
✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。
我是Srlua,在这里我会分享我的知识和经验。🎥
希望在这里,我们能一起探索IT世界的奥妙,提升我们的技能。🔮
记得先点赞👍后阅读哦~ 👏👏
📘📚 所属专栏:Python
欢迎访问我的主页:Srlua 获取更多信息和资源。✨✨🌙🌙

Python爬虫项目实战案例-批量下载网易云榜单音乐
request模块安装下载
win平台安装
Win平台: “以管理员身份运行”cmd,执行pip install requests
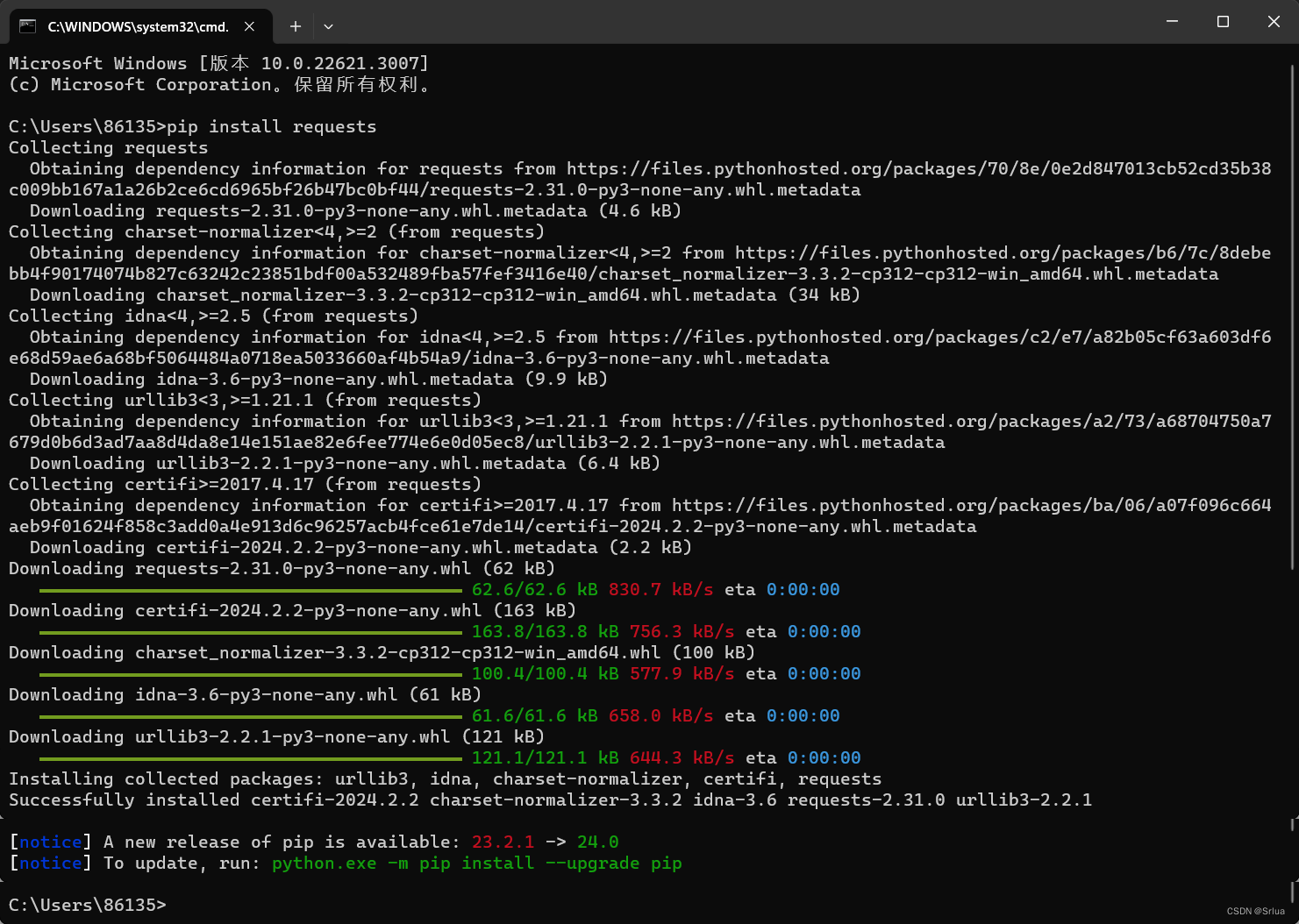
如何查看是否安装成功?
查看以上截图会显示Successfully installed...,即表示安装成功。
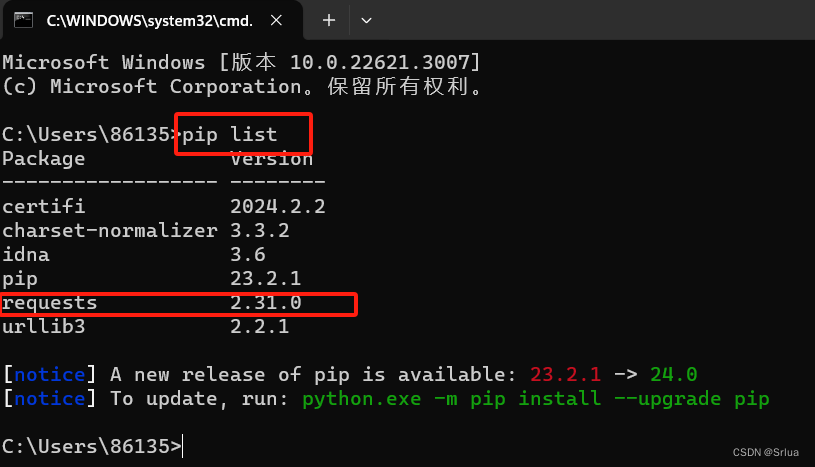
也可以在Win平台: “以管理员身份运行”cmd,执行pip list,查看到以下截图显示requests,即表示安装成功。
pycharm中安装
如果不行的话,也可以通过pycharm中的提示,安装install request packages

首先,我们进入网易云音乐官网 ,选择需要爬取的音乐榜单
这里博主选择热歌榜
想要爬取这些歌曲的话,我们需要获取它的音乐名字和它的音乐id
右击网页页面选择检查进入开发者模式,或者通过按键盘上的F12进入

然后我们control+r刷新页面
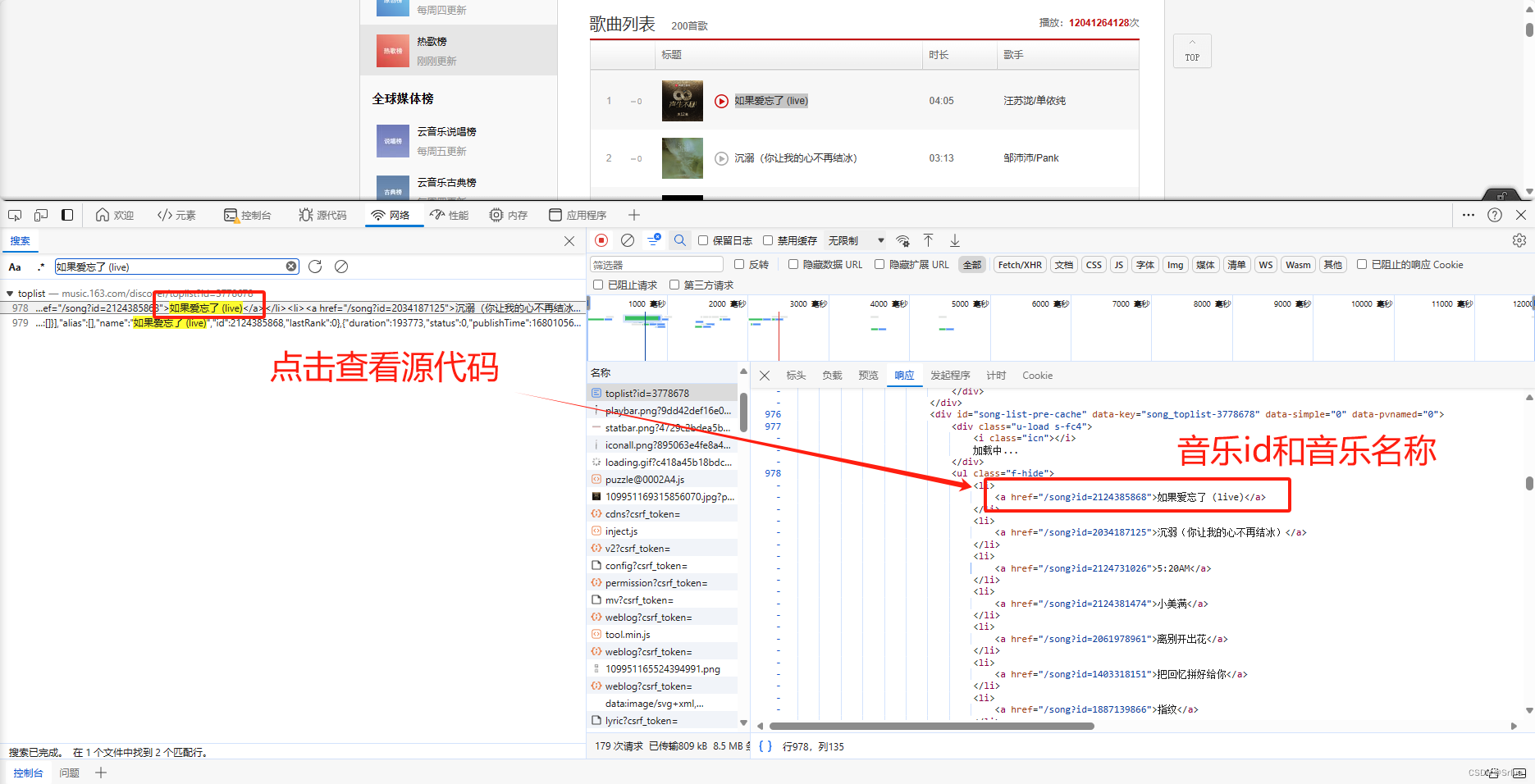
选择标头(headers)获取请求url的内容
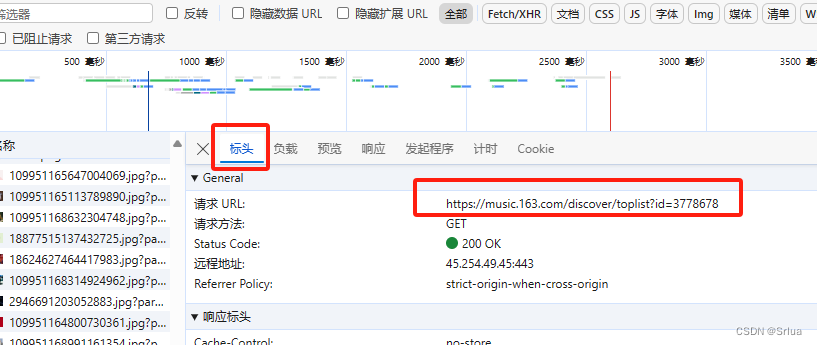

把request header里的User-Agent:复制到header中
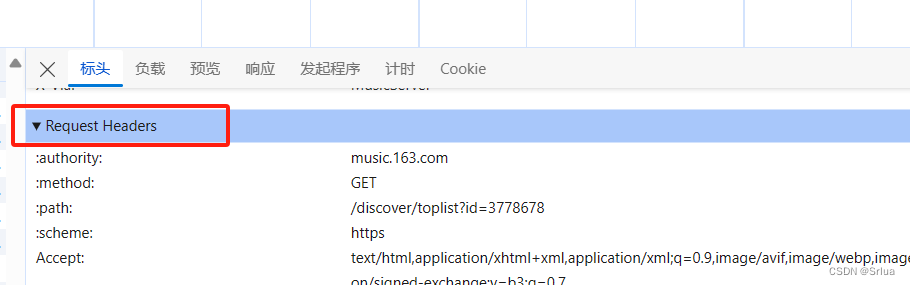
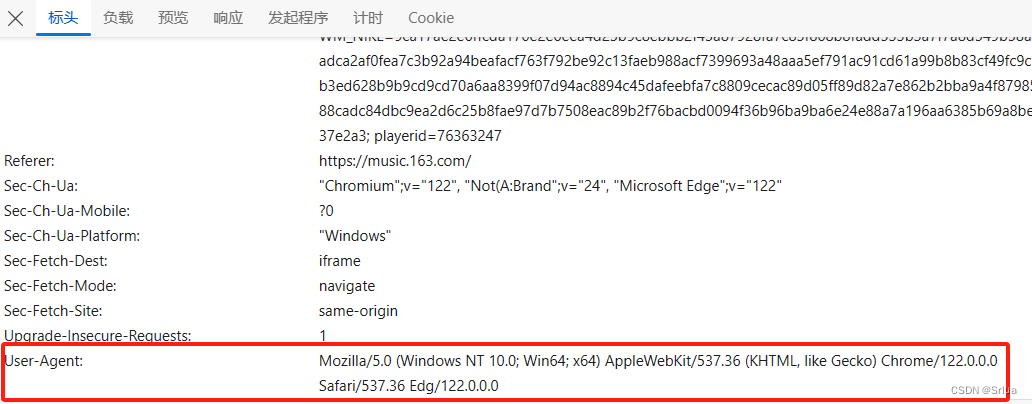
User-Agent:就是我们浏览器的基本信息

成功爬取网易云的源代码
使用Python中的
requests
库发送一个GET请求,并获取指定URL的网页源代码。
response = requests.get(url=url, headers=headers)
print(response.text)获取网页源代码

查看搜索控制台的内容

结合正则表达式查询
'<li><a href="/song\?id=(\d+)">(.*?)</a>'

这是一个正则表达式,用于匹配HTML中的特定模式。具体来说,它匹配的是一个
<li>
标签内的
<a>
标签,其中
<a>
标签的
href
属性以"/song?id="开头,后面跟着一串数字(由
\d+
表示),然后是">"和任意字符(由
(.*?)
表示),最后是闭合的
</a>
标签。
这个正则表达式可以用于从HTML中提取歌曲链接和歌曲名称。例如,如果有一个HTML字符串如下:
<ul>
<li><a href="/song?id=123">歌曲1</a></li>
<li><a href="/song?id=456">歌曲2</a></li>
</ul>
使用这个正则表达式进行匹配,可以得到两个结果:
/song?id=123和歌曲1/song?id=456和歌曲2
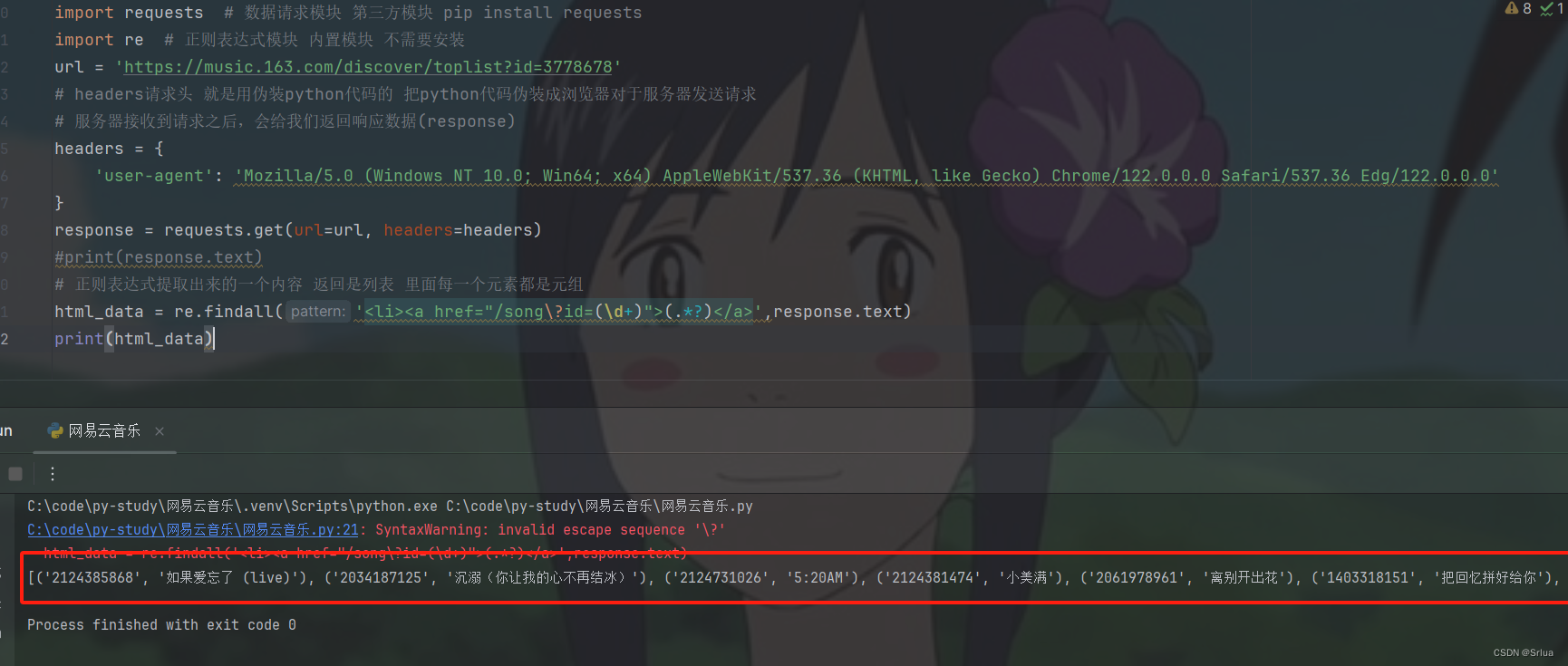
提取出榜单的音乐id和音乐名称
使用正则表达式从HTML文本中提取歌曲的ID和标题。
首先,使用**
re.findall()
函数**来查找所有匹配的字符串。
正则表达式
<li><a href="/song\?id=(\d+)">(.*?)</a>
用于匹配以
<li><a href="/song?id=
开头,后面跟着一串数字(由
\d+
表示),然后是
">
和任意字符(由
(.*?)
表示),最后是闭合的
</a></li>
标签。
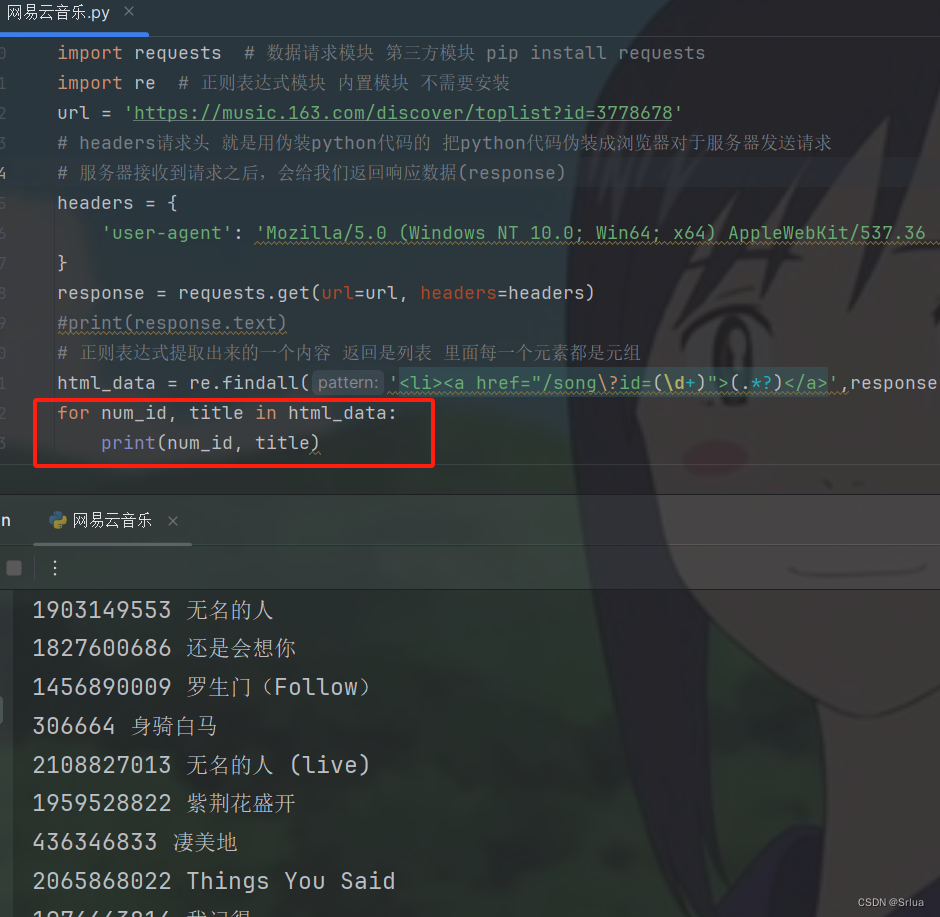
在每次循环中,
num_id
变量存储歌曲的ID,
title
变量存储歌曲的标题。然后,通过
print()
函数将它们打印出来。
实现批量下载
成功获取id和名称之后,我们就可以准备进行下载的部分了


尝试调用接口播放

成功播放
music_url = f'http://music.163.com/song/media/outer/url?id={num_id}.mp3'
# 对于音乐播放地址发送请求 获取二进制数据内容
music_content = requests.get(url=music_url, headers=headers).content
with open(filename +title +'.mp3', mode='wb') as f:
f.write(music_content)
这段代码用于下载歌曲的MP3文件。
首先,它使用
f-string
将歌曲ID插入到音乐URL中,生成完整的音乐播放地址。
然后,通过
requests.get()
函数发送请求获取二进制数据内容。
最后,使用
open()
函数以写入二进制模式打开一个文件,并将音乐内容写入该文件中。文件名由
filename
和
title
拼接而成,并以
.mp3
作为扩展名。
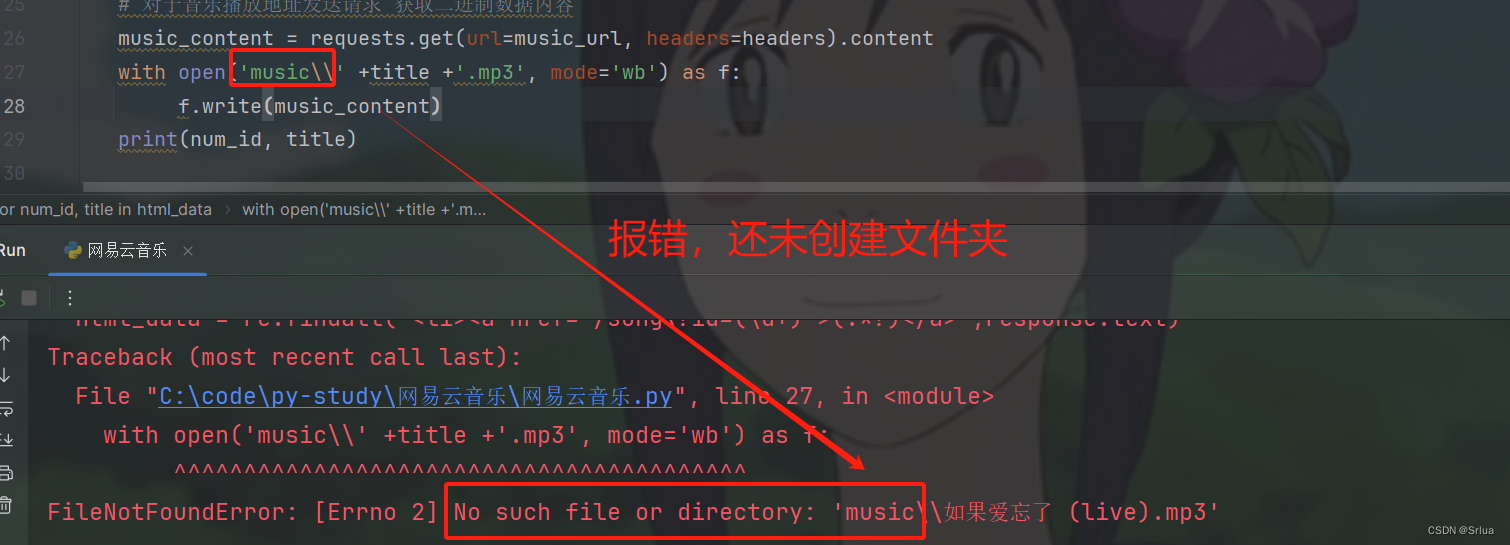
文件创建
手动创建 / os模块自动创建
博主这里选择用os模块创建
运行程序
爬取ing

自动下载至路径文件夹
如何爬取其他榜单?
如果想要爬取其他的榜单的歌曲内容,只要更改请求url中的id
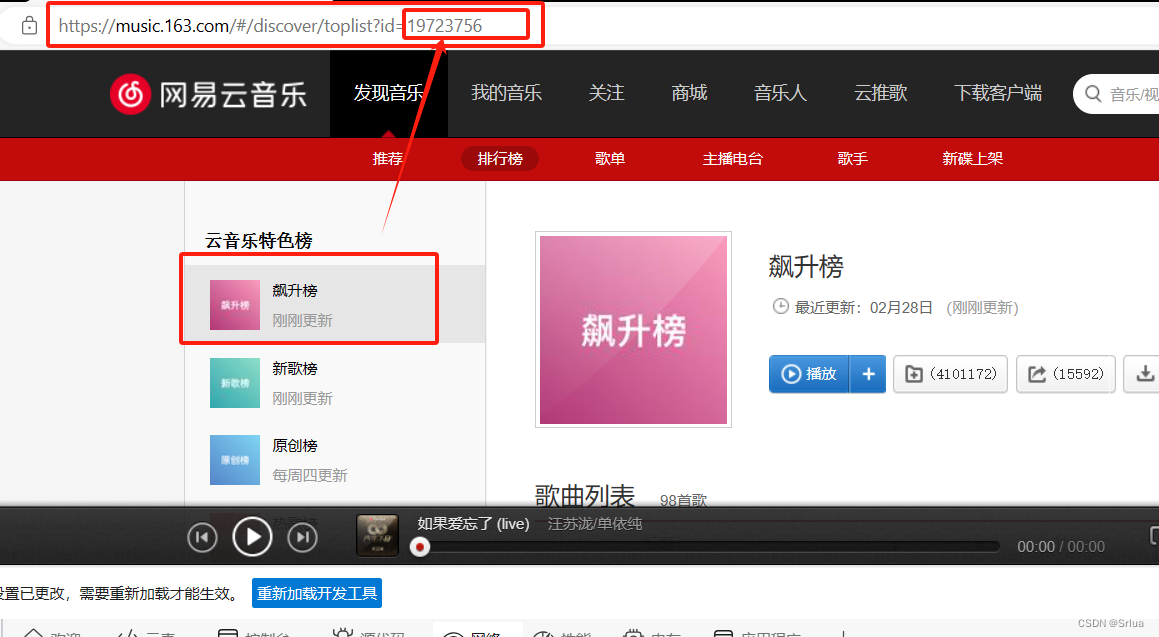
切换榜单id,爬取成功!

完整代码
import requests # 数据请求模块 第三方模块 pip install requests
import re # 正则表达式模块 内置模块 不需要安装
import os # 文件操作模块
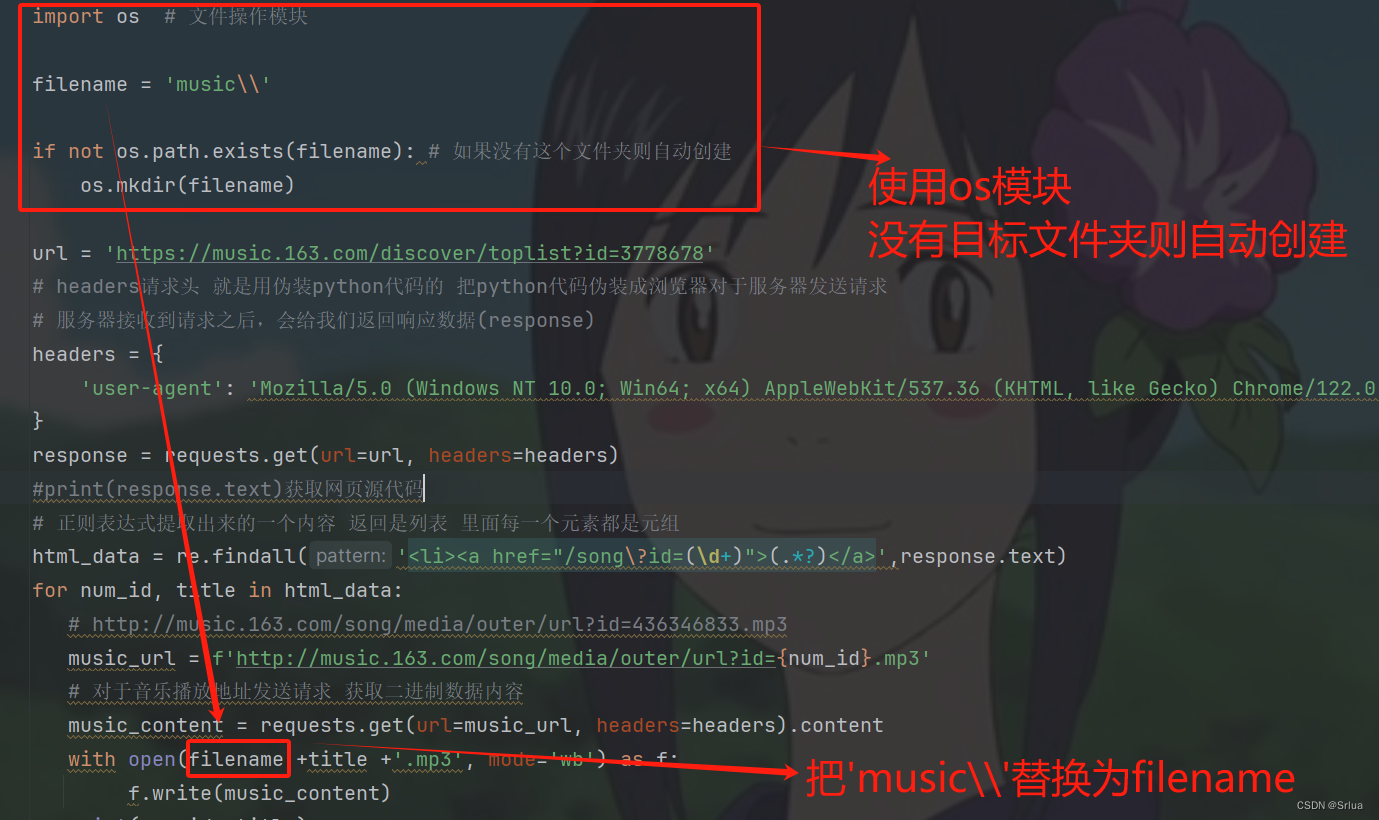
filename = 'music\\'
if not os.path.exists(filename): # 如果没有这个文件夹则自动创建
os.mkdir(filename)
# 如果想要爬取其他的榜单的歌曲内容,只要更改请求url中的id
url = 'https://music.163.com/discover/toplist?id=3778678'
# headers请求头 就是用伪装python代码的 把python代码伪装成浏览器对于服务器发送请求
# 服务器接收到请求之后,会给我们返回响应数据(response)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0'
}
response = requests.get(url=url, headers=headers)
#print(response.text)获取网页源代码
# 正则表达式提取出来的一个内容 返回是列表 里面每一个元素都是元组
html_data = re.findall('<li><a href="/song\?id=(\d+)">(.*?)</a>',response.text)
for num_id, title in html_data:
# http://music.163.com/song/media/outer/url?id=436346833.mp3
music_url = f'http://music.163.com/song/media/outer/url?id={num_id}.mp3'
# 对于音乐播放地址发送请求 获取二进制数据内容
music_content = requests.get(url=music_url, headers=headers).content
with open(filename +title +'.mp3', mode='wb') as f:
f.write(music_content)
print(num_id, title)

希望对你有帮助!加油!
若您认为本文内容有益,请不吝赐予赞同并订阅,以便持续接收有价值的信息。衷心感谢您的关注和支持!
版权归原作者 Srlua小谢 所有, 如有侵权,请联系我们删除。