
需求
数据库(Postgres、Hive等)中的元数据(表信息)可以通过cli命令及ui界面的方式采集元数据信息到Datahub中,并配置表级与列级血缘。那么,SQL 查询语句(SQL脚本/SQL DLL)如何生成数据集及血缘呢,比如FineBI的数据集就是一段SQL查询语句。
分析
将SQL脚本/语句生成Datahub中的数据集及血缘,需要验证以下关键技术点:
- 通过Python Emitter API生成数据集
- 解析SQL脚本为Python Emitter API生成数据集,需要的输入结构体
- 通过Python Emitter API生成表级血缘及列级血缘
- 解析SQL脚本为Python Emitter API生成表级血缘,需要的输入结构体
- 解析SQL脚本为Python Emitter API生成列级血缘,需要的输入结构体
环境
- 安装 Datahub服务
- 安装acryl-datahub==0.9.2.2
- 安装sql-metadata==2.6.0
实验1:Python Emitter API生成数据集
代码:https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/dataset_schema.py
运行:直接修改gms_server地址,运行即可。
实验2:解析SQL脚本为MetadataChangeProposalWrapper结构体
- 解析SQL,提取列字段名,列字段类型(通过FineBI接口获取)
测试代码sql_fields.py
from sql_metadata import Parser
sql ="""
select
id as ID
, opp_header_id ID1
, opp_code opp_code
, order_line_id 订单行ID
, order_line_code 订单行编码
, SUBSTR(order_line_code, 0, INSTR(order_line_code, '-', 1, 2)-1) 订单编码
, op_type 来源类型
, qty 订单数量
, dorn_qty 已退货数量
, unit_price 单价
, ((qty - dorn_qty) * unit_price) 应回款合计
, total_amount 已回款合计
, ((qty - dorn_qty) * unit_price - total_amount) 待回款合计
, total_amount 回款金额
, last_upd_time 回款时间
, remark 备注
, is_enabled 是否生效
from
dscsm_execute.csm_cs_allocate cca
where 1=1
and cca.is_enabled = '1' and cca.is_deleted = '0'
"""
parser = Parser(sql)
aliases = parser.columns_aliases_names
print(parser.columns_aliases_names)print(parser.columns)
运行结果如下:
我们可以按需要将上面提取的字段,传入MetadataChangeProposalWrapper结构体中SchemaFieldClass的fieldPath变量。
实验3:Python Emitter API生成表级血缘
代码:https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/lineage_emitter_rest.py
运行:直接修改gms_server地址,运行即可。
注意事项:
- make_dataset_urn只是引用dataset数据集地址,如果dataset不存在,会默认创建只有数据集名的空数据集(字段名等信息为空)。
- 使用该脚本创建表级别前,建议先通过CLI、UI界面、Python Emitter等导入Dataset信息。
- 通过浏览器地址,获取已有元数据的urn 如下图所示:
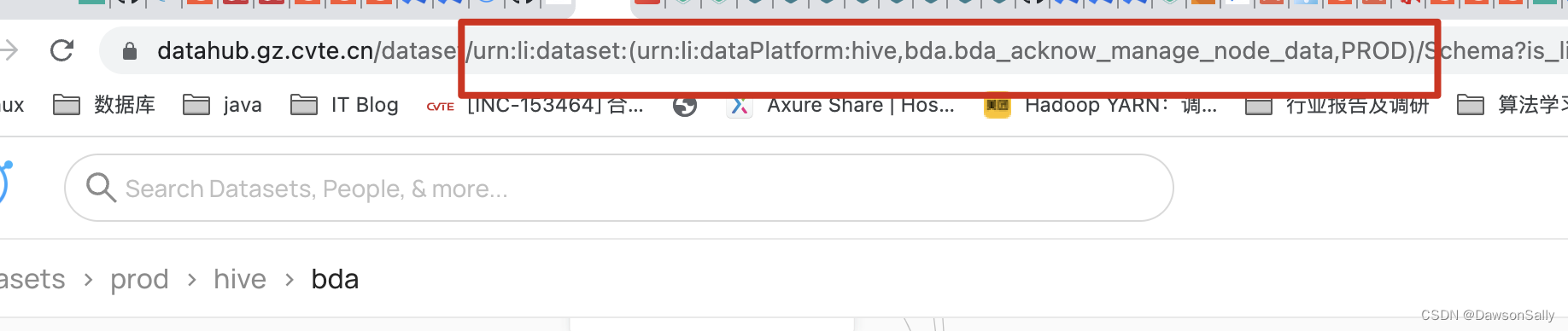
实验4:Python Emitter API生成字段级血缘
代码:https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/lineage_emitter_dataset_finegrained.py
运行:直接修改gms_server地址,运行即可。
注意事项:
- make_dataset_urn只是引用dataset数据集地址,如果dataset不存在,会默认创建只有数据集名的空数据集(字段名等信息为空)。
- 使用该脚本创建表级别前,建议先通过CLI、UI界面、Python Emitter等导入Dataset信息。
- 通过浏览器地址,获取已有元数据的urn
解析SQL生成数据集、表级&列级血缘
- 使用sql_metadata解析SQL Select脚本,获取字段信息,通过MetadataChangeProposalWrapper结构体构建数据集。
#!/usr/bin/python3# coding=utf-8# -----------------------------------------------------------------------------------# 日 期:2023.01.30# 作 者:dawsongzhao# 用 途:根据SQL SELECT生成Datahub数据集# 1. 使用时机:无法通过cli ingest从数据库抽取表元数据时,例如FineBI数据集,只是SQL代码。# 2. 注意事项:代码功能演示用,未考虑性能及编码规范# 3. 使用方法:python3 sql_select_to_datahub.py# 版本记录:# -----------------------------------------------------------------------------------from sql_metadata import Parser
from datahub.emitter.mce_builder import make_data_platform_urn, make_dataset_urn
from datahub.emitter.mcp import MetadataChangeProposalWrapper
from datahub.emitter.rest_emitter import DatahubRestEmitter
import datahub.emitter.mce_builder as builder
# Imports for metadata model classesfrom datahub.metadata.schema_classes import(
AuditStampClass,
ChangeTypeClass,
DateTypeClass,
OtherSchemaClass,
SchemaFieldClass,
SchemaFieldDataTypeClass,
SchemaMetadataClass,
StringTypeClass,)classSQLSelectToDatahub():def__init__(self):
self._table_sql ="""
SELECT
v.evt_code as " 事件编号 ",
v.evt_expenses_code as "费用单号",
v.type_name as "费用类型",
v.duty_bill_amount as "单据金额",
v.duty_settle_amount as "结算金额",
v.duty_rational_amount as "合理金额",
v.lack_amount as "谈少金额",
v.need_confirm_amount as "待确认金额",
v.exp_crt_time as "费用创建时间",
cc.cvte_year_month as "费用单的归属年月",
v.name as " 事件名称 ",
v.status as " 单据状态 ",
v.evt_class as " 事件分类 ",
v.evt_level as " 事件级别 ",
v.urgency_degree as " 紧急程度 ",
v.cust_code as " 客户 ",
v.cus_name as " 客户名称 ",
v.cust_corps as " 客户战队 ",
v.board_no as " 板卡型号 ",
v.problem_source as " 问题来源 ",
v.occur_stage as " 问题阶段 ",
v.process_users as " 处理团队 ",
v.service_user as " 客服 ",
v.bu_id as " 事业部 ",
v.crt_time as " 制单日期 ",
v.fbk_item_code as " 物料料号 ",
v.fbk_supplier as " 供应商 ",
v.fbk_analyze as " 初步分析情况 ",
v.is_analyze as " 是否有原因分析 ",
v.analyze_date as " 原因分析日期 ",
v.analyse_content_str as " 原因分析内容 ",
v.is_temp_plan as " 是否有临时措施 ",
v.temp_plan_date as " 临时措施日期 ",
v.temp_plan_str as " 临时措施内容 ",
v.factory as " 所属工厂 ",
v.is_rework as " 是否返工 ",
v.evt_type as " 事件类型 ",
v.plan as " 方案 ",
v.dis_range as " 禁用范围 ",
v.dis_software_nums as " 禁用软件数 ",
v.dis_order_nums as " 禁用订单数 ",
v.is_able_hold_gary as " 灰度是否可拦截 ",
v.bu_type as " 事业部类型 ",
v.error_class as " 失误分类 ",
v.fty_fee as " 工厂返工费用 ",
v.outsrc_fee as " 外包返工费用 ",
v.claim_fee as " 客户索赔费用",
v.experiment_fee as " 内部实验费用 ",
v.other_fee as " 其他损失费用 ",
v.total_amount as " 总金额 ",
v.submit_time as " 提交审核关闭时间 ",
v.close_time as " 问题审核通过时间 ",
--v.post as " 岗位分类 ",
v.director_user as " 责任经理 ",
v.dept_id as " 责任部门 ",
v.dept_id_sub2 as " 二级部门 ",
v.dept_id_sub3 as " 三级部门 ",
v.rate as " 责任占比 ",
v.why_status as " 根因状态 ",
v.problem_liable as " 问题责任人 ",
v.error_type as " 根因失误分类 ",
v.post_type as " 根因岗位分类 ",
v.bu_code_search as " 所属事业部 ",
v.count_year as " 统计年份",
v.count_month as " 统计月份",
v.count_day as " 统计日期",
v.count_year_month as " 统计年月",
v.cvte_year as " 归属年份",
v.cvte_month as " 归属月份",
v.cvte_date as " 归属日期",
v.cvte_year_month as "归属年月",
v.w_insert_dt as "数仓处理时间",
v.director_user_submit_time as "责任经理提交时间",
v.dept_fee as "责任部门费用"
from hive.bda_csm_part_main_evt_test_3 v
left JOIN hive.dim_date_d cc
on to_char(exp_crt_time,''yyyymmdd'')= substr(cc.period_wid,1,10)
WHERE coalesce(status,'''') <> ''已作废''
"""
self.__table_name ='hive.bda_csm_part_main_evt_test_3'defgenerate_dataset(self):"""
构建SQL数据集
"""
field_list =[]try:for field in Parser(self._table_sql).columns_aliases_names:
field_list.append(
SchemaFieldClass(
fieldPath=field,type=SchemaFieldDataTypeClass(type=StringTypeClass()),
nativeDataType="VARCHAR(50)",# use this to provide the type of the field in the source system's vernacular
description=field,
lastModified=AuditStampClass(
time=1640692800000, actor="urn:li:corpuser:ingestion"),))
event = self.__generate_event(self.__table_name, self._table_sql, field_list)# Create rest emitter
rest_emitter = DatahubRestEmitter(gms_server="http://10.10.10.10:8080")
rest_emitter.emit(event)print("添加SQL数据集[{}]到Datahub".format(self.__table_name))except:print("解析SQL数据集{}失败".format(self.__table_name))def__generate_event(
self,
name_list,
rawSchema_ddl,
fields_list
):
event: MetadataChangeProposalWrapper = MetadataChangeProposalWrapper(
entityType="dataset",
changeType=ChangeTypeClass.UPSERT,# 如果需要多级目录,就在name中使用点号分隔,一般建议,database.shcema.table
entityUrn=make_dataset_urn(platform="postgres", name=name_list, env="PROD"),
aspectName="schemaMetadata",
aspect=SchemaMetadataClass(
schemaName="customer_postgres",# not used
platform=make_data_platform_urn("postgres"),# important <- platform must be an urn
version=0,# when the source system has a notion of versioning of schemas, insert this in, otherwise leave as 0hash="",# when the source system has a notion of unique schemas identified via hash, include a hash, else leave it as empty string
platformSchema=OtherSchemaClass(rawSchema=rawSchema_ddl),
lastModified=AuditStampClass(
time=1640692800000, actor="urn:li:corpuser:ingestion"),
fields=fields_list,),)return event
if __name__ =="__main__":
fd = SQLSelectToDatahub()
fd.generate_dataset()
- datahub查看数据集:
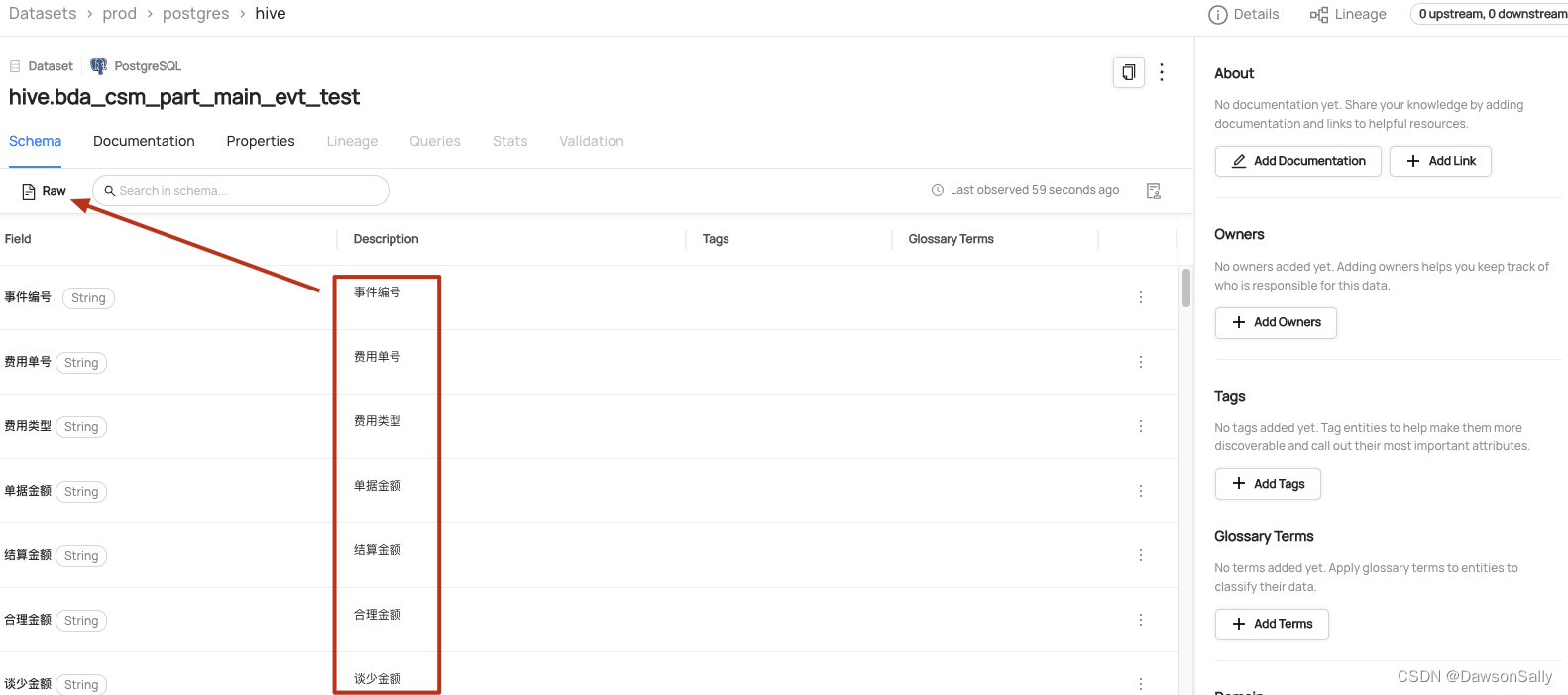
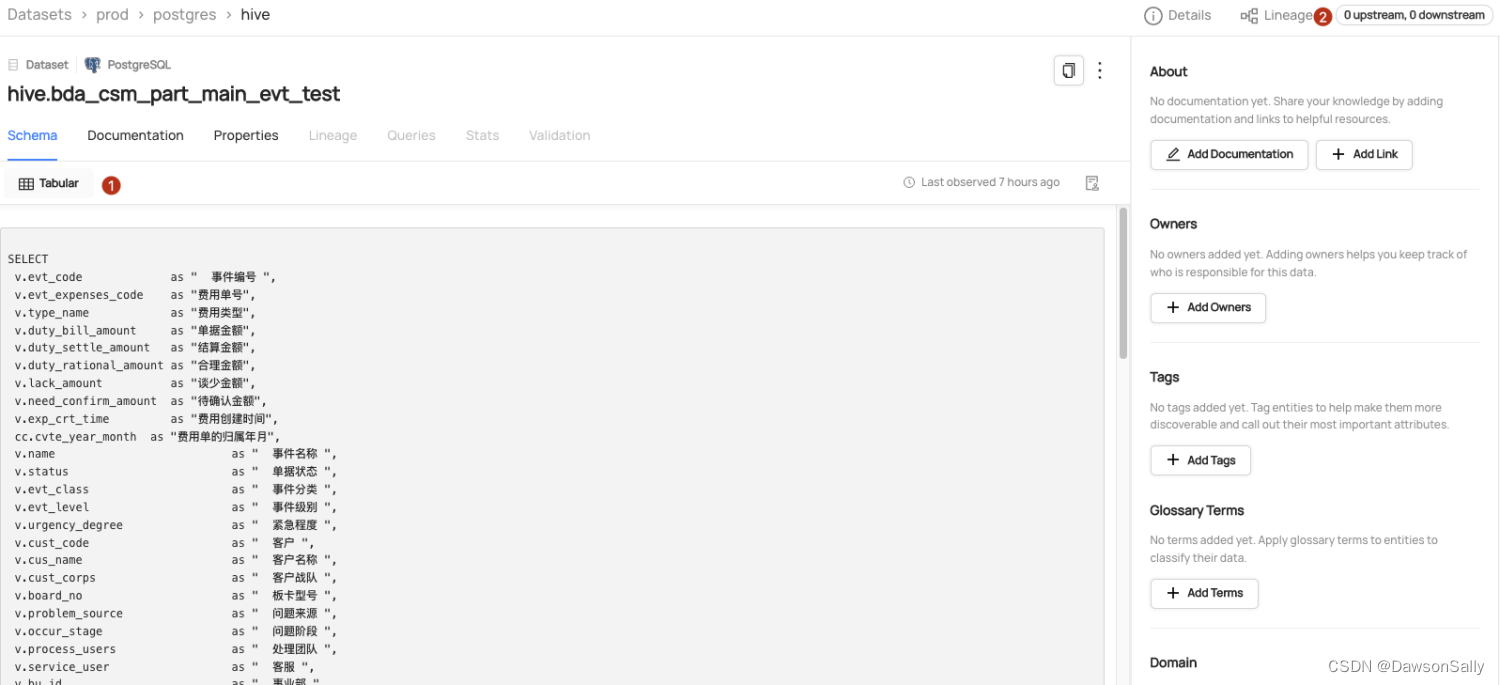 如上图所示,此时数据集,lineage按钮查询不到血缘信息。
如上图所示,此时数据集,lineage按钮查询不到血缘信息。 - 修改以上脚本生成名为:hive.bda_csm_part_main_evt_test、hive.bda_csm_part_main_evt_test_1、hive.bda_csm_part_main_evt_test_2、hive.bda_csm_part_main_evt_test_3的数据集
- 生成表级及字段级血缘
import datahub.emitter.mce_builder as builder
from datahub.emitter.mcp import MetadataChangeProposalWrapper
from datahub.emitter.rest_emitter import DatahubRestEmitter
from datahub.metadata.com.linkedin.pegasus2avro.dataset import(
DatasetLineageType,
FineGrainedLineage,
FineGrainedLineageDownstreamType,
FineGrainedLineageUpstreamType,
Upstream,
UpstreamLineage,)from datahub.metadata.schema_classes import ChangeTypeClass
defdatasetUrn(tbl):return builder.make_dataset_urn("postgres", tbl)deffldUrn(tbl, fld):return builder.make_schema_field_urn(datasetUrn(tbl), fld)# Lineage of fields in a dataset# c1 <-- unknownFunc(bar2.c1, bar4.c1)# c2 <-- myfunc(bar3.c2)# {c3,c4} <-- unknownFunc(bar2.c2, bar2.c3, bar3.c1)# c5 <-- unknownFunc(bar3)# {c6,c7} <-- unknownFunc(bar4)# note that the semantic of the "transformOperation" value is contextual.# In above example, it is regarded as some kind of UDF; but it could also be an expression etc.
fineGrainedLineages =[
FineGrainedLineage(
upstreamType=FineGrainedLineageUpstreamType.FIELD_SET,
upstreams=[fldUrn("hive.bda_csm_part_main_evt_test_1","费用单号"), fldUrn("hive.bda_csm_part_main_evt_test_3","费用单号")],
downstreamType=FineGrainedLineageDownstreamType.FIELD,
downstreams=[fldUrn("hive.bda_csm_part_main_evt_test","费用单号")],),
FineGrainedLineage(
upstreamType=FineGrainedLineageUpstreamType.FIELD_SET,
upstreams=[fldUrn("hive.bda_csm_part_main_evt_test_2","费用类型")],
downstreamType=FineGrainedLineageDownstreamType.FIELD,
downstreams=[fldUrn("hive.bda_csm_part_main_evt_test","费用类型")],
confidenceScore=0.8,
transformOperation="myfunc",),
FineGrainedLineage(
upstreamType=FineGrainedLineageUpstreamType.FIELD_SET,
upstreams=[fldUrn("hive.bda_csm_part_main_evt_test_2","单据金额"), fldUrn("hive.bda_csm_part_main_evt_test_2","结算金额"), fldUrn("hive.bda_csm_part_main_evt_test_3","费用单号")],
downstreamType=FineGrainedLineageDownstreamType.FIELD_SET,
downstreams=[fldUrn("hive.bda_csm_part_main_evt_test","单据金额"), fldUrn("hive.bda_csm_part_main_evt_test","结算金额")],
confidenceScore=0.7,),
FineGrainedLineage(
upstreamType=FineGrainedLineageUpstreamType.DATASET,
upstreams=[datasetUrn("hive.bda_csm_part_main_evt_test_3")],
downstreamType=FineGrainedLineageDownstreamType.FIELD,
downstreams=[fldUrn("hive.bda_csm_part_main_evt_test","合理金额")],),# FineGrainedLineage(# upstreamType=FineGrainedLineageUpstreamType.DATASET,# upstreams=[datasetUrn("bar4")],# downstreamType=FineGrainedLineageDownstreamType.FIELD_SET,# downstreams=[fldUrn("bar", "c6"), fldUrn("bar", "c7")],# ),]# this is just to check if any conflicts with existing Upstream, particularly the DownstreamOf relationship
upstream = Upstream(dataset=datasetUrn("hive.bda_csm_part_main_evt_test_1"),type=DatasetLineageType.TRANSFORMED)
fieldLineages = UpstreamLineage(
upstreams=[upstream], fineGrainedLineages=fineGrainedLineages
)
lineageMcp = MetadataChangeProposalWrapper(
entityType="dataset",
changeType=ChangeTypeClass.UPSERT,
entityUrn=datasetUrn("hive.bda_csm_part_main_evt_test"),
aspectName="upstreamLineage",
aspect=fieldLineages,)# Create an emitter to the GMS REST API.
emitter = DatahubRestEmitter("http://10.10.10.10:8080")# Emit metadata!
emitter.emit_mcp(lineageMcp)
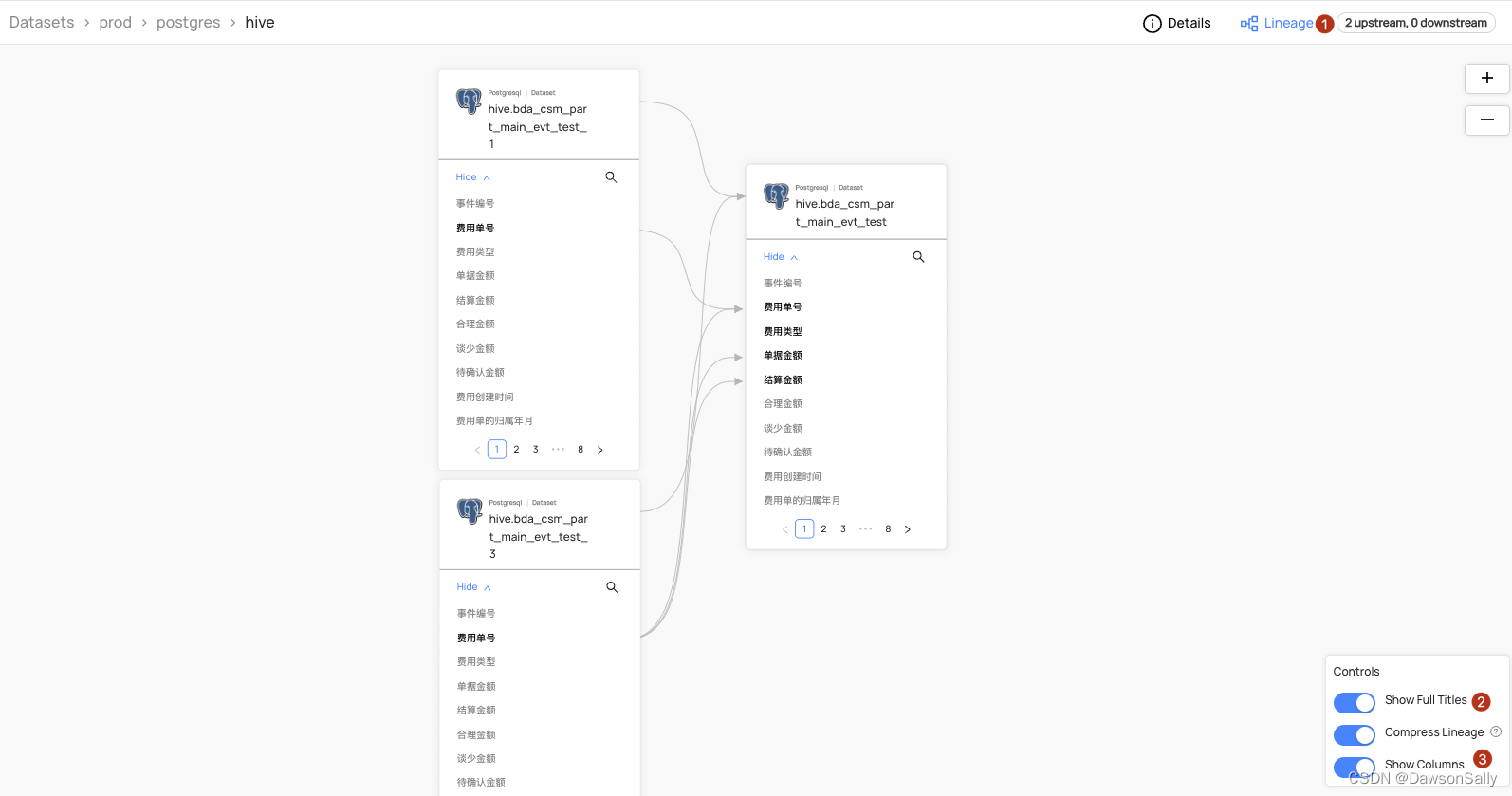
总结
本文简单演示了通过解析SQL代码,并调用Python Emitter API生成datahub数据集、表级、列级别血缘。该演示中还有一些问题没有涉及:
- 如何自动识别SQL代码中字段的类型问题?
- 如何识别Hive SQL代码的字段及类型?
- 能否自动生成Hive SQL的表级及字段级血缘?
如文章:https://blog.csdn.net/zdsx1104/article/details/128808902 中介绍,在生产环境中已经实现FineBI报表-BI图表组件-BI数据-BI PG导出库-数据仓库(ods-dwd-dws-ads)端到端的表级及字段级血缘。有疑问的,欢迎留言沟通。
版权归原作者 DawsonSally 所有, 如有侵权,请联系我们删除。