
一、虚拟机安装
1、创建虚拟机
通过自定义的方式创建虚拟机:
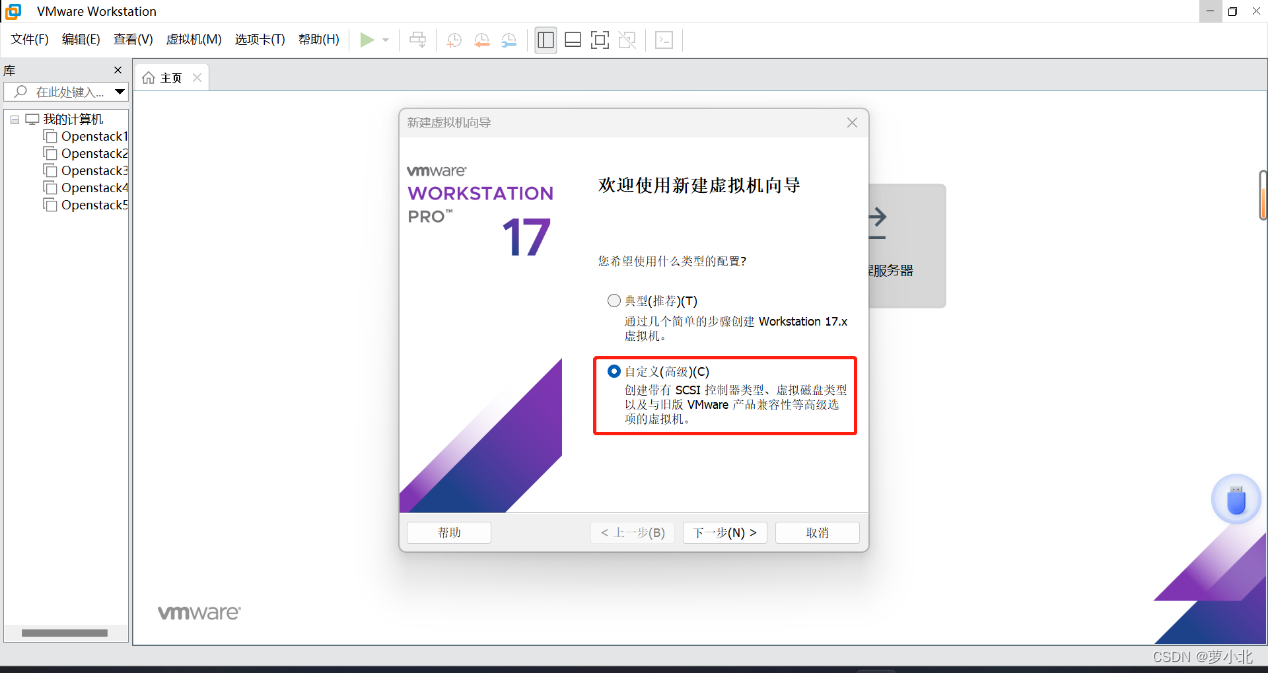
这里列出了VMware Workstation相关的信息:

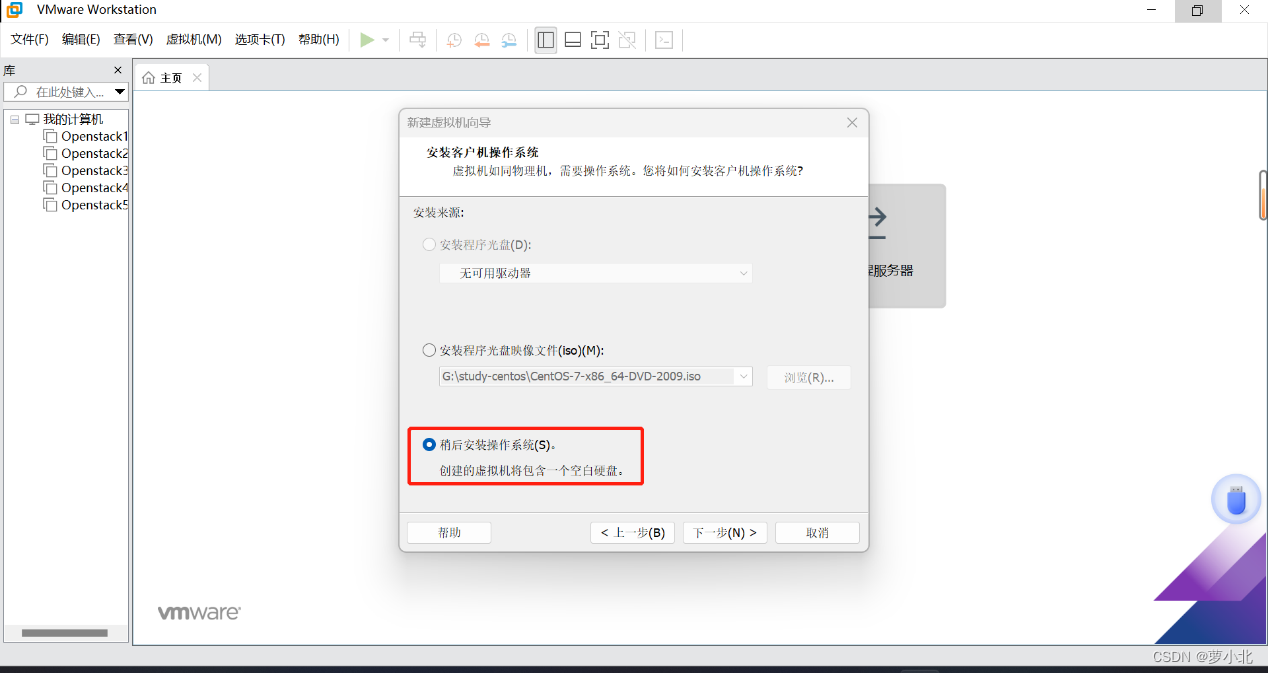
选择稍后安装虚拟机,因为安装虚拟机只是相当于安装了个裸机,还没有操作系统。
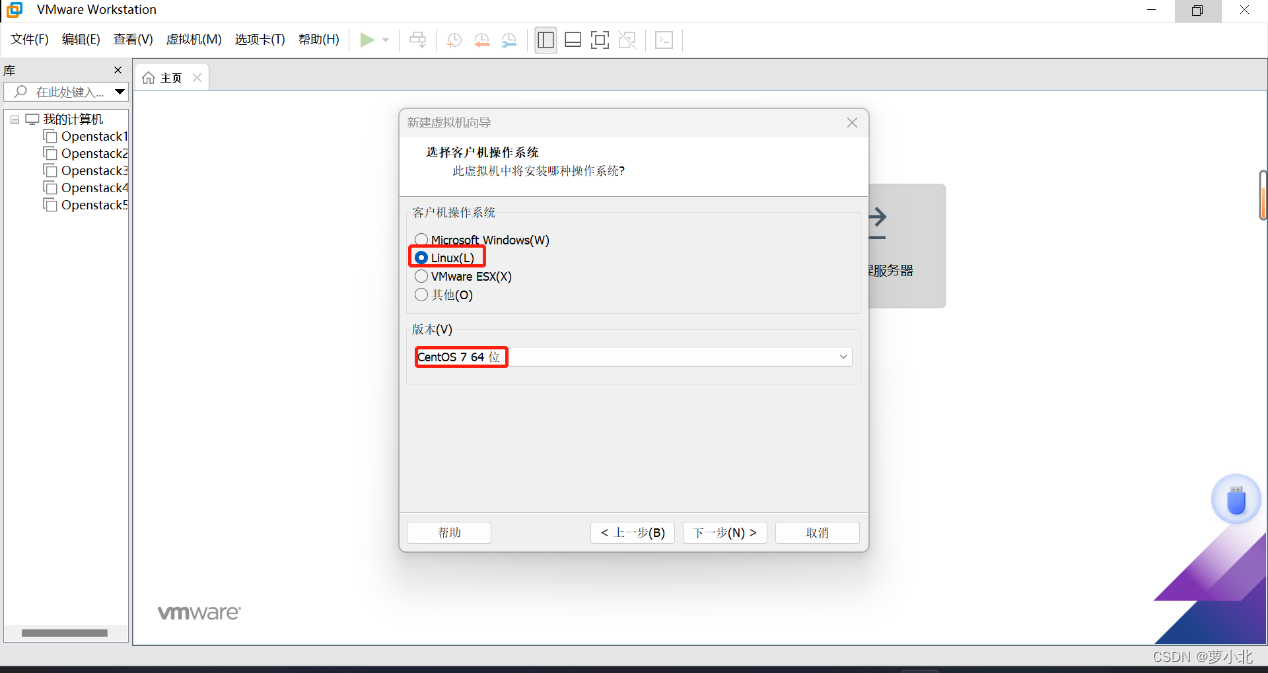
选择客户机操作系统和版本:
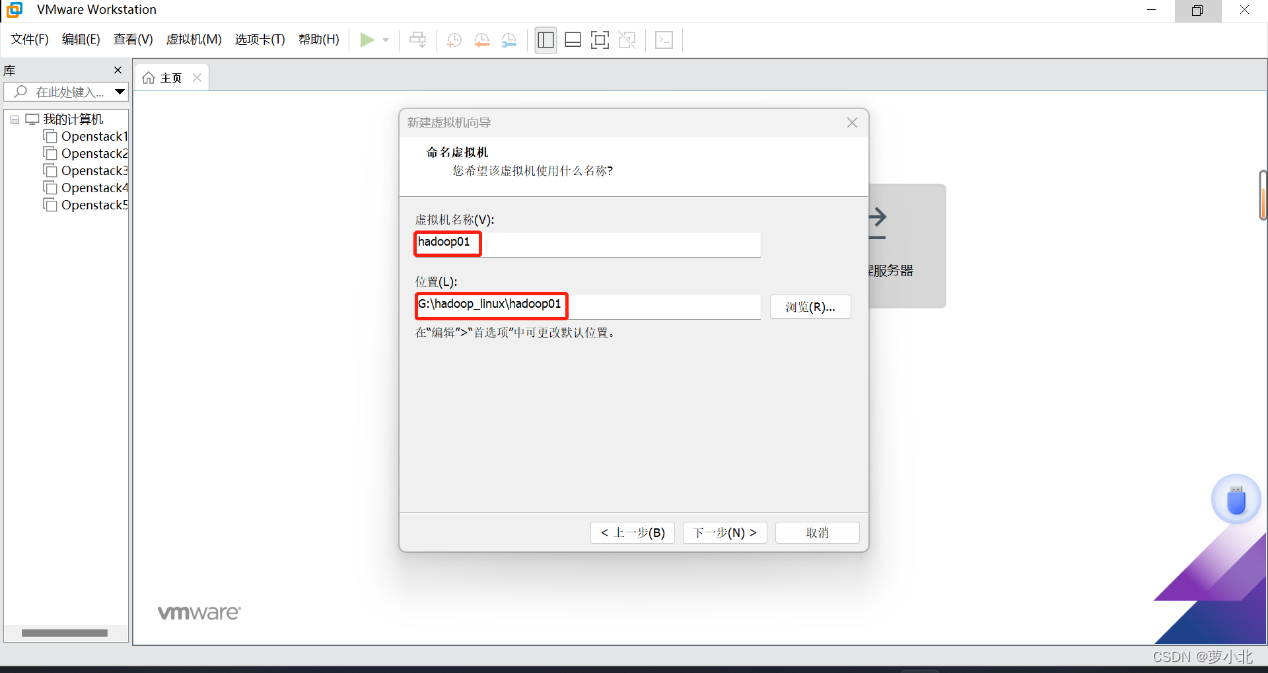
要安装3台虚拟机,把这三台虚拟机放在一个大文件夹里,每个虚拟机再单独放在一个文件夹里,因为所有虚拟机放在一个文件夹里可能会出问题:
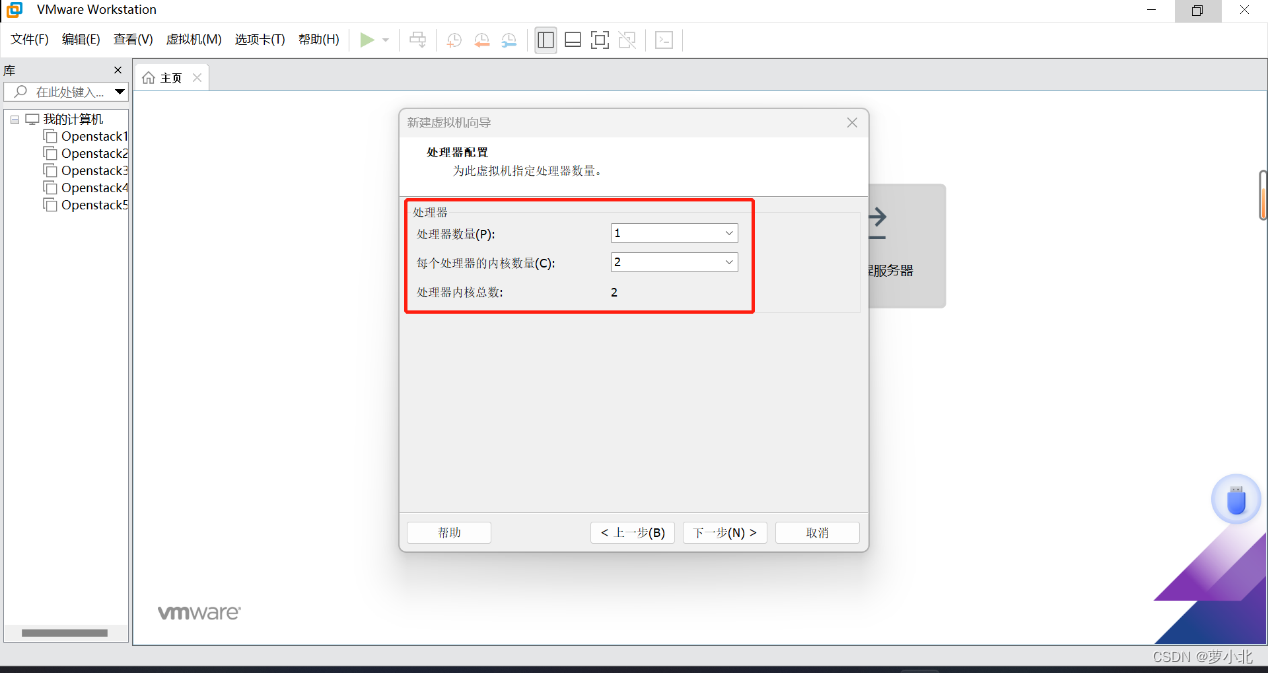
选择分配处理器,分配越多,性能越好,此处只用作学习,所以分配一个处理器就够了:
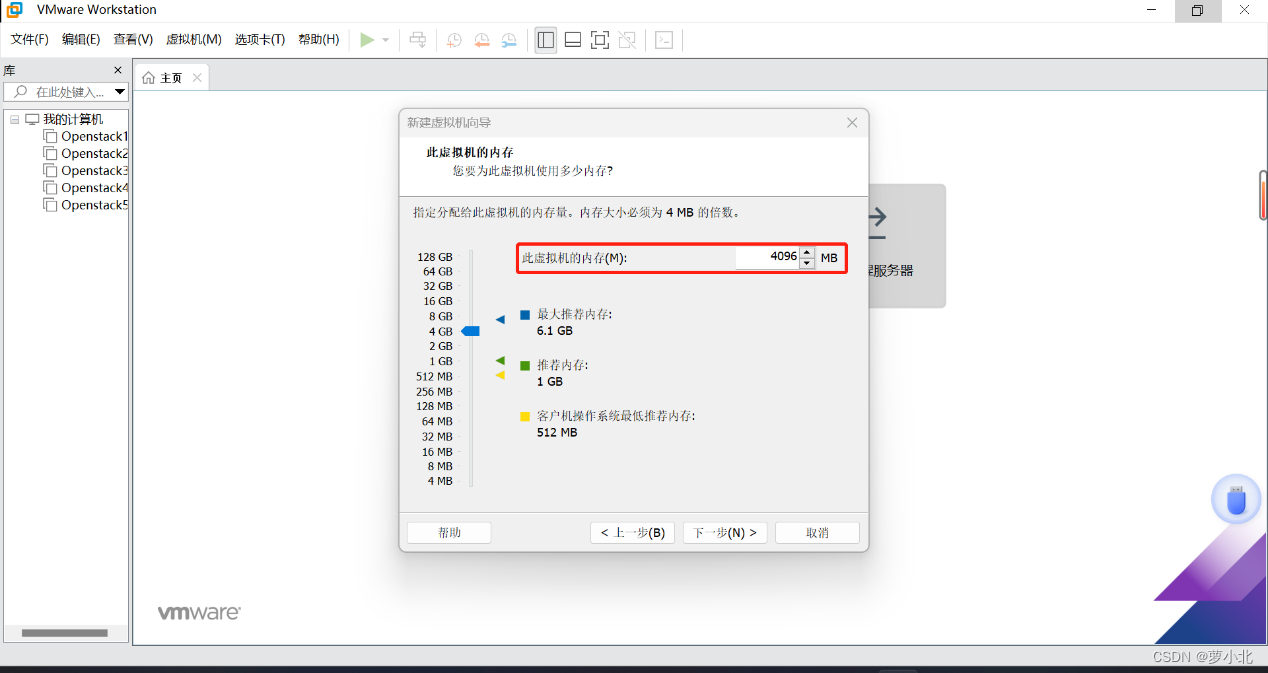
虚拟机内存分配方法:实验要求搭建三台虚拟机,相当于三台电脑,加上Windows系统本身这台电脑,一共四台计算机,可以将内存平分一下界面,即同样根据个人PC端的物理内存进行合理分配,这里搭建的Hadoop01虚拟机后续将作为Hadoop集群主节点,所以通常会分配较多的内存。
完成内存设置后,根据向导可以使用默认安装方式连续单击“下一步”按钮。当进入到“指定磁盘容量”界面后,可以根据实际需要并结合PC端硬件情况合理选择“最大磁盘大小”,此处设置为50GB,因为有时候20GB不够用,50GB也不是立即就占用的,只是最大时占用这么多空间。

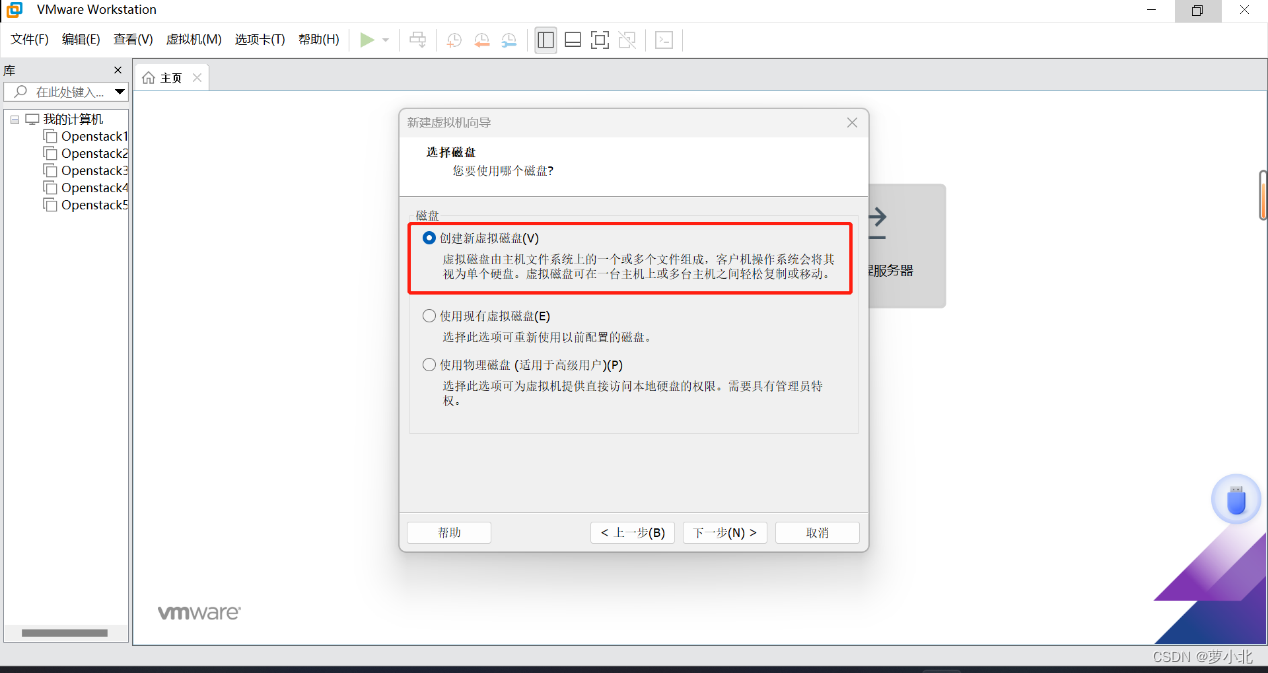
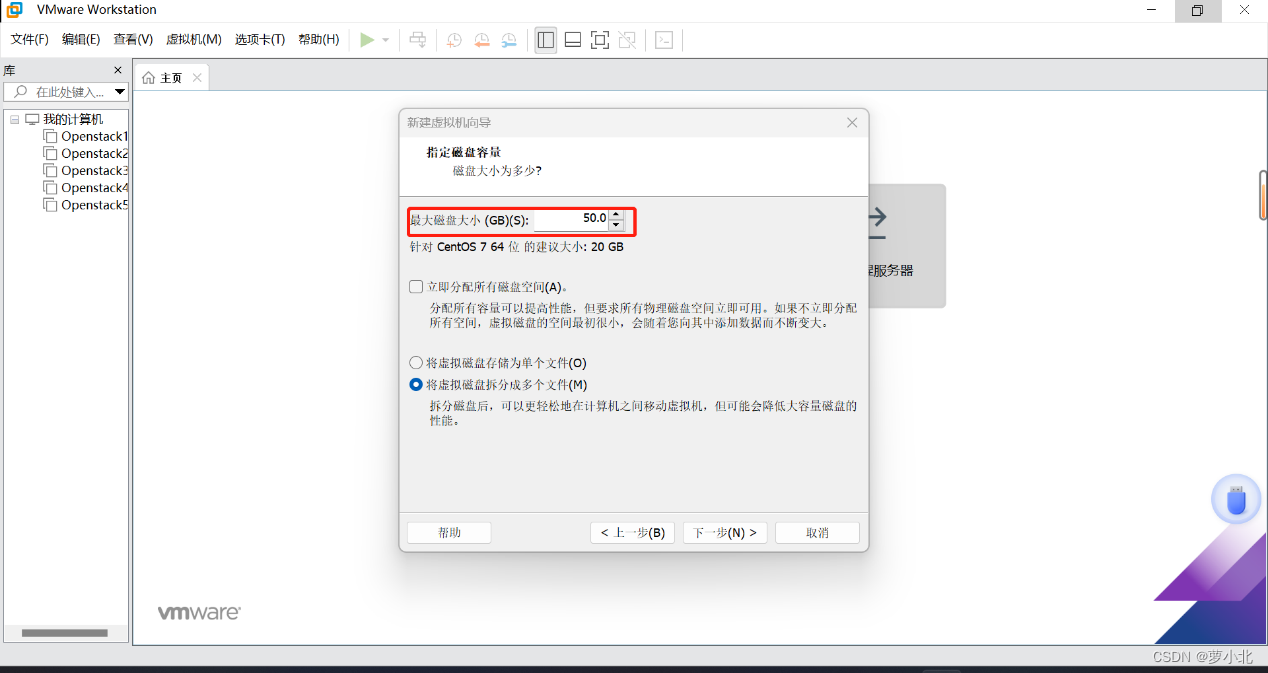
完成磁盘容量设置后,再次根据向导可以使用默认安装方式连续单击“下一步”按钮。当进入到“已准备好创建虚拟机”界面,就可以查看当前设置的要创建的虚拟机参数,在确认无误后单击“完成”按钮,即可完成新建虚拟机的设置。
需注意,此时只是配置好了一台虚拟机,他只是相当于一台裸机,没有操作系统,接下来给他安装一个操作系统。
2、虚拟机启动初始化
选中创建成功的Hadoop01虚拟机,打开“虚拟机设置”中的“CD/DVD(IDE)”选项,选中“使用ISO镜像文件(M)”选项,并单击“浏览(B)”按钮来设置ISO镜像文件的具体地址,此时就相当于给该虚拟机插了个安装光盘,接下来就可以进行安装了。
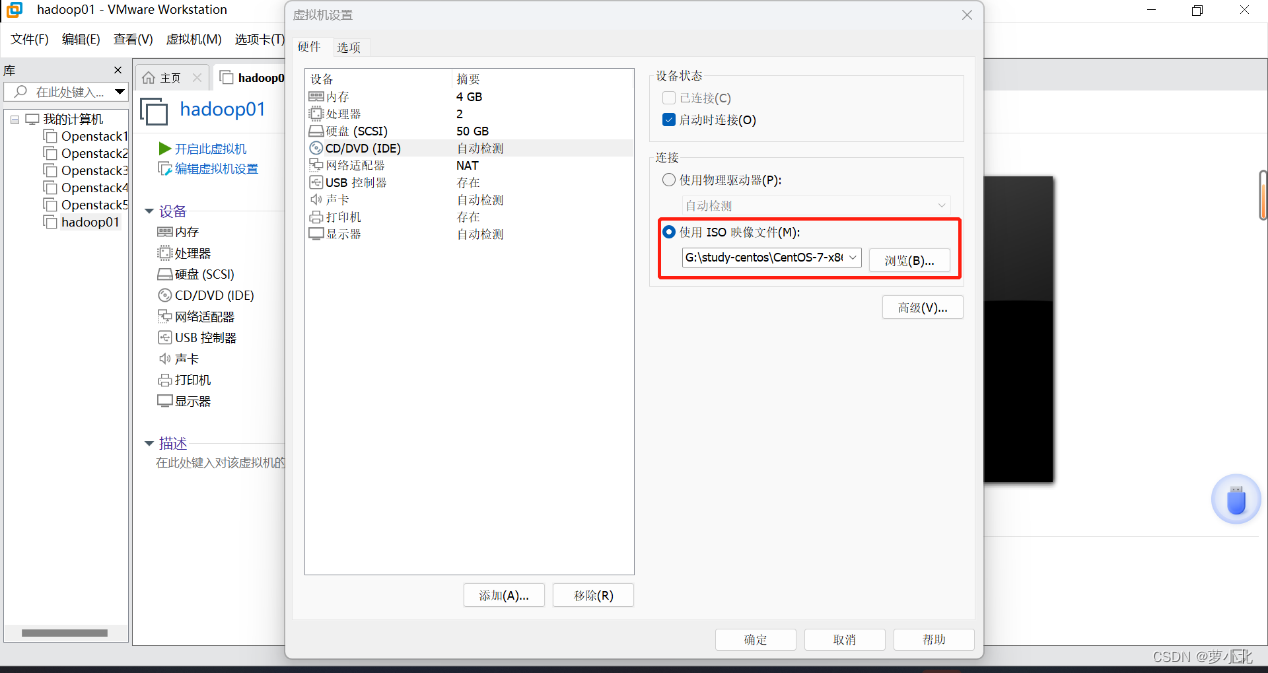
设置完ISO镜像文件后,单击 “确定”按钮,然后选择当前Hadoop01主界面的“打开虚拟机”选项,来启动Hadoop01虚拟机。
点击第一个选项:

主机名 hostname设置界面,自定义该台虚拟机的主机名hostname(此处设置该台虚拟机主机名hostname为 hadoop01)。
完成主机名设置后,单击 “Configure”选项,在弹出的窗口中选择唯一的网卡并选中“Connect automatically(自动连接)”选项,并单击“Apply(应用)”按钮。

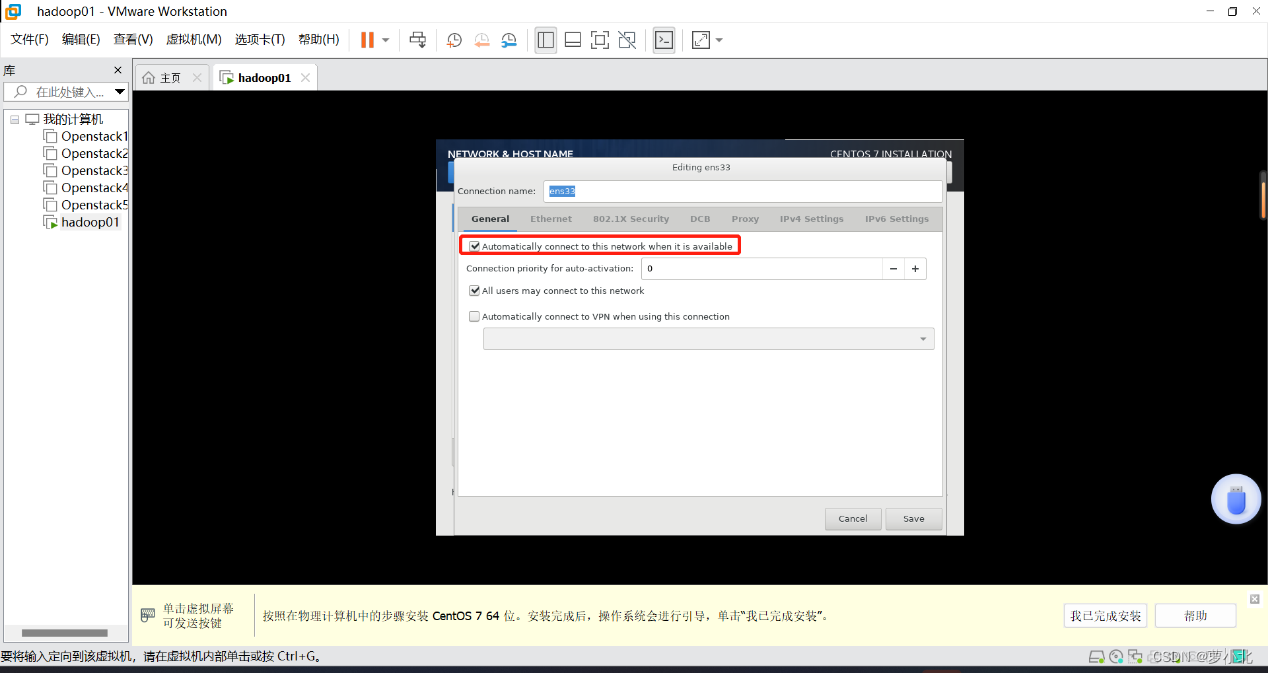
完成主机名和网络配置后,进行系统时区的选择,此处选择Asia/ShangHai。
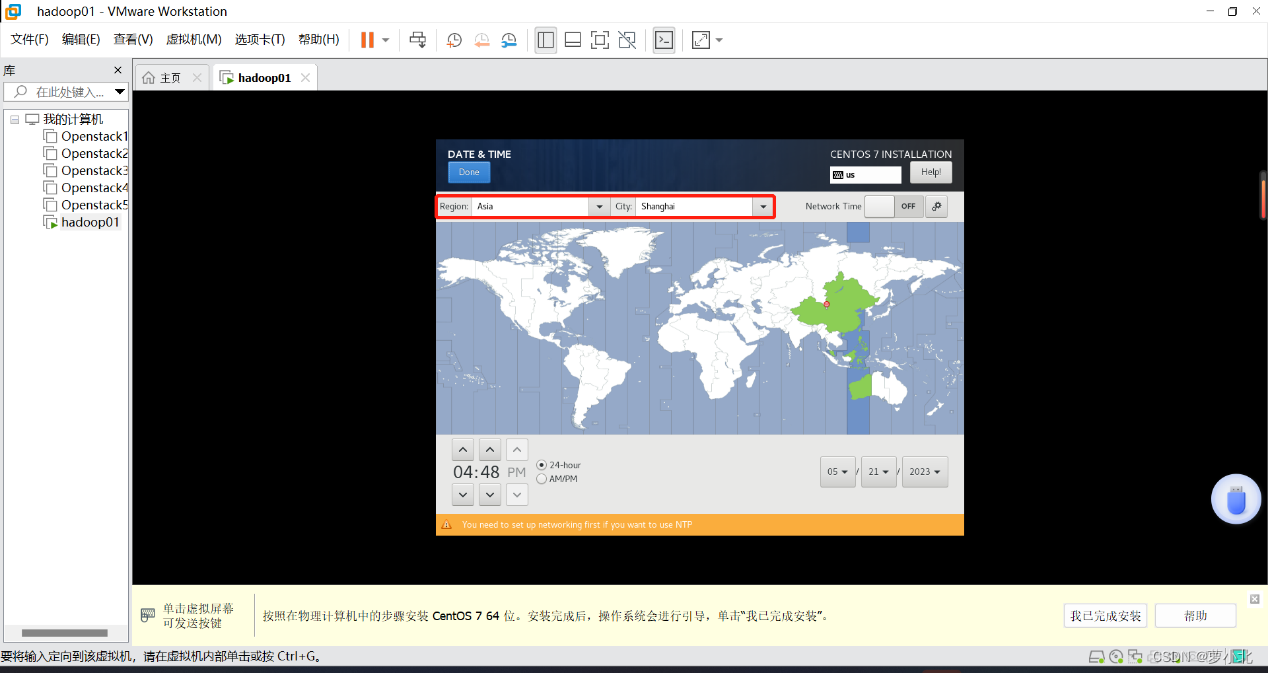
完成系统时区配置后,进入到root 用户密码设置界面,可以自定义root用户密码,但是要求密码长度最低6个字符(如果密码强度较低可能出现提示窗,直接单击“Use Anyway(无论如何都用)”选项即可),此处设置为123456。
然后就是安装和重启:

至此,就完成了CentOS虚拟机的安装。
为了规范后续Hadoop集群相关软件和数据的安装配置,这里在虚拟机的根目录下创建一些文件夹作为约定,具体如下:
/export/data/:存放数据类文件;
/export/servers/:存放服务类软件;
/export/software/:存放安装包文件。

二、 虚拟机克隆
目前已经成功安装好了一台搭载 CentOS镜像文件的Linux系统,而一台虚拟机远远不能满足搭建Hadoop集群的需求,因此需要对已安装的虚拟机进行克隆。VMware提供了两种类型的克隆,分别是完整克隆和链接克隆。
完整克隆:是对原始虚拟机完全独立的一个复制,它不和原始虚拟机共享任何资源,可以脱离原始虚拟机独立使用。
链接克隆:需要和原始虚拟机共享同一虚拟磁盘文件,不能脱离原始虚拟机独立运行。但是,采用共享磁盘文件可以极大缩短创建克隆虚拟机的时间,同时还节省物理磁盘空间。通过链接克隆,可以轻松地为不同的任务创建一个独立的虚拟机。
以上两种克隆方式中,完整克隆的虚拟机文件相对独立并且安全,在实际开发中也较为常用,此处使用完整克隆方式。
在VMware工具左侧系统资源库中右击 Hadoop01,选择“管理”列表下的“克隆”选项,弹出克隆虚拟机向导。
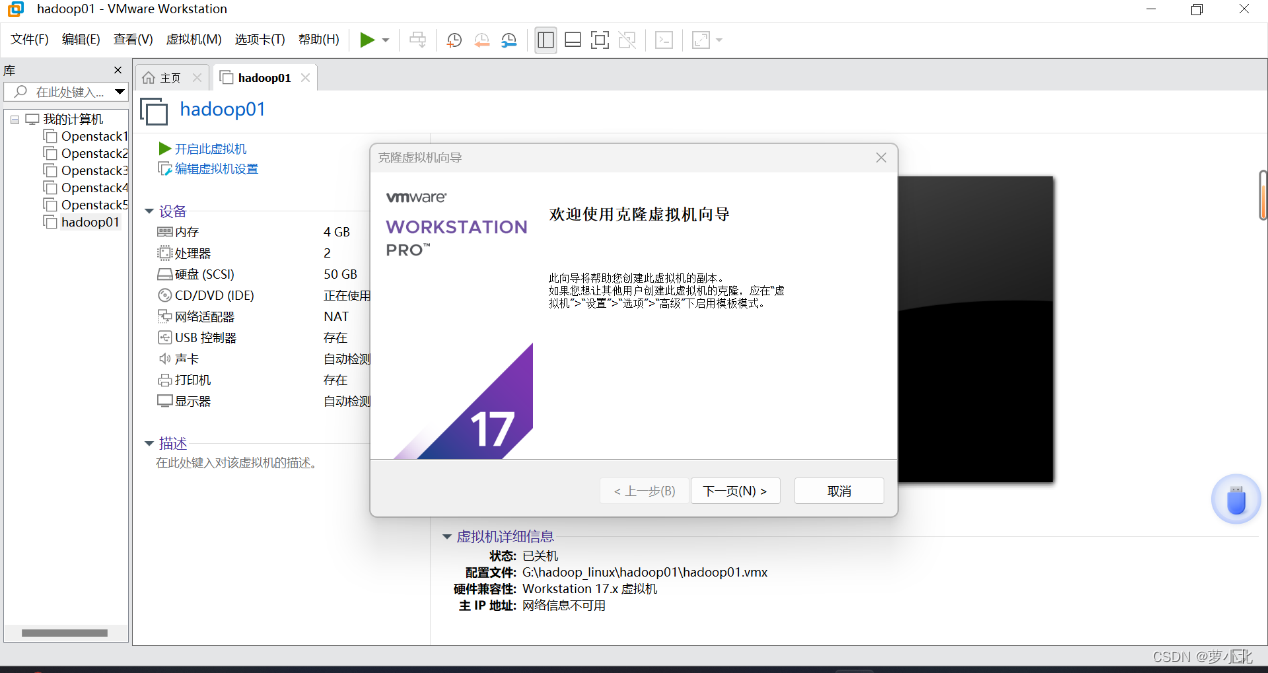
根据克隆向导连续单击界面中的“下一步”按钮,进入到“克隆类型”界面后﹐选择“创建完整克隆(F)”选项。
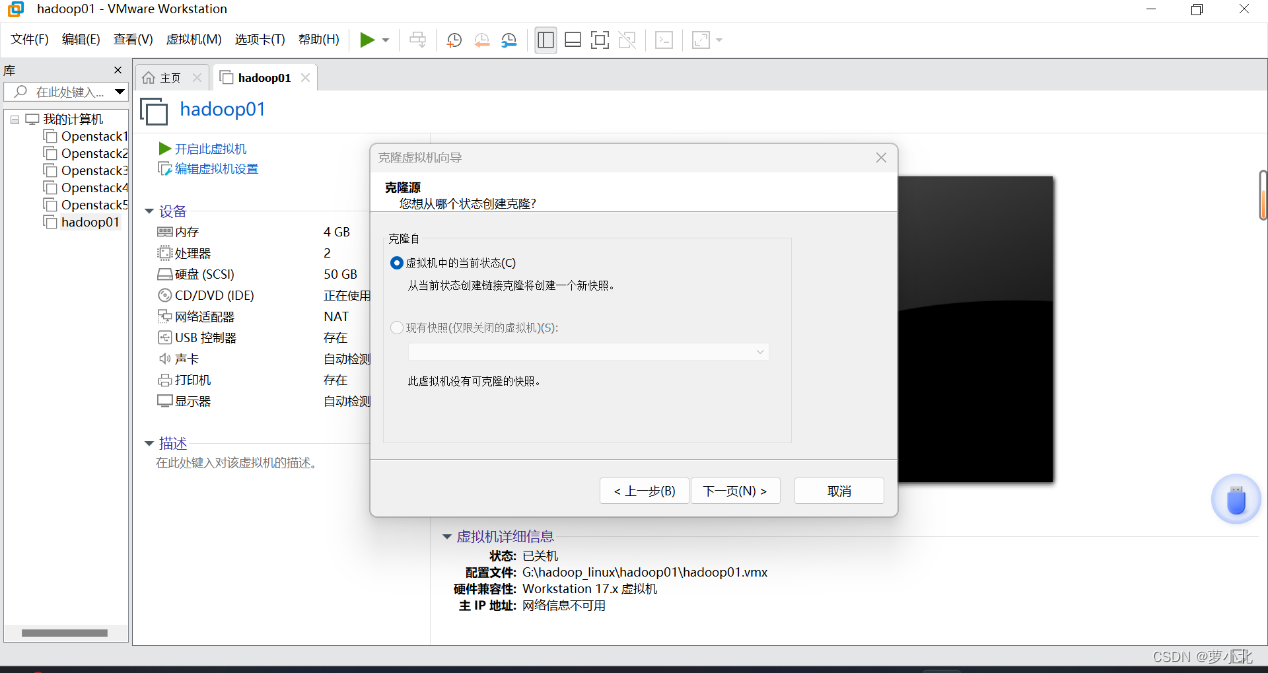
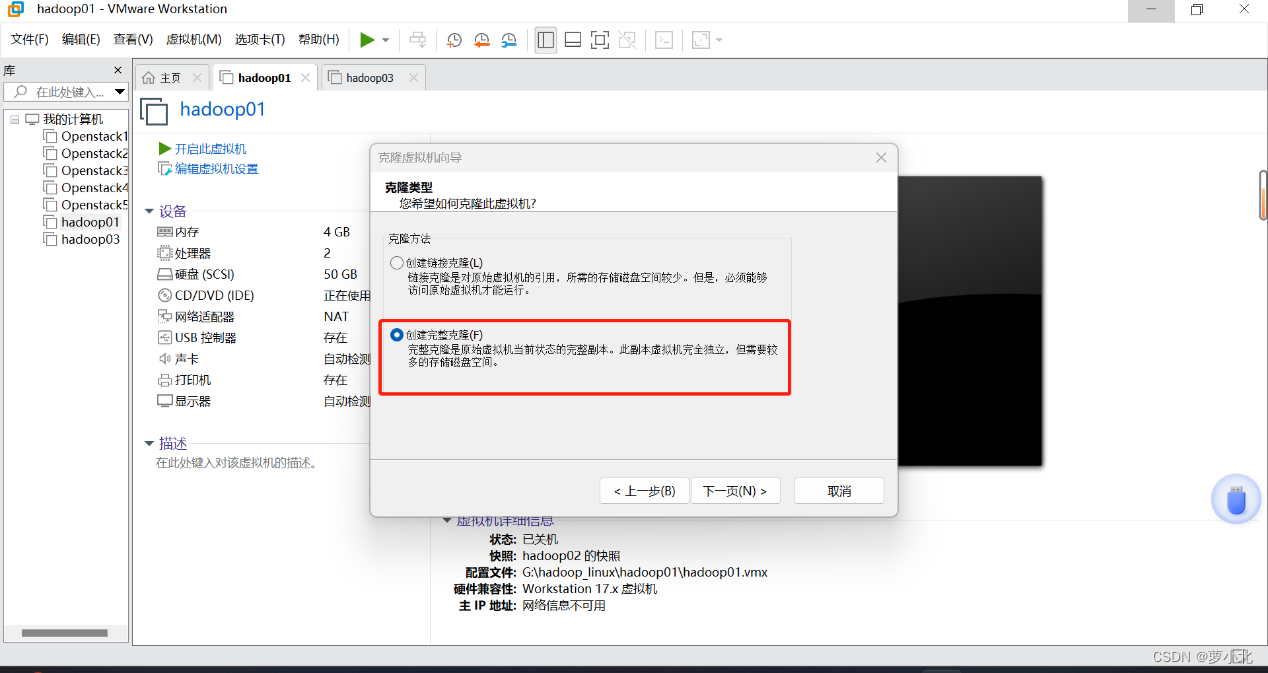
选择完整克隆方式后,单击“下一步”按钮,进入到“新虚拟机名称”界面,在该界面自定义新虚拟机名称和位置。

设置好新虚拟机名称和位置后,单击“完成”按钮就会进入新虚拟机克隆过程,稍等片刻就会跳转到虚拟机克隆的结果界面。在克隆成功界面,单击“关闭”按钮就完成了虚拟机的克隆。
重复上述步骤,即可克隆出hadoop03虚拟机:

有时为了方便管理这三台虚拟机,在VMware工具左侧系统资源库中右击“我的计算机”,新建一个文件夹,将创建好的hadoop01、hadoop02、hadoop03虚拟机拖进去。

三、Linux系统的网络配置
通过前面方式安装的虚拟机hadoop01虽然能够正常使用,但是该虚拟机的IP是动态生成的,在不断的开停过程中很容易改变,非常不利于实际开发;而通过Hadoop01克隆的虚拟机(hadoop02和hadoop03)则完全无法动态分配到IP,直接无法使用。因此,还需要对这三台虚拟机的网络分别进行配置。
1、准备工作
对虚拟机进行网络配置,先把网段都改成137。
并分别对子网、子网掩码、NAT、DHCP进行设置:
子网IP设置为192.168.137.0,最后一位设置为0,否则会出现子网掩码与IP冲突。
网关最后一位设置为2即可。

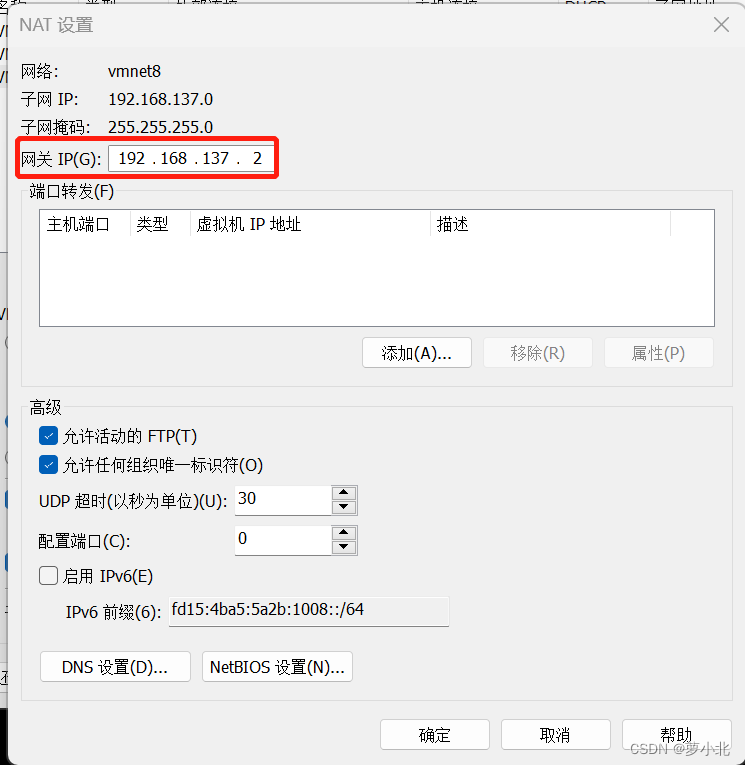
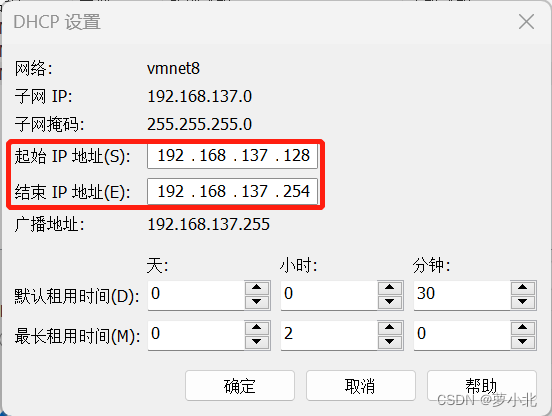
再对Windows进行网络配置,要与虚拟机编辑中的虚拟网络编辑器中的设置一致:


IP地址:这个IP在局域网内部不冲突即可
子网掩码:默认即可
默认网关:要与虚拟机编辑中的虚拟网络编辑器中的NAT设置的网关一致
首选DNS服务器:使用谷歌提供的免费的DNS服务器即可
配置好之后,点确定即可:

2、 主机名和IP映射
遇到的问题:

解决方法:
把虚拟机内存改为2GB即可。
开启三台虚拟机,使用root身份登录,并查询虚拟机hadoop01、hadoop02、hadoop03的主机名,因为hadoop02、hadoop03是从hadoop01克隆过来的,所以主机名都是hadoop01:



2.1 配置主机名
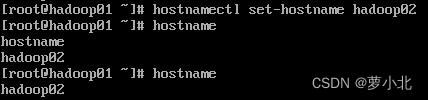
hadoop02:
hadoop03:
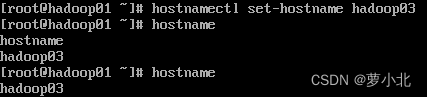
执行上述指令后,虚拟机hadoop01, hadoop02,hadoop03主机名依次设置为hadoop01 , hadoop02和hadoop03。
2.2 配置IP映射
配置IP映射,要明确当前虚拟机的IP和主机名,主机名可以参考前面已配置的主机名,但IP地址必须在VMware 虚拟网络IP地址范围内。
然后,执行如下指令对IP映射文件 hosts进行编辑:


三个虚拟机都按上述步骤执行一遍,IP映射配置完成。
3、网络参数配置
上一步中,对虚拟机的主机名和IP映射进行了配置,而想要虚拟机能够正常使用,还需要进行网络参数配置。
hadoop01:
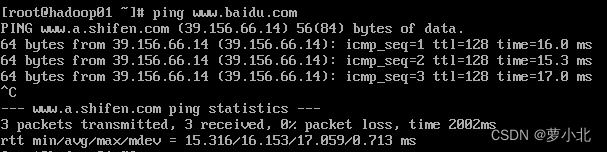
(1)查看网络是否连通
(2)安装net-tools
yum upgrade
yum install net-tools
(3)查看MAC地址(enter后面):
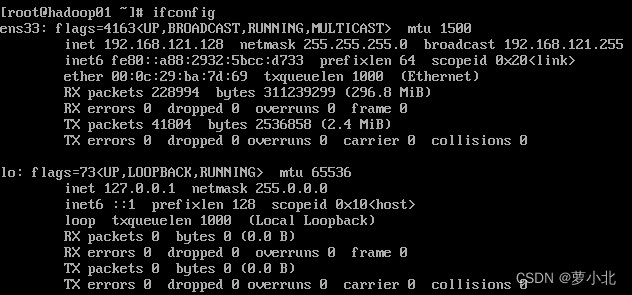
(4)修改网络配置文件:
执行如下指令:

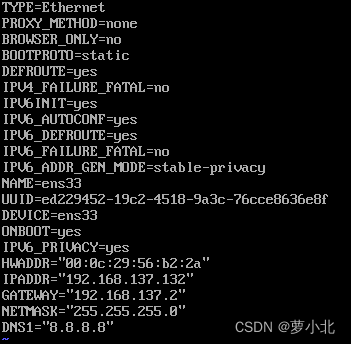
进入文本编辑,把BOOTPROTO改为static,ONBOOT改为yes
ONBOOT=yes:表示启动这块网卡;
BOOTPROTO=static:表示静态路由协议,可以保持IP固定;
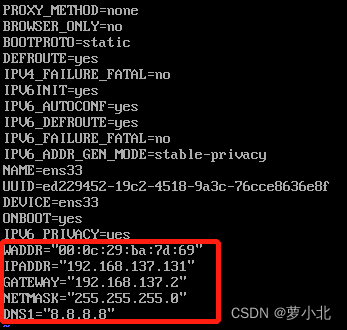
HWADDR:表示虚拟机 MAC地址,需要与当前虚拟机MAC地址一致;
IPADDR:表示虚拟机的IP地址,这里设置的IP地址要与前面IP映射配置时的IP地址一致,否则无法通过主机名找到对应IP;
GATEWAY:表示虚拟机网关,通常都是将IP地址最后一位改成2;
NETMASK:表示虚拟机子网掩码,通常都是255.255.255.0;
DNS1:表示域名解析器,此处采用Google提供的免费DNS服务器8.8.8.8(也可以设置为PC端电脑对应的DNS)。
(5)重启网络服务,查看是否配置成功
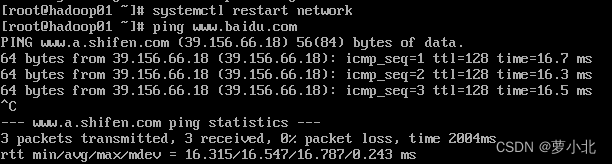
(6)重启虚拟机后,查看是否连通网络(ip地址并未改变,且能连通网络):
 hadoop02:
hadoop02:
(1)查看mac地址

(2)网络配置文件修改
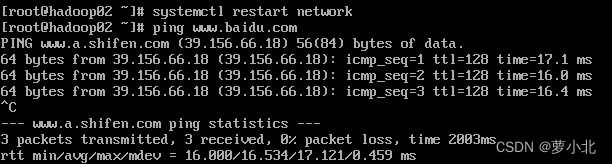
(3)重新启动网络配置(查看网络是否可用):
按照以上步骤,再配置另外一台虚拟机Hadoop03。
hadoop03:
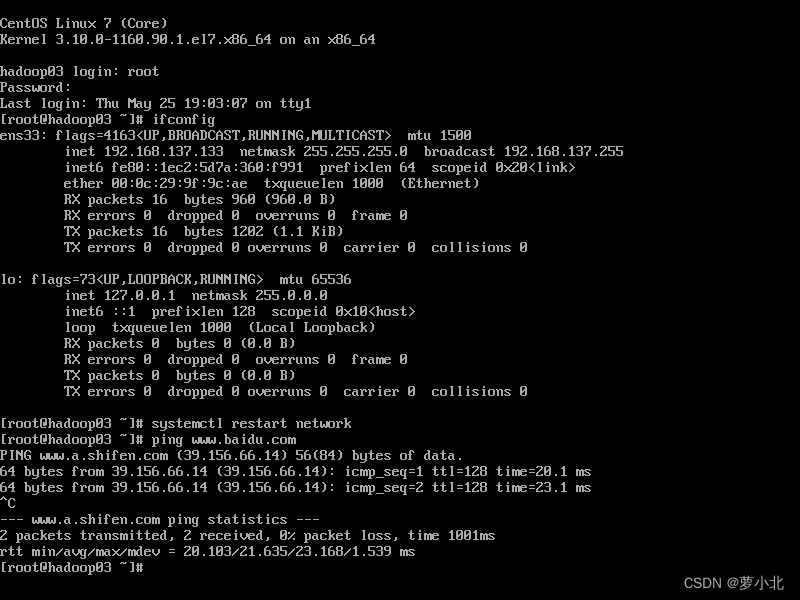
四、SSH服务配置
通过前面的操作,已经完成了三台虚拟机Hadoop01、Hadoop02和Hadoop03的安装和网络配置,虽然这些虚拟机已经可以正常使用了,但是依然存在下列问题:
(1)实际工作中,服务器被放置在机房中,同时受到地域和管理的限制,开发人员通常不会进入机房直接上机操作,而是通过远程连接服务器,进行相关操作。
(2)在集群开发中,主节点通常会对集群中各个节点频繁地访问,就需要不断输入目标服务器的用户名和密码,这种操作方式非常麻烦并且还会影响集群服务的连续运行为了解决上述问题,可以通过配置 SSH 服务来分别实现远程登录和 SSH 免密登录功能。
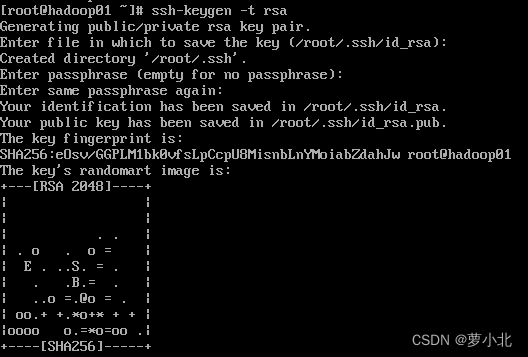
1、生成密钥文件
四次回车:
2、将本机公钥文件复制到其他虚拟机上
注意:接收方需先开机
在hadoop01上执行,先输入yes,后输入对应主机的密码,三台虚拟机配置操作相同:
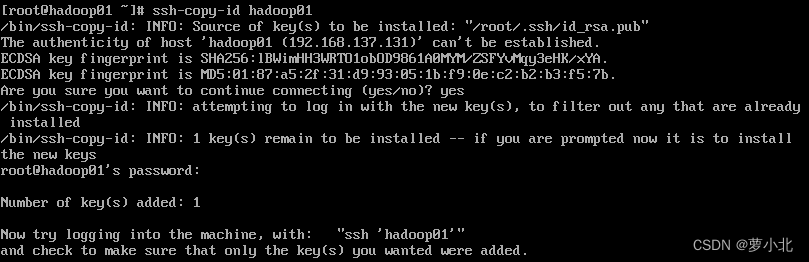
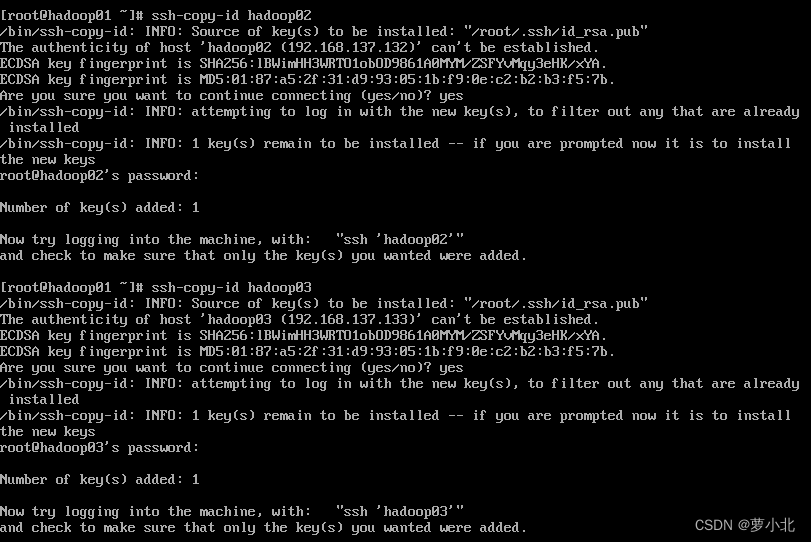
在虚拟机hadoop02,hadoop03都需要执行,保证三台主机都能够免密登录:

五、JDK安装和Hadoop安装
1、准备安装包
hadoop-2.7.4.tar.gz
jdk-8u161-linux-x64.tar.gz
2、下载安装软件Xshell
打开Xshell后点击文件并选择新建,名称填hadoop01,主机填写hadoop01的IP地址,再点击用户身份验证,把hadoop01的账号、密码输入,就可以通过Xshell控制虚拟机,方便后续软件的传输、复制、粘贴。
重复步骤新建会话控制hadoop02,hadoop03。
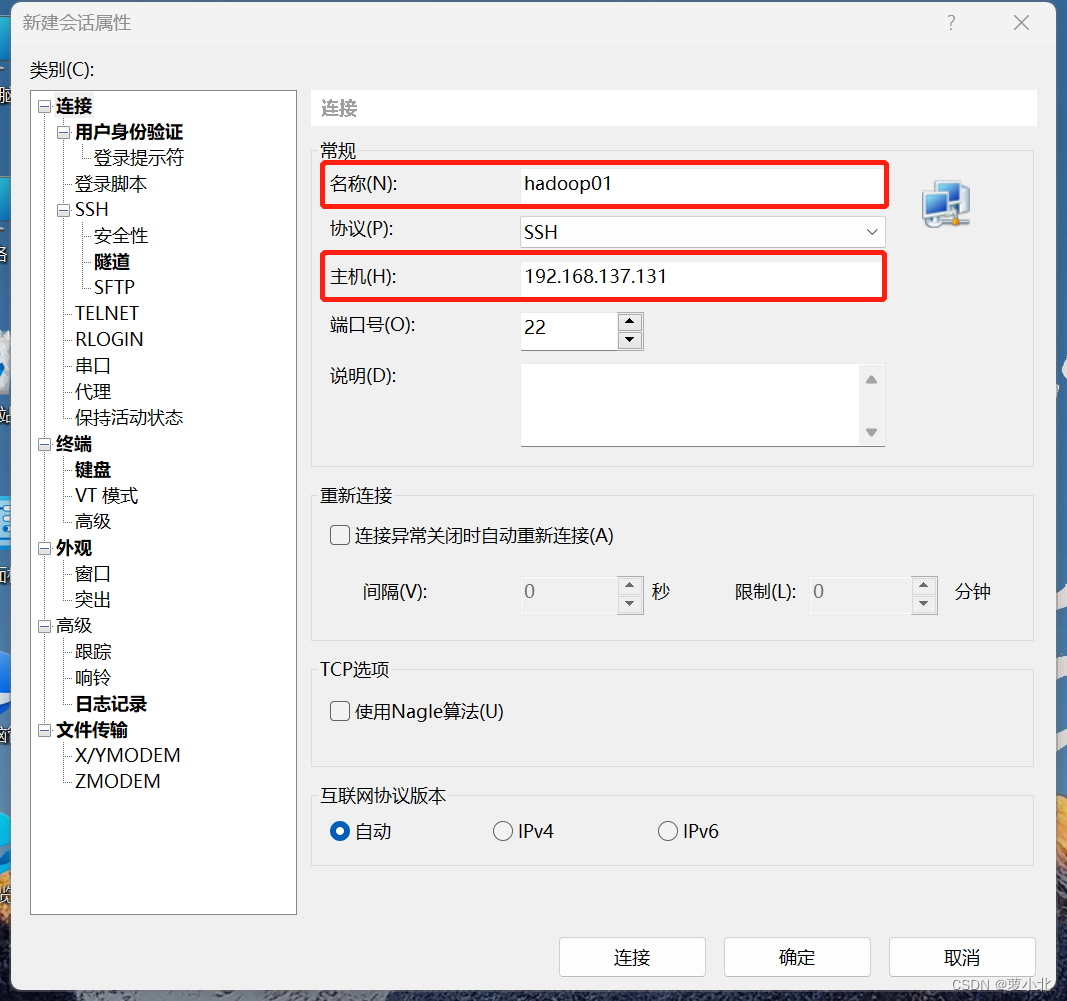
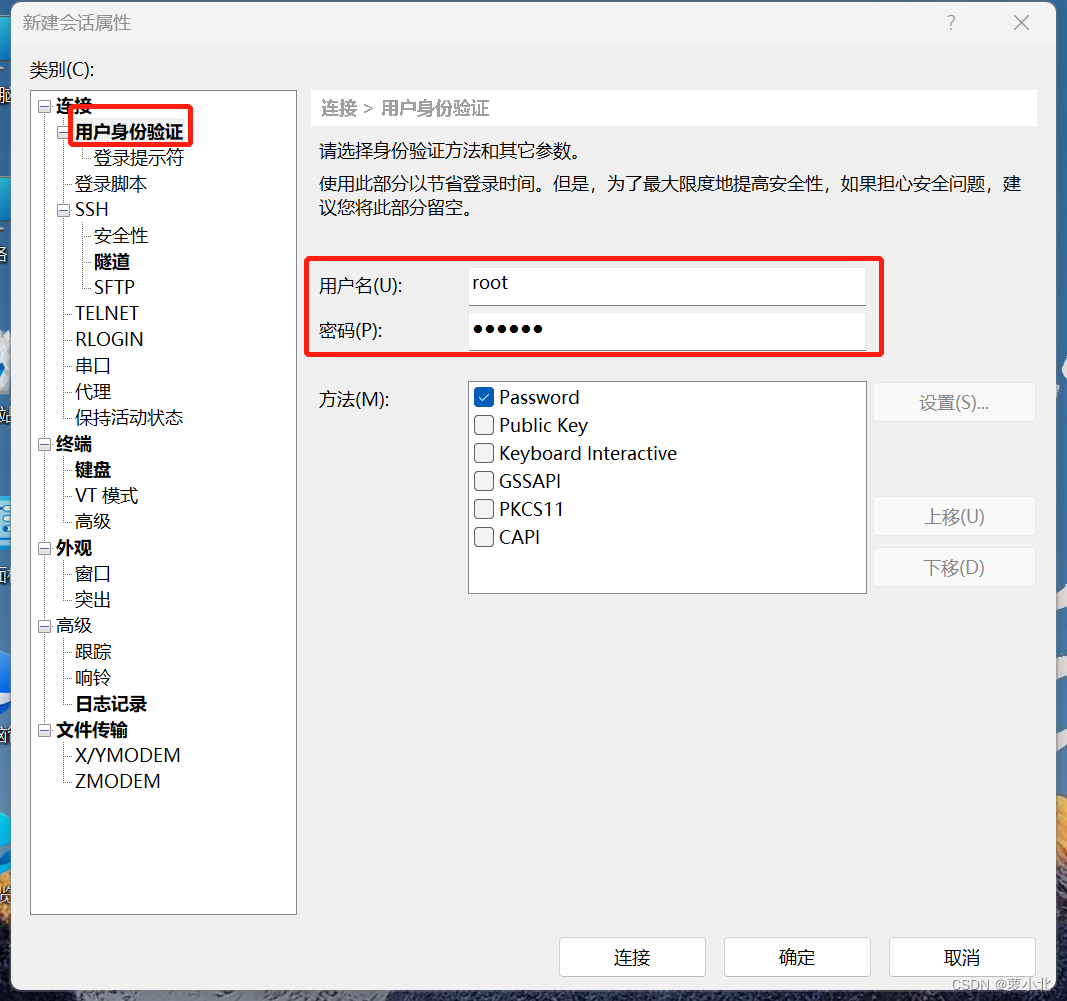
出现下示界面,即为连接成功:

3、安装JDK(所有虚拟机都要操作)
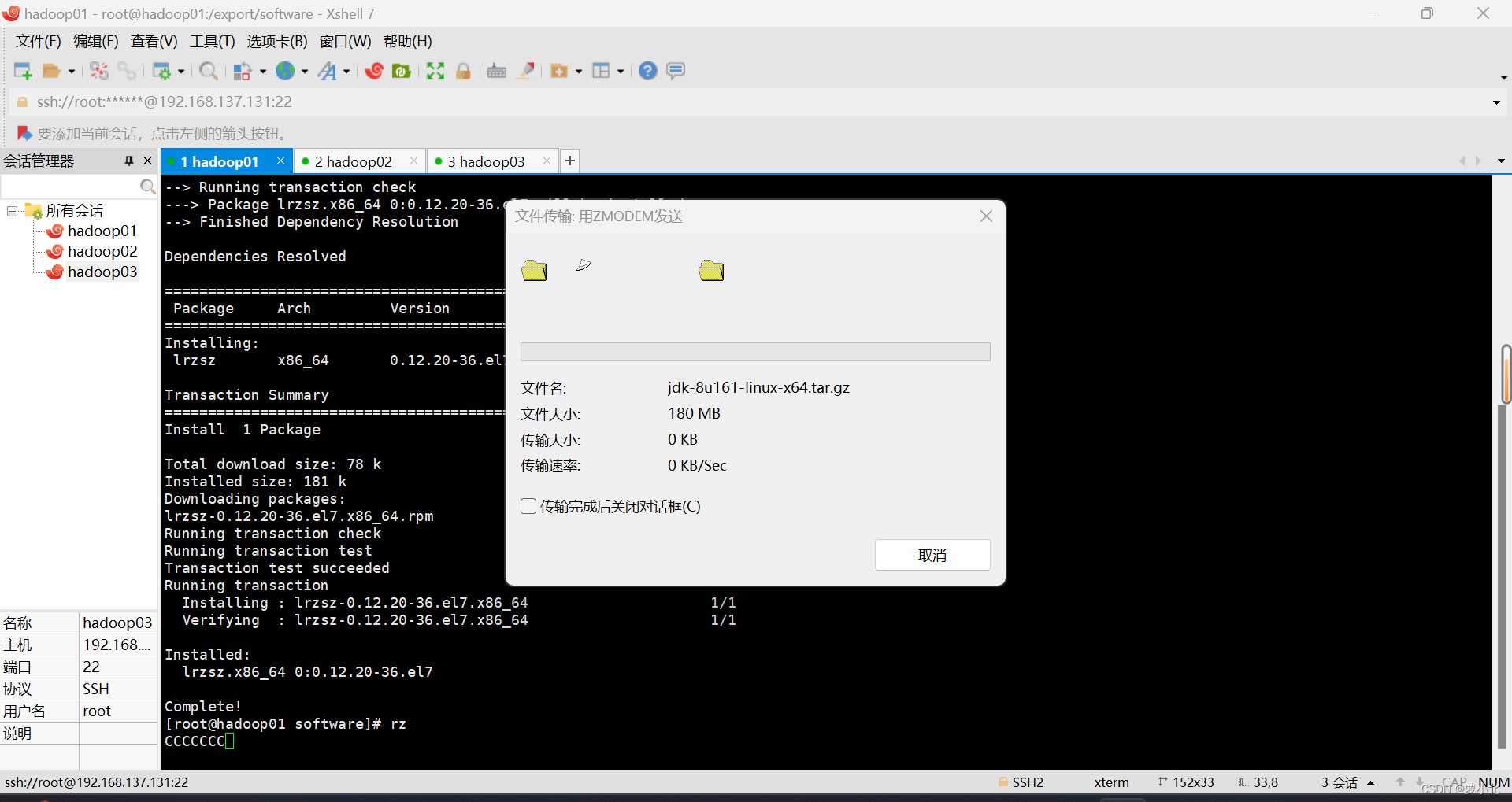
3.1 传输文件
在Xshell先进入software文件内,然后下载rz命令,并使用rz命令进行文件上传,此时会弹出上传的窗口,选择要上传的文件,点击确定即可将本地文件上传到Linux上。


3.2 解压JDK
cd /export/software
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /export/servers/
3.3 重命名JDK目录
cd /export/servers
mv jdk1.8.0_161 jdk
3.4 配置环境变量


3.5 使配置文件生效

3.6 查看是否配置成功

(hadoop02、hadoop03都按上述步骤执行一遍)
4、Hadoop安装(所有虚拟机都要操作)
4.1 传输文件
遇到的问题:

解决方法:
双击左侧会话,重新连接即可。

4.2 解压Hadoop
cd /export/software
tar -zxvf hadoop-2.7.4.tar.gz -C /export/servers/
4.3 打开配置文件

4.4 配置Hadoop环境变量

4.5 使配置文件生效

4.6 查看是否配置成功

(hadoop02、hadoop03都按上述步骤执行一遍)
六、Hadoop集群配置
1、进入主节点配置目录
 2、修改hadoop-env.sh文件
2、修改hadoop-env.sh文件


上述配置文件中设置的是Hadoop运行时需要的JDK环境变量,目的是让Hadoop启动时能够执行守护进程。
3、修改core-site.xml文件

该文件是Hadoop的核心配置文件,其目的是配置HDFS地址、端口号,以及临时文件目录。
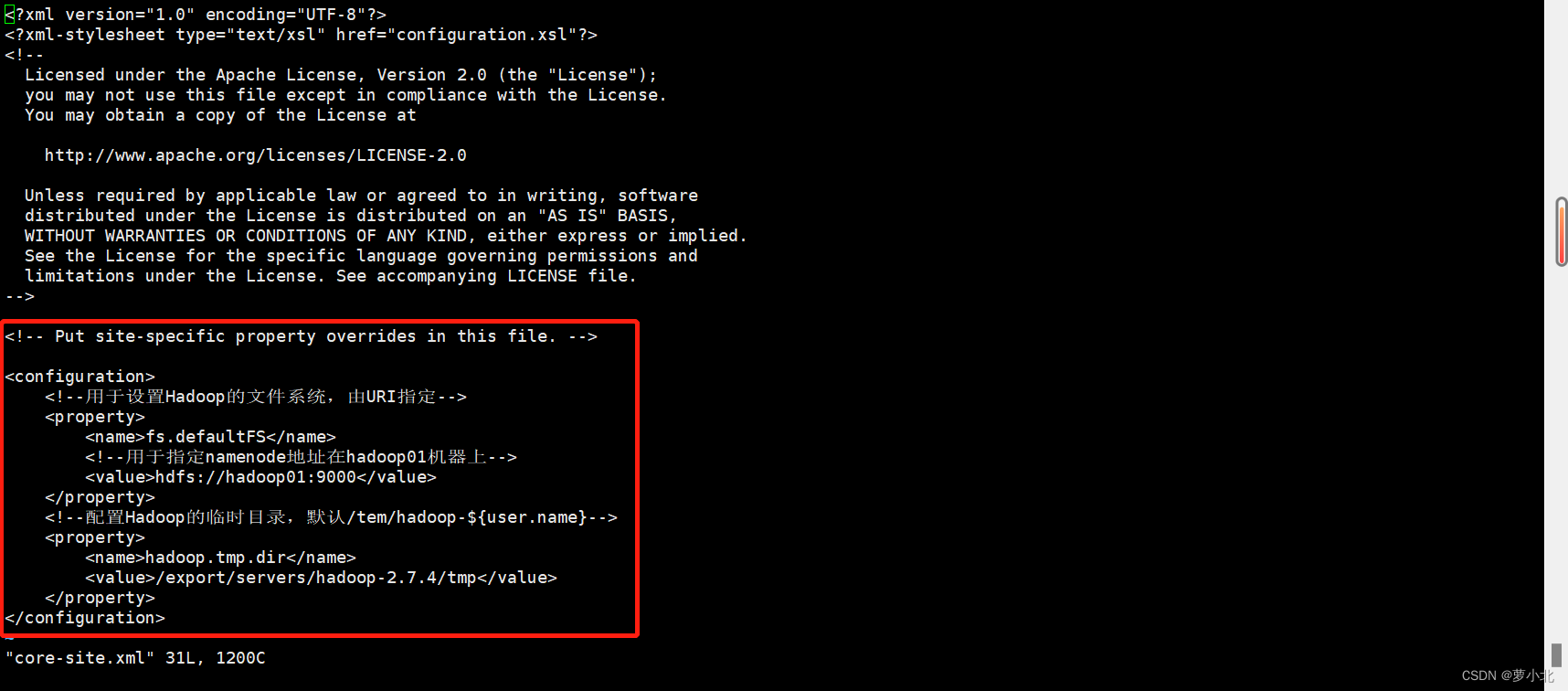
在上述核心配置文件中,配置了HDFS的主进程NameNode运行主机(也就是此次Hadoop集群的主节点位置),同时配置了Hadoop运行时生成数据的临时目录。
4、修改hdfs-site.xml文件

该文件用于设置HDFS的 NameNode和 DataNode两大进程。
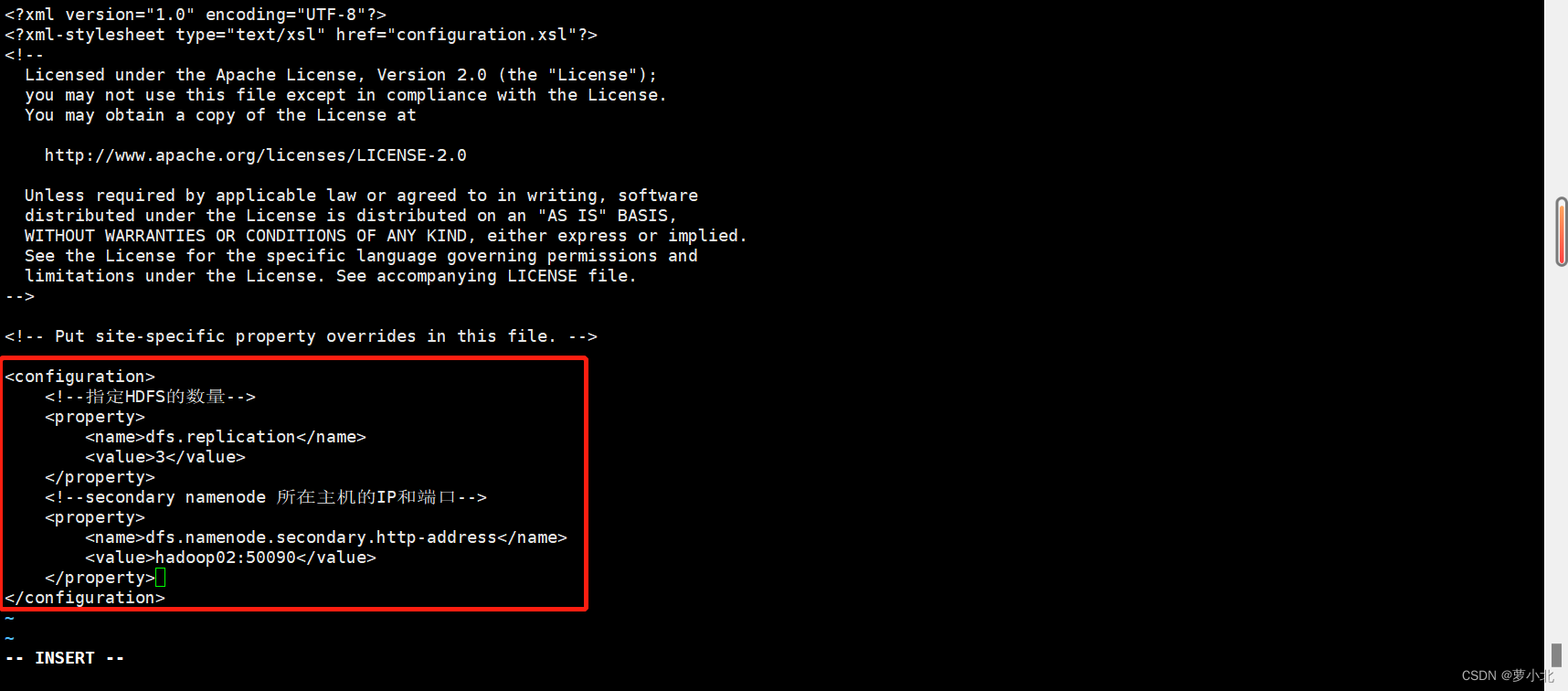
在上述配置文件中,配置了HDFS数据块的副本数量,并根据需要设置了Secondary NameNode所在服务的HTTP协议地址。
5、修改mapred-site.xml文件

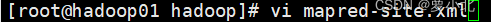

在上述配置文件中,就是指定了Hadoop 的MapReduce运行框架为YARN。
6、修改yarn-site.xml文件

本文件是YARN框架的核心配置文件,需要指定YARN集群的管理者。
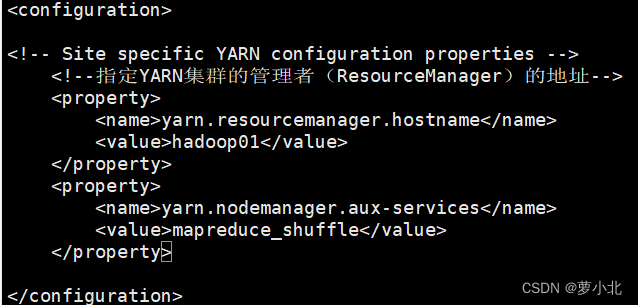
在上述配置文件中,配置了YARN的主进程ResourceManager运行主机为hadoop01 ,同时配置了NodeManager运行时的附属服务,需要配置为mapreduce_shuffle才能正常运行MapReduce默认程序。
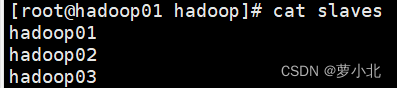
7、修改slaves文件

该文件用于记录Hadoop集群所有从节点(HDFS的 DataNode和 YARN 的NodeManager所在主机)的主机名,用来配合一键启动脚本启动集群从节点。
8、将主节点中配置好的文件和hadoop目录copy给子节点






9、使子节点中的配置文件生效
返回hadoop02和hadoop03节点执行下面命令:


10、在主节点格式化文件系统
至此,整个集群所有节点就都有了hadoop运行所需要的环境和文件,hadoop集群也就安装配置完成。但是此时还不能直接启动集群,因为在初次启动HDFS集群时,必须对主节点进行格式化处理,具体指令如下。

出现successfully formatted 即为格式化成功
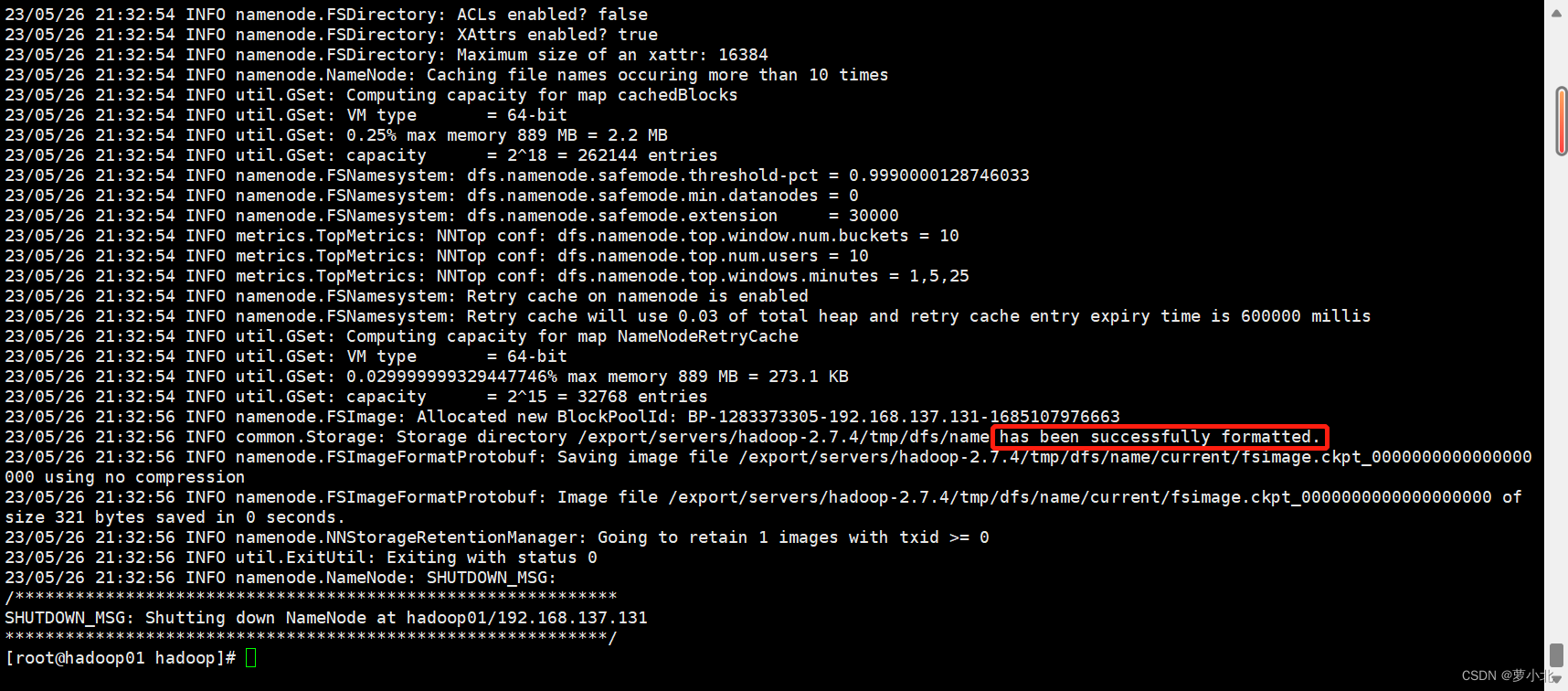
另外需要注意的是,上述格式化指令只需要在 Hadoop集群初次启动前执行即可,后续重复启动就不再需要执行格式化了。
七、Hadoop集群测试
1、启动集群
1.1 在主节点启动所有HDFS服务进程


上述使用脚本一键启动的方式,先启动了集群所有的HDFS服务进程,然后再启动了所有的 YARN服务进程,这就完成了整个Hadoop集群服务的启动。
1.2 使用jps命令查看进程
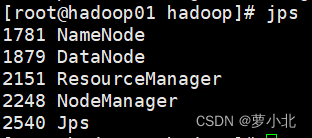
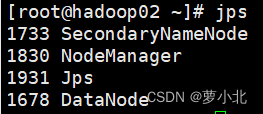
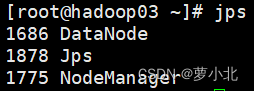
2、关闭防火墙(所有虚拟机都要操作)
遇到的问题:

解决方法:
换用新的命令执行:
systemctl disable firewalld.service



查看防火墙状态,显示操作成功:



3、通过UI界面查看Hadoop运行状态
Hadoop集群正常启动后,它默认开放了50070和8088两个端口,分别用于监控 HDFS集群和YARN集群。通过UI可以方便地进行集群的管理和查看,只需要在本地操作系统的浏览器输入集群服务的IP和对应的端口号即可访问。
在Windows系统下,访问192.168.137.131:50070,查看HDFS集群状态:

在Windows系统下,访问192.168.137.131:8088,查看Yarn集群状态:

4、查看java版本

5、查看hadoop版本
 八、Hadoop集群案例
八、Hadoop集群案例
通过Hadoop经典案例——单词统计,来演示 Hadoop集群的简单使用。
打开 HDFS的UI,选择【Utilities】→【Browse the file system】查看分布式文件系统里的数据文件,可以看到新建的HDFS上没有任何数据文件。

先在集群主节点hadoop01 上的/export/data/目录下,使用“vi word. txt”指令新建一个word.txt文本文件,并编写一些单词内容。


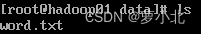
接着,在HDFS上创建/wordcount/input目录,并将word. txt文件上传至该目录下,表示单词统计源文件所在的目录:
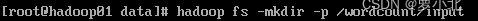
返回HDFS查看是否创建成功:
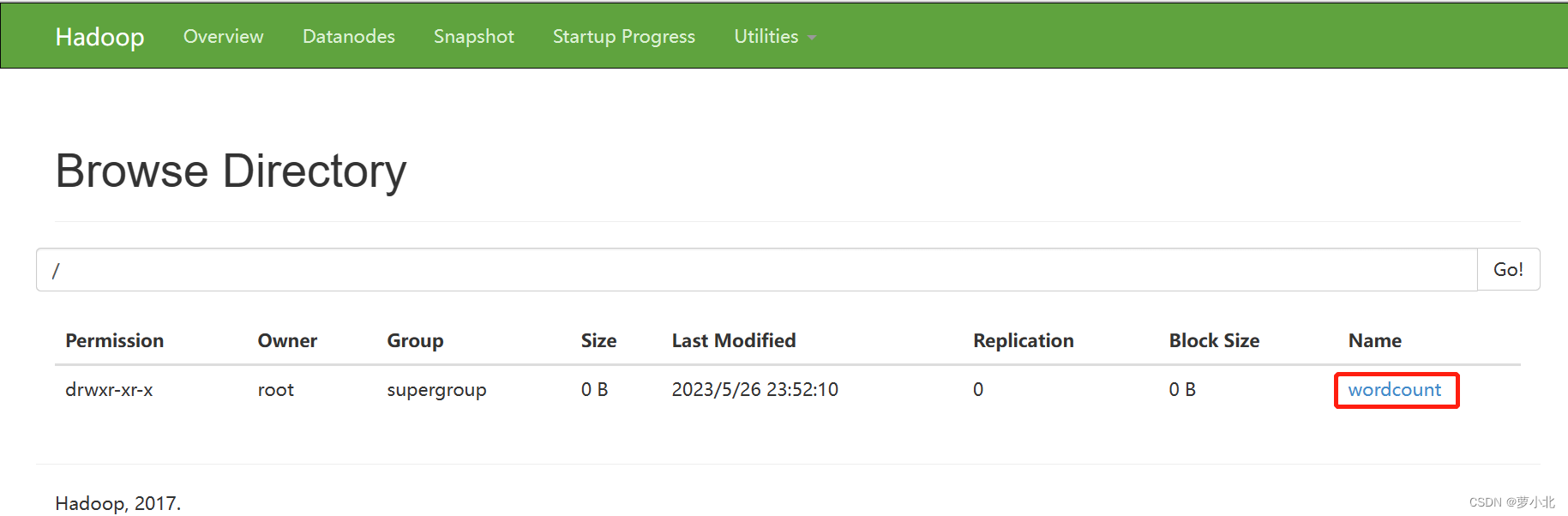
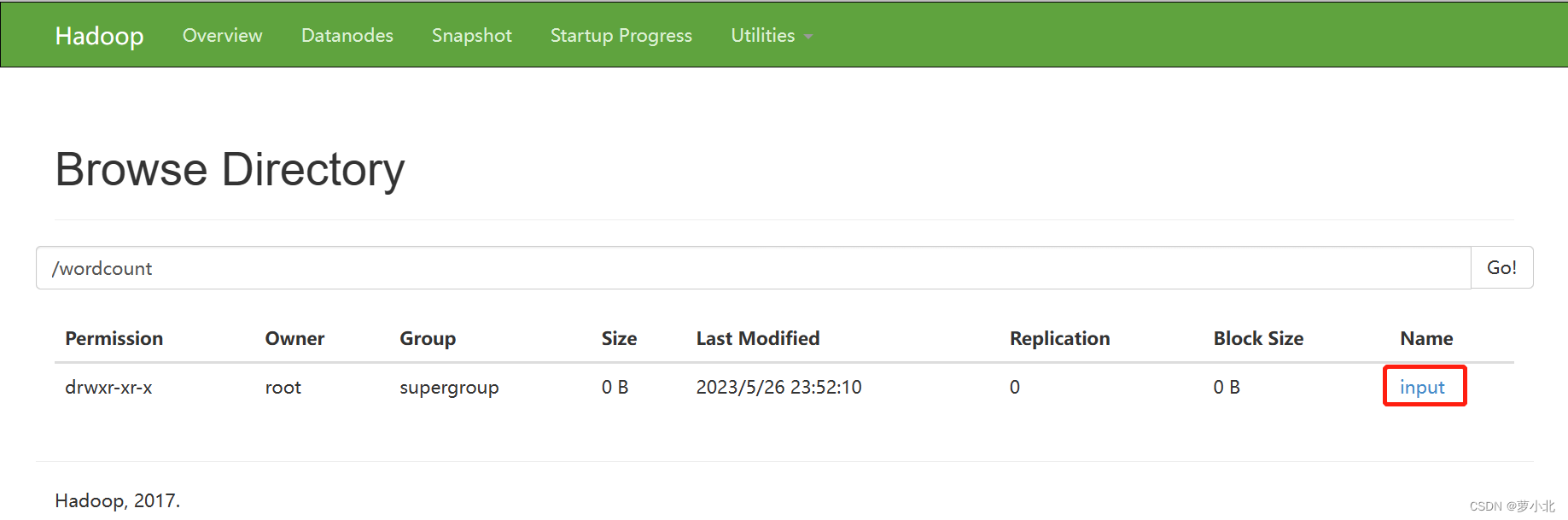
接下来,把word.txt文件从本地上传到input目录下:
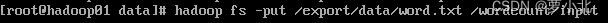
返回HDFS查看是否上传成功:
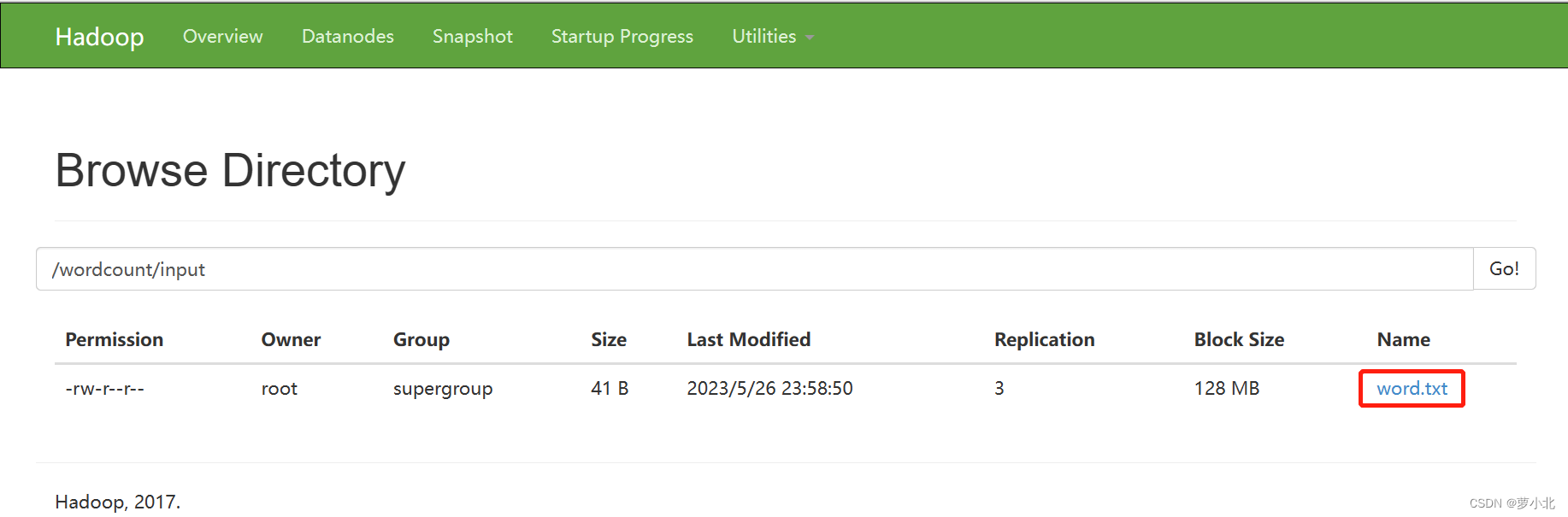
运行jar包,实现词频统计:
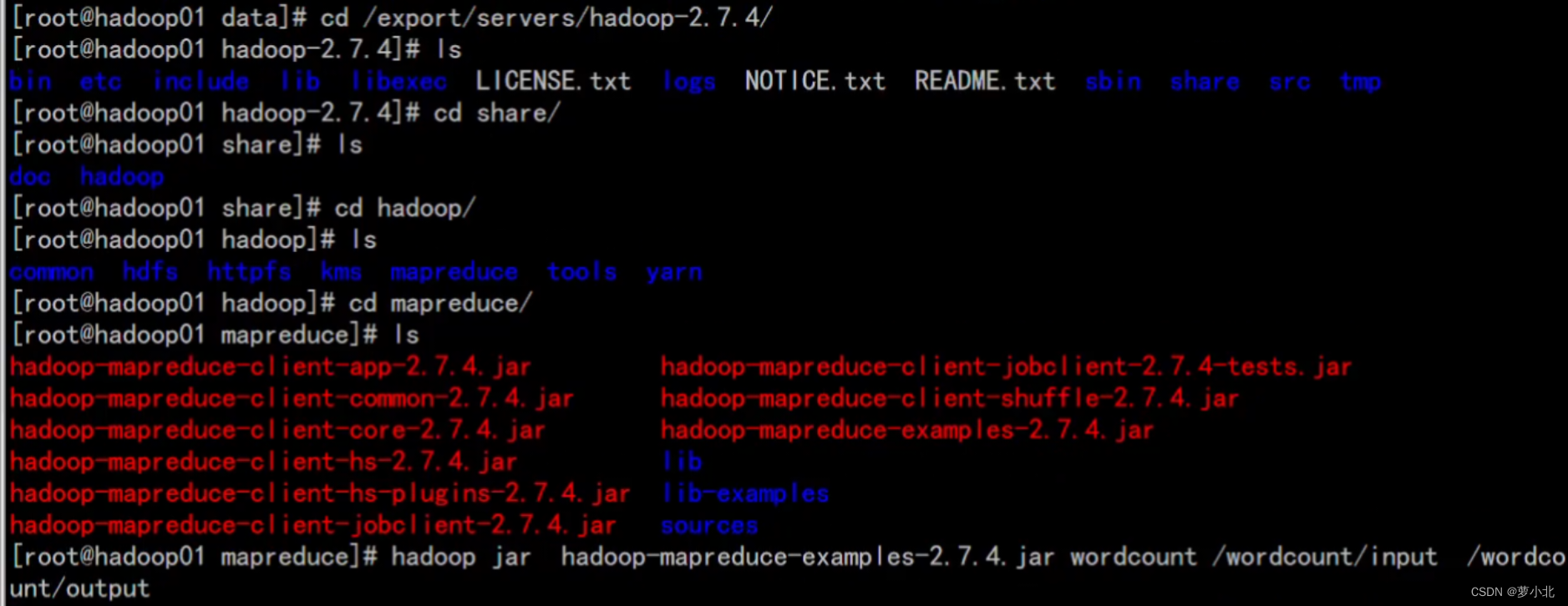
正在运行:
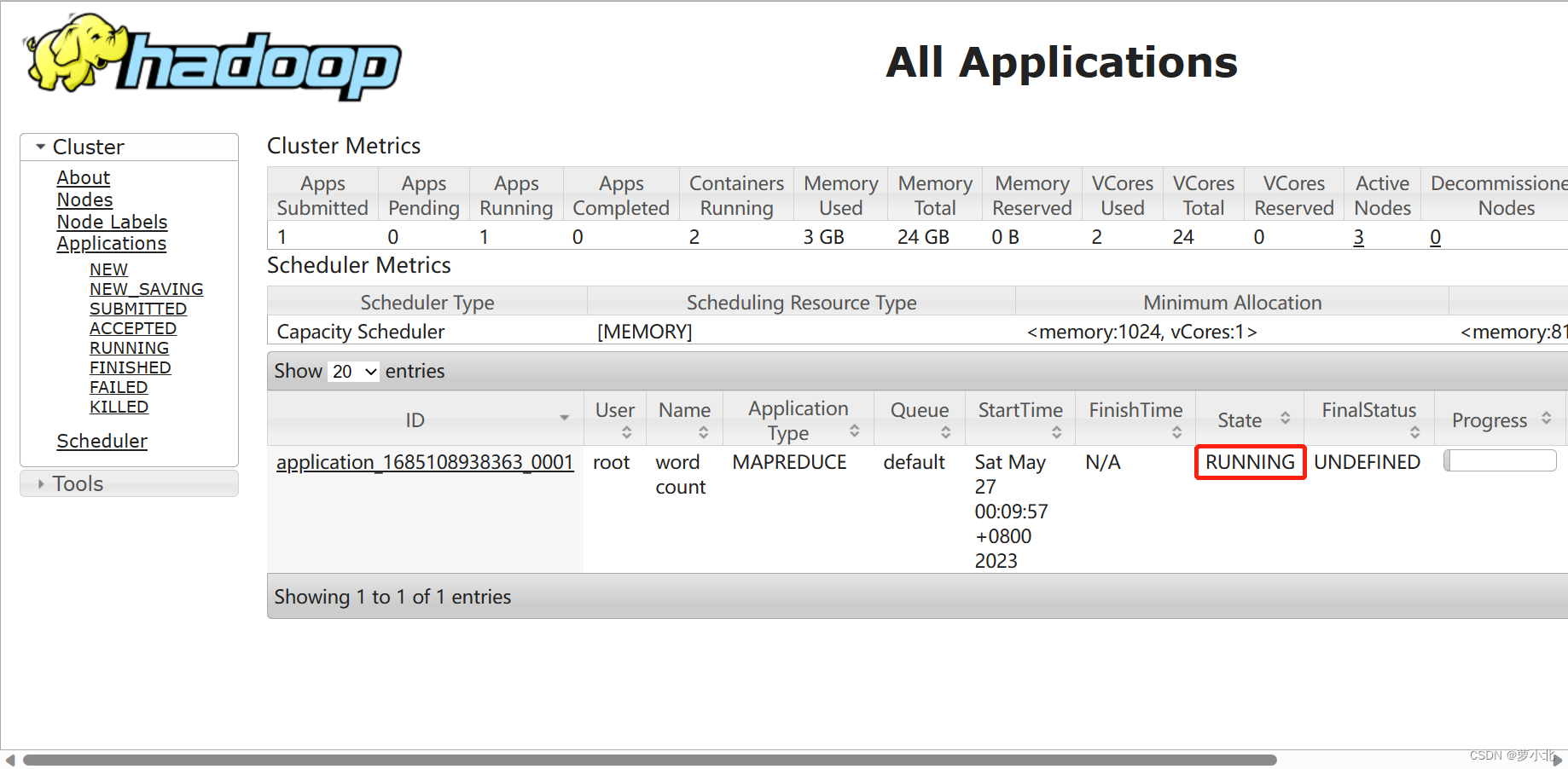
上传完成:

查看输出目录下的文件,是否完成单词统计:

在C:\ Windows\System32\drivers\etc中添加集群服务的IP映射:
单词统计结果,显示成功:
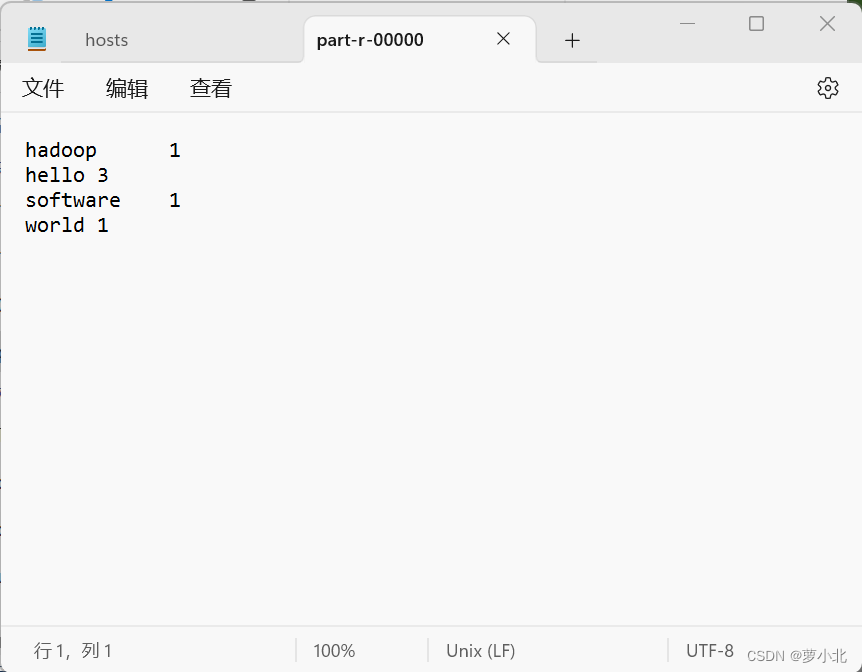
综上所述,Hadoop集群搭建成功。
本文转载自: https://blog.csdn.net/qq_51941741/article/details/131452002
版权归原作者 萝小北 所有, 如有侵权,请联系我们删除。
版权归原作者 萝小北 所有, 如有侵权,请联系我们删除。