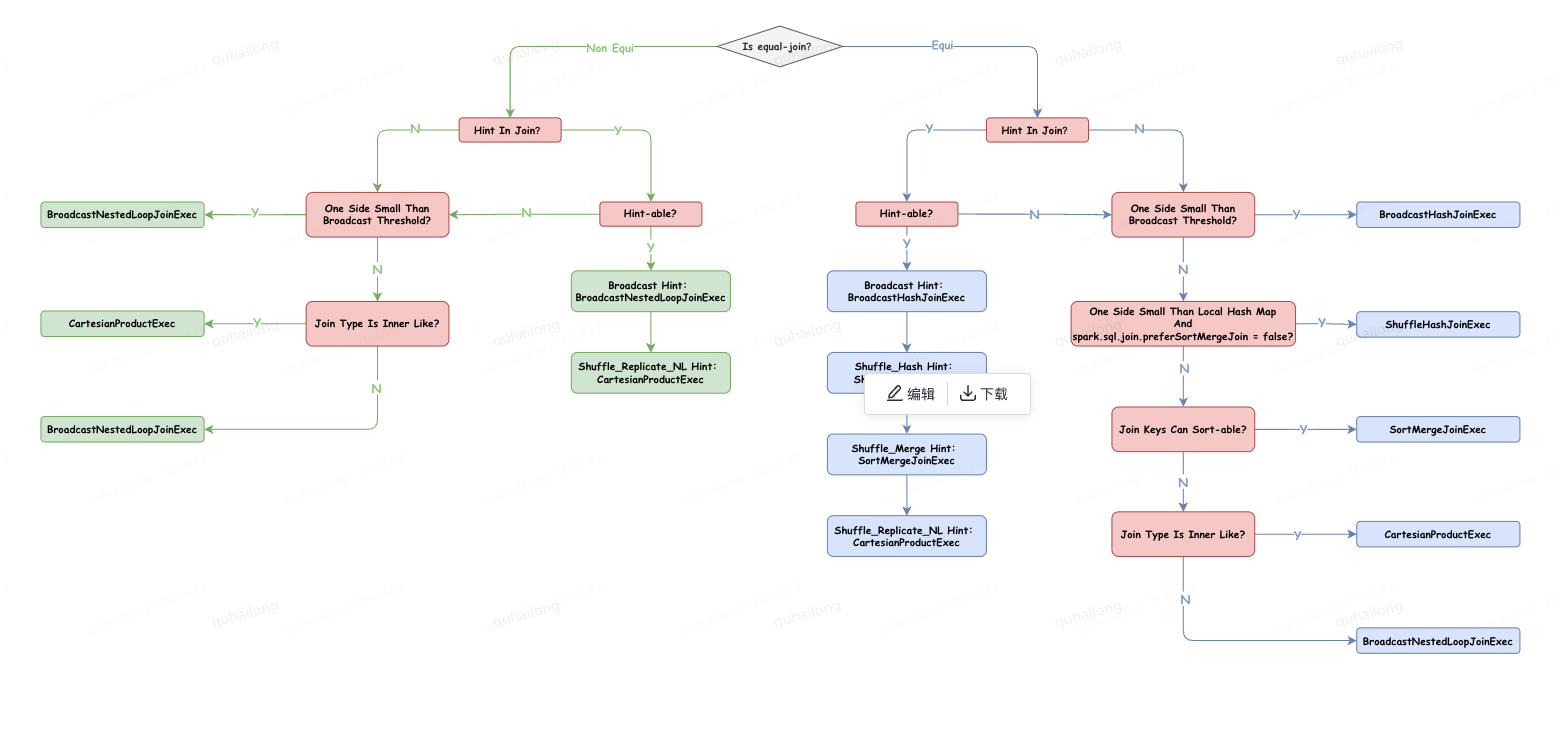
4、五种连接策略运行原理
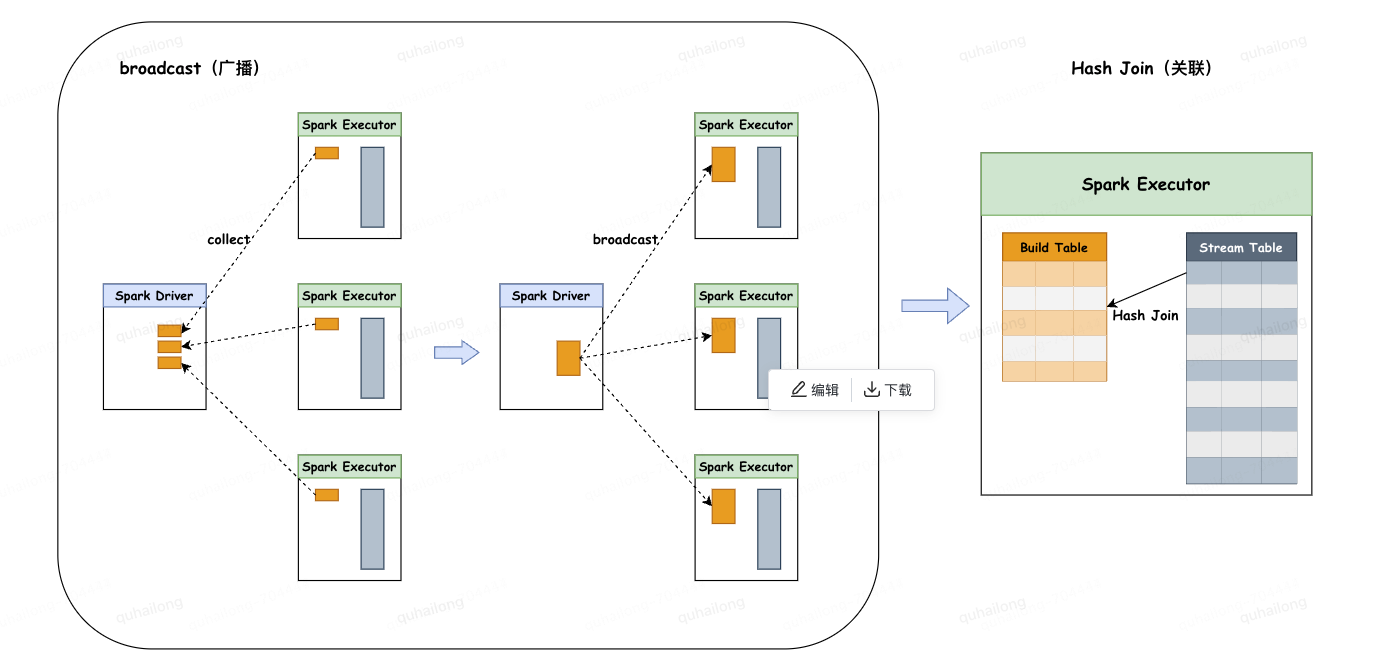
4.1、Broadcast Hash Join(BHJ):广播散列连接
◦主要分为两个阶段:
1.广播阶段:通过collect算子将小表数据拉到Driver端,再把整体的小表广播致每个Executor端一份。
2.关联阶段:在每个Executor上进行hash join,为较小的表通过join key创建hashedRelation作为build table,循环大表stream table通过join key关联build table。
◦限制条件:
1.被广播的小表大小必须小于参数:spark.sql.autoBroadcaseJoinThreshold,默认为10M。
2.基表不能被广播,比如left join时,只能广播右表。
3.数据集的总行数小于MAX_BROADCAST_TABLE_ROWS阈值,阈值被设置为3.41亿行。
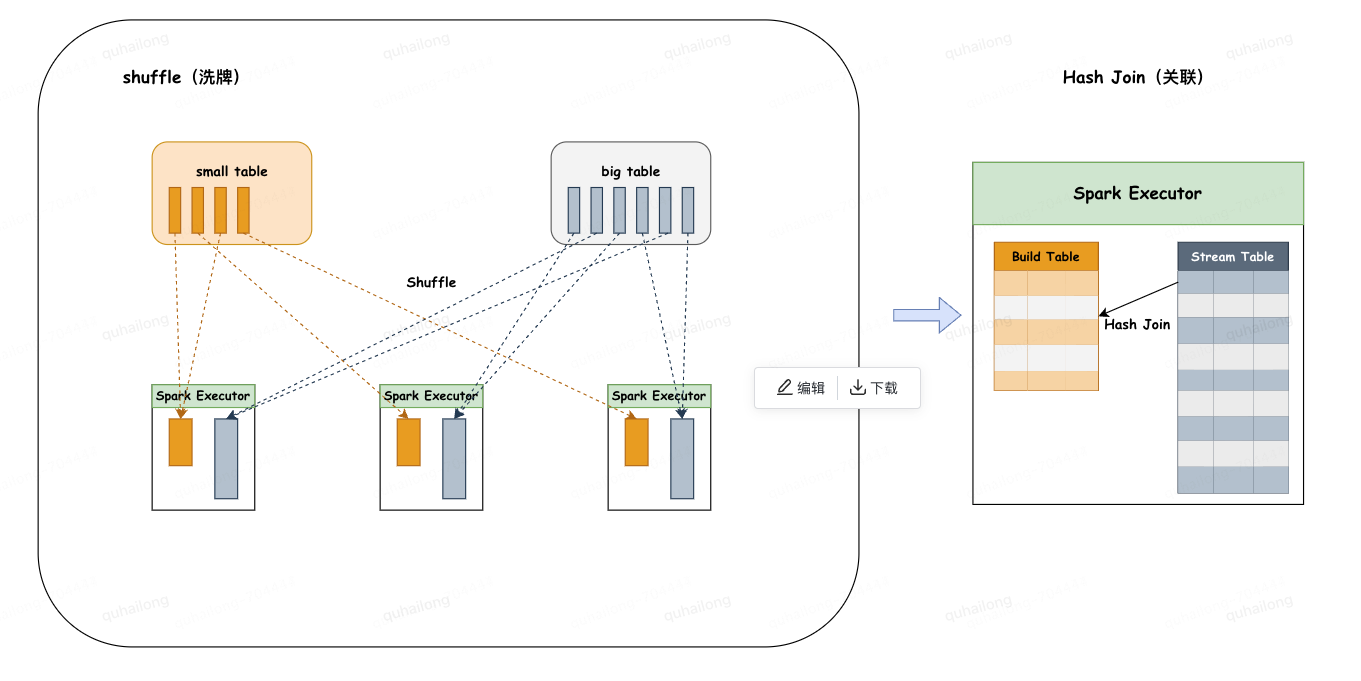
4.2、****Shuffle Hash Join(SHJ):洗牌散列连接
◦主要分为两个阶段:
1.洗牌阶段:通过对两张表分别按照join key分区洗牌,为了让相同join key的数据分配到同一Executor中。
2.关联阶段:在每个Executor上进行hash join,为较小的表通过join key创建hashedRelation作为build table,循环大表stream table通过join key关联build table。
◦限制条件:
1.小表大小必须小于参数:spark.sql.autoBroadcaseJoinThreshold(默认为10M) * shuffle分区数。
2.基表不能被广播,比如left join时,只能广播右表。
3.较小表至少比较大表小3倍以上,否则性能收益未必大于Shuffle Sort Merge Join。
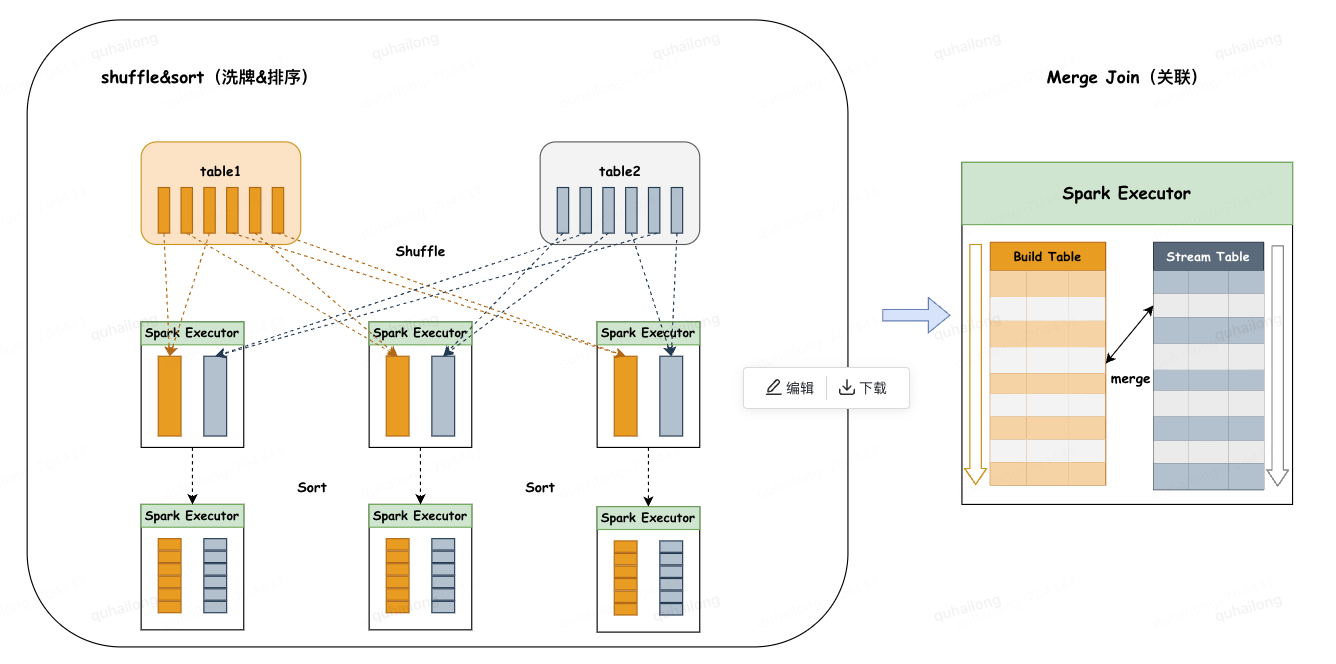
4.3、Shuffle Sort Merge Join(SMJ):洗牌排列合并联系
◦主要分为两个阶段:
1.洗牌阶段:将两张大表分别按照join key分区洗牌,为了让相同join key的数据分配到同一分区中。
2.排序阶段:对单个分区的两张表分别进行升序排序。
3.关联阶段:两张有序表都可以作为stream table或build table,顺序迭代stream table行,在build table顺序逐行搜索,相同键关联,由于stream table或build table都是按连接键排序的,当连接过程转移到下一个stream table行时,在build table中不必从第一个行搜索,只需从与最后一个stream table匹配行继续搜索即可。
◦限制条件:
1.连接键必须是可排序的。
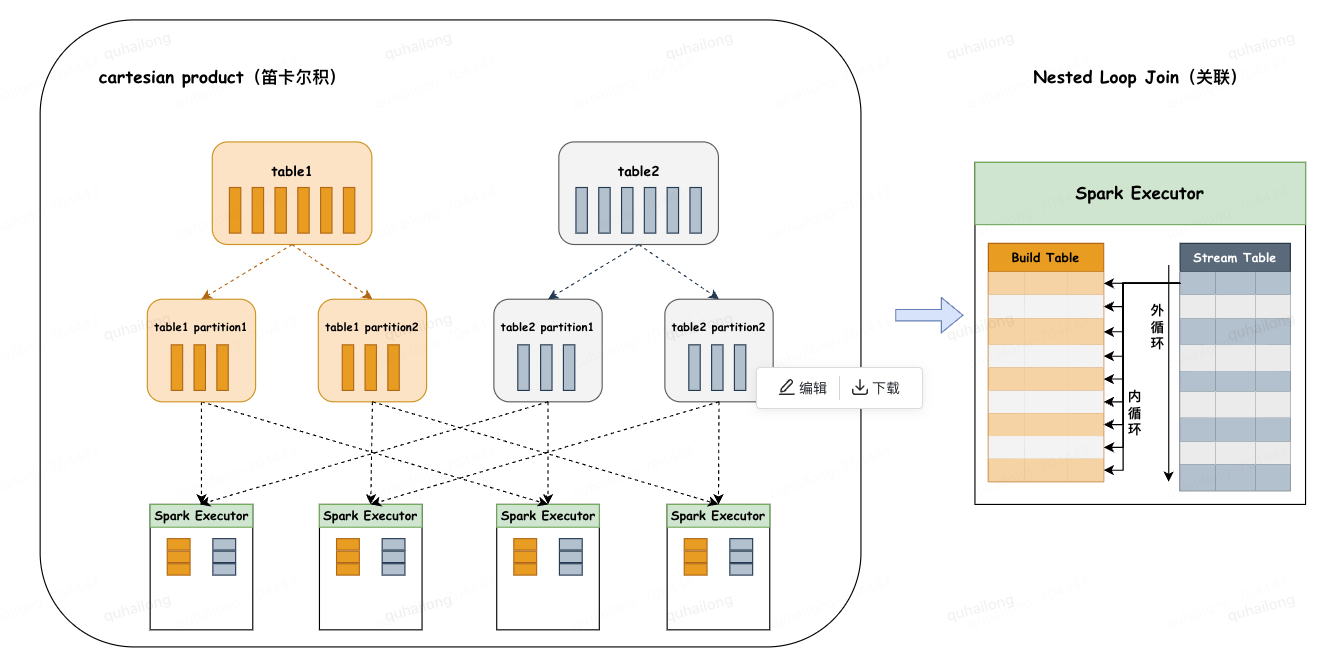
4.4、Cartesian Product Join(CPJ):笛卡尔积连接
◦主要分为两个阶段:
1.分区阶段:将两张大表分别进行分片,再将两个父分片a,b进行笛卡尔积组装子分片,子分片数量:a*b。
2.关联阶段:会对stream table和build table两个表使用内、外两个嵌套的for循环依次扫描,通过关联键进行关联。
◦限制条件:
1.left join广播右表,right join广播左表,inner join广播两张表。
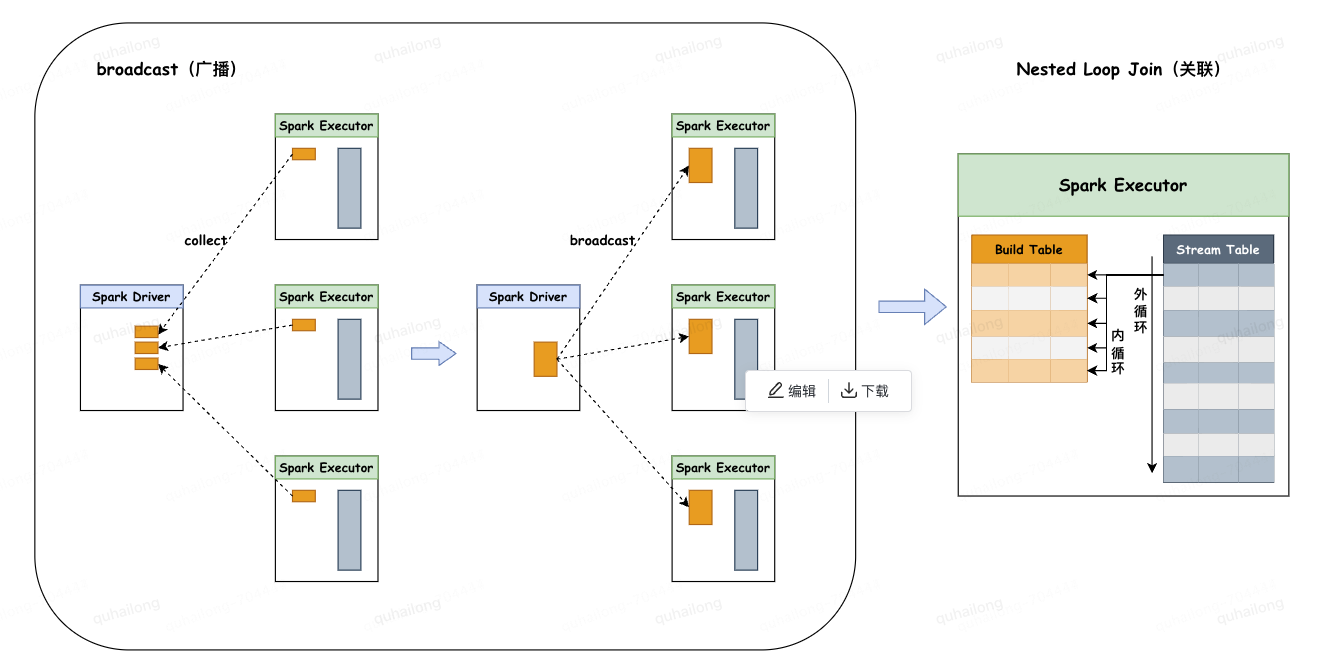
4.5、Broadcast Nested Loop Join(BNLJ):广播嵌套循环连接
◦主要分为两个阶段:
1.广播阶段:通过collect算子将小表数据拉到Driver端,再把整体的小表广播致每个Executor端一份。
2.关联阶段:会对stream table和build table两个表使用内、外两个嵌套的for循环依次扫描,通过关联键进行关联。
◦限制条件:
1.仅支持内连接。
2.开启参数:spark.sql.crossJoin.enabled=true。
作者:曲海龙
来源:京东云开发者社区 转载请注明来源
版权归原作者 京东云开发者 所有, 如有侵权,请联系我们删除。