
1.1网络配置(建议用管理员权限启动虚拟机,防止出现权限不足或者lock等问题)
1.11打开虚拟机点击安装好的centos系统

1.12点击虚拟机的编辑后选择虚拟网络编辑器

1.13点击VMnet8
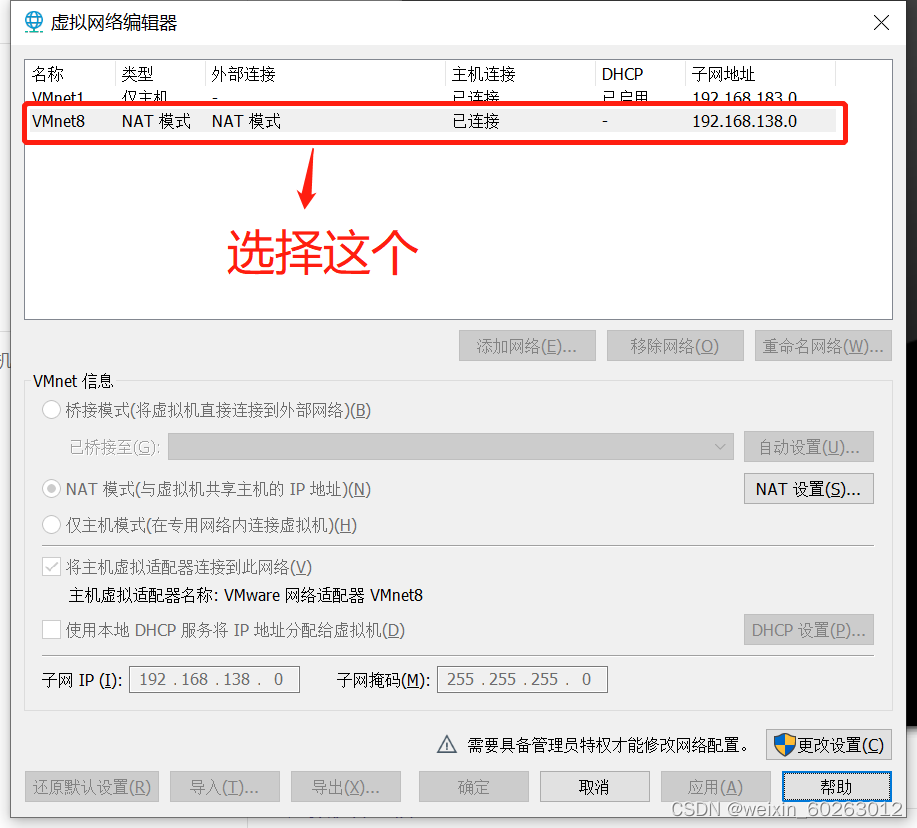
1.14点击NAT设置并关闭
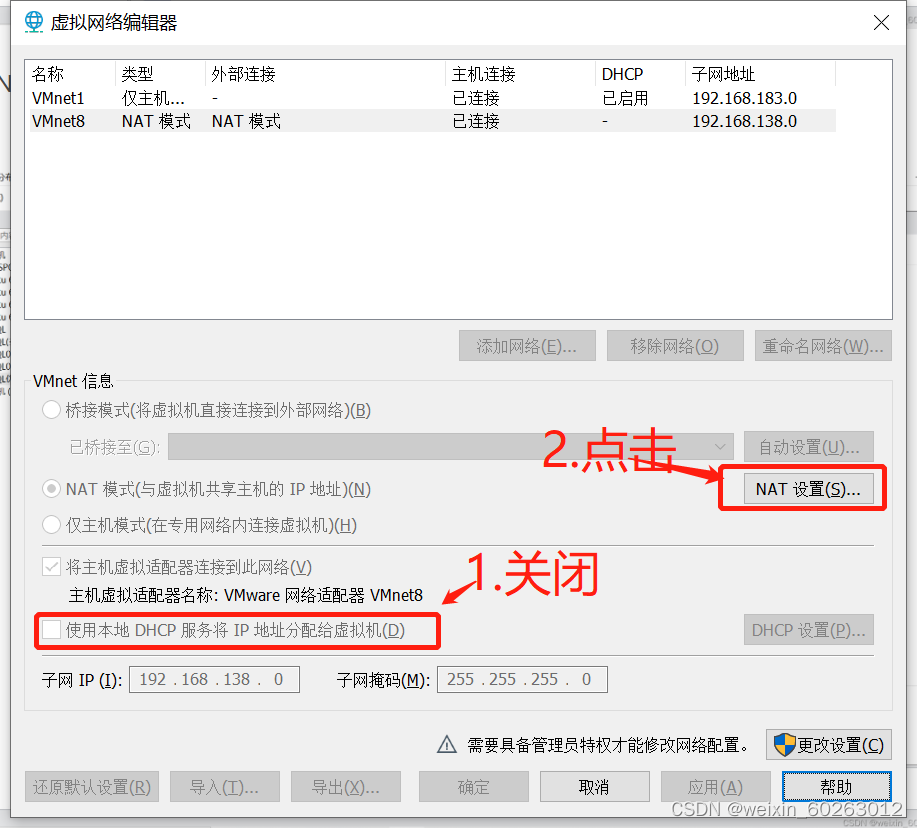
1.15查看网关IP并记住(我这边是192.168.138.2)

1.16打开主机网络点击更改设备选择器
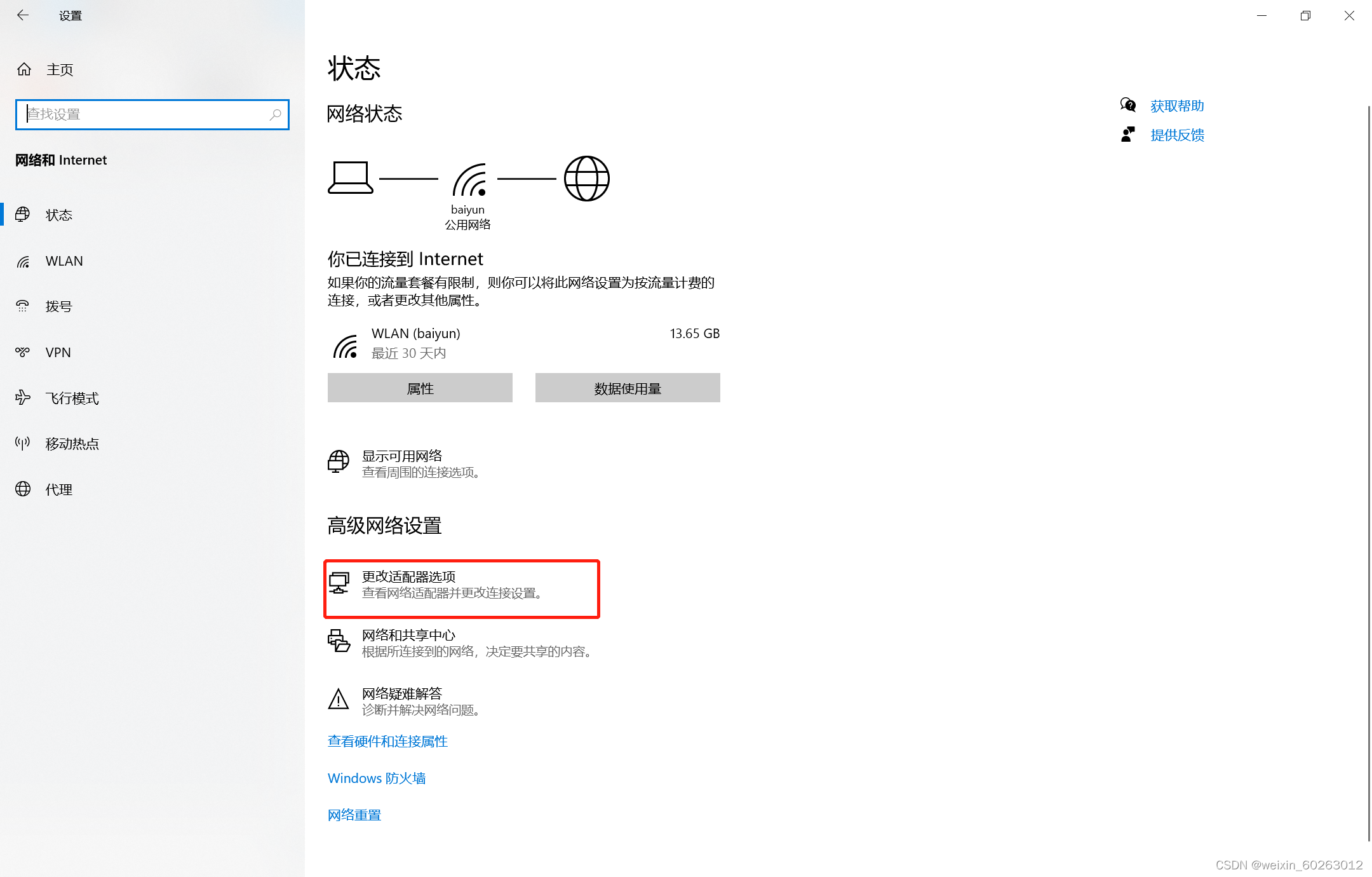
1.17点击VMnet8后右键点击属性

1.18选择Internet协议版本4(TPC/IPv4)
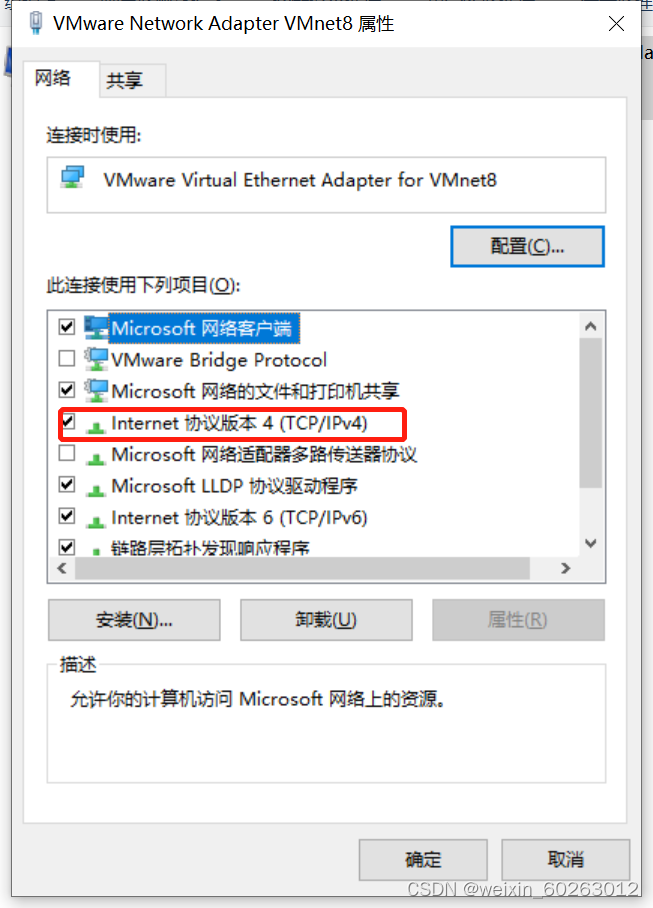
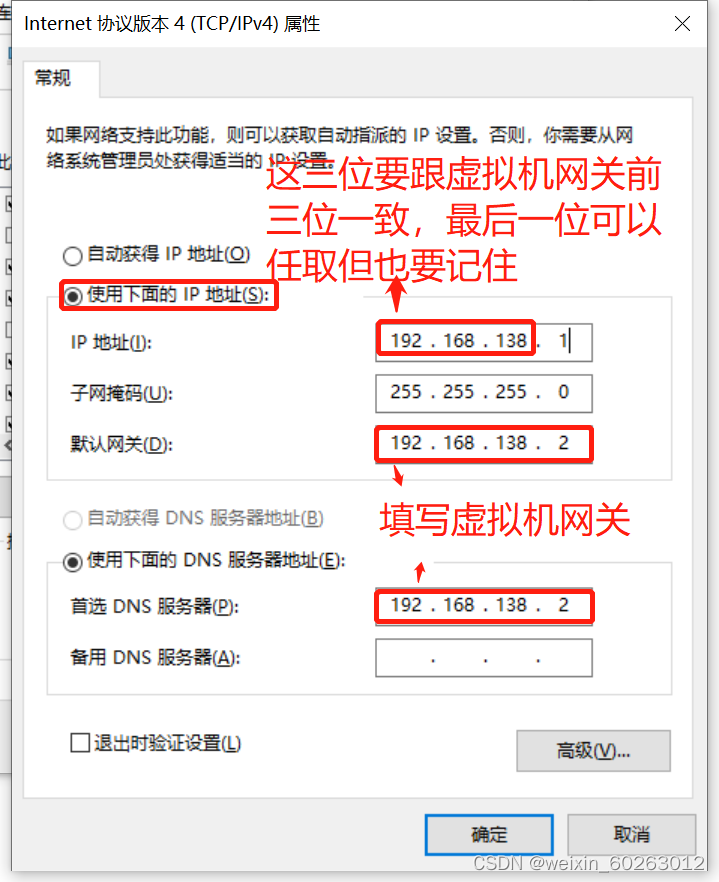
1.19 IP、网关配置(配置完网络环境后千万不要去共享网络不然xshell和xftp到时候连接不上虚拟机系统。)
1.2启动centos系统,进行centos网络配置
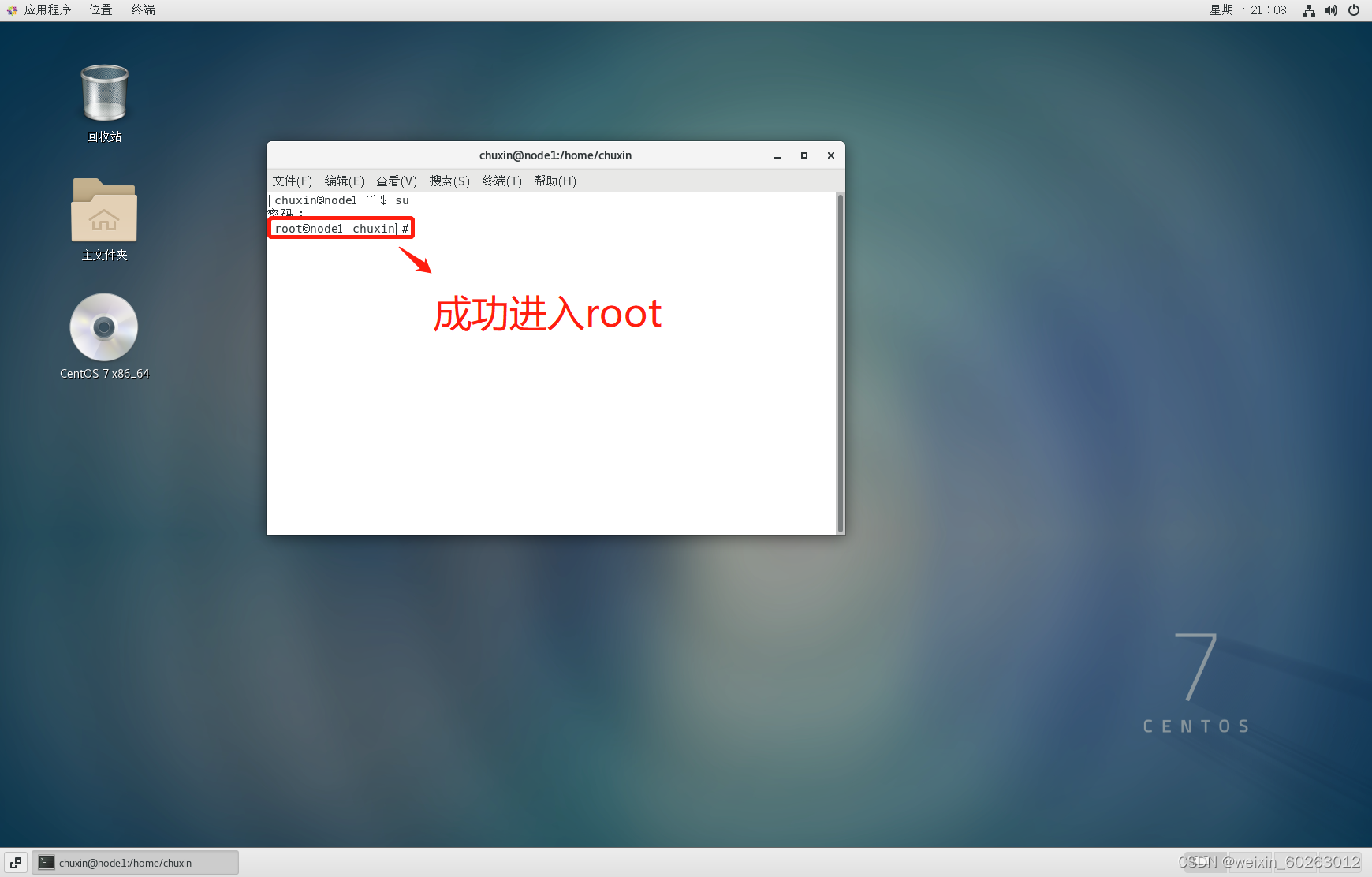
1.21右键桌面打开终端,输入su指令按Enter键后输入密码进入root用户(为了更好的完成下面配置)
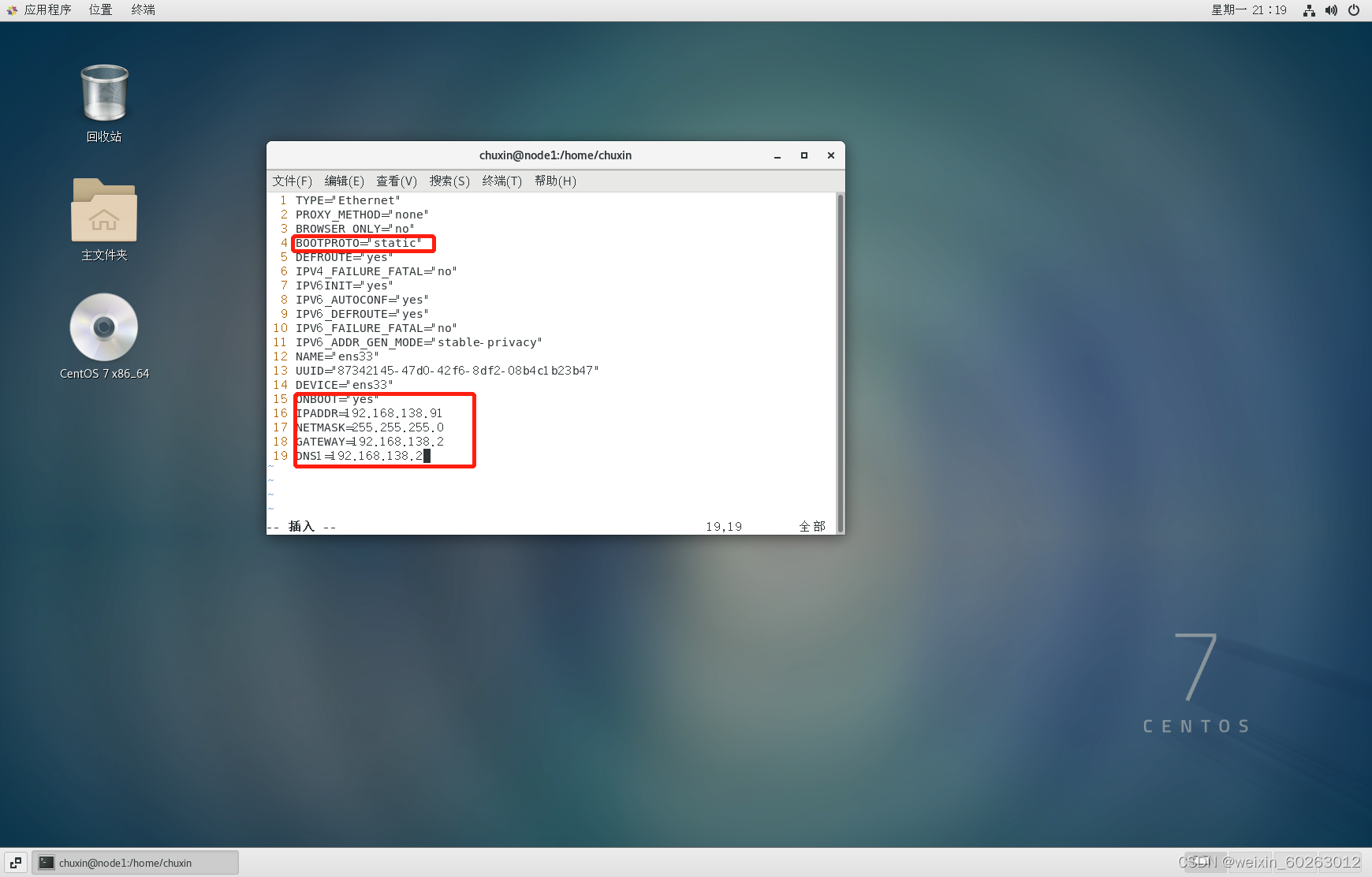
1.22进入网络配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33
把BOOTPROTO修改为static ONBOOT修改为yes
添加(IPADDR前三位要跟虚拟机网关一致,NETMASK跟主机网络配置一致,GATEWAY,DNS1填写虚拟机网关,如果不配做DNS1会出现ping不通域名)
这里以虚拟网关为192.168.138.2为例子进行配置,每台机的虚拟机网关都不一样,请勿完全照搬!
IPADDR=192.168.138.91
NETMASK=255.255.255.0
GATEWAY=192.168.138.2
DNS1=192.168.138.2
配置完后重启网络
重启网络
service network restart
1.23测试网络(先把防火墙关了)
关闭防火墙命令
systemctl stop firewalld.service
开启防火墙
systemctl start firewalld.service
关闭开机自启动
systemctl disable firewalld.service
开启开机启动
systemctl enable firewalld.service
查看防火墙状态
systemctl status firewalld.service
测试
ping www.baidu.com
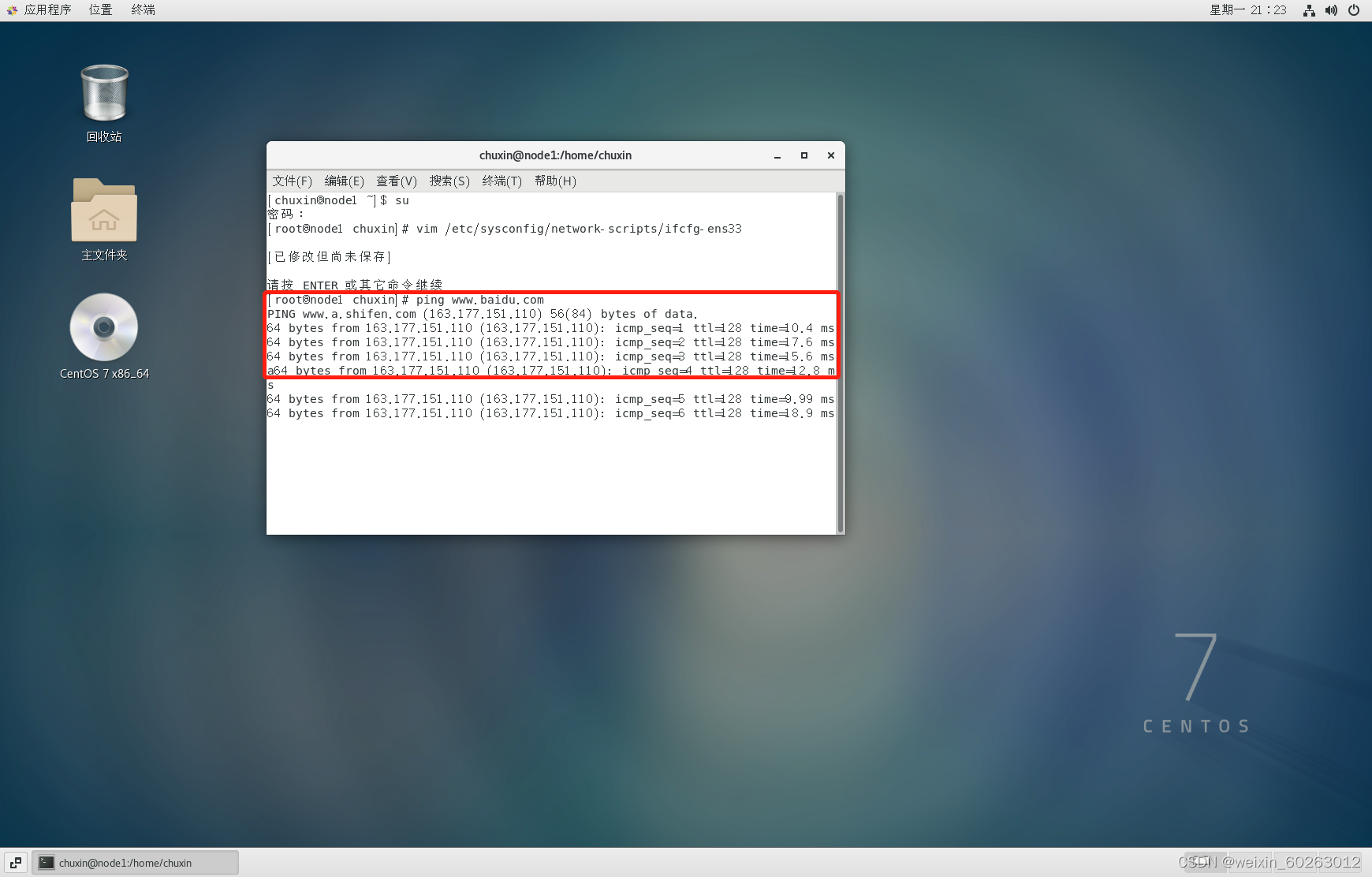
使用Ctrl+Z停止ping百度
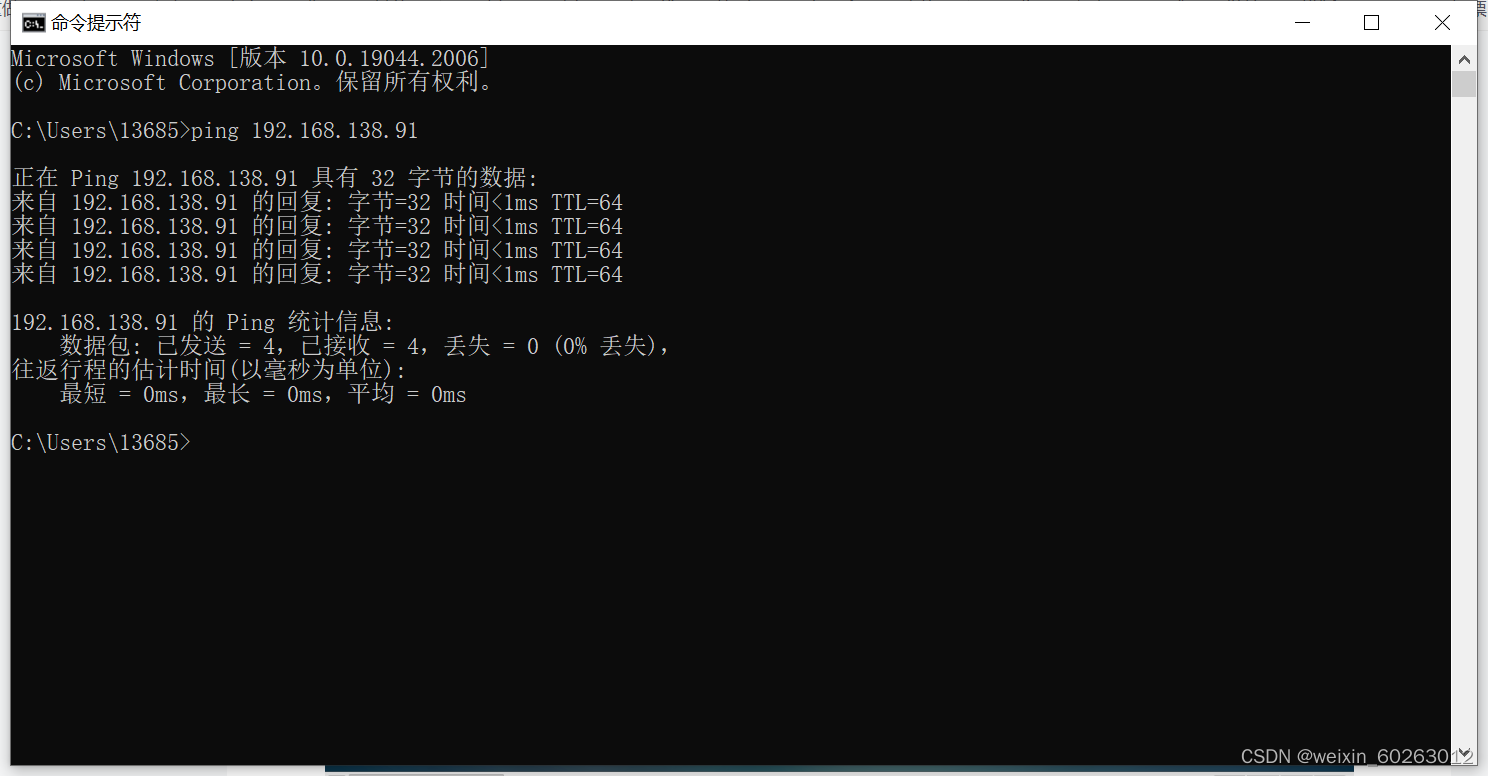
主机ping虚拟机(如果ping不通很大可能是虚拟机防火墙未关闭)
虚拟机ping主机(如果ping不通主机IP很大可能是主机防火墙未关闭)
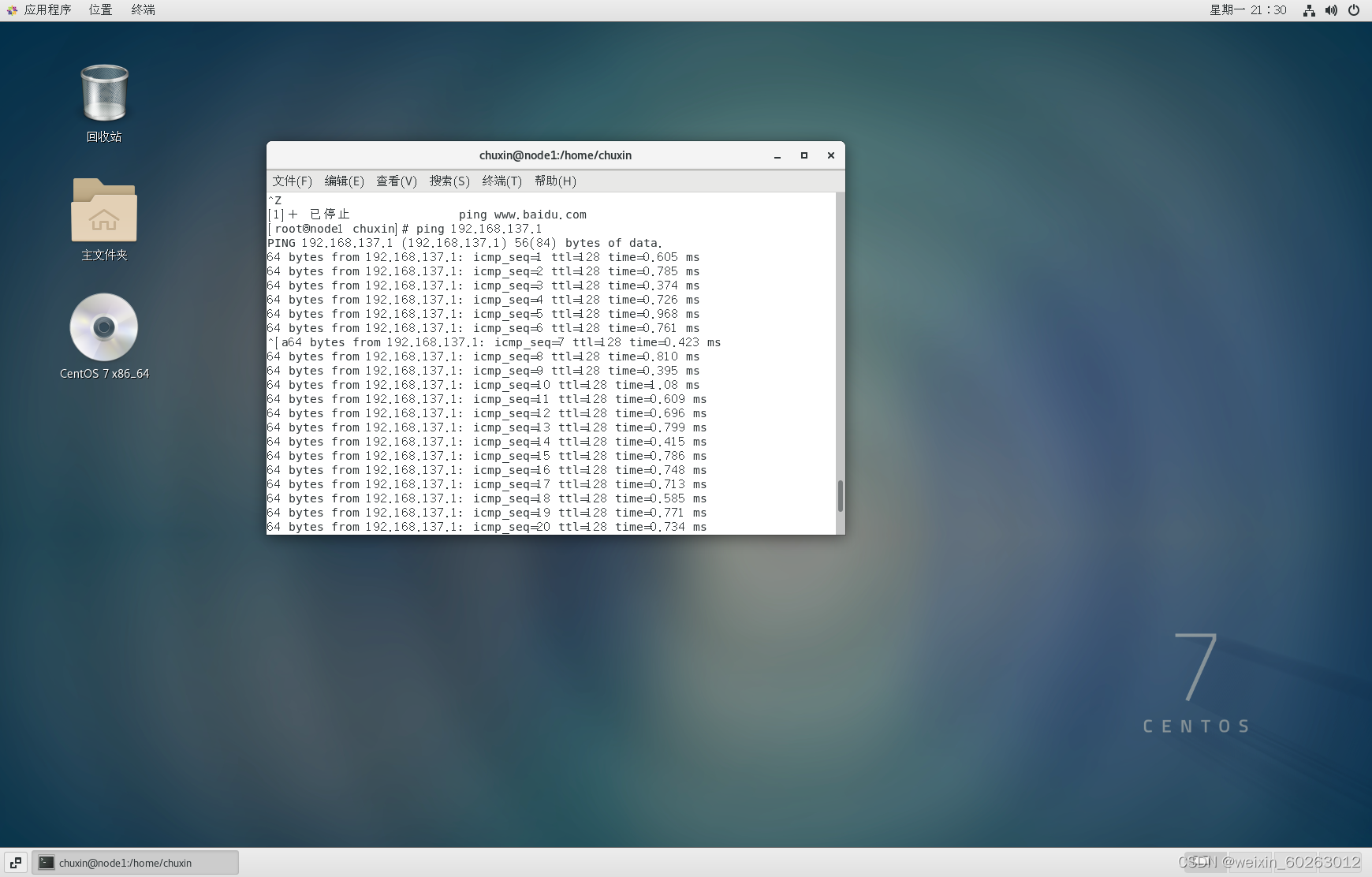
使用Ctrl+Z停止ping主机IP
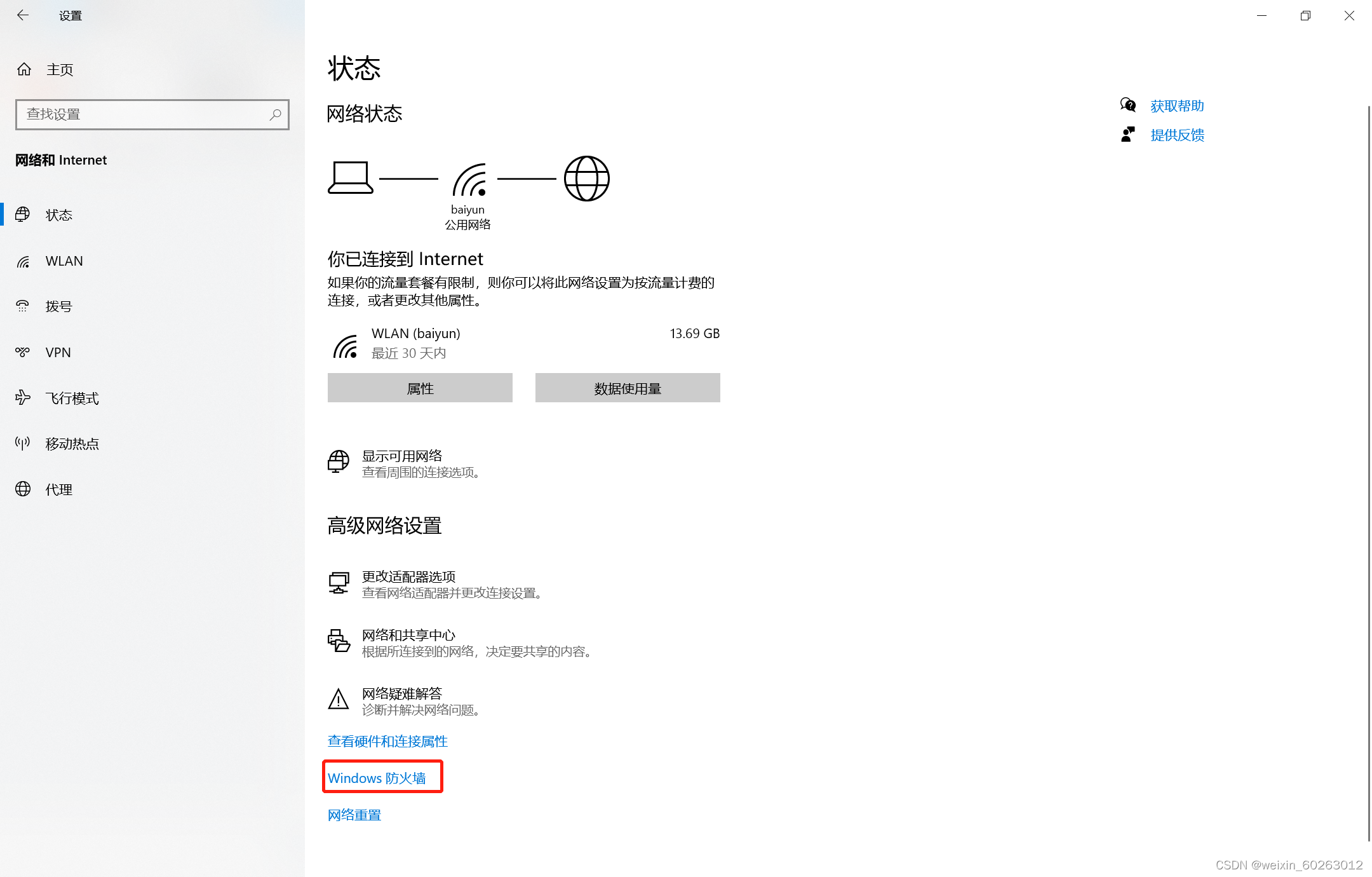
1.24解决虚拟机ping不通主机IP方法
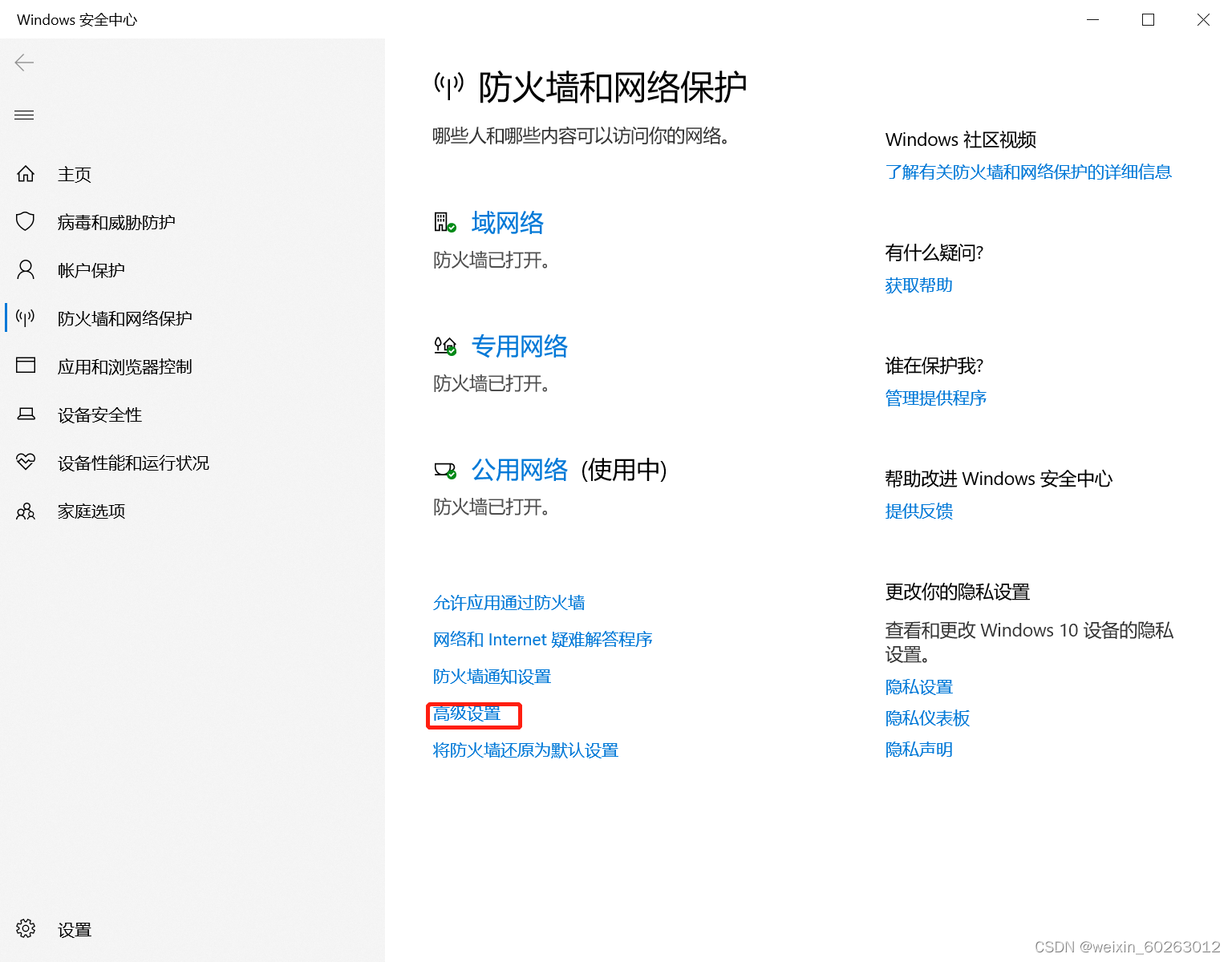
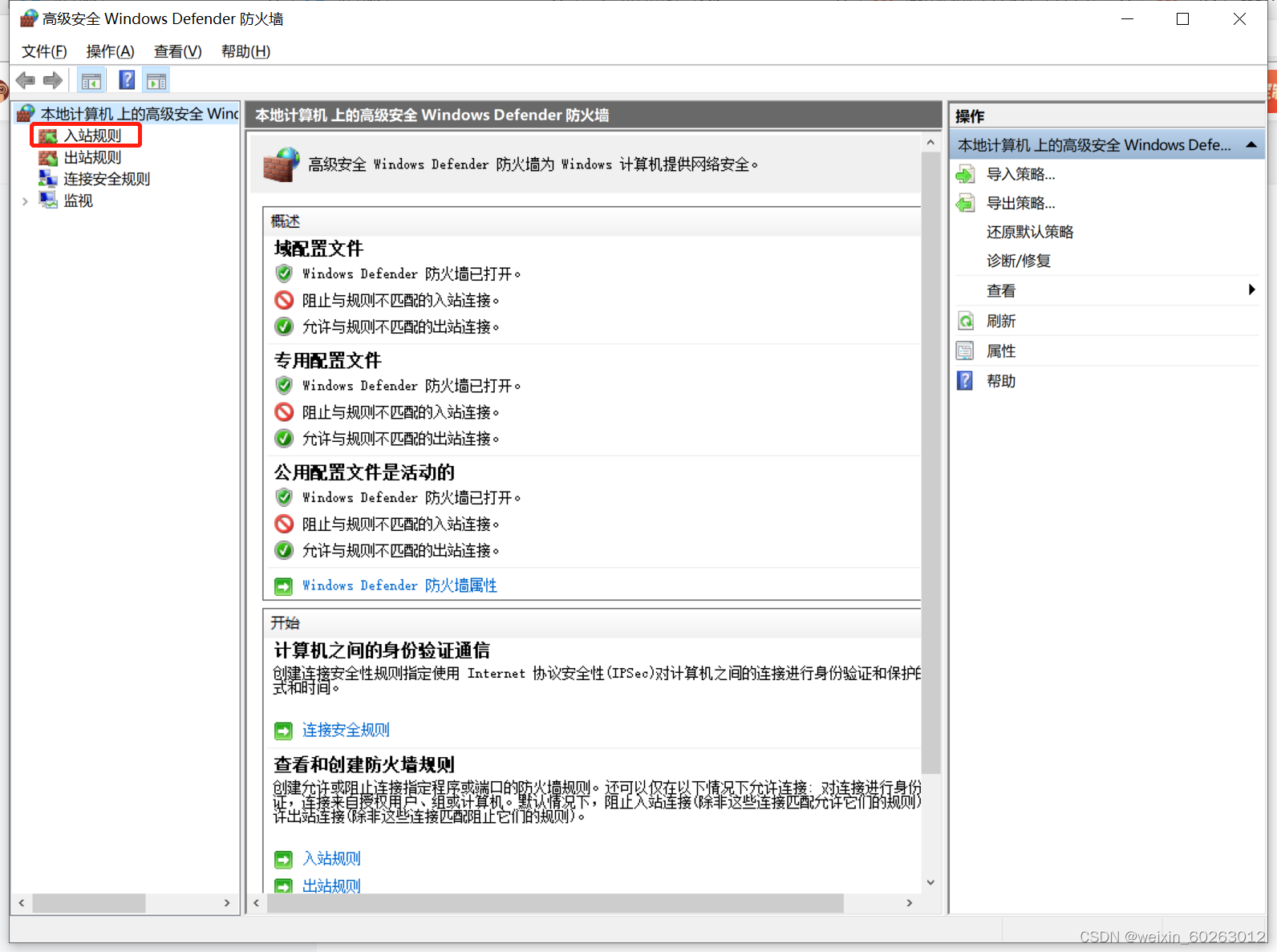
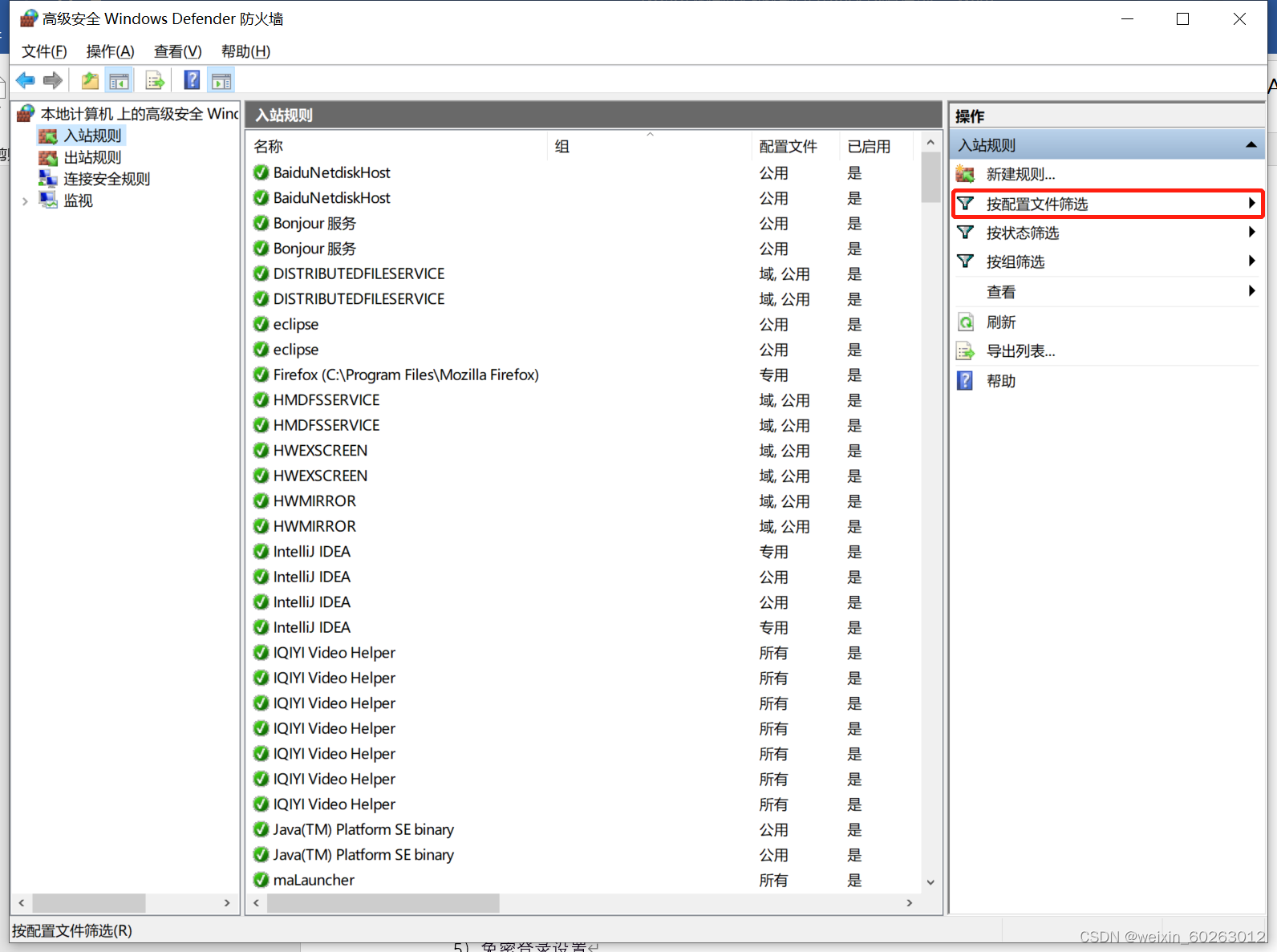
打开主机网络打开防火墙选择高级设置点击入站规则点击按配置文件筛选后选择按公用配置文件筛选找到(回显请求 – ICMPv4-In)改为允许。

2.1hadoop集群搭建(建议用管理员权限启动虚拟机,防止出现权限不足或者lock等问题,在配置hadoop集群过程中建议切换到root用户下进行配置)
2.11修改主机名(这里修改为node1)
hostnamectl set-hostname node1
查看主机名
hostname
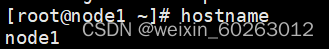
配置主机名(如果忘记主机IP可以用ifconfig命令来查询)
vim /etc/hosts
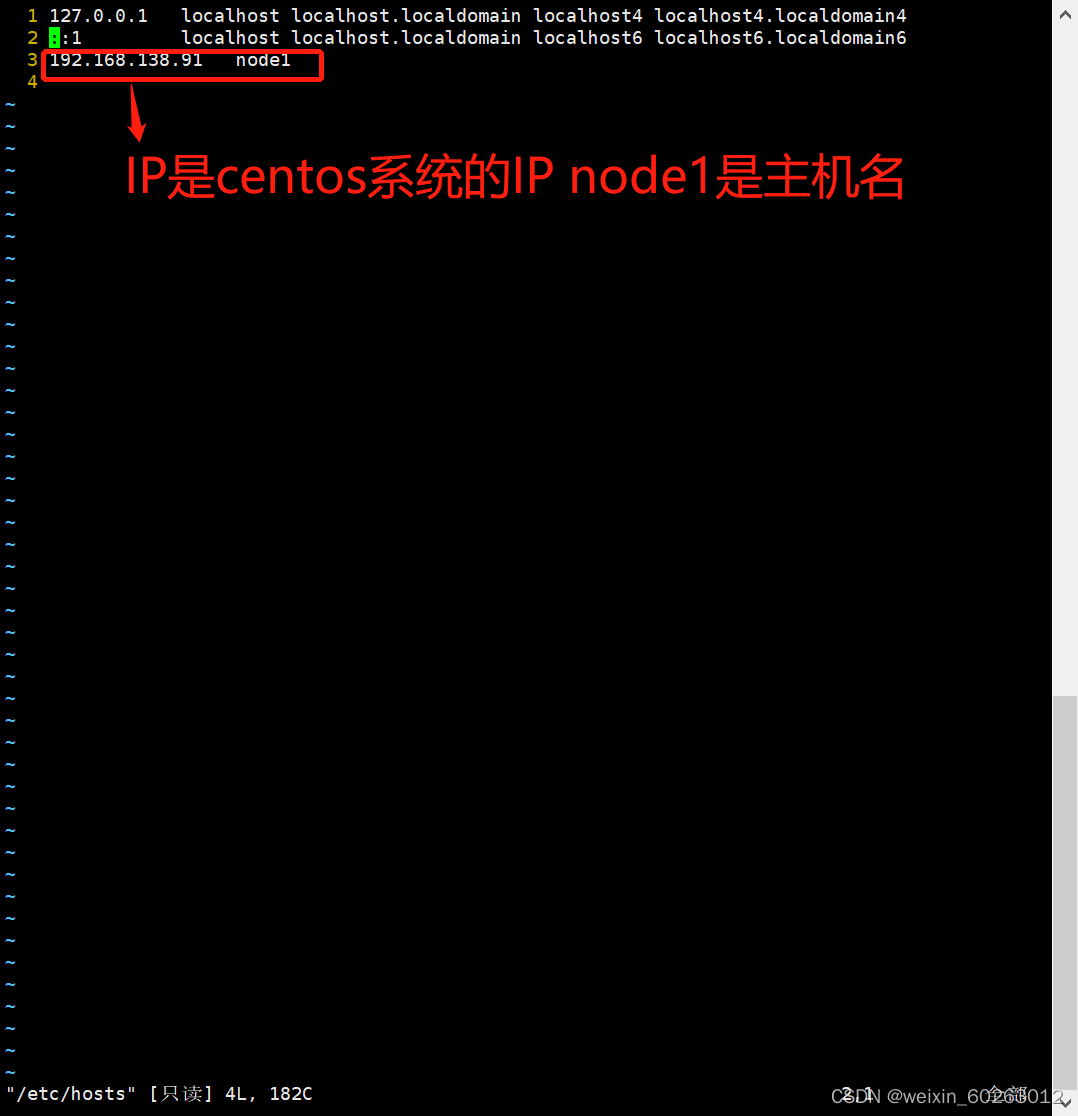
免密码登录配置
执行
ssh-keygen -t rsa
按三次Enter键如果中途出现选择请选择yes
公钥追加到~/.ssh/authorized_keys文件中
ssh-copy-id -i ~/.ssh/id_rsa.pub 主机名(如上面都node1)
测试免密码登录:
ssh node1
2.12.准备好以下这个压缩包(百度网盘提取码1221)

压缩包下载链接
3.1安装jdk
3.11卸载原先的java jdk
rpm -qa | grep java
根据显存版本进行卸载操作
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64
3.12安装jdk
将jdk压缩包拷贝到虚拟机系统的一个目录上(这里拷贝到/usr/java下,一般来说usr目录下是没有java文件夹需要自己创建一个 (mkdir java))
在java目录下进行解压压缩包
tar -zxvf 压缩包名称
修改配置文件
vim ~/.bashrc
在文件的最后添加下面的jdk信息
export JAVA_HOME=centos系统中的jdk路径
export CLASSPATH=$JAVA_HOME/lib/
export PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
配置完成后执行下面代码使环境变量生效
source ~/.bashrc
查看java版本
java -version
3.13hadoop安装
进入hadoop压缩包目录
解压hadoop压缩包
tar -zxvf 压缩包名
可创建文件软链接,简化配置
ln -s 解压后文件名 hadoop
配置环境变量
vim ~/.bashrc
在文件的最后添加下面的hadoop信息
export HADOOP_HOME=hadoop路径
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
配置完成后执行下面代码使环境变量生效
source ~/.bashrc
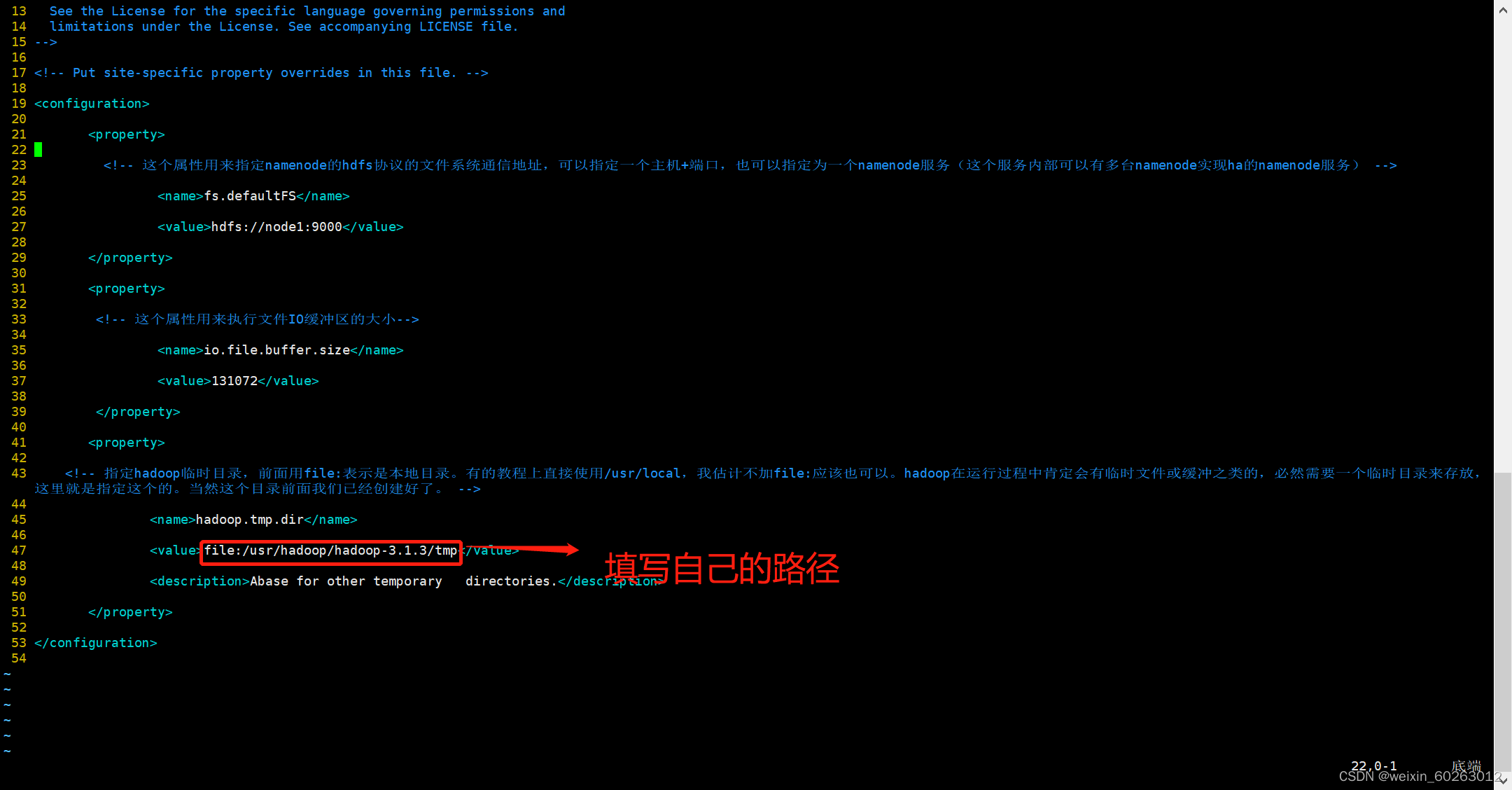
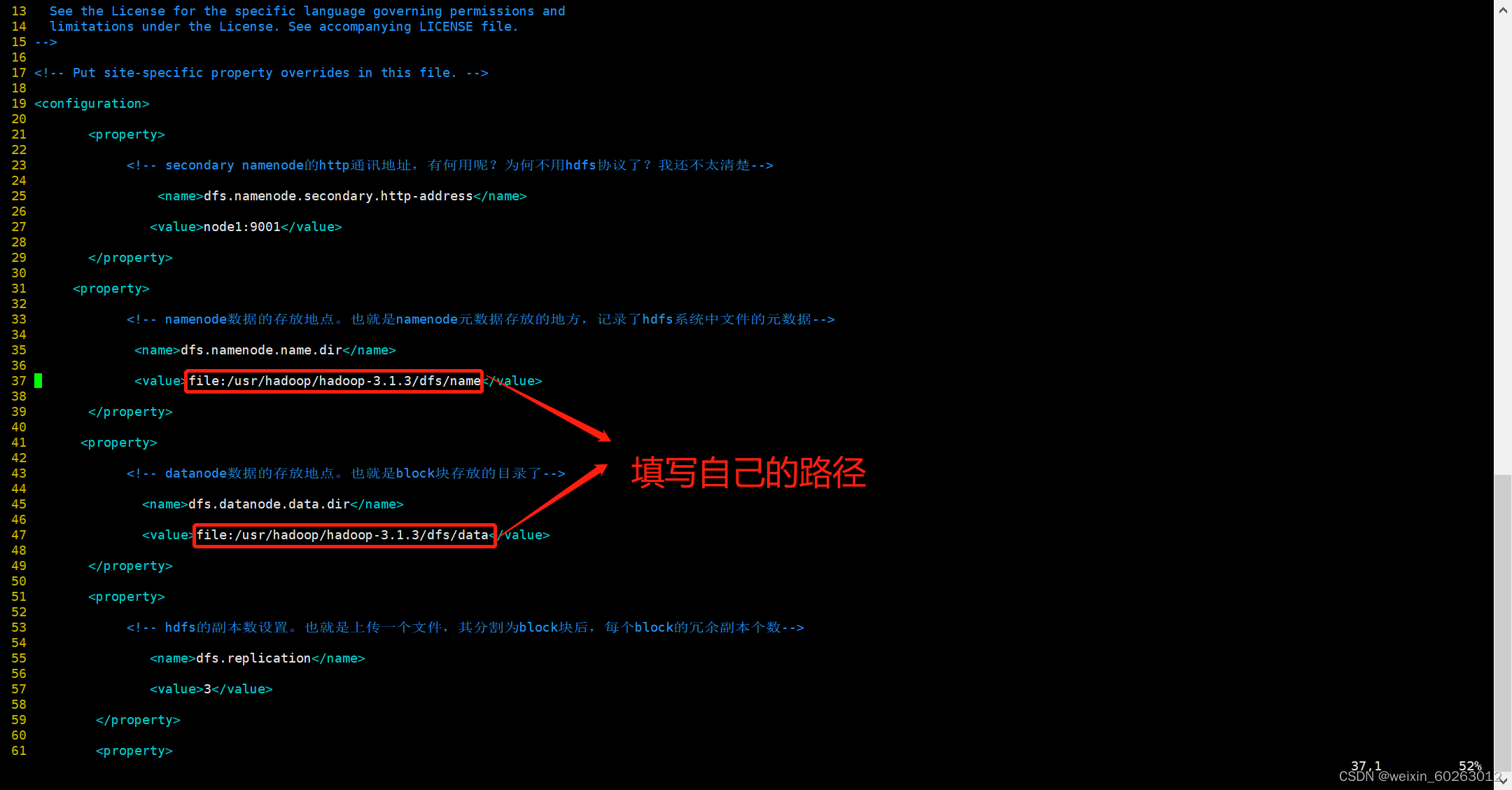
总共要修改的配置文件全部都在hadoop/etc/hadoop目录下,其中hdfs-site.xml这个文件需要设置3个目录来存放一些hadoop运行过程中的临时数据,也就是在hadoop目录下,创建一个dfs和tmp,再在dfs目录下创建name和data目录。hadoop的八个配置文件中,有3个配置文件只需要修改jdk路径。分别是hadoop-env.sh,yarn-env.sh,mapred-env.sh。找到 export JAVA_HOME= , 等号后面改成centos系统中的jdk路径 即可。 当然,如果前面有#注释,可以把注释去掉(一般都没有注释)。
进入hadoop/etc/hadoop目录
3.131core-site.xml配置
执行
vim core-site.xml
<configuration>
<property>
<!-- 这个属性用来指定namenode的hdfs协议的文件系统通信地址,可以指定一个主机+端口,也可以指定为一个namenode服务(这个服务内部可以有多台namenode实现ha的namenode服务) -->
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
<property>
<!-- 这个属性用来执行文件IO缓冲区的大小-->
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:hadoop中tmp文件夹路径</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
3.132hdfs-site.xml配置
执行
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:9001</value>
</property>
<property>
<!-- namenode数据的存放地点。也就是namenode元数据存放的地方,记录了hdfs系统中文件的元数据-->
<name>dfs.namenode.name.dir</name>
<value>file:hadoop的dfs中的name文件夹路径</value>
</property>
<property>
<!-- datanode数据的存放地点。也就是block块存放的目录了-->
<name>dfs.datanode.data.dir</name>
<value>file:hadoop的dfs中的data文件夹路径</value>
</property>
<property>
<!-- hdfs的副本数设置。也就是上传一个文件,其分割为block块后,每个block的冗余副本个数-->
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<!-- 开启hdfs的web访问接口。好像默认端口是50070-->
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
3.133配置mapred-site.xml
如果没有修改文件则执行
cp mapred-site.xml.template mapred-site.xml
执行
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
</configuration>
3.134配置yarn-site.xml
执行
vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<!--yarn总管理器的IPC通讯地址-->
<name>yarn.resourcemanager.address</name>
<value>node1:8032</value>
</property>
<property>
<!--yarn总管理器调度程序的IPC通讯地址-->
<name>yarn.resourcemanager.scheduler.address</name>
<value>node1:8030</value>
</property>
<property>
<!--yarn总管理器的IPC通讯地址-->
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>node1:8031</value> </property>
<property>
<!--yarn总管理器的IPC通讯地址-->
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>node1:8031</value>
</property>
<property>
<!--yarn总管理器的IPC管理地址-->
<name>yarn.resourcemanager.admin.address</name>
<value>node1:8033</value>
</property>
<property>
<!--yarn总管理器的web http通讯地址-->
<name>yarn.resourcemanager.webapp.address</name>
<value>node1:8088</value>
</property>
</configuration>
4.1格式化
hdfs namenode -format
4.11启动停止Hadoop的环境
start-all.sh
stop-all.sh
4.12查看进程
jps
5.1zookeeper环境搭建
5.11进入zookeeper压缩包目录
解压 tar -zxvf 压缩包名
可创建文件软链接,简化配置。
ln -s 解压后文件名 zookeeper
5.12修改配置文件
ZooKeeper的核心服务器属性配置文件是zoo.cfg。在主安装目录下的conf子目录内,系统为用户准备了一个模板文件zoo_sample.cfg,我们可以将这个文件拷贝一份,命名为zoo.cfg,然后修改配置文件。首先我们进入到conf子目录,执行以下命令:
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
然后,我们进入到zoo.cfg文件中修改配置信息,tickTime:这个时间是作为ZooKeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一个心跳;dataDir:顾名思义就是ZooKeeper保存数据的目录,默认情况下,ZooKeeper将数据的日志文件也保存在这个目录里;clientPort:这个端口就是客户端连接ZooKeeper服务器的端口,ZooKeeper会监听这个端口,接收客户端的请求。按如下配置修改tickTime、dataDate、clientPort的值(其余内容不做修改):
tickTime=2000
dataDir=zookeeper中tmp路径
clientPort=2181
5.13配置环境变量
vim ~/.bashrc
在文件末尾增加下面内容:
export ZOOKEEPER_HOME=zookeeper路径
export PATH=$ZOOKEEPER_HOME/bin:$PATH
使环境变量生效:
source ~/.bashrc
5.14启动zookeeper
zkServer.sh start
查看状态:
zkServer.sh status
6.1Hbase环境配置
6.11进入Hbase压缩包位置
tar -zxvf 压缩包名
软链接创建
ln -s 解压后文件名 hbase
6.12配置环境变量
vim ~/.bashrc
在打开文件的末尾添加以下两行代码,保存并退出。
export HBASE_HOME=hbase路径
export PATH=$HBASE_HOME/bin:$PATH
使环境变量生效,执行下面命令:
source ~/.bashrc
6.13创建data目录
cd ~/hbase
mkdir data
6.14修改配置文件hbase-env.sh
cd ~/hbase/conf
vim hbase-env.sh
在打开的文件中,找到“# export JAVA_HOME”开头的文件,去掉前面的“#”,修改为:
export JAVA_HOME=jdk路径
另外,找到“# export HBASE_MANAGES_ZK”开头的文件,去掉前面的“#”,修改为:
export HBASE_MANAGES_ZK=true
6.15修改配置文件hbase-site.xml
cd ~/hbase/conf
vi hbase-site.xml
在打开的文件中编辑内容,如下:
<configuration>
<!--HBase的数据保存在HDFS对应目录-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://node1:9000/hbase</value>
</property>
<!--是否是分布式环境-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--配置ZK的地址-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>node1</value>
</property>
<!--冗余度-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--zookeeper数据目录-->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>zookeeper路径</value>
</property>
</configuration>
6.16修改配置文件regionservers
vim regionservers
在打开的文件中,将里面的内容修改为(自己主机名):
node1
6.17启动hbase
start-hbase.sh
6.18查看进程
jps
配置完成
版权归原作者 初心_xzp 所有, 如有侵权,请联系我们删除。