
文章目录
⛳️ 实战场景
本篇博客为大家介绍一款新的自动化测试工具,效果类似
selenium
,但是这个模块年轻。
模块名称为
playwright-python
,微软开源的,是针对 Python 语言的纯自动化工具,可以通过 API 调用浏览器,github 地址在本文末尾。
接下来将通过 3 篇博客为大家详细介绍该
playwright-python
,彻彻底底了解它。
谁让自动化测试和爬虫不分家呢,这不,橡皮擦来了!
正式开始前依旧是模块安装:
pip install playwright
该模块安装非常快,但完整体验还需要安装浏览器相关驱动,这个有点大,命令如下:
python -m playwright install
安装时注意使用国内源!
等待过程中,可以查阅输出日志,核对安装了哪些模块:
Downloading FFMPEG:FFMPEG;Downloading Firefox 104.0:火狐浏览器驱动;Downloading Chromium:谷歌浏览器驱动;Downloading Webkit 16.0:Webkit 浏览器驱动。
⛳️ 实战操作
第一次实战操作,先从不写代码开始,通过下述命令启动浏览器,然后【录制】我们的操作过程。
python -m playwright codegen
运行代码之后,弹出默认浏览器和一个代码录制展示框,具体如下所示:

下面就可以在左侧的浏览器窗口中进行操作,然后观察右侧自动生成的代码段。
在地址栏输入 baidu.com 跳转到百度首页,然后输入 航天员,点击搜索按钮,生成的代码如下所示。
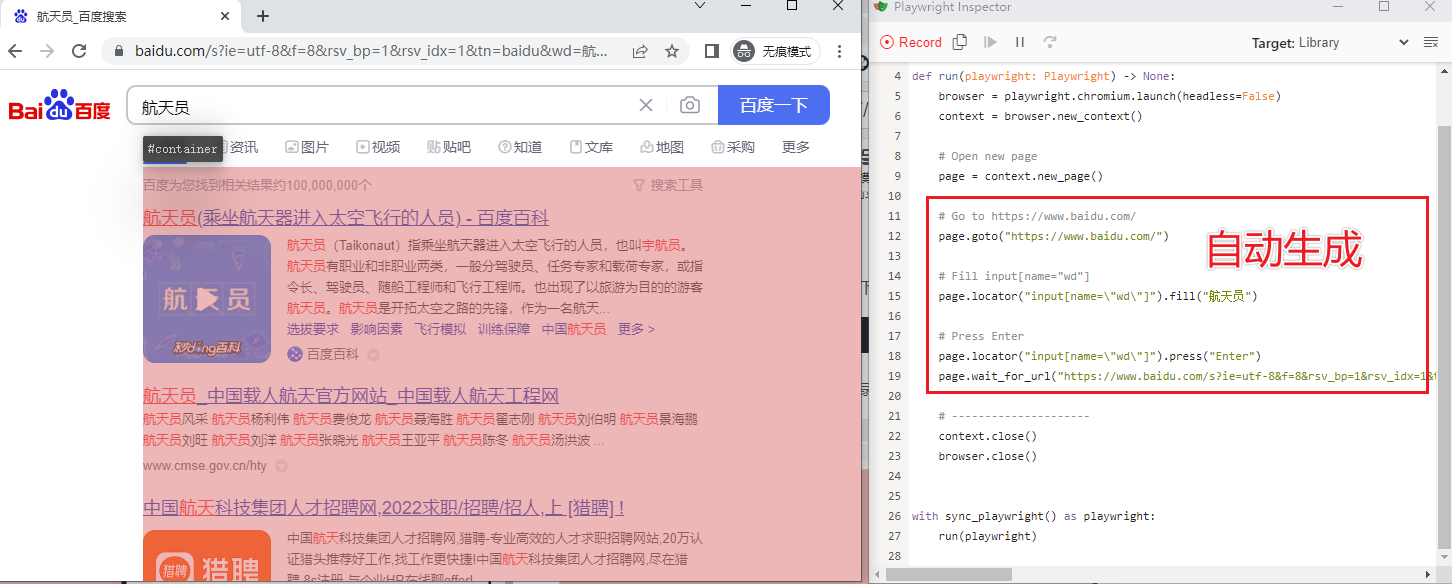
将生成的代码复制到开发工具中,直接运行就可以得到刚刚相同的操作。
from playwright.sync_api import Playwright, sync_playwright, expect
defrun(playwright: Playwright)->None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()# Open new page
page = context.new_page()# Go to https://www.baidu.com/
page.goto("https://www.baidu.com/")# Click input[name="wd"]
page.locator("input[name=\"wd\"]").click()# Fill input[name="wd"]
page.locator("input[name=\"wd\"]").fill("航天员")# Press Enter
page.locator("input[name=\"wd\"]").press("Enter")
page.wait_for_url("https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=%E8%88%AA%E5%A4%A9%E5%91%98&fenlei=256&rsv_pq=0xfde7decb0011bfe6&rsv_t=3a67vLT%2Buti4VKw0mDppSrydbnq6CGsyOVNNxN%2F39naR6lYvxacuqvbYKRs0&rqlang=en&rsv_enter=1&rsv_dl=tb&rsv_sug3=24&rsv_sug1=24&rsv_sug7=100&rsv_sug2=0&rsv_btype=i&prefixsug=%25E8%2588%25AA%25E5%25A4%25A9%25E5%2591%2598&rsp=5&inputT=5824&rsv_sug4=6786&rsv_jmp=fail")# ---------------------
context.close()
browser.close()with sync_playwright()as playwright:
run(playwright)
接下来我们分析一下其生成的代码含义。
from playwright.sync_api import Playwright, sync_playwright
从
playwright.sync_api
模块导入
Playwright
和
sync_playwright
,看到关键字
sync
,可以猜测这是一个同步操作,那与之对应的,也是未来我们要对比学习的,就是异步接口相关内容,这里先埋下一个伏笔,下篇博客在进行讨论。
browser = playwright.chromium.launch(headless=False)
初始化一个谷歌浏览器对象,并且不是无头浏览器,即在桌面打开浏览器窗口。
launch()
方法包含很多参数,常用的有以下内容:
headless:是否为无头浏览器,即是否显示浏览器窗口,默认为不显示;channel:浏览器版本,“chrome”, “chrome-beta”, “chrome-dev”, “chrome-canary”;proxy:代理设置;timeout:超时时间,默认 30s。
context = browser.new_context()
page = context.new_page()
打开一个新浏览器,创建一个新页面,其中
browser.new_context()
的参数都是与浏览器配置相关的内容,实践的时候需要特别设置的在这里设置,例如下述参数:
user_agent:UA 代理;viewport:页面大小,比例,例 1024*768;offline:离线模式加载。
page.goto("https://www.baidu.com/")
page.locator("input[name=\"wd\"]").click()
……
page.wait_for_url(……)
goto():地址跳转,即浏览器跳转;locator():定位元素;wait_for_url():等待页面加载完毕。
本文末尾重点介绍一下
goto()
相关内容,剩余函数下篇博客继续说明。
goto()
函数的重要参数:
url:跳转地址,必须包含协议,例如http://或者https://;referer:请求头中的referer参数;timeout:最大操作时间(毫秒),默认为 30 秒;wait_until:默认操作成功时,执行的内容,还有几个事件,分别是domcontentloaded,networkidle,commit
项目开源地址:https://github.com/microsoft/playwright-python
官方手册:https://playwright.dev/python/docs/intro
📢📢📢📢📢📢
💗 你正在阅读 【梦想橡皮擦】 的博客
👍 阅读完毕,可以点点小手赞一下
🌻 发现错误,直接评论区中指正吧
📆 橡皮擦的第 729 篇原创博客
从订购之日起,案例 5 年内保证更新
- ⭐️ Python 爬虫 120,点击订购 ⭐️
- ⭐️ 爬虫 100 例教程,点击订购 ⭐️
版权归原作者 梦想橡皮擦 所有, 如有侵权,请联系我们删除。