
Spark搭建日志
文章目录
本人在Centos中使用三个虚拟机(node1,node2,node3)搭建hadoop与Spark分布式环境(具体见后记中的Hadoop安装),本文记录一些踩过的坑
错误1:运行./start-all.sh时,遇到权限不够的情况
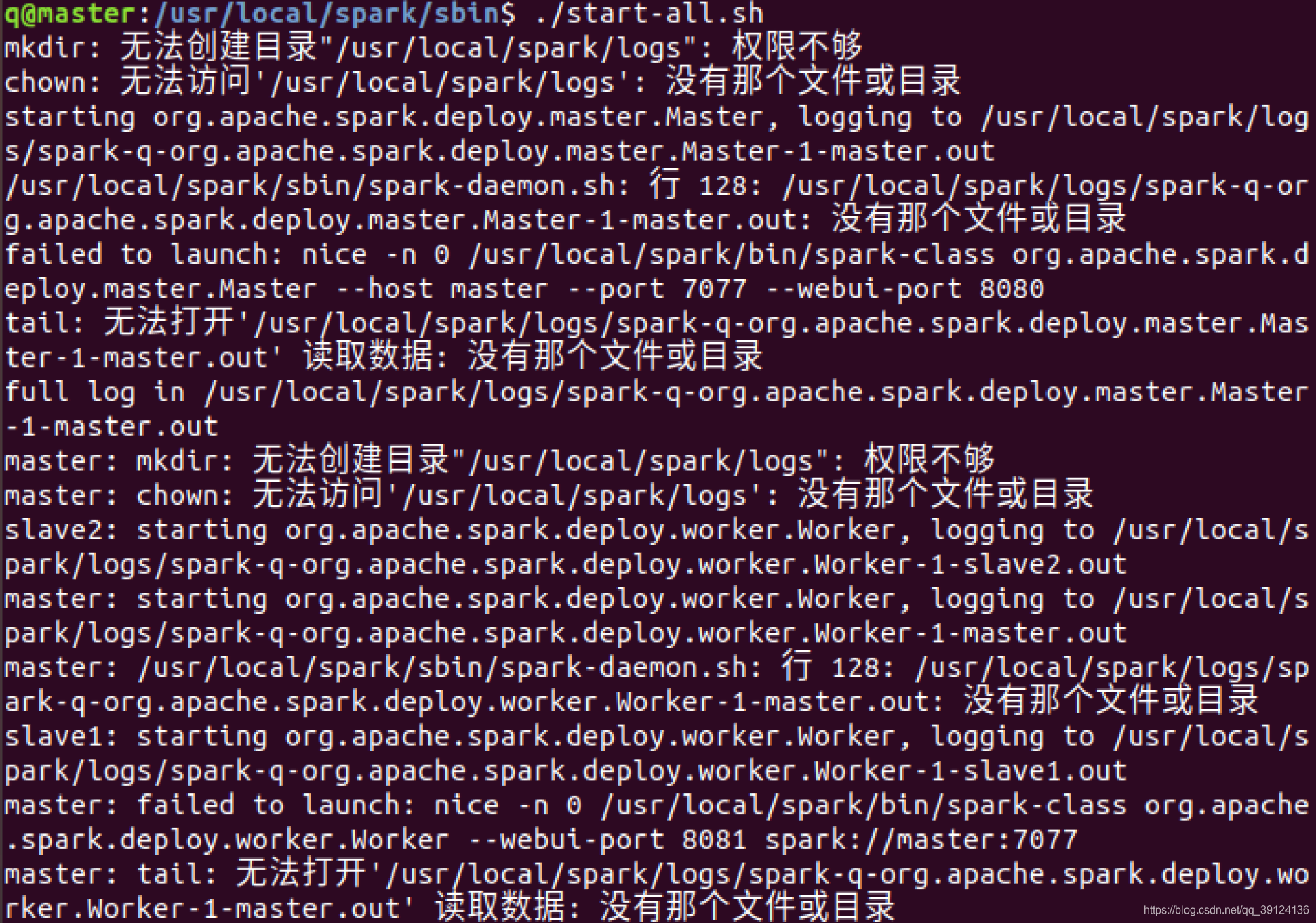
解决办法:sudo chown -R 用户名 /spark(spark或者hadoop所在目录)
原理:文件的初始所有者不是用户名(如root),要把spark目录的初始所有者更换为自己的用户名
错误2:spark运行./start-all.sh时出现Permission Denied错误
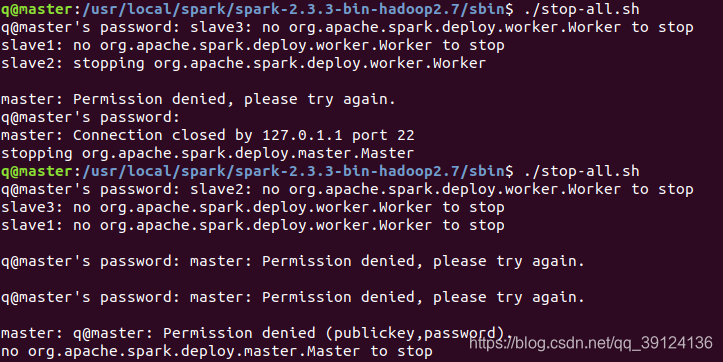
解决办法:重新进行三个节点的ssh免密登录:【精选】大数据Hadoop(一):集群搭建–Hadoop3.3.1、CentOS8、HDFS集群、YARN集群最新保姆级教程_centos8安装yarn_彭瑞琪的博客-CSDN博客
原理:要输入密码,但是一般怎么输入都不对(我也不知道问什么,留个坑),所以要重新进行ssh免密登录才行,避免输入密码
错误3:在root用户下,每次新建终端都要source一下配置文件profile的解决办法
解决办法:**在~/.bashrc文件里添加
source /etc/profile
命令**
[学习笔记]Centos7每次启动都要执行 source /etc/profile才能找到java路径_centos source-CSDN博客
这样每次启动终端都会自动source一下profile文件
原理:普通用户下没有问题,就是在root下出现问题,应该是root用户没有在全局变量中?
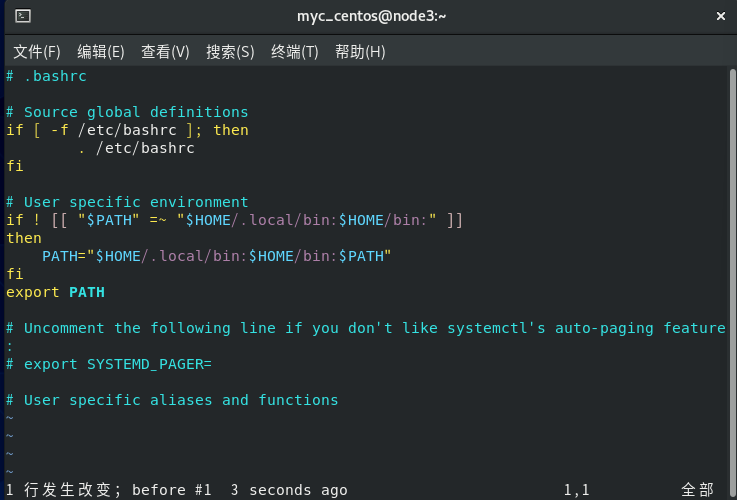
普通用户的~/.bashrc文件
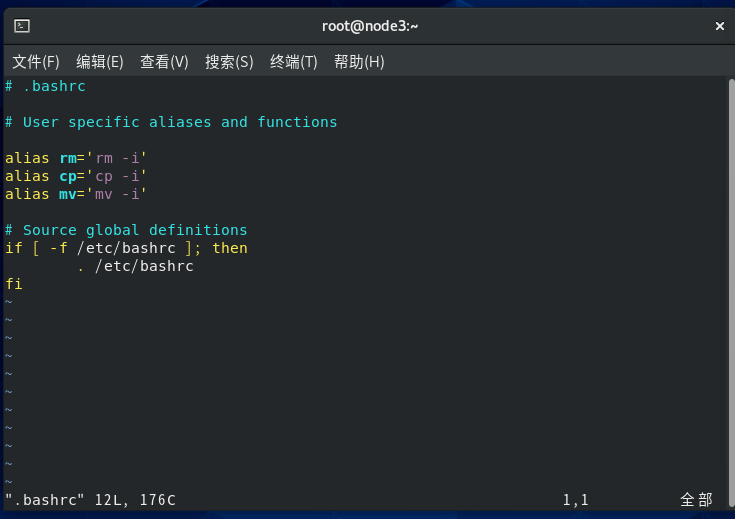
root用户的~/.bashrc文件
如果想设置打开终端后自动激活自己的环境,比如pyspark:只需在.bashrc里最后一行加上 conda activate pyspark即可
各个端口的含义
- spark://node1:7077
spark://node1:7077
是 Apache Spark 集群管理的地址。在这个地址中,
node1
是 Spark 集群的主节点(也称为 Spark Master),而
7077
是 Spark Master 的默认网络监听端口。
spark://:这是 Spark 集群的地址协议头。node1:这是 Spark Master 的主机名或 IP 地址,表示 Spark 集群的主节点。7077:这是 Spark Master 的默认网络监听端口。Spark Master 通过这个端口接收来自工作节点(Spark Worker)的连接以及管理整个 Spark 集群的资源分配和作业调度。
当你使用 Spark Standalone 集群管理模式时,你会在 Spark Master 上通过
spark://node1:7077
地址来连接到集群并提交 Spark 应用程序。这允许你将作业调度到 Spark 集群,管理资源分配以及监视应用程序的运行状态。
请注意,
7077
是默认端口号,你可以在 Spark Master 的配置中更改这个端口号,但在大多数情况下,使用默认端口即可。如果你的 Spark Master 运行在其他端口上,你需要相应地更改地址。
- hdfs://node1:8020
hdfs://node1:8020
是 Hadoop HDFS 的默认文件系统 URL。在这个 URL 中,
node1
通常是你的 Hadoop 集群的 NameNode 主机名或 IP 地址,而
8020
是 HDFS 的默认文件系统端口。
HDFS 使用
8020
作为默认文件系统端口,但你可以根据需要配置不同的端口。通常情况下,你可以通过
hdfs://<namenode-host>:8020
这样的 URL 来访问 HDFS 文件系统。这允许你连接到 Hadoop 集群并执行各种 HDFS 操作,如上传、下载、浏览和管理文件。
如果你的 Hadoop 集群使用不同的端口,你需要相应地修改 URL。端口
8020
是 HDFS 默认端口,但实际部署中可能会有不同的配置。
http://node1:50070
是 Hadoop HDFS 的 Web 用户界面(NameNode Web 用户界面)的默认端口。这个 Web 用户界面提供有关 HDFS 群集的状态信息,如文件系统的用量、节点状态、名称节点(NameNode)状态等。这是一个方便的方式来监视和管理你的 HDFS 群集。
通常情况下,如果你的 Hadoop HDFS 服务正在运行,并且已按默认配置设置,则你可以通过浏览器访问
http://<namenode-host>:50070
来查看 HDFS Web 用户界面,其中
<namenode-host>
是你的 NameNode 主机名或 IP 地址。在这个 Web 用户界面中,你可以查看有关 HDFS 集群的各种信息和指标。这有助于监控和管理 Hadoop 文件系统。
通常情况下,
http://node1:8080
是用于访问 Apache Spark 的 Web UI 的端口。在这个 URL 中,
node1
通常是你 Spark 集群的主节点(Master)的主机名或 IP 地址,而
8080
是 Spark 的默认 Web UI 端口。
Spark Web UI 提供了有关 Spark 应用程序、作业、阶段、任务等的详细信息,以及有关 Spark 集群状态的信息。你可以在这个 Web 用户界面上监视和调试你的 Spark 应用程序。
请注意,
8080
是 Spark 默认的 Web UI 端口,但你可以在 Spark 配置中更改此端口,以适应特定的需求。如果你的集群管理员或 Spark 部署使用了不同的端口,你需要使用相应的端口来访问 Spark Web UI。

错误4:无法连接到master:7077(配置文件出错)
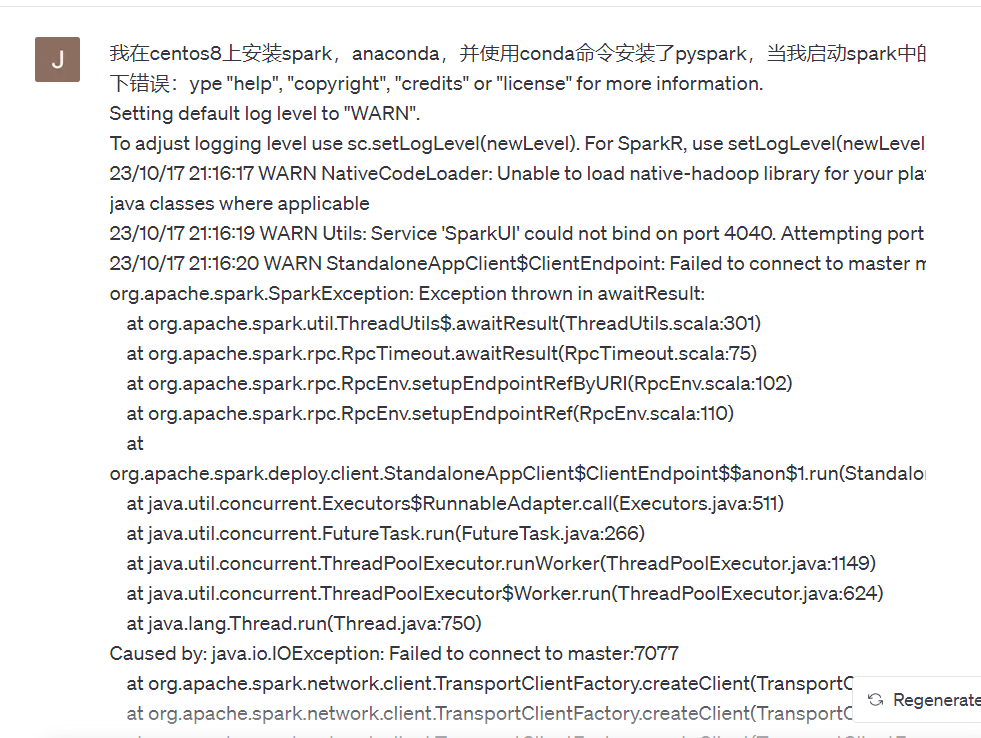
解决方案:

最后发现,我的spark-defaults.conf文件出错了,端口配错了
第一个错误:SparkUI的端口尝试了4040和4041,发现4040端口被占用了,4041端口空余,所以我在spark-defaults.conf文件中,将port改为4041
第二个错误:最致命的错误,我把spark和hadoop的web端口配错了,导致无法解析地址
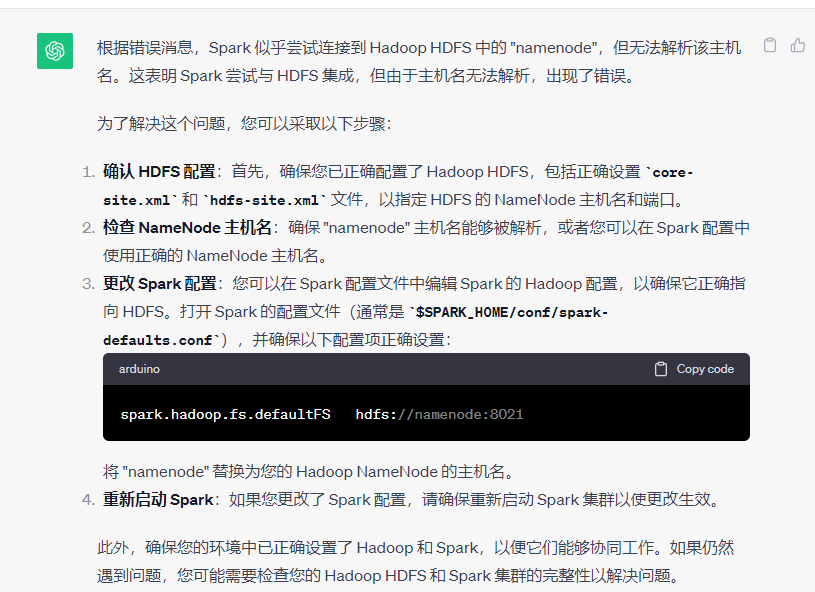
将spark.master对应的web端口改为spark://node1:7077
将spark.hadoop.fs.defaultFS对应的web端口改为hdfs://node1:8020(要与hadoop配置文件中的一致)
加上这几个就可以了:
spark.master spark://node1:7077
spark.ui.port 4041
spark.hadoop.fs.defaultFS hdfs://node1:8020
spark.eventLog.enabled true
## 设置 Spark 主机名和端口
spark.master spark://your-spark-master:7077
# 设置默认的执行内存和CPU核心数
spark.executor.memory 2g
spark.executor.cores 2# 设置 Spark UI 的端口
spark.ui.port 4040# 设置 Spark 日志级别
spark.logConf true
spark.driver.memory 1g
# 设置默认文件系统
spark.hadoop.fs.defaultFS hdfs://namenode:8020
# 配置 HDFS 的 NameNode 节点
spark.hadoop.fs.hdfs.impl org.apache.hadoop.hdfs.DistributedFileSystem
spark.hadoop.fs.hdfs.serverName namenode

spark.hadoop.fs.defaultFS
的作用:指向HDFS的NameNode地址

这个其实出了好多错,配置文件出错了,后面的spark使用的python路径也不对(不是anaconda的,而是spark自身自带的)
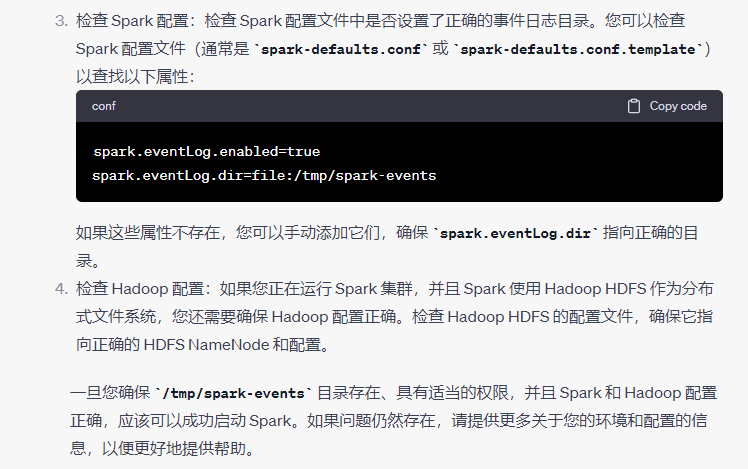
错误5:初始化SparkContext时报错:file:/tmp/spark-events does not exist

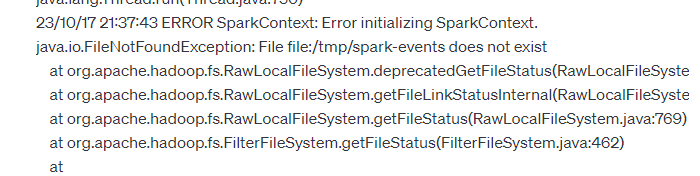

错误原因: Spark 无法找到目录
file:/tmp/spark-events
,因此无法初始化 SparkContext。这个目录通常用于存储 Spark 应用程序事件日志,包括应用程序的执行历史记录
解决方案:
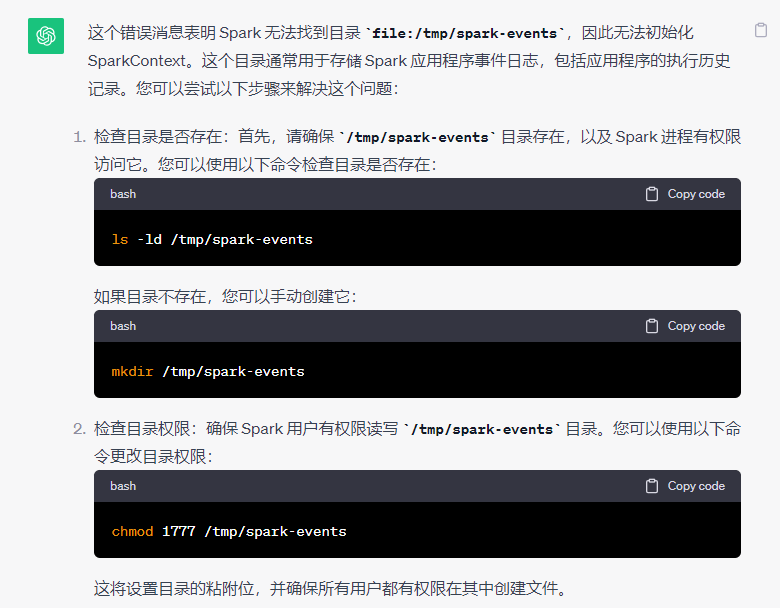
错误6:pyspark启动时,报错:MouduleNotFound(在conda中安装的包找不到)

错误原因:spark中的pyspark使用的是自带的python解释器,而非conda环境下的python,所以要在设置文件/etc/profile中,将
$SPARK_PYTHON
设置为conda虚拟环境中使用的python路径(which python查看)
解决方案:
我的/etc/profile配置文件
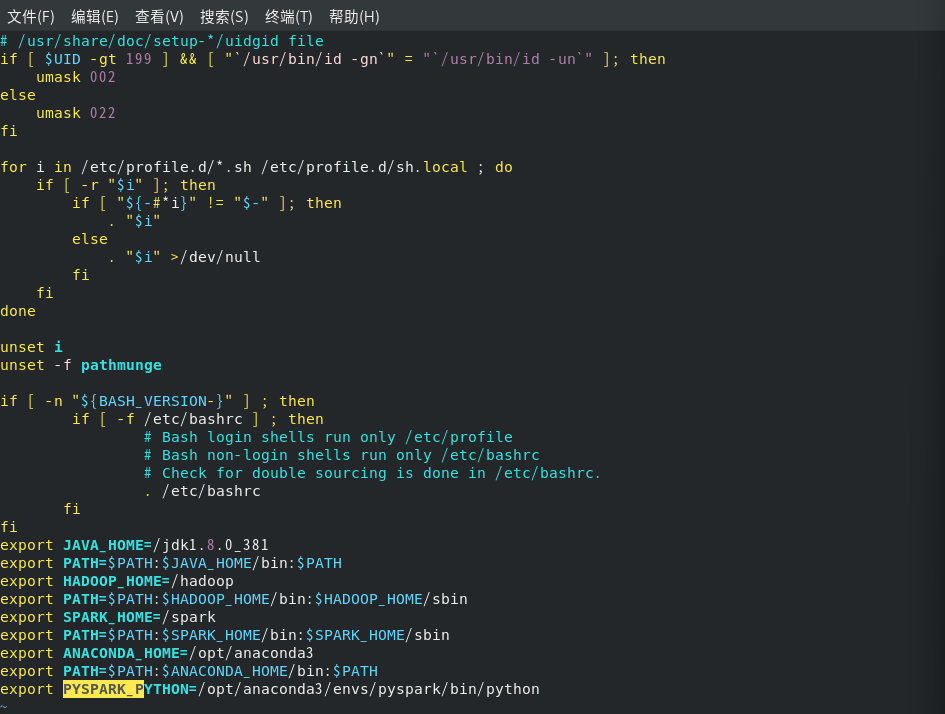
exportJAVA_HOME=/jdk1.8.0_381
exportPATH=$PATH:$JAVA_HOME/bin:$PATHexportHADOOP_HOME=/hadoop
exportPATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
exportSPARK_HOME=/spark
exportPATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
exportANACONDA_HOME=/opt/anaconda3
exportPATH=$PATH:$ANACONDA_HOME/bin:$PATHexportPYSPARK_PYTHON=/opt/anaconda3/envs/pyspark/bin/python
在启动pyspark时,就发现python版本不是我在conda环境下设置的3.8,而是3.11,这也能说明pyspark用的不是我的conda环境下的python
HDFS操作
1.在HDFS上创建文件目录
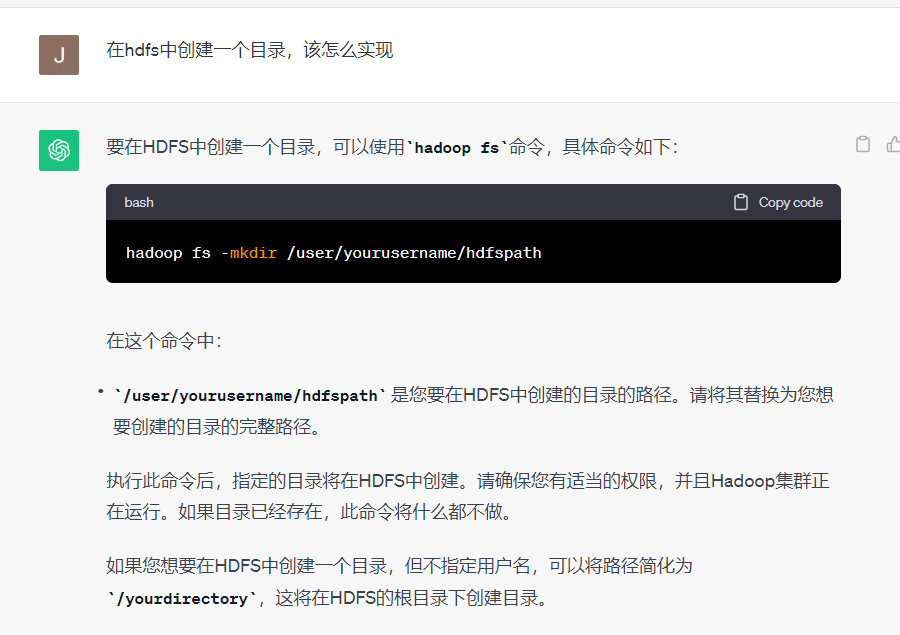
- 报错:不允许在根目录下(与/user和/myc_centos同级)创建文件目录
/user是root用户的根目录
/myc_centos是普通用户的根目录
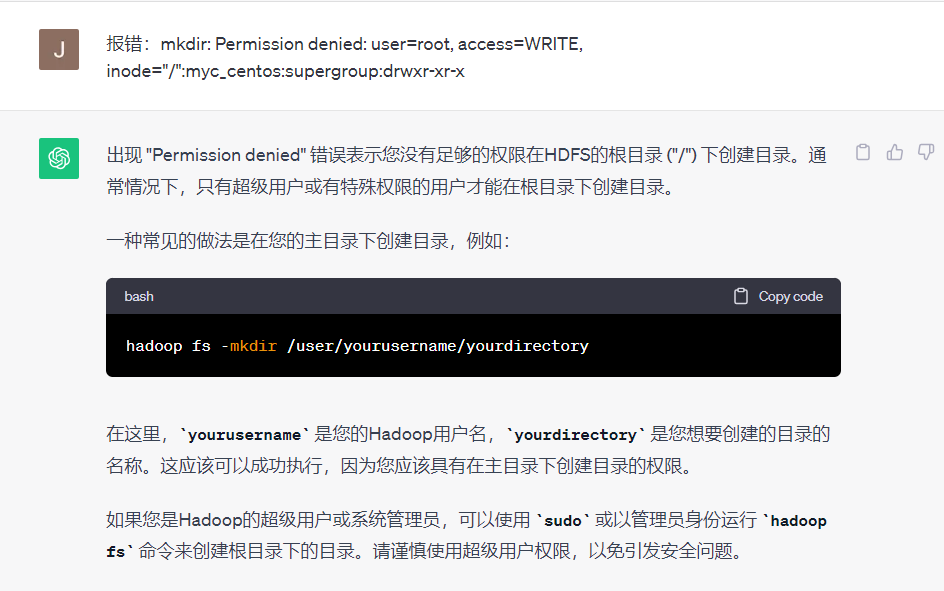
2.将文件上传到HDFS上
要将文件上传到Hadoop分布式文件系统(HDFS),可以使用Hadoop提供的
hadoop fs
命令,或者使用Hadoop的Java API或Hadoop库的其他API来执行文件上传操作。
- 使用
hadoop fs命令:
打开终端并执行以下命令,其中
localfile
是本地文件的路径,
hdfsdir
是HDFS目标目录的路径:
hadoop fs -copyFromLocal localfile hdfsdir
例如,如果要将本地文件
/path/to/localfile.txt
上传到HDFS目录
/user/yourusername/hdfspath/
,可以运行:
hadoop fs -copyFromLocal /path/to/localfile.txt /user/yourusername/hdfspath/
请注意,您需要在Hadoop集群上具有适当的权限才能执行HDFS文件上传操作。
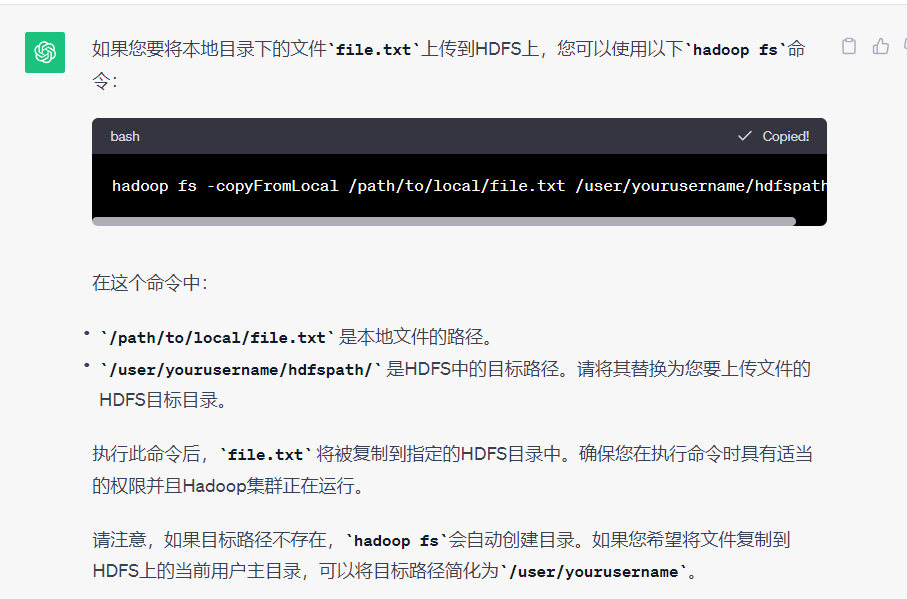
例如我要上传本地的/file.txt到HDFS上的/user/worcount中,在创建好/user/wordcount后,输入命令:
hadoop fs -copyFromLocal /file.txt /user/wordcount
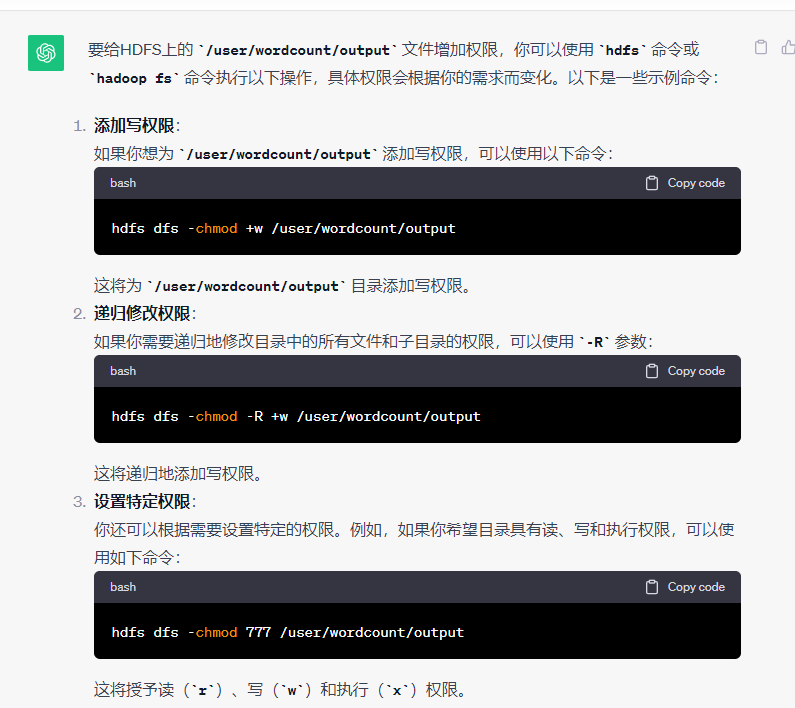
3.给文件增加权限
4.wordcount.py代码实现
在Spark集群中完成
from pyspark import SparkConf, SparkContext
# 创建 Spark 配置
conf = SparkConf().setAppName("WordCount")# 初始化 SparkContext
sc = SparkContext(conf=conf)# 从 HDFS 读取文件
text_file = sc.textFile("hdfs://namenode:8020/user/wordcount/file.txt")# 将 "namenode" 替换为 HDFS 主节点的主机名或IP# 对文件进行单词拆分和计数
word_counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word:(word,1)) \
.reduceByKey(lambda a, b: a + b)# 保存结果到 HDFS
word_counts.saveAsTextFile("hdfs://namenode:8020/user/wordcount/output")# 替换 "namenode" 和路径# 关闭 SparkContext
sc.stop()

5.standalone模式下提交并运行wordcount.py
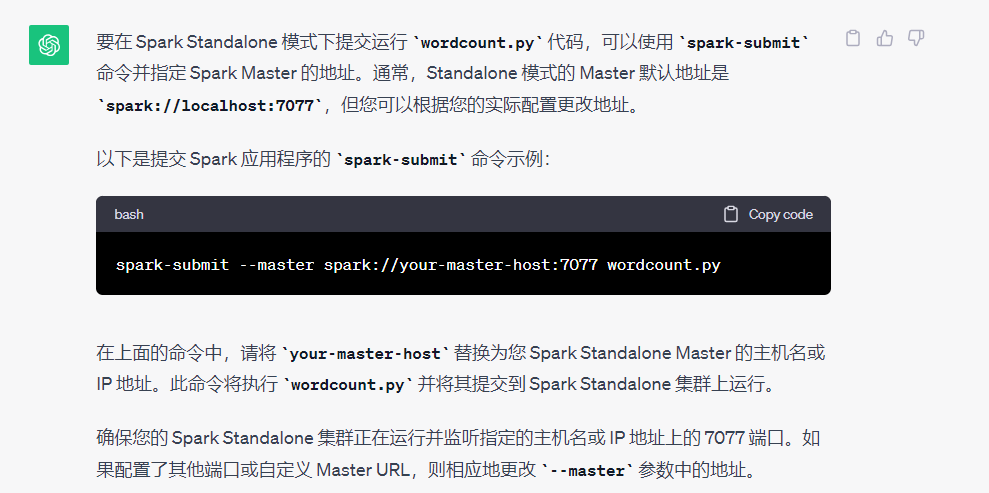
- 报错:output文件没有内容

错误原因:我创建了output目录,程序发现我已经创建好了这个目录,认为该目录已经存在,不能自己新建一个储存数据的目录,所以就终止运行了
可能出现的问题:

我的问题:
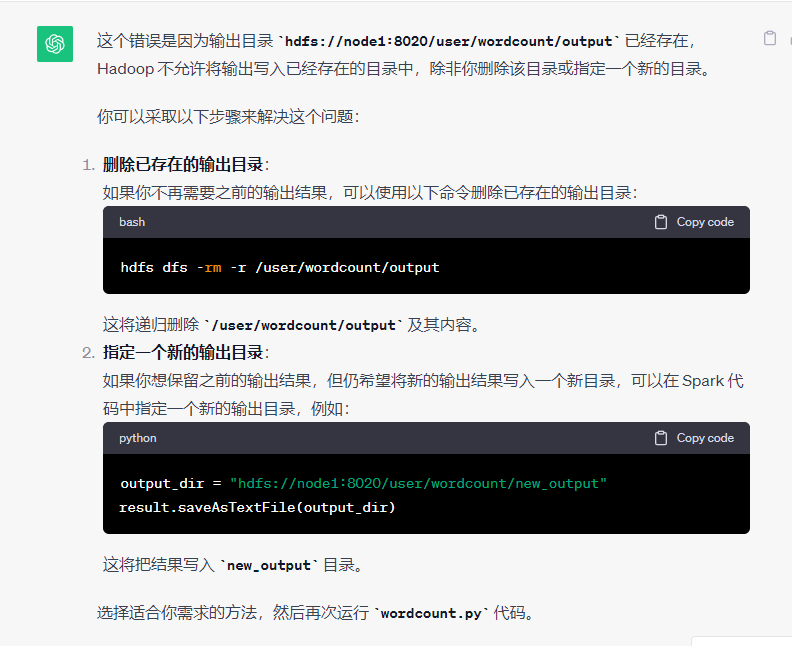
- 运行代码时报错:

问题原因:node2、3上找不到conda环境,但是还要使用这个环境
解决思路:

我在Spark集群中都安装了anaconda,分别创造了pyspark虚拟环境,同时保证了配置文件和地址的正确性
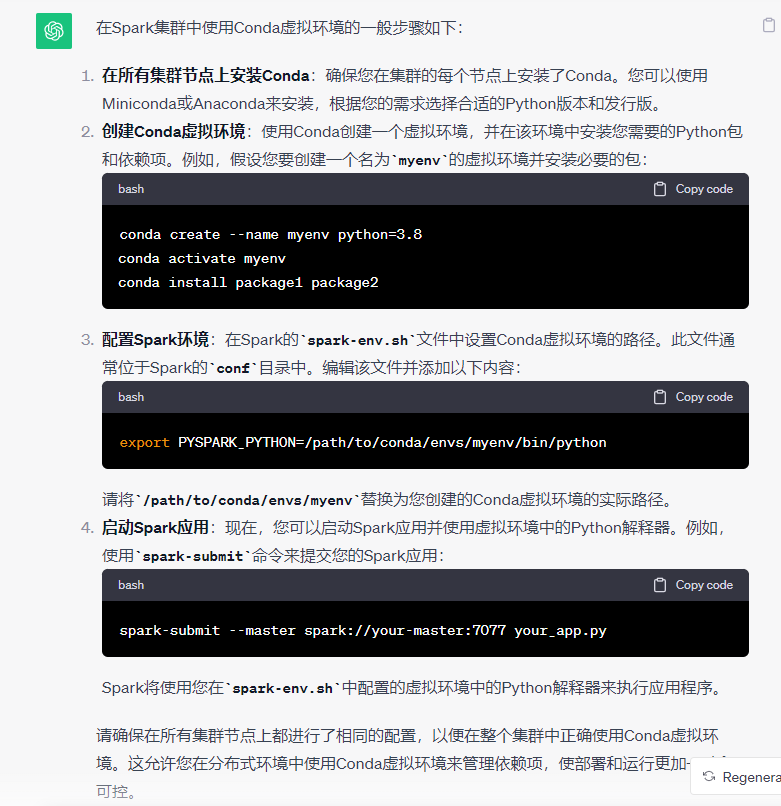
具体,查看:
(超详细) Spark环境搭建(Local模式、 StandAlone模式、Spark On Yarn模式)-CSDN博客
清华源换源:
anaconda | 镜像站使用帮助 | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
终于,运行成功了
6.将结果传回到本地
通过http://node1:50070管理HDFS文件系统,我看到output中有三个文件:
success
part-00000
part-00001
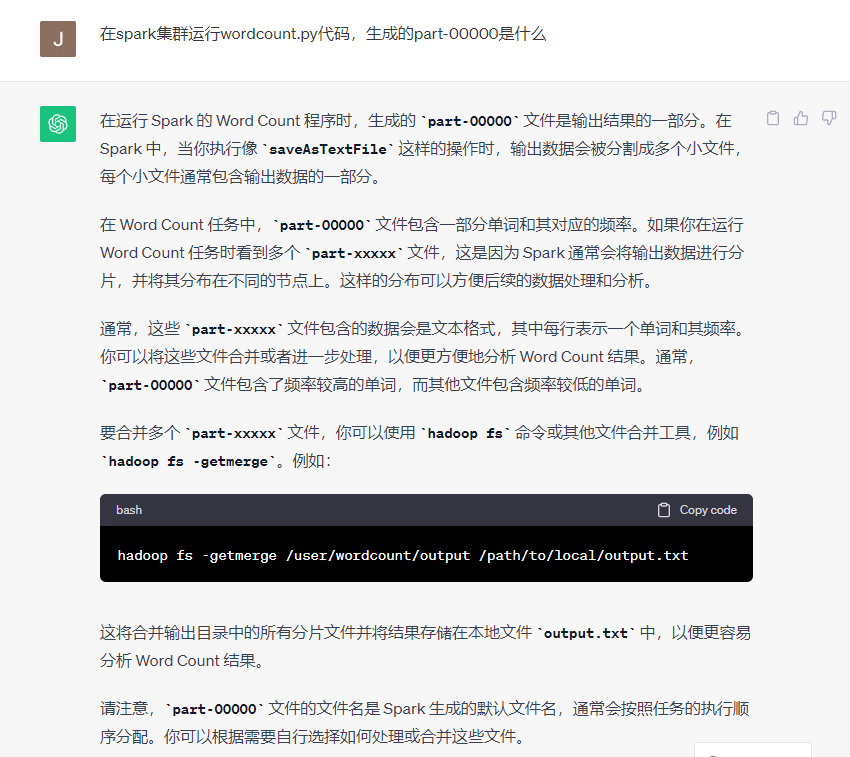
最后,我使用这个命令将结果传回到本地的/output.txt文件
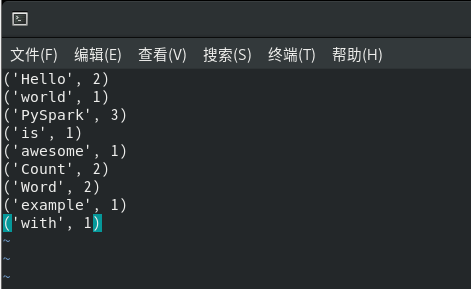
后记:
Hadoop安装(重要)
【精选】大数据Hadoop(一):集群搭建–Hadoop3.3.1、CentOS8、HDFS集群、YARN集群最新保姆级教程_centos8安装yarn_彭瑞琪的博客-CSDN博客
虚拟机扩容centos8
Centos8 硬盘扩容_FDUshiyan的博客-CSDN博客
在普通用户下激活conda环境
【Conda】root用户安装的anaconda如何给普通用户使用_conda命令只能root使用 怎么办-CSDN博客
配置jupyter notebook
centos8 部署 jupyter notebook-CSDN博客
报错:无法初始化SparkContext
Spark 报错解决–Error initializing SparkContext_51CTO博客_spark启动报错
centos8-stream更换yum软件源(我换的是阿里云)
centos8 yum失败完美解决-CSDN博客

hadoop基本文件操作也可以看看这个:
如何往hdfs上上传文件?_将文件上传到hdfs-CSDN博客
最好使用root用户进行上面所有的操作
root用户与普通用户配置文件差别
root用户使用的配置文件在/root下,普通用户使用的配置文件在/home/myc_centos下

root用户的家目录地址:
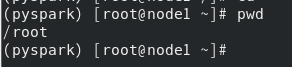
普通用户的家目录地址:

~/.bashrc文件
我的.bashrc文件
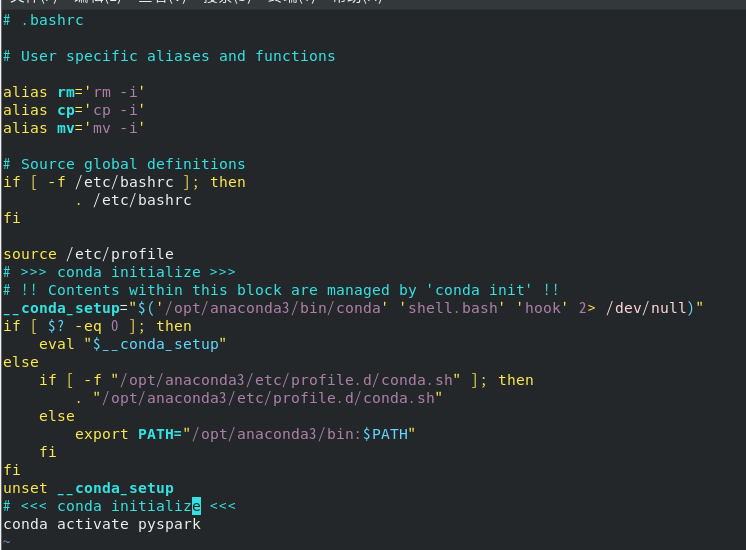
# .bashrc# User specific aliases and functionsaliasrm='rm -i'aliascp='cp -i'aliasmv='mv -i'# Source global definitionsif[-f /etc/bashrc ];then. /etc/bashrc
fisource /etc/profile
# >>> conda initialize >>># !! Contents within this block are managed by 'conda init' !!__conda_setup="$('/opt/anaconda3/bin/conda' 'shell.bash' 'hook' 2> /dev/null)"if[$?-eq0];theneval"$__conda_setup"elseif[-f"/opt/anaconda3/etc/profile.d/conda.sh"];then."/opt/anaconda3/etc/profile.d/conda.sh"elseexportPATH="/opt/anaconda3/bin:$PATH"fifiunset __conda_setup
# <<< conda initialize <<<
conda activate pyspark
spark配置文件内容
spark-env.sh
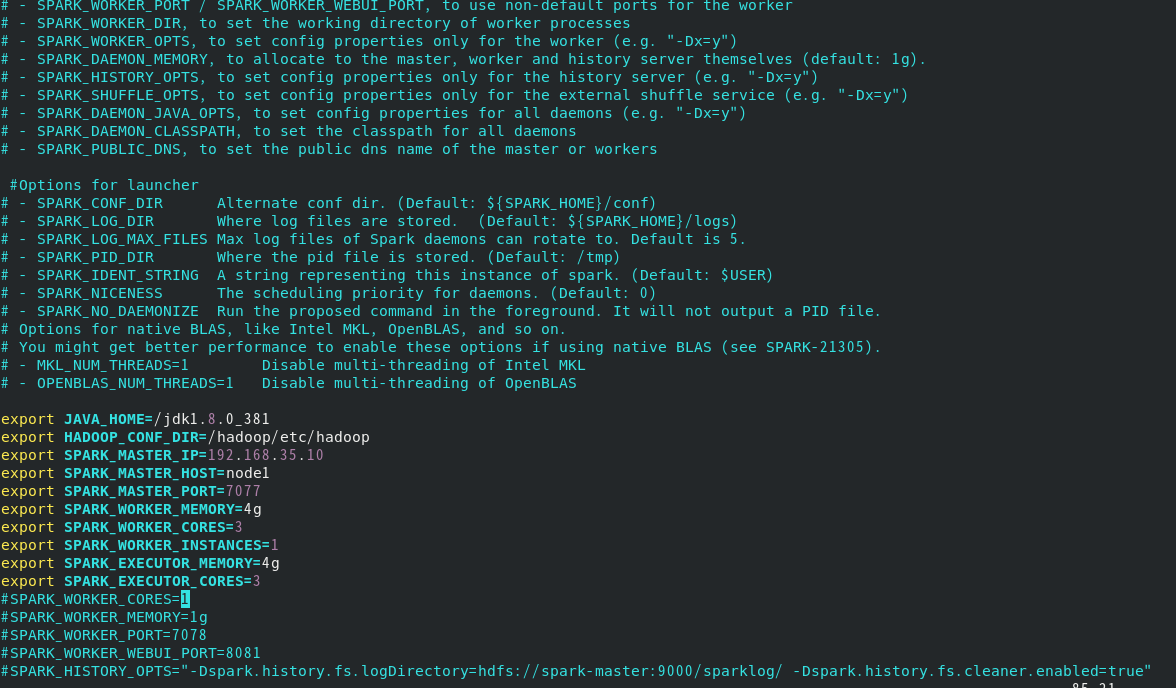
exportJAVA_HOME=/jdk1.8.0_381
exportHADOOP_CONF_DIR=/hadoop/etc/hadoop
exportSPARK_MASTER_IP=192.168.35.10
exportSPARK_MASTER_HOST=node1
exportSPARK_MASTER_PORT=7077exportSPARK_WORKER_MEMORY=4g
exportSPARK_WORKER_CORES=3exportSPARK_WORKER_INSTANCES=1exportSPARK_EXECUTOR_MEMORY=4g
exportSPARK_EXECUTOR_CORES=3
spark-defaults.conf

park.master spark://node1:7077
spark.ui.port 4041
spark.hadoop.fs.defaultFS hdfs://node1:8020
spark.eventLog.enabled true
这个要和自己的Hadoop配置对应
workers

lo4j2.properties
版权归原作者 y=tan(x) 所有, 如有侵权,请联系我们删除。