
MySQL数据库
一、MySQL数据库入门
1.初识数据库
数据库(DataBase,DB)是一个存在于计算机存储设备上的数据集合,它可以简单地理解为一种存储数据地仓库。数据库能够长期、高效地管理和存储数据,其主要目的是能够存储(写入)和提供(读取)数据。
数据库系统地3个重要部分:
- **数据库(DB)**:提供存储空间来存储各种数据;
- **数据库管理系统(DBMS)**:对数据地建立、维护、运行进行管理,对数据库中地数据进行定义、组织和存取。通过数据库管理系统可以科学地组织、存储、维护和获取数据,常见的数据库管理系统包括:MySQL、Oracle、SQL Server、MongoDB等
- 数据库应用程序:虽然已经有了数据库管理系统,但在很多情况下,数据库管理系统无法满足用户对数据库的管理。此时,就需要使用数据库应用程序与数据库管理系统进行通信、访问和管理DBMS中存储的数据。

数据库管理技术发展至今,主要经历的3个阶段:
- 人工管理阶段:20世纪50年代中期以前,计算机主要用于科学计算,硬件方面没有磁盘等直接存取设备,只有磁带、卡片和纸带;软件方面没有操作系统和管理数据的软件;数据的输入、存取等需要人工操作。人工管理阶段处理数据非常麻烦和低效。
- 文件系统阶段:20世纪50年代后期到60年代中期,硬件方面,有了磁盘等直接存取设备;软件方面,出现了操作系统,并且操作系统提供了专门的数据管理软件,称为文件系统;数据处理上,能够联机实时处理。数据以文件为单位保存在外存储器上,由操作系统管理。文件系统阶段程序和数据分离,实现了以文件为单位的数据共享。
- 数据库系统阶段:计算机的应用范围越来越广泛,管理的数据量越来越多,同时对多种应用程序之间数据共享的需求越来越强烈,文件系统的管理方式已经无法满足需求。为了提高数据管理的效率,解决多用户、多应用程序共享数据的需求,数据库技术应运而生,由此进入了数据库系统阶段。
2.数据模型
数据模型是现实世界数据特征的抽象,用来描述数据、组织数据和操作数据。数据模型是数据库系统的核心和基础,现有的数据库系统都是基于某种数据模型。
数据模型按照不同应用层次划分:
概念数据模型中的常用术语:
联系中的一对一、一对多、多对多的表示方法:
- 一对一(1:1):每个学生都有一个学生证,学生和学生证之间是一对一的联系。
- 一对多(1:n):一个班级有多个学生,班级和学生是一对多的联系。
- 多对多(m:n):一个学生可以选修多门课程,一门课程又可以被多个学生选修,学生和课程之间就形成了多对多的联系。
概念数据模型的表示方法——E-R图:E-R图也称为实体-联系图(Entity Relationship Diagram),它是一种用图形表示的实体联系模型。
E-R图通用的表示方式:
- 实体:用矩形框表示,将实体名写在矩形框内。
- 属性:用椭圆框表示,将属性名写在椭圆框内。实体与属性之间用实线连接。
- 联系:用菱形框表示,将联系名写在菱形框内,用连线将相关的实体连接,并在连线旁标注联系的类型。
下图使用了E-R图学生和班级的联系:
下图使用了E-R图学生和课程的联系:
3.SQL
结构化查询语言(Structured Query Language,SQL)是关系数据库语言的标准,同时也是一个通用的关系数据库语言。SQL提供了管理关系数据库的一些语法,通过这些语法可以完成存取数据、删除数据和更新数据等操作。
根据SQL的功能,将SQL划分为4部分:
SQL语句示例:
编写SQL语句的注意事项:
- 不同平台下MySQL对数据库名、数据表名和字段名大小写的区分方式不同。 - 在Windows平台下,数据库名、数据表名和字段名都不区分大小写;- 在Linux平台下,数据库名和数据表名严格区分大小写,字段名不区分大小写。
- 关键字不区分大小写,习惯上使用大写形式。用户自定义的名称习惯上使用小写形式。
- 关键字不能作为用户自定义的名称使用,如果要使用通过反引号“
” 包裹,如select`。 SQL语句可以单行或者多行书写,以分号结束即可。
4.常见的数据库产品
- 常见的关系数据库产品:基于关系数据模型组织的数据库管理系统,一般称为关系数据库。 - Oracle:甲骨文公司开发的一款关系数据库管理系统。可移植性好、使用方便、功能强,但是价格高;- SQL Server:微软公司开发的一款关系数据库管理系统。具有强大、灵活、基于Web应用程序管理功能,界面友好、易操作;- SQLite:一款轻量级的关系数据库管理系统。在使用前不需要安装和配置,支持主流操作系统,能和很多编程语言相结合,如C#、PHP、Java;- PostgreSQL:加州大学计算机系开发的数据库管理系统,支持多种类型的数据库客户端接口和多种数据类型;- MySQL:最早由瑞典的MySQL AB公司开发,目前属于Oracle公司旗下产品。具有跨平台的特性,使用更加方便、快捷。
- 常见的非关系型数据库产品:随着互联网web2.0的星期,关系数据库在处理高并发的数据时,存在一些不足,需要采用更适合大规模数据集合、多重数据种类的数据库,通常将这种类型的数据库称为非关系数据库。 - Redis:Redis是一个使用C语言编写的键值数据库。简直数据库类似传统语言中使用的哈希表。搜索速度快,用于处理大量数据的高负载访问,也用于一些日志系统;- MongoDB:MongoDB是一个面向文档的开源数据库。使用BSON存储数据,用于Web应用;- HBase:HBase是一个分布式的、面向列的开源数据库,是谷歌公司的BigTable数据库设计的分布式非关系数据库。查找速度快,可扩展性强,容易进行分布式扩展,用于应对分布式存储海量数据;- Elasticsearch:Elasticsearch是一个分布式、高扩展、高实时的搜索与数据分析引擎数据库。
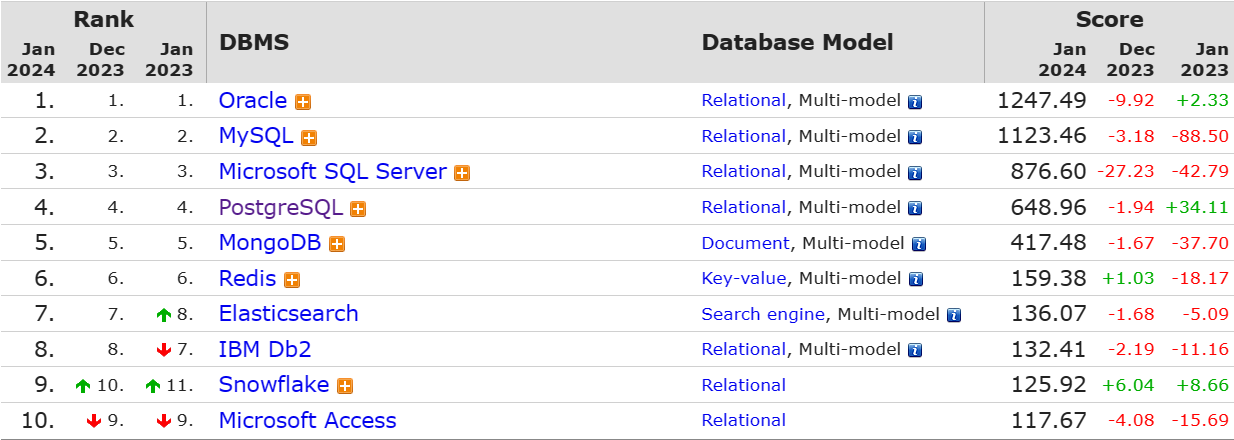
下图为DB-Engines 通过计算每种数据库 2024 年 1 月份的流行度与其 2023 年 1 月份流行度的差值:
5.MySQL安装与配置
下载安装文档参见:MySQL8.0安装教程。
6.图形化工具的使用
我们安装好MySQL后,在命令行窗口操作极其不方面,此时,我们可以采用图形化窗口的方式进行数据库的连接和操作,从而提高效率。
常见的数据库图形化管理工具有:SQLyog、Navicat、DataGrip等。目前企业级开发多数使用后两者。此次课程我们使用Navicat。Navicat是一套可以创建多个连接的数据库图形化工具,可以管理关系型数据库和非关系型数据库。其官网地址为:https://www.navicat.com.cn/。
Navicat下载安装好后就可以创建连接了,连接步骤如下:
- 在菜单栏“连接”中选择MySQL:
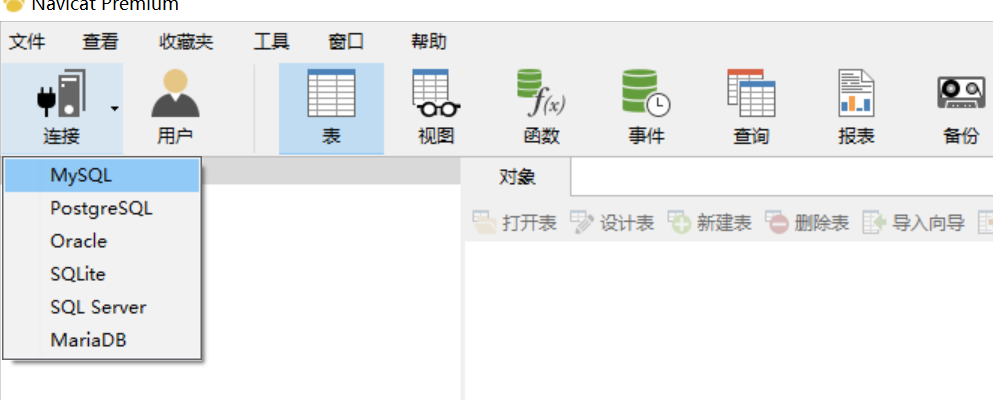
在弹出框中配置连接名、主机名或IP地址、端口、用户名和密码:

点击“确定”后便可连接MySQL数据库。
项目:用Navicat创建库、创建表
二、MySQL的基本操作
1.数据库操作
若要使用MySQL保存数据,首先要在MySQL中创建数据库,然后在数据库中创建数据表,最后将数据保存到数据表中。
1.1.创建数据库
创建数据库就是在数据库系统中划分一块存储数据的空间。使用
CREATE DATABASE
或
CREATE SCHEMA
创建指定名称的数据库。创建数据库的基本语法:
CREATE {DATABASE|SCHEMA} [IFNOTEXISTS] 数据库名称
[DEFAULT]
{CHARACTERSET[=] 字符集名称
|COLLATE[=] 校对集名称
| ENCRYPTION [=] {'Y'|'N'}
};
CREATE {DATABASE | SCHEMA}:表示创建数据库。使用CREATE DATABASE或CREATE SCHEMA都可以创建指定名称的数据库。IF NOT EXISTS:可选项,用于在创建数据库前判断要创建的数据库的名称是否已经存在,只有在要创建的数据库名称不存在时才会执行创建数据库的操作。CHARACTER SET:可选项,用于指定数据库字符集。如果省略此项,则使用MySQL默认字符集。COLLATE:可选项,用于指定校对集,省略则使用字符集对应的默认校对集。ENCRYPTION:可选项,用于为数据库加密,允许的值有Y(启动加密)和N(禁用加密)。
示例:创建名称为
test
的数据库:
CREATEDATABASE test;

如果在创建数据库时,要创建的数据库已经存在,则会出现错误提示信息。

1.2.查看数据库
1.查看所有数据库:语法格式如下:
SHOW {DATABASES| SCHEMAS} [LIKE'pattern'|WHERE expr];
SHOW {DATABASES | SCHEMAS}:表示使用SHOW DATABASES或SHOW SCHEMAS查看已存在的数据库。LIKE 'pattern':可选项,表示LIKE子句,可以根据指定匹配模式匹配数据库。 'pattern’为指定的匹配模式,通过“%”和“_”对字符串进行匹配。“%”表示匹配一个或多个字符;“_”表示匹配一个字符。WHERE expr:可选项,表示WHERE子句,用于根据指定条件匹配数据库。
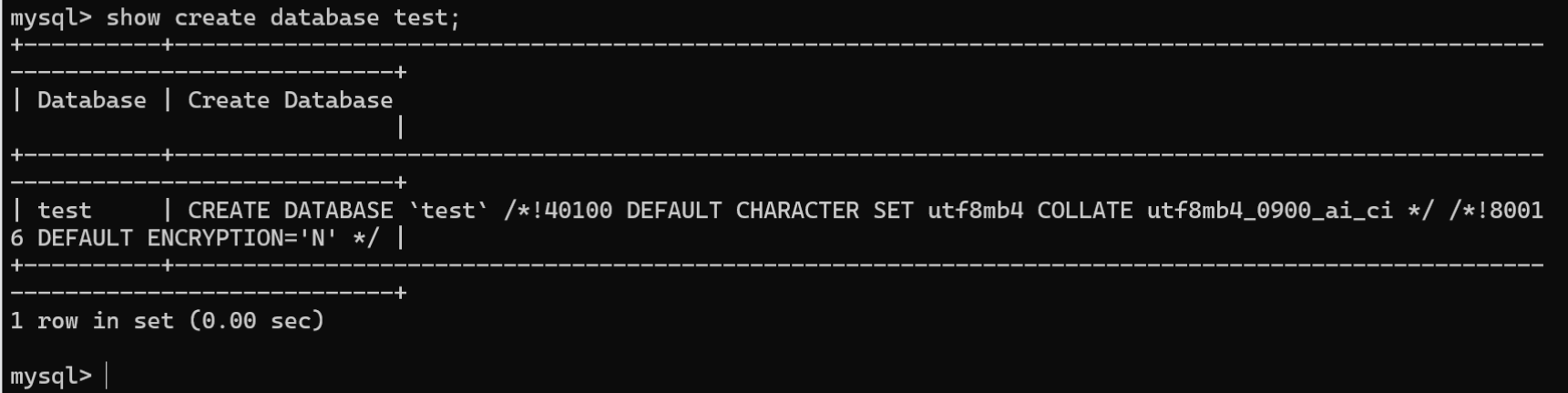
2.查看指定数据库:语法格式如下:
SHOWCREATE {DATABASE|SCHEMA} 数据库名称;
1.3.修改数据库
数据库创建后,如果想要修改数据库,可以使用
ALTER DATABASE
语句实现,语法格式如下:
ALTER {DATABASE|SCHEMA} [数据库名称]
{[DEFAULT]CHARACTERSET[=] 字符集
|[DEFAULT]COLLATE[=] 校对集
|[DEFAULT] ENCRYPTION [=] {'Y'|'N'}
|READ ONLY [=] {DEFAULT|0|1}};
ALTER {DATABASE | SCHEMA}:表示修改指定名称的数据库,可以写成ALTER DATABASE或ALTER SCHEMA的形式。数据库名称:可选项,表示要修改哪个数据库,如果省略数据库名称,则该语句适用于当前所选择的数据库,若没有选择数据库,会发生错误。CHARACTER SET:可选项,用于指定默认的数据库字符集。COLLATE:可选项,用于指定校对集。ENCRYPTION:可选项,用于为数据库加密。READ ONLY:用于控制是否允许修改数据库及其中的数据,允许的值为DEFAULT、 0(非只读)和1(只读)。
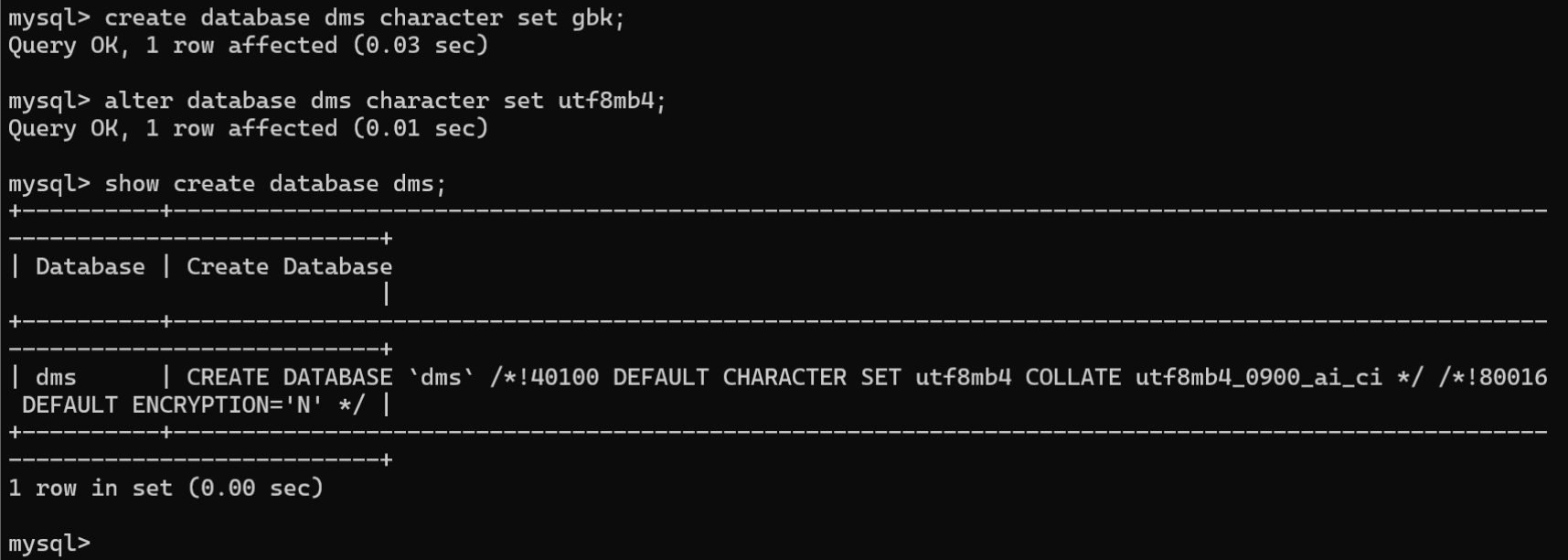
示例:创建dms数据库,并指定字符集为gbk,然后将dms数据库字符集修改为utf8mb4:
CREATEDATABASE dms CHARACTERSET gbk;ALTERDATABASE dms CHARACTERSET utf8mb4;SHOWCREATEDATABASE dms;
1.5.选择数据库
MySQL中可能存在多个数据库,在使用SQL语句对数据库中的数据表进行操作前,需要指定要操作的数据表来自哪个数据库。
在MySQL中,USE语句用于选择某个数据库作为后续操作的默认数据库,语法格式如下:
USE 数据库名称;
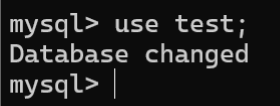
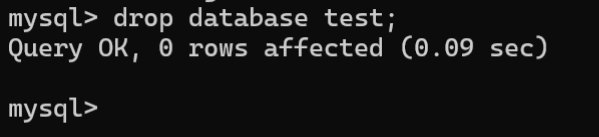
1.6.删除数据库
当一个数据库不再使用时,为了释放存储空间,需要将该数据库删除。删除数据库的语法格式如下:
DROP {DATABASE|SCHEMA} 数据库名称;
2.数据表操作
在MySQL数据库中,所有的数据都存储在数据表中,若要对数据执行增删改查的操作,需要先在指定数据库中准备一张表。
2.1.创建数据表
创建数据表是指在已经创建的数据库中建立新数据表。通过使用
CREATE TABL
语句创建数据表,其语法格式为:
CREATE[TEMPORARY]TABLE[IFNOTEXISTS] 数据表名称 (
字段名 数据类型 [字段属性]...)[表选项];
TEMPORARY:可选项,表示临时表,临时表仅在当前会话可见,会话结束时自动删除。IF NOT EXISTS:可选项,表示只有在数据表名称不存在时,才会创建数据表。 数据表名称:数据表的名称。字段名:字段的名称。数据类型:字段的数据类型,用于确定MySQL存储数据的方式。常见的数据类型有整数类型(如INT)、字符串类型(如VARCHAR)等。字段属性:可选项,用于为字段添加属性,每个属性有不同的功能。常用的属性有COMMENT属性和约束属性。表选项:可选项,用于设置数据表的相关选项,例如存储引擎、字符集、校对集等。
存储引擎是MySQL处理数据表的SQL操作的组件,数据的存储、修改和查询都离不开存储引擎。MySQL默认使用的是
InnoDB
存储引擎。通过“SHOW ENGINES;”语句查看MySQL服务器存储引擎的状态信息:
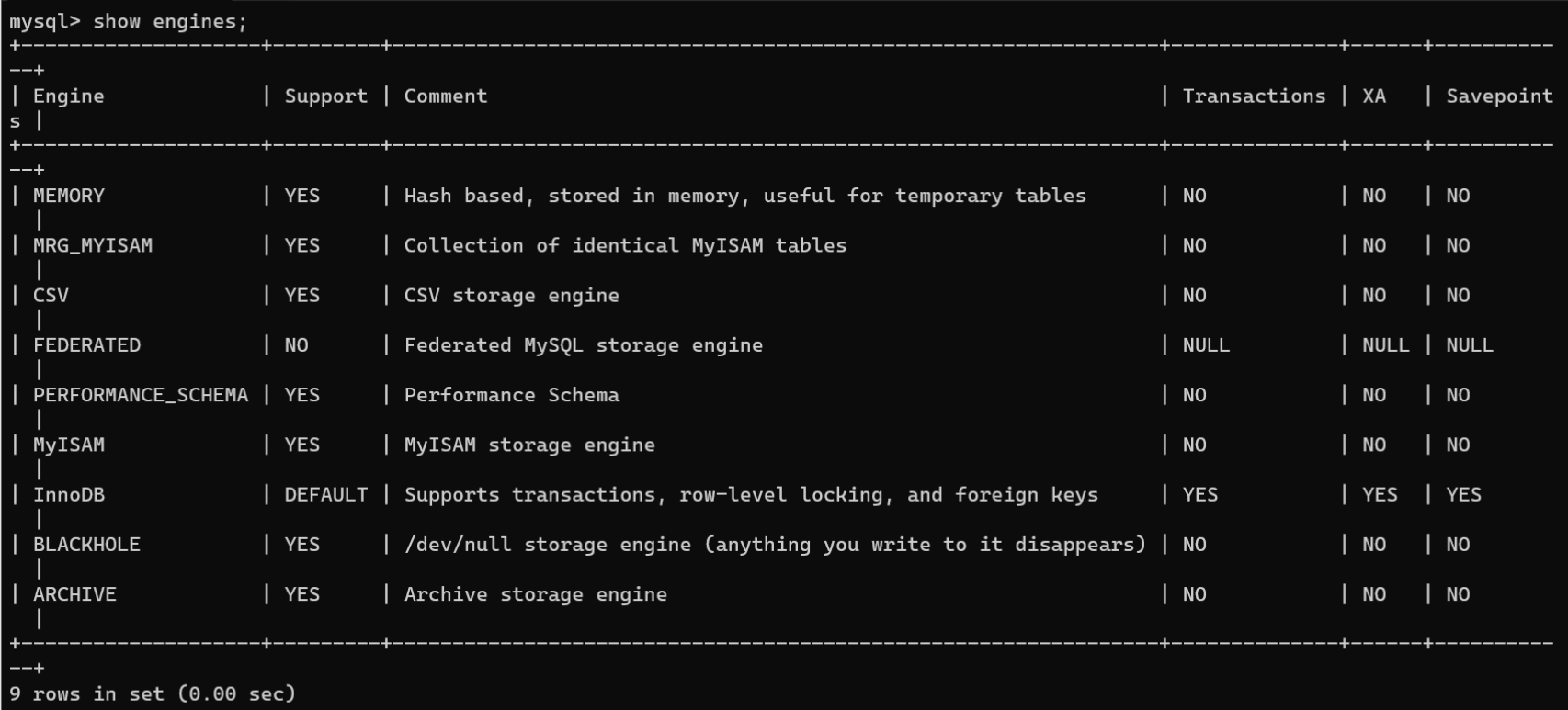
上述列中”Engine“表示存储引擎名称,”Support“表示是否支持,”Comment“表示注释说明,”Transactions“表示是否支持事务,”XA“表示是否支持分布式事务,”Savepoints“表示是否支持事务保存点。
案例:创建
school
数据库,并在该数据库下创建一个用于保存学生信息的
student
数据表:
createdatabase school;use school;# 创建student数据表createtable student (
id intcomment'姓名',
name varchar(20)comment'姓名')comment'学生表';

2.2.查看数据库
- 查看数据库中存在的数据表:通过
SHOW TABLES语句查看数据库中存在的所有数据表的语法:
SHOWTABLES[LIKE'pattern'|WHERE expr];

- 查看数据表的相关信息:通过
SHOW TABLE STATUS语句查看数据表相关信息,如数据表名称、存储引擎、创建时间等。查看数据表相关信息的语法:
SHOWTABLESTATUS[FROM 数据库名称][LIKE'pattern'];
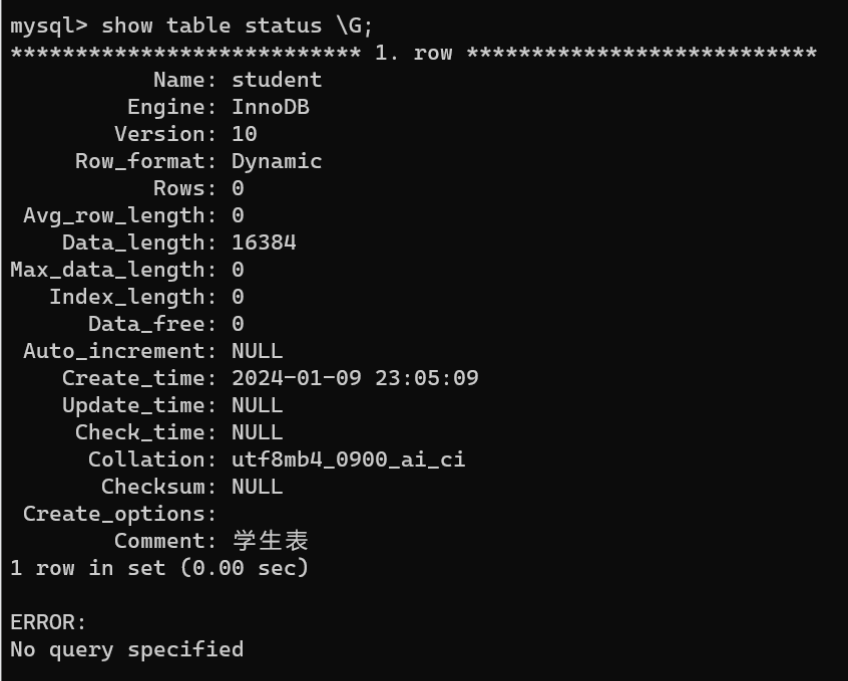
上图中,结束符”\G“用于将显示结果纵向排列。
- 查看数据表的创建语句:通过
SHOW CREATE TABLE语句查看创建数据表的SQL语句以及数据表的字符编码。查看数据表创建语句的语法:
SHOWCREATETABLE 数据表名称;
拓展:MySQL中的注释也分为单行注释和多行注释,具体如下:
SELECT*FROM student;-- 单行注释SELECT*FROM student;# 单行注释/*
多行注释
*/SELECT*FROM student;
2.3.查看表结构
- 通过
DESC语句查看数据表的结构信息,包括所有字段或指定字段的信息。查看表结构的语法:
# 查看所有字段的信息DESC 数据表名称;# 查看指定字段的信息DESC 数据表名称 字段名;# DESC还可以写成DESCRIBE或EXPLAIN,其功能都是相同的
DESC
语句执行成功后,返回信息说明:
Field:表示数据表中字段的名称。Type:表示数据表中字段对应的数据类型。Null:表示该字段是否可以存储NULL值。Key:表示该字段是否已经建立索引。Default:表示该字段是否有默认值,如果有默认值则显示对应的默认值。Extra:表示与字段相关的附加信息。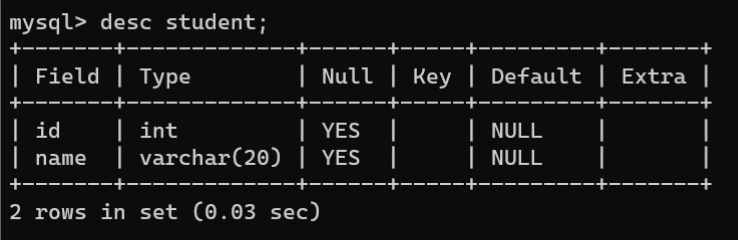
通过
SHOW COLUMNS语句也可以查看数据表的结构信息。SHOW COLUMNS语句查看表结构的语法:
# 语法格式1SHOW[FULL]COLUMNSFROM 数据表名称 [FROM 数据库名称];# 语法格式2SHOW[FULL]COLUMNSFROM 数据库名称.数据表名称;

2.4.修改数据表
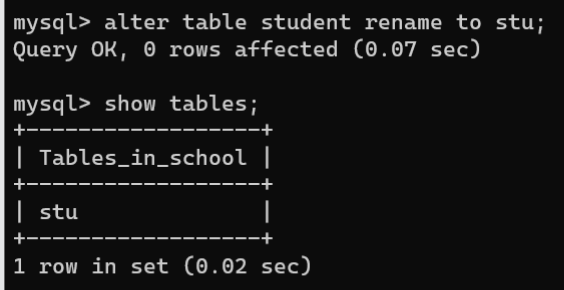
- 修改数据表名称:
ALTER TABLE语句和RENAME TABLE都可以修改数据表名称,语法如下:
ALTERTABLE 旧数据表名称 RENAME[TO|AS] 新数据表名称;RENAMETABLE 旧数据表名称1TO 新数据表名称1[, 旧数据表名称2TO 新数据表名称2]...;
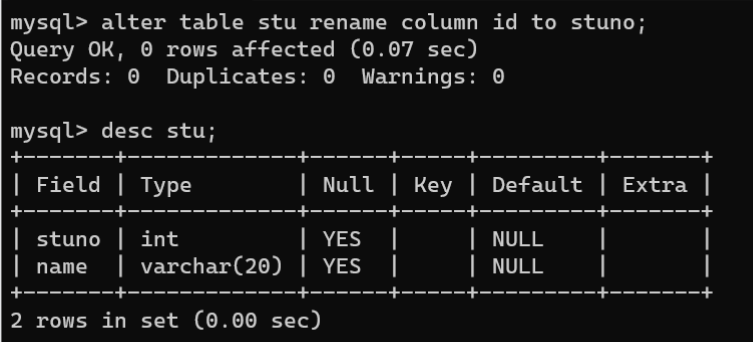
- 修改字段名:
ALTER TABLE的CHANGE子句和RENAME COLUMN子句都可以修改字段名。需要注意的是,RENAME COLUMN子句只能修改字段名,语法如下:
ALTERTABLE 数据表名称 CHANGE [COLUMN] 旧字段名 新字段名 数据类型[字段属性];ALTERTABLE 数据表名称 RENAMECOLUMN 旧字段名 TO 新字段名;
- 修改字段数据类型:
ALTER TABLE的MODIFY子句和CHANGE子句都可以修改字段的数据类型,语法如下:
ALTERTABLE 数据表名称 MODIFY[COLUMN] 字段名 新数据类型;

- 添加指定字段:
ALTER TABLE的ADD子句可以添加新字段,语法如下:
ALTERTABLE 数据表名称 ADD[COLUMN] 新字段名 数据类型 [FIRST|AFTER 字段名];
使用
ALTER TABLE
语句的
ADD
子句添加多个字段的语法:
ALTERTABLE 数据表名称 ADD[COLUMN](新字段名1 数据类型1, 新字段名2 数据类型2,...);
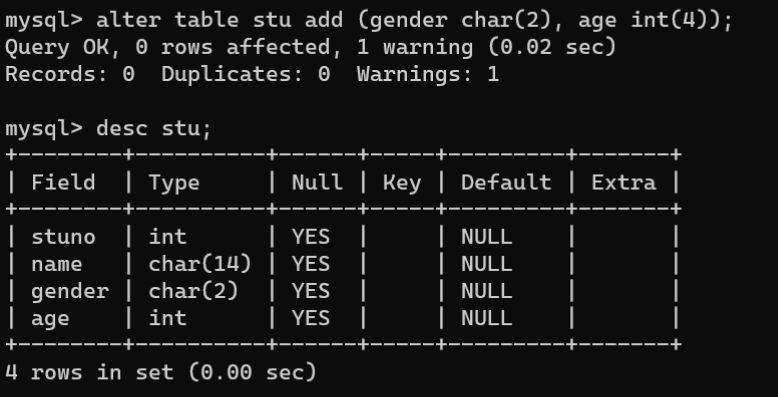
- 修改字段排列位置:
ALTER TABLE的MODIFY子句和CHANGE子句都可以修改字段的排列位置,语法如下:
# MODIFY子句# 语法1,将某个字段修改为表的第一个字段ALTERTABLE 数据表名称 MODIFY 字段名 数据类型 FIRST;# 语法2,将字段名1移动到字段名2的后面ALTERTABLE 数据表名称 MODIFY 字段名1 数据类型 AFTER 字段名2;# CHANGE子句# 语法1,将某个字段修改为表的第一个字段ALTERTABLE 数据表名称 CHANGE 字段名 字段名 数据类型 FIRST;# 语法2,将字段名1移动到字段名2的后面ALTERTABLE 数据表名称
CHANGE 字段名1 字段名1 数据类型 AFTER 字段名2;
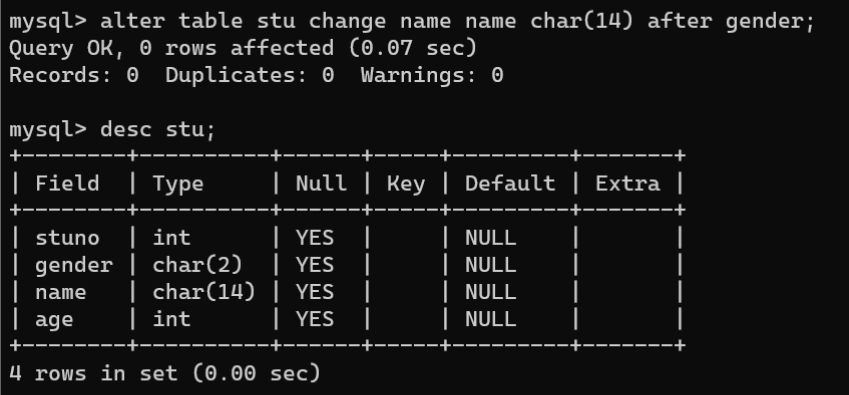
- 删除指定字段:
ALTER TABLE的DROP子句可以删除指定的字段,语法如下:
ALTERTABLE 数据表名称 DROP[COLUMN] 字段名1[,DROP 字段名2]...;
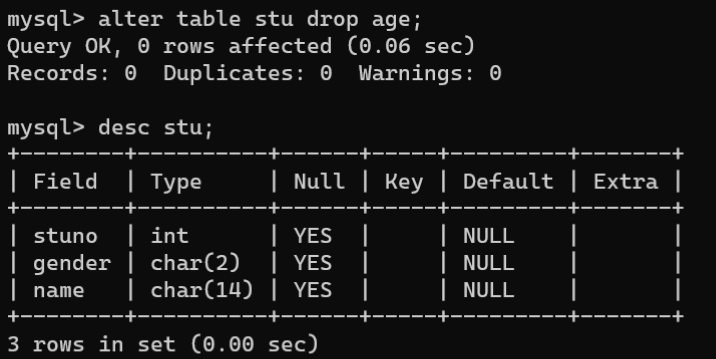
2.5.删除数据表
使用
DROP TABLE
语句删除一张或多张数据表的语法:
DROP[TEMPORARY]TABLE[IFEXISTS] 数据表名称1[, 数据表名称2]...;
TEMPORARY:可选项,表示临时表,如果要删除临时表,可以通过该选项来删除。IF EXISTS:可选项,表示在删除之前判断数据表是否存在,使用该可选项可以避免删除不存在的数据表导致语句执行错误。
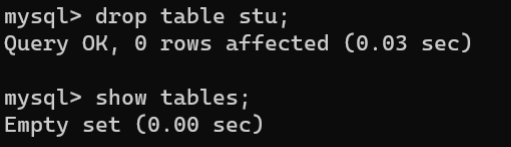
3.数据操作【重点】
3.1.添加数据
数据表创建好之后,可以向数据表中添加数据。添加数据又称为插入数据。在MySQL中,使用
INSERT
语句可以向数据表添加单条数据或者多条数据。
- 添加单条数据:语法如下:
INSERT[INTO] 数据表名称 [(字段名[,...])] {VALUES|VALUE} (值[,...]);- 关键字INTO可以省略,省略后效果相同。- 数据表名称是指需要添加数据的数据表的名称。- 字段名表示需要添加数据的字段名称,字段的顺序需要与值的顺序一一对应,多个字段名之间使用英文逗号分隔。-VALUES和VALUE,可以任选其一,通常情况下使用VALUES。- 值表示字段对应的数据,多个值之间使用英文逗号分隔。
需要注意的是,
insert
添加数据时,字段名是可以省略的,如果不指定字段名,那么值的顺序必须和数据表指定的字段顺序保持一致。
- 以指定所有字段名的方式添加数据:在
school数据库中创建一个用于存储教室信息的教师表teacher,创建好后,使用insert语句向教师表中添加一条数据:
# 创建教师表teacherCREATETABLE teacher(
teacherno INTCOMMENT'教师编号',
tname VARCHAR(8)COMMENT'姓名',
gender VARCHAR(2)COMMENT'性别',
title VARCHAR(12)COMMENT'职称',
birth VARCHAR(16)COMMENT'出生年月',
sal INTCOMMENT'工资')COMMENT'教师表';# 向教师表中添加数据INSERTINTO teacher (teacherno,tname,gender,birth,title,sal)VALUES(101,'邹堂瑞','男','2000-01-01','副教授',80000);
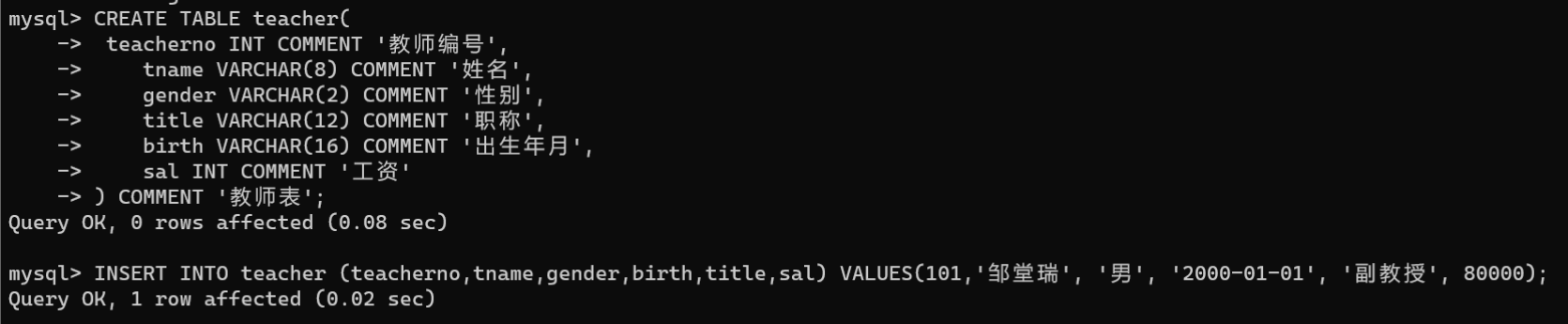
2.以省略所有字段名的方式添加数据:
INSERTINTO teacher VALUES(102,'郑强','男','教授','1960-01-01',15000);

3.向部分字段添加数据:
INSERTINTO teacher (teacherno,tname,title,sal)VALUES(103,'李坤','教授',10000);

除此之外,使用
INSERT
语句的
set
子句也能添加数据,语法格式如下:
INSERT[INTO] 数据表名称 SET 字段名1=值1[, 字段名2=值2,...];
- 添加多条数据:
INSERT语句同时添加多条数据时,其基本语法格式如下:
INSERT[INTO] 数据表名称 [(字段名[,...])] {VALUES|VALUE}
(第1条记录的值1, 第1条记录的值2,...),(第2条记录的值1, 第2条记录的值2,...),...(第n条记录的值1, 第n条记录的值2,...);
上述语法中,如果未指定字段名,则值的顺序要与数据表的字段顺序一致;如果指定了字段名,则值的顺序要与指定的字段名顺序一致。添加多条数据时,多条数据之间用逗号分隔。
需要注意的是,当添加多条数据时,若其中一条数据添加失败,则整条添加语句都会失败。
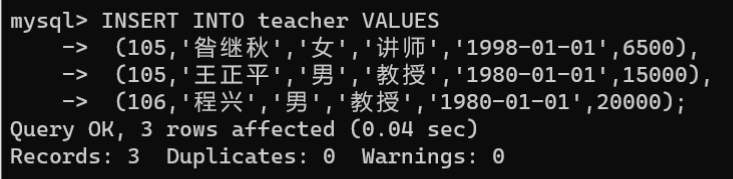
将下表数据添加到教师表中:
teachernotnamegendertitlebirthsal104昝继秋女讲师1998-01-016500105王正平男教授1980-01-0115000106程兴男教授1980-01-0120000
INSERTINTO teacher VALUES(105,'昝继秋','女','讲师','1998-01-01',6500),(105,'王正平','男','教授','1980-01-01',15000),(106,'程兴','男','教授','1980-01-01',20000);
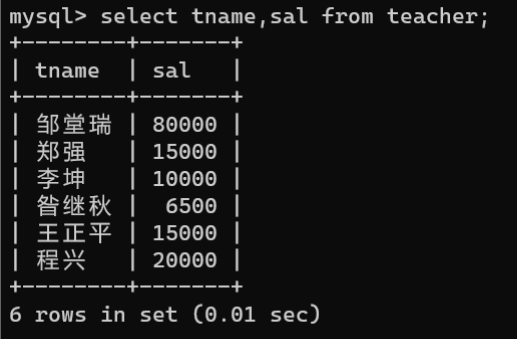
3.2.查询数据
- 查询数据表中指定字段:使用
SELECT语句将指定要查询的字段查询出来,其语法如下:
SELECT 字段名[,...]FROM 数据表名称;
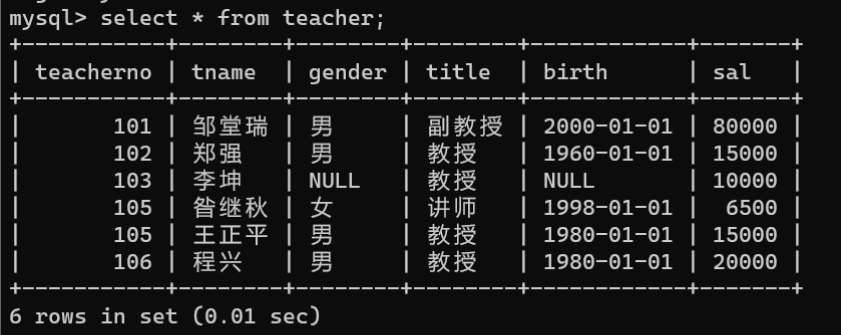
- 查询所有数据:使用通配符‘’*“可以匹配数据表中所有的字段,其语法如下:
SELECT*FROM 数据表名称;
3.3.修改数据
在MySQL中,使用
UPDATE
语句可以修改数据表中部分记录的字段数据或修改数据表中所有记录的字段数据。
- 修改数据表中部分记录的字段数据:通过
WHERE子句指定修改数据的条件,其语法如下:UPDATE 数据表名称 SET 字段名1=值1[,字段名2=值2,...]WHERE 条件表达式;-SET子句用于指定表中要修改的字段名及相应的值。如果想要在原字段的值的基础上修改,可以采用加(+)、减(-)、乘(*)、除()运算符进行运算,例如”字段名+1“表示在原字段基础上加1。-WHERE子句用于指定数据表中要修改的记录,WHERE后跟条件表达式,只有满足了指定条件的记录才会被修改。UPDATE teacher SET sal=50000WHERE tname='邹堂瑞';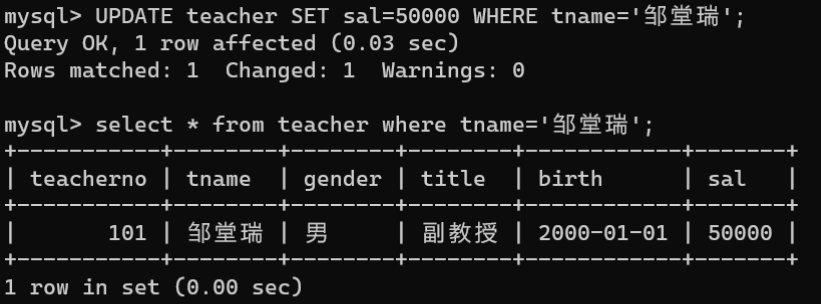
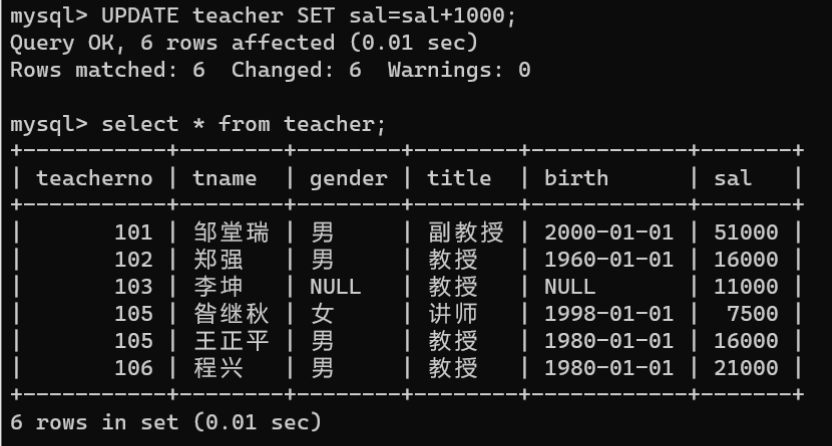
- 修改数据表中所有记录的字段数据:如果没有添加
WHERE子句,则会修改数据表中所有记录的字段数据。
UPDATE teacher SET sal=sal+1000;
3.4.删除数据
在MySQL中,使用
DELETE
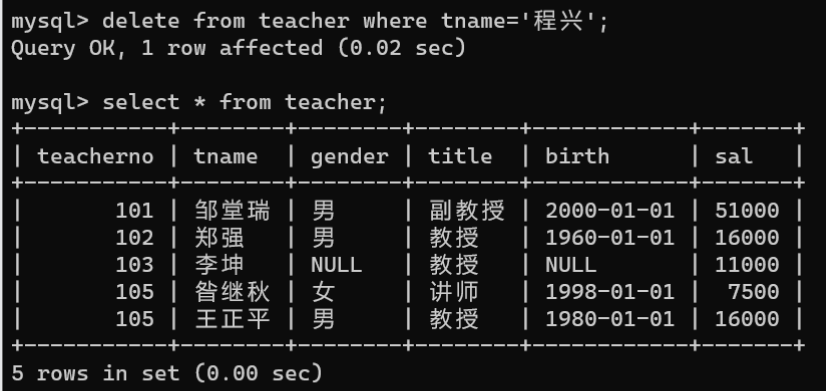
语句可以删除数据表中的部分数据和全部数据。
- 删除数据表中部分记录的数据:删除部分记录的数据需要使用
WHERE子句指定删除数据的条件,其语法为:
DELETEFROM 数据表名称 WHERE 条件表达式;
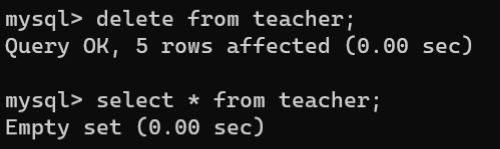
- 删除数据表中全部记录的数据:省略
WHERE子句即可删除全部数据,其语法如下:
DELETEFROM 数据表名称;
3.5.练习:电子杂志订阅表的操作
- 创建一个
mydb数据库,并选择该数据库作为后续操作的数据库。 - 在
mydb中创建一张电子杂志订阅表(subscribe),该数据表中主要包含4个字段,分别为编号(id)、订阅邮件的邮箱地址(email)、订阅确认状态(status)、邮箱确认的验证码(code),其中,订阅确认状态的值为0或1,0表示未确认,1表示确认。表结构如下:字段名称数据类型说明idINT编号emailVARCHAR(60)订阅邮件的邮箱地址statusINT订阅确认状态(0:未确认;1:确认)codeVARCHAR(10)邮箱确认的验证码 - 为电子杂志订阅表添加5条任意测试数据。
- 查看已经通过邮箱确认的电子杂志订阅信息。编号邮箱地址订阅确认状态邮箱确认验证码1tom123@mail.com1ADfG2kitty456@mail.com1LONG3hello789@mail.com0AGFA4micheal@mail.com0DDFR5john@mail.com1QWER
- 将编号4的订阅确认状态设置为”已确认“。
- 删除编号5的电子杂志订阅信息。
三、数据表设计
1.数据类型
数据库中数据的表示形式位数据类型,它决定了数据的存储格式和有效范围。MySQL包含的数据类型有整数类型、浮点类型、定点类型、日期和时间类型、字符串类型、二进制类型和JSON数据类型。
- 整数类型:数据类型后面指定宽度,可写作“数据类型(m)”,m表示查询结果集中显示的宽度,并不影响实际的取值范围。数据类型字节数有符号取值范围无符号取值范围TINYINT1-128
1270255SMALLINT2-3276832767065535MEDIUMINT3-223-223-102^24-1INT4-231231-102^32-1BIGINT8-263263-10~2^64-1 - 浮点与定点类型。数据类型字节数负数的取值范围非负数的取值范围FLOAT4-3.402823466E+38
-1.175494351E-380或-1.175494351E-383.402823466E+38DOUBLE8-1.7976931348623157E+308-2.2250738585072014E-3080或2.2250738585072014E-3081.7976931348623157E+308DECIMAL(M,D)M+2同DOUBLE同DOUBLE浮点类型在数据库中存放的是最近似值,它包括单精度浮点数(FLOAT)和双精度浮点数(DOUBLE)。定点类型是DECIMAL,在数据库中存放的是精度值。DECIMAL的取值范围和DOUBLE相同,但其有效取值范围由M和D决定。数据类型写作DECIMAL(M,D)。其中M表示精度,是数据的总长度;小数点不占位;D位标度,是小数点后的长度。比如DECIMAL(4,1)表示总长度是4,保留一位小数。 - 日期和时间类型。类型字节数取值范围格式用途DATE31000-01-01—9999-12-31YYYY-MM-DD日起值TIME3838:59:59—838:59:59HH:MM:SS时间值YEAR11901—2155YYYY年份数DATETIME81000-01-01 00:00:00—9999-12-31 23:59:59DATETIME混合日期时间值TIMESTAMP81970-01-01 00:00:00—2038-01-19 11:14:07YYYYMMDDHHMMSS混合日期时间戳使用
CURRENT_DATE或NOW()表示当前系统时间: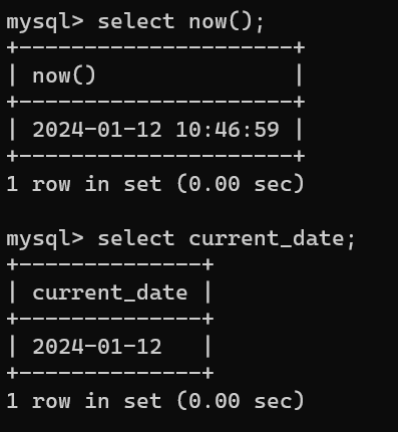
- 字符串类型。类型大小说明CHAR(n)0-255字节固定长度字符串,若输入数据长度位n,则超出部分会截断,不足部分用空格填充VARCHAR(n)同CHAR长度可变字符串,字节数随输入数据的实际长度而变化,最大长度不超过n+1TINYTEXT同CHAR短文本字符串TEXT0-65535字节长文本数据MEDIUMTEXT0-16777215字节中等长度文本数据LONGTEXT0-4294967295字节极大文本数据
- 二进制类型:用于存放图片、声音等多媒体数据以及大文本块数据。类型大小说明BIT(n)n的最大值为64,默认为1位字段类型。如果长度小于n,则左边用0填充BINARY(n)n字节固定长度的二进制字符串。若输入数据长度超过n,则会被截断,不足用“/0”填充VARBINARY(n)n+1字节可变长度二进制字符串TINYBLOB2^8-1字节BLOB是二进制的大对象,可以存放图片音频大文本块等BLOB2^16-1字节MEDIUMBLOB2^24-1字节LONGBLOB2^32-1字节
- JSON数据类型:JSON是一种轻量级的数据交换格式,它有两种形式:对象形式和数组形式:
// 对象类型{"键名1":"值1","键名2":"值2",...,"键名n":"值n"}// 数组类型["ztr",12,NULL]// 常用JSON格式-数组+对象[{"name":"ztr","age":30,"sex":"man"},{"name":"zxy","age":50,"sex":"man"},]
2.表的约束
为了防止在数据表中插入错误的数据,MySQL定义了一些维护数据库中数据完整性和有效性的规则,这些规则即表的约束。表的约束作用于表中的字段上,可以在创建数据表或修改数据表的时候为字段添加约束。表的约束起着规范作用,确保程序对数据表正确使用。
2.1.设置默认值约束
默认值约束用于给数据表中的字段指定默认值,当数据表中插入一条新记录时,如果没有给这个字段赋值,数据库会自动为这个字段插入指定的默认值。
在MySQL中,通过
DEFAULT
关键字设置字段的默认值约束。
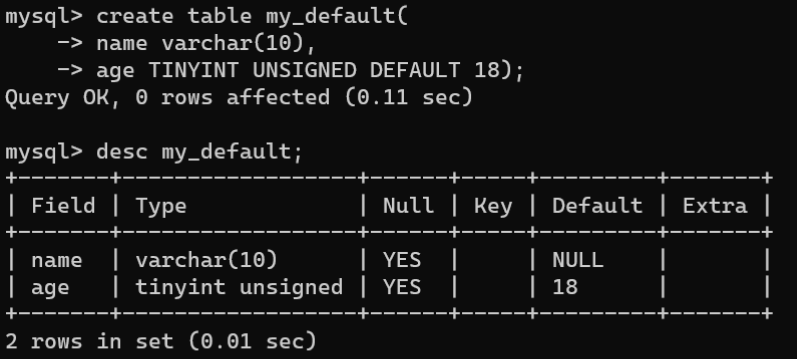
- 创建数据表时设置默认值约束:语法格式如下:
CREATETABLE 表名(
字段名 数据类型 DEFAULT 默认值,...);
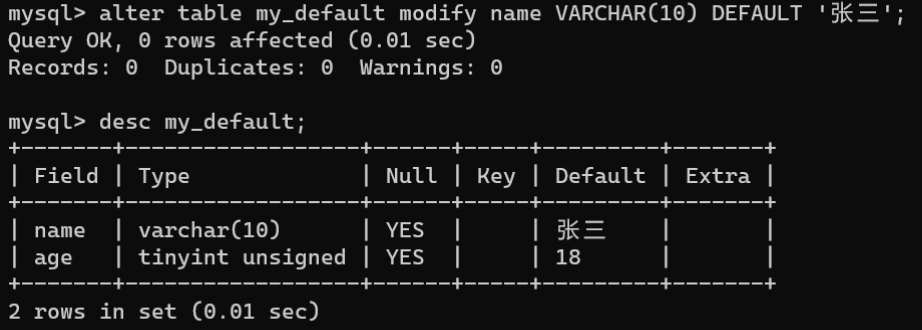
- 修改数据表时添加默认值约束:通过
ALTER TABLE语句的MODIFY子句或CHANGE子句为字段添加默认值约束,语法格式如下:
# 语法1,MODIFY子句ALTERTABLE 表名 MODIFY 字段名 数据类型 DEFAULT 默认值;# 语法2,CHANGE子句ALTERTABLE 表名 CHANGE [COLUMN] 字段名 字段名 数据类型 DEFAULT 默认值;
- 删除默认值约束:通过
ALTER TABLE语句的MODIFY子句或CHANGE子句也可以删除默认值约束,语法如下:
# 语法1,MODIFY子句ALTERTABLE 表名 MODIFY 字段名 数据类型;# 语法2,CHANGE子句ALTERTABLE 表名 CHANGE [COLUMN] 字段名 字段名 数据类型;
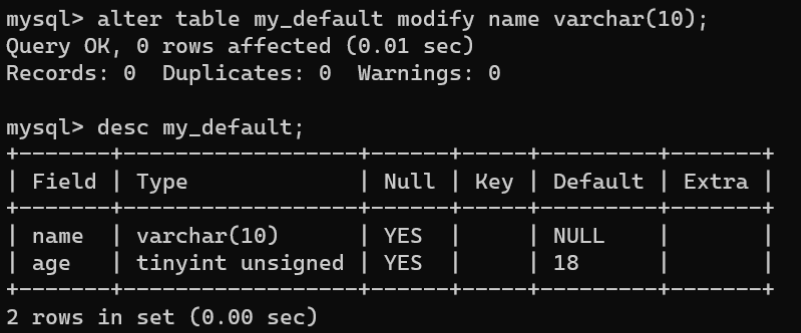
2.2.设置非空约束
在实际开发中,有时需要将一些字段设置为必填项,那么这个时候就需要对这个字段设置非空约束。非空约束用于确保插入字段中值的非空性。如果没有对字段设置非空约束,字段默认允许插入NULL值;如果字段设置了非空约束,那么该字段中存放的值必须是NULL值之外的其他的具体值。
在MySQL中,非空约束通过
NOT NULL
设置。
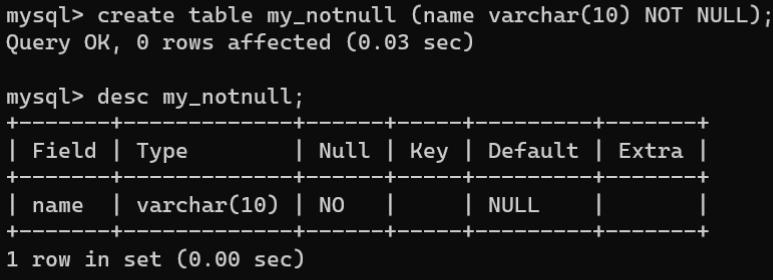
- 创建数据表时设置非空约束:其语法如下:
CREATETABLE 表名 (字段名 数据类型 NOTNULL);
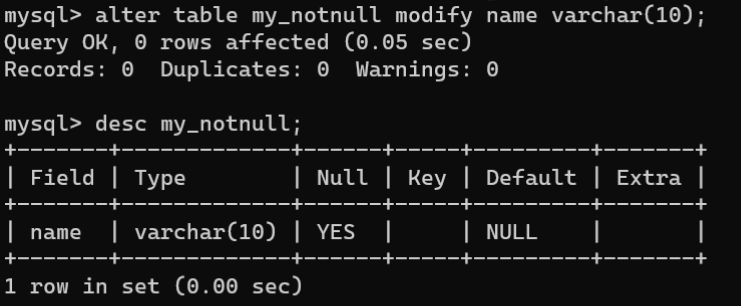
- 修改数据表时添加非空约束:通过
ALTER TABLE语句的MODIFY子句或CHANGE子句也可以重新定义字段,为字段添加非空约束,其语法如下:
# 语法1,MODIFY子句ALTERTABLE 表名 MODIFY 字段名 数据类型 NOTNULL;# 语法2,CHANGE子句ALTERTABLE 表名 CHANGE [COLUMN] 字段名 字段名 数据类型 NOTNULL;
- 删除非空约束:通过
ALTER TABLE语句的MODIFY子句或CHANGE子句也可以删除非空约束,语法如下:
# 语法1,MODIFY子句ALTERTABLE 表名 MODIFY 字段名 数据类型;# 语法2,CHANGE子句ALTERTABLE 表名 CHANGE [COLUMN] 字段名 字段名 数据类型;
2.3.设置唯一约束
在实际开发中,有时需要将字段设置为不允许出现重复值。例如邮箱、电话等。唯一约束用于确保字段中值的唯一性。如果数据表中的字段设置了唯一约束,那么该字段中存放的值不能重复出现。在MySQL中,唯一约束通过UNIQUE设置。
- 创建数据表时设置唯一约束:- 列级约束:定义在列中,紧跟在字段的数据类型之后,只对该字段起约束作用。语法格式如下:
CREATETABLE 表名 ( 字段名1 数据类型 UNIQUE, 字段名2 数据类型 UNIQUE...);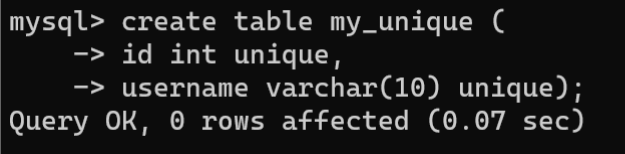 - 表级约束:表级约束独立于字段,可以对数据表的单个或多个字段起约束作用。通过多个字段确保唯一性,当表级约束仅建立在一个字段上时,其效果与列级约束相同。语法格式如下:
- 表级约束:表级约束独立于字段,可以对数据表的单个或多个字段起约束作用。通过多个字段确保唯一性,当表级约束仅建立在一个字段上时,其效果与列级约束相同。语法格式如下:CREATETABLE 表名( 字段名1 数据类型, 字段名2 数据类型, 字段名3 数据类型,...UNIQUE(字段名1[, 字段名2,...]));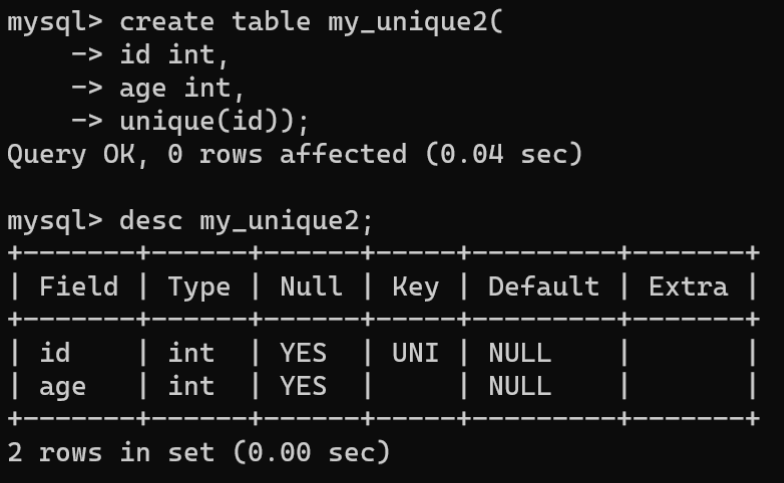 注意:给字段设置唯一约束后,MySQL会自动给对应字段添加唯一索引。通过DESC语句查看表结构时,如果字段的Key列值显示为UNI,表示该字段在创建数据表时设置了唯一约束。 若要指定唯一约束的索引名,可以将UNIQUE写成如下形式:
注意:给字段设置唯一约束后,MySQL会自动给对应字段添加唯一索引。通过DESC语句查看表结构时,如果字段的Key列值显示为UNI,表示该字段在创建数据表时设置了唯一约束。 若要指定唯一约束的索引名,可以将UNIQUE写成如下形式:UNIQUEKEY 索引名 (字段列表)# 索引名可以指定,如果省略,自动使用字段名。当删除索引时,需要指定索引名。 - 修改数据表时添加唯一约束:使用
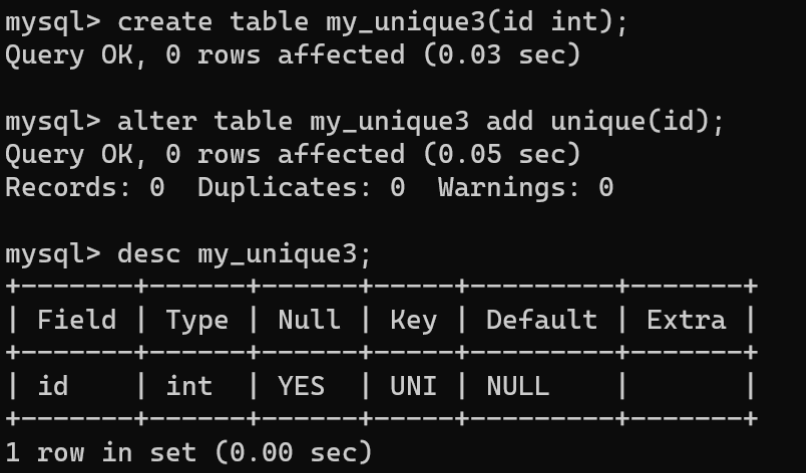
ALTER TABLE语句的MODIFY子句或CHANGE子句以重新定义字段的方式,或通过ALTER TABLE语句中的ADD子句设置唯一约束。语法格式为:
# 语法1,MODIFY子句ALTERTABLE 表名 MODIFY 字段名 数据类型 UNIQUE;# 语法2,CHANGE子句ALTERTABLE 表名 CHANGE [COLUMN] 字段名 字段名 数据类型 UNIQUE;# 语法3,ADD子句ALTERTABLE 表名 ADDUNIQUE(字段);# 使用ADD子句的语法更加简介,通常添加唯一约束时选择使用这种方式
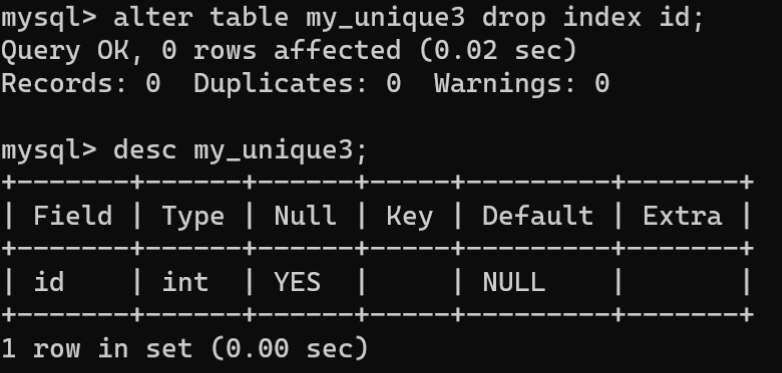
- 删除唯一约束:使用
ALTER TABLE语句的DROP 索引名的方式实现删除唯一约束的索引,并将唯一约束一并删除。语法格式如下:
ALTERTABLE 表名 DROPindex 字段名;
2.4.设置主键约束
在员工数据表中,员工工号字段具有唯一性,一般作为主键使用,如果允许员工的工号重复或为NULL值,管理员工信息时就会出现混乱。这是就可以将员工工号设置为主键约束。
主键约束相当于非空约束和唯一约束的组合,要求被约束字段中的值不能出现重复值,也不能出现NULL值。主键约束通过给字段添加
PRIMARY KEY
设置,每个数据表只能设置一个主键约束。
- 创建数据表时设置主键约束:- 列级约束:
CREATETABLE 表名 ( 字段名 数据类型 PRIMARYKEY,...);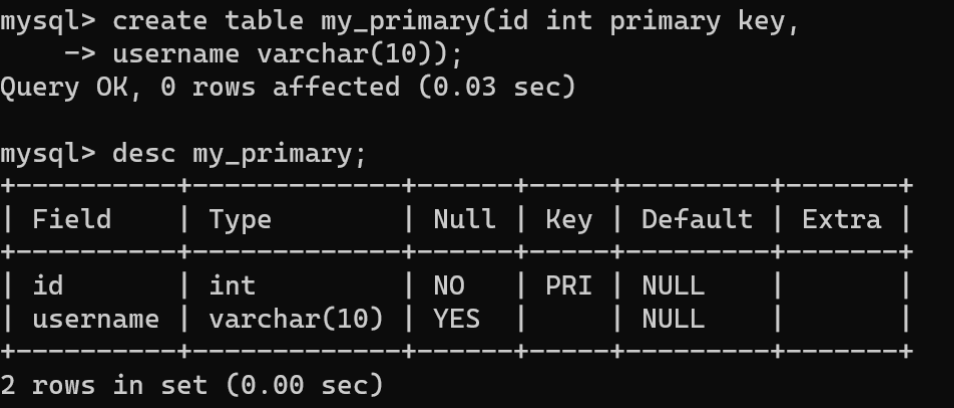 - 表级约束:
- 表级约束:CREATETABLE 表名 ( 字段名1 数据类型, 字段名2 数据类型,...PRIMARYKEY(字段名1[, 字段名2,...]));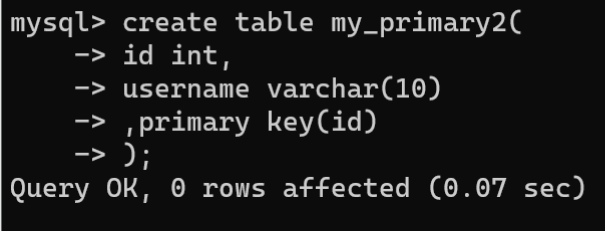

- 修改数据表时添加主键约束:使用ALTER TABLE语句的MODIFY子句或CHANGE子句以重新定义字段的方式添加,也可以通过ADD子句添加。
# 语法1,MODIFY子句ALTERTABLE 表名 MODIFY 字段名 数据类型 PRIMARYKEY;# 语法2,CHANGE子句ALTERTABLE 表名 CHANGE [COLUMN] 字段名 字段名 数据类型 PRIMARYKEY;# 语法3,ADD子句ALTERTABLE 表名 ADDPRIMARYKEY(字段);# 常用ADD子句的方式添加主键

- 删除主键约束:通过
ALTER TABLE语句的DROP子句删除主键约束。删除主键约束时会自动删除主键索引。
ALTERTABLE 表名 DROPPRIMARYKEY;

3.自动增长
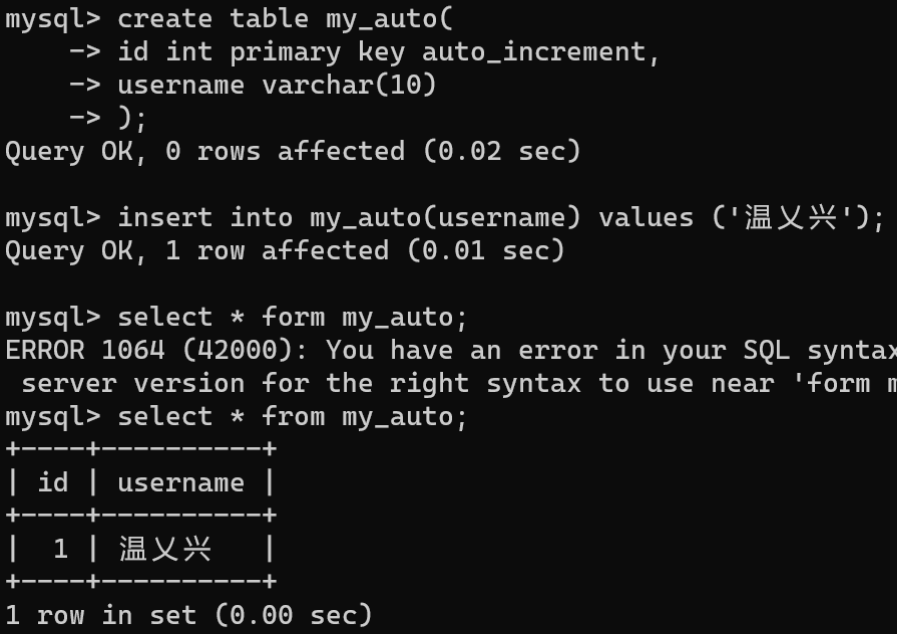
在实际开发中,有时需要为数据表中添加的新纪录自动生成主键值。例如,在员工数据表中添加员工信息时,如果手动填写员工工号,需要在添加员工前查询工号是否被其他员工占用,由于先查询后再添加需要一段时间,有可能出现并发操作时工号被其他人抢占的问题。此时可以为员工工号字段设置自动增长,设置自动增长后,如果往该字段插入值时,MySQL会自动是生成唯一的自动增长值。
通过给字段设置AUTO_INCREMENT实现自动增长。
- 创建数据表时设置自动增长:
CREATETABLE 表名 (
字段名 数据类型 约束 AUTO_INCREMENT,...);
- 修改数据表时添加自动增长:使用ALTER TABLE语句的MODIFY子句或CHANGE子句可以重新定义字段的方式添加自动增长,语法如下:
# 语法1,MODIFY子句ALTERTABLE 表名 MODIFY 字段名 数据类型 AUTO_INCREMENT;# 语法2,CHANGE子句ALTERTABLE 表名 CHANGE 字段名 字段名 数据类型 AUTO_INCREMENT;
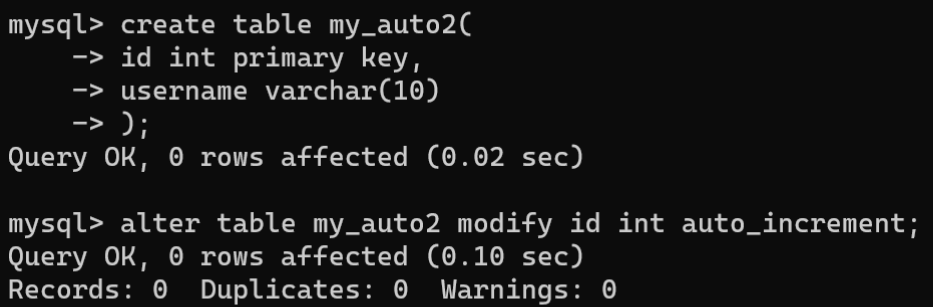
使用AUTO_INCREMENT的注意事项如下:
- 一个数据表只能有一个字段设置
AUTO_INCREMENT,设置自动增长的字段数据类型应该是整数类型,且该字段必须设置唯一约束或主键约束。 - 如果为自动增长字段插入
NULL、0、DEFAULT,或插入数据时省略了自动增长字段,该字段会使用自动增长值;如果插入的是一个具体的值,不会使用自动增长值。 - 默认情况下,设置
AUTO_INCREMENT的字段的值从1开始自增。如果插入了一个大于自动增长值的具体值,下次插入的自动增长的值会自动使用最大值加1;如果插入的值小于自动增长值,不会对自动增长值产生影响。 - 删除数据时,自动增长值不会减少或者填补空缺。
- 删除自动增长并重新添加自动增长后,自动增长的初始值会自动设为该列现有的最大值加1。修改自动增长值时,修改的值小于该列现有的最大值,修改不会生效。
4.字符集与校对集
4.1.字符集概述
计算机采用二进制方式保存数据,用户输入的字符会被计算机按照一定的规则转换为二进制后保存,这个转换的过程称为字符编码。将一系列字符的编码规则组合起来就形成了字符集。MySQL中的字符集规定了字符再数据库中的存储格式,不同的字符集有不同的编码规则。
常用的字符集有:
- UTF-8:支持世界上大多数国家的语言文字,通用性比较强,适用于大多数场合,MySQL中的写法为utf8和utf8mb4,utf8中的单个字符最多占用3个字节,utf8mb4中的单个字符允许占用4个字节。
- GBK:只需要支持英文、中文、日文和韩文,MySQL中的写法为gbk 。
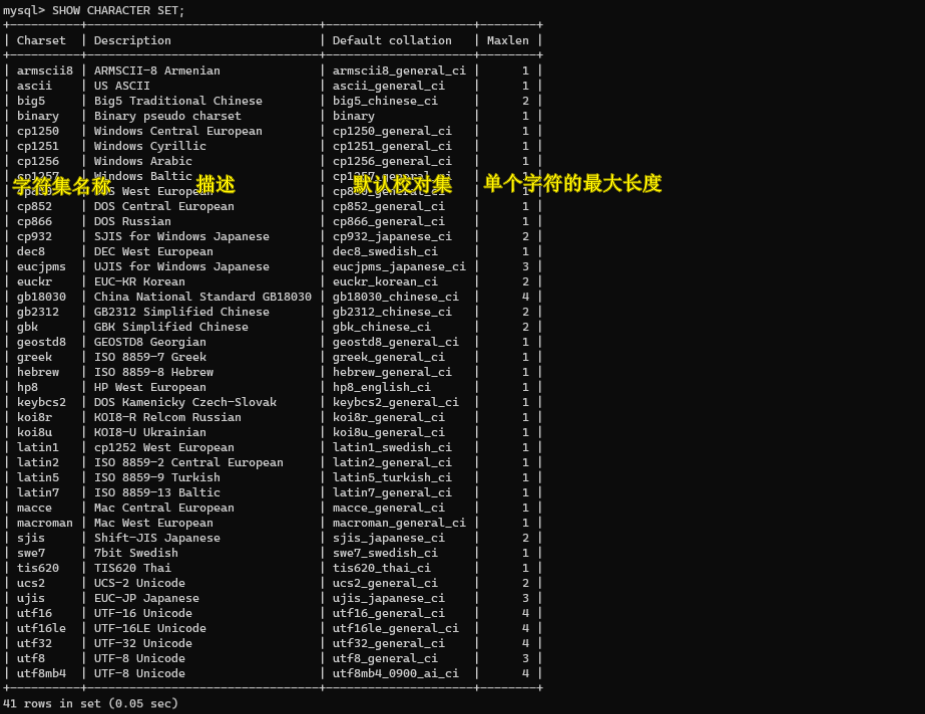
MySQL提供多种字符集,用户可以通过以下两种方式查看字符集:
# 第1种方式SHOW {CHARACTERSET|CHARSET} [LIKE'匹配模式'|WHERE 表达式];# 第2种方式SELECT*FROM INFORMATION_SCHEMA.CHARACTER_SETS [WHERE CHARACTER_SET_NAME LIKE'匹配模式'];
LIKE '匹配模式' | WHERE 表达式:可选项,LIKE子句可以根据指定模式匹配字符集;WHERE子句用于筛选满足条件的字符集。'匹配模式':为指定的匹配模式,可以通过“%”和“_” 匹配字符串。INFORMATION_SCHEMA.CHARACTER_SETS:存储数据库相关字符集信息。CHARACTER_SET_NAME:用于设置字符集的名称。
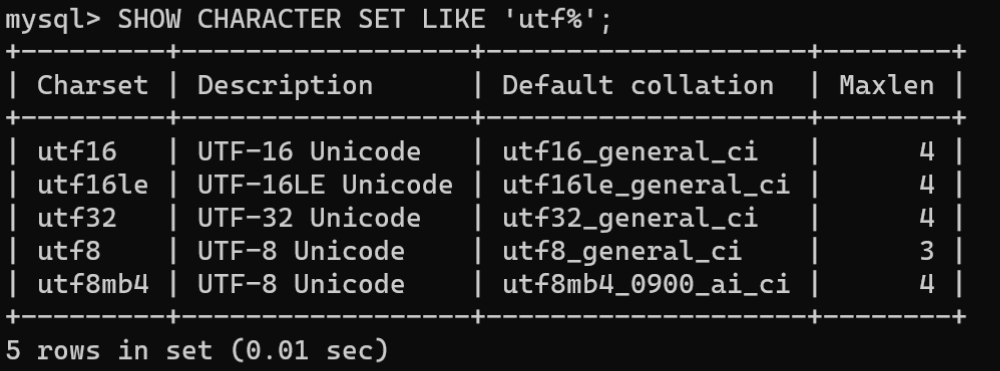
1.查看MySQL中所有可用字符集:
SHOWCHARACTERSET;
2.查看MySQL中含有
utf
的字符集:
SHOWCHARACTERSETLIKE'utf%';
4.2.校对集概述
校对集用于为不同字符集指定比较和排序的规则。MySQL 8.0.x版本默认校对集为
utf8mb4_0900_ai_ci
,其中
utf8
表示该校对集对应的字符集;
0900
是指Unicode校对算法版本;
_ai
表示口音不敏感,
_ci
表示大小写不敏感。
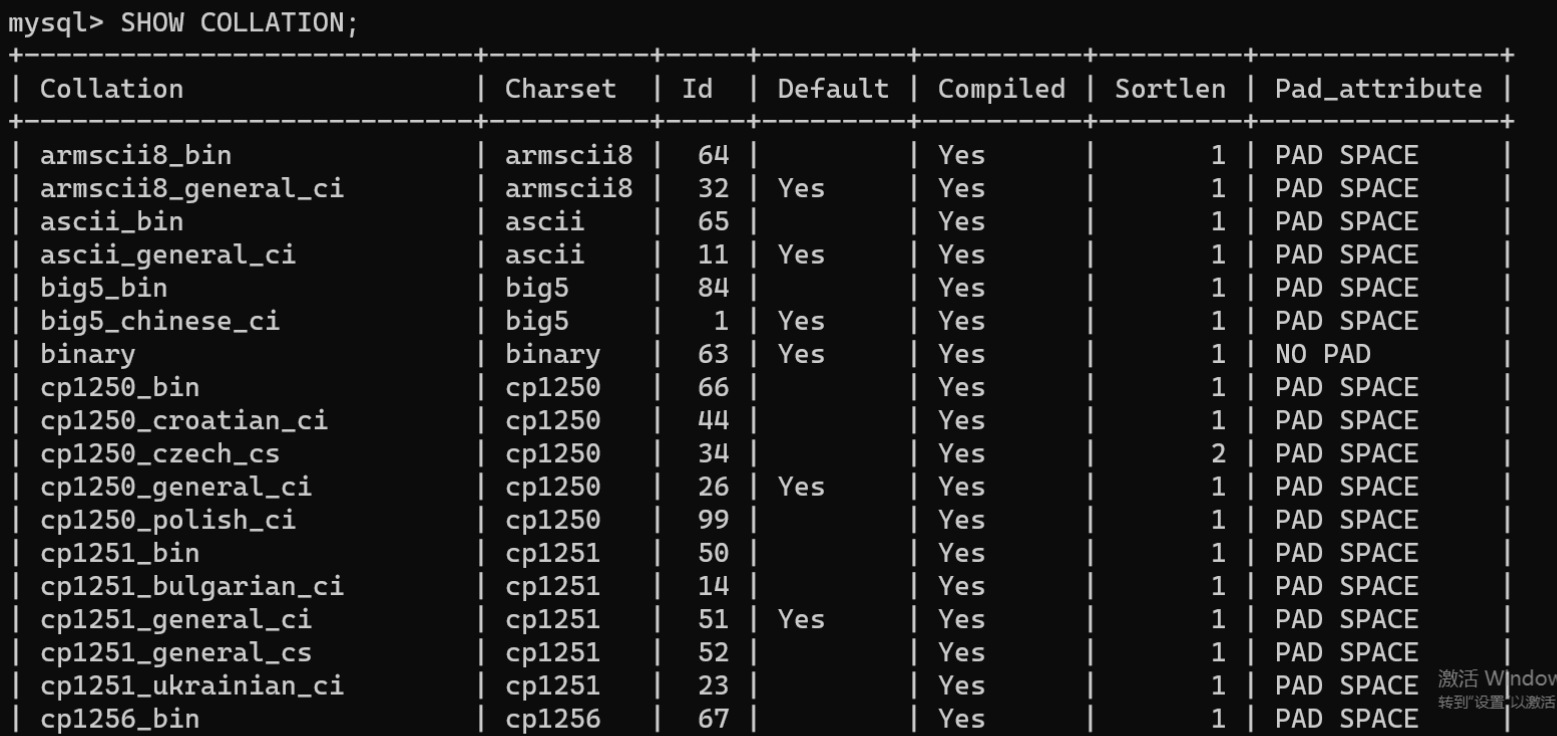
MySQL提供多种校对集,用户可以通过如下两种方式查看校对集:
# 第1种方式SHOW COLLATION [LIKE'匹配模式'|WHERE 表达式];# 第2种方式SELECT*FROM INFORMATION_SCHEMA.COLLATIONS [WHERE COLLATION_NAME LIKE'匹配模式'];
4.3.字符集和校对集的设置
- 设置服务器字符集和校对集:MySQL服务器的字符集为
utf8mb4,校对集为utf8mb4_0900_ai_ci。设置MySQL服务器字符集和校对集,需要了解当前MySQL服务器中有关字符集的变量。使用“SHOW VARIABLES LIKE 'character%';”语句查看MySQL服务器中的字符集变量: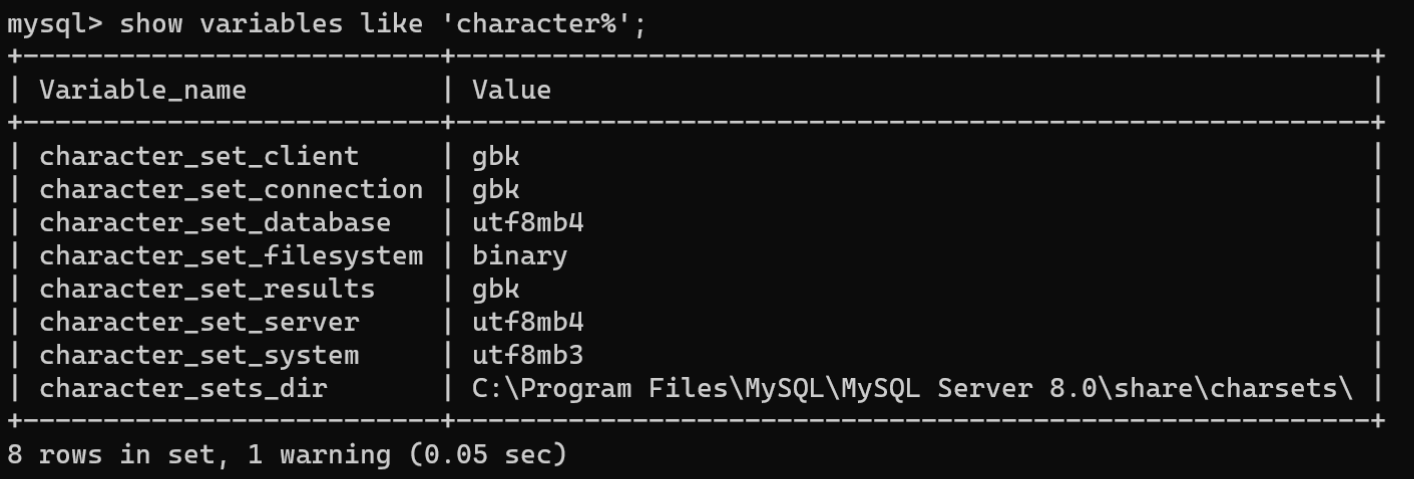
上述字符集相关变量说明:
变量名****说明character_set_client客户端字符集character_set_connection客户端与服务器连接使用的字符集character_set_database默认数据库使用的字符集(5.7.6版本后不推荐使用)character_set_filesystem文件系统字符集character_set_results将查询结果(如结果集或错误信息)返回给客户端的字符集character_set_server服务器默认字符集character_set_system服务器用来存储标识符的字符集character_sets_dir安装字符集的目录
若想要改变变量的值,可以通过
SET 变量名=值;
的方式实现:
SET character_set_client=utf8mb4;SET character_set_connection=utf8mb4;SET character_set_results=utf8mb4;
由于上述宁陵需要通过3条语句修改3个变量的值为utf8mb4,比较麻烦,在MySQL中还可以通过一条语句同时改变3个变量的值:
SET NAMES utf8mb4;
- 设置数据库字符集和校对集:
CREATE {DATABASE|SCHEMA} [IFNOTEXISTS] 数据库名称
[DEFAULT]CHARACTERSET[=] 字符集名称 |COLLATE[=] 校对集名称;# 若仅指定字符集,表示使用该字符集的默认校对集;若仅指定校对集,表示使用该校对集对应的字符集。
示例:创建数据库时设置字符集和校对集:
# 创建数据库时,指定字符集CREATEDATABASE mydb_1 CHARACTERSET utf8;# 创建数据库时,指定字符集和校对集CREATEDATABASE mydb_2 CHARACTERSET utf8 COLLATE utf8_bin;
- 设置数据表字符集和校对集:
CREATE[TEMPORARY]TABLE[IFNOTEXISTS] 表名 (
字段名 数据类型 [字段属性]...)[DEFAULT]CHARACTERSET[=] 字符集名称 |COLLATE[=] 校对集名称;
示例:创建数据表时设置字符集和校对集:
CREATETABLE my_charset (
username VARCHAR(20))CHARACTERSET utf8 COLLATE utf8_bin;
- 设置字段字符集和校对集:
CREATE[TEMPORARY]TABLE[IFNOTEXISTS] 表名 (
字段名 数据类型 [CHARACTERSET 字符集名称][COLLATE 校对集名称]...)[表选项];# 若没有为字段设置字符集与校对集,则会自动使用数据表的字符集与校对集
示例:创建数据表时设置字段的字符集和校对集,以及修改字段的字符集和校对集:
# 创建数据表时,设置字段的字符集与校对集CREATETABLE my_charset (
username VARCHAR(20)CHARACTERSET utf8 COLLATE utf8_bin
);# 修改字段的字符集与校对集ALTERTABLE my_charset MODIFY
username VARCHAR(20)CHARACTERSET utf8 COLLATE utf8_bin;
5.练习:设计用户表
设计用户表的字段需求如下:
- 用户身份标识号字段:用于唯一标识每个用户;
- 用户名字段:用于保存用户名,可以使用中文,不同用户的用户名不能相同,长度在20个字符以内;
- 手机号码字段:用于保存手机号码,长度为11个字符;
- 性别字段:用于爆粗你性别,有男、女、保密三种选择;
- 注册时间字段:用于保存之策时的日期和时间;
- 会员等级字段:用于保存标识会员等级的数字,最高为100.
四、数据库设计
1.数据库设计概述
数据库设计要求设计者对数据库设计的过程有深入的了解。数据库设计一般分为6个阶段:

- 需求分析:在需求分析阶段,数据库设计人员需要分析用户的需求,记录分析结果并形成需求分析报告。在此阶段,数据库设计人员需要与用户进行深入沟通,避免由于理解不准导致后续工作出现问题。在需求分析中需要收集数据、指定标准,这样才能为后续的工作做好铺垫。
- 概念结构设计:是整个数据库设计的关键,通过对用户的需求进行综合、归纳与抽象,形成一个概念数据模型。概念数据模型使设计人员摆脱数据库系统的具体技术问题,将精力集中在分析数据及数据之间的联系等方面。一般通过绘制E-R图,直观呈现数据库设计人员对用户需求的理解。
- 逻辑结构设计:此阶段需要将概念结构设计中完成的E-R图等成果,转换为数据库管理系统所支持的数据模型(如关系模型),完成实体、属性和联系的转换。在进行逻辑数据库设计时,应避免数据库出现数据冗余、更新异常、插入异常、删除异常等问题。
- 物理结构设计:此阶段需要为逻辑数据模型确定数据库的存储结构、文件类型等。
- 数据库实施:设计人员根据逻辑设计和物理设计的成果建立数据库,编写与调试应用程序,组织数据入库,并进行试运行。
- 数据库运行与维护:将数据库应用系统正式投入运行,在运行过程中不断进行维护、调整、备份和升级等工作。
2.数据库设计范式
为了规范化数据库,数据库专家提出了各种范式(Normal Form),常用的有第一范式(1NF)、第二范式(2NF)和第三范式(3NF),这3个范式简称三范式。
- 第一范式:指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值,或不能有重复的属性。简而言之,第一范式遵从原子性,属性不可再分。- 不满足第一范式的情况1:编号姓名性别手机号1代义男138001380002温乂兴男13800138001、13800138002- 不满足第一范式的情况2:编号姓名手机号手机号1代义13800138001138001380002温乂兴1380013800213800138000
- 第二范式:是在第一范式基础上建立起来的,满足第二范式必须先满足第一范式。第二范式要求实体的属性完全依赖于主键,对于复合主键而言,不能仅依赖主键的一部分。简而言之,第二范式遵从唯一性,非主键字段需完全依赖主键。- 不满足第二范式的情况-订单表:订单编号订单商品购买件数下单时间20240118001电脑12024-01-1820240120056键盘22024-01-2020240111345手机22023-12-31- 用户表:用户编号订单编号用户名付款状态120240118001温乂兴已支付120240120056温乂兴未支付220240111345杨鹏已支付在上表中,“用户编号”和“订单编号”组成了复合主键,“付款状态”完全依赖复合主键,而“用户名”只依赖“用户编号”。采用这种方式设计的用户表存在以下问题:1. 插入异常:如果一个用户没有下过订单,则该用户无法插入;2. 删除异常:如果删除一个用户的所有订单,则该用户也会被删除;3. 更新异常:由于用户名冗余,修改一个用户时需要修改多条记录,稍有不慎,漏掉某些记录,会出现更新异常。为满足第二范式,将复合主键“用户编号”和“订单编号”放到订单表中保存- 用户表用户编号用户名1温乂兴2杨鹏- 订单表用户编号订单编号订单商品购买件数下单时间付款状态120240118001电脑12024-01-18已支付120240120056键盘22024-01-20未支付220240111345手机22023-12-31已支付
- 第三范式:是在第二范式的基础上建立起来的,即满足第三范式必须先满足第二范式。第三范式要求一个数据表中每一列数据都和主键直接相关,而不能间接相关。简而言之,第三范式就是非主键字段不能相互依赖。- 不满足第三范式的情况:用户编号用户名用户等级用户享受折扣1杨仲翔10.952叶力齐10.953杨珺茹20.85上表中,“用户享受折扣”和“用户等级”相关,两者存在依赖关系。这种问题可能存在以下问题:- 插入异常:如果想增加一个新的等级,比如等级3及其折扣,由于没有用户,导致无法插入。- 删除异常:如果删除某个等级下的所有用户,则等级对应的折扣也被删除。- 更新异常:如果修改某个用户的等级,折扣也必须随之修改;如果修改某个等级的折扣,又因为折扣存在冗余,容易发生漏改。为满足第三范式,将“用户等级”和“用户享受折扣”拆分到单独的数据表中保存:- 用户表:用户编号用户名用户等级1杨仲翔12叶力齐13杨珺茹2- 折扣表:用户等级用户享受折扣10.9520.85
3.绘制E-R图
E-R
图也称实体-联系图(Entity Relationship Diagram),提供了表示实体类型、属性和联系的方法,用来描述现实世界的概念模型。
它是描述现实世界关系概念模型的有效方法。是表示概念关系模型的一种方式。用"矩形框"表示实体型,矩形框内写明实体名称;用"椭圆图框"表示实体的属性,并用"实心线段"将其与相应关系的"实体型"连接起来;
用"菱形框"表示实体型之间的联系成因,在菱形框内写明联系名,并用"实心线段"分别与有关实体型连接起来,同时在"实心线段"旁标上联系的类型(1:1,1:n或m:n)。
绘制E-R图的工具有很多,如draw.io、DiagramDesigner、Processon等,只要选用适合自己的工具绘制出正确的E-R图都是可以的。
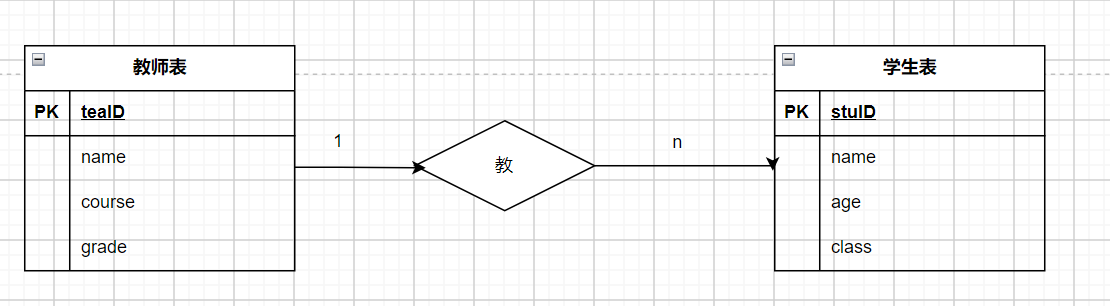
下图为老师和学生关系的E-R图:
4.练习:电子商务网站数据库设计
- 创建一个数据库
shop,用于保存电子商务网站中的数据; - 创建一个商品分类表,用于保存分类名称、分类排序、是否显示等信息,并要求支持多级分类嵌套;
- 创建一个商品表,用于保存商品id、商品名称、商品详情、图片等信息;
- 创建一个商品规格表,用于保存商品规格id和规格名称等信息;
- 创建也给商品属性表,用于保存商品属性id、商品属性名称、排序等信息;
- 创建一个用户表,用于保存用户id、用户名、密码、手机号、金额等信息;
- 创建一个评论表,用于保存评论id、用户id、评论内容、创建时间等信息;
- 创建一个购物车表,用于保存购物车id、用户id、商品id、单价等信息;
- 创建一个收货地址表,用于保存地址id、用户id、具体地址、收件人等信息;
- 创建一个订单表,用于保存订单id、用户id、订单总价等信息;
- 创建一个商品评分表,用于保存评分id、用户id、商品id、商品评分等信息。
参考sql:
# 创建数据库CREATEDATABASE shop;# 选择数据库USE shop;#创建商品分类表CREATETABLE sh_goods_category (
id INTUNSIGNEDPRIMARYKEYAUTO_INCREMENTCOMMENT'分类id',
parent_id INTUNSIGNEDNOTNULLDEFAULT0COMMENT'上级分类id',
name VARCHAR(100)DEFAULT''COMMENT'分类名称',
sort INTNOTNULLDEFAULT0COMMENT'排序值',
is_show TINYINTUNSIGNEDNOTNULLDEFAULT0COMMENT'是否显示',
create_time DATETIMENOTNULLDEFAULTCURRENT_TIMESTAMPCOMMENT'创建时间',
update_time DATETIMEDEFAULTNULLCOMMENT'更新时间')COMMENT'商品分类表';#添加测试数据INSERTINTO sh_goods_category (id, parent_id, name)VALUES(1,0,'办公'),(2,1,'耗材'),(3,2,'文具'),(4,0,'电子产品'),(5,4,'通讯'),(6,5,'手机'),(7,4,'影音'),(8,7,'音箱'),(9,7,'耳机'),(10,4,'计算机'),(11,10,'台式计算机'),(12,10,'笔记本计算机'),(13,0,'服装'),(14,13,'女装'),(15,14,'风衣'),(16,14,'毛衣');#创建商品表CREATETABLE sh_goods (
id INTUNSIGNEDPRIMARYKEYAUTO_INCREMENTCOMMENT'商品id',
category_id INTUNSIGNEDNOTNULLDEFAULT0COMMENT'分类id',
spu_id INTUNSIGNEDNOTNULLDEFAULT0COMMENT'SPU id',
sn VARCHAR(20)NOTNULLDEFAULT''COMMENT'编号',
name VARCHAR(120)NOTNULLDEFAULT''COMMENT'商品名称',
keyword VARCHAR(255)NOTNULLDEFAULT''COMMENT'关键词',
picture VARCHAR(255)NOTNULLDEFAULT''COMMENT'图片',
description VARCHAR(255)NOTNULLDEFAULT''COMMENT'描述',
content TEXTNOTNULLCOMMENT'详情',
score DECIMAL(3,2)NOTNULLDEFAULT0COMMENT'评分',
price DECIMAL(10,2)NOTNULLDEFAULT0COMMENT'价格',
stock INTUNSIGNEDNOTNULLDEFAULT0COMMENT'库存',
is_on_sale TINYINTUNSIGNEDNOTNULLDEFAULT0COMMENT'是否上架',
is_del TINYINTUNSIGNEDNOTNULLDEFAULT0COMMENT'是否删除',
is_free_shipping TINYINTUNSIGNEDNOTNULLDEFAULT0COMMENT'是否包邮',
sell_count INTUNSIGNEDNOTNULLDEFAULT0COMMENT'销量计数',
comment_count INTUNSIGNEDNOTNULLDEFAULT0COMMENT'评论计数',
on_sale_time DATETIMEDEFAULTNULLCOMMENT'上架时间',
create_time DATETIMENOTNULLDEFAULTCURRENT_TIMESTAMPCOMMENT'创建时间',
update_time DATETIMEDEFAULTNULLCOMMENT'更新时间')COMMENT'商品表';#添加测试数据INSERTINTO sh_goods (id, category_id, name, keyword, content, price, stock, score, comment_count)VALUES(1,3,'2H铅笔S30804','办公','考试专用',0.5,500,4.9,40000),(2,3,'钢笔T1616','办公','练字必不可少',15,300,3.9,500),(3,3,'碳素笔GP1008','办公','平时使用',1,500,5,98000),(4,12,'超薄笔记本Pro12','电子产品','轻小便携',5999,0,2.5,200),(5,6,'华为P50智能手机','电子产品','人人必备',1999,0,5,98000),(6,8,'桌面音箱BMS10','电子产品','扩音装备',69,750,4.5,1000),(7,9,'头戴耳机Star Y360','电子产品','独享个人世界',109,0,3.9,500),(8,11,'办公计算机 天逸510Pro','电子产品','适合办公',2000,0,4.8,6000),(9,15,'收腰风衣中长款','服装','春节潮流单品',299,0,4.9,40000),(10,16,'薄毛衣联名款','服装','居家旅行必备',48,0,4.8,98000);#创建商品SPU表CREATETABLE sh_goods_spu (
id INTUNSIGNEDPRIMARYKEYAUTO_INCREMENTCOMMENT'SPU id',
name VARCHAR(80)NOTNULLDEFAULT''COMMENT'SPU名称')COMMENT'商品SPU表';#创建商品规格表CREATETABLE sh_goods_spec (
id INTUNSIGNEDPRIMARYKEYAUTO_INCREMENTCOMMENT'规格id',
name VARCHAR(80)NOTNULLDEFAULT''COMMENT'规格名称')COMMENT'商品规格表';#创建商品规格项表CREATETABLE sh_goods_spec_item (
id INTUNSIGNEDPRIMARYKEYAUTO_INCREMENTCOMMENT'规格项id',
spec_id INTUNSIGNEDNOTNULLDEFAULT0COMMENT'规格id',
name VARCHAR(80)NOTNULLDEFAULT''COMMENT'规格项名称',
description VARCHAR(255)NOTNULLDEFAULT''COMMENT'描述',
picture VARCHAR(255)NOTNULLDEFAULT''COMMENT'可选图')COMMENT'商品规格项表';#创建商品规格组合表CREATETABLE sh_goods_spec_set (
goods_id INTUNSIGNEDNOTNULLDEFAULT0COMMENT'SKU id',
spec_item_id INTUNSIGNEDNOTNULLDEFAULT0COMMENT'规格项id')COMMENT'商品规格组合表';#添加测试数据INSERTINTO sh_goods_spu (id, name)VALUES(1,'新款智能手机');INSERTINTO sh_goods_spec (id, name)VALUES(1,'网络'),(2,'颜色'),(3,'内存');INSERTINTO sh_goods_spec_item (id, spec_id, name)VALUES(1,1,'移动'),(2,1,'电信'),(3,2,'白色'),(4,2,'黑色'),(5,3,'4GB'),(6,3,'6GB');INSERTINTO sh_goods_spec_set (goods_id, spec_item_id)VALUES(5,2),(5,3),(5,5);#创建商品属性表CREATETABLE sh_goods_attr (
id INTUNSIGNEDPRIMARYKEYAUTO_INCREMENTCOMMENT'属性id',
parent_id INTUNSIGNEDNOTNULLDEFAULT0COMMENT'上级属性id',
category_id INTUNSIGNEDNOTNULLDEFAULT0COMMENT'商品分类id',
name VARCHAR(80)NOTNULLDEFAULT''COMMENT'属性名称',
sort INTNOTNULLDEFAULT0COMMENT'排序值')COMMENT'商品属性表';#创建商品属性值表CREATETABLE sh_goods_attr_value (
id INTUNSIGNEDPRIMARYKEYAUTO_INCREMENTCOMMENT'属性值id',
goods_id INTUNSIGNEDNOTNULLDEFAULT0COMMENT'商品id',
attr_id INTUNSIGNEDNOTNULLDEFAULT0COMMENT'属性id',
attr_value VARCHAR(80)NOTNULLDEFAULT''COMMENT'属性值')COMMENT'商品属性值表';#创建商品筛选表CREATETABLE sh_goods_selector (
id INTUNSIGNEDPRIMARYKEYAUTO_INCREMENTCOMMENT'筛选id',
parent_id INTUNSIGNEDNOTNULLDEFAULT0COMMENT'上级筛选id',
category_id INTUNSIGNEDNOTNULLDEFAULT0COMMENT'商品分类id',
name VARCHAR(80)NOTNULLDEFAULT''COMMENT'筛选名称',
sort INTNOTNULLDEFAULT0COMMENT'排序值')COMMENT'商品筛选表';#创建商品筛选值表CREATETABLE sh_goods_selector_value (
id INTUNSIGNEDPRIMARYKEYAUTO_INCREMENTCOMMENT'筛选值id',
goods_id INTUNSIGNEDNOTNULLDEFAULT0COMMENT'商品id',
selector_id INTUNSIGNEDNOTNULLDEFAULT0COMMENT'筛选id',
selector_value VARCHAR(80)NOTNULLDEFAULT''COMMENT'筛选值')COMMENT'商品筛选值表';#添加测试数据INSERTINTO sh_goods_attr VALUES(1,0,6,'基本信息',0),(2,1,6,'机身颜色',0),(3,1,6,'输入方式',1),(4,1,6,'操作系统',2),(5,0,6,'屏幕',1),(6,5,6,'屏幕尺寸',0),(7,5,6,'屏幕材质',1),(8,5,6,'分辨率',2),(9,0,6,'摄像头',2),(10,9,6,'前置摄像头',0),(11,9,6,'后置摄像头',1),(12,0,6,'电池信息',3),(13,12,6,'电池容量',0),(14,12,6,'是否可拆卸',1);INSERTINTO sh_goods_attr_value VALUES(1,5,2,'黑色'),(2,5,3,'触摸屏'),(3,5,4,'Android'),(4,5,6,'5.5 寸'),(5,5,7,'IPS'),(6,5,8,'1920*1080'),(7,5,10,'1600 万'),(8,5,11,'800 万'),(9,5,13,'3500mAh'),(10,5,14,'否');#创建用户表CREATETABLE sh_user (
id INTUNSIGNEDPRIMARYKEYAUTO_INCREMENTCOMMENT'用户id',
name VARCHAR(100)NOTNULLUNIQUEDEFAULT''COMMENT'用户名',
password VARCHAR(255)NOTNULLDEFAULT''COMMENT'密码',
salt CHAR(32)NOTNULLDEFAULT''COMMENT'密码盐',
email VARCHAR(128)NOTNULLDEFAULT''COMMENT'邮箱',
mobile CHAR(11)NOTNULLDEFAULT''COMMENT'手机号',levelTINYINTUNSIGNEDNOTNULLDEFAULT0COMMENT'用户级别',
money DECIMAL(10,2)NOTNULLDEFAULT0COMMENT'金额',
gender TINYINTUNSIGNEDNOTNULLDEFAULT0COMMENT'性别',
qq VARCHAR(20)NOTNULLDEFAULT''COMMENT'QQ',
is_active TINYINTUNSIGNEDNOTNULLDEFAULT0COMMENT'是否激活',
reg_time DATETIMEDEFAULTNULLCOMMENT'注册时间',
create_time DATETIMENOTNULLDEFAULTCURRENT_TIMESTAMPCOMMENT'创建时间',
update_time DATETIMEDEFAULTNULLCOMMENT'更新时间')COMMENT'用户表';SELECT MD5(CONCAT(MD5('123456'),'salt1'));INSERTINTO sh_user (id, name, password, salt, money, is_active)VALUES(1,'Alex', MD5(CONCAT(MD5('123'),'salt1')),'salt1',1000,1),(2,'Bill', MD5(CONCAT(MD5('123'),'salt2')),'salt2',1000,1);SELECT id, name, password, salt FROM sh_user;#创建商品评论表CREATETABLE sh_goods_comment (
id INTUNSIGNEDPRIMARYKEYAUTO_INCREMENTCOMMENT'评论id',
parent_id INTUNSIGNEDNOTNULLDEFAULT0COMMENT'上级评论id',
user_id INTUNSIGNEDNOTNULLDEFAULT0COMMENT'用户id',
goods_id INTUNSIGNEDNOTNULLDEFAULT0COMMENT'商品id',
content TEXTNOTNULLCOMMENT'评论内容',
is_staff TINYINTUNSIGNEDNOTNULLDEFAULT0COMMENT'是否为工作人员',
is_show TINYINTUNSIGNEDNOTNULLDEFAULT0COMMENT'是否显示',
is_del TINYINTUNSIGNEDNOTNULLDEFAULT0COMMENT'是否删除',
create_time DATETIMENOTNULLDEFAULTCURRENT_TIMESTAMPCOMMENT'创建时间',
update_time DATETIMEDEFAULTNULLCOMMENT'更新时间')COMMENT'评论表';INSERTINTO sh_goods_comment ( id, user_id, goods_id, content, is_show, create_time)VALUES(1,1,8,'好',0,'2022-4-08 00:00:00'),(2,2,10,'不错',1,'2022-6-03 00:00:00'),(3,3,9,'满意',1,'2022-6-30 00:00:00'),(4,4,4,'携带方便',1,'2022-02-19 00:00:00'),(5,4,7,'中低音效果特别棒',1,'2022-01-19 00:00:00'),(6,5,8,'卡机',1,'2022-01-22 00:00:00'),(7,6,5,'黑夜拍照也清晰',1,'2022-02-15 00:00:00'),(8,7,9,'掉色、有线头',0,'2022-03-03 00:00:00'),(9,4,9,'还行',1,'2022-04-05 00:00:00'),(10,8,9,'特别彰显气质',1,'2022-04-16 00:00:00');#创建购物车表CREATETABLE sh_user_shopcart (
id INTUNSIGNEDPRIMARYKEYAUTO_INCREMENTCOMMENT'购物车id',
user_id INTUNSIGNEDNOTNULLDEFAULT0COMMENT'用户id',
goods_id INTUNSIGNEDNOTNULLDEFAULT0COMMENT'商品id',
goods_price DECIMAL(10,2)NOTNULLDEFAULT0COMMENT'单价',
goods_num INTUNSIGNEDNOTNULLDEFAULT0COMMENT'购买件数',
is_select TINYINTUNSIGNEDNOTNULLDEFAULT0COMMENT'是否选中',
create_time DATETIMENOTNULLDEFAULTCURRENT_TIMESTAMPCOMMENT'创建时间',
update_time DATETIMEDEFAULTNULLCOMMENT'更新时间')COMMENT'购物车表';#创建收货地址表CREATETABLE sh_user_address (
id INTUNSIGNEDPRIMARYKEYAUTO_INCREMENTCOMMENT'地址id',
user_id INTUNSIGNEDNOTNULLDEFAULT0COMMENT'用户id',
is_default TINYINTUNSIGNEDNOTNULLDEFAULT0COMMENT'是否默认',
province VARCHAR(20)NOTNULLDEFAULT''COMMENT'省',
city VARCHAR(20)NOTNULLDEFAULT''COMMENT'市',
district VARCHAR(20)NOTNULLDEFAULT''COMMENT'区',
address VARCHAR(255)NOTNULLDEFAULT''COMMENT'具体地址',
zip VARCHAR(20)NOTNULLDEFAULT''COMMENT'邮编',
consignee VARCHAR(20)NOTNULLDEFAULT''COMMENT'收件人',
phone VARCHAR(20)NOTNULLDEFAULT''COMMENT'联系电话',
create_time DATETIMENOTNULLDEFAULTCURRENT_TIMESTAMPCOMMENT'创建时间',
update_time DATETIMEDEFAULTNULLCOMMENT'更新时间')COMMENT'收货地址表';#创建订单表CREATETABLE sh_order (
id INTUNSIGNEDPRIMARYKEYAUTO_INCREMENTCOMMENT'订单id',
user_id INTUNSIGNEDNOTNULLDEFAULT0COMMENT'用户id',
total_price DECIMAL(10,2)NOTNULLDEFAULT0COMMENT'订单总价',
order_price DECIMAL(10,2)NOTNULLDEFAULT0COMMENT'应付金额',
province VARCHAR(20)NOTNULLDEFAULT''COMMENT'省',
city VARCHAR(20)NOTNULLDEFAULT''COMMENT'市',
district VARCHAR(20)NOTNULLDEFAULT''COMMENT'区',
address VARCHAR(255)NOTNULLDEFAULT''COMMENT'具体地址',
zip VARCHAR(20)NOTNULLDEFAULT''COMMENT'邮编',
consignee VARCHAR(20)NOTNULLDEFAULT''COMMENT'收件人',
phone VARCHAR(20)NOTNULLDEFAULT''COMMENT'联系电话',
is_valid TINYINTUNSIGNEDNOTNULLDEFAULT0COMMENT'是否有效',
is_cancel TINYINTUNSIGNEDNOTNULLDEFAULT0COMMENT'是否取消',
is_pay TINYINTUNSIGNEDNOTNULLDEFAULT0COMMENT'是否付款',statusTINYINTUNSIGNEDNOTNULLDEFAULT0COMMENT'物流状态',
is_del TINYINTUNSIGNEDNOTNULLDEFAULT0COMMENT'是否删除',
create_time DATETIMENOTNULLDEFAULTCURRENT_TIMESTAMPCOMMENT'创建时间',
update_time DATETIMEDEFAULTNULLCOMMENT'更新时间')COMMENT'订单表';#创建订单商品表CREATETABLE sh_order_goods (
id INTUNSIGNEDPRIMARYKEYAUTO_INCREMENTCOMMENT'id',
order_id INTUNSIGNEDNOTNULLDEFAULT0COMMENT'订单id',
goods_id INTUNSIGNEDNOTNULLDEFAULT0COMMENT'商品id',
goods_name VARCHAR(120)NOTNULLDEFAULT''COMMENT'商品名称',
goods_num INTUNSIGNEDNOTNULLDEFAULT0COMMENT'购买数量',
goods_price DECIMAL(10,2)NOTNULLDEFAULT0COMMENT'商品单价',
user_note VARCHAR(255)NOTNULLDEFAULT''COMMENT'用户备注',
staff_note VARCHAR(255)NOTNULLDEFAULT''COMMENT'卖家备注')COMMENT'订单商品表';#创建商品评分表CREATETABLE sh_goods_score (
id INTUNSIGNEDPRIMARYKEYAUTO_INCREMENTCOMMENT'评分id',
user_id INTUNSIGNEDNOTNULLDEFAULT0COMMENT'用户id',
goods_id INTUNSIGNEDNOTNULLDEFAULT0COMMENT'商品id',
goods_score TINYINTUNSIGNEDNOTNULLDEFAULT0COMMENT'商品评分',
service_score TINYINTUNSIGNEDNOTNULLDEFAULT0COMMENT'服务评分',
express_score TINYINTUNSIGNEDNOTNULLDEFAULT0COMMENT'物流评分',
is_invalid TINYINTUNSIGNEDNOTNULLDEFAULT0COMMENT'是否无效',
create_time DATETIMENOTNULLDEFAULTCURRENT_TIMESTAMPCOMMENT'评分时间')COMMENT'商品评分表';
五、单表操作
1.数据进阶操作
在实际开发中,除了需要对数据进行增删改查操作外,有时还需要进行一些进阶操作,如复制表结构和数据、解决主键冲突、清空数据和去除查询结构中的重复记录。
1.1.复制表结构和数据
- 复制已有的表结构:在开发时,若需要创建一个与已有数据表相同结构的数据表,基本语法格式如下:
CREATE[TEMPORARY]TABLE[IFNOTEXISTS] 新数据表名称 {LIKE 源表 |(LIKE 源表)}
我们以上一章节的数据库
shop
为例,将
sh_goods
数据表的表结构复制出来并命名为
my_goods
,并存放于
mydb
数据库中:
# 选择数据库use shop;# 创建mydb数据库createdatabase mydb characterset gbk;# 复制表结构CREATETABLE mydb.my_goods (LIKE sh_goods);
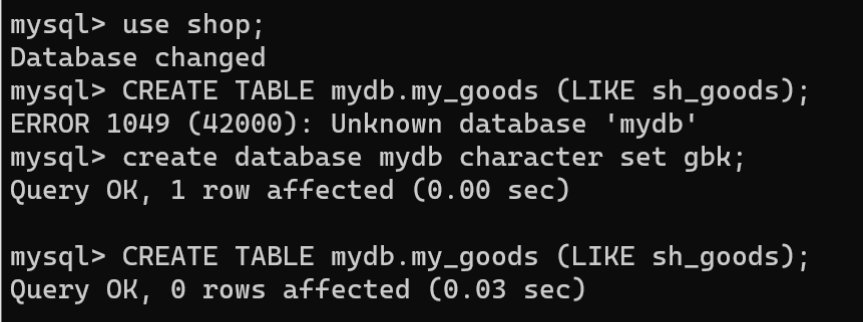
完成上步操作后,通过
show create table
语句查看
my_goods
数据表结构:
showcreatetable mydb.my_goods;
- 复制已有表数据:复制已有的表数据是新增数据的一种方式,它是从已有的数据中获取数据,并将获取的数据添加到对应的数据表中。需要注意的是,此种方式获取数据与添加数据的表结构要相同,否则可能会遇到添加不成功的情况,基本语法格式如下:
INSERT[INTO] 新数据表名称 [(字段名[,...])]SELECT*| {字段名[,...]} FROM 源表;
将
sh_goods
表中的数据复制到数据表
my_goods
中:
INSERTINTO mydb.my_goods SELECT*FROM sh_goods;
需要注意的是,在向一张数据表中复制数据时,如果数据表中含有主键,会遇到主键重复的问题,该如何解决呢?
INSERTINTO mydb.my_goods SELECT*FROM sh_goods;

对于上述问题,可以通过指定主键
id
字段以外的字段来完成数据复制,以解决主键重复问题,具体执行sql如下:
INSERTINTO mydb.my_goods (category_id, name, keyword, content, price, stock, score, comment_count)SELECT category_id, name, keyword, content, price, stock, score, comment_count FROM sh_goods;

1.2.解决主键冲突
在向数据表中添加一条记录时,如果添加的记录的主键值在现有的数据中已经存在,会产生主键冲突的情况。
下面当
my_goods
表经过数据复制以后,再添加一条会引起主键冲突的数据:
insertinto mydb.my_goods(id,name,content,keyword)values(20,'橡皮','修正书写错误','文具');
 从上述执行结果可以看出,系统提示添加数据的主键发生冲突。若要解决这类问题,MySQL提供了两种方式:
从上述执行结果可以看出,系统提示添加数据的主键发生冲突。若要解决这类问题,MySQL提供了两种方式:
- 主键冲突更新:主键冲突更新是指在添加数据的过程中若发生主键冲突,则添加数据操作利用更新的方式实现,语法格式如下:
INSERT[INTO] 数据表名称 [(字段名[,...])]
{VALUES|VALUE} (值[,...])ONDUPLICATEKEYUPDATE 字段名1=新值1[, 字段名2=新值2,...];
发生主键冲突时通过
“字段名1=新值1[, 字段名2=新值2, ...]”
更新此条记录中设置的字段名对应的新值。
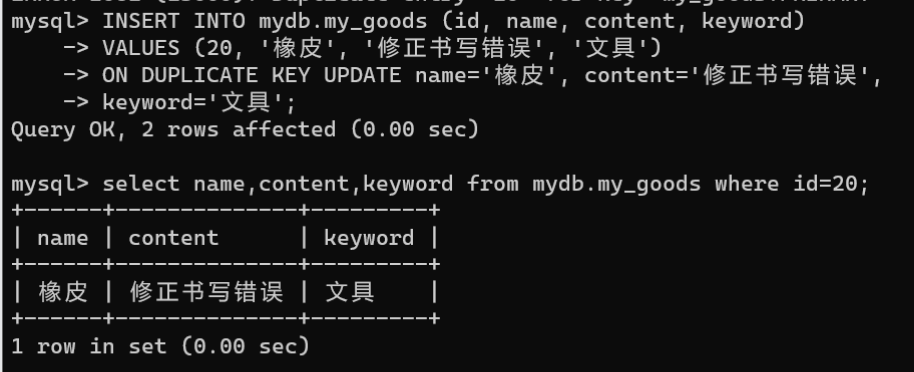
案例:修改以上发生主键冲突的添加语句:
INSERTINTO mydb.my_goods (id, name, content, keyword)VALUES(20,'橡皮','修正书写错误','文具')ONDUPLICATEKEYUPDATE name='橡皮', content='修正书写错误',
keyword='文具';
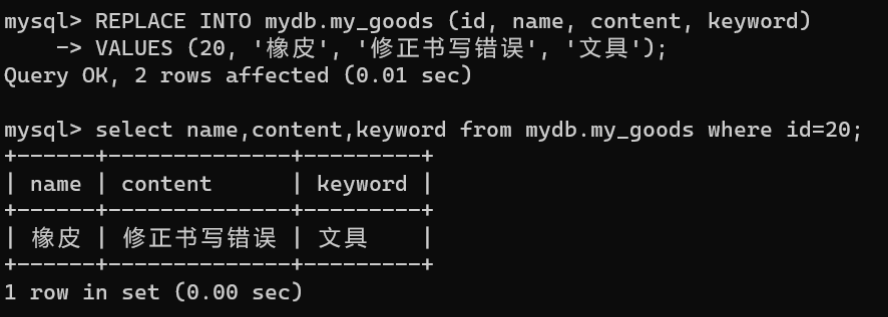
- 主键冲突替换:主键冲突替换是指在添加数据的过程中若发生主键冲突,则先删除原有记录,再新增记录,语法格式如下:
REPLACE[INTO] 数据表名称 [(字段名[,...])] {VALUES|VALUE} (值[,...]);
通过主键冲突替换的方式解决主键冲突:
REPLACEINTO mydb.my_goods (id, name, content, keyword)VALUES(20,'橡皮','修正书写错误','文具');
1.3.清空数据
在MySQL中,除了可以使用
delete
语句删除数据表中的部分数据或全部数据外,还可以通过
truncate
语句删除数据表中的全部数据,基本语法为:
TRUNCATE[TABLE] 数据表名称;
使用TRUNCATE语句与使用DELETE语句的本质区别:
① 实现方式不同:TRUNCATE语句相当于先执行删除数据表(DROP TABLE)的操作,再根据有效的表结构文件(.frm)重新创建数据表,实现数据清空操作;而DELETE语句则是逐条地删除数据表中保存的数据。
② 执行效率不同:针对数据量大的数据表,TRUNCATE语句比DELETE语句删除数据的方式执行效率更好。当删除的数据量很小时,DELETE语句的执行效率高于TRUNCATE语句。
③ 对设置了AUTO_INCREMENT字段的影响不同:使用TRUNCATE语句删除数据后,如果字段值设置AUTO_INCREMENT,再次添加数据时,该字段的值会从默认的初始值重新开始;使用DELETE语句删除数据时,字段值会保持原有的自动增长值。
④ 删除数据的范围不同:TRUNCAT语句只能用于清空数据表中的全部数据;而DELECT语句可以通过WHERE子句指定删除满足条件的部分数据。
⑤ 返回值含义不同:TRUNCAT语句的返回值一般是无意义的;而DELECT语句则会返回符合条件被删除的数据数量。
⑥ 所属SQL语言的组成部分不同:TRUNCAT语句通常被认为是数据定义语言;而DELECT语句属于数据操作语言。
truncatetable mydb.my_goods;
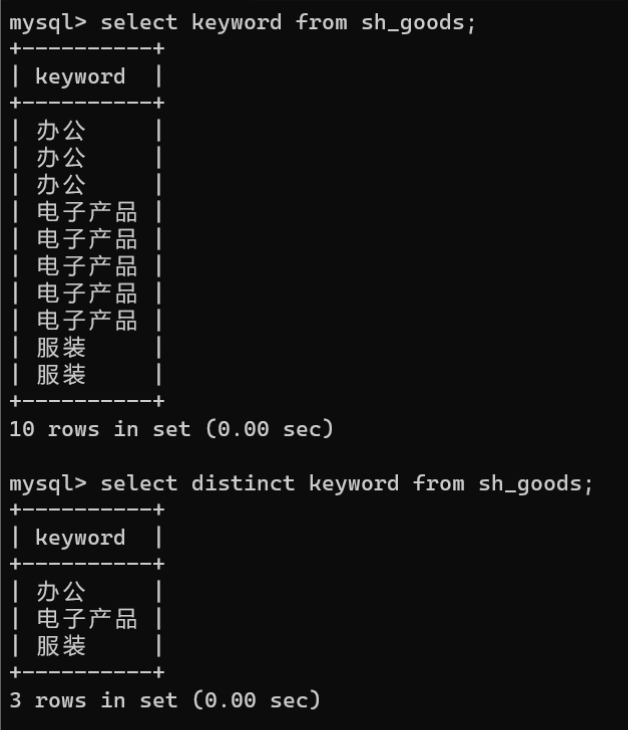
1.4.去除查询结果中的重复记录
在MySQL中,使用
SELECT
语句的查询选项
DISTINCT
实现去重查询,语法格式如下:
SELECT[查询选项] 字段名[,...]FROM 数据表名称;
查询选项为可选项,取值为
ALL
或
DISTINCT
。
ALL
为默认值,表示保留所有查询到的记录;
DISTINCT
表示去除重复记录,只保留一条记录。
select keyword from sh_goods;# 去重selectdistinct keywork from sh_goods;
2.排序和限量
随着电子商务网站的迅速发展,商品的数量越来越多,种类越来越丰富。人们在查看这些数据时,往往会希望对这些数据进行排序和限量,以便符合要求的数据显示在前面。
2.1.排序
在查询数据时,可以通过
ORDER BY
实现排序查询,其语法格式:
SELECT*| {字段名[,...]} FROM 数据表名称
ORDERBY 字段名1[ASC|DESC][, 字段名2[ASC|DESC]]...;
如果不指定排序方式默认按照ASC(ascending,升序)排序。排序意味着数据与数据发生比较,需要遵循一定的比较规则,具体规则取决于当前使用的校对集。默认情况下,数据和日期的顺序为从小到大;英文字母的顺序按ASCII码的次序,即从A到Z。如果想要降序排列,将
ASC
改为
DESC
(descending,降序)即可。
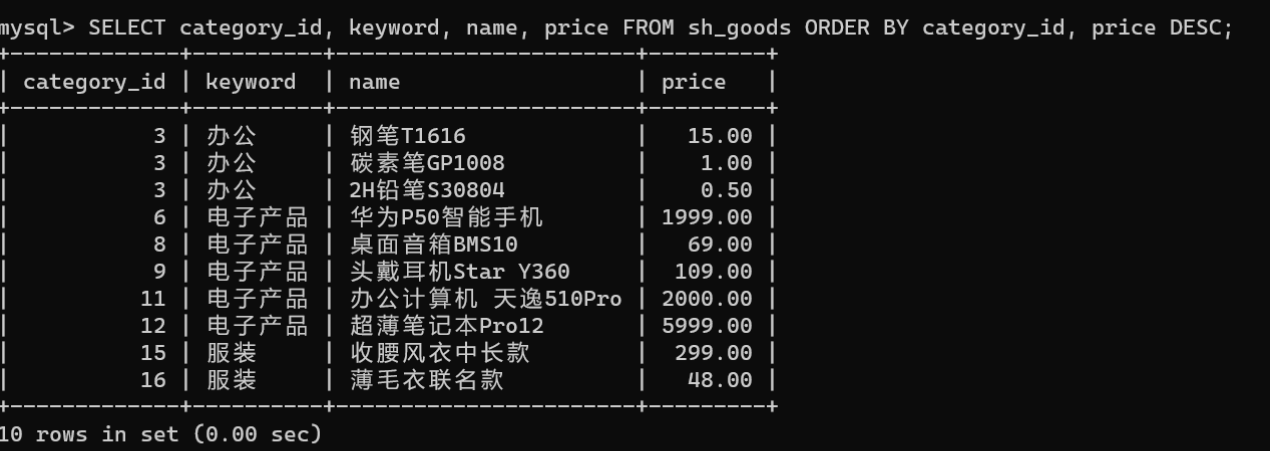
SELECT category_id, keyword, name, price FROM sh_goods ORDERBY category_id, price DESC;
2.2.限量
在查询数据时,
select
语句可能会返回多条数据,而用户现需要的数据可能只是其中的一条或几条,在
SELECT
语句中使用
LIMIT
语句即可实现数据的限量,语法为:
SELECT[查询选项]*| {字段名[,...]} FROM 数据表名称 [WHERE 条件表达式]LIMIT[OFFSET,] 记录数;
OFFSET为可选项,如果不指定OFFSET的值,默认值为0表示从第1条数据开始获取OFFSET值为1则从第2条数据开始获取,以此类推,“记录数”表示查询结果中的最大条数限制。
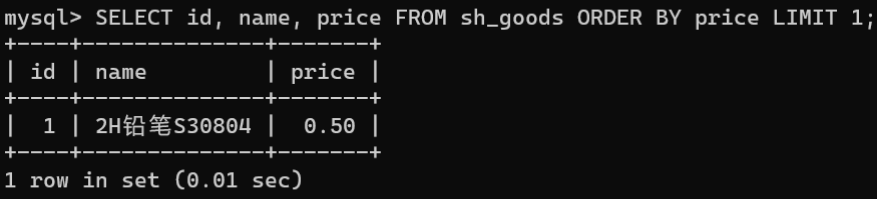
- 获取限量查询记录:查询sh_goods中价格最低的一件商品,首先获取商品的最低价格,然后将查询结果中的第1条记录获取出来。
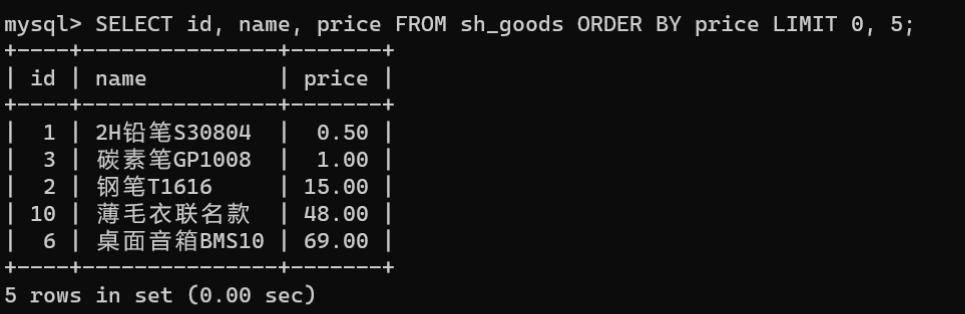
SELECT id, name, price FROM sh_goods ORDERBY price LIMIT1;
- 获取指定区间的记录:获取指定区间的记录通常在项目开发中用于实现数据的分页展示,从而缓解网络和服务器的压力。例如,从第1条记录开始,获取5条商品记录,商品记录中包含id、name和price。
SELECT id, name, price FROM sh_goods ORDERBY price LIMIT0,5;
3.分组与聚合函数
3.1.分组
在对数据表中的数据进行统计时,有时需要按照一定的类别进行统计。在MySQL中,可以使用
GROUP BY
根据指定的字段对返回的数据进行分组,如果某些数据的指定字段具有相同的值,分组后会被合并为一条数据。
查询数据时,在
WHERE
子句后添加
GROUP BY
即可根据指定字段进行分组,语法格式如下:
SELECT[查询选项]*| {字段名[,...]} FROM 数据表名称 [WHERE 条件表达式]GROUPBY 字段名[,...];
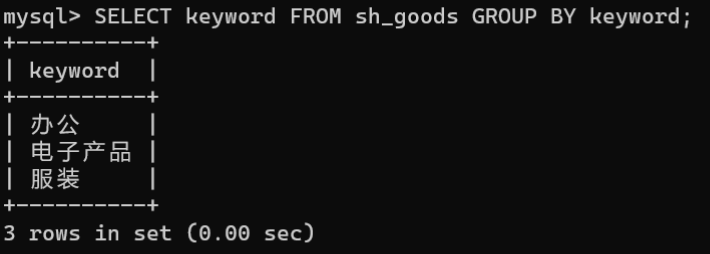
通过GROUP BY获取sh_goods表中keyword的分类:
SELECT keyword FROM sh_goods GROUPBY keyword;
3.2.聚合函数
在对数据进行分组统计时,经常需要结合MySQL提供的聚合来统计有价值的数据。可以通过聚合函数实现。聚合函数用于完成聚合操作,聚合操作是指对一组值进行运算,获得一个运算结果。
MySQL中常见的聚合函数如下:
聚合函数功能描述COUNT()返回参数字段的行数,参数可以时字段名或*SUM()返回参数字段的总和AVG()返回参数字段的平均值MAX()返回参数字段的最大值MIN()返回参数字段的最小值GROUP_CONCAT()返回符合条件的参数字段值的连接字符串JSON_ARRAYAGG()将结果集作为单个JSON数组返回JSON_OBJECTAGG()将结果集作为单个JSON对象返回
- COUNT():COUNT()函数用于统计查询的总记录数,语法格式如下:
SELECTCOUNT(*|字段名)FROM 数据表名称;
如果参数为
*
,标识统计数据表中数据的总条数,不会忽略字段中值为NULL的行。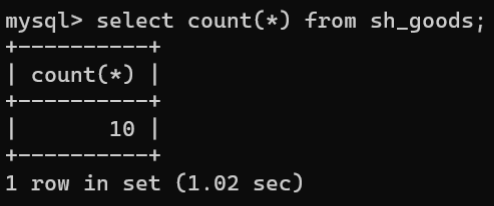
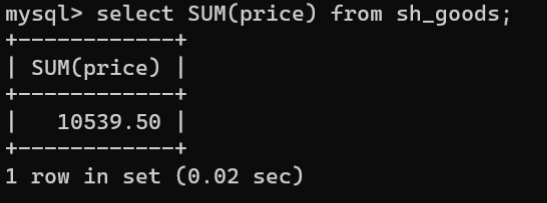
- SUM():SUM()函数会对指定字段中的值进行累加,并且在数据累加时忽略字段中的NULL值,语法格式如下:
SELECTSUM(字段名)FROM 数据表名称;
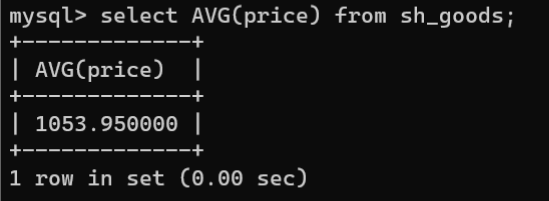
- AVG()函数:AVG()函数用于计算指定字段中的值的平均值,并且计算时会忽略字段中的NULL值,即只对非NULL的数值进行累加,然后将累加和除以非NULL的行数计算出平均值。语法格式如下:
SELECTAVG(字段名)FROM 数据表名称;
如果想要统计的字段中包含NULL值时,可以使用IFNULL()函数,将NULL值转换为0再计算。
语法格式如下:
SELECTAVG(IFNULL(sal,0))FROM 数据表名称;
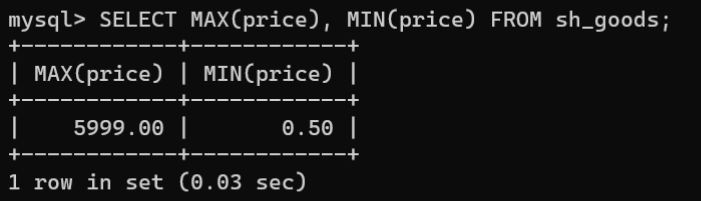
- MAX()函数和MIN()函数:分别用于统计指定字段的最大值和最小值,语法格式如下:
# MAX()SELECTMAX(字段名)FROM 数据表名称;# MIN()SELECTMIN(字段名)FROM 数据表名称;
- JSON_ARRAYAGG()函数和JSON_OBJECTAGG()函数:JSON_ARRAYAGG()函数的参数可以是一个字段或表达式,返回值为一个JSON数组;JSON_OBJECTAGG()函数将两个字段名或表达式作为参数,其中第1个参数表示“键”,第2个参数表示“键”对应的值,并返回一个包含键值对的JSON对象。 将id字段的结果集作为JSON数组返回,将id和name字段作为JSON对象返回:
SELECT JSON_ARRAYAGG(id)AS'[编号]', JSON_OBJECTAGG(id, name)AS'{编号:名称}'FROM sh_goods\G

3.3.分组并使用聚合函数
如果分组查询时要统计汇总,需要将
GROUP BY
和聚合函数一起使用,语法格式为:
SELECT[查询选项][字段名[,...]] 聚合函数 FROM 数据表名称 [WHERE 条件表达式]GROUPBY 字段名[,...];
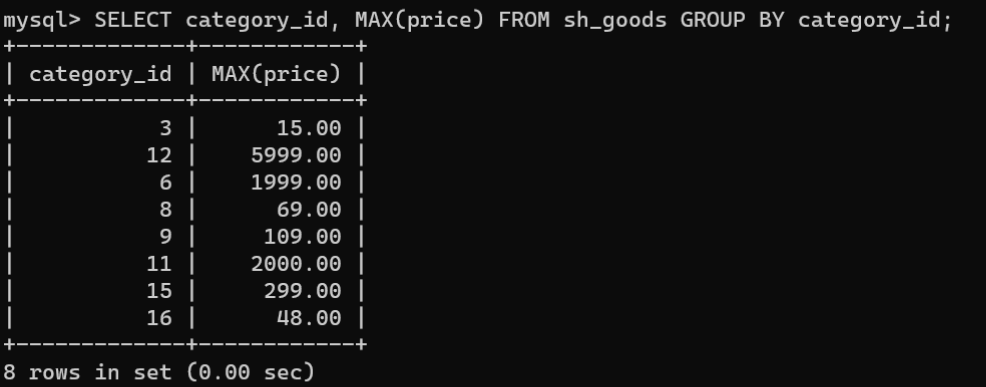
使用
GROUP BY
结合聚合函数
MAX()
统计每个分类下商品的最高价格:
SELECT category_id,MAX(price)FROM sh_goods GROUPBY category_id;
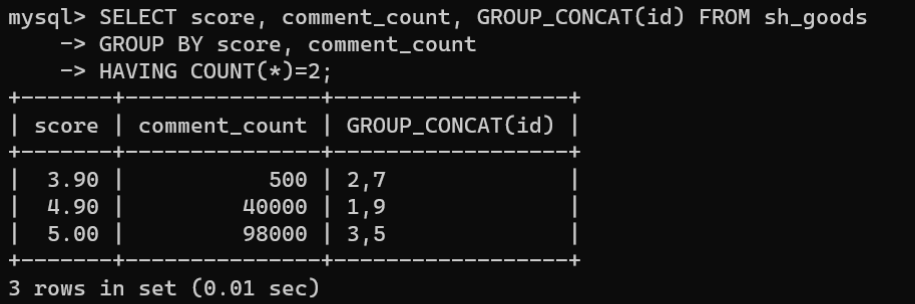
3.4.分组后进行条件筛选
如果需要对分组后的结果进行条件筛选,需要将
GROUP BY
和
HAVING
结合使用。语法格式为:
SELECT[查询选项][字段名[,...]]FROM 数据表名称 [WHERE 条件表达式]GROUPBY 字段名[,...]HAVING 条件表达式;
以评分字段score和评论计数字段comment_count分组统计含有两件商品的商品id:
SELECT score, comment_count, GROUP_CONCAT(id)FROM sh_goods
GROUPBY score, comment_count
HAVINGCOUNT(*)=2;
3.5.使用别名
有时候当数据表或字段名字很长,处理起来比较麻烦时,可以使用别名的方式。为字段设置别名需在字段名后面添加“AS 别名”即可。语法格式为:
# 数据表别名SELECT 数据表别名.字段名[,...]FROM 数据表名称 [AS] 数据表别名;# 字段别名SELECT 字段名1[AS] 数据表别名1, 字段名2[AS] 数据表别名2...FROM 数据表名称;
获取商品分类id为3或6的商品的最低价格:
SELECT category_id cid,MIN(price) min_price FROM sh_goods
GROUPBY cid HAVING cid=3OR cid=6;SELECT g.category_id cid,MIN(price) min_price FROM sh_goods g
GROUPBY cid HAVING cid=3OR cid=6;
3.5.回溯统计
回溯统计用于对数据进行分析。回溯统计按照指定字段分组后,系统自动对分组的字段进行了一次新的统计,产生一个新的统计数据,该数据对应的分组字段值为NULL。回溯统计的语法格式为:
SELECT[查询选项][字段名[,...]]FROM 数据表名称
[WHERE 条件表达式]GROUPBY 字段名[,...]WITH ROLLUP;
查看
sh_goods
表中每个分类编号
category_id
字段下的商品数量并回溯统计:
SELECT category_id,COUNT(*)FROM sh_goods
GROUPBY category_id WITH ROLLUP;
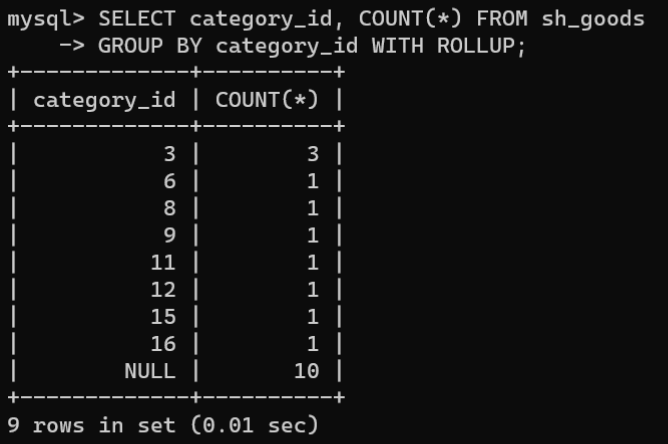
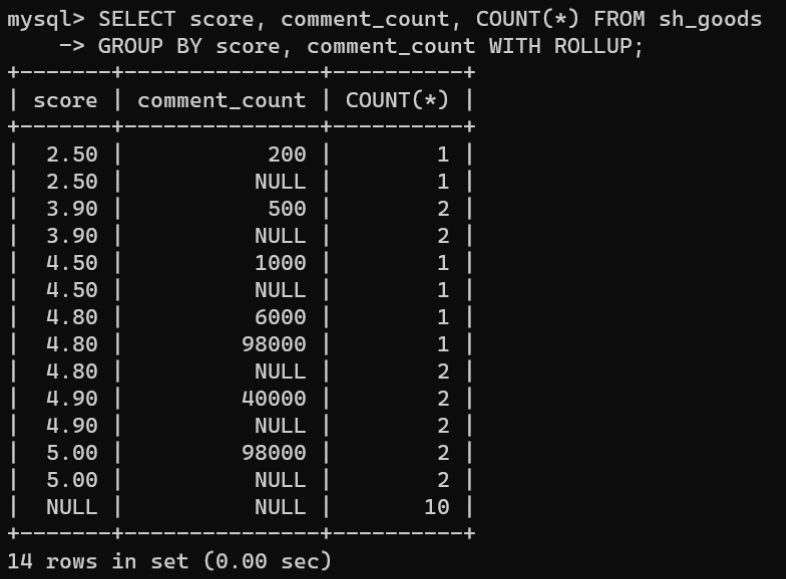
对多个分组进行回溯统计:
SELECT score, comment_count,COUNT(*)FROM sh_goods
GROUPBY score, comment_count WITH ROLLUP;
4.常用运算符
算术运算符适用于数值类型的数据,通常用于SELECT查询结果的字段。MySQL中常用的算术运算符:
算术运算符说明示例****结果+加法运算SELECT 5+2;7-减法运算SELECT 5-2;3乘法运算SELECT 52;10/除法运算SELECT 5/2;2.5%取模运算SELECT 5%2;1DIV除法运算,只返回整数部分SELECT 5 DIV 2;2MOD取模运算SELECT 5 MOD 21
MySQL所有运算符从高到低的优先级:
**运算符(优先级至上而下)***、/、DIV、%、MOD-(减运算符)、+<<、>>&|=(比较运算符)、<=>、>=、>、<=、<、<>、!=、IS、LIKE、REGEXP、IN、MEMBER OFBETWEEN、CASE、WHEN、THEN、ELSENOTAND、&&XOROR、||=(赋值运算符)、:=
5.练习
- 查询商品id等于9且有效的评论内容。
- 查询每个用户评论的商品数量。
- 查询最新发布的4条有效商品评论内容。
- 查询评论过两种以上不同商品的用户id及对应的商品id。
- 结合sh_goods表和sh_goods_comment表,查询没有任何评论信息的商品id和name。
- 结合sh_goods表和sh_goods_comment表,查询商品评分为5星的商品评论信息。
六、多表查询
1.联合查询
在数据库操作中,若想同时查看员工表和部门表中的数据,可以使用联合查询实现。联合查询是一种夺标查询方式,它将多个查询结果集合并为一个结果进行查询,还可以对数据量较大的表进行分表操作,将每张表的数据合并起来显示,联合查询的基本语法为:
SELECT*|{字段名[,...]} FROM 数据表名称1...UNION[ALL|DISTINCT]SELECT*|{字段名[,...]} FROM 数据表名称2...;
ALL
关键字保留所有查询结果,
DISTINCT
关键字为默认值,可以省略,表示去除查询结果中完全重复的数据。
注意:参与联合查询的SELECT语句的字段数量必须一致,查询结果中的列来源于第一条SELECT语句的字段。即使UNION后的SELECT查询的字段与第一个SELECT查询的字段不同,MySQL仅会根据第一个SELECT查询字段出现的顺序,对结果进行合并
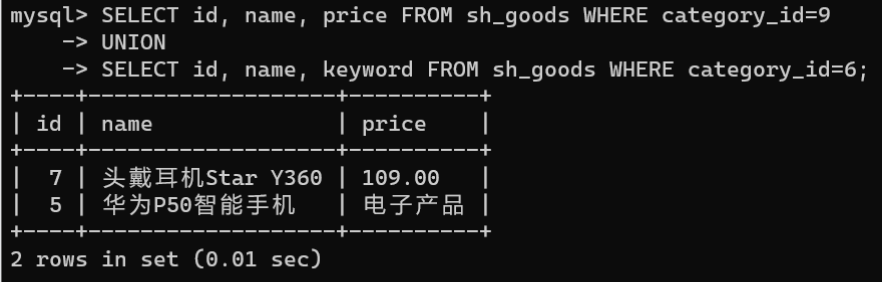
案例:在数据库
shop
下的
sh_goods
表中,以联合查询的方式获取
category_id
为9的
id
、
name
和
price
字段的信息,以及
category_id
为6的
id
、
name
和
keyword
字段的信息:
SELECT id, name, price FROM sh_goods WHERE category_id=9UNIONSELECT id, name, keyword FROM sh_goods WHERE category_id=6;
此外,若要对联合查询的记录进行排序操作,需要使用括号“()”包裹每一个
SELECT语句,在SELECT
语句内或在联合查询的最后添加
ORDER BY
语句。若要排序生效,必须在
ORDER BY
后添加
LIMIT
限定联合查询返回结果集的数量。
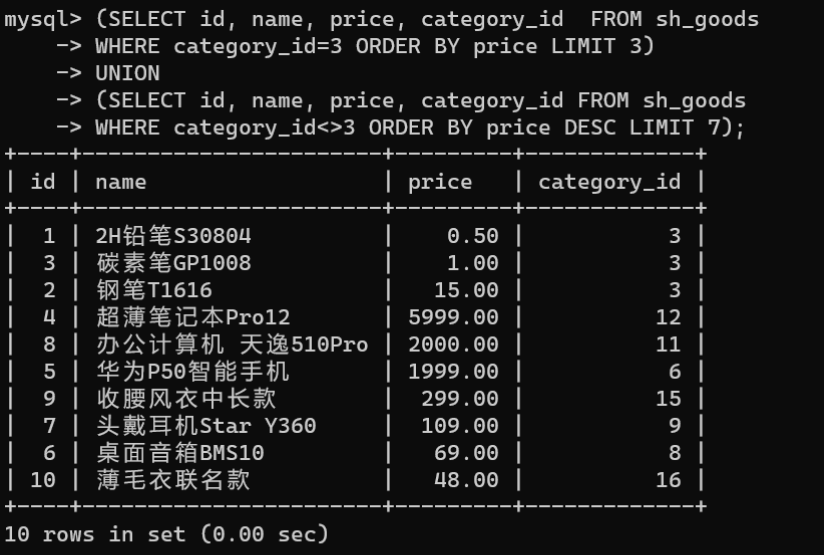
案例:使用联合查询对
sh_goods
表中
category_id
为3的商品按价格升序排序,其他类型的产品按价格降序排序:
(SELECT id, name, price, category_id FROM sh_goods
WHERE category_id=3ORDERBY price LIMIT3)UNION(SELECT id, name, price, category_id FROM sh_goods
WHERE category_id<>3ORDERBY price DESCLIMIT7);
2.联合查询
在关系数据库中,如果想要同时获得多张数据表中的数据,可以将多张数据表中相关联的字段进行连接,并对连接后的数据表进行查询,这样的查询放过是称为连接查询。在MySQL中,连接查询包括交叉连接查询、内连接查询和外连接查询。
2.1.交叉连接查询
交叉连接(CROSS JOIN)查询是笛卡儿积在SQL中的实现,查询结果由第1张表的每行与第2张表的每行连接组成。例如,数据表A有4条数据,5个字段,数据表B有10条数据,4个字段,这两张数据表交叉连接查询后的结果是40(4×10)条数据,每条记录中含有9(5+4)个字段。
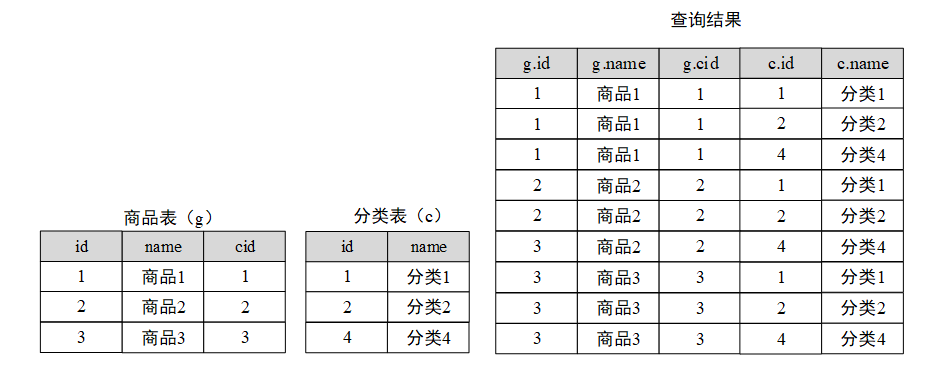
下图中,商品表定义了3个字段,其中
id
表示商品编号,
name
表示商品名称,
cid
表示商品分类。分类表中定义了2个字段,其中
id
表示分裂编号,
name
表示分类名称。有查询结果可知,商品表和分类表中的全部记录都显示在一个结果中,商品表中有3条记录,分类表中有3条记录,最后的查询结果有9条记录,每条记录中含有5个字段。
交叉连接查询的语法格式为:
SELECT*|{字段名[,...]} FROM 数据表名称1CROSSJOIN 数据表名称2;# 以上写法可以简写为:SELECT*|{字段名[,...]} FROM 数据表名称1,数据表名称2;
将商品分类表
sh_goods_category
和商品表
sh_goods
进行交叉连接查询:
SELECT c.id cid, c.name cname, g.id gid, g.name gname
FROM sh_goods_category c
CROSSJOIN sh_goods g ORDERBY c.id, g.id;# 简写形式SELECT c.id, c.name, g.id, g.name
FROM sh_goods_category AS c, sh_goods AS g;
2.2.内连接查询
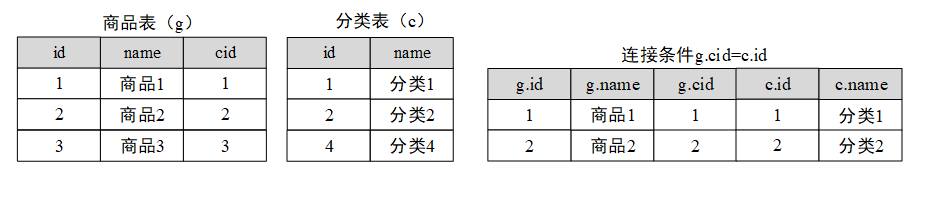
内连接(INNER JOIN)查询是将一张表中的每一条数据按照指定条件到另外一张表中进行匹配,如果匹配成功,则保留数据,如果匹配失败,则不保留数据。
下图为商品表和分类表,使用内连接查询添加商品分类的商品的信息:
MySQL中内连接查询分为隐式内连接查询和显示内连接查询两种。
- 隐式内连接查询:语法格式如下:
SELECT*|{字段名[,...]} FROM 数据表名称1, 数据表名称2WHERE 连接条件;
- 显示内连接查询:在查询多张表时速度比隐式内连接查询快,语法格式如下:
SELECT*|{字段名[,...]} FROM 数据表名称1[INNER]JOIN 数据表名称2ON 连接条件;
[INNER] JOIN
用于连接两张数据表,其中
INNER
可以省略;
ON
用来设置内连接的连接条件。由于内连接查询是对两张表进行操作,在查询数据时,为了避免重名出现错误,需要在连接条件中指定所操作的字段来源于哪一张表,可以使用“数据表.字段名”或“表别名.字段名”的方式进行区分。
对商品分类表
sh_goods_category
和商品表
sh_goods
进行内连接查询:
SELECT g.id gid, g.name gname, c.id cid, c.name cname
FROM sh_goods_category c JOIN sh_goods g
ON g.category_id=c.id;
2.3.外连接查询
有时需要查询出符合条件的记录外,还需要查询出其中一张数据表中符合条件之外的其他记录,此时就需要使用外连接查询。外连接查询的语法格式如下:
SELECT 数据表名称.字段名[,...]FROM
数据表名称1LEFT|RIGHT[OUTER]JOIN 数据表名称2ON 连接条件;# 数据表名称1一般称为左表,数据表名称2一般称为右表
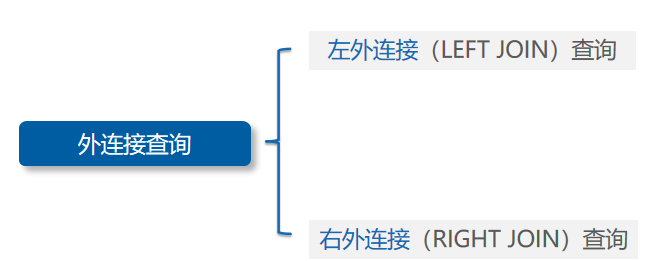
使用左外连接查询和右外连接查询的区别:
- 左外连接查询:返回左表中的所有记录和右表中符合连接条件的记录。
- 右外连接查询:返回右表中的所有记录和左表中符合连接条件的记录。
- 左外连接查询:左外连接查询是用左表的记录匹配右表的记录,查询的结果包括左表中的所有记录,以及右表中满足连接条件的记录。如果左表的某条记录在右表中不存在,则右表中对应字段的值显示为NULL。左外连接查询示意图:
 查询评分为5的商品名称及对应的分类名称,查询出所有商品的分类名称,使用左外连接将商品表作为查询中的左表:
查询评分为5的商品名称及对应的分类名称,查询出所有商品的分类名称,使用左外连接将商品表作为查询中的左表:SELECT g.name gname, g.score gscore, c.name cnameFROM sh_goods g LEFTJOIN sh_goods_category cON g.category_id=c.id AND g.score=5ORDERBY g.score;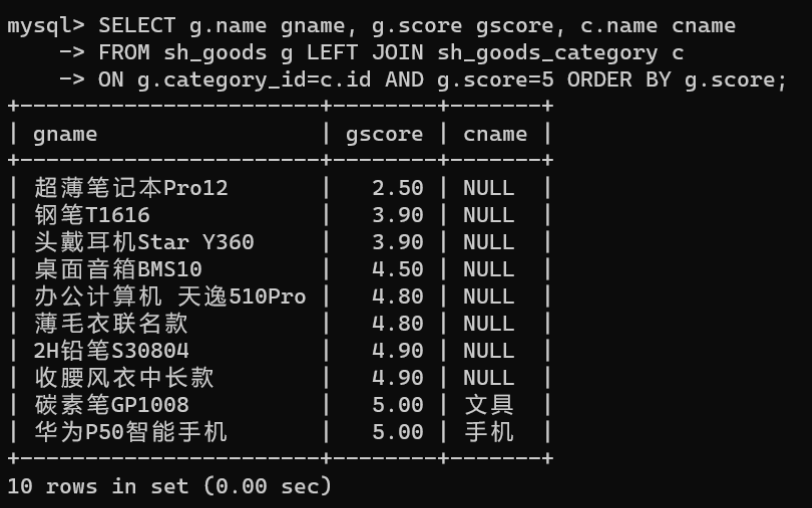 2.右外连接查询:右外连接查询是用右表的记录匹配左表的记录,查询的结果包括右表中的所有记录,以及左表中满足连接条件的记录。如果右表的某条记录在左表中不存在,则左表中对应字段的值显示为NULL。左外连接查询示意图:
2.右外连接查询:右外连接查询是用右表的记录匹配左表的记录,查询的结果包括右表中的所有记录,以及左表中满足连接条件的记录。如果右表的某条记录在左表中不存在,则左表中对应字段的值显示为NULL。左外连接查询示意图: 查询评分为5的商品分类名称对应的商品名称,评分不为5的商品分类名称也需要查询出来,使用右外连接,将商品分类表作为查询中的右表:
查询评分为5的商品分类名称对应的商品名称,评分不为5的商品分类名称也需要查询出来,使用右外连接,将商品分类表作为查询中的右表:SELECT g.name gname, g.score gscore, c.name cnameFROM sh_goods g RIGHTJOIN sh_goods_category cON g.category_id=c.id AND g.score=5ORDERBY g.score DESC;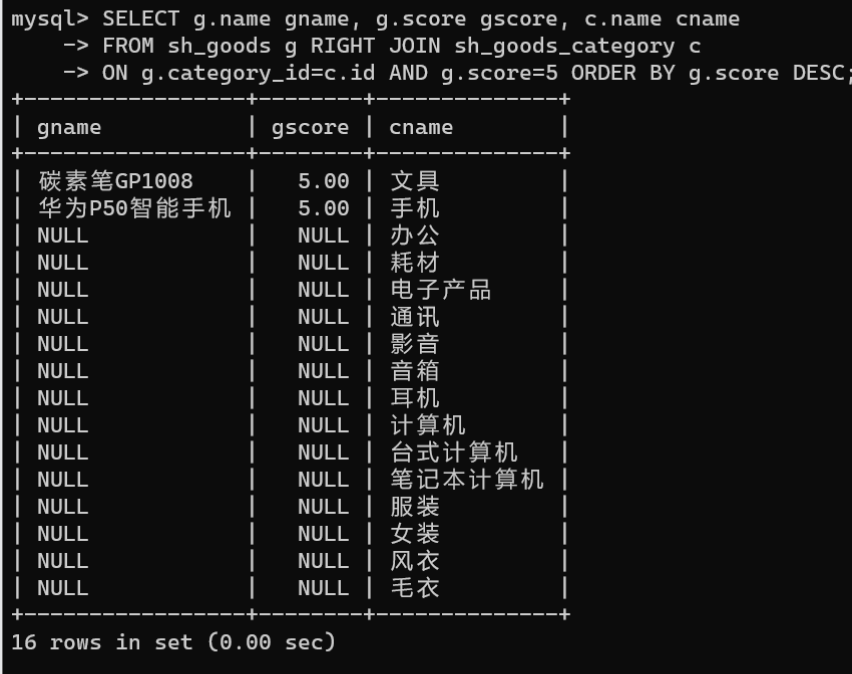
3.子查询
3.1.子查询的分类
子查询是指在一个SQL语句A(A可以是SELECT语句、INSERT语句、UPDATE语句或DELETE语句)中嵌入一个查询语句B,将语句B作为执行的条件或查询的数据源,语句B就是子查询语句。子查询语句是一条完整的SELECT语句,能够独立执行,并且需要使用小括号进行包裹。
在含有子查询的语句中,子查询必须书写在小括号内。MySQL首先执行子查询中的语句,然后再将返回的结果作为外层SQL语句的过滤条件。当同一条SQL语句包含多层子查询时,他们执行的顺序是从最里层的子查询开始执行。
子查询常见的划分方式有以下5种: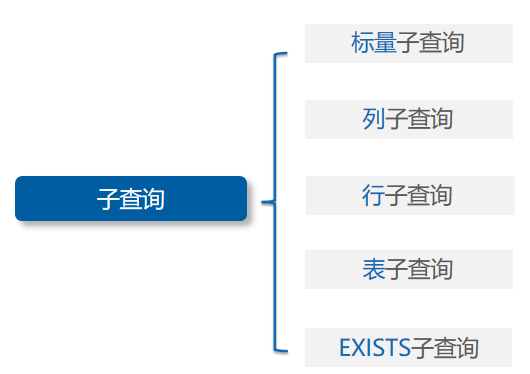
- 标量子查询:标量子查询是指子查询返回的结果为单个数据,即一行一列。标量子查询位于WHERE之后,通常与运算符=、<>、>、>=、<、<=结合使用。语法格式如下:
SELECT*|{字段名[,...]} FROM 数据表名称
WHERE 字段名 {=|<>|>|>=|<|<=}
(SELECT 字段名 FROM 数据表名称 [WHERE][GROUPBY][HAVING][ORDERBY][LIMIT]);
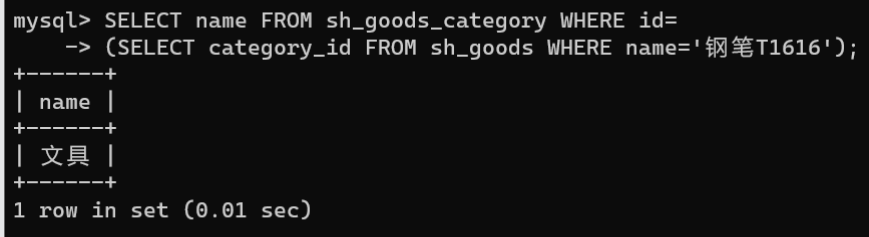
利用标量子查询的方式,从
sh_goods_category
表中获取商品名称为“钢笔T1616”所在的商品分类名称。
① 通过子查询返回
name
为“钢笔T1616”的
category_id
的值。
② 根据
category_id
的值筛选出与
sh_goods_category
表中的id值相等的信息。
SELECT name FROM sh_goods_category WHERE id=(SELECT category_id FROM sh_goods WHERE name='钢笔T1616');
- 列子查询:列子查询是一种返回结果为一列多行数据的子查询。列子查询位于
WHERE之后,通常与运算符IN、NOT IN结合使用。其中,IN表示在指定的集合范围之内,多选一;NOT IN表示不在指定的集合范围之内。语法格式如下:
SELECT*|{字段名[,...]} FROM 数据表名称
WHERE 字段名 {IN|NOTIN}
(SELECT 字段名 FROM 数据表名称 [WHERE][GROUPBY][HAVING][ORDERBY][LIMIT]);
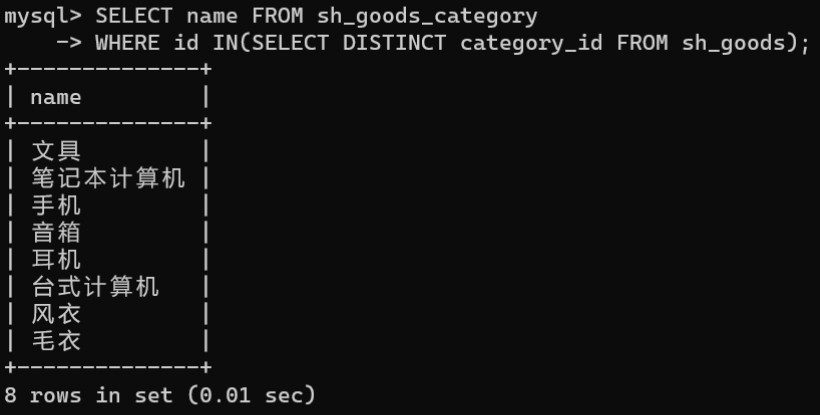
利用列子查询的方式,从sh_goods_category表中获取添加了商品的商品分类名称有哪些。
① 先通过子查询返回category_id的值。
② 使用IN关键字根据category_id的值查询部门分类名称的信息。
SELECT name FROM sh_goods_category
WHERE id IN(SELECTDISTINCT category_id FROM sh_goods);
- 行子查询:行子查询的返回结果为一行多列,位于WHERE之后,通常与比较运算符、
IN和NOT IN结合使用。不同比较运算符的行比较:
不同比较运算符的行比较****逻辑关系等价于(a, b)=(x, y)(a=x) AND (b=y)(a, b)<=>(x, y)(a<=>x) AND (b<=>y)(a, b)<>(x, y)或(a, b)!=(x, y)(a<>x) OR (b<>y)(a, b)>(x, y)(a>x) OR ((a=x) AND (b>y))(a, b)>=(x, y)(a>x) OR ((a=x) AND (b>=y))(a, b) < (x, y)(a<x) OR ((a=x) AND (b<y))(a, b)<=(x, y)(a<x) OR ((a=x) AND (b<=y))
语法格式如下:
SELECT*|{字段名[,...]} FROM 数据表名称
WHERE(字段名1, 字段名2,...) {比较运算符|IN|NOTIN}
(SELECT 字段名1, 字段名2...FROM 数据表名称 [WHERE][GROUPBY][HAVING][ORDERBY][LIMIT]);
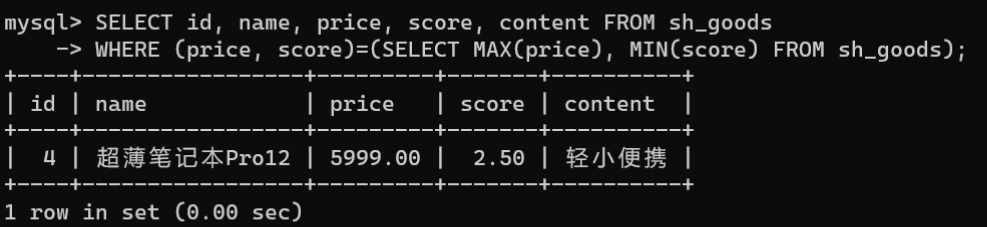
从sh_goods表中获取价格最高,且评分最低的商品信息:
SELECT id, name, price, score, content FROM sh_goods
WHERE(price, score)=(SELECTMAX(price),MIN(score)FROM sh_goods);
- 表子查询:表子查询是一种返回结果为多行多列的子查询,可以是一行一列、一列多行、一行多列或多行多列。表子查询多位于FROM关键字之后。语法格式如下:
SELECT*|{字段名[,...]} FROM(表子查询)[AS] 别名
[WHERE][GROUPBY][HAVING][ORDERBY][LIMIT];
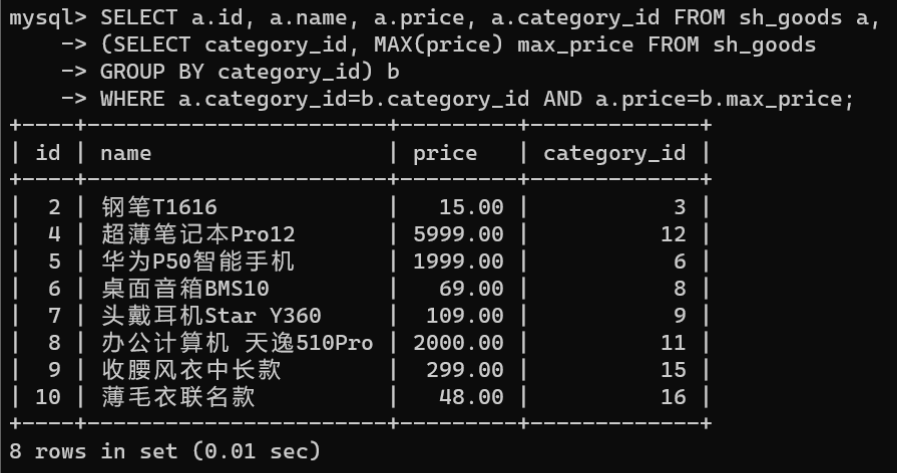
从
sh_goods
表中获取每个商品分类下价格最高的商品信息:
SELECT a.id, a.name, a.price, a.category_id FROM sh_goods a,(SELECT category_id,MAX(price) max_price FROM sh_goods
GROUPBY category_id) b
WHERE a.category_id=b.category_id AND a.price=b.max_price;
- EXISTS子查询:
EXISTS子查询用于判断子查询语句是否有返回的结果,若存在结果则返回1,代表成立;否则返回0,代表不成立。EXISTS子查询位于WHERE之后。语法格式如下:
SELECT*|{字段名[,...]} FROM 数据表名称 WHEREEXISTS(SELECT*FROM 数据表名称 [WHERE][GROUPBY][HAVING][ORDERBY][LIMIT]);
在
sh_goods_category
表中存在名称为“厨具”的分类时,将
sh_goods
表中id等于5的商品名称修改为电饭煲,价格修改为400,分类修改为“厨具”对应的id:
UPDATE sh_goods SET name='电饭煲', price=400,
category_id=(SELECT id FROM sh_goods_category WHERE name='厨具')WHEREEXISTS(SELECT id FROM sh_goods_category WHERE name='厨具')AND id=5;

3.2.子查询关键字
在
WHERE
子查询中,不仅可以使用比较运算符,还可以使用MySQL提供的一些特定关键字,常用的子查询关键字还有
ANY和ALL
。带ANY、SOME、ALL关键字的子查询,不能使用运算符<=>。若子查询结果与条件匹配时有
NULL
,那么此条记录不参与匹配。
- ANY关键字结合子查询:ANY关键字表示“任意一个”的意思,必须和比较运算符一起使用。语法格式如下:
SELECT*|{字段名[,...]} FROM 数据表名称 WHERE 字段名 比较运算符
ANY(SELECT 字段名 FROM 数据表名称 [WHERE][GROUPBY][HAVING][ORDERBY][LIMIT]);
从
sh_goods_category
表中获取商品价格小于200的商品分类名称:
SELECT name FROM sh_goods_category WHERE id=ANY(SELECTDISTINCT category_id FROM sh_goods WHERE price<200);
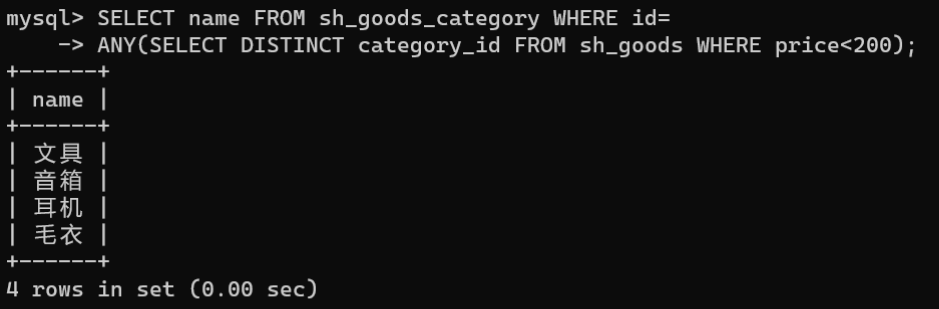
- ALL关键字结合子查询:
ALL关键字表示“所有”的意思,ALL关键字结合子查询时,表示与子查询返回的所有值进行比较,只有全部符合ALL子查询的结果时,才返回1,否则返回0。语法格式如下:
SELECT*|{字段名[,...]} FROM 数据表名称 WHERE 字段名 比较运算符
ALL(SELECT 字段名 FROM 数据表名称 [WHERE][GROUPBY][HAVING][ORDERBY][LIMIT]);
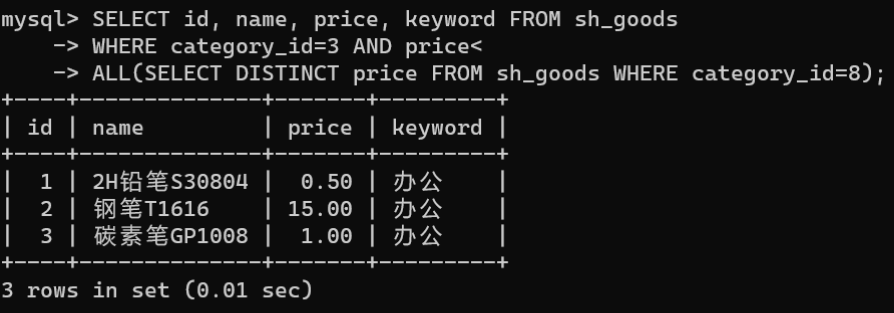
从
sh_goods
表中获取
category_id
为3,且商品价格全部低于
category_id
为8的商品信息:
SELECT id, name, price, keyword FROM sh_goods
WHERE category_id=3AND price<ALL(SELECTDISTINCT price FROM sh_goods WHERE category_id=8);
4.外键约束
外键约束指在一个数据表中引用另一个数据表中的一列或多列,被引用的列应该具有主键约束或唯一性约束,从而保证数据的一致性和完整性。其中,被引用的表称为主表;引用外键的表称为从表。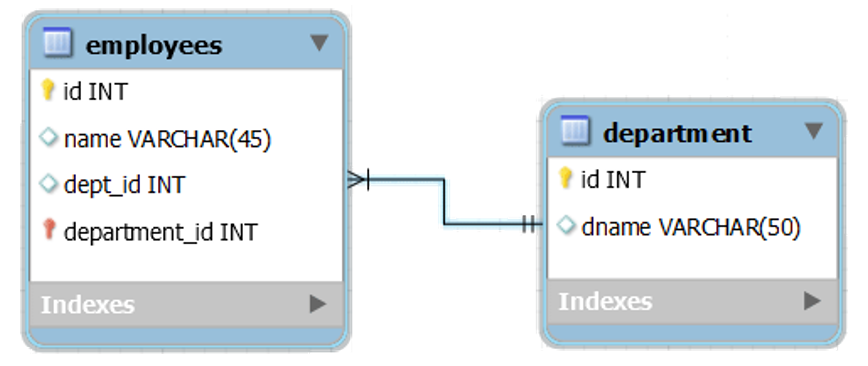
4.1.添加外键约束
在MySQL中,可以通过
FOREIGN KEY
添加外键约束。外键约束可以在创建数据表时设置,也可以在修改数据表示添加。
- 创建数据表时设置外键约束:语法格式如下:
CREATETABLE 数据表名称 (
字段名1 数据类型,...[CONSTRAINT[外键名称]]FOREIGNKEY(外键字段名)REFERENCES 主表(主键字段名)[ONDELETE {RESTRICT|CASCADE|SETNULL|NOACTION|SETDEFAULT}][ONUPDATE {RESTRICT|CASCADE|SETNULL|NOACTION|SETDEFAULT}]);
关键字
CONSTRAINT
用于定义外键名称,
FOREIGN KEY
表示外键约束,
REFERENCES
用于指定外键引用哪个表的主键。
ON DELETE
与
ON UPDATE
用于设置主表中的数据被删除或修改时,从表对应数据的处理办法,从而保证数据的一致性。
ON DELETE
与
ON UPDATE
的各参数的具体说明:
参数****说明RESTRICT默认值,拒绝主表删除或更新外键关联的字段CASCADE主表中删除或更新数据时,自动删除或更新从表中对应的数据SET NULL主表中删除或更新数据时,使用NULL值替换从表中对应的数据(不适用于设置了非空约束的字段)NO ACTION拒绝主表删除或更新外键关联的字段SET DEFAULT设为默认值,但InnoDB目前不支持
在
mydb
数据库中,部门表
department
为主表,员工表
employees
为从表,添加外键约束:
1.创建主表部门表:
CREATETABLE mydb.department (
id INTUNSIGNEDPRIMARYKEYAUTO_INCREMENTCOMMENT'部门编号',
name VARCHAR(50)NOTNULLCOMMENT'部门名称')COMMENT'部门表';
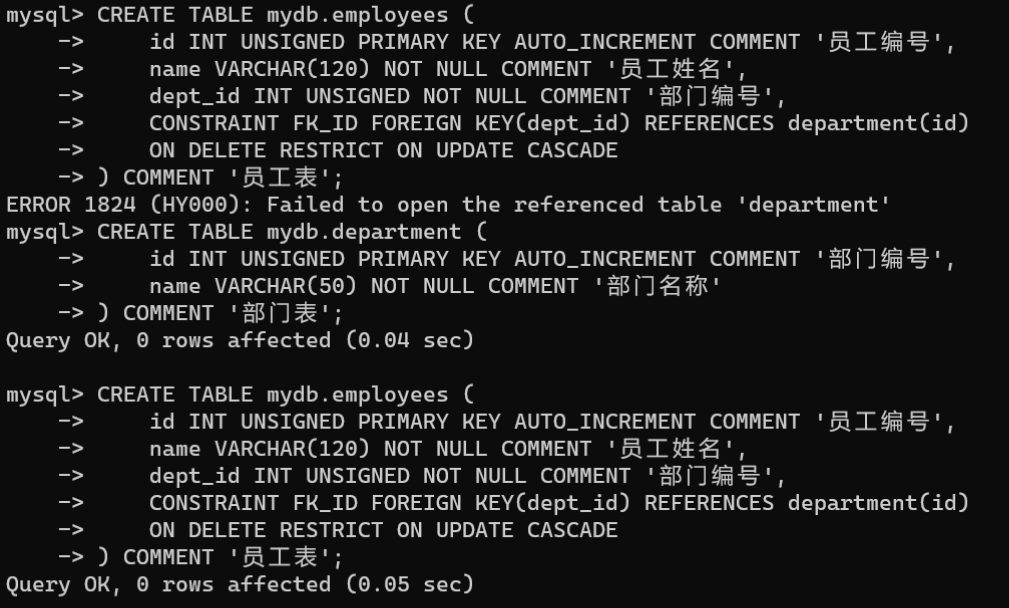
2.创建从表员工表,为
dept_id
字段添加外键约束:
CREATETABLE mydb.employees (
id INTUNSIGNEDPRIMARYKEYAUTO_INCREMENTCOMMENT'员工编号',
name VARCHAR(120)NOTNULLCOMMENT'员工姓名',
dept_id INTUNSIGNEDNOTNULLCOMMENT'部门编号',CONSTRAINT FK_ID FOREIGNKEY(dept_id)REFERENCES department(id)ONDELETERESTRICTONUPDATECASCADE)COMMENT'员工表';
- 修改数据表时添加外键约束:修改数据表时使用
ALTER TABLE语句的ADD子句添加外键约束。yu发格式如下:
ALTERTABLE 从表
ADD[CONSTRAINT[外键名称]]FOREIGNKEY(外键字段名)REFERENCES 主表(主键字段名)[ONDELETE {CASCADE|SETNULL|NOACTION|RESTRICT|SETDEFAULT}][ONUPDATE {CASCADE|SETNULL|NOACTION|RESTRICT|SETDEFAULT}];
修改方式添加外键约束:
droptable mydb.employees;CREATETABLE mydb.employees (
id INTUNSIGNEDPRIMARYKEYAUTO_INCREMENTCOMMENT'员工编号',
name VARCHAR(120)NOTNULLCOMMENT'员工姓名',
dept_id INTUNSIGNEDNOTNULLCOMMENT'部门编号')COMMENT'员工表';ALTERTABLE mydb.employees
ADDCONSTRAINT FK_ID FOREIGNKEY(dept_id)REFERENCES department(id)ONDELETERESTRICTONUPDATECASCADE;
4.2.关联表操作
- 添加数据:一个具有外键约束的从表在添加数据时,外键字段的值会受到主表数据的约束。若要为两个数据表添加数据,需要先为主表添加数据,再为从表添加数据,且从表中外键字段不能添加主表中不存在的数据。向从表中添加主表不存在的数据时:
mysql>INSERTINTO mydb.employees (name, dept_id)VALUES('Tom',3);ERROR 1452(23000): Cannot addorupdate a child row: a foreignkeyconstraint fails (`mydb`.`employees`,CONSTRAINT`FK_ID`FOREIGNKEY(`dept_id`)REFERENCES`department`(`id`)ONDELETERESTRICTONUPDATECASCADE)先向主表添加数据,再向从表添加主表存在的数据时:INSERTINTO mydb.department (id, name)VALUES(3,'研发部');INSERTINTO mydb.employees (name, dept_id)VALUES('Tom',3);
- 更新数据:如果对主表执行更新操作,从表将按照其设置外键约束时设置的ON UPDATE参数自动执行相应的操作。将部门名称为“研发部”的部门编号修改为1:
UPDATE mydb.department SET id=1WHERE name='研发部'; 当主表
当主表department中name为“研发部”的id值成功修改为1后,从表employees中的相关用户(Tom)的外键dept_id也同时被修改为1: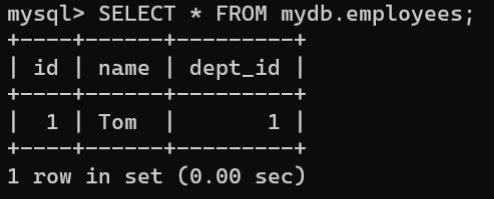
- 删除数据:如果对主表执行删除操作,从表将按照其设置外键约束时设置的
ON DELETE参数自动执行相应的操作。删除主表数据时,从表中含有该条记录对应的数据:mysql>DELETEFROM mydb.department WHERE id=1;ERROR 1451(23000): Cannot deleteorupdate a parent row: a foreignkeyconstraint fails (`mydb`.`employees`,CONSTRAINT`FK_ID`FOREIGNKEY(`dept_id`)REFERENCES`department`(`id`)ONDELETERESTRICTONUPDATECASCADE)先删除从表中的记录,再删除主表中的记录:DELETEFROM mydb.employees WHERE dept_id=1;DELETEFROM mydb.department WHERE id=1;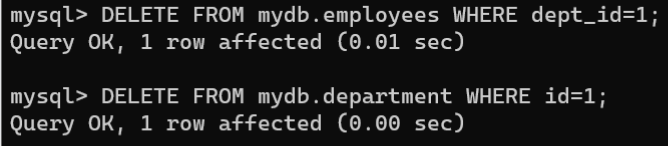
4.3.删除外键约束
若要解除两张数据表之间的关联,可以使用ALTER TABLE语句的DROP子句删除外键约束。基本语法格式ru下:
ALTERTABLE 从表 DROPFOREIGNKEY 外键名称;
删除主表department和从表employees之间的外键约束:
ALTERTABLE mydb.employees DROPFOREIGNKEY FK_ID;

若要在删除外键约束的同时删除索引,则需要通过手动删除索引的方式完成。基本语法格式如下:
ALTERTABLE 数据表名称 DROPKEY 外键索引名称;
手动删除索引:
ALTERTABLE mydb.employees DROPKEY FK_ID;
5.练习
- 查询sh_goods_attr表中category_id为6所对应的商品的属性信息,将属性信息按照层级升序排列。
- 查询sh_goods_attr_value表中goods_id为5的商品所具有的属性信息,显示属性名称和属性值。
- 查询sh_goods_attr表中parent_id为1的属性包含的所有子属性值。
- 查询拥有属性值个数大于1的商品的id和name。
七、事务
1.事务的概念
在现实生活中,人们经常会进行转账操作,转账可以分为转入和转出两部分,只有这两部分都完成才认为转账成功。在数据库中,转账操作通过两条SQL语句来实现,如果其中任意一条SQL语句出现异常没有执行成功,会导致两个账户的金额不正确。为了防止这种情况的发生,就需要使用MySQL中的事务(transaction)。
在MySQL中,事务是针对数据库的一组操作,它可以由一条或多条SQL语句组成,且每个SQL语句是相互依赖的。事务执行的过程中,只要有一条SQL语句执行失败或发生错误,则其他语句都不会执行。也就是说,事务的执行要么成功,要么就返回到事务开始前的状态。
MySQL中的事务必须满足4个特性,分别是原子性(atomicity)、一致性(consistency)、隔离性(isolation)和持久性(durability)。
- 原子性:指一个事务必须被视为不可分割的最小工作单元,只有事务中所有的数据操作都执行成功,整个事务才算执行成功。事务中如果有任何一个SQL语句执行失败,已经执行成功的SQL语句必须撤销,数据库的状态返回到事务执行前的状态。
- 一致性:指在使用事务时,无论执行成功还是失败,都要保证数据库系统处于一致状态,保证数据库系统不会返回一个未处理的事务中。MySQL中的一致性主要由日志机制实现,通过日志记录数据库的所有变化,为事务恢复提供跟踪记录。
- 隔离性:指事务在执行时不受其他事务的影响。隔离性保证了未完成事务的所有操作与数据库系统的隔离,直到事务完成为止,才能看到事务的执行结果。
- 持久性:指事务一旦提交,其对数据库中数据的修改就是永久性的。事务的持久性不能做到百分之百的持久,只能从事务本身的角度来保证持久性,如果遇到一些外部原因(例如硬盘损坏)导致数据库发生故障,所有提交的数据可能都会丢失。
2.事务的处理
2.1.事务的基本操作
默认情况下,用户用户执行的每一条SQL语句都会被当成单独的事务自动提交。如果想要将一组SQL语句作为一个事务,则需要先启动事务,启动事务的语句如下:
STARTTRANSACTION;

启动事务后,每一条SQL语句不再自动提交,需要手动提交,手动提交事务的语句如下:
COMMIT;
如果不想提交当前事务,可以将事务取消(即回滚),回滚事务的语句如下:
ROLLBACK;
操作事务时应注意以下5点:
ROLLBACK只能针对未提交的事务回滚,已提交的事务无法回滚。当执行COMMIT或ROLLBACK后,当前事务就会自动结束。- MySQL中的事务不允许嵌套,若在执行
START TRANSACTION语句前上一个事务还未提交,会隐式地执行提交操作。 - 事务处理主要是针对数据表中数据的处理,不包括创建或删除数据库、数据表,修改表结构等操作,而且执行这类操作时会隐式地提交事务。
InnoDB存储引擎支持事务,而另一个常见的存储引擎MyISAM不支持事务。对于MyISAM存储引擎的数据表,无论事务是否提交,对数据的操作都会立即生效,不能回滚。- 在MySQL中,还可以使用
START TRANSACTION的别名BEGIN或BEGIN WORK来显式地开启一个事务。由于BEGIN与存储过程中的BEGIN…END冲突,因此不推荐使用BEGIN。
案例:事务的演示。
1.选择
shop
数据库后查看
sh_user
表中的用户数据:
use shop;SELECT name, money FROM sh_user;
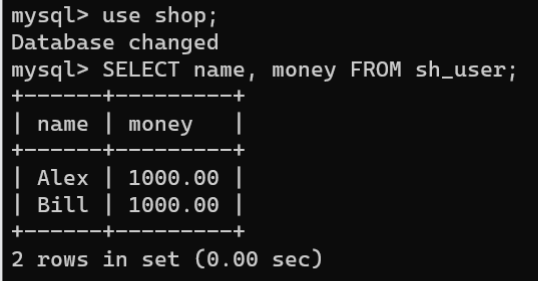
2.开启事务,通过
UPDATE
语句将
Alex
用户的100元钱转给
Bill
用户,提交事务:
# 开启事务STARTTRANSACTION;# Alex的金额减少100元UPDATE sh_user SET money=money-100WHERE name='Alex';# Bill的金额增加100元UPDATE sh_user SET money=money+100WHERE name='Bill';# 提交事务COMMIT;
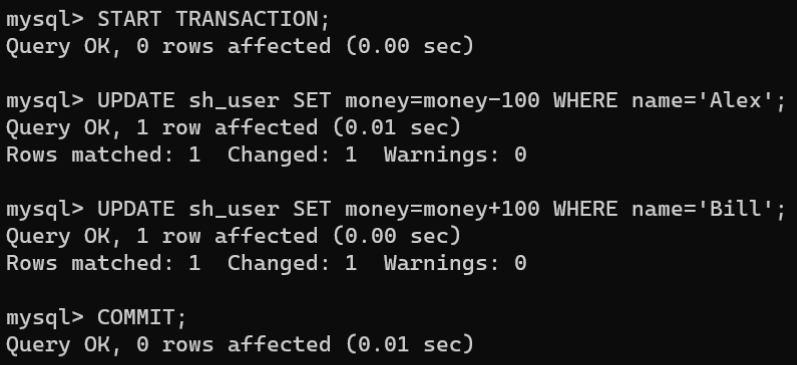
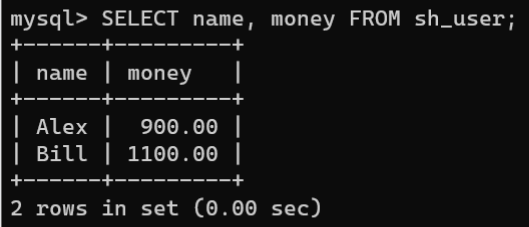
3.使用
SELECT
语句查询
Alex
和
Bill
的金额:
SELECT name, money FROM sh_user;
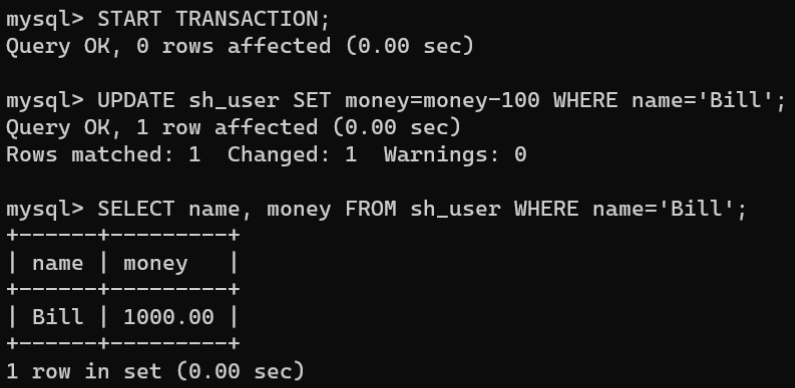
4.测试事务的回滚,开启事务将
Bill
的金额扣除100元,查询
Bill
的金额:
STARTTRANSACTION;UPDATE sh_user SET money=money-100WHERE name='Bill';SELECT name, money FROM sh_user WHERE name='Bill';
5.执行回滚操作,查询
Bill
的金额:
ROLLBACK;# 回滚事务SELECT name, money FROM sh_user WHERE name='Bill';
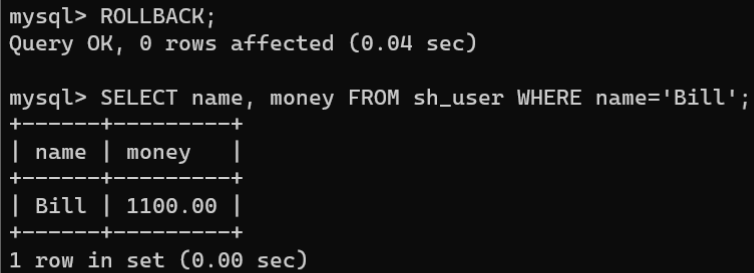
Bill
的金额又恢复成1100元,说明事务回滚成功。
MySQL中的每一条SQL语句都会被当成一个事务自动提交。通过修改
AUTOCOMMIT
变量控制事务的自动提交,将其值设为1表示开启自动提交,设为0表示关闭自动提交。
查看当前会话的AUTOCOMMIT值:
SELECT @@autocommit;
关闭当前会话的事务自动提交的语句:
SET AUTOCOMMIT=0;
关闭自动提交后,需要执行提交事务的语句才会提交事务。如果没有提交事务就直接退出MySQL会话,事务会自动回滚。
2.2.事务的保存点
回滚事务时,事务内的所有操作都将撤销。如果希望只撤销一部分,可以使用保存点来实现。在事务中设置保存点的语句:
SAVEPOINT 保存点名;
设置保存点后,可以将事务回滚到指定保存点。回滚到指定保存点的语句:
ROLLBACKTOSAVEPOINT 保存点名;
若不再需要使用某个保存点,可以将这个保存点删除。删除保存点的语句:
RELEASESAVEPOINT 保存点名;
注意:一个事务中可以创建多个保存点,提交事务后,事务中的保存点就会被删除。另外,回滚至某个保存点后,该保存点之后创建的保存点都会消失。
案例:演示事务保存点:
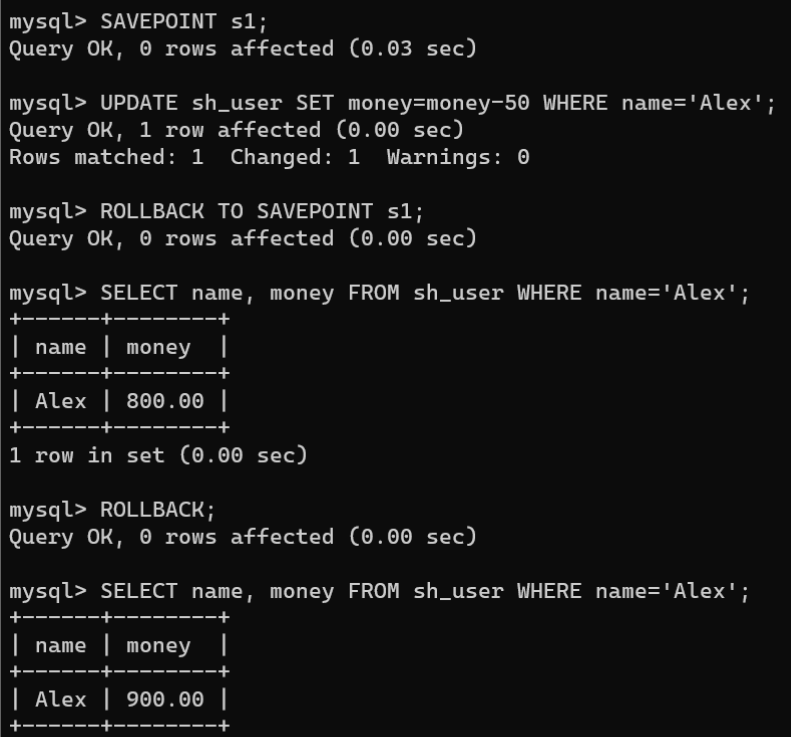
1.查询Alex的金额:
SELECT name, money FROM sh_user WHERE name ='Alex';
2.开启事务,将
Alex
的金额扣除100元,创建保存点
s1
,再将
Alex
的金额扣除50元:
# 开启事务STARTTRANSACTION;# Alex的金额扣除100元UPDATE sh_user SET money=money-100WHERE name='Alex';# 创建保存点s1SAVEPOINT s1;# Alex的金额再扣除50元UPDATE sh_user SET money=money-50WHERE name='Alex';
3.将事务回滚到保存点
s1
,查询
Alex
的金额:
# 回滚到保存点s1ROLLBACKTOSAVEPOINT s1;# 查询Alex的金额SELECT name, money FROM sh_user WHERE name='Alex';
4.再次执行回滚操作:
# 回滚事务ROLLBACK;# 查看Alex的金额SELECT name, money FROM sh_user WHERE name='Alex';
3.事务日志
在MySQL中进行事务操作时,会产生事务日志。事务日志包括
redo
日志和
undo
日志,其中,
redo
日式可以保证事务的持久性,
undo
日志可以保证事务的原子性。
3.1.redo日志
在MySQL中,redo日志用于保证事务的持久性,它由redo日志缓冲(redo log buffer)和redo日志文件(redo log file)组成,其中,redo日志缓冲保存在内存中,redo日志文件保存在磁盘中。
redo日志保存的是物理日志,提交事务后InnoDB存储引擎会把数据页变化保存到redo日志中。
redo日志的工作流程如下图:
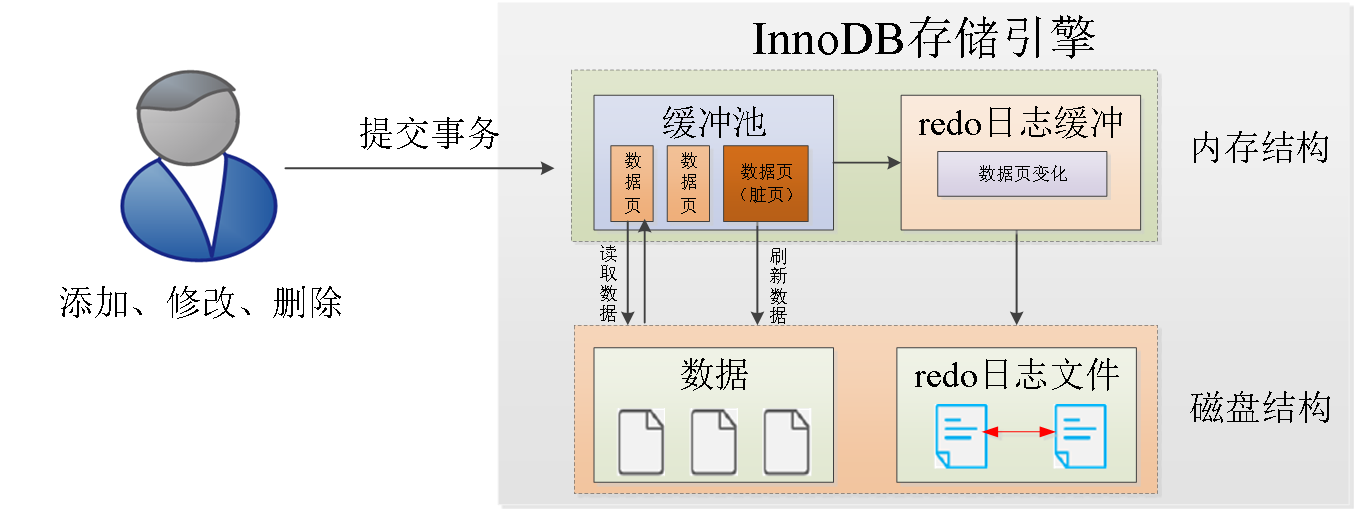
在上图中,内存结构中包括缓冲池和redo体制缓冲,缓冲池中缓存了很多数据页,当一个驶入执行多个增删改的操作时,InnoDB存储引擎会先操作缓冲池中的数据,如果缓冲池中没有对应的数据,会通过后台线程读取该磁盘结构中的数据保存到缓冲池中。缓冲池中修改后的数据页称为脏页,数据页的变化同时也会记录到redo体制缓冲中。
为了保证内存结构和磁盘结构数据的一致,InnoDB存储引擎会在一定的时机通过后台线程将脏页刷新到磁盘中。如果脏页数据刷新到磁盘时发生错误,此时就可以借助redo日志进行数据回复,这样就保证了事务的持久性。如果脏页数据成功刷新到磁盘,此时redo日志就没有作用了,可以将其删除。
当用户提交事务时,InnoDB存储引擎会先将redo日志刷新到磁盘,而不是直接将缓冲池中的脏页数据刷新到磁盘,这是因为在业务操作中,数据一般都是随机从磁盘中读写的,redo日志是顺序写入磁盘中的,顺序写入要比随机写入的效率高,这种写日志的方式被称为预写式日志(Write-Ahead Logging,WAL)。
3.2.undo日志
undo日志用于记录数据被修改前的信息。undo日志的有两个主要作用,第一个作用是提供回滚,保证事务的原子性,另一个作用是实现多版本并发控制。
undo日志保存的是逻辑日志,当执行回滚事务操作时,可以从undo日志中保存的逻辑日志进行回滚。
undo日志的工作流程如下图:
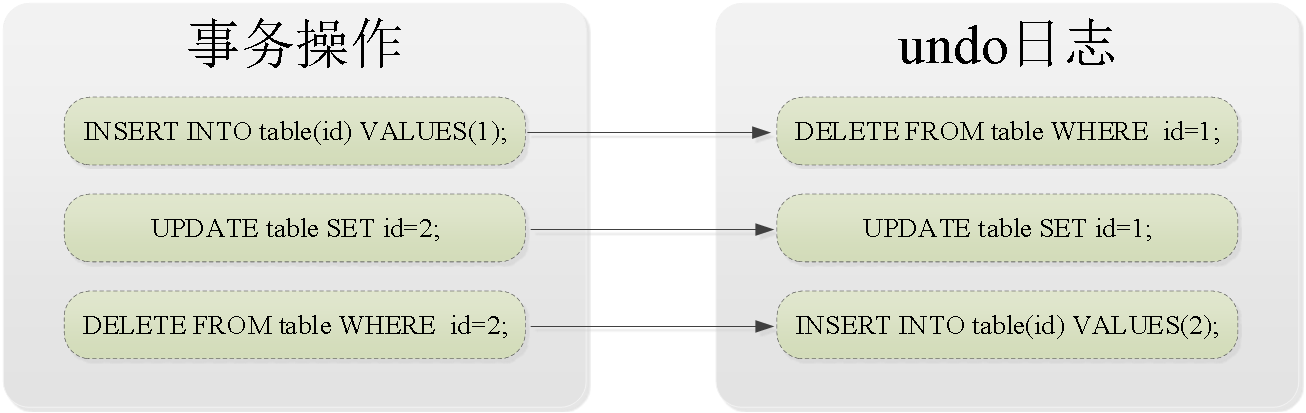
上图中,当通过事务添加数据时,undo日志中就会保存删除这条数据的SQL语句,当通过事务更新数据时,undo日志中就会保存将数据更新到事务操作前的SQL语句,当通过事务删除数据时,undo日志中就会保存添加这条数据的SQL语句。
4.事务隔离级别
MySQL允许多线程并发访问,用户可以通过不同的线程执行不同的事务,为了保证这些事务之间不受影响,设置事务的隔离级别十分必要。
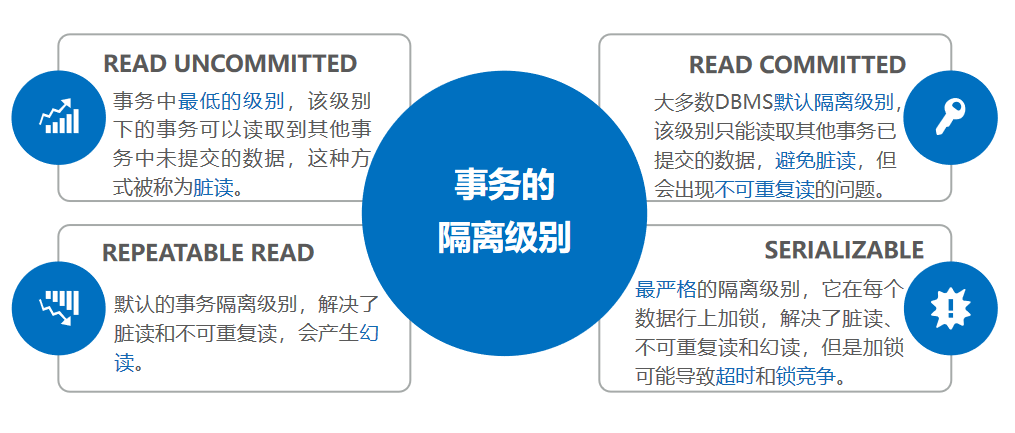
4.1.隔离级别概述
4.2.查看隔离级别
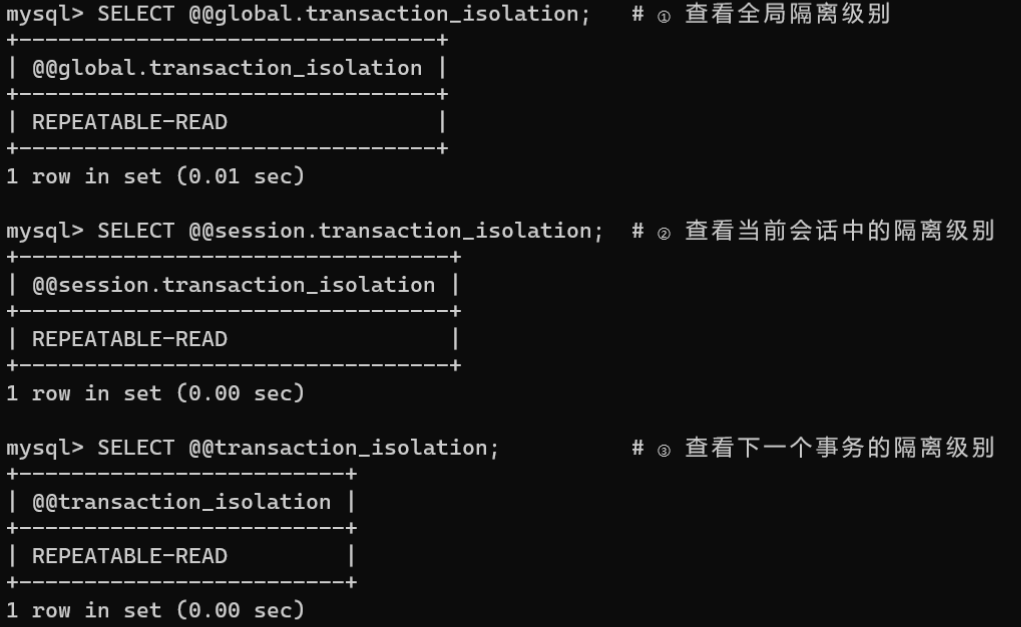
MySQL提供了3种方式查看隔离级别,具体如下:
SELECT @@global.transaction_isolation;# ① 查看全局隔离级别SELECT @@session.transaction_isolation;# ② 查看当前会话中的隔离级别SELECT @@transaction_isolation;# ③ 查看下一个事务的隔离级别
4.3.修改隔离级别
使用SET语句设置事务的隔离级别:
SET[SESSION|GLOBAL]TRANSACTIONISOLATIONLEVEL 参数值;
SESSION
表示当前会话,
GLOBAL
表示全局会话,若省略表示设置下一个事务的隔离级别。
参数值可以是
REPEATABLE READ
、
READ COMMITTED
、
READ UNCOMMITTED
和
SERIALIZABLE
。
将事务的隔离级别修改为
READ UNCOMMITTED
:
SETSESSIONTRANSACTIONISOLATIONLEVELREADUNCOMMITTED;

- 只读事务:事务的访问模式默认为
READ WRITE(读/写模式),表示事务可以执行读(查询)或写(更改、插入、删除等)操作。若开发需要,可以将事务的访问模式设置为READ ONLY(只读模式),禁止对表更改。
# ① 设置只读事务SETSESSIONTRANSACTIONREAD ONLY;SETGLOBALTRANSACTIONREAD ONLY;# ② 恢复成读写事务SETSESSIONTRANSACTIONREADWRITE;SETGLOBALTRANSACTIONREADWRITE;# ③ 查看事务的访问模式SHOW VARIABLES LIKE'transaction_read_only';
4.4.使用隔离级别
不同的隔离级别在事务中的表现不同,例如,
READ UNCOMMITTED
隔离级别会造成脏读,
READ COMMITTED
隔离级别会出现不可重复读的问题,
REPEATABLE READ
隔离级别会出现幻读。
下面通过具体的案例分别演示这3种问题的出现的原因和解决方法。
- 脏读:使用
READ UNCOMMITTED隔离级别会造成脏读。
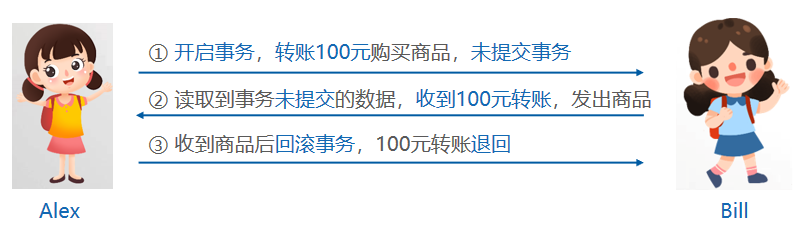
通过案例演示脏读。打开两个命令行窗口分别模拟
Alex
和
Bill
,以下称为客户端A和客户端B。
1.将客户端B的隔离级别设置为
READ UNCOMMITTED
:
# 客户端BSETSESSIONTRANSACTIONISOLATIONLEVELREADUNCOMMITTED;
2.在客户端B中查询
Bill
当前的金额:
# 客户端BSELECT name, money FROM sh_user WHERE name='Bill';
3.在客户端A中开启事务,并执行转账操作:
# 客户端ASTARTTRANSACTION;UPDATE sh_user SET money=money-100WHERE name='Alex';UPDATE sh_user SET money=money+100WHERE name='Bill';
4.客户端A未提交事务的情况下,在客户端B查询金额,会看到金额已经增加:
# 客户端BSELECT name, money FROM sh_user WHERE name='Bill';
5.为了避免客户端B的脏读,修改客户端B的隔离级别:
# 客户端BSETSESSIONTRANSACTIONISOLATIONLEVELREADCOMMITTED;SELECT name, money FROM sh_user WHERE name='Bill';
- 不可重复读:使用
READ COMMITTED隔离级别会出现不可重复读的问题。

通过案例演示不可重复读。打开两个命令行窗口,客户端A模拟Alex用户,客户端B模拟网站后台, 查询用户的金额。
1.将客户端B的隔离级别设置为
READ COMMITTED
:
# 客户端BSETSESSIONTRANSACTIONISOLATIONLEVELREADCOMMITTED;
2.在客户端B开启事务,查询Alex的金额:
# 客户端BSTARTTRANSACTION;SELECT name, money FROM sh_user WHERE name='Alex';
3.在客户端A中将Alex的金额扣除100元:
# 客户端AUPDATE sh_user SET money=money-100WHERE name='Alex';
4.在客户端B中查询Alex的金额:
# 客户端BSELECT name, money FROM sh_user WHERE name='Alex';
5.为了避免客户端B的不可重复读的问题,修改客户端B的隔离级别:
# 客户端BSETSESSIONTRANSACTIONISOLATIONLEVELREPEATABLEREAD;
修改客户端B的隔离级别后,重新执行案例中的操作,查看两次查询结果是否一致。
- 幻读:使用
REPEATABLE READ隔离级别会出现幻读。
通过案例演示幻读。打开两个命令行窗口,假设客户端A用于新增用户,客户端B用于查询用户。
1.将客户端B的隔离级别设置为
REPEATABLE READ
:
# 客户端BSETSESSIONTRANSACTIONISOLATIONLEVELREPEATABLEREAD;
2.在客户端B开启事务,查询用户数据:
# 客户端BSTARTTRANSACTION;SELECT id, name, money FROM sh_user;
3.在客户端A新增一个id为3的用户:
# 客户端AINSERTINTO sh_user (id, name, money)VALUES(3,'Tom',1000);
4.在客户端B中插入并查询id为3的用户:
INSERTINTO sh_user (id, name, money)VALUES(3,'Tom',1000);
ERROR 1062(23000): Duplicate entry '3'forkey'sh_user.PRIMARY'SELECT id, name, money FROM sh_user;
5.为了避免客户端B的幻读问题,修改客户端B的隔离级别:
# 客户端BSETSESSIONTRANSACTIONISOLATIONLEVELSERIALIZABLE;
修改客户端B的隔离级别后,重新执行案例中的操作,只有客户端B提交事务后,客户端A的操作才会执行,显示执行结果。如果客户端B一直未提交事务,客户端A的操作会一直等待,直到超时。
5.练习
请利用事务实现在用户下订单后,订单商品表
sh_order_goods
中对应订单插入的商品数量大于实际商品库存量时,取消向
sh_order_goods
表中添加数据。
八、数据库优化
1.存储引擎
在MySQL中,存储引擎是数据库的核心,在创建数据表时也需要根据不同的使用场景选择合适的存储引擎。MySQL支持的存储引擎有很多,常用的有InnoDB和MyISAM。
1.1.存储引擎概述
存储引擎是MySQL服务器的底层组件之一,用于处理不同表类型的SQL操作。使用不同的存储引擎,获得的功能也不同,例如,存储机制、索引、锁等。
存储引擎可以灵活选择,根据实际需求和性能要求,选择和使用合适的存储引擎,提高整个数据库的性能。
MySQL的存储引擎采用了“可插拔” 架构,“可插拔”架构是对运行中的MySQL服务器,使用特定的语句插入(加载)或拔出(卸载)所需的存储引擎文件。
“可插拔”存储引擎架构提供了一组标准的管理和支持服务,执行数据库的实际数据I/O操作,针对特定应用需求自由选择或自定义专用的存储引擎,无须增加其他编码选项等额外操作,从而达到可插拔存储引擎架构的目的,为特定的应用程序提供一组较优的选择,减少不必要的开销,增强数据库性能。
1.2.MySQL支持的存储引擎
使用
SHOW
语句查看MySQL支持的存储引擎的语法:
SHOW ENGINES;
运行结果包含的6个字段:
- Engine(存储引擎)
- Support(是否支持)
- Comment(注释说明)
- Transactions(是否支持事务)
- XA(是否支持分布式事务)
- Savepoints(是否支持事务保存点)
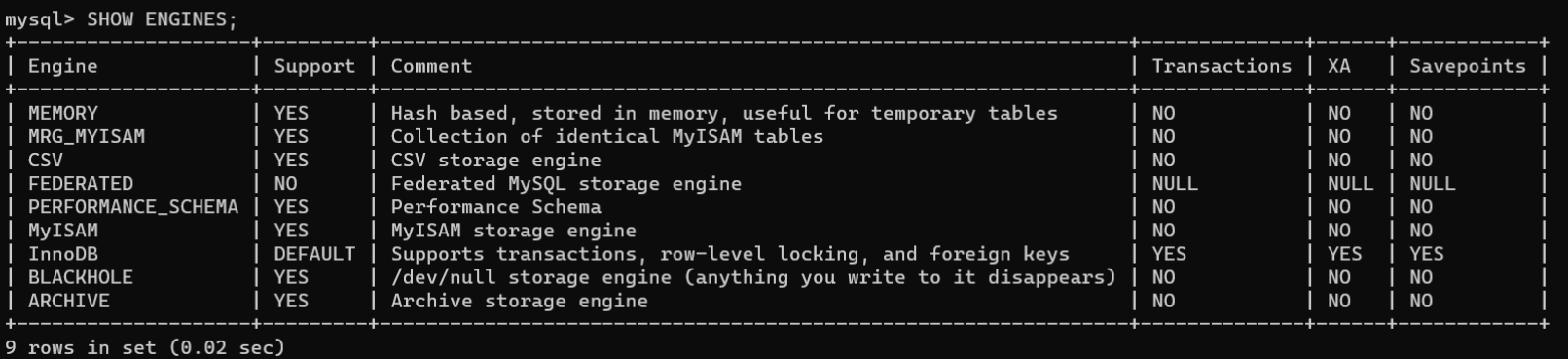
MySQL支持的存储引擎如下表:
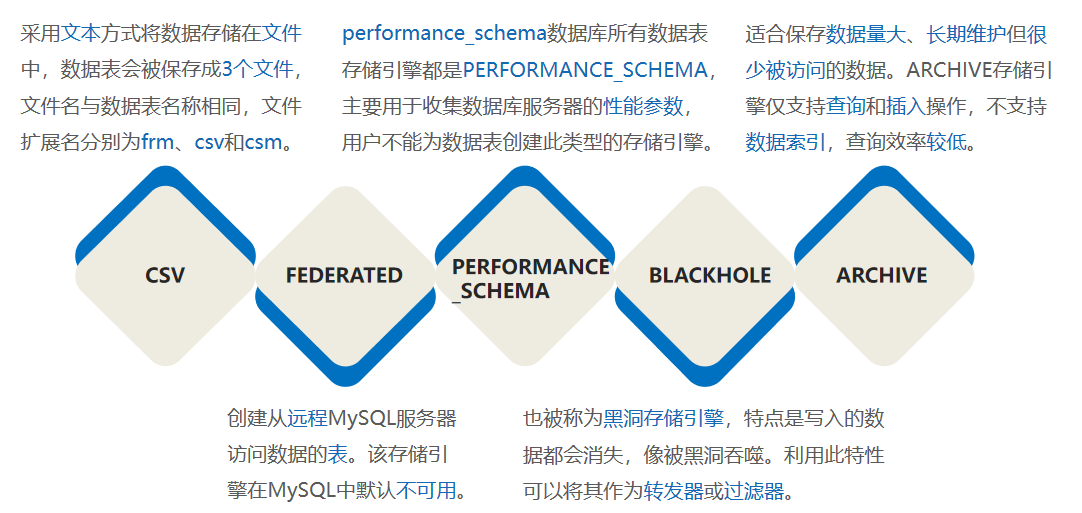
存储引擎是否支持是否支持事务是否支持分布式事务是否支持保存点****描述InnoDBDEFAULTYESYESYES支持事务、行级锁和外键MyISAMYESNONONO支持表锁、全文索引MEMORYYESNONONO数据保存在内存中,速度快但数据容易丢失,适用于临时表MRG_MYISAMYESNONONO相同MyISAM表的集合CSVYESNONONO数据以文本方式存储在文件中FEDERATEDNONULLNULLNULL用于访问远程的MySQL数据库PERFORMANCE_SCHEMAYESNONONO适用于性能架构BLACKHOLEYESNONONO黑洞引擎,写入的数据都会消失,适合做中继存储ARCHIVEYESNONONO适用存储海量数据,有压缩功能,不支持索引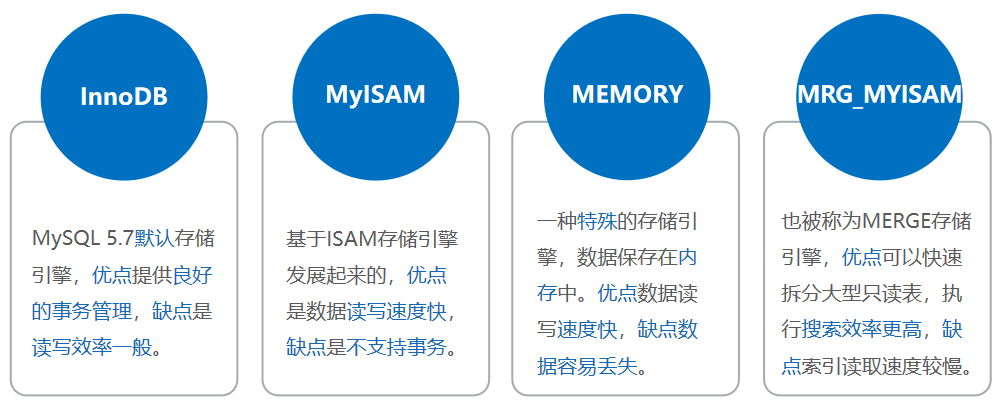
1.3.InnoDB存储引擎
MySQL默认的存储引擎是
InnnoDB
,该存储引擎适合业务逻辑比较强,修改操作比较多的项目。
下面从存储格式、表空间设置以及多版本并发控制这3个方面对
InnoDB
存储引擎进行讲解。
1.存储格式:InnoDB存储引擎有两个表空间,分别是共享表空间和独立表空间,共享表空间文件用于集中存储数据和索引,保存在data目录下。
独立表空间文件保存在data目录下的数据库中。
查看shop数据库中的独立表空间文件:
如果想要让数据表公用同一个表空间文件,可以关闭InnoDB存储引擎独立表空间,操作步骤如下:
- 关闭InnoDB存储引擎的独立表空间前查看
innodb_file_per_table的默认值:show variables like'innodb_file_per_table';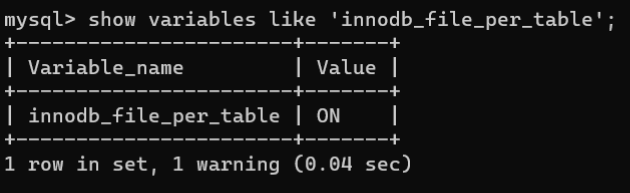 默认值为NO,表示数据表使用独立的表空间。
默认值为NO,表示数据表使用独立的表空间。 - 将全局变量
innodb_file_per_table的值设置为OFF:SETGLOBAL innodb_file_per_table=OFF;
2.表空间设置:保存数据时,可能会遇到存储空间不足的情况,此时可以增加表空间的大小。增加表空间的两种方式:一种是配置自动扩展,另一种是表空间达到指定大小后,将数据存储到另一个文件中。
- 自动扩展表空间:通过系统变量
innodb_data_file_path可以查看表空间的最后一个数据文件,通过系统变量innodb_autoextend_increment可以查看每次自动扩展的空间大小,以兆字节为单位。# 查看表空间的最后一个数据文件show variables like'innodb_data_file_path';# 查看自动扩展的空间大小show variables like'innodb_autoextend_increment';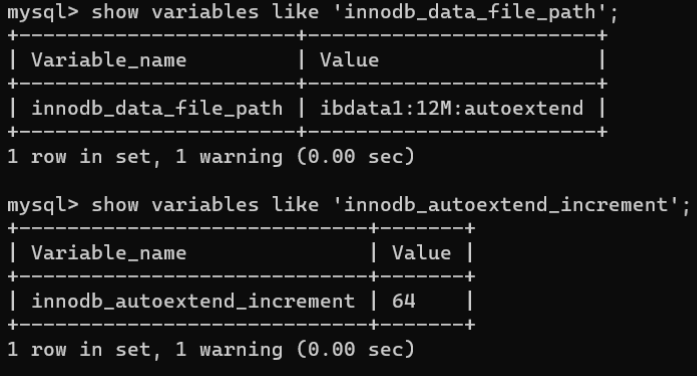 从上述查询结果中,系统变量
从上述查询结果中,系统变量innodb_data_file_path的值为ibdata1:12M:autoextend,表示表空间由一个12MB的ibdata1文件组成,autoextend表示自动扩展表空间;系统变量innodb_autoextend_increment的值为64,表示每次扩展的表空间大小为64MB,该值可以根据实际情况自定义。 - 将数据存储到另一个文件:配置前先停止MySQL服务;在my.ini中添加配置,删除系统变量innodb_data_file_path的autoextend属性,将文件ibdata1存储的数据大小设置为一个固定值,在文件后面添加分号;添加另外一个文件的路径和大小,最后启动MySQL服务。 配置表空间ibdata1达到12MB时,将数据添加到ibdata2,当ibdata2达到50MB自动扩展:
# 使用管理员身份停止MySQL80服务net stop MySQL80# 在my.ini中添加配置innodb_data_file_path=ibdata1:12M;ibdata2:50M:autoextend# 启动mySQL80net start MySQL80在data目录下新创建的文件: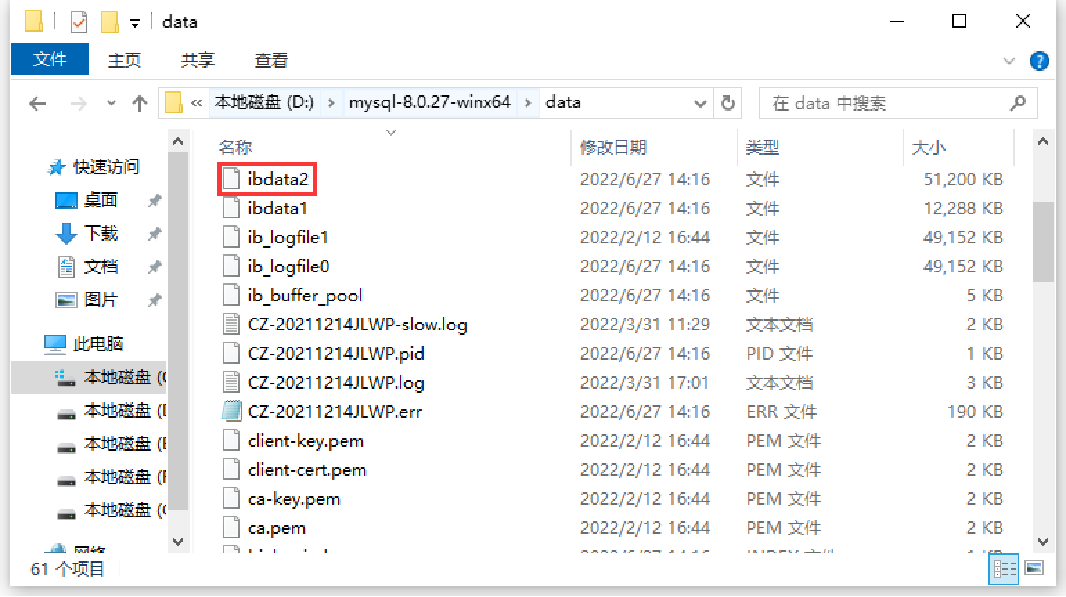
3.多版本并发控制:InnoDB是一个多版本并发控制(MVCC)的存储引擎,它可以维护一个数据的多个版本,保存更改前的数据信息来处理多用户并发和事务回滚,保证读取数据的一致性,使得读写操作不会产生冲突。
MVCC的实现主要依赖InnoDB存储引擎数据表中的3个隐藏字段、
undo
日志和
ReadView
。
(1)InnoDB存储引擎数据表中的3个隐藏字段
DB_TRX_ID字段:表示最后一个插入或更新此记录的事务标识符,删除操作也被视为更新操作。DB_ROLL_PTR字段:表示滚动指针,指向MySQL中撤销日志的记录,用于事务的回滚操作,并在事务提交后会立即删除。DB_ROW_ID字段:用于保存新增记录的ID。
(2)
undo
日志
执行INSERT、UPDATE、DELETE操作时,会产生用于回滚事务的undo日志。执行INSERT操作时,产生的undo日志在回滚时需要,事务提交后立即被删除;执行UPDATE、DELETE操作时,产生的undo日志不仅在回滚时需要,读取数据时也需要,不会立即被删除。
(3)
ReadView
执行读取数据的SQL语句时,ReadView是MVCC提取数据的依据,ReadView记录并维护系统当前活跃的事务ID。ReadView的4个核心字段:
字段****含义m_ids当前活跃的事务ID集合min_trx_id最小活跃事务IDmax_trx_id预分配事务ID,当前最大事务ID加1(事务ID是自增的)creator_trx_idReadView创建者的事务ID
ReadView规定的数据访问规则:
trx_id表示当前事务的ID,将当前事务ID和其他字段作对比,判断是否可以访问数据。
条件是否可以访问说明trx_id == creator_trx_id可以访问该版本成立,说明数据是当前这个事务更改的trx_id < min_trx_id可以访问该版本成立,说明数据已经提交了trx_id > max_trx_id不可以访问该版本成立,说明该事务是在ReadView生成后才开启min_trx_id <= trx_id <= max_trx_id如果trx_id不在m_ids中,是可以访问该版本的成立,说明数据已经提交
不同隔离级别生成ReadView的时机不同,具体如下:
READ COMMITTED:在事务中每一次读取数据时生成ReadView。REPEATABLE READ:仅在事务中第一次读取数据时生成ReadView,后续复用该ReadView。
1.4.MyISAM存储引擎
使用MyISAM存储引擎的数据表占用空间小,数据写入速度快,适合数据读写操作比较频繁的项目,例如论坛、博客等。
MyISAM存储引擎的数据表会被存储成3个文件,文件名和数据表的名称相同,文件扩展名分别为sdi、myd和myi。
MyISAM存储引擎的相关文件:
文件扩展名****功能说明sdi用于存储数据表结构myd用于存储数据,是MYData的缩写myi用于存储索引,是MYIndex的缩写
MyISAM存储引擎和InnoDB存储引擎存储数据的方式: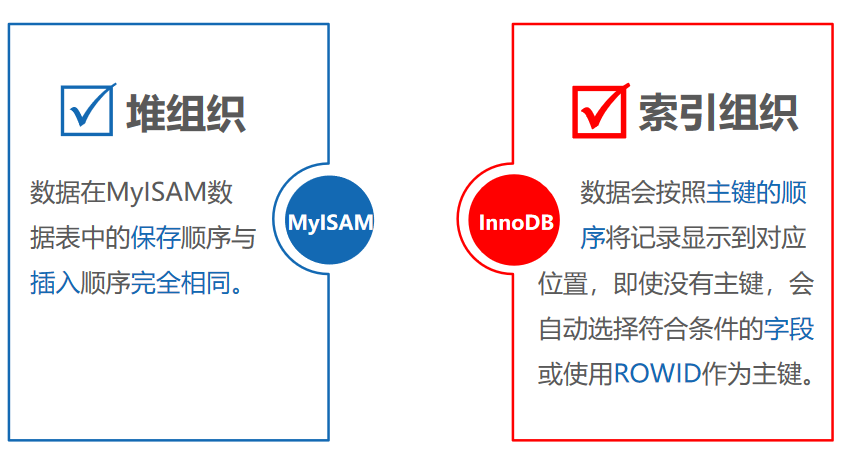
2.索引
2.1.索引概述
索引是一种特殊的数据结构,将数据表中的某个或某些字段与记录的位置建立一个对应关系,并按照一定的顺序排序,使用索引可以快速定位到指定数据的位置。
根据创建索引的语法对索引分类:
- 普通索引:普通索引是MySQL中的基本索引类型,使用KEY或INDEX关键字定义,不需要添加任何限制条件。
- 唯一索引:使用UNIQUE INDEX定义,防止用户添加重复的值,创建唯一索引的字段需要添加唯一约束。
- 主键索引:使用PRIMARY KEY定义,是一种特殊的唯一索引,根据主键自身的唯一性标识每条记录,防止添加主键索引的字段值重复或为NULL。
- 全文索引:使用FULL TEXT INDEX定义,提高数据量较大的字段的查询速度。
- 空间索引:使用SPATIAL INDEX定义,提高系统获取空间数据的效率。空间数据类型用于存储位置、大小、形状以及自身分布特征的数据。根据创建索引的字段个数对索引分类:
- 单列索引:在数据表的单个字段上创建索引,它可以是普通索引、唯一索引、主键索引或全文索引,该索引对应数据表中的一个字段。
- 复合索引:在数据表的多个字段上创建索引,当查询条件中使用了这些字段中的第一个字段时,下一个字段才有可能被匹配。
2.2.索引结构
MySQL中常见的索引结构是B+树索引和哈希索引。InnoDB存储引擎和MylSAM存储引擎的索引结构是优化版的B+树索引;Memory存储引擎默认的索引结构是哈希索引。
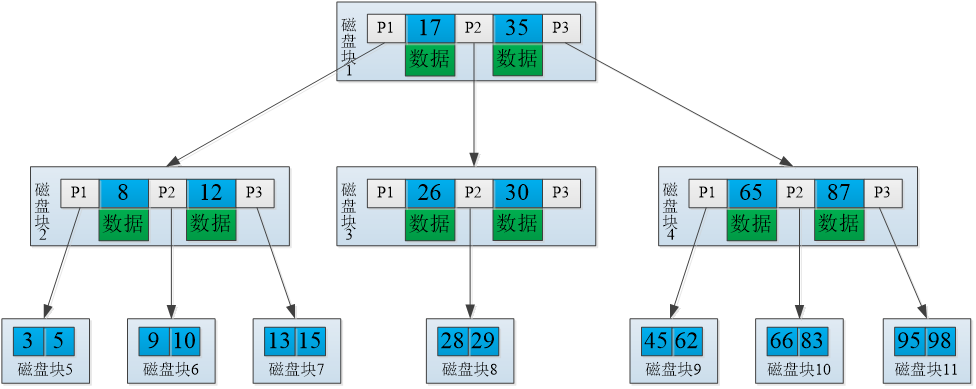
1.B+树索引:B+树索引是在B树(B-tree)索引的基础上改进而来的,B树索引的结构是一种应用广泛的多路平衡查找树,多路是指一个节点包含了多个子节点。子节点的个数使用度数表示,数据项个数为度数减1,指针数和度数相同。例如,一个节点中包含了3个子节点,则度数为3,又称为3阶B树索引,3阶的B树索引包含2个数据项和3个指针。
3阶B树索引示意图:
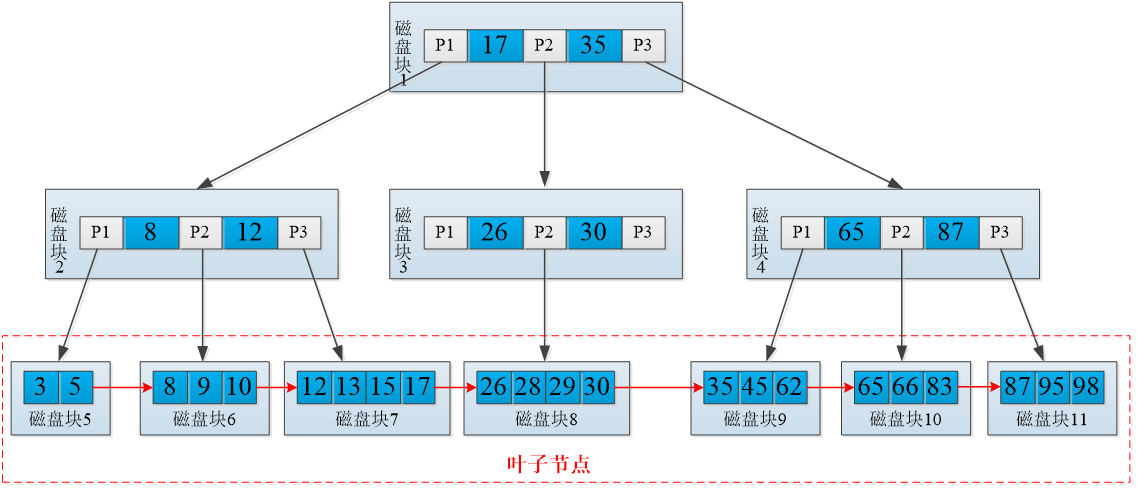
B+树索引的数据只出现在叶子节点中,B+树索引示意图:
MySQL对B+树索引的结构进行了优化,在原来的B+树索引基础上,增加了一个指向相邻叶子节点的链表指针,这就形成了带有顺序指针的B+树索引,提高了区间访问的性能。
优化后的B+树索引示意图:
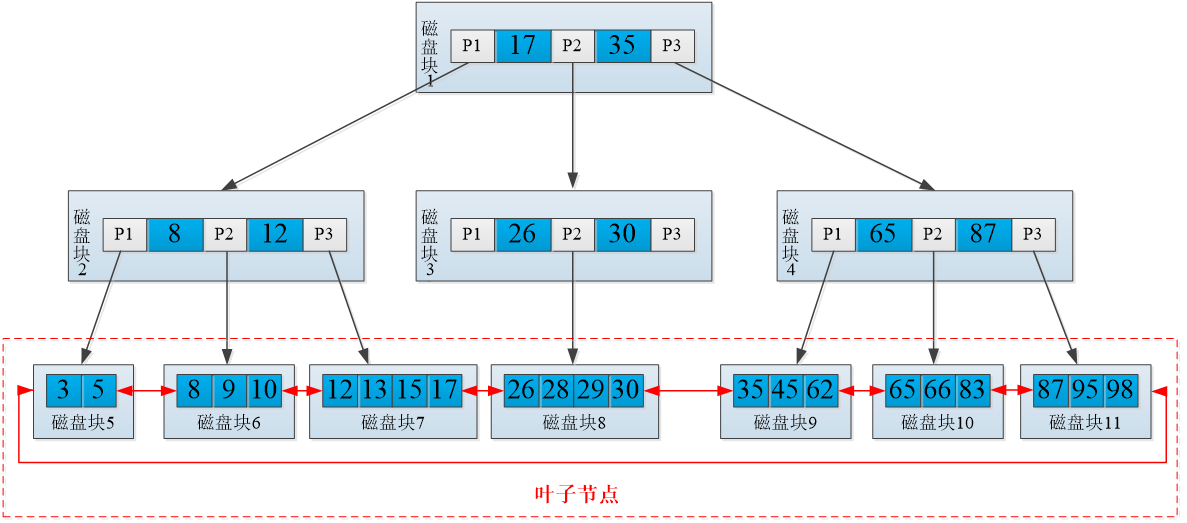
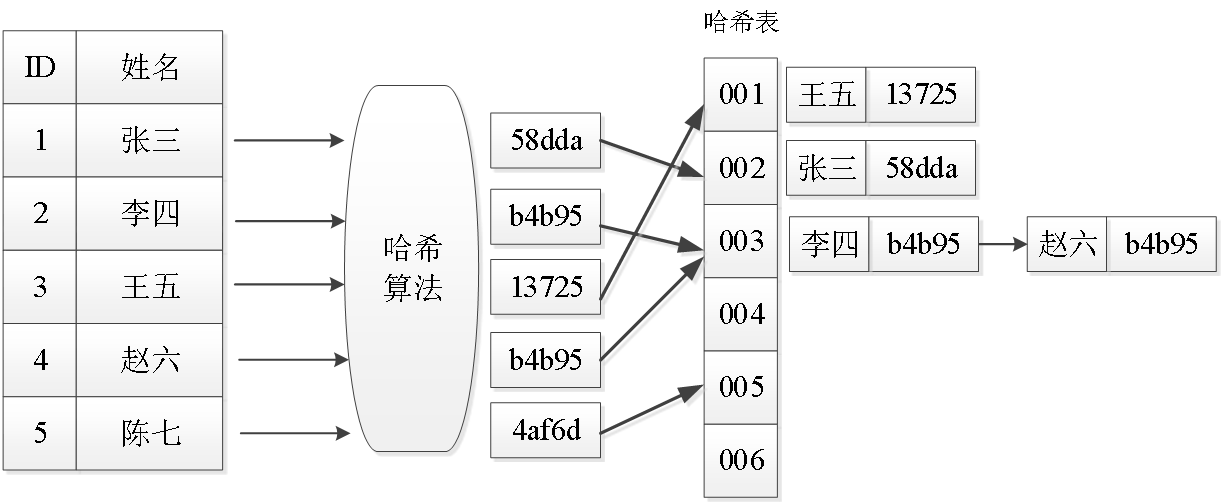
2.哈希索引:哈希索引采用哈希(Hash)算法,将键值换算成哈希值后再映射到哈希表对应的槽位上。哈希索引的优点是查询效率高,缺点是只能进行等值比较,不支持范围查询。
哈希索引示意图:
2.3.创建索引
- 创建数据表的同时创建索引:语法结构如下:
CREATE[TEMPORARY]TABLE[IFNOTEXISTS] 数据表名称 (字段名 数据类型 [字段属性]...PRIMARYKEY[索引类型](字段列表)[索引选项],| {INDEX|KEY} [索引名称][索引类型](字段列表)[索引选项],|UNIQUE[INDEX|KEY][索引名称][索引类型](字段列表)[索引选项],| {FULLTEXT | SPATIAL} [INDEX|KEY][索引名称](字段列表)[索引选项])[表选项];创建索引语法的各选项说明:选项****语法索引类型USING {BTREE | HASH}字段列表字段 [(长度) [ASC | DESC]]索引选项KEY_BLOCK_SIZE [=] 值| 索引类型 | WITH PARSER 解析器插件名 | COMMENT ‘描述信息’字段列表是必选项,其余均是可选项。 索引选项中的KEY_BLOCK_SIZE表示索引的大小,仅可在MyISAM存储引擎的表中使用,WITH PARSER只能用于全文索引。主键索引不能设置索引名称,其他索引类型的名称可以省略。省略索引名称时,默认使用字段名作为索引名称,复合索引则使用第一个字段作为索引名称。 下面演示在创建数据表的同时创建单列索引和复合索引。- 在创建数据表的同时创建单列索引:创建index01数据表时创建单列的主键索引、唯一索引、普通索引和全文索引:CREATETABLE index01 ( id INT, indexno INT, name VARCHAR(20), introduction VARCHAR(200),PRIMARYKEY(id),-- 创建主键索引UNIQUEINDEX(indexno),-- 创建唯一索引INDEX(name),-- 创建普通索引 FULLTEXT (introduction)-- 创建全文索引);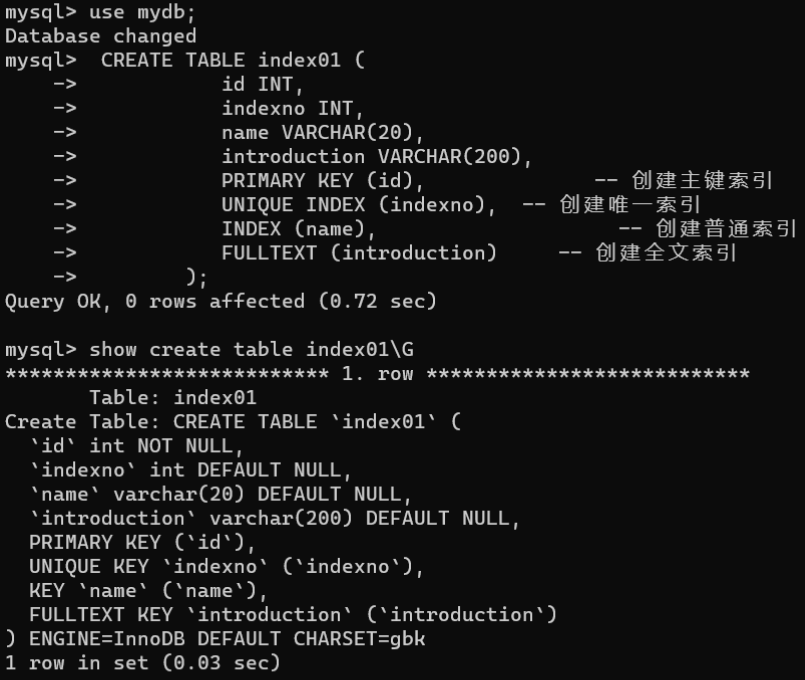 - 在创建数据表的同时创建复合索引:创建index_multi数据表时给id字段和name字段创建索引名称为multi的复合索引:
- 在创建数据表的同时创建复合索引:创建index_multi数据表时给id字段和name字段创建索引名称为multi的复合索引:CREATETABLE index_multi ( id INTNOTNULL, name VARCHAR(20)NOTNULL,INDEX multi (id, name)); - 给已存在的数据表创建索引:语法结构如下:
CREATE[UNIQUE| FULLTEXT | SPATIAL]INDEX 索引名称[索引类型]ON 数据表名称 (字段列表)[索引选项][算法选项 | 锁选项]给sh_goods数据表创建单列的唯一索引:CREATEUNIQUEINDEX unique_index ON sh_goods (id); - 修改数据表的同时创建索引:语法结构如下:
ALTERTABLE 数据表名称ADDPRIMARYKEY[索引类型](字段列表)[索引选项]|ADD {INDEX|KEY} [索引名称][索引类型](字段列表)[索引选项]|ADDUNIQUE[INDEX|KEY][索引名称][索引类型](字段列表)[索引选项]|ADD {FULLTEXT|SPATIAL} [INDEX|KEY][索引名称](字段列表)[索引选项];- 修改数据表时创建单列索引:ALTERTABLE sh_goodsADDINDEX name_index (name),ADD FULLTEXT INDEX ft_index (content);- 修改数据表时创建复合索引:ALTERTABLE sh_goods ADDINDEX multi (name, price, keyword);
2.4.查看索引
查看索引的语法:
SHOW {INDEXES |INDEX|KEYS} FROM 数据表名称;
查看sh_goods表的所有索引信息:
SHOWINDEXFROM sh_goods\G
索引信息字段含义:
字段名****描述Table索引所在的数据表的名称Non_unique索引是否可以重复,0表示不可以,1表示可以Key_name索引的名字,如果索引是主键索引,则它的名字为PRIMARYSeq_in_index创建索引的字段序号值,默认从1开始Column_name创建索引的字段Collation索引字段是否有排序,A表示有排序,NULL表示没有排序CardinalityMySQL连接时使用索引的可能性(精确度不高),值越大可能性越高Sub_part前缀索引的长度,如果字段值都被索引则为NULLPacked关键词如何被压缩,如果没有被压缩则为NULLNull索引字段是否包含NULL值,YES表示包含,NO表示不包含Index_type索引类型,可选值有BTREE、FULLTEXT、HASH、RTREEComment索引字段的注释信息Index_comment创建索引时添加的注释信息Visible索引对查询优化器是否可见,YES表示可见,NO表示不可见Expression使用什么表达式作为创建索引的字段,NULL表示没有
2.5.删除索引
数据表中不需要使用的索引,应该及时删除,避免占用资源,影响数据库性能。
在MySQL中,使用
ALTER TABLE
语句或
DROP INDEX
语句删除索引:
- 使用
ALTER TABLE语句删除索引:
ALTERTABLE 数据表名称 DROPINDEX 索引名;
删除
sh_goods
数据表中名称为
ft_index
的全文索引:
ALTERTABLE sh_goods DROPINDEX ft_index;
- 使用
DROP INDEX语句删除索引:
DROPINDEX 索引名 ON 数据表名称;
删除
sh_goods
数据表中名称为
name_index
的普通索引:
DROPINDEX name_index ON sh_goods;
主键索引的索引名是
PRIMARY
,
PRIMARY
是MySQL的关键字,在删除主键索引时,主键索引的名称必须使用反引号“`”包裹,否则程序会报错误提示信息。
删除sh_goods表中的主键索引:
DROPINDEX`PRIMARY`ON sh_goods;
2.6.索引的使用原则
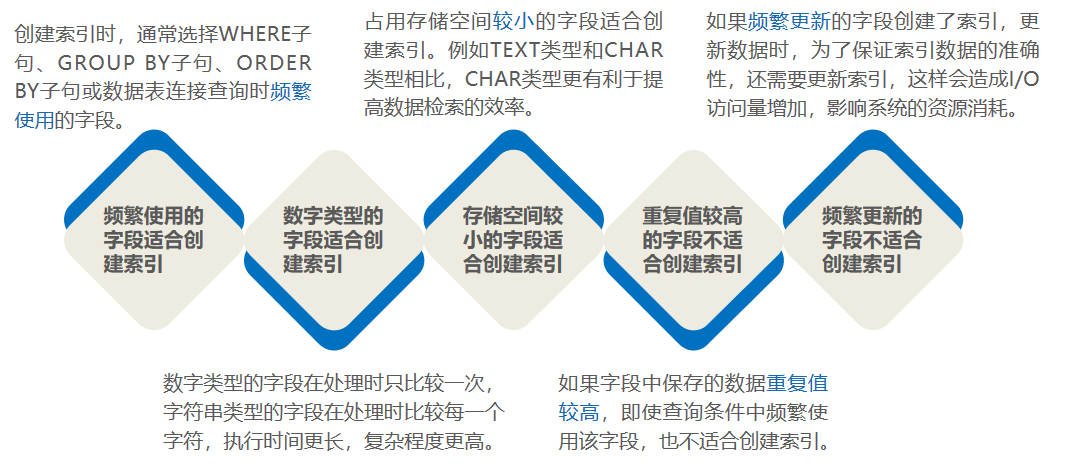
使用索引时遵循的原则:
查询时使索引生效的注意事项:

3.锁机制
3.1.锁机制概述
当多个用户并发存取数据时,会产生多个事务同时存取同一数据的情况。若对并发操作不加控制可能会读取和存储不正确的数据,破坏数据库一致性,通过给数据表加锁保证数据库一致性。
锁是计算机协调多个进程或线程并发访问某一资源的机制,根据锁在MySQL中的状态可将其分为“隐式”锁与“显式”锁。
“隐式”锁:MySQL服务器本身对数据资源的争用进行管理,它完全由服务器自动执行。
“显式”锁:指用户根据实际需求,对操作的数据显式加锁,操作完数据资源后需要对其解锁。未添加锁状态下,多个用户操作同一条数据,出现数据不一致的情况:
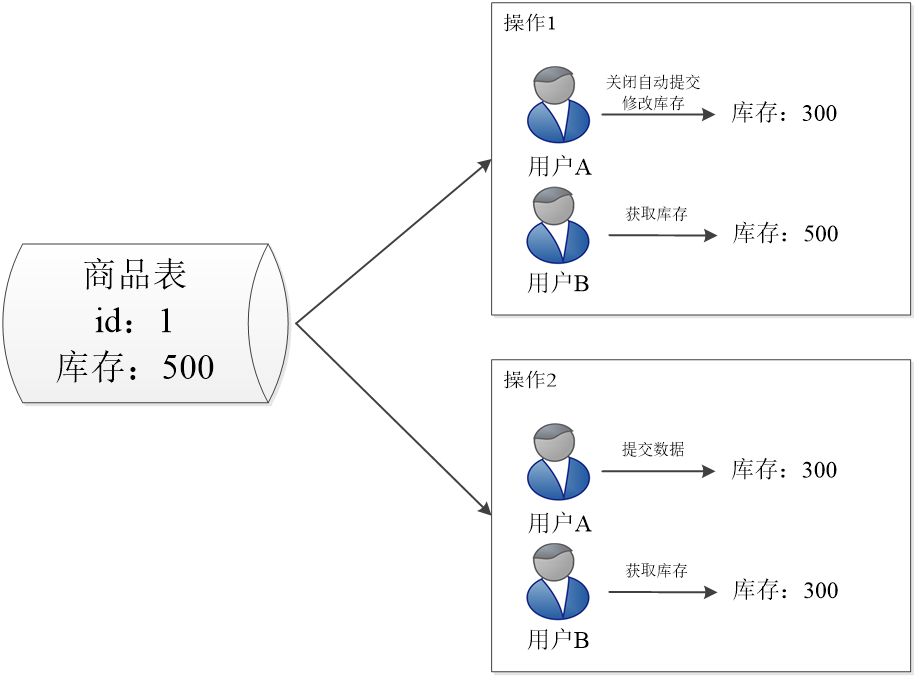
存在两个问题:操作1中两个用户查询到的库存值不同。
用户B在两次操作中获取到的库存值不一致。解决方法: 给数据表加锁,当用户A和用户B同时操作商品表时,根据内部设定的操作优先级锁住指定用户(如用户A)要操作的资源(商品表),另一个用户(如用户B)排队等候,直到指定用户操作完成并释放锁后,另一个用户再操作资源。
MySQL中常见的锁有表级锁和行级锁,具体介绍如下:
锁类型锁粒度特点表级锁锁定整张数据表开销小,加锁快,不会出现死锁,发生锁冲突的概率高,并发度低行级锁锁定指定数据行开销大,加锁慢,会出现死锁,发生锁冲突的概率低,并发度高
MySQL常用的存储引擎支持的锁类型:
存储引擎表级锁行级锁MyISAM支持不支持InnoDB支持支持MEMORY支持不支持
3.2.表级锁
根据操作不同,表级锁可以分为读锁和写锁。
- 读锁:也被称为共享锁,当用户读取数据时添加读锁,其他用户不可以修改或增加数据,可以读取数据。
- 写锁:也被称为排他锁或独占锁,当用户对数据执行写操作时添加写锁,除了当前添加写锁的用户外,其他用户都不能对数据进行读或写操作。
下面以MyISAM存储引擎的数据表为例,讲解如何添加“隐式”表级锁和“显式”表级锁。
- 添加“隐式”表级锁:
操作类型****表级锁类型SELECT查询自动添加表级读锁INSERT、UPDATE、DELETE操作自动添加表级写锁
当作完成后,服务器自动为其解锁。操作的执行时间是“隐式”表级锁的生命周期,该生命周期的持续时间一般都比较短暂。服务器自动添加“隐式”表级锁时,表的更新操作优先级高于表的查询操作。
- 添加读锁时,若表中没有写锁则添加,否则将其插入到读锁等待的队列中。
- 添加写锁时,若表中没有任何锁则添加,否则将其插入到写锁等待的队列中。
- 添加“显式”表级锁:添加“显式”表级锁的语法:
LOCKTABLES 数据表名称[, 数据表名称]READ[LOCAL]|WRITE;
READ
表示读锁,
READ LOCAL
表示并发插入读锁,添加读锁的用户可以读取数据表但不能进行写操作,否则系统会报错,其他用户可以读取此数据表,执行写操作会进入等待队列。
WRITE
表示写锁,添加写锁的用户可以对该表进行读和写操作,在释放锁之前,不允许其他用户访问与操作。
案例:通过不同的客户端操作数据表查看数据的读写情况。
1.打开两个客户端A和B,在客户端A中为
table_lock
添加读锁,执行查询和更新操作,查看其他未锁定的数据表:
mysql>LOCKTABLE mydb.table_lock READ;
mysql>SELECT*FROM mydb.table_lock\G
***************************1.row***************************
id: 1***************************2.row***************************
id: 2
mysql>UPDATE mydb.table_lock SET id=3WHERE id=1;
ERROR 1099(HY000): Table'table_lock' was locked with a READlockand can't be updated
mysql> SELECT * FROM mydb.index01\G
ERROR 1100 (HY000): Table 'index01' was not locked withLOCKTABLES
2.在客户端B中执行查询和更新操作:
mysql>SELECT*FROM mydb.table_lock\G
***************************1.row***************************
id: 1***************************2.row***************************
id: 2
mysql>UPDATE mydb.table_lock SET id=3WHERE id=1;# 此处光标会不停闪烁,进入锁等待状态
3.在客户端A中释放锁,查看客户端B的执行结果:
# 在客户端A中释放锁
mysql>UNLOCKTABLES;
Query OK,0rows affected (0.00 sec)# 客户端B中会立即执行步骤二中的更新的操作
mysql>UPDATE mydb.table_lock SET id=3WHERE id=1;
Query OK,1row affected (5.64 sec)Rowsmatched: 1 Changed: 1Warnings: 0
4.在客户端A中为
table_lock
添加写锁,执行更新和查询操作:
mysql>LOCKTABLE mydb.table_lock WRITE;
mysql>UPDATE mydb.table_lock SET id=1WHERE id=2;
Query OK,1row affected (0.00 sec)Rowsmatched: 1 Changed: 1Warnings: 0
mysql>SELECT*FROM mydb.table_lock\G
***************************1.row***************************
id: 3***************************2.row***************************
id: 1
5.在客户端B中执行查询和更新操作:
mysql>SELECT*FROM mydb.table_lock;# 此处光标会不停闪烁,进入锁等待状态
mysql>UPDATE mydb.table_lock SET id=1WHERE id=2;# 此处光标会不停闪烁,进入锁等待状态# 未添加锁的客户端B执行任何操作都只能处于锁等待状态
6.在客户端A中释放锁,查看客户端B的执行结果:
mysql>UNLOCKTABLES;# 客户端A
Query OK,0rows affected (0.00 sec)
mysql>SELECT*FROM mydb.table_lock;# 客户端B+------+| id |+------+|3||1|+------+2rowsinset(0.02 sec)
3.3.行级锁
1.添加“隐式”行级锁:
当用户对InnoDB存储引擎的数据表执行写操作前,服务器会自动为通过索引条件检索的记录添加行级排他锁;操作完成后,服务器再自动为其解锁。
操作语句的执行时间是“隐式”行级锁的生命周期,该生命周期的持续时间一般都比较短暂,如果想要增加行级锁的生命周期,最常使用的方式是事务处理,让其在事务提交或回滚后再释放行级锁,使行级锁的生命周期与事务的相同。
案例:给数据表添加“隐式”行级锁后数据的读写情况。
1.打开两个客户端A和B,在客户端A中开启事务并修改cid等于3的name值,会隐式的为
mydb.row_lock
设置行级排他锁:
# 开启事务
mysql>STARTTRANSACTION;
Query OK,0rows affected (0.00 sec)# 修改cid等于3的name值
mysql>UPDATE mydb.row_lock SET name='cc'WHERE cid=3;
Query OK,1row affected (0.00 sec)Rowsmatched: 1 Changed: 1Warnings: 0
2.在客户端B中开启事务,删除cid等于2和3的记录:
# 开启事务
mysql>STARTTRANSACTION;
Query OK,0rows affected (0.00 sec)# 删除cid等于2的记录
mysql>DELETEFROM mydb.row_lock WHERE cid=2;
Query OK,0rows affected (0.00 sec)# 删除cid等于3的记录
mysql>DELETEFROM mydb.row_lock WHERE cid=3;# 此处光标会不停闪烁,进入锁等待状态
2.添加“显式”行级锁:语法结构为:
SELECT语句 FORUPDATE|LOCKINSHAREMODE;# FOR UPDATE表示添加的锁类型是行级排他锁# LOCK IN SHARE MODE表示添加的锁类型是行级共享锁
“显式”添加行级锁时,会自动添加意向锁,再添加行级锁。意向锁是“隐式”表级锁,多个意向锁之间不会产生冲突且互相兼容。MySQL服务器会判断添加的是行级共享锁或行级排他锁,再自动添加意向共享锁或意向排他锁,不能人为干预。
意向锁的作用是标识表中的某些记录正在被锁定或其他用户将要锁定表中的某些记录。
表级锁类型的兼容性:
共享锁排他锁意向共享锁意向排他锁共享锁兼容冲突兼容冲突排他锁冲突冲突冲突冲突意向共享锁兼容冲突兼容兼容意向排他锁冲突冲突兼容兼容
案例:给数据表添加行级排他锁后客户端A和客户端B的读写情况。
1.在客户端A中开启事务,为cid等于3的记录添加行级排他锁:
# 开启事务
mysql>STARTTRANSACTION;
Query OK,0rows affected (0.00 sec)# 添加行级排他锁
mysql>SELECT*FROM mydb.row_lock WHERE cid=3FORUPDATE;+----+-------+------+| id | name | cid |+----+-------+------+|1| 铅笔 |3|+----+-------+------+1rowinset(0.00 sec)
2.在客户端B中开启事务,为cid等于2的记录添加隐式行级排他锁:
# 开启事务
mysql>STARTTRANSACTION;
Query OK,0rows affected (0.00 sec)# 添加隐式行级排他锁
mysql>UPDATE mydb.row_lock SET name='lili'WHERE cid=2;
Query OK,0rows affected (0.00 sec)Rowsmatched: 0 Changed: 0Warnings: 0
3.在客户端B中为row_lock数据表添加表级读锁:
mysql>LOCKTABLE mydb.row_lock READ;# 此处光标会不停闪烁,进入锁等待状态# 为数据表添加表级读锁时会发生冲突,进行锁等待状态
当InnoDB存储引擎处于
REPEATABLE READ
(可重复读)隔离级别时,行级锁实际上是一个
next-key
锁,它由间隙锁(gap lock)和记录锁(record lock)组成。
记录锁就是行锁;间隙锁是在索引记录之间的间隙、负无穷到第1个索引记录之间或最后1个索引记录到正无穷之间添加的锁,它的作用是在并发时防止其他事务在间隙插入记录,解决事务幻读的问题。
案例:演示给数据表添加行锁,查看间隙锁是否存在。
1.在客户端A中开启事务,为cid等于3的记录添加行锁:
mysql>STARTTRANSACTION;
Query OK,0rows affected (0.00 sec)
mysql>SELECT*FROM mydb.row_lock WHERE cid=3FORUPDATE;+----+-------+------+| id | name | cid |+----+-------+------+|1| 铅笔 |3|+----+-------+------+1rowinset(0.00 sec)
2.在客户端B中,插入cid等于1、2、5、6的记录:
mysql>INSERTINTO mydb.row_lock (name, cid)VALUES('电视',1);# 此处光标会不停闪烁,进入锁等待状态
mysql>INSERTINTO mydb.row_lock (name, cid)VALUES('电视',2);# 此处光标会不停闪烁,进入锁等待状态
mysql>INSERTINTO mydb.row_lock (name, cid)VALUES('电视',5);# 此处光标会不停闪烁,进入锁等待状态
mysql>INSERTINTO mydb.row_lock (name, cid)VALUES('电视',6);
Query OK,1row affected (0.00 sec)
3.4.查看InnoDB的锁
InnoDB存储引擎的锁比较复杂,使用
SHOW ENGINE INNODB STATUS
语句可以查看当前表中添加的锁类型。在查看时要保证系统变量
innodb_status_output_locks
开启。
查看和设置系统变量
innodb_status_output_locks`的语句:
mysql>SHOW VARIABLES LIKE'innodb_status_output_locks';# 查看系统变量+------------------------------+-------+| Variable_name |Value|+------------------------------+-------+| innodb_status_output_locks |OFF|+------------------------------+-------+
mysql>SETGLOBAL innodb_status_output_locks=ON;# 设置系统变量
使用
SHOW ENGINE INNODB STATUS
语句查看数据表添加的锁:
mysql>SHOWENGINEINNODBSTATUS\G
***************************1.row***************************Type: InnoDB
Name:
Status:
……(此处省略部分内容)
TABLELOCKtable`mydb`.`row_lock` trx id 10386lockmode IX
RECORD LOCKS space id 247 page no4 n bits 80index cid oftable`mydb`.`row_lock` trx id 10386
lock_mode X
# X表示next-key lock的排他锁,IX在X之前添加
……(此处省略部分内容)
RECORD LOCKS space id 247 page no3 n bits 80indexPRIMARYoftable`mydb`.`row_lock` trx id
10386 lock_mode X locks rec but not gap
……(此处省略部分内容)
RECORD LOCKS space id 247 page no4 n bits 80index cid oftable``mydb`.`row_lock` trx id 10386
lock_mode X locks gap before rec
……(此处省略部分内容)
4.分表技术
随着时间的推移,数据库中创建的数据会越来越多,而单张数据表存储的数据是有限的,当数据表中的数据达到一定的量级(如千万级)时,即使添加了索引,查询寻数据时依然会很慢,尤其是对数据表进行并发操作时,增加了单表的访问压力。此时,可以考虑使用分表技术,根据不同的需求对数据表进行拆分,从而达到分散数据表压力的目的,提升数据库的访问性能。
MySQL中常用的分表技术有两种,分别时水平分表和垂直分表。
4.1.水平分表
水平分表是根据指定的拆分算法,将一张数据表中的全部记录分别存储到多个数据表中,水平分表必须保证每个数据表的字段相同,但每个数据表名称不同。
水平分表实现原理: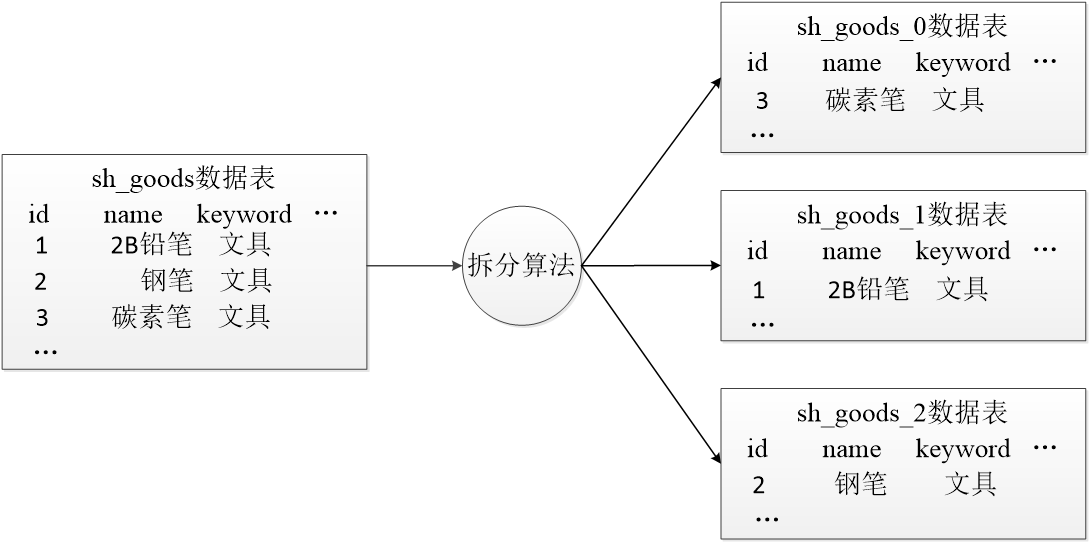
水平分表的拆分算法有很多,根据项目的业务不同可以演化出多种不同的算法。常用的拆分算法是根据记录ID与分表的个数取余获取分表编号,根据商品的创建时间、品牌、店铺、销量等级的不同将其分别存储到不同的分表中。
分表的数量以及拆分方式还需考虑表的预估容量、可扩展性等因素。
水平分表的优点:使单张表的数据保持在一定的量级,提高系统的稳定性和负载能力。
水平分表的缺点:使得数据分散存储各个表中,加大了数据的维护难度。
4.2.垂直分表
垂直分表是将同一个业务的不同字段存储到多张数据表中,经常使用的字段放到主表中,不常使用的字段放到从表中,主表和从表通过一个字段(通常为主键)连接。
假如用户表包含12个字段,使用垂直分表将用户表拆分成一个主表和一个从表:
主表字段****从表字段用户ID(主键)用户ID(主键)用户名用户级别密码性别邮箱注册时间手机号创建时间QQ号更新时间是否激活—
垂直分表的优点:
- 业务逻辑更加清晰。
- 方便数据进行整合与扩展。
- 可以根据实际需求为主表和从表选择不同的存储引擎。
垂直分表的缺点:
- 需要管理冗余字段。
- 查询用户完整信息时需要进行表连接查询。
5.分区技术
5.1.分区概述
分区技术是在操作数据表时根据给定的算法,将数据在逻辑上分到多个区域中存储,还可以设置子分区,将数据存放到更加具体的区域内。
分区技术可以使一张数据表的数据存储在不同的物理磁盘中,相比单个磁盘或文件系统能够存储更多的数据,实现更高的查询吞吐量。
如果
WHERE子
句包含分区条件,系统只需扫描相关一个或多个分区而不用全表扫描,提高查询效率。
5.2.创建分区
创建数据表的同时创建分区的语法:
CREATETABLE 数据表名称
[(字段与索引列表)][表选项]PARTITIONBY 分区算法(分区字段)[PARTITIONS 分区数量][SUBPARTITION BY 子分区算法(子分区字段)[SUBPARTITIONS 子分区数量]][(PARTITION 分区名 [VALUES 分区选项][其他选项][(SUBPARTITION 子分区名 [子分区其他选项])],
…
)];# 一个数据表包含分区的最大数量为1024,分区文件的序号默认从0开始,当有多个分区时依次递增加1
分区算法分别为
LIST、RANGE、HASH和KEY
,每种算法对应的分区字段不同,具体如下:
RANGE|LIST{(表达式)|COLUMNS(字段列表)}
HASH(表达式)KEY[ALGORITHM={1|2}](字段列表)
KEY
算法的
ALGORITHM
选项用于指定
key-hashing
函数的算法,值为1适用于MySQL 5.1版本;默认值为2,适用于MySQL 5.5及以后版本,子分区算法只支持
HASH和KEY
。
使用
RANGE
分区算法时,必须使用
LESS THAN
关键字定义分区选项,使用
LIST
分区算法时,必须使用IN关键字定义分区选项,具体语法如下:
# RANGE算法的分区选项PARTITION 分区名 VALUES LESS THAN {(表达式 | 值列表)| MAXVALUE}
PARTITION 分区名 VALUESIN(值列表)# LIST算法的分区选项
创建分区的其他选项:
选项名****描述ENGINE用于设置分区的存储引擎COMMENT用于为分区添加注释DATA DIRECTORY用于为分区设置数据目录INDEX DIRECTORY用于为分区设置索引目录MAX_ROWS用于为分区设置最大的记录数MIN_ROWS用于为分区设置最小的记录数TABLESPACE用于为分区设置表空间名称
创建分区时还应注意以下两点:
① 创建分区的数据表时,主键必须包含在建立分区的字段中。
② 当创建分区的数据表仅有一个AUTO_INCREMENT字段时,该字段必须为索引字段。
案例:演示创建LIST分区和HASH分区。
1.创建LIST分区:
CREATETABLE mydb.p_list(
id INTAUTO_INCREMENTCOMMENT'ID 编号',
name VARCHAR(50)COMMENT'姓名',
dpt INTCOMMENT'部门编号',KEY(id))PARTITIONBY LIST(dpt)(PARTITION p1 VALUESIN(1,3),PARTITION p2 VALUESIN(2,4));# 给p_list表中的dpt字段分区# 当字段的值为1或3时,将记录放在p1分区# 当字段的值为2或4时,将记录放在p2分区
2.分区创建完成后,会在MySQL的
data/mydb
目录下看到对应的分区数据文件:
p_list#p#p1.idb
p_list#p#p2.idb# p_list是建立分区的数据表名称# p1和p2是分区名称
3.使用
SHOW TABLE STATUS
语句查看p_list数据表的信息:
mysql>SHOWTABLESTATUSLIKE'p_list'\G
***************************1.row***************************
Name: p_list
Engine: InnoDB
Version: 10
Row_format: Dynamic
……(此处省略部分查询结果)
Checksum: NULL
Create_options: partitioned
Comment:
4.创建
HASH
分区:
CREATETABLE mydb.p_hash(
id INTAUTO_INCREMENT,
name VARCHAR(50),
dpt INT,KEY(id))ENGINE=INNODBPARTITIONBYHASH(dpt)PARTITIONS 3;# 使用HASH算法为p_hash数据表创建了3个分区,分区文件的序号依次为0、1和2
5.3.增加分区
给已创建的数据表增加分区的语法:
# LIST或RANGE分区ALTERTABLE 数据表名称 ADDPARTITION(PARTITION 分区名 VALUESIN(值列表), …);# HASH或KEY分区ALTERTABLE 数据表名称 ADDPARTITION PARTITIONS 分区数量;
给
mydb
数据库中的
p_list
和
p_hast
数据表添加分区:
# 给p_list数据表添加分区ALTERTABLE mydb.p_list ADDPARTITION(PARTITION new1 valuesIN(5,6),PARTITION new2 valuesIN(7,8));# 给p_hash数据表添加分区ALTERTABLE mydb.p_hash ADDPARTITION PARTITIONS 1;
5.4.删除分区
如果数据表不再需要设置分区,可以将分区删除,不同的分区算法删除方式也不同,删除分区的语法:
# 删除HASH、KEY分区ALTERTABLE 数据表名称 COALESCEPARTITION 分区数量;# 删除RANGE、LIST分区ALTERTABLE 数据表名称 DROPPARTITION 分区名;
删除HASH和KEY分区时,会将分区内的数据重新整合到剩余的分区中
删除RANGE和LIST分区时,会同时删除分区中保存的数据
数据表仅剩一个分区时,只能使用DROP TABLE语句删除分区
仅清空各分区表中的数据,不删除对应的分区文件的语法:
ALTERTABLE 数据表名称 TRUNCATEPARTITION {分区名 |ALL};
案例:删除分区:
1.给
mydb.p_list
表添加数据,测试删除分区后数据的变化:
INSERTINTO mydb.p_list (name, dpt)VALUES('Tom',5),('Lucy',6),('Lily',7),('Jim',8);# dpt为5和6的记录保存在名为new1的分区中# dpt为7和8的记录保存在名为new2的分区中
2.删除
mydb.p_list
表中名为
new1
的分区,查看数据表中的数据:
ALTERTABLE mydb.p_list DROPPARTITION new1;SELECT*FROM mydb.p_list;+----+------+------+| id | name | dpt |+----+------+------+|3| Lily |7||4| Jim |8|+----+------+------+# p_list表中new1分区下保存的数据同时被删除,仅剩new2分区下的两条记录
6.整理数据碎片
在MySQL中,删除数据时,只删除了数据表中的数据,数据占用的存储空间仍然会被保留。
如果项目长期进行删除数据操作,索引文件和数据文件都将产生“空洞”,形成很多不连续碎片,造成数据表占用空间很大,实际保存的数据很少问题。
为了解决数据碎片问题,可以使用MySQL提供的
OPTIMIZE TABLE
命令,该命令可以在使用
MyISAM
存储引擎或
InnoDB
存储引擎的数据表中进行数据碎片维护,重新组织表中数据和关联索引数据的物理存储,减少存储空间并提高访问表时的
I/O
效率。
案例:演示数据碎片的整理:
1.创建
my_optimize
数据表并添加数据:
# 创建my_optimize数据表CREATETABLE mydb.my_optimize (
id INTUNSIGNEDPRIMARYKEYAUTO_INCREMENT,
name VARCHAR(20)NOTNULLDEFAULT'');
Query OK,0rows affected (0.01 sec)# 添加数据INSERTINTO mydb.my_optimize (name)VALUES('TOM'),('JIMMY'),('LUCK'),('CAKE');
Query OK,4rows affected (0.00 sec)
Records: 4 Duplicates: 0Warnings: 0
2.使用数据复制的方式添加50万条以上的数据:
INSERTINTO mydb.my_optimize (name)SELECT name FROM mydb.my_optimize;
Query OK,4rows affected (0.00 sec)
Records: 4 Duplicates: 0Warnings: 0# 多次执行上述语句直到数据达到50万条以上,此处省略
3.添加数据后,打开数据库
data
目录,查看
my_optimize.idb
数据文件的大小:
my_optimize.idb
数据文件的大小约为40MB。
4.删除数据后查看
my_optimize.idb
数据文件的大小:
DELETEFROM mydb.my_optimize WHERE name='LUCK';
Query OK,262144rows affected (2.25 sec)
5.使用
OPTIMIZE TABLE
命令整理数据碎片:
OPTIMIZETABLE mydb.my_optimize\G
***************************1.row***************************Table: mydb.my_optimize
Op: optimize
Msg_type: note
Msg_text: Table does not support optimize, doing recreate +analyze instead
***************************2.row***************************Table: mydb.my_optimize
Op: optimize
Msg_type: status
Msg_text: OK
2rowsinset(5.33 sec)
6.整理数据碎片后,查看
my_optimize.idb
数据文件的大小:
注意:修复数据表的数据碎片时,会把所有的数据文件重新整理一遍。如果数据表的记录数比较多,会消耗一定的资源,可以根据实际情况按周、月或季度进行数据碎片整理。
7.分析SQL的执行情况
在项目的开发阶段,由于数据量比较小,开发人员更注重功能的实现,项目上线后,随着用户数量的不断增加,数据库中的数据量也不断增加,有些SQL语句查询数据的速度越来越慢,影响整个项目的性能。因此,对这些有问题的SQL语句进行优化称为急需解决的问题。
7.1.慢查询日志
慢查询日志记录了执行时间超过指定时间的查询语句,找到执行效率低的查询语句并优化。
查看慢查询日志的示例:
SHOW VARIABLES LIKE'slow_query%';+---------------------+-----------------------------------+| Variable_name |Value|+---------------------+-----------------------------------+| slow_query_log |OFF|| slow_query_log_file | D:\mysql-8.0.27-winx64\data\ ||| CZ-20211214JLWP-slow.log |+---------------------+-----------------------------------+# slow_query_log用于设置慢查询日志的开启状态,OFF表示关闭# slow_query_log_file是慢查询日志文件所在的目录x
慢查询日志默认是关闭的,需要手动开启慢查询日志,命令如下:
SETGLOBAL slow_query_log=ON;
当查询语句超过指定时间才会记录到慢查询日志,查看慢查询日志超时时间的命令:
SHOW VARIABLES LIKE'long_query_time';+------------------+------------+| Variable_name |Value|+------------------+------------+| long_query_time |10.000000|+------------------+------------+# 默认值10秒,超过设定的时间会记录到慢查询日志
执行慢查询语句后查看记录的日志信息:
SELECT sleep(10);
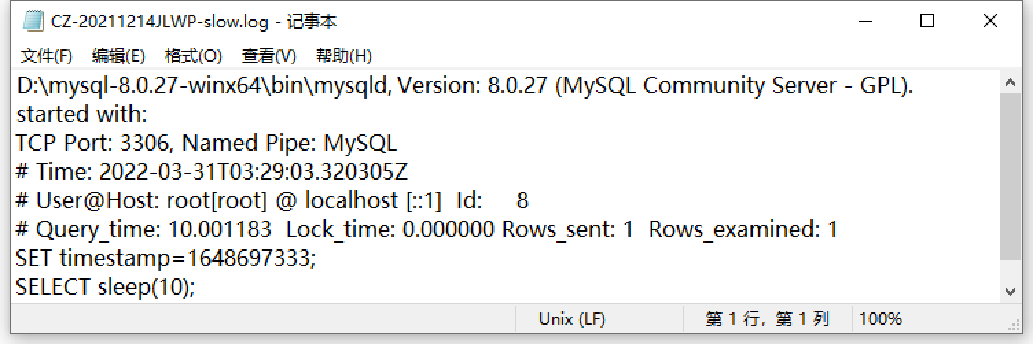
- Time表示执行慢查询语句的服务器时间
- User@Host指定执行慢查询语句的用户
- Query_time表示慢查询语句的执行时间
- Lock_time表示锁定的时间
- Rows_sent表示发送的记录数
- Rows_examined表示检索的记录数
- SET timestamp是信息写入日志的时间戳
- 最后一行是慢查询的SQL语句
7.2.通过performance_schema进行查询分析
通过查询
performance_schema
数据库可以获取SQL语句的资源消耗信息,从而监控MySQL服务器的性能,了解执行SQL语句的过程中各个环节的消耗情况,例如打开表、检查权限、返回数据这些操作分别用了多长时间。
该数据库的
setup_actors
数据表限制指定主机和指定用户收集历史事件,查看数据表的数据:
SELECT*from performance_schema.setup_actors;+------+------+------+-----------+----------+| HOST |USER| ROLE | ENABLED | HISTORY |+------+------+------+-----------+----------+|%|%|%| YES | YES |+------+------+------+-----------+----------+# ENABLED列和HISTORY列的值为YES,表示开启了事件收集# HOST列和USER列的值为%说明允许监控和收集所有的历史事件
为了减少运行时的开销和历史表中收集的数据量,更新
setup_actors
数据表中的数据,禁止监控和收集所有的历史事件:
UPDATE performance_schema.setup_actors SET ENABLED='NO', HISTORY='NO'WHERE HOST='%'ANDUSER='%';
Query OK,1row affected (0.04 sec)Rowsmatched: 1 Changed: 1Warnings: 0
案例:演示监控和收集用户的历史事件。
1.创建
test_user
用户,授予
test_user
用户查询
shop
数据库的权限:
# 创建test_user用户CREATEUSER'test_user'@'localhost' IDENTIFIED BY'123456';
Query OK,0rows affected (0.11 sec)# 授予test_user用户权限GRANTSELECTON shop.*TO'test_user'@'localhost';
Query OK,0rows affected (0.00 sec)
2.向
setup_actors
数据表中添加一条新的记录,查看添加结果:
INSERTINTO performance_schema.setup_actors (HOST,USER,ROLE,ENABLED,HISTORY)VALUES('localhost','test_user','%','YES','YES');SELECT*FROM performance_schema.setup_actors;+-----------+-----------+------+-----------+----------+| HOST |USER| ROLE | ENABLED | HISTORY |+-----------+-----------+------+-----------+----------+|%|%|%|NO|NO|| localhost | test_user |%| YES | YES |+-----------+-----------+------+-----------+----------+
3.为了保证监控和收集的事件信息的全面性,需要更新
setup_instruments
数据表和
setup_consumers
数据表的相关配置项:
UPDATE performance_schema.setup_instruments SET ENABLED='YES', TIMED='YES'WHERE NAME LIKE'%stage/%';UPDATE performance_schema.setup_consumers SET ENABLED='YES'WHERE NAME LIKE'%events_statements_%';UPDATE performance_schema.setup_consumers SET ENABLED='YES'WHERE NAME LIKE'%events_stages_%';
4.重新打开新的命令行窗口,使用
test_user
用户登录MySQL,执行要分析的语句:
SELECT*FROM sh_goods WHERE id=1;
在原有的命令行窗口中查看SQL语句的耗时情况:
SELECT EVENT_ID,TRUNCATE(TIMER_WAIT/1000000000000,6)as Duration, SQL_TEXT FROM performance_schema.events_statements_history_long WHERE SQL_TEXT like'%1%';+-----------+----------+-----------------------------------------------+| EVENT_ID | Duration | SQL_TEXT |+-----------+----------+-----------------------------------------------+|76|0.0042|SELECT*FROM sh_goods WHERE id=1|+-----------+----------+-----------------------------------------------+# EXENT_ID表示每个查询语句对应的ID,Duration表示SQL语句执行过程中每一个步骤的耗时# SQL_TEXT是执行的具体SQL语句
5.查看这个SQL语句在执行过程中的状态和消耗时间:
SELECT event_name AS Stage,TRUNCATE(TIMER_WAIT/1000000000000,6)AS Duration FROM performance_schema.events_stages_history_long WHERE NESTING_EVENT_ID=76;+-----------------------------------------------------+----------+| Stage | Duration |+-----------------------------------------------------+----------+| stage/sql/starting|0.0000|| stage/sql/Executing hook ontransactionbegin.|0.0000|| stage/sql/starting|0.0000|| stage/sql/checking permissions |0.0000|
……(此处省略部分内容)
+------------------------------------------------+----------+# Stage表示SQL语句的执行状态,Duration表示每个状态的执行时间
8.练习
(1)在mydb数据库中创建my_user用户表,数据表的字段有id、name和pid,添加200万条测试数据。
(2)设置查询时间超过0.5秒的查询为慢查询,执行一系列的查询语句,找到慢查询语句。
(3)通过performance_schema进行查询分析,获取语句执行的精确时间。
(4)优化慢查询语句,提高查询效率。
检索的记录数
- SET timestamp是信息写入日志的时间戳
- 最后一行是慢查询的SQL语句
7.2.通过performance_schema进行查询分析
通过查询
performance_schema
数据库可以获取SQL语句的资源消耗信息,从而监控MySQL服务器的性能,了解执行SQL语句的过程中各个环节的消耗情况,例如打开表、检查权限、返回数据这些操作分别用了多长时间。
该数据库的
setup_actors
数据表限制指定主机和指定用户收集历史事件,查看数据表的数据:
SELECT*from performance_schema.setup_actors;+------+------+------+-----------+----------+| HOST |USER| ROLE | ENABLED | HISTORY |+------+------+------+-----------+----------+|%|%|%| YES | YES |+------+------+------+-----------+----------+# ENABLED列和HISTORY列的值为YES,表示开启了事件收集# HOST列和USER列的值为%说明允许监控和收集所有的历史事件
为了减少运行时的开销和历史表中收集的数据量,更新
setup_actors
数据表中的数据,禁止监控和收集所有的历史事件:
UPDATE performance_schema.setup_actors SET ENABLED='NO', HISTORY='NO'WHERE HOST='%'ANDUSER='%';
Query OK,1row affected (0.04 sec)Rowsmatched: 1 Changed: 1Warnings: 0
案例:演示监控和收集用户的历史事件。
1.创建
test_user
用户,授予
test_user
用户查询
shop
数据库的权限:
# 创建test_user用户CREATEUSER'test_user'@'localhost' IDENTIFIED BY'123456';
Query OK,0rows affected (0.11 sec)# 授予test_user用户权限GRANTSELECTON shop.*TO'test_user'@'localhost';
Query OK,0rows affected (0.00 sec)
2.向
setup_actors
数据表中添加一条新的记录,查看添加结果:
INSERTINTO performance_schema.setup_actors (HOST,USER,ROLE,ENABLED,HISTORY)VALUES('localhost','test_user','%','YES','YES');SELECT*FROM performance_schema.setup_actors;+-----------+-----------+------+-----------+----------+| HOST |USER| ROLE | ENABLED | HISTORY |+-----------+-----------+------+-----------+----------+|%|%|%|NO|NO|| localhost | test_user |%| YES | YES |+-----------+-----------+------+-----------+----------+
3.为了保证监控和收集的事件信息的全面性,需要更新
setup_instruments
数据表和
setup_consumers
数据表的相关配置项:
UPDATE performance_schema.setup_instruments SET ENABLED='YES', TIMED='YES'WHERE NAME LIKE'%stage/%';UPDATE performance_schema.setup_consumers SET ENABLED='YES'WHERE NAME LIKE'%events_statements_%';UPDATE performance_schema.setup_consumers SET ENABLED='YES'WHERE NAME LIKE'%events_stages_%';
4.重新打开新的命令行窗口,使用
test_user
用户登录MySQL,执行要分析的语句:
SELECT*FROM sh_goods WHERE id=1;
在原有的命令行窗口中查看SQL语句的耗时情况:
SELECT EVENT_ID,TRUNCATE(TIMER_WAIT/1000000000000,6)as Duration, SQL_TEXT FROM performance_schema.events_statements_history_long WHERE SQL_TEXT like'%1%';+-----------+----------+-----------------------------------------------+| EVENT_ID | Duration | SQL_TEXT |+-----------+----------+-----------------------------------------------+|76|0.0042|SELECT*FROM sh_goods WHERE id=1|+-----------+----------+-----------------------------------------------+# EXENT_ID表示每个查询语句对应的ID,Duration表示SQL语句执行过程中每一个步骤的耗时# SQL_TEXT是执行的具体SQL语句
5.查看这个SQL语句在执行过程中的状态和消耗时间:
SELECT event_name AS Stage,TRUNCATE(TIMER_WAIT/1000000000000,6)AS Duration FROM performance_schema.events_stages_history_long WHERE NESTING_EVENT_ID=76;+-----------------------------------------------------+----------+| Stage | Duration |+-----------------------------------------------------+----------+| stage/sql/starting|0.0000|| stage/sql/Executing hook ontransactionbegin.|0.0000|| stage/sql/starting|0.0000|| stage/sql/checking permissions |0.0000|
……(此处省略部分内容)
+------------------------------------------------+----------+# Stage表示SQL语句的执行状态,Duration表示每个状态的执行时间
8.练习
(1)在mydb数据库中创建my_user用户表,数据表的字段有id、name和pid,添加200万条测试数据。
(2)设置查询时间超过0.5秒的查询为慢查询,执行一系列的查询语句,找到慢查询语句。
(3)通过performance_schema进行查询分析,获取语句执行的精确时间。
(4)优化慢查询语句,提高查询效率。
版权归原作者 邹老师的小课堂 所有, 如有侵权,请联系我们删除。