
本文主要讲述在Kettle开发中实现循环操作的两种简单方法,即使没有编程经验的朋友也比较容易掌握。
本系列文章的前两篇,感兴趣的朋友可以看下:1、变量的使用;2、参数的使用。
循环的实现条件
在Kettle中要实现一个正常的循环操作,一般要满足下面四个条件:
1、有一个业务执行模块,可以是一个作业或者转换等,用来接收变化值,变化值的载体一般是变量;
2、要有需要遍历的值,可以是提前准备好的一组结果值,也可以是循环脚本执行过程中动态生成的;
3、要能够实现值的逐行输入;
4、要保证循环能够正常结束。
针对循环的实现条件,我会在下面具体的循环实现方法中进行详细说明。
循环的实现方法1:对一组值进行循环
下图是完整的作业图:

清空数据表的操作,就是通过简单的SQL语句实现:
truncate table selected_city
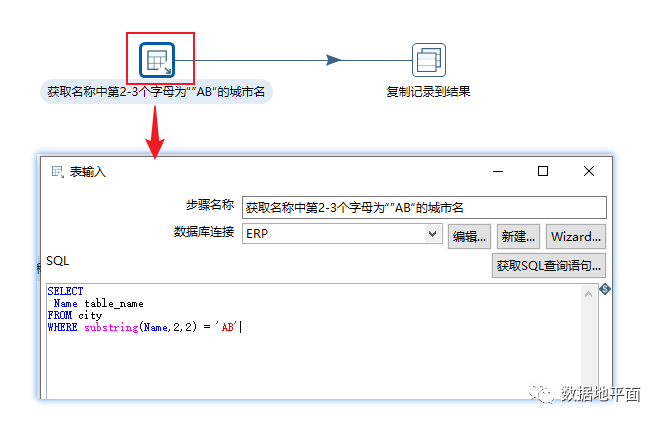
转换对象"get_variable_set"对应的具体内容如下所示:通过该脚本,确定执行循环操作时需要遍历的值的范围。
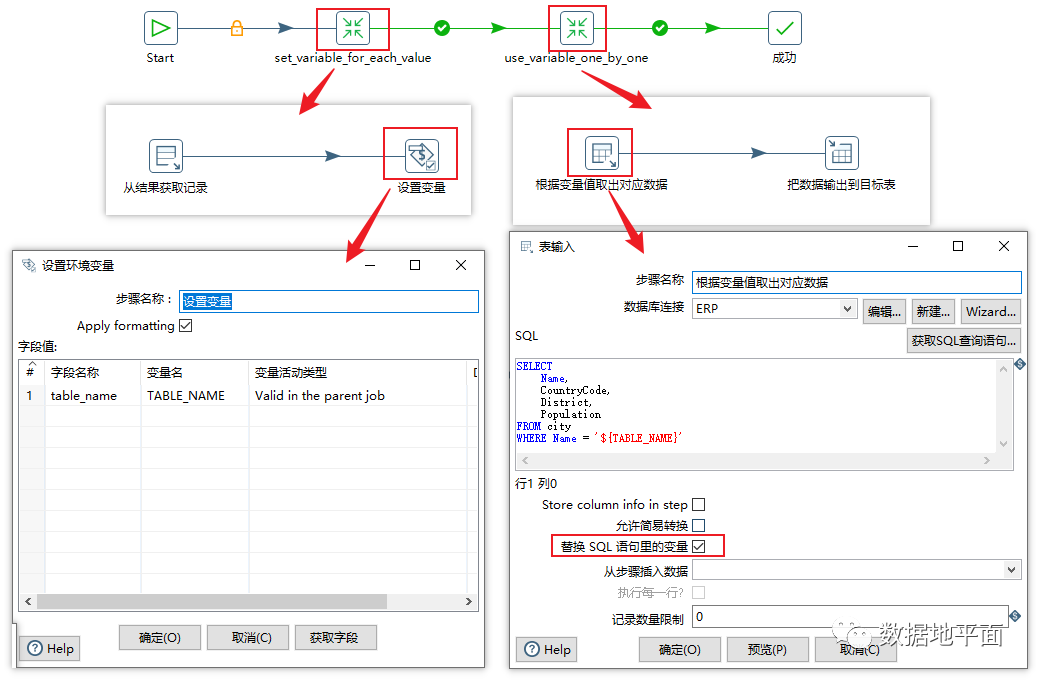
作业对象"use_variable"对应的具体内容如下所示:作业对象"use_variable"就是一个业务执行模块,该模块主要分为两部分内容:1、把需要遍历的值逐个设置为变量;2、引用变量值,实现业务需求。
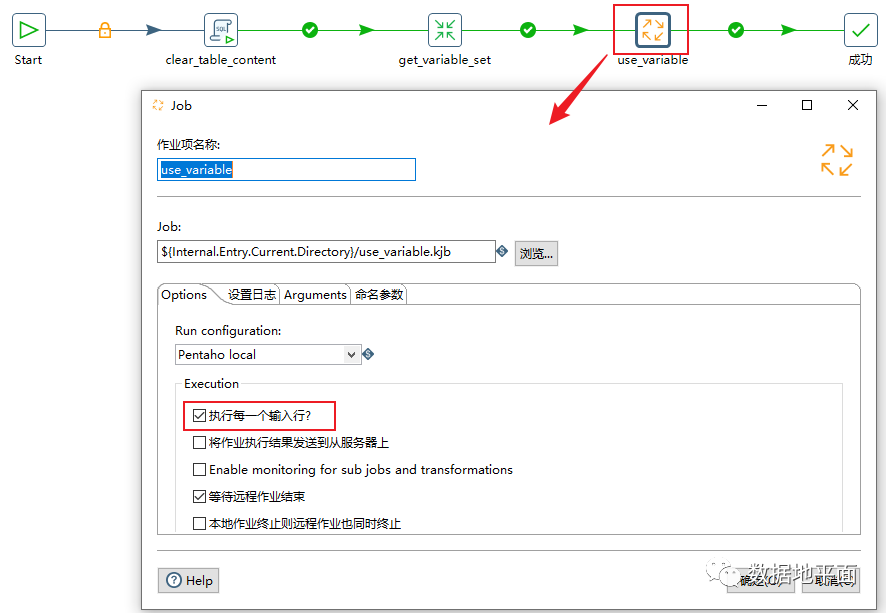
还有一个关键操作,鼠标双击作业对象"use_variable",勾选"执行每一个输入行",实现值的逐行输入。当所有的值都被逐个输入后,循环也就结束了。
循环的实现方法2:动态生成变化值
下图是完整的作业图:
步骤"设置变量"对应的具体内容如下所示:作业里的"设置变量"组件,可以指定具体的值。
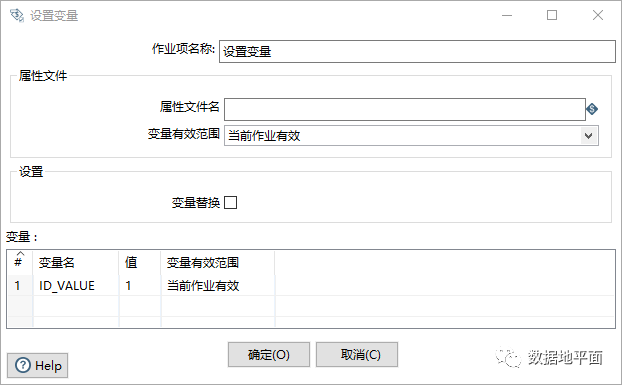
步骤"检验字段的值"对应的具体内容如下所示:该步骤设置了结束循环的条件,当满足条件时循环就会结束。
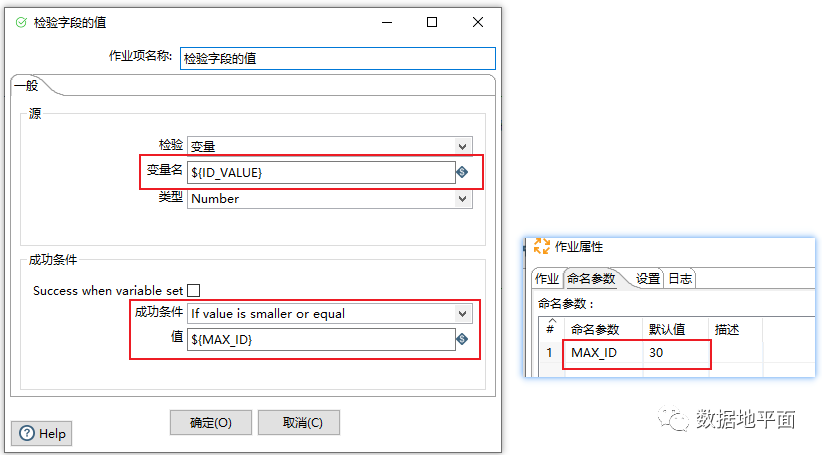
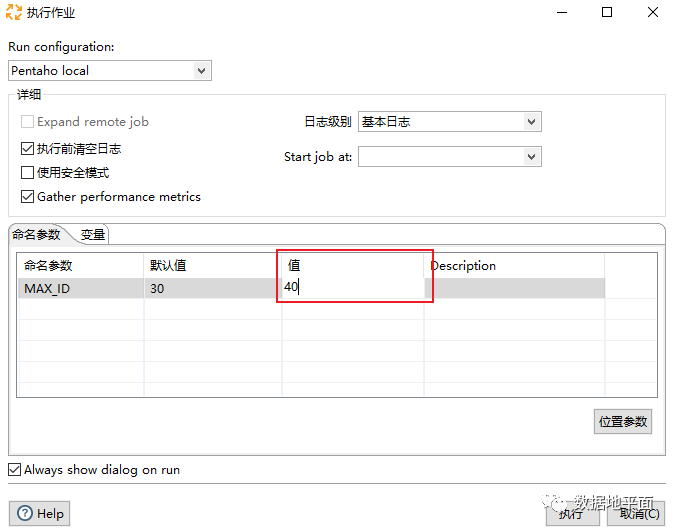
上图中命令参数"MAX_ID"的默认值为30,也可以在执行作业时手动设置:
转换对象"设置变量(覆盖原有变量)"对应的具体内容如下所示:通过特定的公式更新变量值。

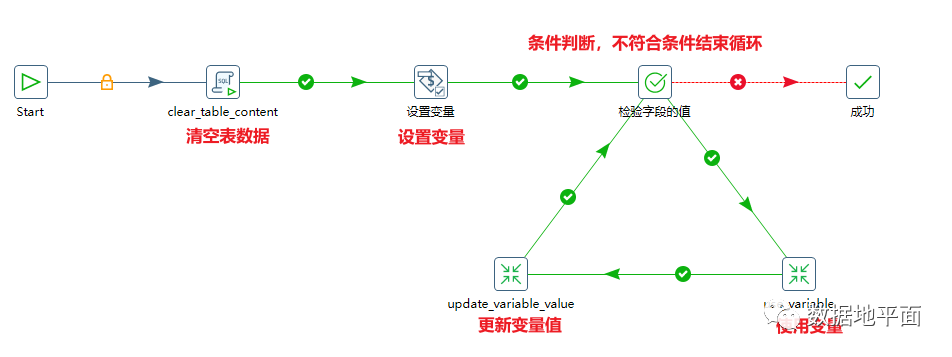
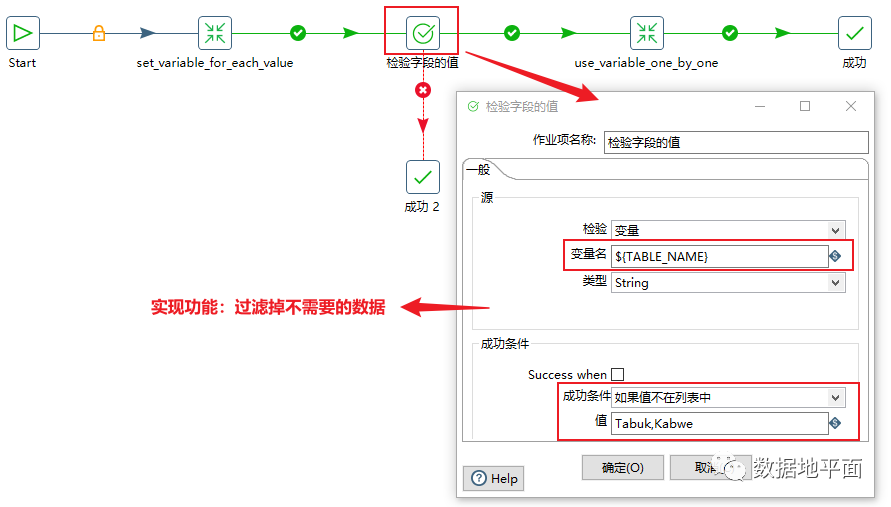
循环内部操作:设置条件,判断是否跳过本次执行
我们在进行循环操作时,有时需要对执行条件进行判断,对于不符合条件的值,跳过后面的执行脚本,继续执行下一轮的循环。下图是在作业对象"use_variable"中的实现:
总结
本文介绍了Kettle开发中实现循环操作的几种简单方法,我已经把对应的Kettle脚本文件上传到百度网盘,需要的话,请关注公众号后,回复“变量和参数”获取。
版权归原作者 数据地平面 所有, 如有侵权,请联系我们删除。