
一 ack 应答机制
kafka 为用户提供了三种应答级别: all,leader,0
acks :0
这一操作提供了一个最低的延迟,partition的leader接收到消息还没有写入磁盘就已经返回ack,当leader故障时有可能丢失数据;
生产者发送完消息后不会等待到 broker 的任何确认消息,这种方式虽然效率提升但是它的可靠性大大降低;
acks:1(leader)
partition的leader落盘成功后返回ack,如果在follower同步成功之前leader故障,尽管 leader 已经落盘成功,但是 follower 的同步进度肯定是低于leader,这时故障,那么将会丢失 follower 还未同步 leader 那部分数据;
这种模式下,具有一定的可靠性和效率,但是依旧有丢失数据的可能性;

acks:-1(all)
partition的leader和follower全部落盘成功后才返回ack。但是如果在follower同步完成后,broker发送ack之前,leader发生故障,即选举出新的 leader,新的 leader 将再次落盘一次,那么会造成数据重复;
这种模式下,效率是最低的,但是数据可靠性则最高
java api 中相应参数
// 设置acks
properties.put(ProducerConfig.ACKS_CONFIG, "all");
// 重试次数retries,默认是int最大值,2147483647
properties.put(ProducerConfig.RETRIES_CONFIG, 3);
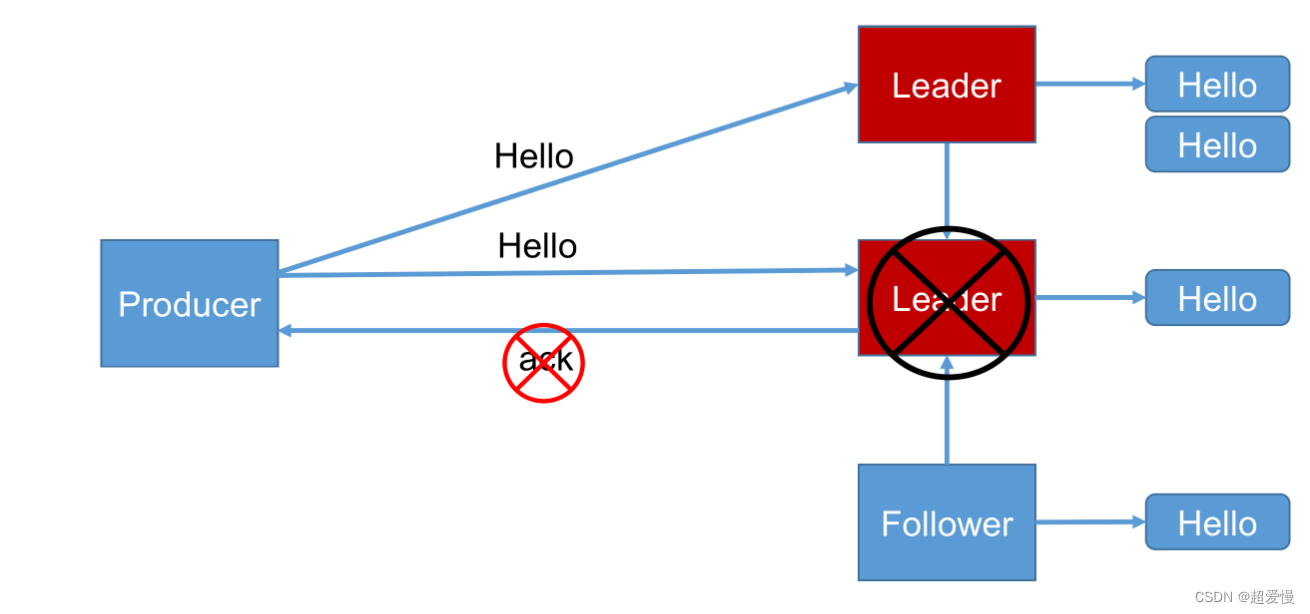
二 ISR 集合
ISR(in-sync replica) 就是 Kafka 为某个分区维护的一组同步集合,即每个分区都有自己的一个 ISR 集合,处于 ISR 集合中的副本,意味着 follower 副本与 leader 副本保持同步状态,只有处于 ISR 集合中的副本才有资格被选举为 leader。一条 Kafka 消息,只有被 ISR 中的副本都接收到,才被视为“已同步”状态。这跟 zk 的同步机制不一样,zk 只需要超过半数节点写入,就可被视为已写入成功。
想象如下场景
如果一个follower因为某种故障迟迟无法与leader 同步,那么如果选择 ack 为 all 的话,leader 要一直等待follower 同步完才发 ack 吗
显然不是,in-sync replica set (ISR),意为和leader保持同步的follower集合。当ISR中的follower完成数据的同步之后,leader就会给producer发送ack。如果follower长时间未向leader同步数据,则该follower将被踢出ISR,该时间阈值由**replica.lag.time.max.ms**参数设定。Leader发生故障之后,就会从ISR中选举新的leader。
被踢出 ISR 的 follower 在选举新的 leader 时不被考虑,待该follower恢复后,follower会读取本地磁盘记录的上次的HW,并将log文件高于HW的部分截取掉,从HW开始向leader进行同步。等该follower的LEO大于等于该Partition的HW,即follower追上leader之后,就可以重新加入ISR了。
同样的 leader 故障的话,会从ISR中选出一个新的leader,之后,为保证多个副本之间的数据一致性,其余的follower会先将各自的log文件高于HW的部分截掉,然后从新的leader同步数据。
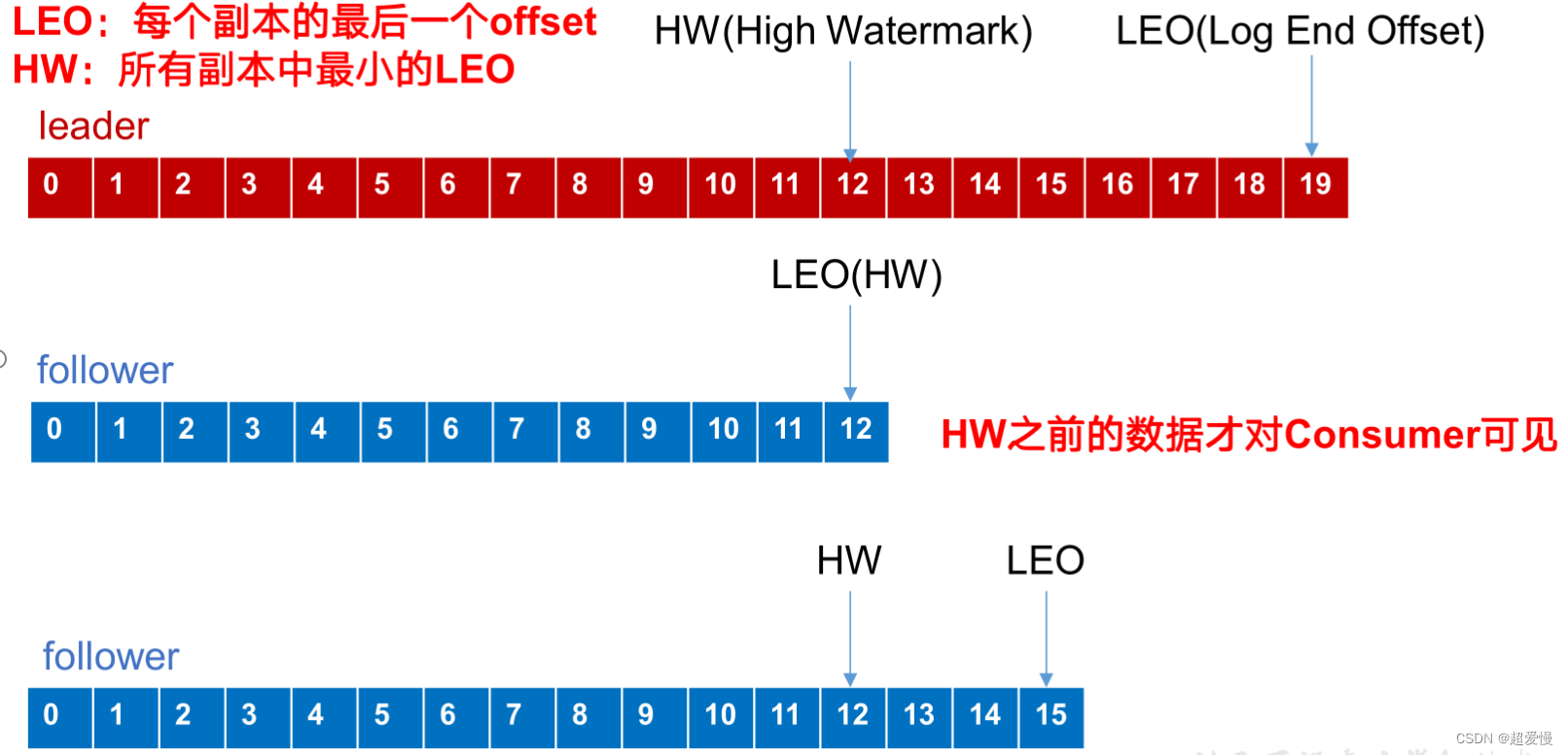
** LEO:指的是每个副本最大的offset;**
** HW:指的是消费者能见到的最大的offset,ISR队列中最小的LEO。**
本文转载自: https://blog.csdn.net/jojo_oulaoula/article/details/133042118
版权归原作者 超爱慢 所有, 如有侵权,请联系我们删除。
版权归原作者 超爱慢 所有, 如有侵权,请联系我们删除。