
1 Rancher概述
rancher官方文档
Rancher 是一个 Kubernetes 管理工具,让你能在任何地方和任何提供商上部署和运行集群。
Rancher 可以创建来自 Kubernetes 托管服务提供商的集群,创建节点并安装 Kubernetes,或者导入在任何地方运行的现有 Kubernetes 集群。
Rancher 基于 Kubernetes 添加了新的功能,包括统一所有集群的身份验证和 RBAC,让系统管理员从一个位置控制全部集群的访问。
此外,Rancher 可以为集群和资源提供更精细的监控和告警,将日志发送到外部提供商,并通过应用商店(Application Catalog)直接集成 Helm。如果你拥有外部 CI/CD 系统,你可以将其与 Rancher 对接。没有的话,你也可以使用 Rancher 提供的 Fleet 自动部署和升级工作负载。
Rancher 是一个 全栈式 的 Kubernetes 容器管理平台,为你提供在任何地方都能成功运行 Kubernetes 的工具。
2 安装Rancher
2.1 环境
软件版本Ubuntu20.04.2docker20.10.6
2.2 环境初始化
2.2.1 关闭swap分区
sudo swapoff -a
验证
free -m
2.2.2 确保时区,时间正确
sudo timedatectl
2.2.3 确保虚机不会自动suspend
sudo systemctl mask sleep.target suspend.target hibernate.target hybrid-sleep.target
2.2.4 加载内核模块br_netfilter,并调整参数
执行
sudo modprobe br_netfilter
确认已加载
lsmod |grep br_netfilter
调整内核参数,修改 /etc/sysctl.conf
将桥接的IPv4流量传递到iptables的链
vim /etc/sysctl.conf
cat> /etc/sysctl.conf <<EFO
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EFO
使配置生效,执行:
sudo sysctl --system
2.2.5 设置rp_filter的值
执行
sudovi /etc/sysctl.d/10-network-security.conf
将文件中如下两个参数的值从2修改为1
net.ipv4.conf.default.rp_filter=1
net.ipv4.conf.all.rp_filter=1
使配置生效,执行:
sudo sysctl --system
2.3 启动Rancher
2.3.1 启动Rancher
启动时需要添加 --privileged 参数
sudodocker run -d --restart=unless-stopped --privileged --name rancher -p 20080:80 -p 443:443 rancher/rancher
2.3.2 在Web界面登录
地址:https:// + ip
例如:https://192.168.20.4
因为是使用https的方式登录,所以会报错。点继续前往就可以了。
如果您预先设置了自己的引导密码,请在这里输入。否则会为您生成一个随机的。
用docker ps找到你的容器ID,然后运行:
sudodocker logs container-id 2>&1|grep"Bootstrap Password:"
执行
sudodocker logs 28fedd17fc15 2>&1|grep"Bootstrap Password:"2022/10/21 06:49:08 [INFO] Bootstrap Password: zrv99r7xrs22wvfksfwlxqt5n52j4mh8pgntc4nvm6xc8269jwxk4w
设置密码,最少12位
至此,Rancher安装完成!
3 使用Rancher搭建K8S集群
如果已经搭建k8s集群,可以选择导入已有集群。
这边我们选择创建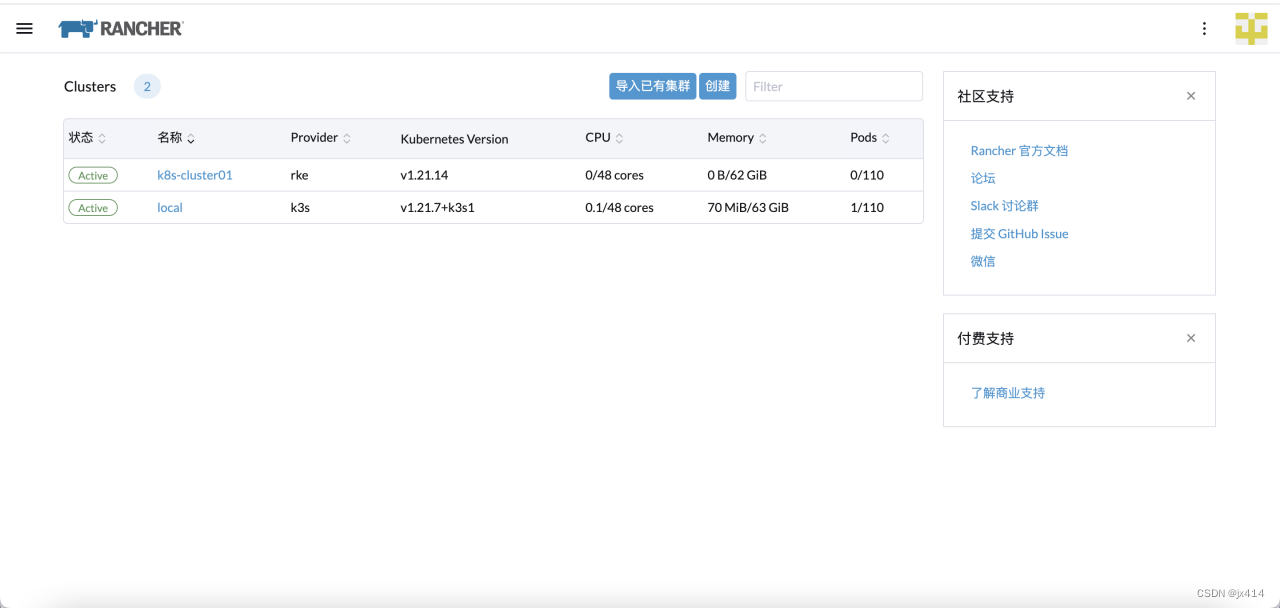
选择在现有的节点上使用RKE创建集群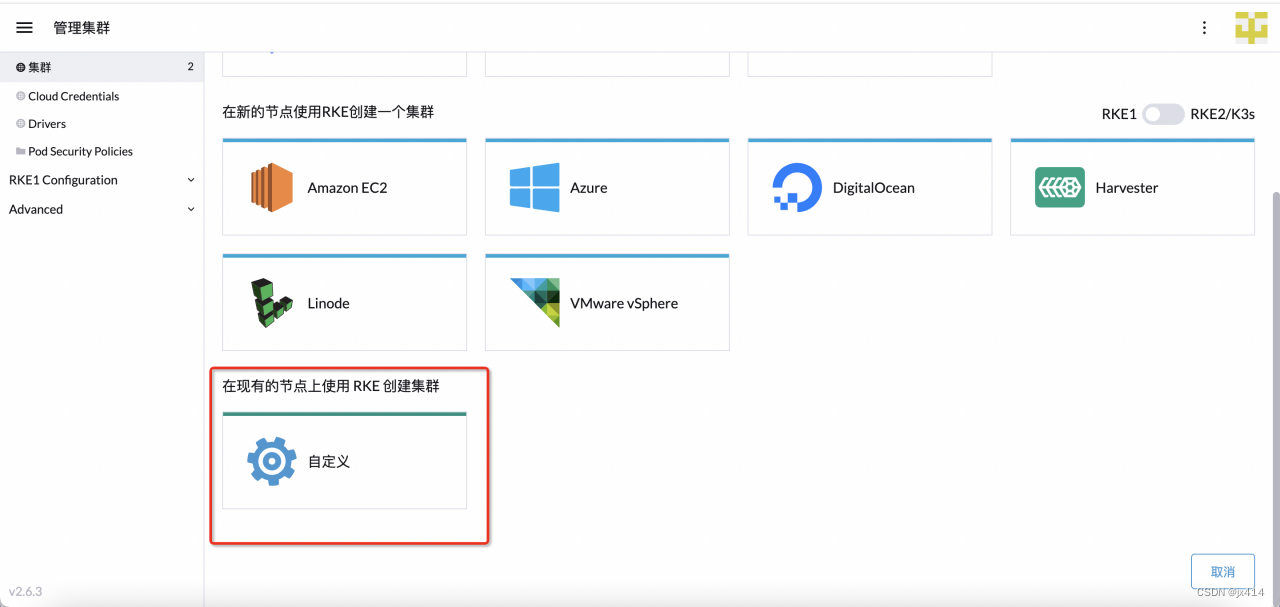
输入集群的名称,选择k8s版本,然后根据自己的需求修改其他配置,然后点击Next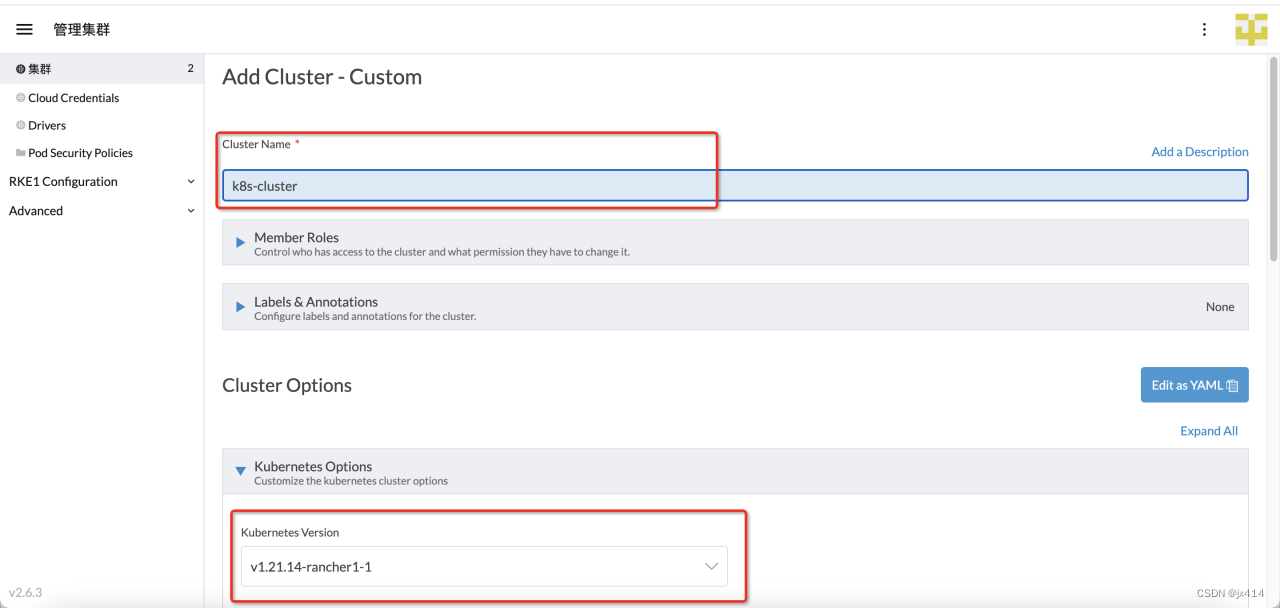
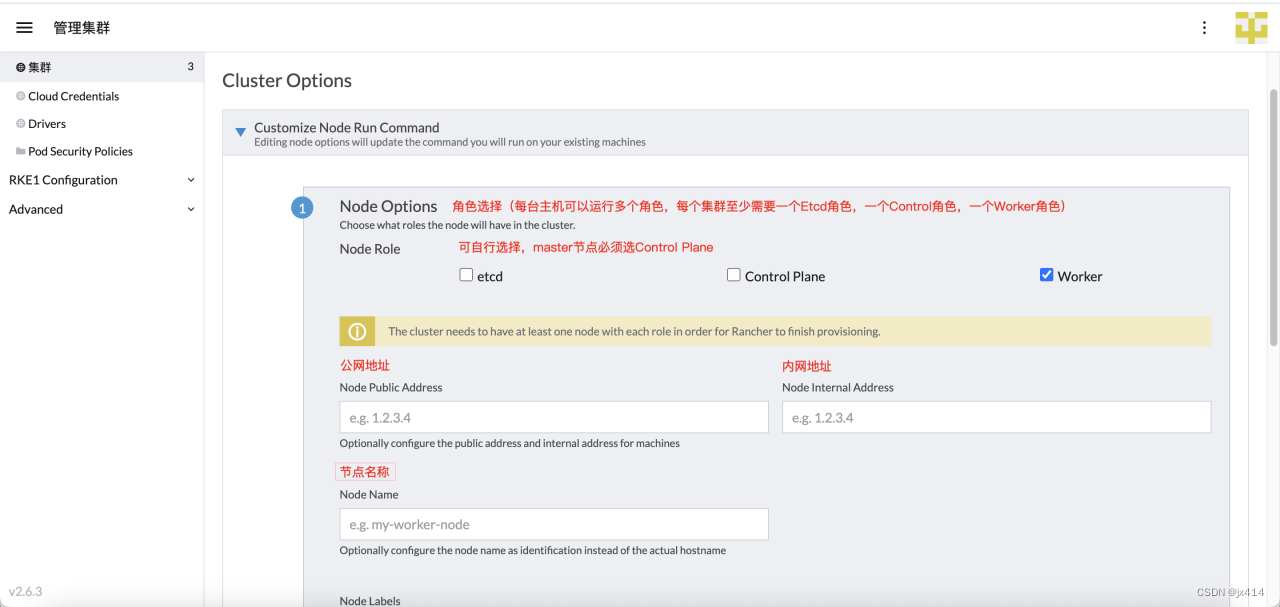
登录到节点服务器,服务器上需要装有对应版本的docker,然后执行下面的命令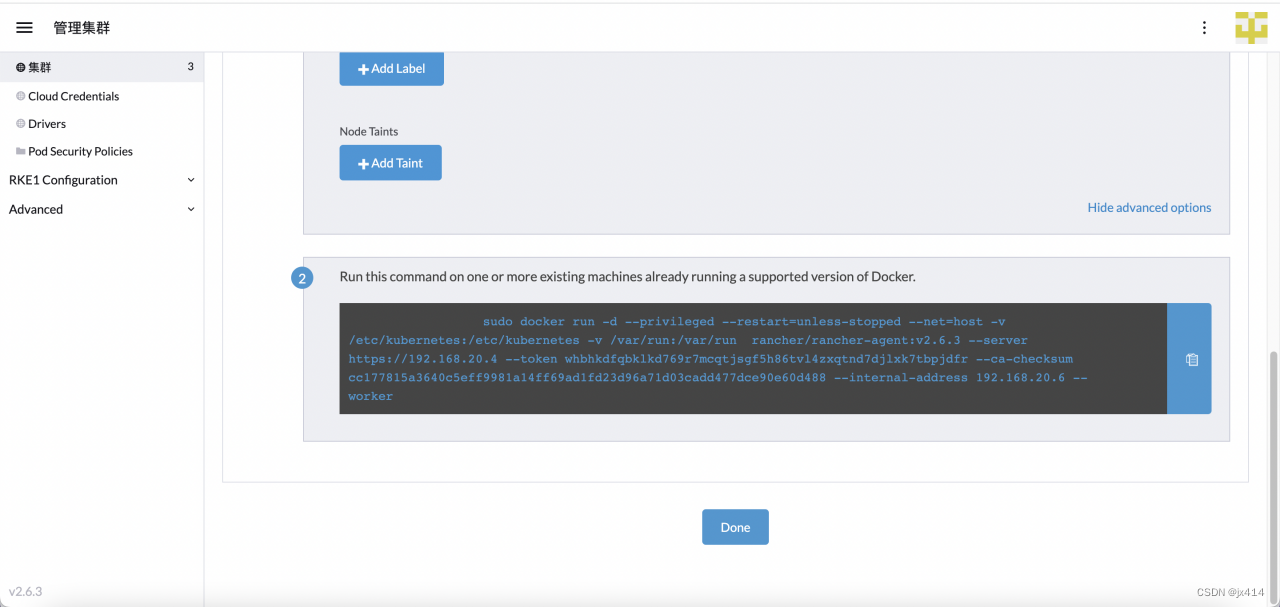
然后在首页查看cluster的状态是否是Active,Active说明成功了。
如果出现:Cluster health check failed:
可能是服务器没有关闭防火墙
查看防火墙状态
sudo ufw status
关闭防火墙
sudo ufw disable
4 Rancher的使用
这边以一个SpringBoot项目为例子。
Docker私库使用的是Harbor,需要将镜像上传到Harbor中。
Harbor的搭建可以看我的另一篇文章 搭建Docker私库Harbor
4.1 创建命名空间
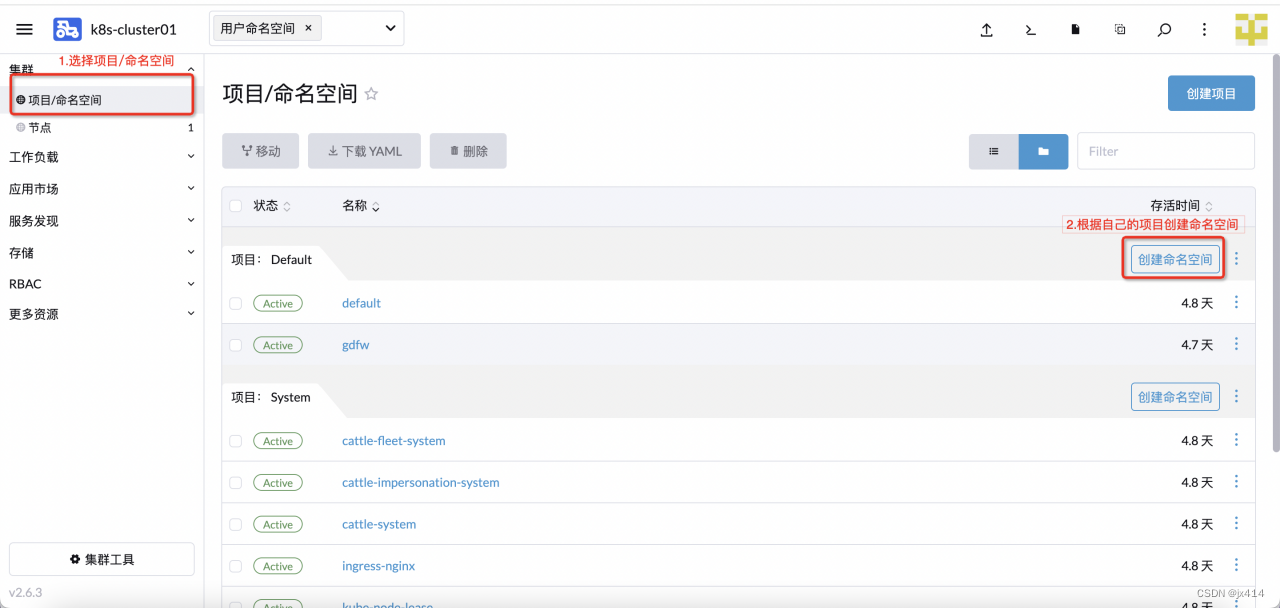
这边可以使用YAML文件创建,也可以在页面直接输入创建。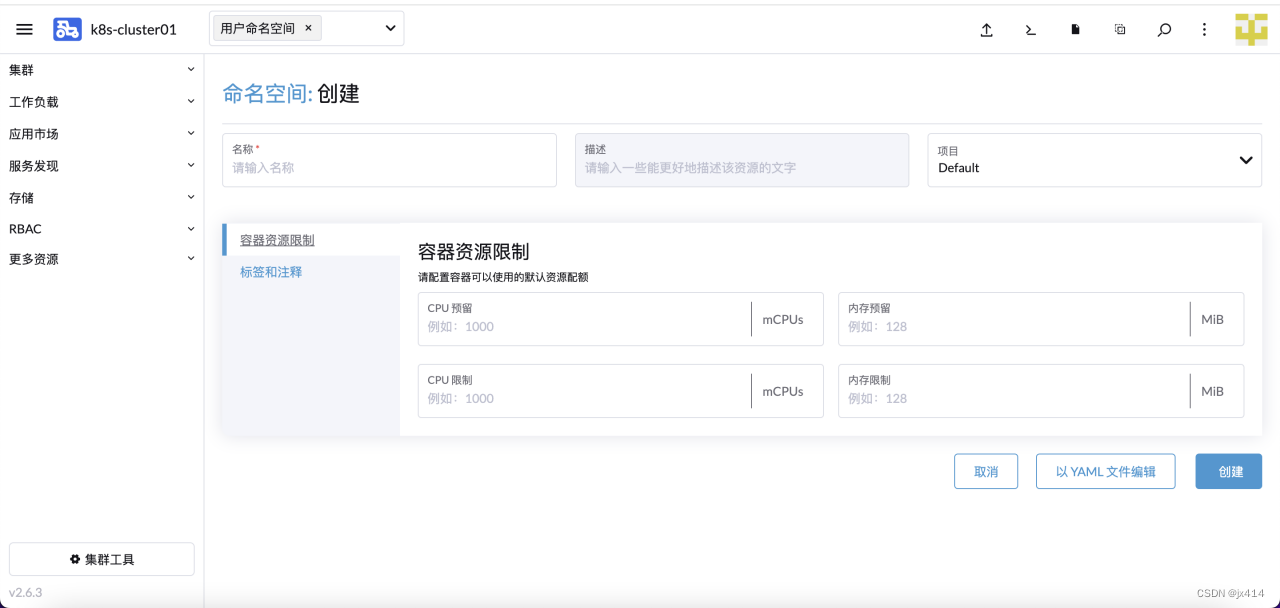
4.2 Secret
首先创建Harbor私库的密钥
选择 存储=> Secrets =>创建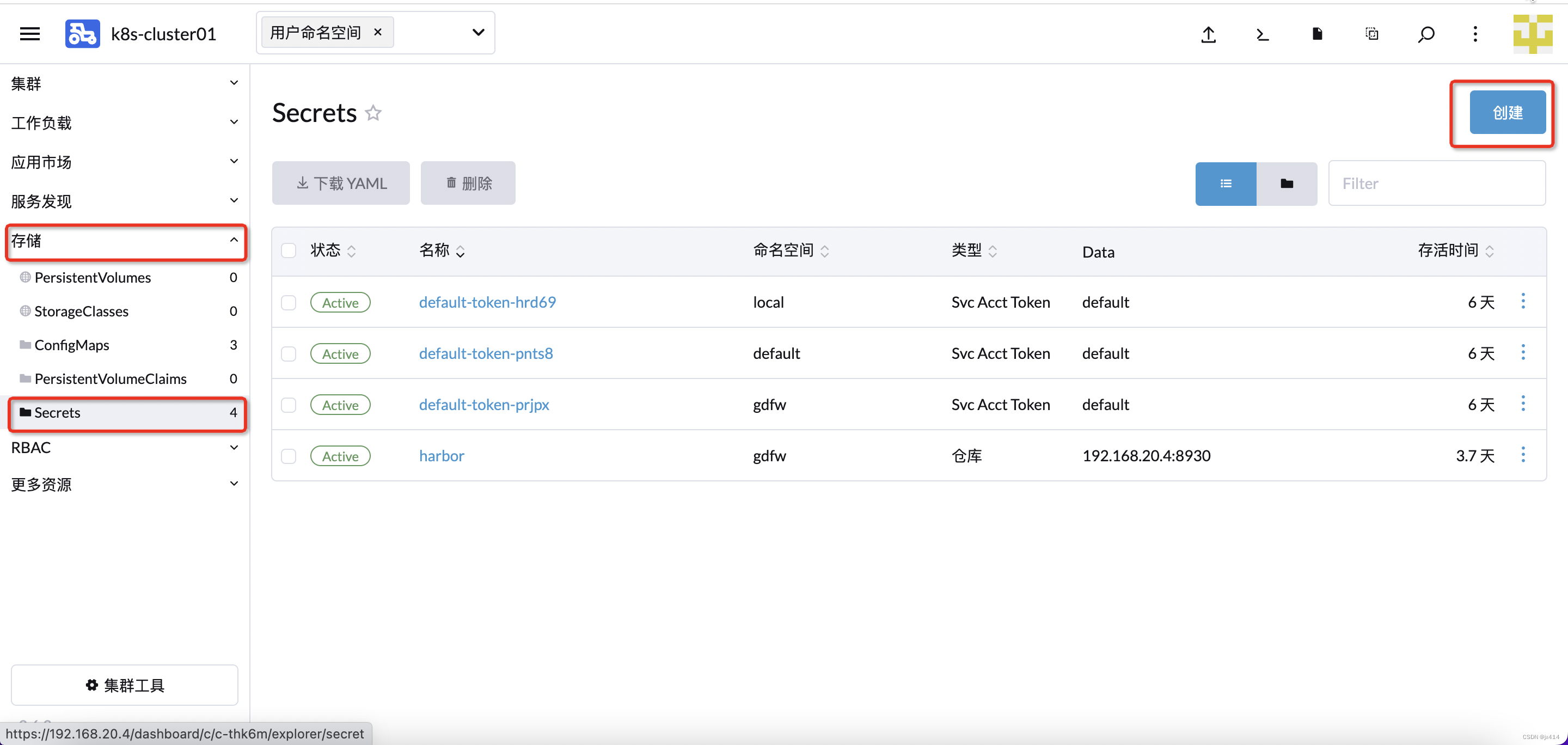
选择 仓库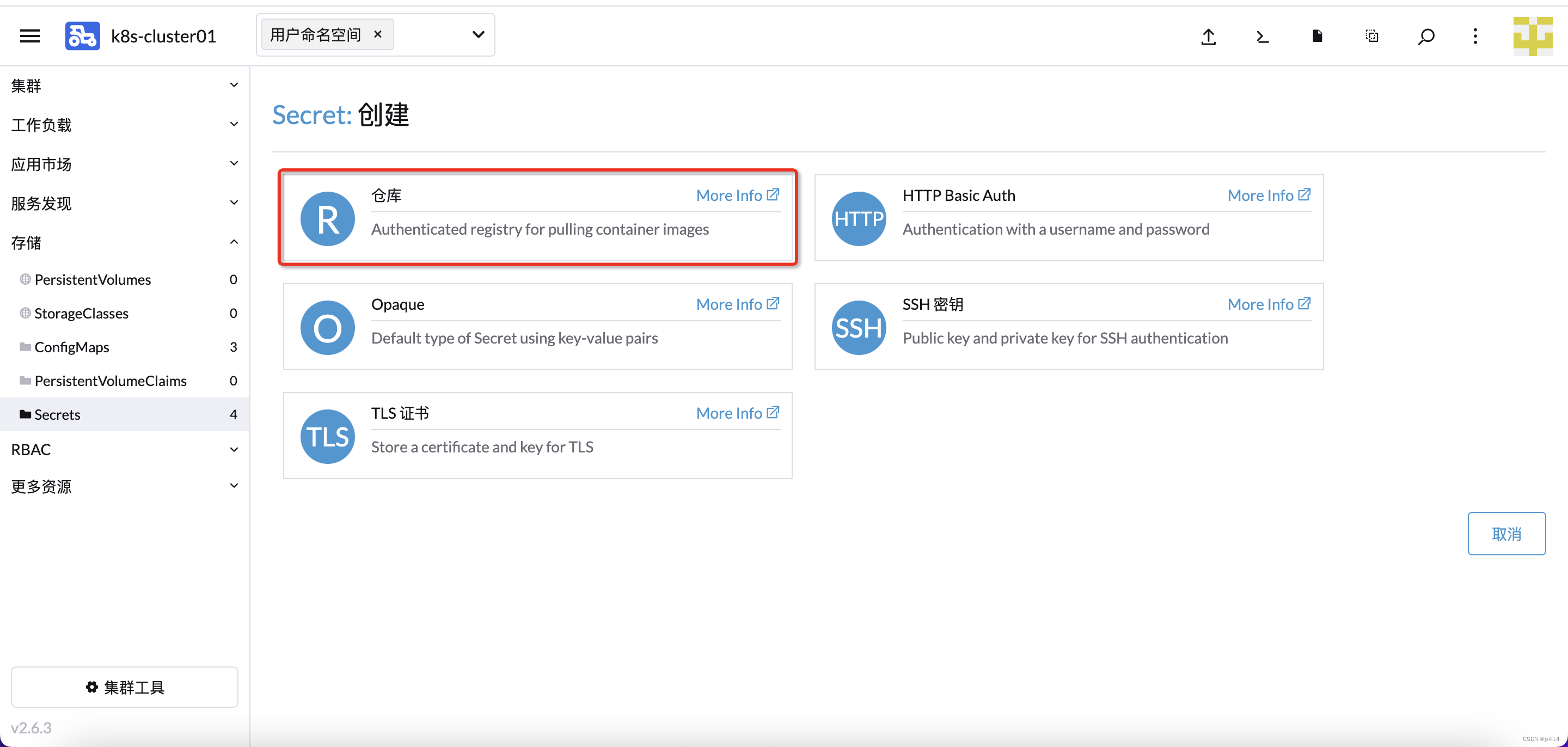
命名空间选择之前自己创建的,填写名称,然后选择 Custom,仓库地址就是Harbor的地址,再输入Habor的用户名和密码。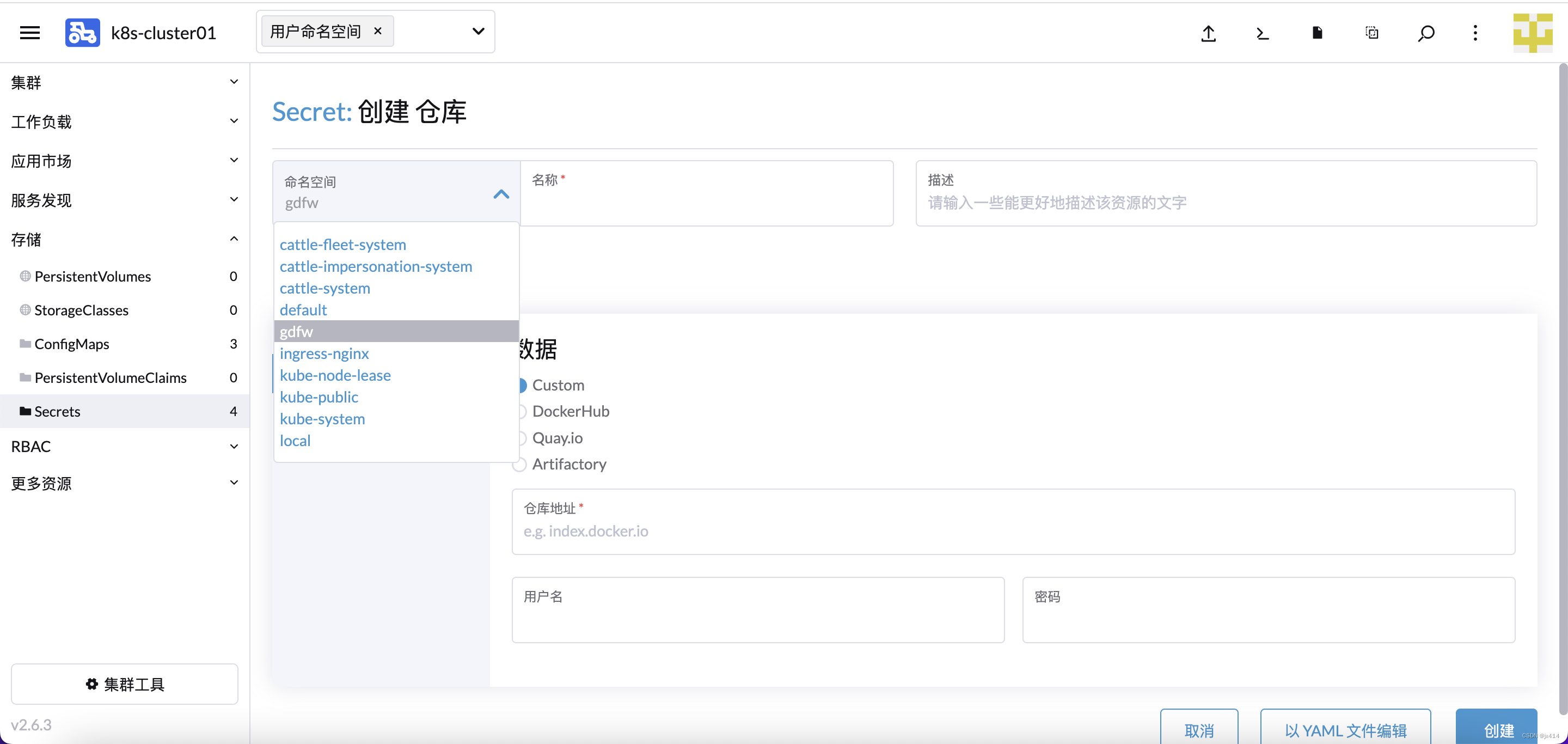
4.3 Deployment
4.3.1 概述
一个 Deployment 为 Pod 和 ReplicaSet 提供声明式的更新能力。
你负责描述 Deployment 中的 目标状态,而 Deployment 控制器(Controller) 以受控速率更改实际状态, 使其变为期望状态。你可以定义 Deployment 以创建新的 ReplicaSet,或删除现有 Deployment, 并通过新的 Deployment 收养其资源。
说明:
不要管理 Deployment 所拥有的 ReplicaSet 。 如果存在下面未覆盖的使用场景,请考虑在 Kubernetes 仓库中提出 Issue。
4.3.2 用例
以下是 Deployments 的典型用例:
- 创建 Deployment 以将 ReplicaSet 上线。ReplicaSet 在后台创建 Pod。 检查 ReplicaSet 的上线状态,查看其是否成功。
- 通过更新 Deployment 的 PodTemplateSpec,声明 Pod 的新状态 。 新的ReplicaSet 会被创建,Deployment 以受控速率将 Pod 从旧 ReplicaSet 迁移到新 ReplicaSet。每个新的 ReplicaSet 都会更新 Deployment 的修订版本。
- 如果 Deployment 的当前状态不稳定,回滚到较早的Deployment 版本。 每次回滚都会更新 Deployment 的修订版本。
- 扩大 Deployment 规模以承担更多负载。 暂停Deployment 以应用对 PodTemplateSpec 所作的多项修改, 然后恢复其执行以启动新的上线版本。
- 使用Deployment 状态来判定上线过程是否出现停滞。
- 清理较旧的不再需要的 ReplicaSet 。
4.3.3 创建 Deployment
4.3.3.1 使用表单编辑创建Deployment
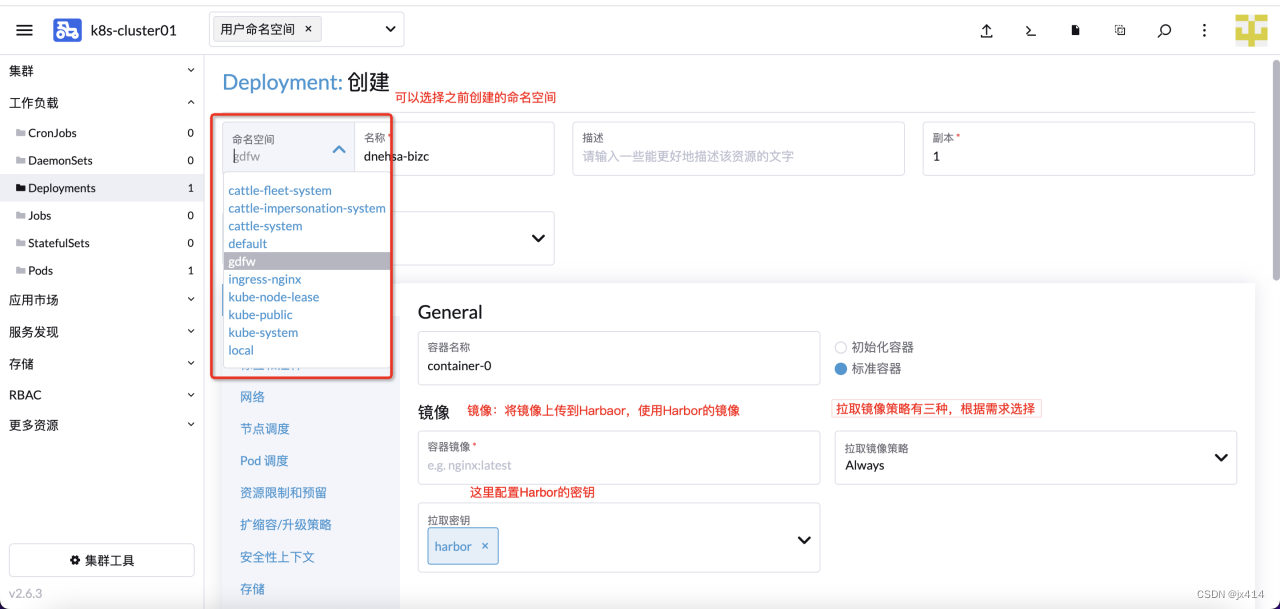

4.3.3.2 使用YAML文件创建Deployment
- YAML文件包含四个部分:**
apiVersion: 表示版本
kind: 表示资源
metadata: 表示元信息
spec: 资源规范字段
下面是具体的字段说明:
apiVersion: apps/v1 # 指定api版本,此值必须在kubectl api-versions中kind: Deployment # 指定创建资源的角色/类型metadata:# 资源的元数据/属性name: dnehsa-bizc # 资源的名字,在同一个namespace中必须唯一namespace: gdfw # 部署在哪个namespace中labels:# 设定资源的标签app: dnehsa-bizc
spec:# 资源规范字段replicas:1# 声明副本数目revisionHistoryLimit:10# 保留历史版本selector:# 选择器matchLabels:# 匹配标签app: dnehsa-bizc
strategy:# 策略rollingUpdate:# 滚动更新maxSurge: 25% # 最大额外可以存在的副本数,可以为百分比,也可以为整数maxUnavailable: 25% # 表示在更新过程中能够进入不可用状态的 Pod 的最大值,可以为百分比,也可以为整数type: RollingUpdate # 滚动更新策略template:# 模版metadata:# 资源的元数据/属性labels:# 设定资源的标签app: dnehsa-bizc
spec:# 资源规范字段containers:-name: dnehsa-bizc # 容器的名字image: 192.168.20.4:8930/library/dnehsa_bizc:v1.0 # 容器使用的镜像地址imagePullPolicy: Always # 每次Pod启动拉取镜像策略,三个选择 Always、Never、IfNotPresent# Always,每次都检查;Never,每次都不检查(不管本地是否有);IfNotPresent,如果本地有就不检查,如果没有就拉取resources:# 资源管理limits:# 最大使用cpu: 300m # CPU,1核心 = 1000mmemory: 500Mi # 内存,1G = 1000Mirequests:# 容器运行时,最低资源需求,也就是说最少需要多少资源容器才能正常运行cpu: 100m
memory: 100Mi
livenessProbe:#存活探针器配置httpGet:#1.存活探针器三种方式 1.cmd命令方式进行探测 2.http 状态码方式 3.基于tcp端口探测path: /healthy #k8s源码中healthz 实现 https://github.com/kubernetes/kubernetes/blob/master/test/images/agnhost/liveness/server.goport:32189#应用程序监听端口failureThreshold:3#处于成功时状态时,探测操作至少连续多少次的失败才被视为检测不通过,显示为#failure属性.默认值为3,最小值为 1,存活探测情况下的放弃就意味着重新启动容器。initialDelaySeconds:600#存活性探测延迟时长,即容器启动多久之后再开始第一次探测操作,显示为delay属性.默认值为0,即容器启动后立刻便开始进行探测.periodSeconds:10#执行探测的时间间隔(单位是秒)。默认是 10 秒。最小值是 1秒,过高的频率会对Pod对象带来较大的额外开销,而过低的频率又会使得对错误的反应不及时.successThreshold:1#处于失败状态时,探测操作至少连续多少次的成功才被人为是通过检测,显示为#success属性,默认值为1,最小值也是1timeoutSeconds:3#存活性探测的超时时长,显示为timeout属性,默认值1s,最小值也是1sreadinessProbe:#定义就绪探测器failureThreshold:3#处于成功时状态时,探测操作至少连续多少次的失败才被视为检测不通过,显示为#failure属性.默认值为3,最小值为 就绪探测情况下的放弃 Pod 会被打上未就绪的标签.tcpSocket:# 1.就绪探针三种方式 1.cmd命令方式进行探测 2.http 状态码方式 3.基于tcp端口探测port:32189#应用程序监听端口initialDelaySeconds:10#执行探测的时间间隔(单位是秒)。默认是 10 秒。最小值是 1秒,过高的频率会对Pod对象带来较大的额外开销,而过低的频率又会使得对错误的反应不及时.periodSeconds:10#执行探测的时间间隔(单位是秒)。默认是 10 秒。最小值是 1秒,过高的频率会对Pod对象带来较大的额外开销,而过低的频率又会使得对错误的反应不及时successThreshold:1#处于失败状态时,探测操作至少连续多少次的成功才被人为是通过检测,显示为#success属性,默认值为1,最小值也是1timeoutSeconds:3#存活性探测的超时时长,显示为timeout属性,默认值1s,最小值也是1senv:#环境变量-name: TZ
value: Asia/Shanghai
# JVM env-name: JAVA_OPTS
value:-Xms1024m -Xmx2048m -Dfile.encoding=UTF-8# profile-name: PROFILE
value: dev
volumeMounts:# 使用存储卷-mountPath: /var/logs # 将存储卷挂载到容器内部路径name: log-volume
dnsPolicy: ClusterFirst # 使用宿主机dns ; None 无任何策略 ;ClusterFirst 集群DNS优先;ClusterFirstWithHostNet 集群 DNS 优先,并伴随着使用宿主机网络imagePullSecrets:# 镜像仓库拉取密钥-name: harbor # 镜像Secrets需要在集群中手动创建restartPolicy: Always # 重启策略volumes:# 定义存储卷-name: log-volume # 卷名称hostPath:# 卷类型详细见:https://kubernetes.io/zh/docs/concepts/storage/volumes/path: /data/logs/prod/dnehsa_bizc # 宿主机存在的目录路径type: DirectoryOrCreate # 如果在给定路径上什么都不存在,那么将根据需要创建空目录,权限设置为 0755,具有与 kubelet 相同的组和属主信息-name: sidecar #emptyDir:{}#emptyDir 卷的存储介质(磁盘、SSD 等)是由保存 kubelet 数据的根目录 (通常是 /var/lib/kubelet)的文件系统的介质确定。
创建一个Deployment后,还会自动创建一个Pod。
这边状态显示为Active,说明创建成功。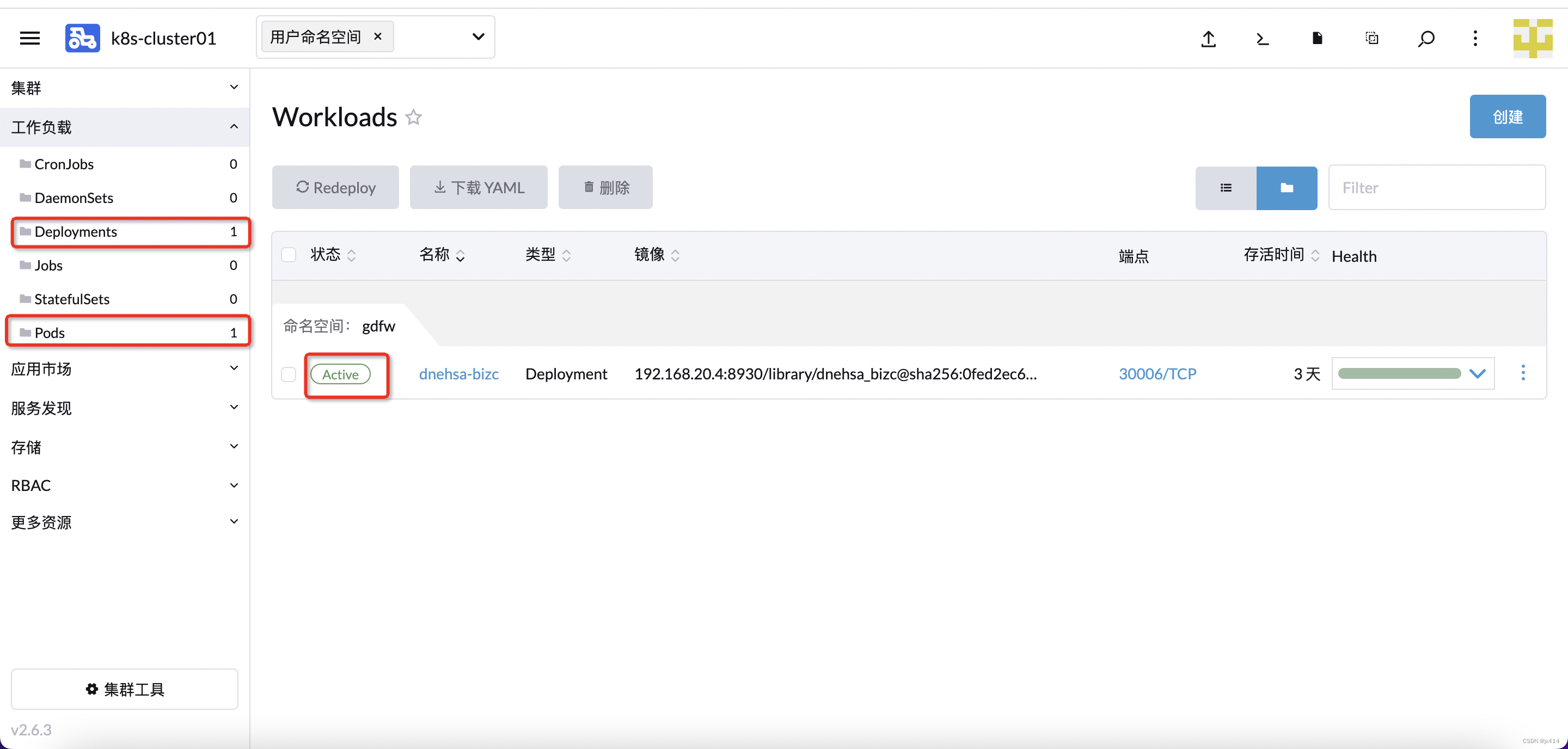
4.4 Pod
Pod 是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元。
Pod(就像在鲸鱼荚或者豌豆荚中)是一组(一个或多个) 容器; 这些容器共享存储、网络、以及怎样运行这些容器的声明。 Pod 中的内容总是并置(colocated)的并且一同调度,在共享的上下文中运行。 Pod 所建模的是特定于应用的 “逻辑主机”,其中包含一个或多个应用容器, 这些容器相对紧密地耦合在一起。 在非云环境中,在相同的物理机或虚拟机上运行的应用类似于在同一逻辑主机上运行的云应用。
除了应用容器,Pod 还可以包含在 Pod 启动期间运行的 Init 容器。 你也可以在集群支持临时性容器的情况下, 为调试的目的注入临时性容器。
4.4.1 什么是 Pod?
说明: 除了 Docker 之外,Kubernetes 支持很多其他容器运行时, Docker 是最有名的运行时, 使用 Docker 的术语来描述 Pod 会很有帮助。
Pod 的共享上下文包括一组 Linux 名字空间、控制组(cgroup)和可能一些其他的隔离方面, 即用来隔离容器的技术。 在 Pod 的上下文中,每个独立的应用可能会进一步实施隔离。
Pod 类似于共享名字空间并共享文件系统卷的一组容器。
4.4.2 使用Pod
Pod 通常不是直接创建的,而是使用工作负载资源创建的。
这边状态显示为Running,说明正在运行。
Execute Shell 可以进入Pod的容器中,相当于执行命令:kubectl exec -it podName -n namespaceName – /bin/sh
View Logs 查看日志,相当于执行命令:kubectl logs -f --tail 500 podName -n namespaceName
4.5 Service
将运行在一组 Pods 上的应用程序公开为网络服务的抽象方法。
使用 Kubernetes,你无需修改应用程序即可使用不熟悉的服务发现机制。 Kubernetes 为 Pod 提供自己的 IP 地址,并为一组 Pod 提供相同的 DNS 名, 并且可以在它们之间进行负载均衡。
动机
创建和销毁 Kubernetes Pod 以匹配集群的期望状态。 Pod 是非永久性资源。 如果你使用 Deployment 来运行你的应用程序,则它可以动态创建和销毁 Pod。
每个 Pod 都有自己的 IP 地址,但是在 Deployment 中,在同一时刻运行的 Pod 集合可能与稍后运行该应用程序的 Pod 集合不同。
这导致了一个问题: 如果一组 Pod(称为“后端”)为集群内的其他 Pod(称为“前端”)提供功能, 那么前端如何找出并跟踪要连接的 IP 地址,以便前端可以使用提供工作负载的后端部分?
进入 Services。
具体可看服务(Service)
4.5.1 创建Service
创建Service成功后,就可以访问到服务了。说明:如果你将 type 字段设置为 NodePort,则 Kubernetes 控制平面将在 --service-node-port-range 标志指定的范围内分配端口(默认值:30000-32767)。详情请看:发布服务(服务类型)
4.5.1.1 使用表单编辑创建Service
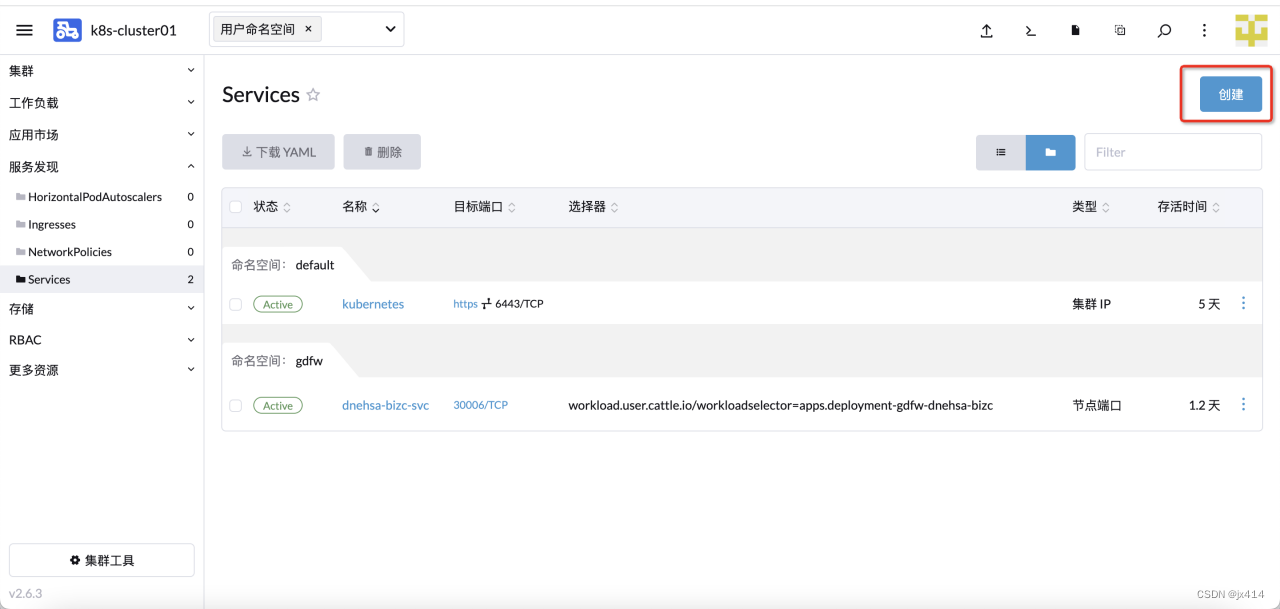

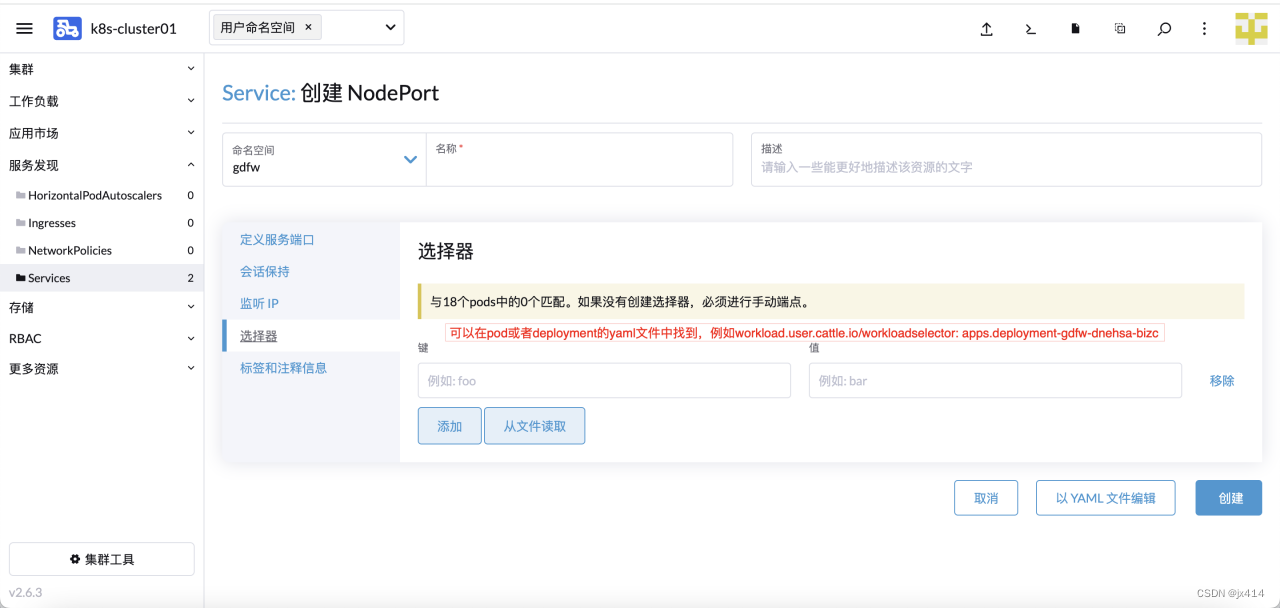
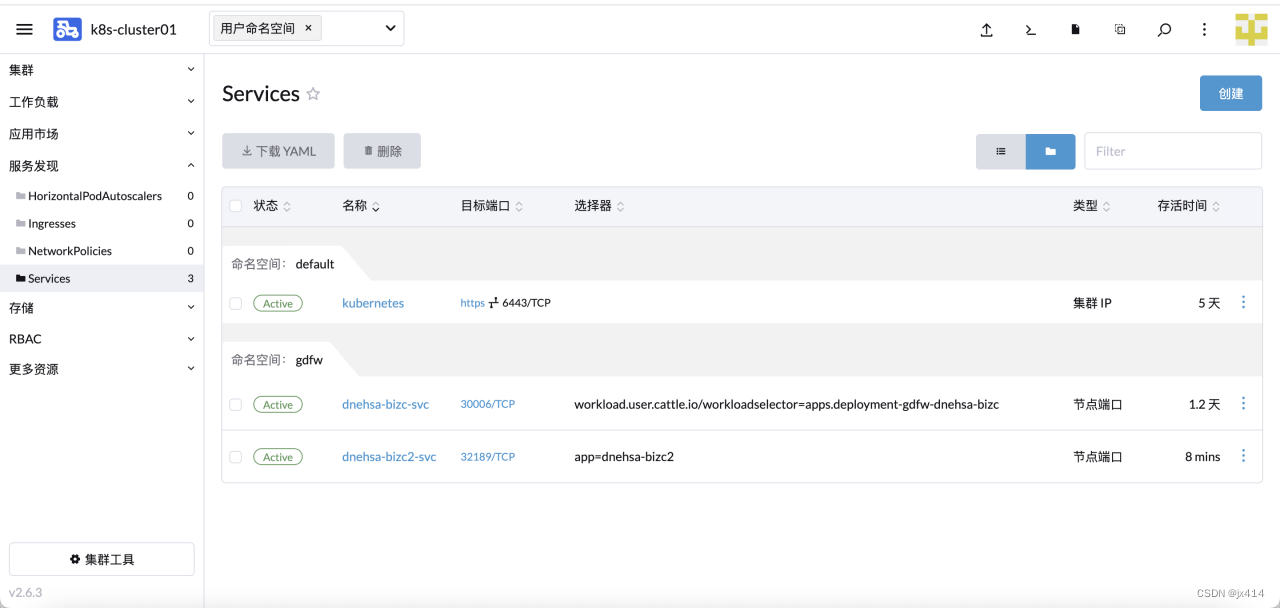
4.5.1.2 使用YAML文件创建Service
下面是具体的字段说明:
apiVersion: v1 # 指定api版本,此值必须在kubectl api-versions中kind: Service # 指定创建资源的角色/类型 metadata:# 资源的元数据/属性name: dnehsa-bizc-svc # 资源的名字,在同一个namespace中必须唯一namespace: gdfw # 部署在哪个namespace中labels:# 设定资源的标签app: dnehsa-bizc-svc
spec:# 资源规范字段type: NodePort # 类型:集群IP,外部DNS服务名称,Headless,负载均衡器,节点端口ports:-name: dnehsa-bizc-svc # 端口名称nodePort:30006# 节点端口port:30006# 监听端口protocol: TCP # 协议targetPort:30006# 目标端口selector:# 选择器app: dnehsa-bizc
版权归原作者 jx414 所有, 如有侵权,请联系我们删除。