
一、什么是ClickHouse
- clickHouse是俄罗斯的 Yandex 公司于 2016 年开源的列式存储数据库,使用 C++ 语言编写;
- 一款面向 OLAP 的数据库
- ClickHouse支持类SQL语言,提供了传统关系型数据的便利
二、ClickHouse有什么用途
专门用于 OLAP(联机分析处理),其性能惊人;
什么是 OLAP? 联机分析处理,又可以称之为多维分析处理。它指的是通过多种不同的维度审视数据,进行深层次分析。
三、ClickHouse的不足
高性能面向 OLAP 的数据库,不擅长的方面:
- 不支持事务
- 不擅长根据主键按行粒度进行查询(虽然支持),所以不应该把 ClickHouse 当做键值对数据库使用
- 不擅长按行删除数据(虽然支持)
对于 OLAP 数据库而言,上述这些能力不是重点,只能说这是为了极致的查询性能所做的权衡。
四、适用场景
- 绝大多数请求都是读取访问权限。
- 数据以相当大的批次(> 1000行)更新,而不是单行更新; 或者它根本没有更新。
- 数据已添加到数据库,但未进行修改。
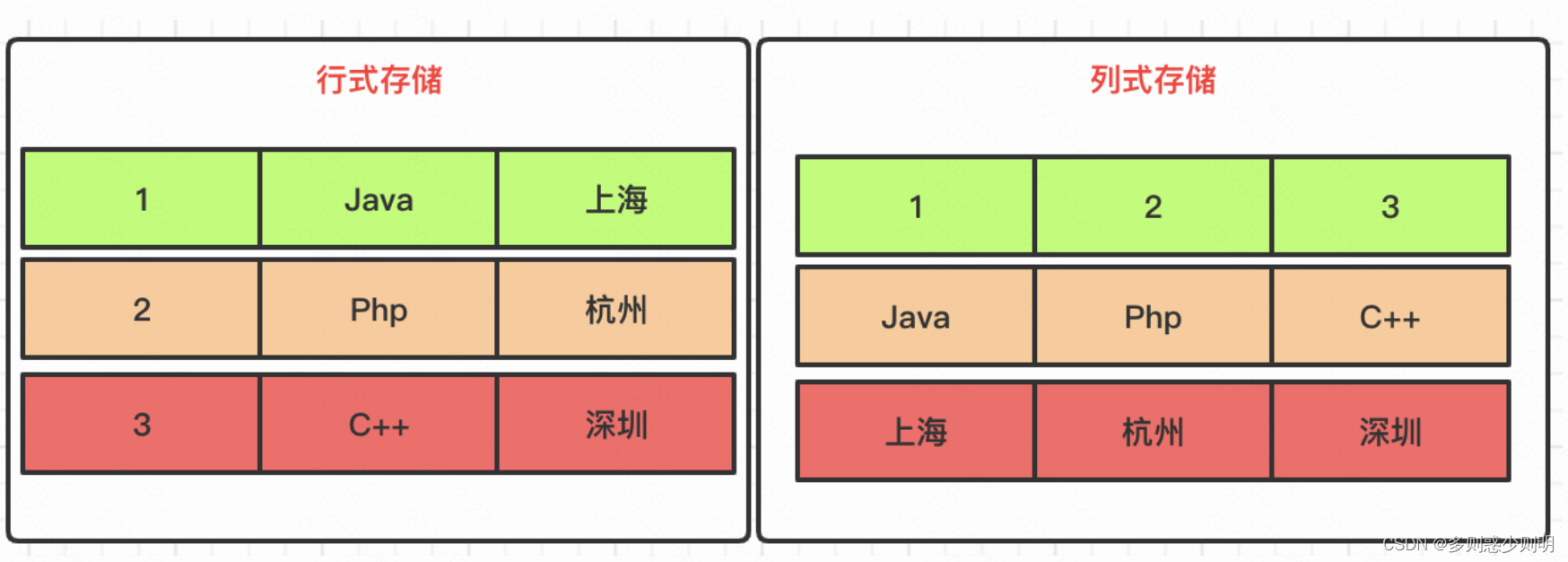
- 读取数据时,会从数据库中提取出大量的行,但只用到一小部分列 列式存储
- 数据一致性要求较低
五、ClickHouse特点
完备的DBMS功能
列式存储和数据压缩列式存储,在扫描指定列时,不用按行组织其他非指定列的数据,避免多余的数据扫描。数据压缩,按照一定步长对数据进行匹配扫描,当发现重复部分的时候就进行编码转换,降低IO和存储的压力。
向量化执行引擎简单理解就是消除程序循环的优化,堆机器加快速度,数据级并行。
关系模型与SQL查询
其他数据库迁移到CK的成本很低。多样化的表引擎CK的最初架构是基于MySQL实现的,表引擎设计就与MySQL类似,存储引擎作为一层独立的接口。种类繁多,根据业务场景自行选择。
多线程与分布式
多线程处理就是通过线程级并行的方式实现了性能的提升。 预先将数据分布到各台服务器,将数据的计算查询直接下推到数据所在的服务器,因为计算移动比数据移动更加划算。多主架构
Multi-Master多主架构,集群中的每个节点角色对等,天然规避单点故障问题,适用于多数据中心、异地多活场景
- 在线查询,CK又快又免费
与其他分析型数据库对比,存在许多相似之处,例如都支持海量查询场景、支持列式存储、数据分片、计算下推等特效,说明CK在设计上吸取了各路优点。
价格方面:其他开源系统慢,商用系统贵。CK又快又免费。
数据分片和分布式查询
CK有本地表(Local Table)和分布式表(Distributed Table),一张本地表等同于一份数据的分片,而分布式表不存储数据,只是本地表的访问代理。 分布式表类似分库中间件,代理访问多个数据分片,实现分布式查询。
六、CH表对比
1、ClickHouse VS MySQL
- MySQL单条SQL是单线程的,只能跑满一个core,ClickHouse相反,有多少CPU,吃多少资源,所以飞快;
- ClickHouse不支持事务,不存在隔离级别。ClickHouse的定位是分析性数据库,而不是严格的关系型数据库。
- IO方面,MySQL是行存储,ClickHouse是列存储,后者在count()这类操作天然有优势,同时,在IO方面,MySQL需要大量随机IO,ClickHouse基本是顺序IO。
2、ClickHouse VS Druid
参考:https://www.sohu.com/a/516246493_411876

在广告场景下,基于benchmark分析来看,ClickHouse会比druid有许多可取之处:
- 数据存储方面,ClickHouse的数据压缩和列式存储会极大节省存储空间,而druid和其他多数数据库都是基于时序的,druid在查询大范围的数据时会出现性能问题,而利用ClickHouse的分区键优化可以有效的解决这个问题
- 在查询方面,druid的排序,聚合能力都不太好,灵活性和扩展性也不够,比如缺少join,子查询,主键排序等这些需求。而这些用SQL都可以通过ClickHouse来支持解决。
- 运维成本方面,Druid的运维是非常复杂的,虽然支持多种数据摄入的组件,但是组件的构成是比较复杂的,节点数量有6种之多,而ClickHouse架构采用的是对等节点的设计,节点就有一种类型,没有主从节点。
七、类SQL 语句
1、 客户端登陆命令 : clickhouse-client -u user --password 123456 --port 9000
2、利用system数据库中的parts_columns表进行查询。
select distinct column from system.parts_columns
where database='表所属的数据库名称' and table='所需要查询的表名'
例如:
select distinct column from system.parts_columns where database='test' and table='table1'
3、利用system数据库中的columns表进行查询。
select distinct name from system.columns
where database='表所属的数据库名称' and table='所需要查询的表名'
例如:
select distinct name from system.columns where database='test' and table='table1'
ps :–推荐使用第二种方式来查询表的所有列名。
4、
alter table 表名称 ON 集群名称 add column 列名称; --添加列
alter table 表名称 ON 集群名称 drop column 列名称; --删除列
alter table 表名称 ON 集群名称 modify column 列名称 数据类型; --修改数据类型
alter table 表名称 ON 集群名称 COMMENT COLUMN 列名称 注解; --修改注释
5、建表
CREATE TABLE test.table1(
`id` String COMMENT '主键',
`chinese_name` Nullable(String) COMMENT '中文名称',
`english_name` Nullable(String) COMMENT '英文名称',
`update_time` Nullable(DATETIME) COMMENT '更新时间',
`create_time` Nullable(DATETIME) COMMENT '创建时间'
)
ENGINE = MergeTree
order by id
6、删除表
//删除本地表
DROP table ti.java4al_base on cluster ck;
//删除分布式表
DROP table ti.java4al_base_all on cluster ck;
7、删除数据:
方法1: 删除分区 alter table name drop partition 分区;
方法:alter 语句 : alter table name delete where
ALTER TABLE <table_name> UPDATE col1 = expr1, ... WHERE <filter>
方法:
索引列不能进行更新
8、查询表容量及压缩
select
table as "表名",
sum(rows) as "总行数",
formatReadableSize(sum(data_uncompressed_bytes)) as "原始大小",
formatReadableSize(sum(data_compressed_bytes)) as "压缩大小",
round(sum(data_compressed_bytes) / sum(data_uncompressed_bytes) * 100, 0) "压缩率"
from system.parts
group by table;
八、核心概念
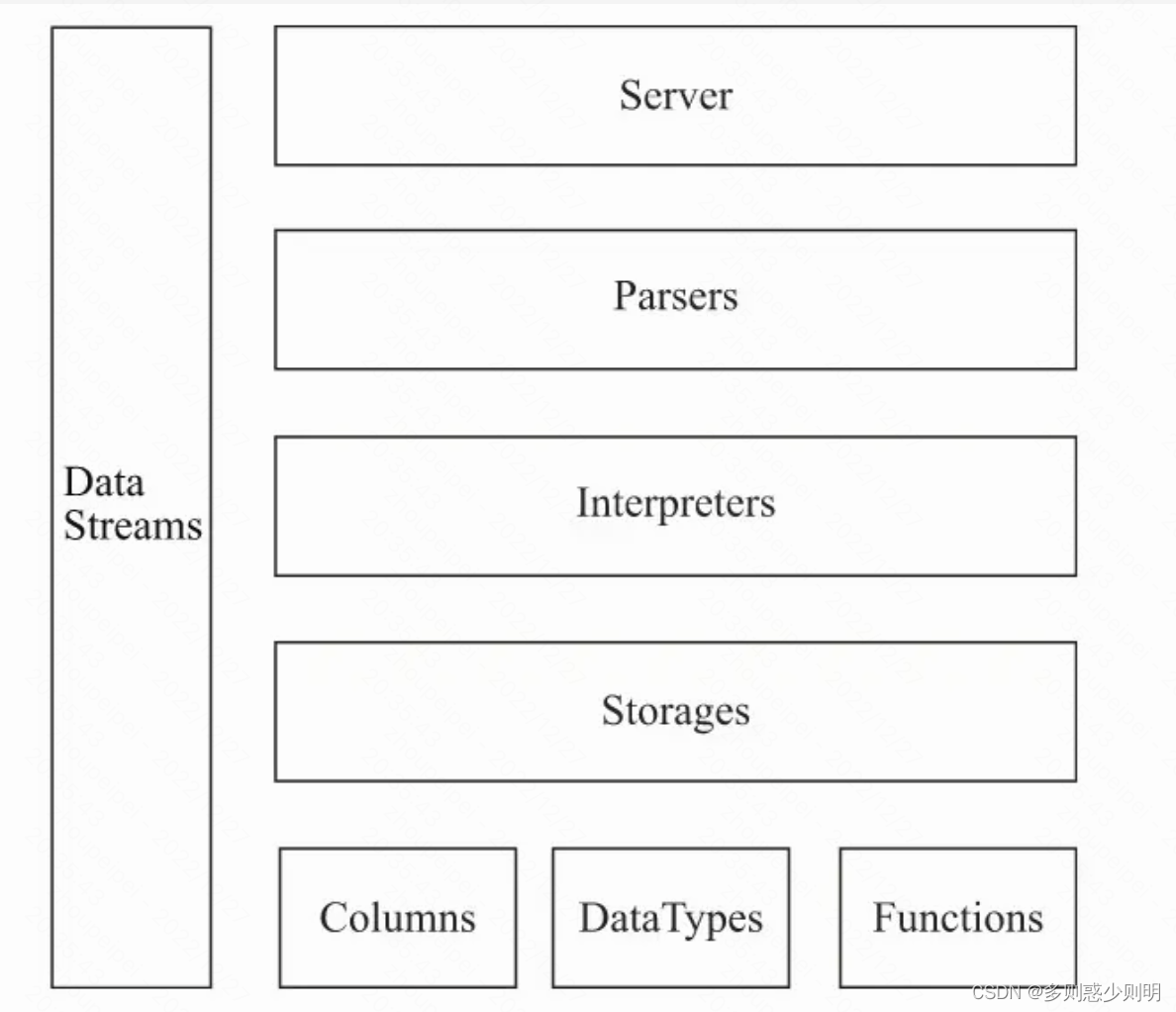
几个概念:
1、Column与Field:一列中的某一行(具体数值)用Field对象表示;一列数据用一个Column对象表现
2、DataType : 负责数据的序列化和反序列化相关工作,但是并不直接负责数据的读取,而是转由Column或Field对象获取。在DataType的实现类中,聚合了相应数据类型的Column对象和Field对象。
3、Block对象:CK的数据操作是面向Block对象进行的,并且是采用流的形式。Block=数据对象(Column/Feild) + DataType + 列名称字符串。
4、Table:
在数据表的底层设计中并没有所谓的Table对象,它直接使用 IStorage接口指代数据表。
表引擎是ClickHouse的一个显著特性, 不同的表引擎由不同的子类实现,例如IStorageSystemOneBlock (系统表)、StorageMergeTree(合并树表引擎)和 StorageTinyLog(日志表引擎)等。
5、Parser和Interpreter
Parser分析器负责创建AST对象,而Interpreter解释器则负责解释AST,并进一步创建查询的执行管道。它们与IStorage一起,串联起了整个数据查询的过程。
Parser分析器可以将一条SQL语句以递归下降的方法解析成 AST语法树的形式。
不同的SQL语句,会经由不同的Parser实现类解析。
6、Functions与Aggregate Functions
- 普通函数,例如四则运算、日前转换、网址提取函数、IP地址脱敏函数。没有状态,函数效果作用于每行数据之上。在函数具体执行过程中,采用向量化的方式直接作用于一整列数据,而不是一行一行计算。
- 聚合函数,有状态的,例如COUNT聚合函数,AggregateFunctionCount的状态用整型UInt64记录。聚合函数 的状态支持序列化与反序列化,所以能够在分布式节点之间进行传 输,以实现增量计算。
7、Cluster与Replication
集群由分片(Shard)组成,分片由副本(Replica)组成。
CK的1个节点只能拥有一个分片,如果要实现1分片、1副本,至少需要部署两个服务节点。
分片是逻辑概念,物理承载由副本承担。
版权归原作者 多则惑少则明 所有, 如有侵权,请联系我们删除。