
HBase是一个基于Hadoop的分布式列式数据库,可以存储海量的结构化和半结构化数据。本文介绍如何在三个Ubuntu系统上搭建一个HBase集群,并进行简单的数据操作。
在三个Ubuntu系统上分布式安装配置HBase-2.3.7,主要步骤包括:
- 准备工作:下载安装包,设置环境变量,解压安装包。
- 安装配置HBase:编辑配置文件,指定分布式模式,数据目录,Zookeeper地址,RegionServer列表,分发安装包。
- 启动HBase集群:启动服务,查看状态,使用客户端连接。
一、准备工作
首先确保已经安装配置好Hadoop和Zookeeper,并且可以正常运行。本文假设已经按照之前文章的步骤搭建了一个三节点的Hadoop集群和一个三节点的Zookeeper集群,它们的IP地址和主机名分别如下:
IP地址主机名192.168.1.100hadoop100192.168.1.200hadoop200192.168.1.201hadoop201然后官网下载HBase-2.3.7的安装包
接着在hadoop100上将下载的安装包放到桌面,然后解压到/usr/local/hbase目录下,例如:
tar zxvf ~/Desktop/hbase-2.3.7-bin.tar.gz -C /usr/local
mv /usr/local/hbase-2.3.7 /usr/local/hbase
- 最后在hadoop100上设置HBASE_HOME环境变量,可以在/etc/profile文件中添加如下内容:
export HBASE_HOME=/usr/local/hbase
export PATH=$PATH:$HBASE_HOME/bin
然后执行
source /etc/profile
命令使配置生效。
二、安装配置HBase
- 在hadoop100上编辑$HBASE_HOME/conf/hbase-env.sh文件,取消以下几行的注释,并修改其中内容:
export JAVA_HOME=/usr/local/java/jdk1.8.0_341 # 根据实际的JAVA_HOME路径修改
export HBASE_MANAGES_ZK=false # 设置为false,表示使用外部的Zookeeper集群
export HBASE_CLASSPATH=/usr/local/hadoop/hadoop-3.2.4/etc/hadoop # 添加Hadoop的配置文件路径
export LD_LIBRARY_PATH=/usr/local/hadoop/hadoop-3.2.4/lib/native
如果报错:HADOOP_ORG.APACHE.HADOOP.HBASE.UTIL.GETJAVAPROPERTY_OPTS: invalid variable name
##修改配置文件最后一项配置,取消注释
# Tell HBase whether it should include Hadoop's lib when start up,
# the default value is false,means that includes Hadoop's lib.
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true"
- 在hadoop100上编辑$HBASE_HOME/conf/hbase-site.xml文件,添加以下内容:
<configuration>
<property>
<!-- 指定HBase在分布式模式下运行 -->
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 临时文件存储位置 -->
<property>
<name>hbase.tmp.dir</name>
<value>/home/c914/hbasetsst/tmp</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<!-- 指定Zookeeper集群的地址和端口 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop100,hadoop200,hadoop201</value>
</property>
<!-- 配置hbase存储位置,根据自己的hadoop集群配置端口 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop100:9000/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/hbase/zk</value>
</property>
</configuration>
注意,这里的hbase.rootdir的值要和Hadoop配置中core-site.xml里fs.defaultFS的值一致,而hbase.zookeeper.quorum的值要和Zookeeper配置中zoo.cfg里server.x的值一致。
- 在hadoop100上编辑$HBASE_HOME/conf/regionservers文件,添加以下内容:
hadoop100
hadoop200
hadoop201
这里指定了三个节点都作为HBase的RegionServer,负责存储数据。
- 在hadoop100上将配置好的HBase安装包分发到其他两个节点上,例如:
scp -r /usr/local/hbase/ c914@hadoop200:/usr/local/
scp -r /usr/local/hbase/ c914@hadoop201:/usr/local/
这里假设已经在三个节点上配置了免密登录,否则需要输入密码。
三、启动HBase集群
启动顺序是 先启动hadoop ==> 再启动zookeeper ==> 最后启动hbase。
关闭的顺序是 先关闭hbase ==> 再关闭zookeeper ==> 最后关闭hadoop。
- 在主节点hadoop100上执行如下命令启动HBase集群:
start-hbase.sh
- 在任意一个节点上执行如下命令查看HBase集群的状态:
jps
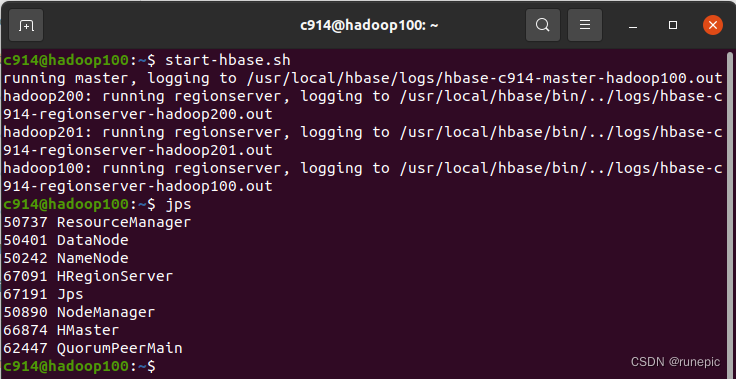
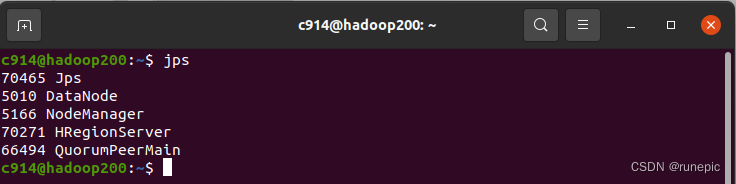
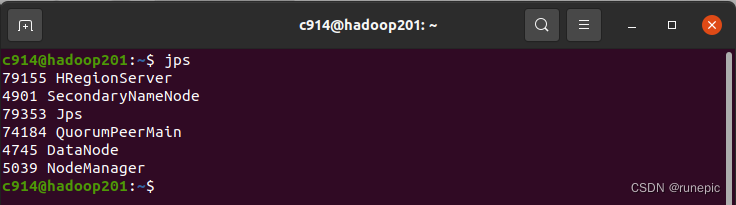
如果输出中显示了HMaster和HRegionServer进程,说明该节点已经加入到集群中。
- 在任意一个节点上执行如下命令使用命令行客户端连接到HBase集群:
hbase shell
如果连接成功,会进入一个交互式的shell环境,可以输入一些命令来操作HBase,例如:
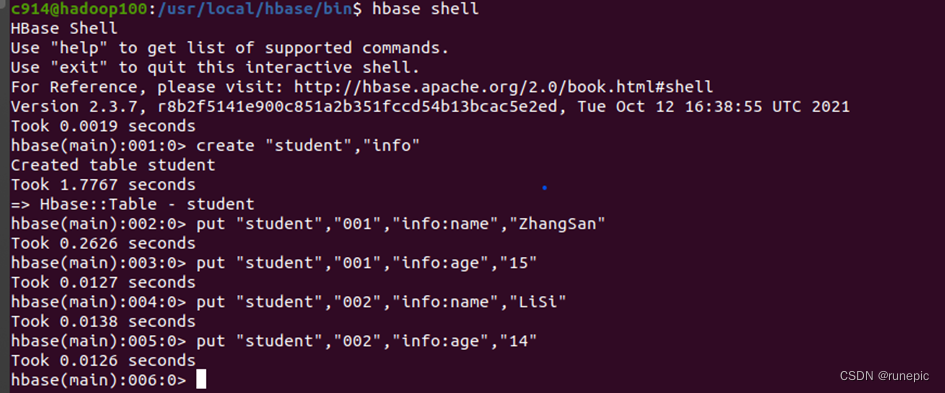
管理界面
如果上述结果都输出成功,就可以到浏览器中查看网页:
主节点IP地址:16010/
版权归原作者 runepic 所有, 如有侵权,请联系我们删除。