
一.项目概览
电商的防止薅羊毛的风控系统
需要使用 groovy 进行风控规则引擎的编写 然后其它技术进行各种数据的 存储及处理

薅羊毛大致流程

如果单纯使用 if else在业务代码中进行风控规则的编写 那么 维护起来会比较麻烦 并且跟业务系统强绑定不合适 所以一般独立成一个单独的系统
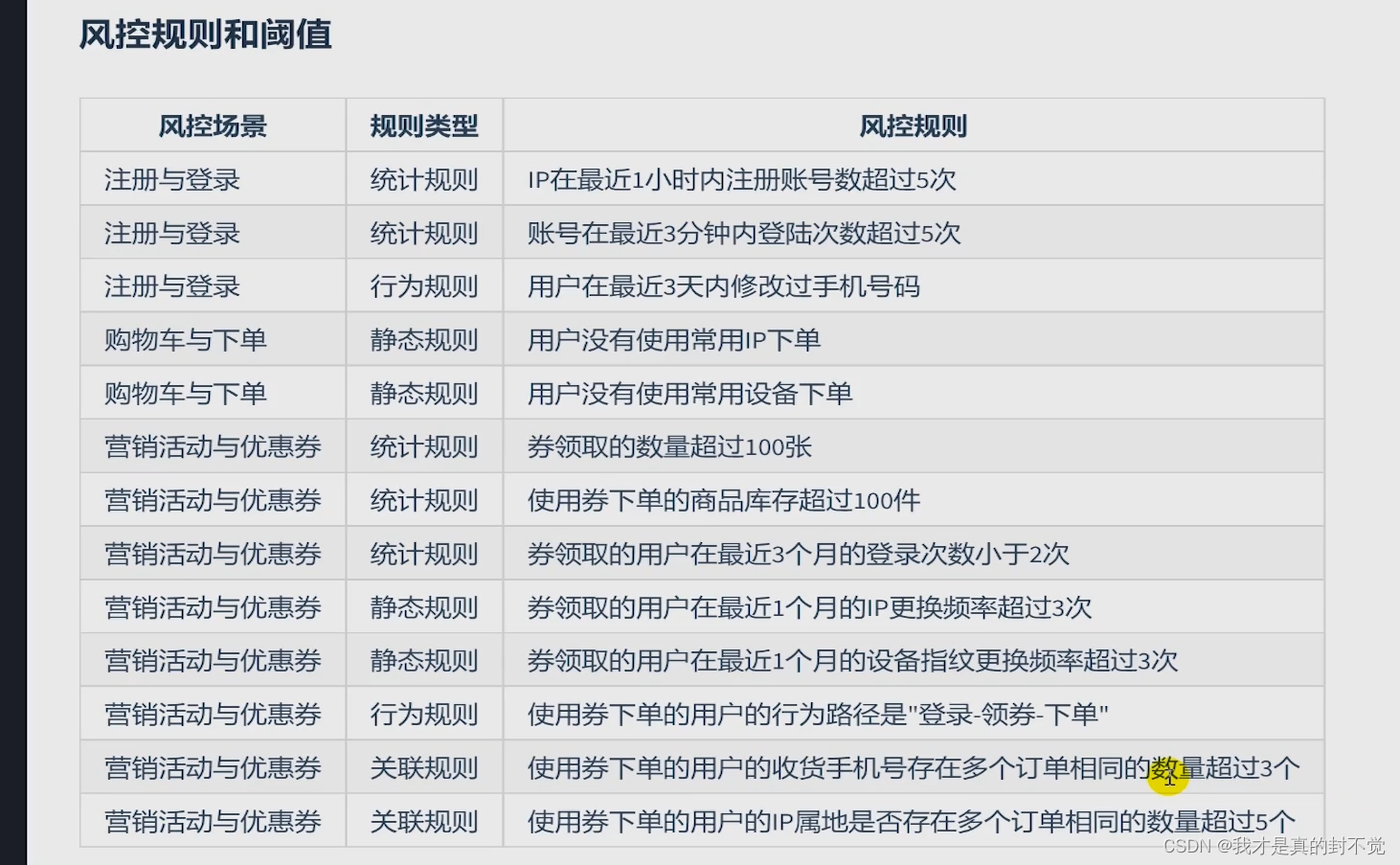
常见风控规则列举

风控引擎设计的核心点
业务逻辑概览

事件接入中心


技术架构

分层

各单位占比

二.flink常见知识点实战
从下图可以看出 跟之前yarn类似 还是有管理 有大领导 校领导 打工人 打工人来执行任务
分别对应 jobmamager taskmanager taskslot 由 taskslot 执行任务 每个

2.1state

实战
首先看个入门级代码 就是对 字符串的出现次数的结果进行实时统计与打印
package com.juege.hope.opentech.flinktest;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class FlinkTurotial1_17 {
public static void main(String[] args) throws Exception {
//todo 1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//todo 2.读取数据
DataStreamSource<String> stringDataStreamSource = env.readTextFile("D:\\juege\\code\\hope-backend\\opentech\\src\\main\\resources\\flinkTextSource.txt");
//todo 3.进行数据处理 先 flatmap 再 keyby 再 sum 再打印输出
stringDataStreamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = s.split(" ");
for (String word : words) {
collector.collect(new Tuple2<>(word, 1));
}
}
}).keyBy(0).sum(1).print();
//todo 4.执行任务
env.execute("pantouyu");
}
}
数据源
显示结果如下
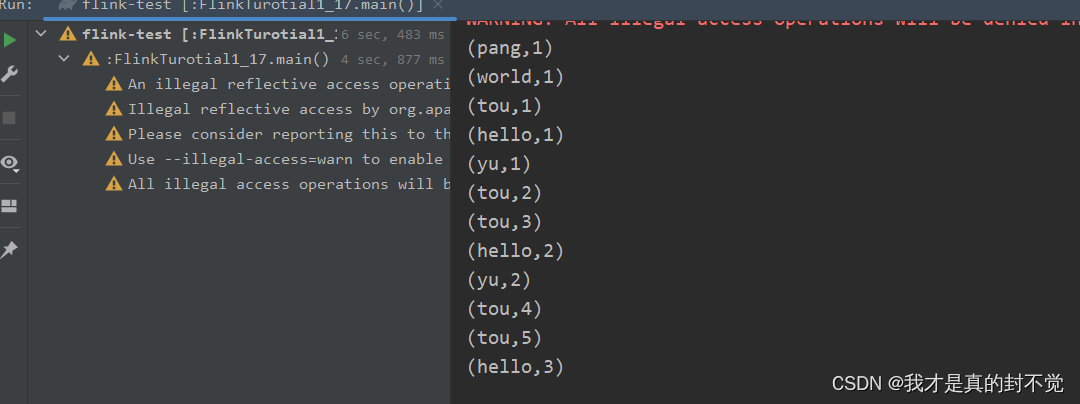
使用state来实现sum方法的效果
package com.example.flinktest.test;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class FlinkTurotial1_17 {
public static void main(String[] args) throws Exception {
//todo 1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//todo 2.读取数据
DataStreamSource<String> stringDataStreamSource = env.readTextFile("D:\\juege\\code\\flink-test\\src\\main\\resources\\flinkTextSource.txt");
//todo 3.进行数据处理 先 flatmap 再 keyby 再 sum 再打印输出
stringDataStreamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = s.split(" ");
for (String word : words) {
collector.collect(new Tuple2<>(word, 1));
}
}
}).keyBy(0)
.flatMap(new SumFunction()).print();
// .sum(1).print();
//todo 4.执行任务
env.execute("pantouyu");
}
}
package com.example.flinktest.test;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.util.Collector;
public class SumFunction extends RichFlatMapFunction<Tuple2<String, Integer>, Tuple2<String, Integer>> {
private transient ValueState<Integer> sumState;
@Override
public void open(Configuration parameters) throws Exception {
ValueStateDescriptor<Integer> descriptor = new ValueStateDescriptor<>("sumState", Integer.class);
sumState = getRuntimeContext().getState(descriptor);
}
@Override
public void flatMap(Tuple2<String, Integer> value, Collector<Tuple2<String, Integer>> out) throws Exception {
String key = value.f0;
Integer inputValue = value.f1;
Integer currentSum = sumState.value();
if (currentSum == null) {
currentSum = 0;
}
currentSum += inputValue;
sumState.update(currentSum);
out.collect(new Tuple2<>(key, currentSum));
}
}
2.2时间,窗口,水印
窗口


全局窗口
根据数据条数触发计算 比如如下就是 每来五条计算一次 并且并行度 等于1
滚动窗口
根据固定时间确定一个个窗口来触发计算 如下为10分钟
滑动窗口
根据固定时间确定一个窗口 然后间隔一定的时间触发窗口的计算
比如如下为 10分钟一个窗口 然后间隔时间为 1分钟那么 第一次计算的窗口
时间为 0-10分钟这个窗口内的数据 第二次 为 1-11分钟这个窗口内的数据 以此类推

时间


水印
水位线是个动态值 水印 = 当前窗口最大事件事件-允许延迟事件
当系统中以提取事件或者处理时间为准时不需要水印, 以事件事件为准时才需要水印 水印在国内又被称作水位线 在我们后面解决数据延迟问题时比较重要 这里先看下 不懂也没关系


2.3 窗口 时间 水印综合运用 解决数据延迟问题案例
如下图 左侧有个窗口 数据从上往下先后来了三条数据
首先 水印/水位线 = 当前窗口最大事件事件-允许延迟事件
当水位线 >= 窗口时间时 就触发计算
以下说的除了窗口时间外都是事件事件 也就是 数据上携带的时间戳
举个例子 当前 窗口时间为10分钟 但是有一条本应该9分钟到的数据 12分钟才到 那么你可以设置
允许延迟的时间为 2分钟 那么 当12分钟那条数据到的时候,通过公式计算
水位线 = 12-2 = 10>10(窗口时间) 那么这个时候刚好可以触发计算 12分钟到的那条数据也被包含在了这个窗口

2.4CEP
复杂事件找共性处理

2.5并行度,任务,子任务
并行度
首先并行就是并发执行 前面我们说到了 一个taskmanager对应一个jvm进程,一个taskmanager中又有多个slot那么 一个slot就对应一个并行度,如果我们现在有两个jobmanager 每个jobmanager下有两个taskmanger 然后 每个taskmanager下面有三个slot 那么 这个flink app支持设置的最大并行度为多少呢 支持的最大并行度 = jobmanager数量* taskmanager数量slot数量 =slot总数=22*3=12 那么 这个时候我如果设置 并行度为 10,那么就会有俩slot空闲 如果设置为12那就刚好
如果设置为14那么启动报错 因为我们计算结果支持的最大并行度为12
任务及子任务
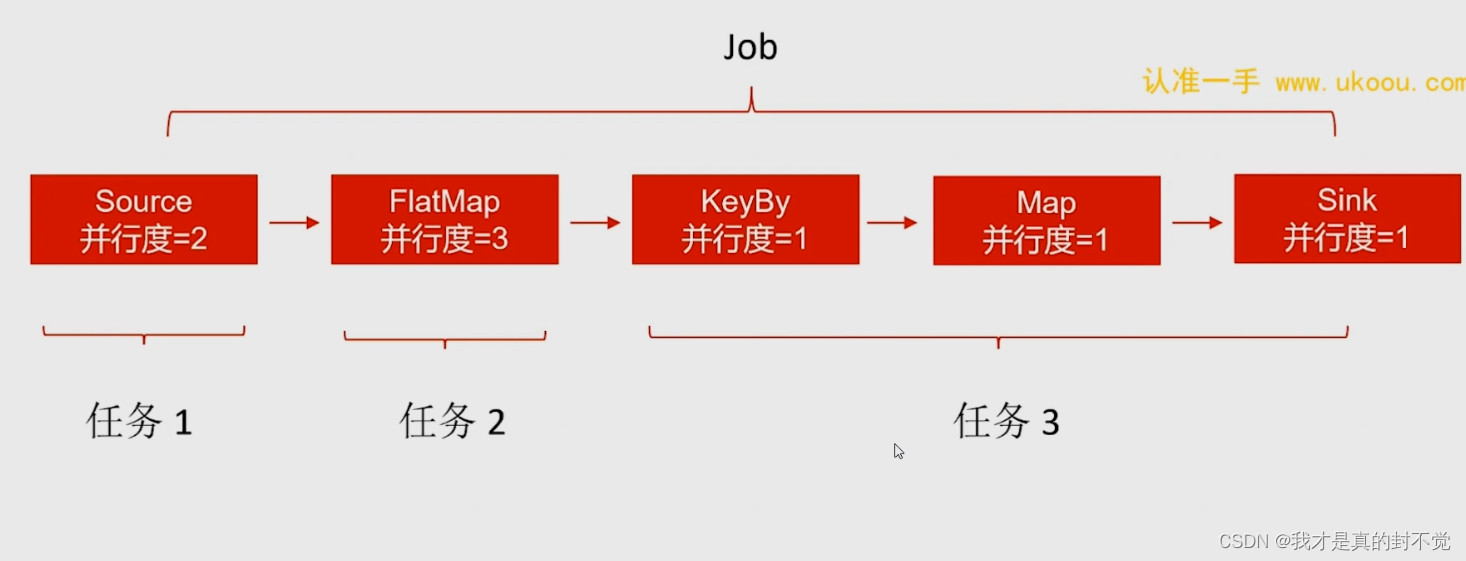
通过以下这句话 判断下一张图片中任务及子任务数

首先source为第一个任务 他的并行度为2 所以有俩子任务
然后flatmap的并行度是3 按上图所说 并行度相对于前一个任务发生了变化 无法合并 所以
flatmap是第二个任务 他的并行度为3 所以有三个子任务
再来到下一个算子 keyby 根据上图所说 就算这里的keyby并行度为3 他也是个独立的任务
然后keyby后面的并行度没变 并且没有新的keyby所以 后面俩算子都可以跟keyby合并成为一个任务
2.6checkpoint及savepoint
版权归原作者 我才是真的封不觉 所有, 如有侵权,请联系我们删除。