
内容介绍
单表索引失效案例
0、思考题:如果把100万数据插入MYSQL ,如何提高插入效率
(1)关闭自动提交,只手动提交一次
(2)删除除主键索引外其他索引
(3)拼写mysql可以执行的长sql,批量插入数据
(4)使用java多线程
(5)使用框架,设置属性,实现批量插入
1、计算、函数导致索引失效
CREATE INDEX idx_name ON emp (NAME);
EXPLAIN SELECT * FROM emp WHERE emp.name LIKE 'abc%';
EXPLAIN SELECT * FROM emp WHERE LEFT(emp.name,3) = 'abc'; ----索引失效
2 LIKE以%开头索引失效
EXPLAIN SELECT * FROM emp WHERE NAME LIKE '%ab%'; ----索引失效
3、不等于(!= 或者<>)索引失效
EXPLAIN SELECT * FROM emp WHERE emp.name = 'abc' ;
EXPLAIN SELECT * FROM emp WHERE emp.name <> 'abc' ; ----索引失效
4、IS NOT NULL 和 IS NULL
EXPLAIN SELECT * FROM emp WHERE emp.name IS NULL;
EXPLAIN SELECT * FROM emp WHERE emp.name IS NOT NULL; ----索引失效
5、类型转换导致索引失效
EXPLAIN SELECT * FROM emp WHERE NAME='123';
EXPLAIN SELECT * FROM emp WHERE NAME= 123; ----索引失效
6、全值匹配我最爱
EXPLAIN SELECT * FROM emp WHERE emp.age = 30 AND deptid = 4 AND emp.name = 'abcd';
CREATE INDEX idx_age ON emp(age);
CREATE INDEX idx_age_deptid ON emp(age,deptid);
CREATE INDEX idx_age_deptid_name ON emp(age,deptid,name);
7、最佳左前缀法则
EXPLAIN SELECT * FROM emp WHERE emp.age=30 AND emp.name = 'abcd' ;
CREATE INDEX idx_age_name ON emp (age,NAME);
EXPLAIN SELECT * FROM emp WHERE emp.deptid=1 AND emp.name = 'abcd';
EXPLAIN SELECT * FROM emp WHERE emp.age = 30 AND emp.deptid=1 AND emp.name = 'abcd';
CREATE INDEX idx_age_deptid_name ON emp(age,deptid,name);
EXPLAIN SELECT * FROM emp WHERE emp.deptid=1 AND emp.name = 'abcd' AND emp.age = 30;
8、索引中范围条件右边的列失效
CREATE INDEX idx_age_deptid_name ON emp(age,deptid,name);
EXPLAIN SELECT * FROM emp WHERE emp.age=30 AND emp.name = 'abc' AND emp.deptId>1000 ;
CREATE INDEX idx_age_name_deptid ON emp(age,name,deptid);
关联查询优化
1、数据准备
-- 分类
CREATE TABLE IF NOT EXISTS `class` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`id`)
);
-- 图书
CREATE TABLE IF NOT EXISTS `book` (
`bookid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`bookid`)
);
-- 插入16条记录
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
-- 插入20条记录
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
2、左外连接实例
(1)明确角色
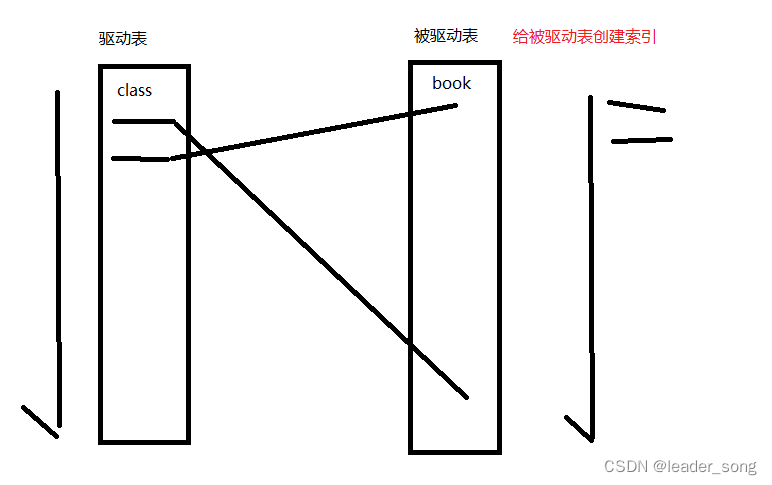
(2)优化
EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card;
CREATE INDEX idx_class_card ON class(card);
CREATE INDEX idx_book_card ON book(card);
*使用LEFT JOIN,前面的是驱动表、后面是被驱动表
针对两张表的连接条件涉及的列,索引要创建在被驱动表上,驱动表尽量是小表
- 如果驱动表上没有where过滤条件- 当驱动表的连接条件没有索引时,驱动表是全表扫描- 当针对驱动表的连接条件建立索引时,驱动表依然要进行全索引扫描- 因此,此时建立在驱动表上的连接条件上的索引是没有太大意义的
- 如果驱动表上有where过滤条件,那么针对过滤条件创建的索引是有必要的
3、内连接实例
EXPLAIN SELECT * FROM class INNER JOIN book ON class.card = book.card;
CREATE INDEX idx_class_card ON class(card);
CREATE INDEX idx_book_card ON book(card);
*使用INNER JOIN,驱动表、被驱动表不固定,mysql选择
MySQL优化器也会自动选择驱动表,自动选择驱动表的原则是:索引创建在被驱动表上,驱动表是小表。
4、分析4种查询sql(mysql5)
#1 NO3
EXPLAIN SELECT ab.name,c.`name` ceoname FROM
(SELECT a.`name`,b.`CEO` FROM emp a
LEFT JOIN dept b ON a.`deptId`=b.`id`)ab
LEFT JOIN emp c ON ab.ceo=c.`id`;
#2 NO4
EXPLAIN SELECT c.name,ab.name ceoname FROM emp c LEFT JOIN
(SELECT a.`name`,b.`id` FROM emp a
INNER JOIN dept b ON b.`CEO` = a.`id`)ab
ON c.`deptId`= ab.id;
#3 NO1
EXPLAIN SELECT a.`name`,c.`name` ceoname FROM emp a
LEFT JOIN dept b ON a.`deptId`= b.id
LEFT JOIN emp c ON b.`CEO`= c.`id`;
#4 NO2
EXPLAIN SELECT a.`name`,(SELECT c.name FROM emp c WHERE c.id =b.`CEO`)ceoname
FROM emp a
LEFT JOIN dept b ON a.`deptId`=b.`id`;
5、总结
- 保证被驱动表的JOIN字段已经创建了索引
- 需要JOIN 的字段,数据类型保持绝对一致。
- LEFT JOIN 时,选择小表作为驱动表,大表作为被驱动表。减少外层循环的次数。
- INNER JOIN 时,MySQL会自动将小结果集的表选为驱动表。选择相信MySQL优化策略。
- 能够直接多表关联的尽量直接关联,不用子查询。(减少查询的趟数)
- 衍生表建不了索引(MySQL5.5)
其他优化
1、子查询优化
(1)获取非掌门人成员
#获取非掌门人成员
CALL proc_drop_index("atguigudb","emp");
CALL proc_drop_index("atguigudb","dept");
SELECT * FROM t_emp a WHERE a.id NOT IN
(SELECT b.ceo FROM t_dept b WHERE b.ceo IS NOT NULL);
EXPLAIN SELECT * FROM emp a WHERE a.id NOT IN
(SELECT b.ceo FROM dept b WHERE b.ceo IS NOT NULL);
#子查询优化NOT IN
EXPLAIN SELECT * FROM emp a LEFT JOIN dept b ON a.id = b.ceo
WHERE b.id IS NULL;
(2)结论
尽量不要使用NOT IN 或者 NOT EXISTS,用LEFT JOIN xxx ON xx = xx WHERE xx IS NULL替代
2、排序优化
(1)实例
CALL proc_drop_index("atguigudb","emp");
CALL proc_drop_index("atguigudb","dept");
CREATE INDEX idx_age_deptid_name ON emp (age,deptid,name);
#无过滤,不索引
EXPLAIN SELECT * FROM emp ORDER BY age,deptid;
EXPLAIN SELECT * FROM emp ORDER BY age,deptid LIMIT 10;
EXPLAIN SELECT * FROM emp WHERE age=45 ORDER BY deptid;
#顺序错,不索引
EXPLAIN SELECT * FROM emp WHERE age=45 ORDER BY deptid, name;
EXPLAIN SELECT * FROM emp WHERE age=45 ORDER BY deptid, empno;
CREATE INDEX idx_age_deptid_empno ON emp (age,deptid,empno);
EXPLAIN SELECT * FROM emp WHERE age=45 ORDER BY name, deptid;
EXPLAIN SELECT * FROM emp WHERE deptid=45 ORDER BY age;
#方向反,不索引
EXPLAIN SELECT * FROM emp WHERE age=45 ORDER BY deptid DESC, name DESC;
EXPLAIN SELECT * FROM emp WHERE age=45 ORDER BY deptid ASC, name DESC;
- 总结
无过滤,不索引
顺序错,不索引
方向反,不索引
3、mysql索引选择
EXPLAIN SELECT * FROM emp WHERE age =30 AND empno <101000 ORDER BY name;
CREATE INDEX idx_age_empno ON emp (age,empno);
CREATE INDEX idx_age_name ON emp (age,NAME);

*当【范围条件】和【group by 或者 order by】的字段出现二选一时,优先观察条件字段的过滤数量,如果过滤的数据足够多,而需要排序的数据并不多时,优先把索引放在范围字段上。反之,亦然。
也可以将选择权交给MySQL:索引同时存在,mysql自动选择最优的方案:(对于这个例子,mysql选择idx_age_empno),但是,随着数据量的变化,选择的索引也会随之变化的。
4、双路排序和单路排序
(1)双路排序(慢)
取一批数据,要对磁盘进行两次扫描。
众所周知,IO是很耗时的,所以在mysql4.1之后,出现了第二种改进的算法,就是单路排序。
(2)单路排序(快)
它的效率更快一些,因为
只读取一次磁盘
,避免了第二次读取数据。
并且把随机
IO
变成了顺序
IO
。但是它会
使用更多的空间
,因为它把每一行都保存在内存中了。
5、分组优化
group by ``````使用索引的原则几乎跟``````order by``````一致。但是group by 即使没有过滤条件用到索引,也可以直接使用索引(Order By 必须有过滤条件才能使用上索引)- 包含了order by、group by、distinct这些查询的语句,where条件过滤出来的结果集请保持在1000行以内,否则SQL会很慢。
6、覆盖索引优化
总结
- 禁止使用select *,禁止查询与业务无关字段
- 尽量利用覆盖索引
慢查询日志
1、如何对系统查询慢做索引优化
(1)找运维人员开启生产数据库慢查询日志
(2)等待1-2周时间,积累慢查询日志
(3)借助工具获取慢查询次数最多和查询时间最长的几个sql进行优化
(4)在生产数据库,使用EXPLAIN进行sql分析,找到瓶颈,创建索引优化
(5)关闭慢查询日志。
2、是什么
一种日志记录,查看哪些SQL超出了我们的最大忍耐时间值。
3、使用
(1)开启slow_query_log
SET GLOBAL slow_query_log=1;
SHOW VARIABLES LIKE '%slow_query_log%';
(2)修改long_query_time阈值
SHOW VARIABLES LIKE '%long_query_time%'; -- 查看值:默认10秒
SET GLOBAL long_query_time=0.1; -- 设置一个比较短的时间,便于测试
(3)运行sql
(4)查看慢查询日志

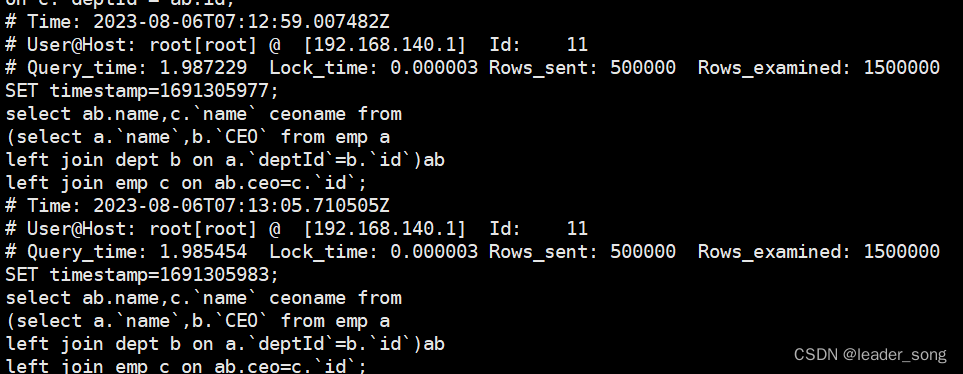
(5)使用工具分析慢查询日志
-- 查看mysqldumpslow的帮助信息
mysqldumpslow --help
-- 工作常用参考
-- 1.得到返回记录集最多的10个SQL
mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log
-- 2.得到访问次数最多的10个SQL
mysqldumpslow -s c -t 10 /var/lib/mysql/atguigu-slow.log
-- 3.得到按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/atguigu-slow.log
-- 4.另外建议在使用这些命令时结合 | 和more 使用 ,否则语句过多有可能出现爆屏情况
mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log | more
1、单表索引失效案例
2、关联查询优化
3、其他优化
4、慢查询日志
5、视图
6、高性能架构模式
版权归原作者 leader_song 所有, 如有侵权,请联系我们删除。