
spark简介官网 Apache Spark™ - Unified Engine for large-scale data analytics
Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发的通用内存并行计算框架Spark得到了众多大数据公司的支持,这些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。当前百度的Spark已应用于大搜索、直达号、百度大数据等业务;阿里利用GraphX构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾讯Spark集群达到8000台的规模,是当前已知的世界上最大的Spark集群。
Spark Core:实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed DataSet,简称RDD)的API定义。
Spark SQL:是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用
SQL或者Apache Hive版本的HQL来查询数据。Spark SQL支持多种数据源,比如Hive表、Parquet以及JSON等。
Spark Streaming:是Spark提供的对实时数据进行流式计算的组件。提供了用来操作数据流的API,并且与Spark Core中的 RDD API高度对应。
Spark MLlib:提供常见的机器学习功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。
Spark GraphX:主要用于图形并行计算和图挖掘系统的组件。
集群管理器:Spark设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark支持在各种集群管理器(Cluster Manager)上运行,包括Hadoop YARN、Apache Mesos,以及Spark自带的一个简易
调度器,叫作独立调度器。
spark特点
运行速度快:
与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。计算的中间结果是存在于内存中
易用性好:
Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的Shell,可以非常方便地在这些Shell中使用Spark集群来验证解决问题的方法
通用性强:
Spark提供了统一的解决方案。Spark可以用于,交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。减少了开发和维护的人力成本和部署平台的物力成本
高兼容性:
Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力
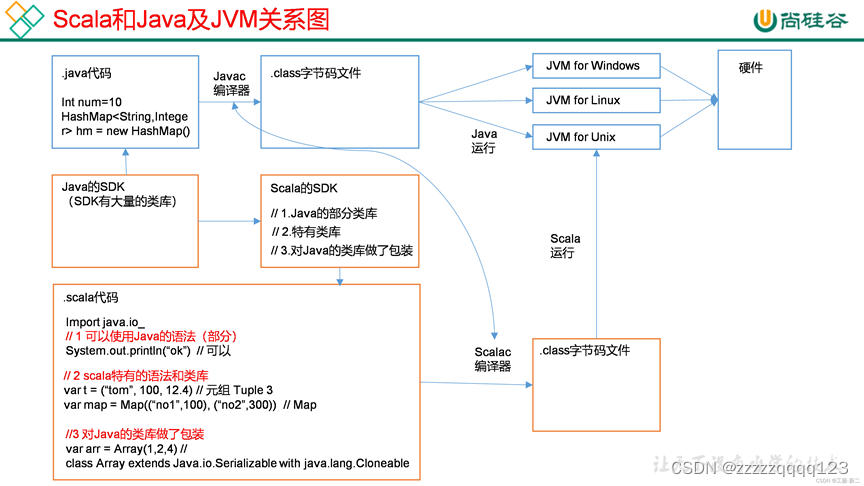
1.1 图解Scala和Java的关系
1.2 关键字说明
package: 包,等同于java中的package
object:关键字,声明一个单例对象(伴生对象)
main方法:从外部可以直接调用执行的方法
def 方法名称 ( 参数名称 : 参数类型 ) : 返回值类型 = { 方法体 }
Scala 完全面向对象,故scala去掉了Java中非面向对象的元素,如static关键字,void类型
- static
scala无static关键字,由object实现类似静态方法的功能(类名.方法名)
class关键字和Java中的class关键字作用相同,用来定义一个类
- void
对于无返回值的函数,scala定义其返回值类型为Unit类型
1.3 代码案例
package com.scala.chapter1
object Hello {
def main(args: Array[String]): Unit = {
println("hello scala")
System.out.println("hello scala")
}
}
1.4 Scala语言特点
Scala是一门以Java虚拟机 (JVM)为运行环境并将面向对象和函数式编程的最佳特性结合在一起的静态类型编程语言(静态语言需要提前编译的如: Java、C、C++等,动态语言如:JS)。
1)Scala是一门多范式的编程语言,Scala支持面向对象和函数式编程。 (多范式,就是多种编程方法的意思。有面向过程、面向对象、泛型、函数式四种程序设计方法。)
2)Scala源代码 (.scala) 会被编译成Java字节码 (.class),然后运行于JVM之上,并可以调用现有的Java类库,实现两种语言的无缝对接。
3)Scala单作为一门语言来看,非常的简洁高效
4)Scala在设计时,马丁·奥德斯基是参考了Java的设计思想,可以说Scala是源于Java,同时马丁·奥德斯基也加入了自己的思想,将函数式编程语言的特点融合到JAVA中,因此,对于学习过Java的同学,只要在学习Scala的过程中,搞清楚Scala和Java相同点和不同点,就可以快速的掌握Scala这门语言。
二、变量和数据类型
Any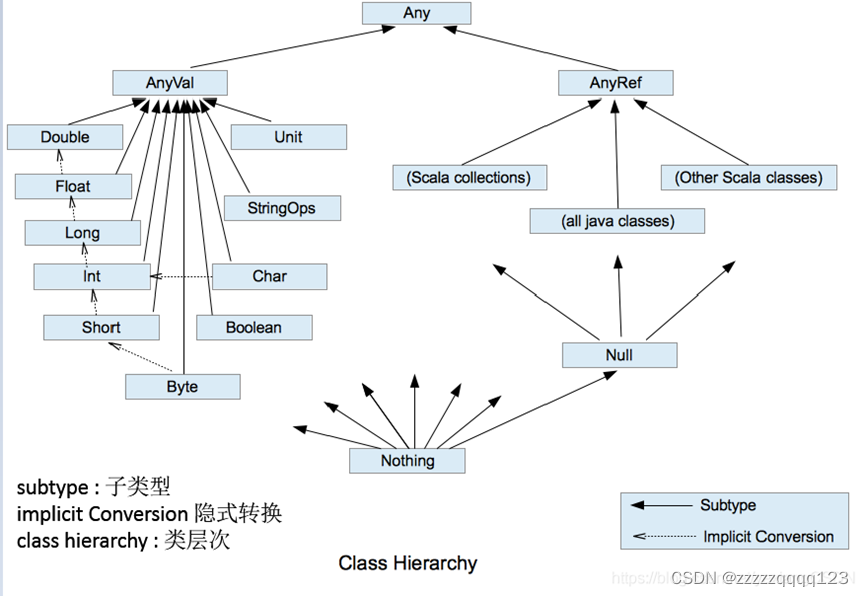 : 所有类型的超类(顶级类型)
: 所有类型的超类(顶级类型)
AnyVal: 值类型的超类
AnyRef: 引用类型的超类,对应java.lang.Object
Unit: 无值,类似java中的void
Nothing: 所有类型的子类
Null: 表示null或空引用
2.1 注释
Scala注释使用和Java完全一样。
注释是一个程序员必须要具有的良好编程习惯。将自己的思想通过注释先整理出来,再用代码去体现。
1****)基本语法
(1)单行注释://
(2)多行注释:/* */
(3)文档注释:/**
*
*/
3) 代码规范
(1)使用一次tab操作,实现缩进,默认整体向右边移动,用shift+tab整体向左移
(2)或者使用ctrl + alt + L来进行格式化
(3)运算符两边习惯性各加一个空格。比如:2 + 4 * 5
(4)一行最长不超过80个字符,超过的请使用换行展示,尽量保持格式优雅
2.2 变量和常量(重点)
常量:在程序执行的过程中,其值不会被改变的变量
1)基本语法
var 变量名 [: 变量类型] = 初始值 var i:Int = 10
val 常量名 [: 常量类型] = 初始值 val j:Int = 20
注意:能用常量的地方不用变量
2)案例实操
(1)声明变量时,类型可以省略,编译器自动推导,即类型推导
(2)类型确定后,就不能修改,说明Scala是强数据类型语言。
(3)变量声明时,必须要有初始值
(4)在声明/定义一个变量时,可以使用var或者val来修饰,var修饰的变量可改变,val修饰的变量不可改
版权归原作者 zzzzzqqqq123 所有, 如有侵权,请联系我们删除。