

大家好,我是每天分享AI应用的萤火君!
Flux横空出世有段时间了,模型效果也得到了广泛的认可,但是 Stable Diffusion WebUI 官方迟迟没有跟进,据说是因为要修改很多底层的处理机制,加之ComfyUI如火如荼,可能越南大佬的心气也不是很高,选择了躺平,又或者是在秘密的憋大招。
不过在开源的AI绘画界还有另一个大佬,那就是 ControlNet 的作者张吕敏,他搞了一个SD WebUI的衍生版:Stable Diffusion WebUI Forge。Flux发布没多久,Forge就开始了相关的支持工作,虽然目前还有很多特性没有得到支持(这也间接说明WebUI支持Flux的改造难度确实很大),比如ControlNet,但是基本的文生图和图生图已经没有什么问题了,喜欢WebUI的同学可以体验下了。
使用方法
我这里截了一张在Forge中使用Flux生图的操作过程,大家可以有个基本的认识。
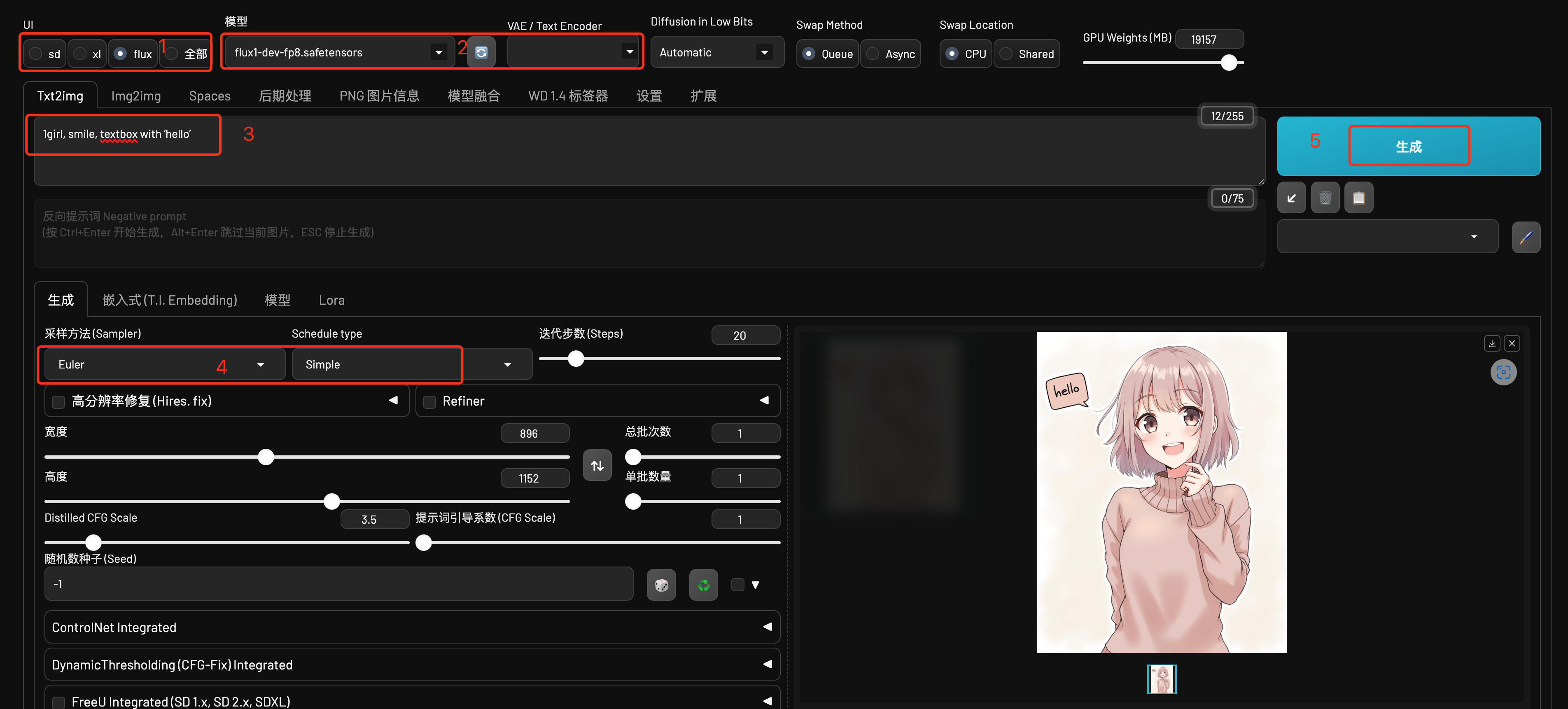
下面分步介绍下:
1、UI
选择Flux。选择不同的UI,下边的一些选项会有所变化,比如宽度和高度、提示词引导系数的默认值等等。
2、模型和VAE/Text Encoder
这里演示用的Flux基础模型自带VAE(潜空间编解码器)和Text Encoder(文本提示词编码器),所以不需要选择VAE/Text Encoder;如果你使用的Flux模型是单独的unet模型,则需要选择VAE和Text Encoder。
Forge支持的Flux基础模型一般有这几种:
- flux1-dev-bnb-nf4-v2.safetensors 张吕敏大佬搞的unet量化模型。
- flux1-dev-fp8_unet.safetensors 只包含unet模型。
- flux1-dev-fp8.safetensors 包含unet、vae和text encoder模型。
这几个模型需要放到 Forge 模型目录的基础模型子目录下。
Forge需要的VAE和Text Encoder模型包括:
- ae.safetensors Flux使用的VAE模型;
- clip_l.safetensors 相对传统的文本提示词编码器模型;
- t5xxl_fp16.safetensors 比较新的文本提示词编码器模型,使用自然语言。
这几个模型需要放到 Forge 模型目录的 vae 子目录下。
这里给出一些模型的搭配组合:

- flux1-dev-fp8.safetensors
- flux1-dev-fp8_unet.safetensors + ae.safetensors + clip_l.safetensors + t5xxl_fp16.safetensors
- flux1-dev-bnb-nf4-v2.safetensors + ae.safetensors + clip_l.safetensors + t5xxl_fp16.safetensors(可选)
3、提示词
只需要正向提示词,Flux目前开放的模型不支持反向提示词。这里演示用的是:
1girl, black hair, smile, a textbox with 'hello'
4、采样方法和调度器
不是所有的采样方法和调度器都支持Flux。
采样方法我测试了这几个是可以的:
- DPM++ 2M
- Euler
- DPM2
- [Forge] Flux Realistic(速度快,推荐)
调度器(Schedule type)选择 :Simple、Normal或者SGM Uniform都可以。
5、生成
最后点击生成就可以了,根据机器系统不同,需要的时间会有所差别。
首次生图需要加载模型,可能需要的时间更长一些。
6、其它参数
这里边还有一些其它参数:
- 宽度和高度:可以根据自己的需要进行调整,Flux模型支持的尺寸可以覆盖SD1.5和SDXL支持的尺寸。
- 迭代步数:20-30
- 总批次数:一共生成几次。可以连续生成多次,选择其中最好看的,俗称抽卡。
- 单批数量:每次生成几张图片,比较消耗显存,显存大的话可以设置的多点。
- Distilled CFG Scale 和 提示词引导系数:这两个都不能设置的很大,默认就可以了,绝大部分情况下不需要调整。
- 随机数种子:每次生成都是用不同的随机数,图片会更加多样化。
环境配置
量化之后的Flux模型需要的显存大幅降低,12G显存就能跑起来。
不过要想实现更好的效果,还得是尽量选择损失比较小的模型。演示用的 flux1-dev-fp8 在资源和质量之间取得了一个平衡,推荐大家使用。
本地部署
Stable Diffusion WebUI Forge 提供了一个一键安装包:
下载后需要解压,然后进入解压出的文件夹,双击执行
update.bat
,将程序升级到最新版本,最后双击执行
run.bat
,启动程序。
其它模型还需要自己手动下载,放到相应的目录中。
具体说明可以看官方文档:
https://github.com/lllyasviel/stable-diffusion-webui-forge?tab=readme-ov-file#installing-forge
云环境体验
我在 AutoDL 的 SD WebUI Forge 镜像已经升级到最新版本,一键启动,即可快速体验Flux生成图片。
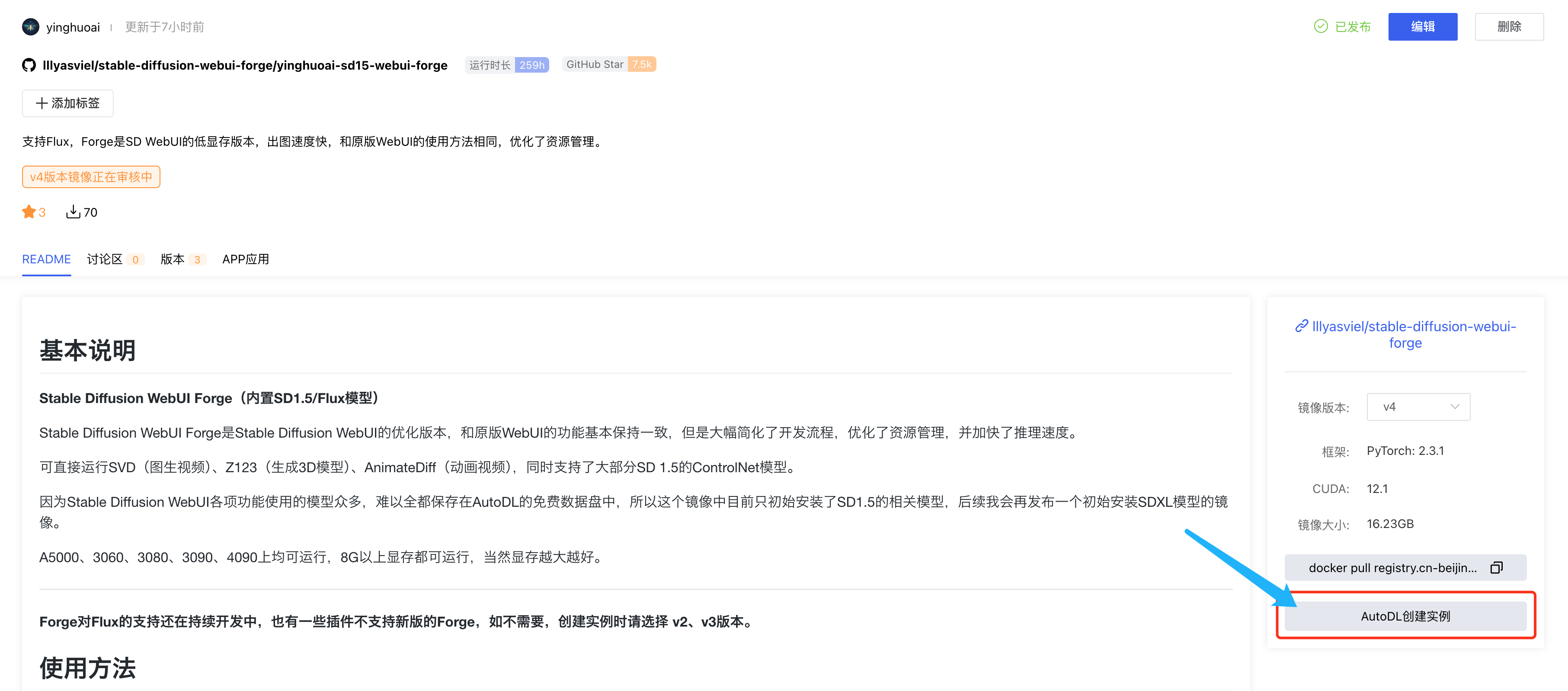
实例创建方法1
镜像地址:https://www.codewithgpu.com/i/lllyasviel/stable-diffusion-webui-forge/yinghuoai-sd15-webui-forge
点击页面右下角的“AutoDL 创建实例”即可。
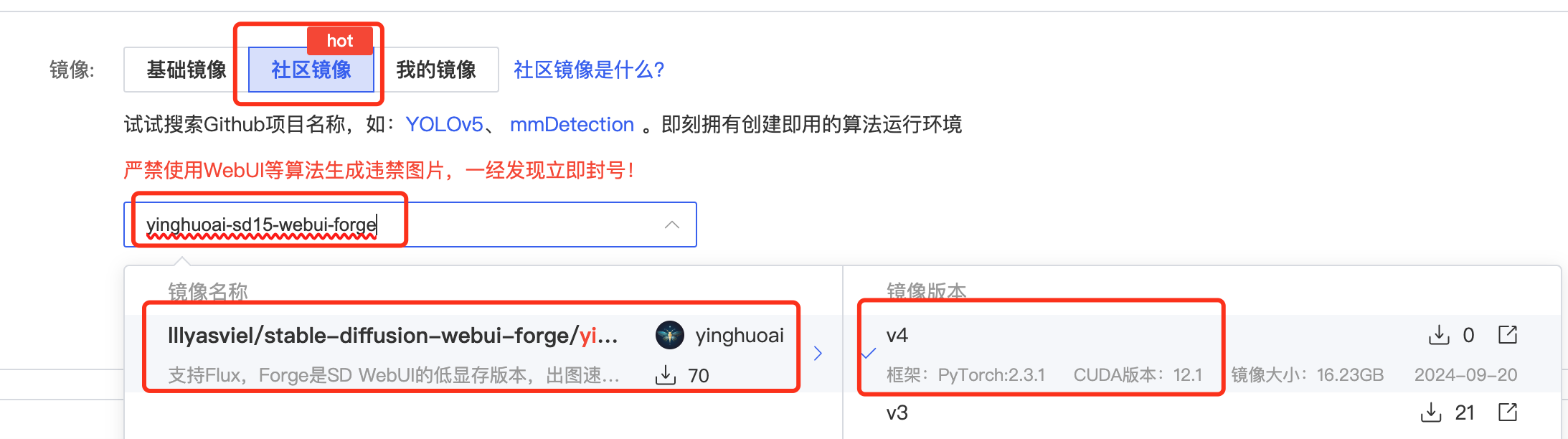
实例创建方法2
直接租用新实例:https://www.autodl.com/create
镜像选择“社区镜像”->“yinghuoai-sd15-webui-forge”。
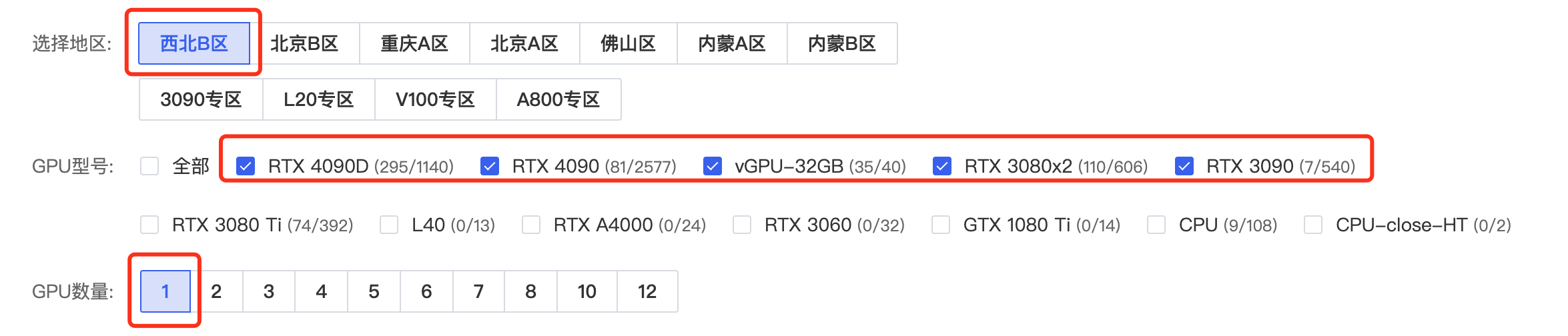
显卡选择
显卡最好选择20G显存以上的,3090或者4090最佳,1卡即可,首选“西北B区”,网络稳定,如下图所示:
启动Forge程序
首先通过容器实例进入 JupyterLab 交互管理界面:

然后在其中的“Flux-启动器”中启动程序:
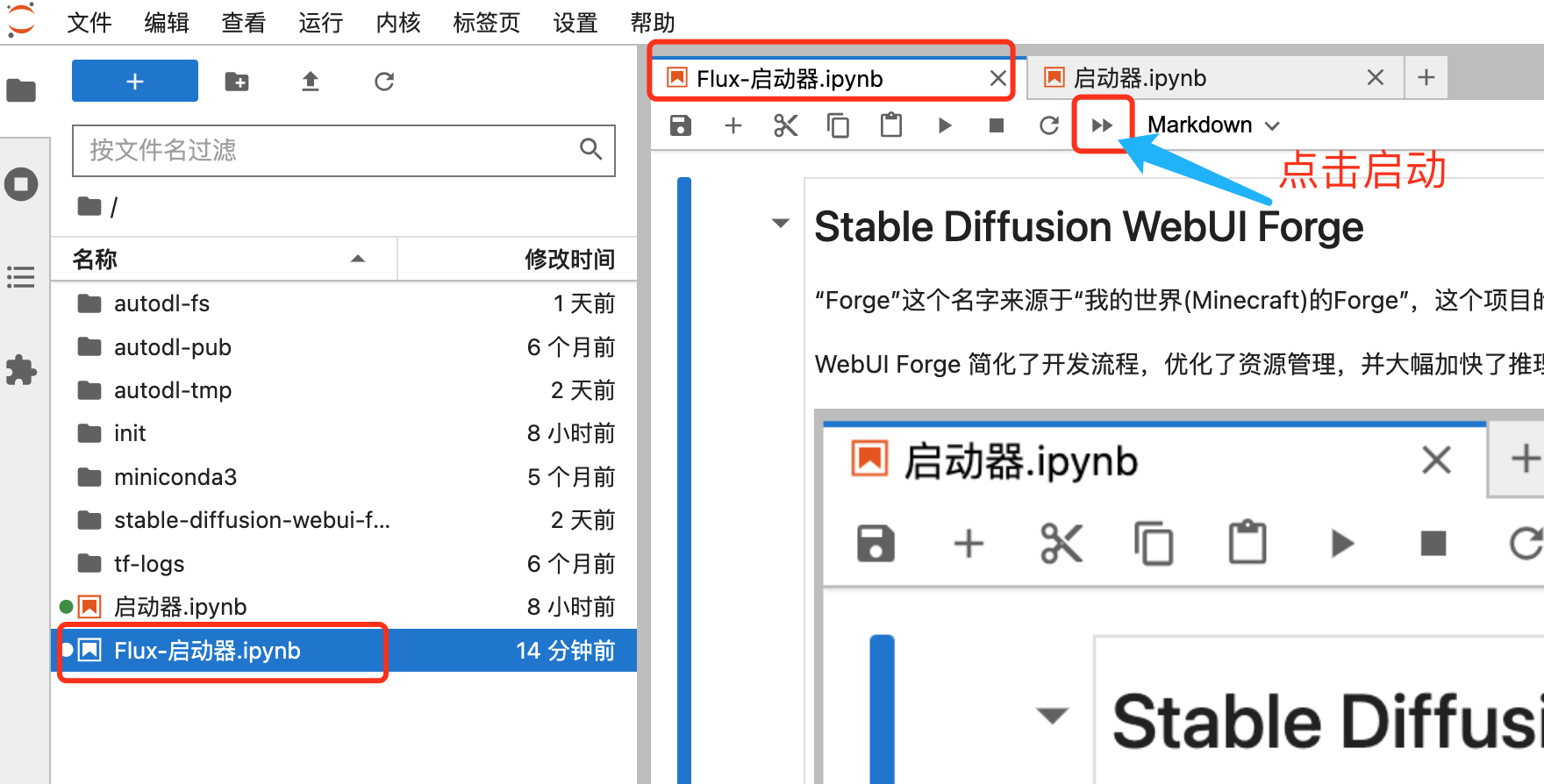
待页面展示,http://127.0.0.1:6006,代表启动成功。

回到容器实例列表页面,点击“自定义服务”,即可在浏览器打开 SD WebUI Forge:

资源下载
文章中使用的Flux模型和程序,都已经上传到我整理的 Stable Diffusion 绘画资源中,最新下载地址可给公/众\号 “萤火遛AI” 发消息 “Flux”,即可获取。
另外我创建了一个AI绘画专栏,更多的工作流、模型等资源会发布在这个专栏中。加入专栏,还可以零门槛,全面系统的学习 SD WebUI 和 ComfyUI 的创作,让灵感轻松落地!如有需要请点击链接或下方扫码进入:https://xiaobot.net/post/03340243-9df6-4ea0-bad6-9911a5034bd6
以上就是本文的主要内容,如有问题,欢迎留言!
版权归原作者 萤火架构 所有, 如有侵权,请联系我们删除。