
通过Java操作Kafka
前置知识:https://editor.csdn.net/md/?articleId=125883056
创建maven项目
导入kafka客户端依赖:
<dependencies><!--导入kafka客户端依赖--><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.4.1</version></dependency></dependencies>
1 Java客户端,生产者的实现
1.1 生产者的基本实现
entity:
publicclassOrder{privatelong id;privateint count;publiclonggetId(){return id;}publicvoidsetId(long id){this.id = id;}publicintgetCount(){return count;}publicvoidsetCount(int count){this.count = count;}}
producer:
//消息发送方publicclassMyProducer{//主题名称privatefinalstaticStringTOPIC_NAME="my-replicated-topic";publicstaticvoidmain(String[] args)throwsExecutionException,InterruptedException{//1. 设置参数Properties props =newProperties();//指定服务器配置【ip:端口】
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.145.13:9092, 192.168.145.13:9093, 192.168.145.13:9094");//把发送的key从字符串序列化为字节数组
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());//把发送消息的value从字符串序列化为字节数组
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());//2. 创建生产消息的客户端,传入参数Producer<String,String> producer =newKafkaProducer<String,String>(props);//3. 创建消息;key:作用是决定了往哪个分区上发,value:具体要发送的消息内容ProducerRecord<String,String> producerRecord =newProducerRecord<>(TOPIC_NAME,"myKeyValue","helloKafka");//4. 发送消息,得到消息发送的元数据并输出RecordMetadata metadata = producer.send(producerRecord).get();System.out.println("同步方式发送消息结果:"+"topic-"+ metadata.topic()+"|partition-"+ metadata.partition()+"|offset-"+ metadata.offset());}}
上面配置的服务器地址为远程之前创建好的kafka集群,
如有不了解的,参考:https://editor.csdn.net/md/?articleId=125883056
发送结果:
同步方式发送消息结果:topic-my-replicated-topic|partition-1|offset-3
1.2 发送同步消息
//3. 创建消息;key:作用是决定了往哪个分区上发,value:具体要发送的消息内容// ProducerRecord<String, String> producerRecord = new ProducerRecord<>(// TOPIC_NAME,"myKeyValue", "helloKafka");//指定partition分区为0ProducerRecord<String,String> producerRecord =newProducerRecord<>(TOPIC_NAME,0,"myKeyValue","helloKafka");//4. 同步发送消息,得到消息发送的元数据并输出RecordMetadata metadata = producer.send(producerRecord).get();System.out.println("同步方式发送消息结果:"+"topic-"+ metadata.topic()+"|partition-"+ metadata.partition()+"|offset-"+ metadata.offset());
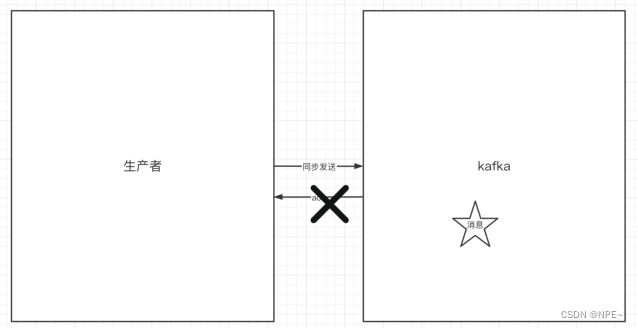
如果生产者发送消息没有收到ack,生产者会阻塞,阻塞到3s的时间,如果还没有收到消息,会进行重试。重试的次数为3次。
1.3 发送异步消息
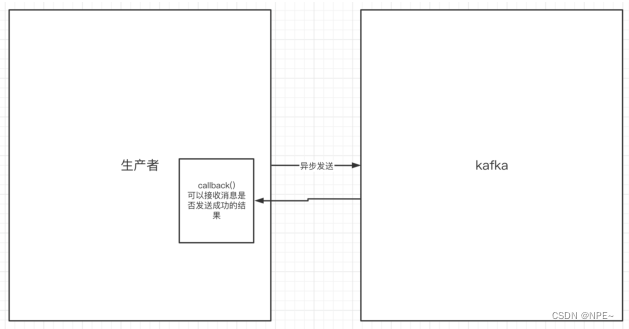
异步发送,生产者发送完消息后就可以执行之后的业务,broker在收到消息后异步调用生产者提供的callback回调方法。
...//5. 异步发送消息
producer.send(producerRecord,newCallback(){@OverridepublicvoidonCompletion(RecordMetadata metadata,Exception exception){if(exception !=null){System.out.println("发送消息失败:"+ exception.getStackTrace());}if(metadata !=null){System.out.println("异步方式发送消息结果:"+"topic-"+
metadata.topic()+"|partition-"+
metadata.partition()+"|offset-"+ metadata.offset());}}});Thread.sleep(100000000L);//为了方便观察打印结果...
结果:
异步方式发送消息结果:topic-my-replicated-topic|partition-0|offset-2
- 同步异步区别:
同步是发送消息完成之后,需要等待对方响应之后才能继续干其他的;异步则是,发送完消息之后,就可以继续往下执行业务逻辑。
上述代码的Callback()为回调方法,如果发送成功,会返回metadata,同时exception为null;反之。
- 让主线程睡眠是因为,发送消息之后,kafka会回调我们的方法,如果我们不睡眠的话,程序会继续往下执行,kafka还没来得及调用Callback回调方法,main线程就已经执行完了。
1.4 生产者中ack的配置
在同步发送的前提下,生产者在获得集群返回的ack之前那会一直阻塞。那么集群什么时候返回ack呢?此时ack有3个配置:
- ack=0,kafka-cluster不需要任何的broker收到消息,就立即返回ack给生产者,最容易丢消息,但是效率是最高的
- ack=1(默认):多副本之间得leader已经收到消息,并把消息写入到本地log中,才会返回ack给生产者,性能和安全是最均衡的。
- ack=-1/all。里面有默认的配置min.insync.replicas=2(默认为1,推荐配置大于等于2),此时就需要leader和一个follower同步完成之后,才会返回ack给生产者(此时集群中有2个broker已完成数据的接收),这种方式最安全,但性能最差。
 下面是关于ack和重试(如果没有收到ack,就开启重试)的配置:
下面是关于ack和重试(如果没有收到ack,就开启重试)的配置:
/*
发送失败会重试,默认重试时间间隔100ms,重试能保证消息发送的可靠性,但是也可能造成消息重复发送,比如:网络抖动,
所以需要在接收者那边做好消息接收的幂等性处理
*///重试次数设置
props.put(ProducerConfig.RETRIES_CONFIG,3);//重试间隔设置
props.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG,300);
1.5 消息发送的缓冲区
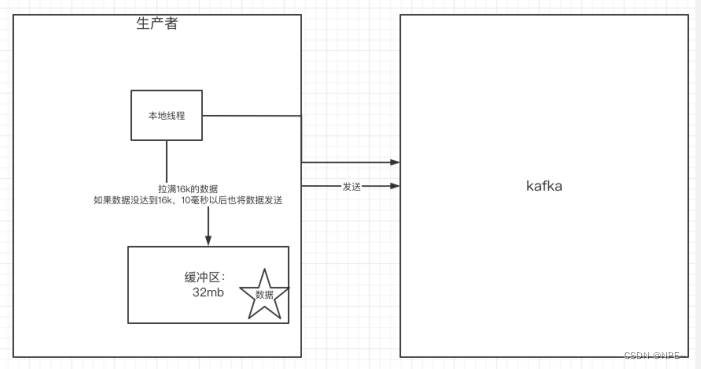
- Kafka默认会创建一个消息缓冲区,用来存放要发送的消息,缓冲区是32MB
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432);
- Kafka本地线程会去缓冲区拉一次16K的数据,发送到broker
props.put(ProducerConfig.BATCH_SIZE_CONFIG,16384);
- 如果拉不到16K的数据,间隔10ms也会将已拉到的数据发送到broker
props.put(ProducerConfig.LINGER_MS_CONFIG,10);
2 Java客户端,消费者的实现
首先在linux上搭建kafka集群,并创建对应主题与分区
./kafka-topics.sh --create--zookeeper localhost:2181 --replication-factor 3--partitions2--topic my-replicated-topic
2.1 消费者的简单实现
publicclassMySimpleConsumer{privatefinalstaticStringTOPIC_NAME="my-replicated-topic";privatefinalstaticStringCONSUMER_GROUP_NAME="testGroup";publicstaticvoidmain(String[] args){//设置配置Properties props =newProperties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.145.13:9092, 192.168.145.13:9093, 192.168.145.13:9094");//消费分组名、key序列化、value序列化
props.put(ConsumerConfig.GROUP_ID_CONFIG,CONSUMER_GROUP_NAME);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());//1. 创建一个消费者客户端(设置配置文件)KafkaConsumer<String,String> consumer =newKafkaConsumer<String,String>(props);//2. 消费者订阅主题列表
consumer.subscribe(Arrays.asList(TOPIC_NAME));while(true){//3. poll() API是拉取消息的长轮询ConsumerRecords<String,String> records =
consumer.poll(Duration.ofMillis(1000));for(ConsumerRecord<String,String> record : records){//4. 打印消息System.out.printf("收到消息:partition = %d, offset = %d, key = %s, value = %s%n",
record.partition(), record.offset(), record.key(), record.value());}}}}
通过上面创建的producer发送消息,查看控制台
收到消息:partition =0, offset =6, key = myKeyValue, value = helloKafka
2.2 消费者自动提交与手动提交offset
- 提交的内容 消费者无论是自动提交还是手动提交,都需要把所属的消费者组+消费的某个主题+消费的某个分区+消费的偏移量,这样的信息提交到集群的_consumer_offsets主题里面。
- 自动提交 消费者poll消息下来以后就会自动提交到offset
//是否自动提交offset,默认:true
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"true");//自动提交offset的间隔时间
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"1000");
注意:自动提交会丢消息。因为消费者在消费前提交offset,有可能提交完后还没有来得及消费消息,消费者就挂了。
- 手动提交 将自动提交的配置改为false
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false");
手动提交分为了两种:
- 手动同步提交 在消费完消费后调用同步提交的方法,当集群返回ack前一直阻塞,返回ack后表示提交成功,执行之后的逻辑。
while(true){/*
poll() API是拉取消息的长轮询
*/ConsumerRecords<String,String> records = consumer.poll(Duration.ofMillis(1000));for(ConsumerRecord<String,String> record : records){System.out.printf("收到消息:partition = %d, offset = %d, key = %s, value = %s%n",
record.partition(), record.offset(), record.key(), record.value());}//所有消息已经消费完if(records.count()>0){//有消息//手动同步提交offset,当前线程会阻塞,直到offset提交成功//一般使用同步提交,因为提交之后一般也没有什么逻辑代码了
consumer.commitSync();//=========阻塞==== 提交成功}}
- 手动异步提交 在消息消费完后提交,不需要等到集群ack,直接执行之后的逻辑,可以设置一个回调方法,供集群调用
while(true){/*
poll() API是拉取消息的长轮询
*/ConsumerRecords<String,String> records = consumer.poll(Duration.ofMillis(1000));for(ConsumerRecord<String,String> record : records){System.out.printf("收到消息:partition = %d, offset = %d, key = %s, value = %s%n",
record.partition(), record.offset(), record.key(), record.value());}//所有消息已经消费完if(records.count()>0){//有消息//手动异步提交offset,当前线程提交offset不会阻塞,可以继续处理后面的程序逻辑
consumer.commitAsync(newOffsetCommitCallback(){@OverridepublicvoidonComplete(Map<TopicPartition,OffsetAndMetadata> offsets,Exception e){if(e !=null){System.err.println("Commit failed for "+ offsets);System.err.println("Commit failed exception: "+ e.getStackTrace());}}});}}
2.3 长轮询poll消息
- 默认情况下,消费者一次会poll500条消息
//一次poll最大拉取消息的条数,可以根据消费速度的快慢来设置
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,500);
- 代码中设置了长轮询的时间是1000毫秒
while(true){/*
poll() API是拉取消息的长轮询
*///设置长轮询时间是1000msConsumerRecords<String,String> records = consumer.poll(Duration.ofMillis(1000));for(ConsumerRecord<String,String> record : records){System.out.printf("收到消息:partition = %d, offset = %d, key = %s, value = %s%n",
record.partition(), record.offset(), record.key(), record.value());}}
意味着:
- 如果一次poll到500条,直接执行for循环; 如果这一次没有poll到500条,且时间在1s内,要么长轮询继续poll,要么到500条,要么到1s; 如果多次poll都没达到500条,且1s时间到了,那么直接执行for循环
- 如果两次poll的间隔超过30s,集群会认为该消费者的消费能力过弱,该消费者被提出消费组,触发rebalance机制,rebalance机制会造成性能开销。可以通过设置这个参数,让一次poll的消息条数少一点。
//一次poll最大拉取消息的条数,可以根据消费速度的快慢来设置
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,500);//如果两次poll的时间超出了30s的时间间隔,kafka会认为其消费能力过弱,将其提出消费组。将分区分配给其他消费者。-rebalance
props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG,30*1000);
2.4 消费者的健康状态检查
消费者每隔1s向kafka集群发送心跳,集群发现如果有超过10s没有续约的消费者,将被踢出消费组,触发该消费组的rebalance机制,将该分区交给其他消费组里的其他消费者进行消费。
//consumer给broker发送⼼跳的间隔时间
props.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG,1000);//kafka如果超过10秒没有收到消费者的⼼跳,则会把消费者踢出消费组,//进⾏rebalance,把分区分配给其他消费者。
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG,10*1000)
2.5 指定分区和偏移量、时间消费
- 指定分区消费
//TOPIC_NAME主题下的0号分区
consumer.assign(Arrays.asList(newTopicPartition(TOPIC_NAME,0)));
- 从头消费
consumer.assign(Arrays.asList(newTopicPartition(TOPIC_NAME,0)));
consumer.seekToBeginning(Arrays.asList(newTopicPartition(TOPIC_NAME,0)));
- 指定offset消费
consumer.assign(Arrays.asList(newTopicPartition(TOPIC_NAME,0)));
consumer.seek(newTopicPartition(TOPIC_NAME,0),10);//offset=10
- 指定时间消费 根据时间,去所有的partition中确定该时间对应的offset,然后去所有的partition中找到该offset之后的消息开始消费
List<PartitionInfo> topicPartitions = consumer.partitionsFor(TOPIC_NAME);//从1⼩时前开始消费long fetchDataTime =newDate().getTime()-1000*60*60;Map<TopicPartition,Long> map =newHashMap<>();for(PartitionInfo par : topicPartitions){
map.put(newTopicPartition(TOPIC_NAME, par.partition()),
fetchDataTime);}Map<TopicPartition,OffsetAndTimestamp> parMap =
consumer.offsetsForTimes(map);for(Map.Entry<TopicPartition,OffsetAndTimestamp> entry :
parMap.entrySet()){TopicPartition key = entry.getKey();OffsetAndTimestamp value = entry.getValue();if(key ==null|| value ==null)continue;Long offset = value.offset();System.out.println("partition-"+ key.partition()+"|offset-"+ offset);System.out.println();//根据消费⾥的timestamp确定offsetif(value !=null){
consumer.assign(Arrays.asList(key));
consumer.seek(key, offset);}}
2.6 新消费组的消费offset规则
新消费组的消费者在启动以后,默认会从当前分区的最后一条消息的offset+1开始消费(消费新消息)。可以通过以下的设置,让新的消费者第一次从头开始消费。之后开始消费新消息(最后消费位置的偏移量+1)
- Latest:默认, 消费最新消息
- earliest:第一次从头开始消费,之后开始消费新消息(最后消费位置的偏移量+1)
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
版权归原作者 NPE~ 所有, 如有侵权,请联系我们删除。