
一、概述
Java 8 是一个非常成功的版本,这个版本新增的Stream,配合同版本出现的Lambda ,给我们操作集合(Collection)提供了极大的便利。Stream流是JDK8新增的成员,允许以声明性方式处理数据集合,可以把Stream流看作是遍历数据集合的一个高级迭代器。Stream 是 Java8 中处理集合的关键抽象概念,它可以指定你希望对集合进行的操作,可以执行非常复杂的查找/筛选/过滤、排序、聚合和映射数据等操作。使用Stream API 对集合数据进行操作,就类似于使用 SQL 执行的数据库查询。也可以使用 Stream API 来并行执行操作。简而言之,Stream API 提供了一种高效且易于使用的处理数据的方式。
1、使用流的好处
代码以声明性方式书写,说明想要完成什么,而不是说明如何完成一个操作。
可以把几个基础操作连接起来,来表达复杂的数据处理的流水线,同时保持代码清晰可读。
2、流是什么?
从支持数据处理操作的源生成元素序列.数据源可以是集合,数组或IO资源。
从操作角度来看,流与集合是不同的. 流不存储数据值; 流的目的是处理数据,它是关于算法与计算的。
如果把集合作为流的数据源,创建流时不会导致数据流动; 如果流的终止操作需要值时,流会从集合中获取值; 流只使用一次。
流中心思想是延迟计算,流直到需要时才计算值。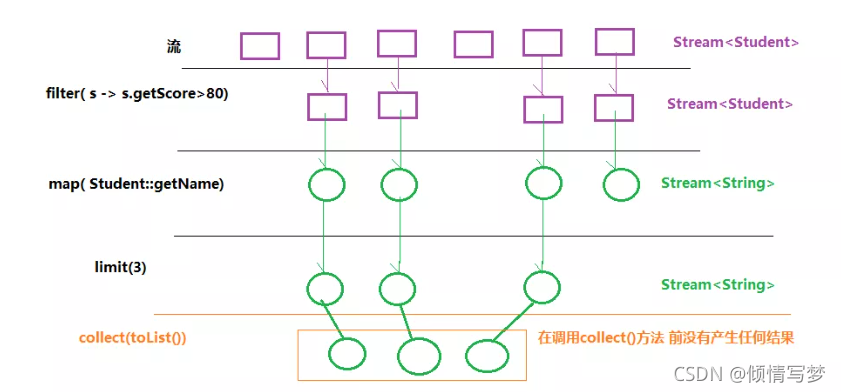
Stream可以由数组或集合创建,对流的操作分为两种:
中间操作,每次返回一个新的流,可以有多个。
终端操作,每个流只能进行一次终端操作,终端操作结束后流无法再次使用。终端操作会产生一个新的集合或值。
特性:
不是数据结构,不会保存数据。
不会修改原来的数据源,它会将操作后的数据保存到另外一个对象中。(保留意见:毕竟peek方法可以修改流中元素)
惰性求值,流在中间处理过程中,只是对操作进行了记录,并不会立即执行,需要等到执行终止操作的时候才会进行实际的计算。
二、分类
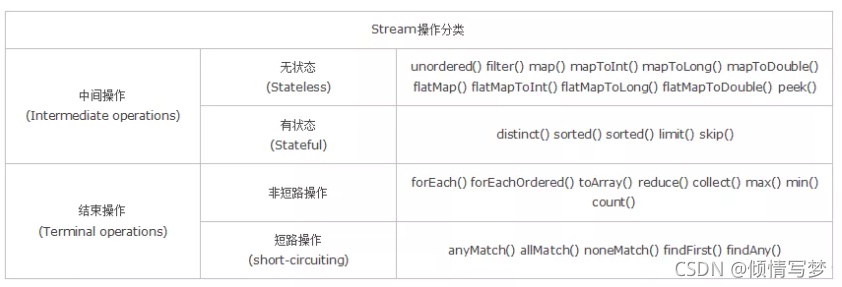
无状态:指元素的处理不受之前元素的影响;
有状态:指该操作只有拿到所有元素之后才能继续下去。
非短路操作:指必须处理所有元素才能得到最终结果;
短路操作:指遇到某些符合条件的元素就可以得到最终结果,如 A || B,只要A为true,则无需判断B的结果。
三、Stream的创建
Stream可以通过集合数组创建。
1、通过 java.util.Collection.stream() 方法用集合创建流
List<String> list = Arrays.asList("a", "b", "c");
// 创建一个顺序流
Stream<String> stream = list.stream();
// 创建一个并行流
Stream<String> parallelStream = list.parallelStream();
2、使用 java.util.Arrays.stream(T[]array)方法用数组创建流
int[]array={1,3,5,6,8};
IntStream stream = Arrays.stream(array);
3、使用 Stream的静态方法:of()、iterate()、generate()
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6);
Stream<Integer> stream2 = Stream.iterate(0, (x) -> x + 3).limit(4);
stream2.forEach(System.out::println);
Stream<Double> stream3 = Stream.generate(Math::random).limit(3);
stream3.forEach(System.out::println);
输出结果:
03690.67961569092719940.19143142088542830.8116932592396652
stream和 parallelStream的简单区分:stream是顺序流,由主线程按顺序对流执行操作,而 parallelStream是并行流,内部以多线程并行执行的方式对流进行操作,但前提是流中的数据处理没有顺序要求。例如筛选集合中的奇数,两者的处理不同之处: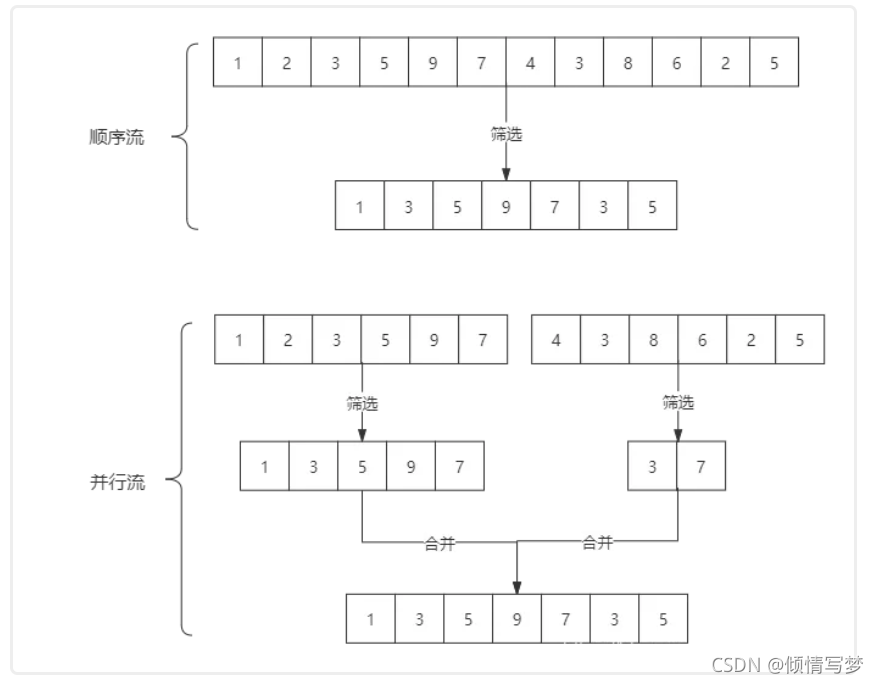
如果流中的数据量足够大,并行流可以加快处速度。
除了直接创建并行流,还可以通过 parallel()把顺序流转换成并行流:
Optional<Integer> findFirst = list.stream().parallel().filter(x->x>6).findFirst();
四、Stream API简介
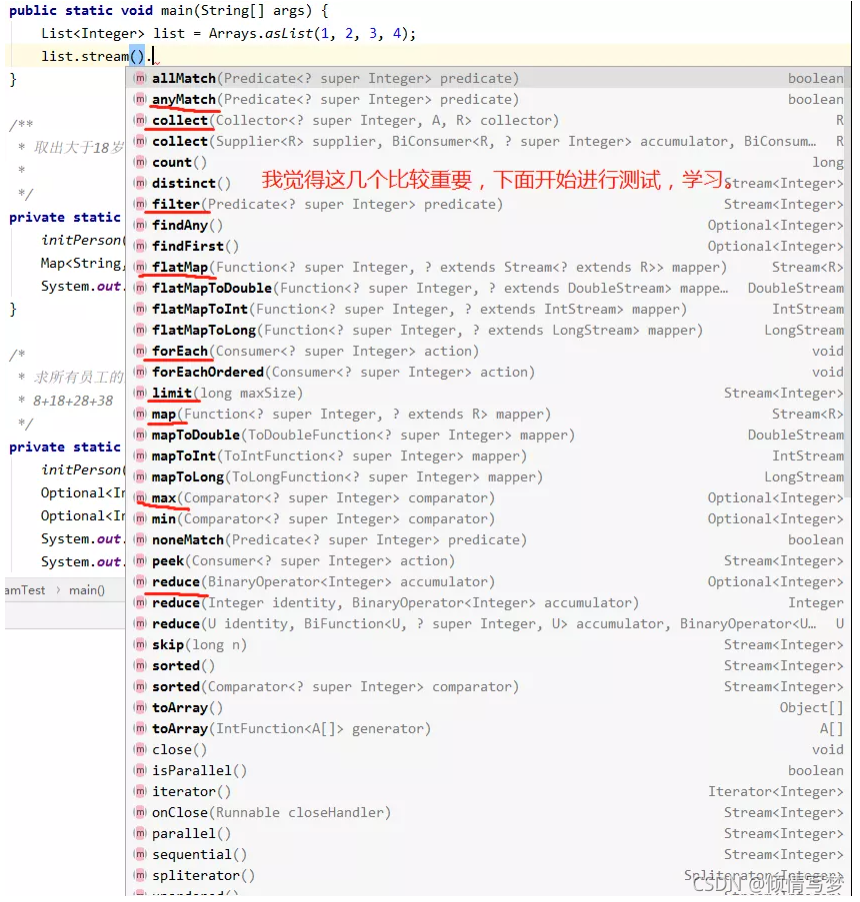
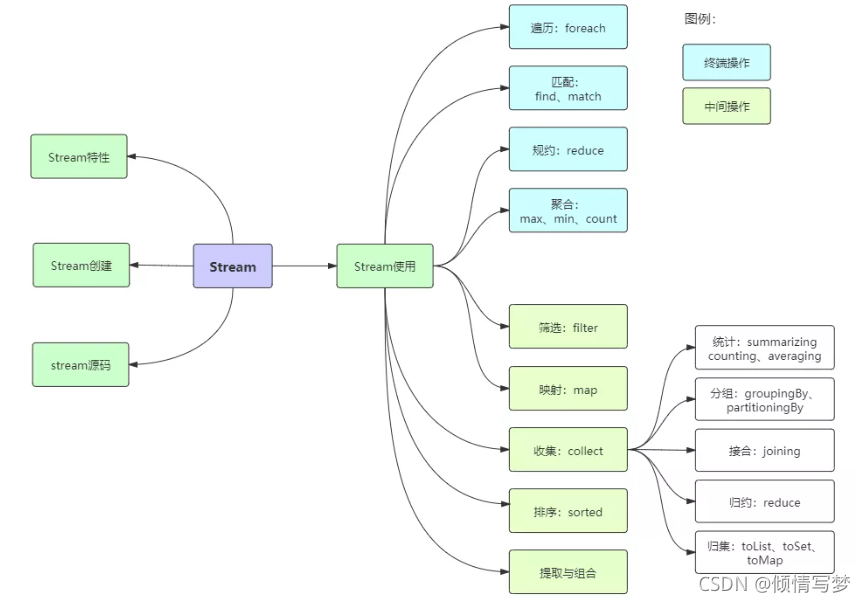
先贴上几个案例,水平高超的同学可以挑战一下:从员工集合中筛选出salary大于8000的员工,并放置到新的集合里。统计员工的最高薪资、平均薪资、薪资之和。将员工按薪资从高到低排序,同样薪资者年龄小者在前。将员工按性别分类,将员工按性别和地区分类,将员工按薪资是否高于8000分为两部分。用传统的迭代处理也不是很难,但代码就显得冗余了,跟Stream相比高下立判。
前提:员工类
static List<Person> personList = new ArrayList<Person>();
private static void initPerson(){
personList.add(new Person("张三", 8, 3000));
personList.add(new Person("李四", 18, 5000));
personList.add(new Person("王五", 28, 7000));
personList.add(new Person("孙六", 38, 9000));}
1、遍历/匹配(foreach/find/match)
Stream也是支持类似集合的遍历和匹配元素的,只是 Stream中的元素是以 Optional类型存在的。Stream的遍历、匹配非常简单。
// import已省略,请自行添加,后面代码亦是
public class StreamTest {
public static void main(String[] args){
List<Integer> list = Arrays.asList(7, 6, 9, 3, 8, 2, 1);
// 遍历输出符合条件的元素
list.stream().filter(x -> x >6).forEach(System.out::println);
// 匹配第一个
Optional<Integer> findFirst = list.stream().filter(x -> x >6).findFirst();
// 匹配任意(适用于并行流)
Optional<Integer> findAny = list.parallelStream().filter(x -> x >6).findAny();
// 是否包含符合特定条件的元素
boolean anyMatch = list.stream().anyMatch(x -> x <6);
System.out.println("匹配第一个值:" + findFirst.get());
System.out.println("匹配任意一个值:" + findAny.get());
System.out.println("是否存在大于6的值:" + anyMatch);}}
2、按条件匹配filter
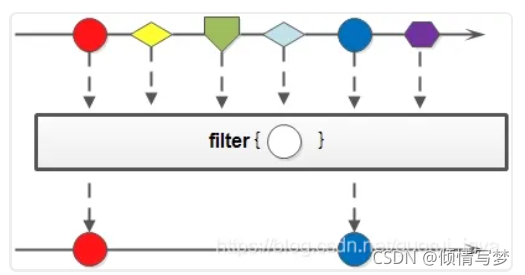
(1)筛选员工中已满18周岁的人,并形成新的集合
/**
* 筛选员工中已满18周岁的人,并形成新的集合
* @思路
* List<Person> list = new ArrayList<Person>();
* for(Person person : personList){
* if(person.getAge()>=18){
* list.add(person);
* }
* }
*/
private static void filter01(){
initPerson();
List<Person> collect = personList.stream().filter(x -> x.getAge()>=18).collect(Collectors.toList());
System.out.println(collect);}

(2)自定义条件匹配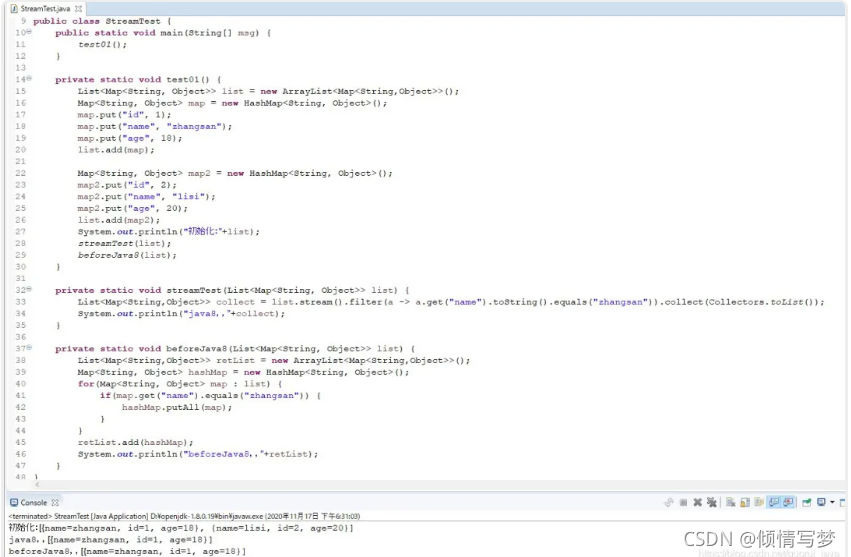
3、聚合max、min、count
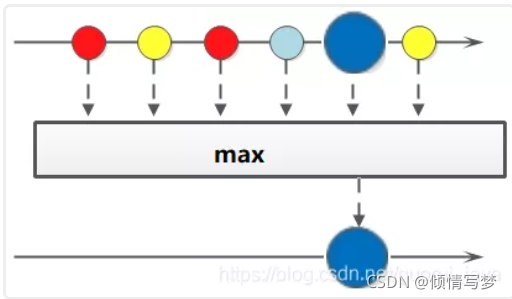
(1)获取String集合中最长的元素
/**
* 获取String集合中最长的元素
* @思路
* List<String> list = Arrays.asList("zhangsan", "lisi", "wangwu", "sunliu");
* String max ="";
* int length =0;
* int tempLength =0;
* for(String str : list){
* tempLength = str.length();
* if(tempLength > length){
* length = str.length();
* max = str;
* }
* }
* @return zhangsan
*/
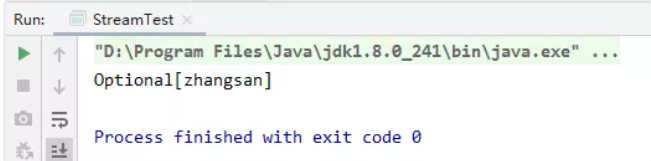
private static void test02(){
List<String> list = Arrays.asList("zhangsan", "lisi", "wangwu", "sunliu");
Comparator<? super String> comparator = Comparator.comparing(String::length);
Optional<String> max = list.stream().max(comparator);
System.out.println(max);}
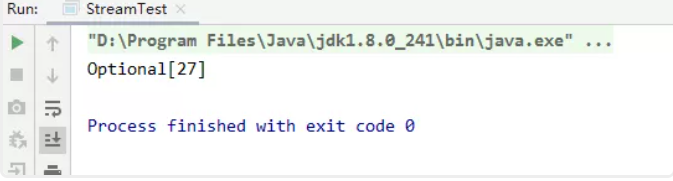
(2)获取Integer集合中的最大值
//获取Integer集合中的最大值
private static void test05(){
List<Integer> list = Arrays.asList(1, 17, 27, 7);
Optional<Integer> max = list.stream().max(Integer::compareTo);
// 自定义排序
Optional<Integer> max2 = list.stream().max(new Comparator<Integer>(){
@Override
public int compare(Integer o1, Integer o2){return o1.compareTo(o2);}});
System.out.println(max2);}
//获取员工中年龄最大的人
private static void test06(){
initPerson();
Comparator<? super Person> comparator = Comparator.comparingInt(Person::getAge);
Optional<Person> max = personList.stream().max(comparator);
System.out.println(max);}
(3)获取员工中年龄最大的人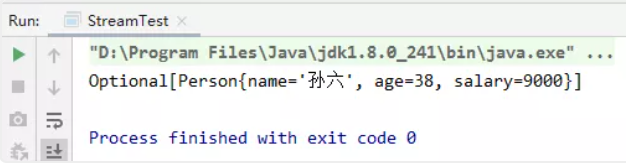
(4)计算integer集合中大于10的元素的个数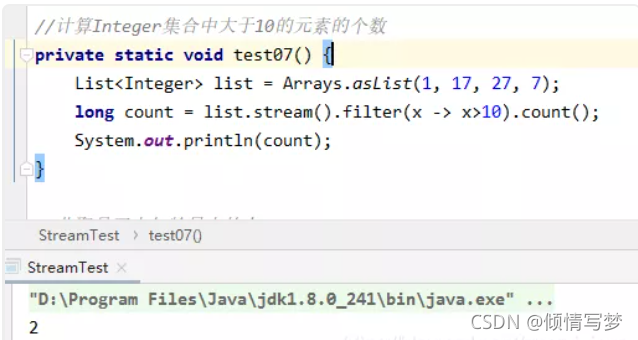
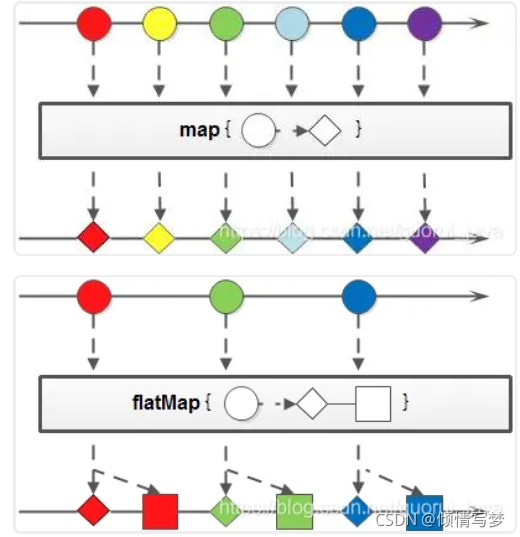
4、map与flatMap
map:接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。
flatMap:接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
(1)字符串大写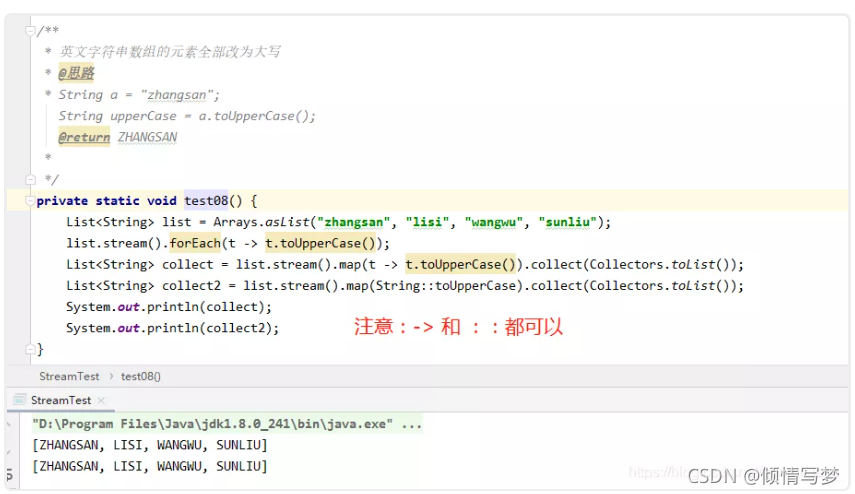
(2)整数数组每个元素+3
/**
* 整数数组每个元素+3
* @思路
* List<Integer> list = Arrays.asList(1, 17, 27, 7);
List<Integer> list2 = new ArrayList<Integer>();
for(Integer num : list){
list2.add(num + 3);}
@return [4, 20, 30, 10]
*/
private static void test09(){
List<Integer> list = Arrays.asList(1, 17, 27, 7);
List<Integer> collect = list.stream().map(x -> x + 3).collect(Collectors.toList());
System.out.println(collect);}
(3)公司效益好,每人涨2000
/**
* 公司效益好,每人涨2000
*
*/
private static void test10(){
initPerson();
List<Person> collect = personList.stream().map(x ->{
x.setAge(x.getSalary()+2000);return x;}).collect(Collectors.toList());
System.out.println(collect);}
(4)将两个字符数组合并成一个新的字符数组
/**
* 将两个字符数组合并成一个新的字符数组
*
*/
private static void test11(){
String[] arr ={"z, h, a, n, g", "s, a, n"};
List<String> list = Arrays.asList(arr);
System.out.println(list);
List<String> collect = list.stream().flatMap(x ->{
String[] array = x.split(",");
Stream<String> stream = Arrays.stream(array);return stream;}).collect(Collectors.toList());
System.out.println(collect);}
(5)将两个字符数组合并成一个新的字符数组
/**
* 将两个字符数组合并成一个新的字符数组
* @return [z, h, a, n, g, s, a, n]
*/
private static void test11(){
String[] arr ={"z, h, a, n, g", "s, a, n"};
List<String> list = Arrays.asList(arr);
List<String> collect = list.stream().flatMap(x ->{
String[] array = x.split(",");
Stream<String> stream = Arrays.stream(array);return stream;}).collect(Collectors.toList());
System.out.println(collect);}
5、规约reduce
归约,也称缩减,顾名思义,是把一个流缩减成一个值,能实现对集合求和、求乘积和求最值操作。
(1)求Integer集合的元素之和、乘积和最大值
/**
* 求Integer集合的元素之和、乘积和最大值
*
*/
private static void test13(){
List<Integer> list = Arrays.asList(1, 2, 3, 4);
//求和
Optional<Integer> reduce = list.stream().reduce((x,y) -> x+ y);
System.out.println("求和:"+reduce);
//求积
Optional<Integer> reduce2 = list.stream().reduce((x,y) -> x * y);
System.out.println("求积:"+reduce2);
//求最大值
Optional<Integer> reduce3 = list.stream().reduce((x,y) -> x>y?x:y);
System.out.println("求最大值:"+reduce3);}
(2)求所有员工的工资之和和最高工资
/*
* 求所有员工的工资之和和最高工资
*/
private static void test14(){
initPerson();
Optional<Integer> reduce = personList.stream().map(Person :: getSalary).reduce(Integer::sum);
Optional<Integer> reduce2 = personList.stream().map(Person :: getSalary).reduce(Integer::max);
System.out.println("工资之和:"+reduce);
System.out.println("最高工资:"+reduce2);}
6、收集(toList、toSet、toMap)
取出大于18岁的员工转为map
/**
* 取出大于18岁的员工转为map
*
*/
private static void test15(){
initPerson();
Map<String, Person> collect = personList.stream().filter(x -> x.getAge()>18).collect(Collectors.toMap(Person::getName, y -> y));
System.out.println(collect);}
7、collect
Collectors提供了一系列用于数据统计的静态方法:
计数: count
平均值: averagingInt、 averagingLong、 averagingDouble
最值: maxBy、 minBy
求和: summingInt、 summingLong、 summingDouble
统计以上所有: summarizingInt、 summarizingLong、 summarizingDouble
/**
* 统计员工人数、平均工资、工资总额、最高工资
*/
private static void test01(){
//统计员工人数
Long count = personList.stream().collect(Collectors.counting());
//求平均工资
Double average = personList.stream().collect(Collectors.averagingDouble(Person::getSalary));
//求最高工资
Optional<Integer> max = personList.stream().map(Person::getSalary).collect(Collectors.maxBy(Integer::compare));
//求工资之和
Integer sum= personList.stream().collect(Collectors.summingInt(Person::getSalary));
//一次性统计所有信息
DoubleSummaryStatistics collect = personList.stream().collect(Collectors.summarizingDouble(Person::getSalary));
System.out.println("统计员工人数:"+count);
System.out.println("求平均工资:"+average);
System.out.println("求最高工资:"+max);
System.out.println("求工资之和:"+sum);
System.out.println("一次性统计所有信息:"+collect);}
8、分组(partitioningBy/groupingBy)
分区:将stream按条件分为两个 Map,比如员工按薪资是否高于8000分为两部分。
分组:将集合分为多个Map,比如员工按性别分组。有单级分组和多级分组。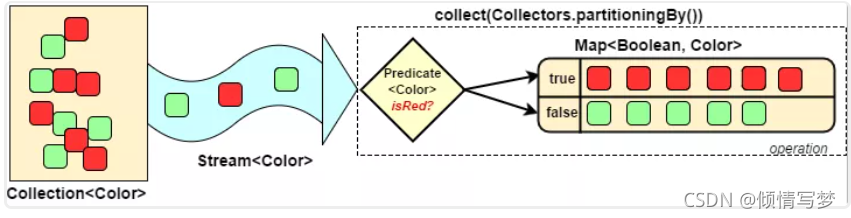
将员工按薪资是否高于8000分为两部分;将员工按性别和地区分组
public class StreamTest {
public static void main(String[] args){
personList.add(new Person("zhangsan",25, 3000, "male", "tieling"));
personList.add(new Person("lisi",27, 5000, "male", "tieling"));
personList.add(new Person("wangwu",29, 7000, "female", "tieling"));
personList.add(new Person("sunliu",26, 3000, "female", "dalian"));
personList.add(new Person("yinqi",27, 5000, "male", "dalian"));
personList.add(new Person("guba",21, 7000, "female", "dalian"));
// 将员工按薪资是否高于8000分组
Map<Boolean, List<Person>> part = personList.stream().collect(Collectors.partitioningBy(x -> x.getSalary()>8000));
// 将员工按性别分组
Map<String, List<Person>> group = personList.stream().collect(Collectors.groupingBy(Person::getSex));
// 将员工先按性别分组,再按地区分组
Map<String, Map<String, List<Person>>> group2 = personList.stream().collect(Collectors.groupingBy(Person::getSex, Collectors.groupingBy(Person::getArea)));
System.out.println("员工按薪资是否大于8000分组情况:" + part);
System.out.println("员工按性别分组情况:" + group);
System.out.println("员工按性别、地区:" + group2);}}
9、连接joining
joining可以将stream中的元素用特定的连接符(没有的话,则直接连接)连接成一个字符串。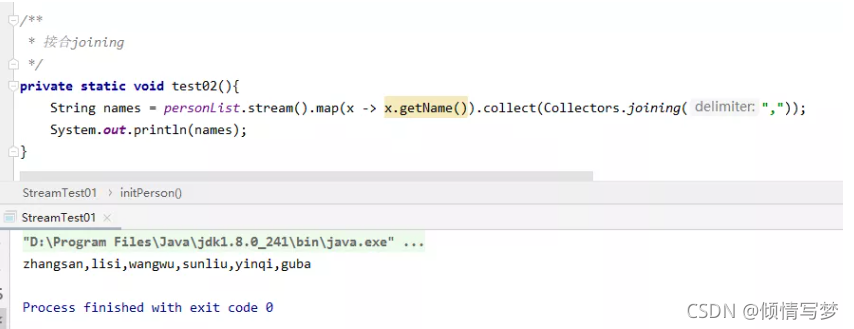
10、排序sorted
将员工按工资由高到低(工资一样则按年龄由大到小)排序
private static void test04(){
// 按工资升序排序(自然排序)
List<String> newList = personList.stream().sorted(Comparator.comparing(Person::getSalary)).map(Person::getName)
.collect(Collectors.toList());
// 按工资倒序排序
List<String> newList2 = personList.stream().sorted(Comparator.comparing(Person::getSalary).reversed())
.map(Person::getName).collect(Collectors.toList());
// 先按工资再按年龄升序排序
List<String> newList3 = personList.stream()
.sorted(Comparator.comparing(Person::getSalary).thenComparing(Person::getAge)).map(Person::getName)
.collect(Collectors.toList());
// 先按工资再按年龄自定义排序(降序)
List<String> newList4 = personList.stream().sorted((p1, p2)-> {
if (p1.getSalary()== p2.getSalary()){return p2.getAge() - p1.getAge();}else{return p2.getSalary() - p1.getSalary();}}).map(Person::getName).collect(Collectors.toList());
System.out.println("按工资升序排序:" + newList);
System.out.println("按工资降序排序:" + newList2);
System.out.println("先按工资再按年龄升序排序:" + newList3);
System.out.println("先按工资再按年龄自定义降序排序:" + newList4);}
11、提取/组合
流也可以进行合并、去重、限制、跳过等操作。
private static void test05(){
String[] arr1 ={"a", "b", "c", "d"};
String[] arr2 ={"d", "e", "f", "g"};
Stream<String> stream1 = Stream.of(arr1);
Stream<String> stream2 = Stream.of(arr2);
// concat:合并两个流 distinct:去重
List<String> newList = Stream.concat(stream1, stream2).distinct().collect(Collectors.toList());
// limit:限制从流中获得前n个数据
List<Integer> collect = Stream.iterate(1, x -> x + 2).limit(10).collect(Collectors.toList());
// skip:跳过前n个数据
List<Integer> collect2 = Stream.iterate(1, x -> x + 2).skip(1).limit(5).collect(Collectors.toList());
System.out.println("流合并:" + newList);
System.out.println("limit:" + collect);
System.out.println("skip:" + collect2);}
12、读取文件的流操作
13、计算两个list中的差集
//计算两个list中的差集
List<String> reduce1 = allList.stream().filter(item ->!wList.contains(item)).collect(Collectors.toList());
版权归原作者 大梦谁先觉i 所有, 如有侵权,请联系我们删除。