
一、Hadoop简介
Hadoop是一个开源的分布式存储和计算框架,能够处理大规模数据集,并且具有高可靠性和高扩展性。它由Apache软件基金会开发,采用Java编程语言编写,提供了一个可靠、高效的分布式系统基础架构。
二、Hadoop核心组件
- Hadoop分布式文件系统(HDFS):HDFS是Hadoop的核心组件之一,用于存储大规模数据集。它将数据分布式存储在集群的多个节点上,并提供了高容错性。
- Hadoop MapReduce:MapReduce是Hadoop的另一个核心组件,用于并行处理大规模数据集。它将计算任务分成多个步骤(Map和Reduce),并在集群中的多个节点上并行执行。
- YARN:Yet Another Resource Negotiator(YARN)是Hadoop的资源管理器,负责集群资源的分配和调度。它允许多个数据处理框架共享集群资源,提高了集群的利用率。
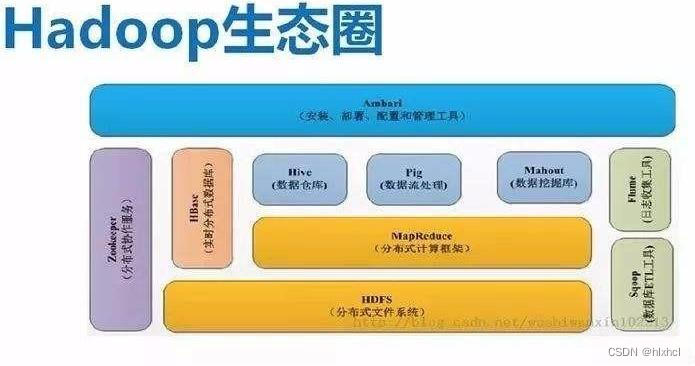
三、Hadoop生态系统
除了核心组件之外,Hadoop还有许多相关项目和工具,构成了一个完整的生态系统,包括但不限于:
- Apache Hive:用于数据仓库查询和分析的数据仓库框架。
- Apache Pig:用于大规模数据分析的高级数据流语言和执行框架。
- Apache HBase:一个分布式、面向列的数据库,用于实时读写大规模数据。
- Apache Spark:一个通用的、基于内存的大规模数据处理引擎,比MapReduce更快。
- Apache Kafka:一个分布式的流数据平台,用于构建实时数据管道和应用程序。
- Apache Flume:用于高可用性、大规模日志数据收集、聚合和传输的分布式系统。
四、hadoop项目实践
下面是一个简单的Hadoop MapReduce示例,用于统计文本文件中每个单词出现的次数。我们将使用Java编写MapReduce作业,并在Hadoop集群上执行。
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
}
WordCountMapper类继承自
org.apache.hadoop.mapreduce.Mapper
,它定义了Map阶段的逻辑。在这个例子中,Mapper的输入键值对类型是
LongWritable
和
Text
,输出键值对类型是
Text
和
IntWritable
。
map方法是Mapper的核心,它接受一行文本作为输入,然后使用StringTokenizer将这一行分割成单词。- 对于每一个单词,它会创建一个键值对,其中键是单词本身(转换为
Text类型),值是常量1(IntWritable类型)。 - 这些键值对会被写入到Context对象中,以便后续的Shuffle和Sort阶段处理。
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
context.write(key, new IntWritable(sum));
}
}
WordCountReducer类继承自
org.apache.hadoop.mapreduce.Reducer
,它定义了Reduce阶段的逻辑。Reduce的输入键值对类型是
Text
和
Iterable<IntWritable>
,输出键值对类型是
Text
和
IntWritable
。
reduce方法是Reducer的核心,它接受一组具有相同键的值。- 遍历这些值,将它们累加起来得到总和。
- 最后,它将这个总和作为一个新的键值对写入到Context对象中,这个键值对的键是单词,值是该单词的总出现次数。
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException ,ClassNotFoundException {
//1.获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2.设置jar路径
job.setJarByClass(WordCountDriver.class);
//3.关联mapper和reducer
job.setMapperClass(WordCountMap.class);
job.setReducerClass(WordCountReduce.class);
//4.设置map输出key,value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5.设置最终输出的key,value的类型
job.setOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//6.设置输入路径和输出路径
// D:\hadoop\hadoop\hadoop\input\inputword.txt
FileInputFormat.setInputPaths(job, new Path(job, new Path("args[0]"));
FileOutputFormat.setOutputPath(job,new Path(job, new Path("args[1]"));
//7.提交job
boolean result =job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
WordCountDriver类是整个作业的驱动程序,它负责设置和运行MapReduce作业。
main方法是入口点,它首先创建一个Configuration对象,然后使用这个对象创建一个Job实例。- 设置了作业的名称、Jar文件的路径、Mapper、Combiner(在本例中与Reducer相同)和Reducer类。
- 还指定了输出键值对的类型。
- 通过
FileInputFormat.addInputPath和FileOutputFormat.setOutputPath方法,它设置了输入和输出的路径。 - 最后,它使用
job.waitForCompletion(true)来提交作业并等待其完成。如果作业成功完成,则退出状态码为0,否则为1。
执行WordCountDrive类,代码运行如下成功即可打包成jar文件 ,同时准备一个txt文件,随便输入几行单词,同时在hdfs上创建input这个文件夹,将txt文件上传到hdfs的input文件上,提交到集群运行,使用cd ..命令回到虚拟机上自己构建的jar包的路径里,输入以下命令:
hadoop jar ./test/syadhsaj.jar com.hadoop.mapreduce.wordcountlinux.WordCountDrive /input /output
./test/syadhsaj.jar替换到自己的路径,com.hadoop.mapreduce.wordcountlinux.WordCountDrive复制自己的WordCountDrive类的全类名。
提交运行后,使用命令hdfs dfs -cat /output查看结果
五、项目实践步骤
- 编写MapReduce作业:编写Mapper、Reducer和Driver类。
- 打包项目:将Java源代码打包成JAR文件。
- 准备输入数据:准备要处理的文本文件,将其上传到HDFS。
- 运行作业:在Hadoop集群上提交MapReduce作业,并监视作业的执行情况。
- 查看结果:查看作业执行完成后生成的输出文件,即单词计数结果。
六、结论
Hadoop MapReduce是一个强大的工具,适用于处理大规模数据集的并行计算任务。它的并行处理能力、容错性设计、灵活性和可扩展性使其成为处理大数据的首选技术之一。然而,开发者需要投入时间和精力去学习和掌握这一技术,以便充分利用其潜力。随着技术的发展,Hadoop MapReduce也在不断进化,与其他新兴技术结合,以满足更多样化的数据处理需求。
版权归原作者 hlxhcl 所有, 如有侵权,请联系我们删除。