
初识Spark
1.Spark概述:
Spark是一种快速、通用、可扩展的大数据分析引擎,项目是用Scala进行编写。目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLib、SparkR等子项目,Spark是基于内存计算的大数据并行计算框架。除了扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理。Spark 适用于各种各样原先需要多种不同的分布式平台的场景,包括批处理、迭代算法、交互式查询、流处理。通过在一个统一的框架下支持这些不同的计算,Spark 使我们可以简单而低耗地把各种处理流程整合在一起。而这样的组合,在实际的数据分析 过程中是很有意义的。不仅如此,Spark 的这种特性还大大减轻了原先需要对各种平台分 别管理的负担
2.spark的特点
1)快速
Spark支持内存计算,Spark在内存中的运行速度是Hadoop MapReduce运行速度的100多倍,Spark在磁盘上的运行速度是Hadoop MapReduce运行速度的10多倍
2)易用
Spark支持使用Scala,Python,Java,R等语言的快速编写应用
3)通用
Spark可以与SQL语句,实时计算及其他复杂的分析计算进行良好的结合
4)随处运行
Spark可以在数据源中读取数据
5)代码简洁
Spark支持使用Scala,Python等语言编写代码
3、mapreduce的运行框架
1、Map 框架解释
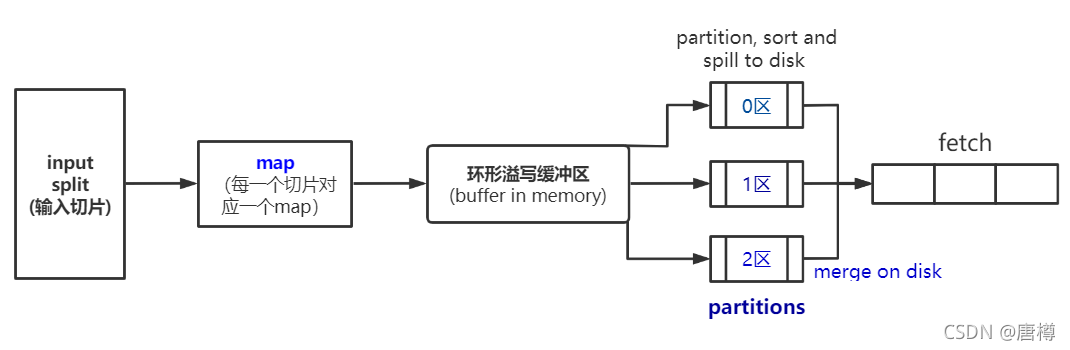
首先根据分片大小划分文件块,即输入切片(InputSplit);交给map处理,每一个切片对应一个map;map输出的数据,放入环形溢写缓冲区(默认100M,达到80M进行溢写,写入到本地文件)
2、Reduce 框架解释
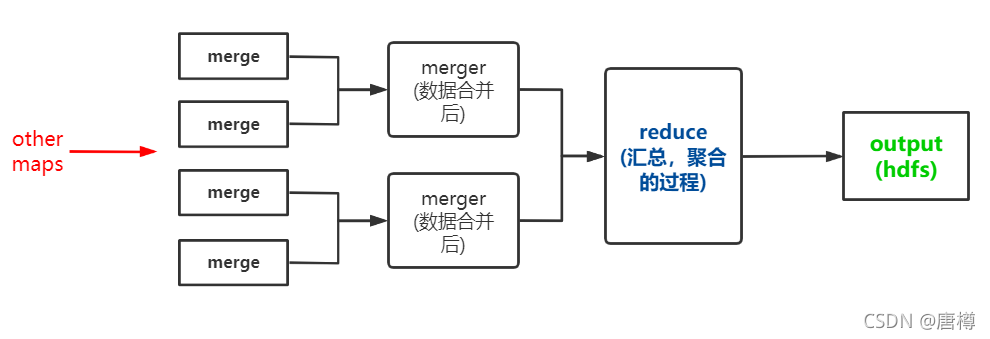
4、mapreduce与spark对比
MR只能做离线计算,如果实现复杂计算逻辑,一个MR搞不定,就需要将多个MR按照先后顺序连成一串,一个MR计算完成后会将计算结果写入到HDFS中,下一个MR将上一个MR的输出作为输入,这样就要频繁读写HDFS,网络IO和磁盘IO会成为性能瓶颈。从而导致效率低下。
spark既可以做离线计算,有可以做实时计算,提供了抽象的数据集(RDD、Dataset、DataFrame、DStream)有高度封装的API,算子丰富,并且使用了更先进的DAG有向无环图调度思想,可以对执行计划优化后在执行,并且可以数据可以cache到内存中进行复用
4、介绍hadoop生态圈
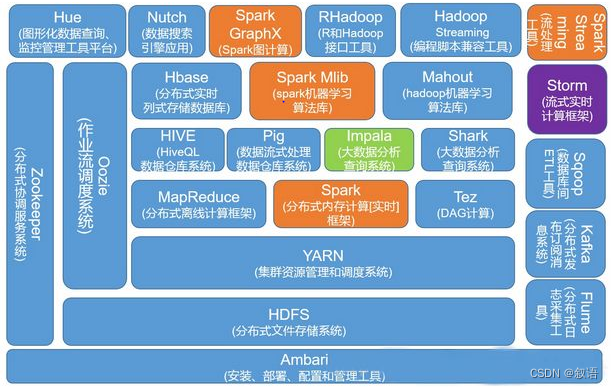
需要说明的是,上图并没有包括当前生态圈中的所有组件。而且hadoop生态圈技术在不断的发展,会不断有新的组件出现,一些老的组件也可能被新的组件替代。需要持续关注Hadoop开源社区的技术发展才能跟得上变化
5、Linux操作系统的使用
pwd 命令
ls 命令

cd 命令

mkdir 命令

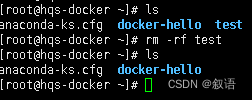
rm 命令
cp 命令

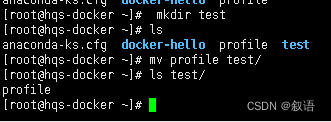
mv 命令
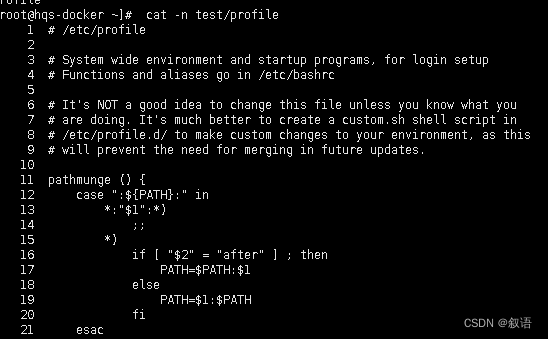
cat 命令
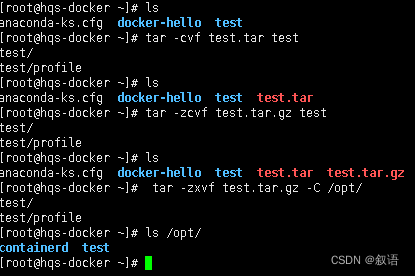
tar 命令
useradd 命令

passwd 命令
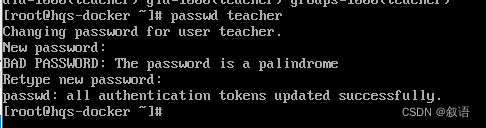
chown 命令
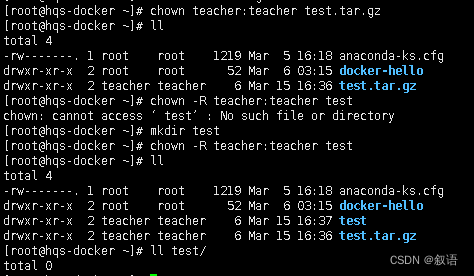
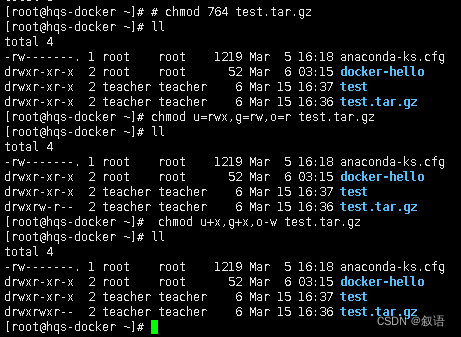
chmod 命令
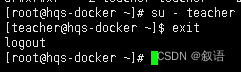
su 命令
文本操作
步骤一:命令模式

步骤二:输入模式

步骤三:末行模式

clear 命令
hostname 命令

ip 命令


systemctl 命令

reboot 命令
重新启动计算机
poweroff 命令
关闭计算机操作系统并且切断系统电源
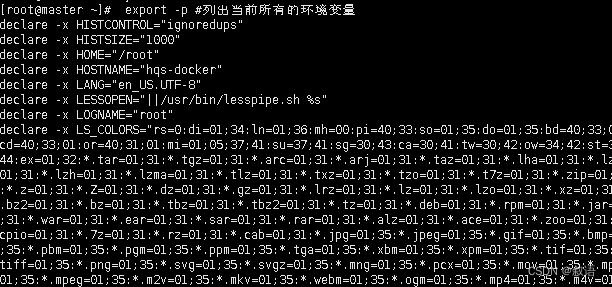
export 命令

echo 命令

source 命令

6、结构化数据和非结构化数据
结构化数据:即行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据。
非结构化数据:不方便用数据库二维逻辑表来表现的数据,包括所有格式的办公文档、文本、图片、XML、HTML、各类报表、图像和音频/视频信息等等。
7、冷备,热备和温备
热备(在线备份):在数据库运行时直接备份,对数据库操作没有任何影响。
冷备(离线备份):在数据库停止时进行备份。
温备:在数据库运行时加全局读锁备份,保证了备份数据的一致性,但对性能有影响
8、HDFS简介:
HDFS(Hadoop Distributed File System,Hadoop分布式文件系统),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
2、HDFS优缺点
优点:
HDFS的使用场景:适合一次写入,多次读取的场景。
(1)高容错性,自动保存多个副本,即使多个副本不可用,仍可以通过可用副本恢复;
(2)适合处理大数据,适合处理GB,TB甚至PB级别的数据;
(3)成本可控,可构建在廉价的机器上,通过多副本确保可靠性
缺点:
(1)不适合低延时数据访问,比如毫秒级的存储数据,是做不到的。
(2)无法高效的对大量小文件进行存储,因为NameNode的内存总是有限的
(3)不支持并发写入
(4)仅支持数据的追加,不支持数据的修改,适合一次写入,多次读取的操作
版权归原作者 叙语 所有, 如有侵权,请联系我们删除。