

spark集群部署
1 修改spark-env.sh配置文件
$ssh master
$cd opt/module/spark/conf
$vi spark-env.sh

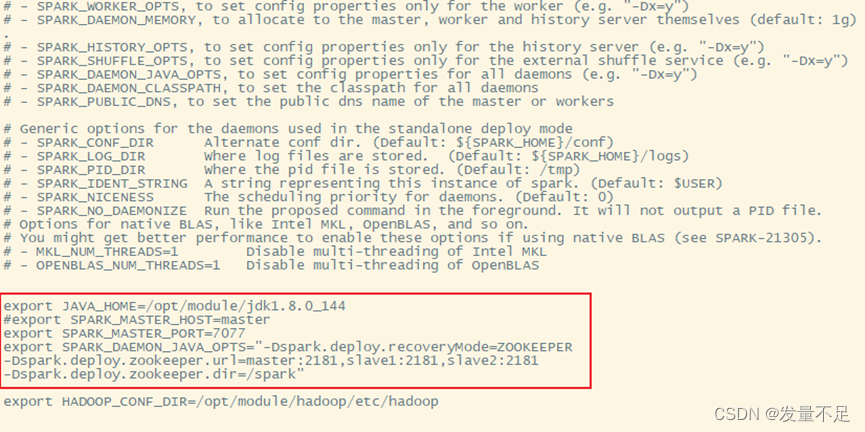
步骤1 将指定master节点配置参数注释‘#’,添加SPARK_DAEMON_JAVA_OPTS配置参数
export JAVA_HOME=/opt/module/jdk1.8.0_144
**#**export SPARK_MASTER_HOST=master
export SPARK_MASTER_PORT=7077
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=master:2181,slave1:2181,slave2:2181
-Dspark.deploy.zookeeper.dir=/spark"
(1)spark.deploy.recoveryMode=ZOOKEEPER:设置zookeeper去启用备用master模式
(2)spark.deploy.zookeeper.url=master:指定zookeeper的server地址
(3)spark.deploy.zookeeper.dir:保存集群元数据信息的文件和目录
将spark-env.sh分发至slave1和slave2节点上,保证配置文件统一
scp spark-env.sh slave1:/opt/module/spark/conf/
scp spark-env.sh slave2:/opt/module/spark/conf/

2 启动spark HA集群
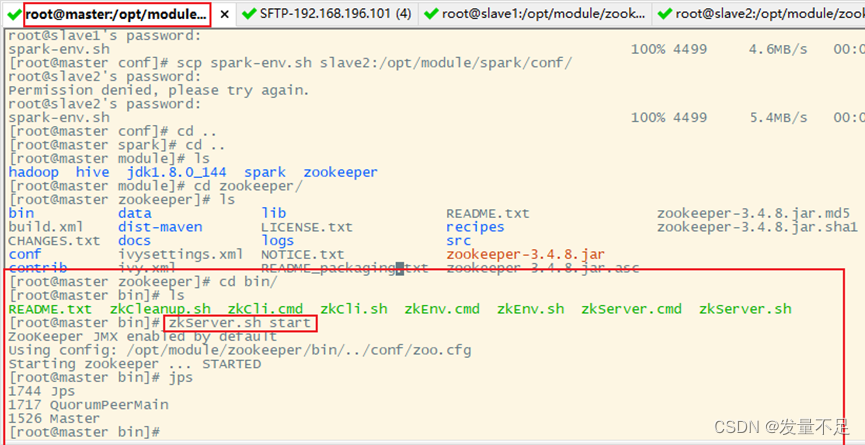
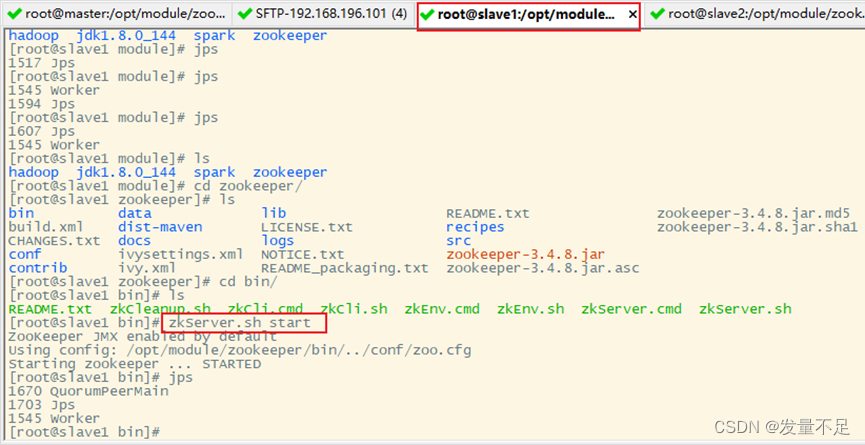
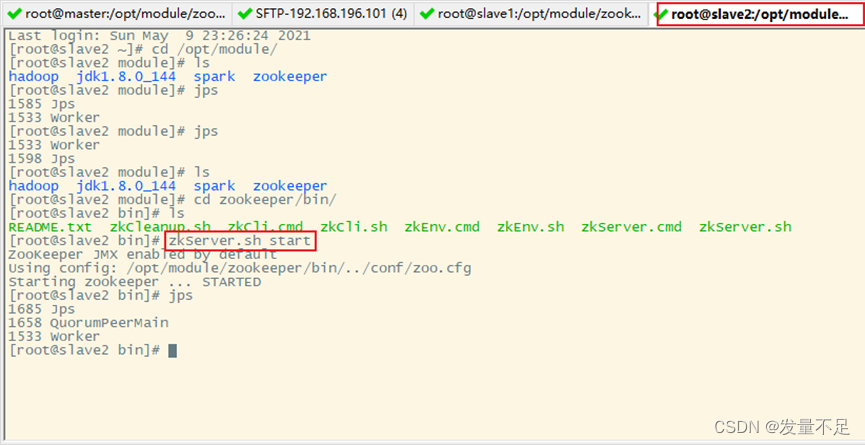
步骤1 启动zookeeper服务,3台节点都要
$cd /opt/module/zookeeper/bin
$ zkServer.sh start
问题1 : 启动spark集群出现以下问题


解决:配置问题,自己把spark-env.sh配置内容里的横杆空格了

问题2 在slave1节点启动master服务报 stop it first(意思是要你先停止这个,才能开启master,也可以不去停止)

解决:在master节点上停止spark集群
$cd opt/software/spark
$sbin/stop-all.sh

解决以上的问题后,重新在master节点启动spark集群与在slave节点单独启动master服务
在master节点上单独启动spark服务
$/opt/module/spark/sbin/start-all.sh

在slave1节点上单独启动Master服务
$/opt/module/spark/sbin/start-master.sh

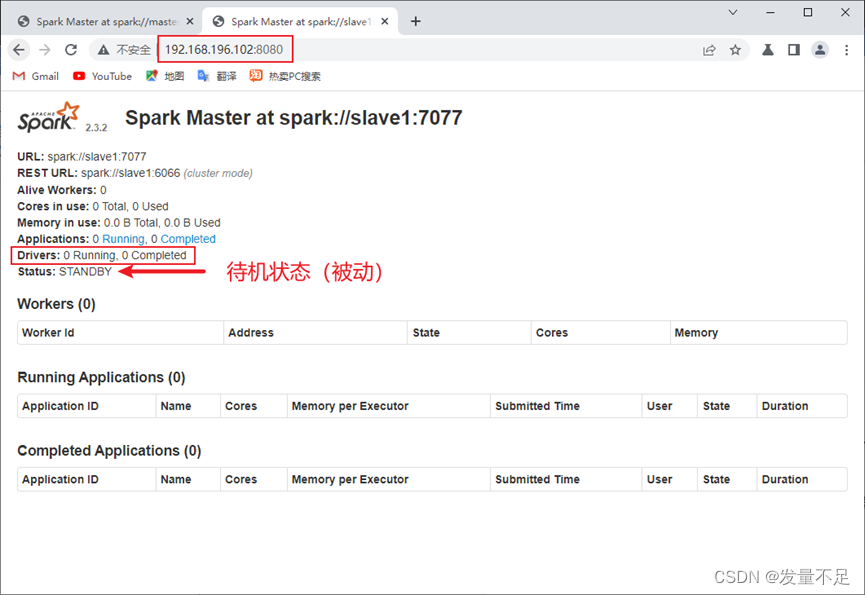
步骤2 访问http://192.168.196.102(slave1):8080,查看备用master节点状态
Status****:STANDBY # 说明spark HA配置完成
3.测试spark HA集群,为演示是否解决单点故障问题,关闭master节点的master进程
$ /opt/module/spark/sbin/stop-master.sh
版权归原作者 发量不足 所有, 如有侵权,请联系我们删除。