
selenium 操作已经打开的浏览器
有时通过selenium打开网站时,发现有些网站需要扫码登录,就很头疼,导致爬虫进展不下去。
例如打开该网站:https://xh.newrank.cn/content/notes/notesSearch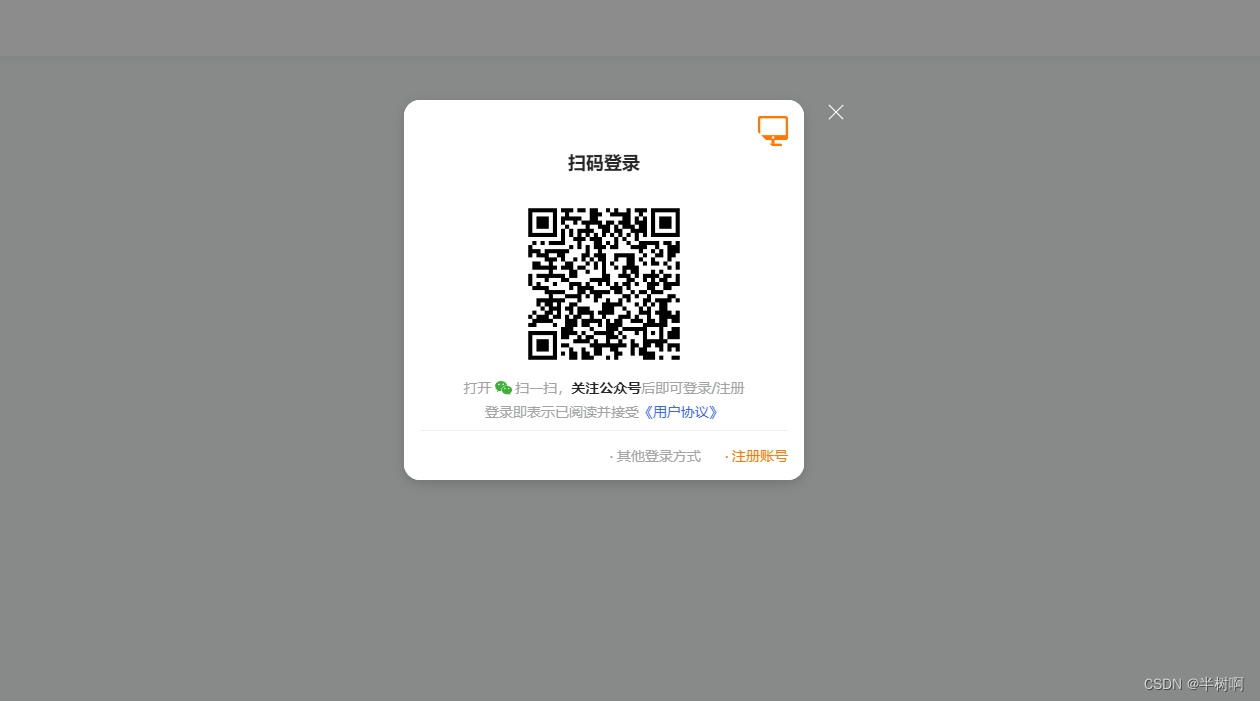
如果继续想使用selenium进行数据抓取,下一步应该怎么办呢?
步骤一:创建文件夹
在电脑的D盘或者F盘或者合适的盘创建一个文件夹。
例如:在D盘创建了一个名为“AutomationProfile”的文件夹,路径为 D:\AutomationProfile
步骤二:找到谷歌浏览器路径
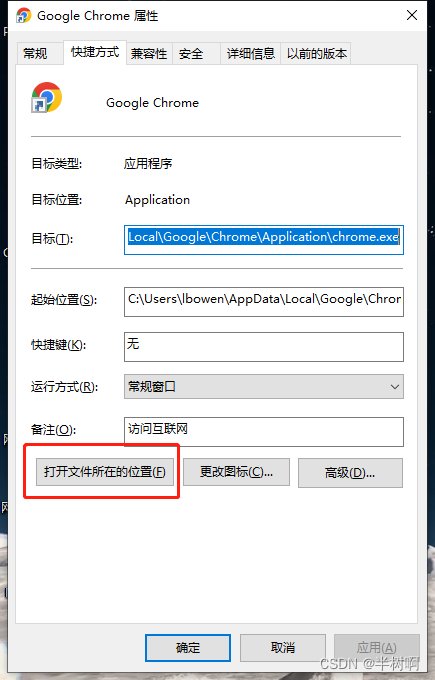
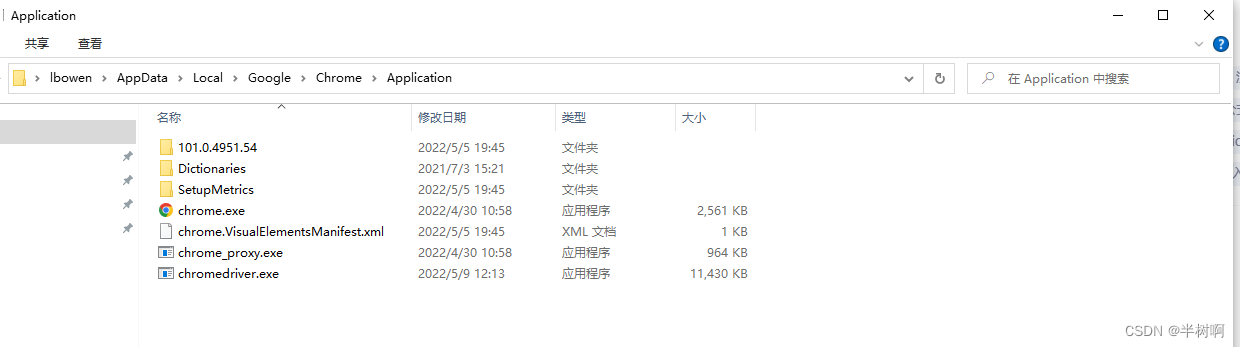
步骤三:在谷歌浏览器路径下打开命令提示符
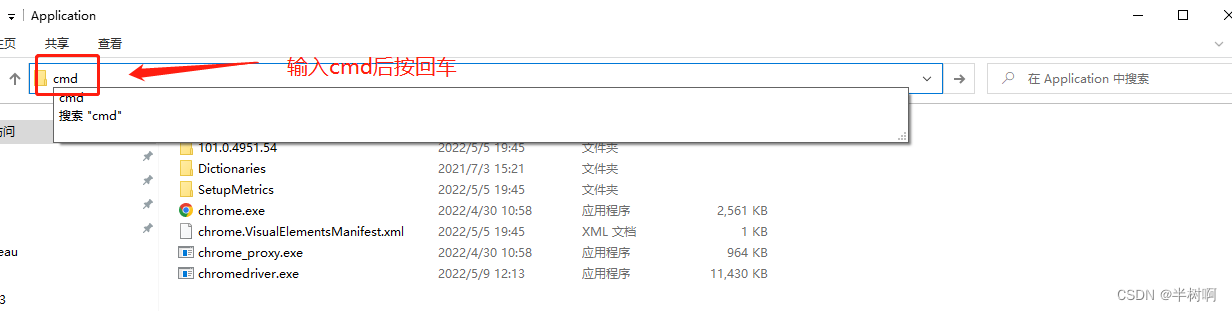
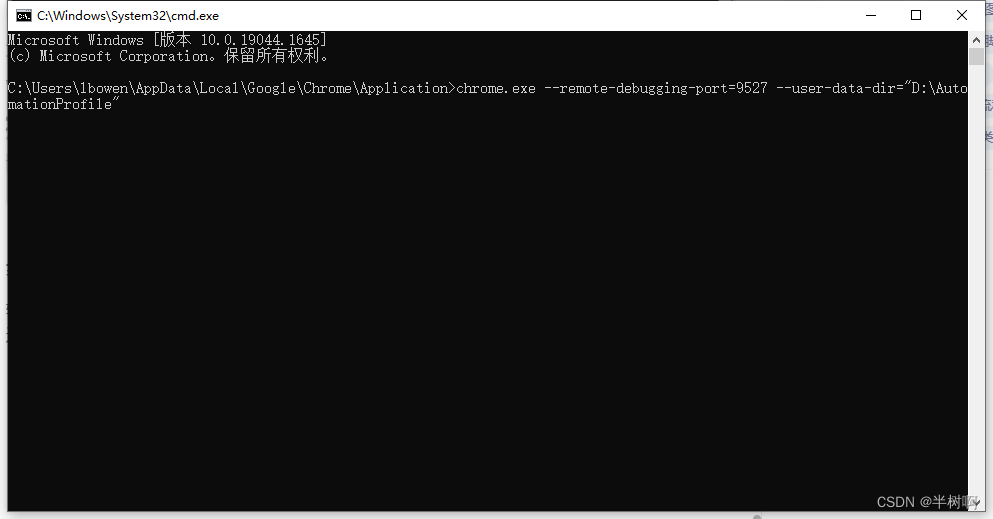
步骤四:输入指令
输入:chrome.exe --remote-debugging-port=9527 --user-data-dir=“D:\AutomationProfile” ,并回车。
这句代码的意思是启动 chrome浏览器 的调试模式。
- user-data-dir=“D:\AutomationProfile” 其中的 D:\AutomationProfile 就是刚才新创建文件夹的路径。
- 其中 9527 为端口号,可自行指定。
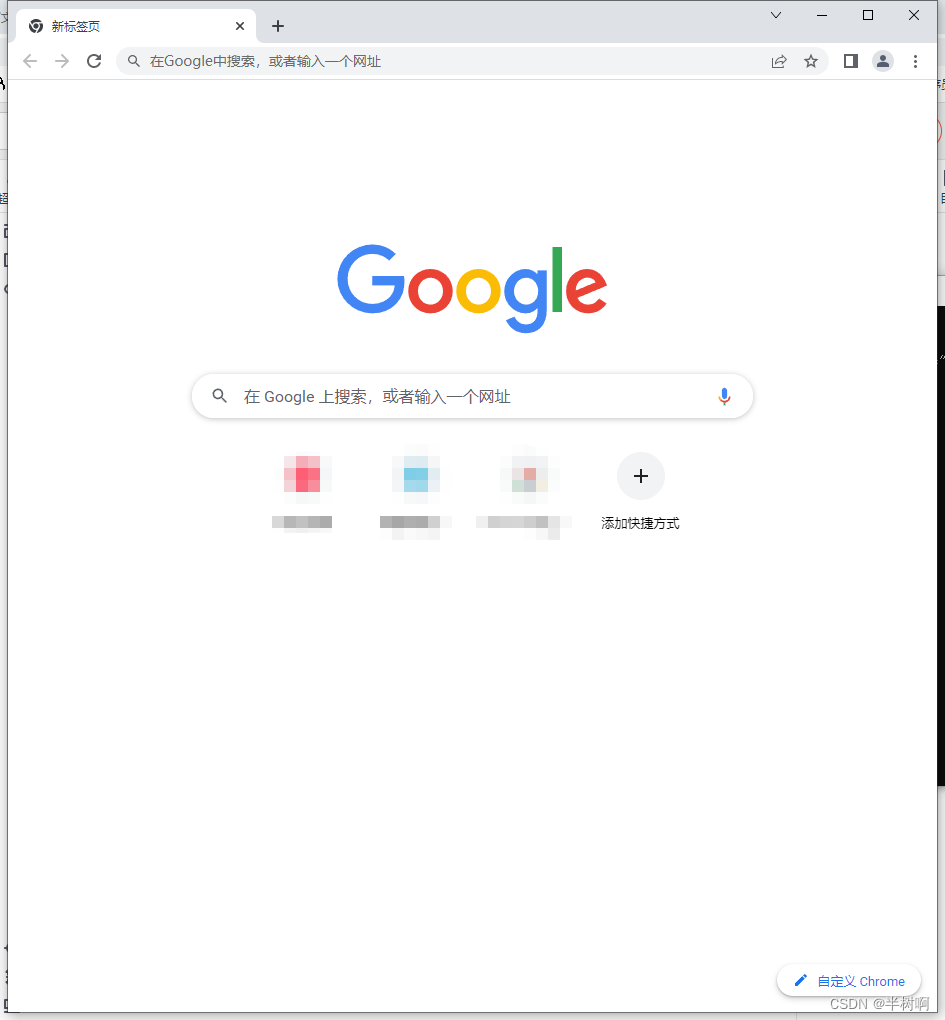 如果成功,就会看到已经打开新的浏览器窗口。
如果成功,就会看到已经打开新的浏览器窗口。
步骤五:运行代码
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from time import sleep
from selenium.webdriver.common.by import By
options = Options()
options.add_experimental_option("debuggerAddress","127.0.0.1:9527")
bro = webdriver.Chrome(options=options)
url ='https://xh.newrank.cn/content/notes/notesSearch'
bro.get(url)
执行上面代码,发现就会在刚才打开的浏览器窗口下打开该网址,发现还是出现扫码,我们只需扫一次码,再执行代码的时候,就不需要扫码了,就可以进行数据抓取了。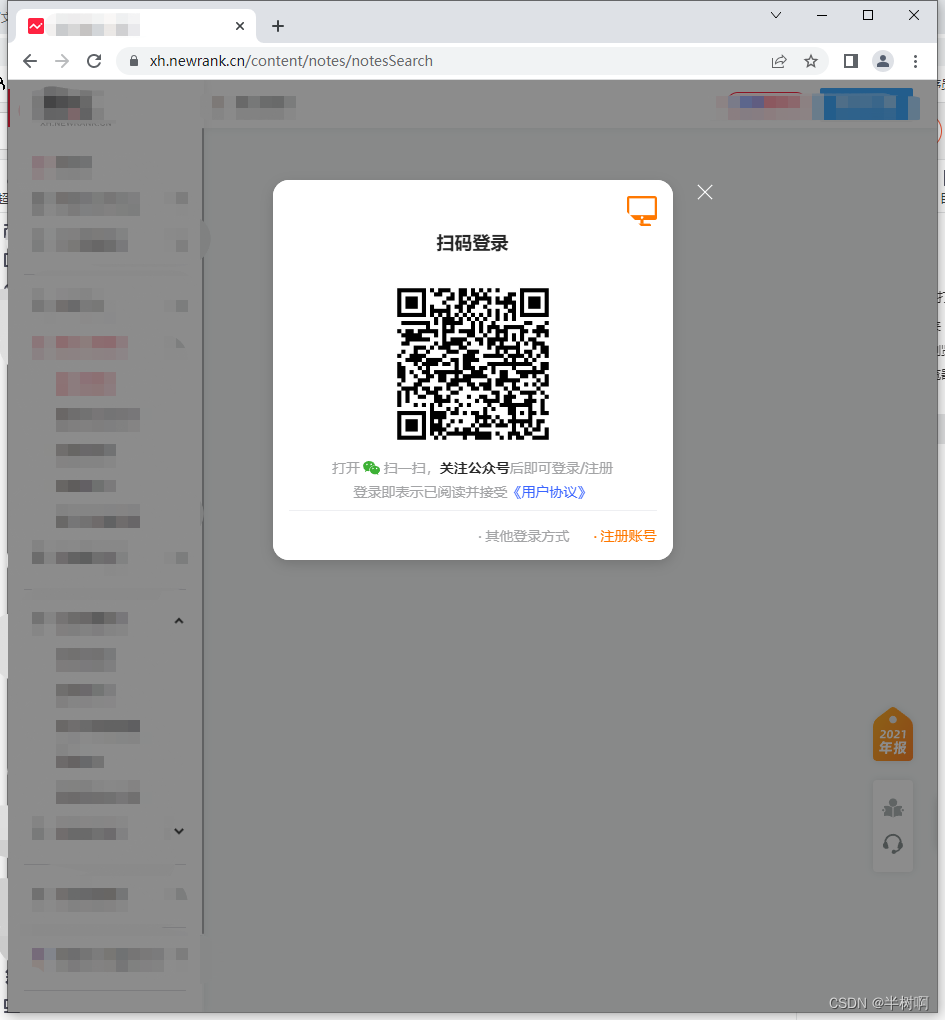
总结:应用场景(理论上)
- 登录账号并且需要输入手机验证码的网站;
- 登录账号并且需要人机验证的网站(如图片点选、文字点选等人机验证;
- 登录账号需要滑动验证的网站;
本文部分转载于:https://blog.csdn.net/weixin_45081575/article/details/112621581
本文转载自: https://blog.csdn.net/weixin_44791551/article/details/124719506
版权归原作者 半树啊 所有, 如有侵权,请联系我们删除。
版权归原作者 半树啊 所有, 如有侵权,请联系我们删除。