
需求:
1、做某个文件的词频统计//某个单词在这个文件出现次数
步骤:
1、文件单词规律(空格分开)
2、单词切分
3、单词的统计
(k,v)->(k:单词,V:数量)
4、打印
框架:
1、单例对象,main()
2、创建CONF
3、创建SC-->读取文件的方式--》RDD
4、RDD进行处理
5、关闭资源
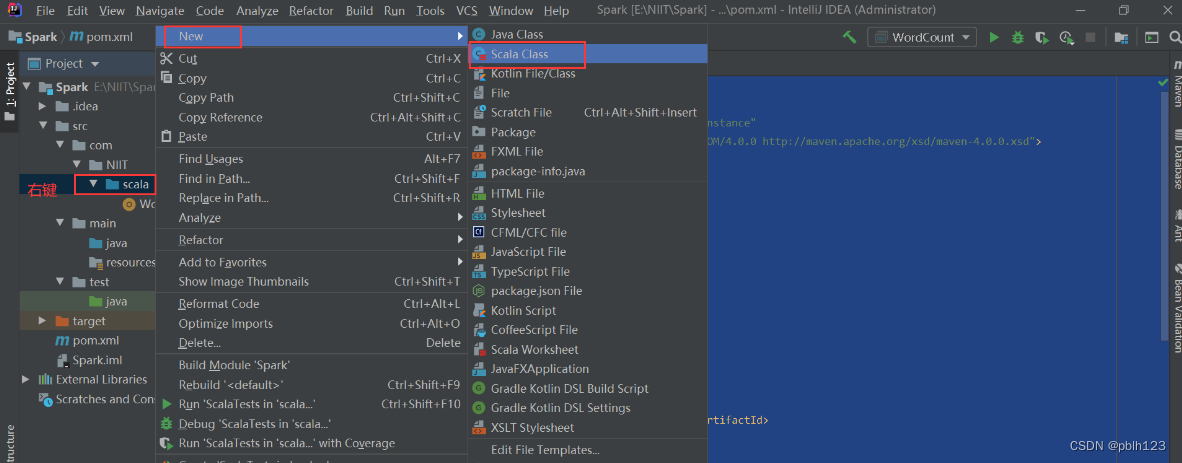
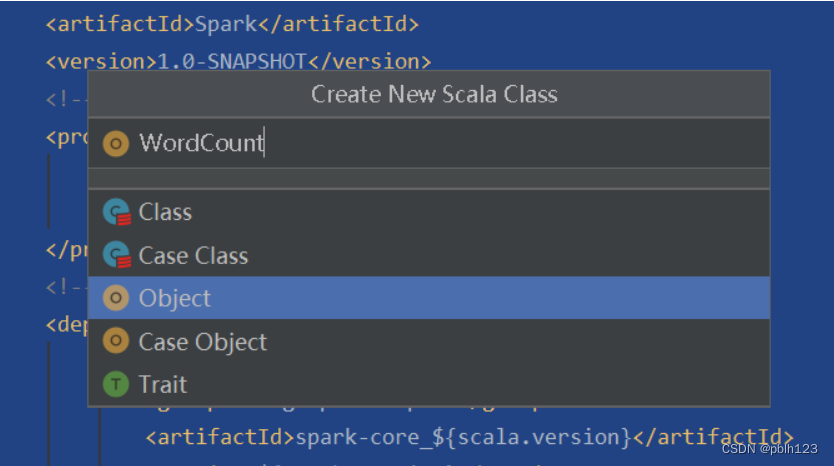
一、新建object类取名为WordCount
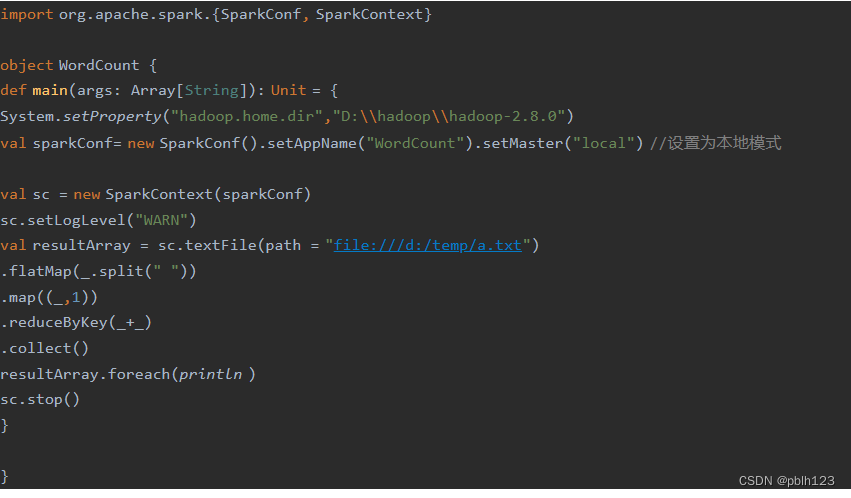
2、编写如下代码
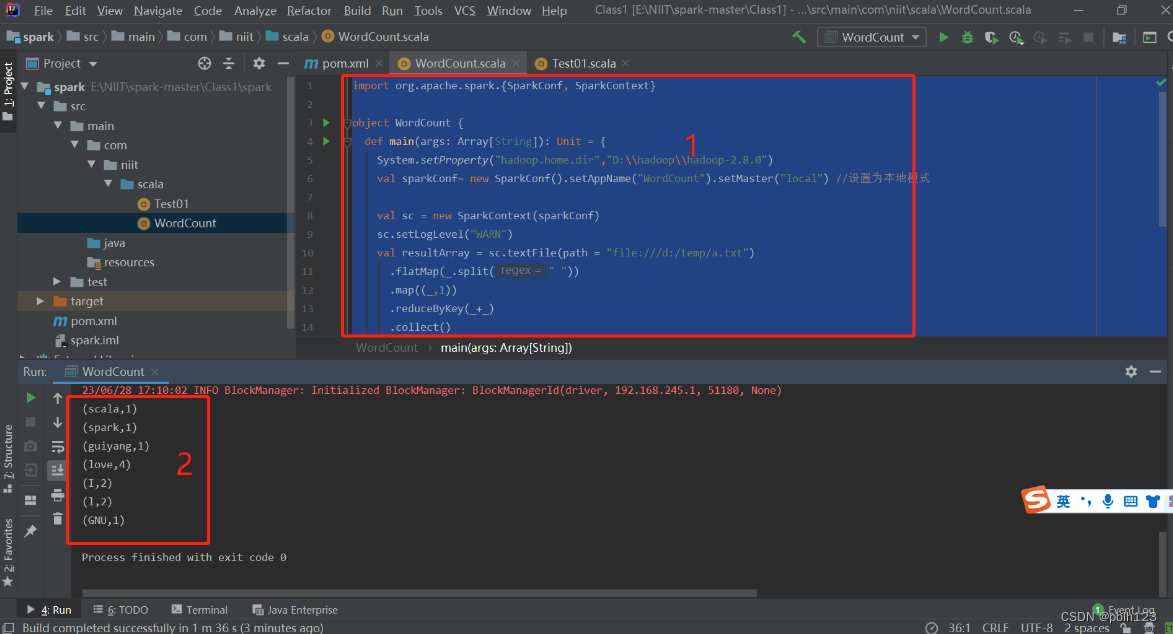
3、本地运行,查看运行结果如下
解决无法下载spark与打包插件的办法
maven打包插件与spark所需依赖下载地址:
链接:百度网盘 请输入提取码
提取码:jnta
解决步骤:
0、到网盘下载maven打包插件与spark依赖,网盘吗中的内容如下:

1、将下载的插件plugins.rar解压,并复制插件文件夹到你本地maven仓库下,如下图所示:
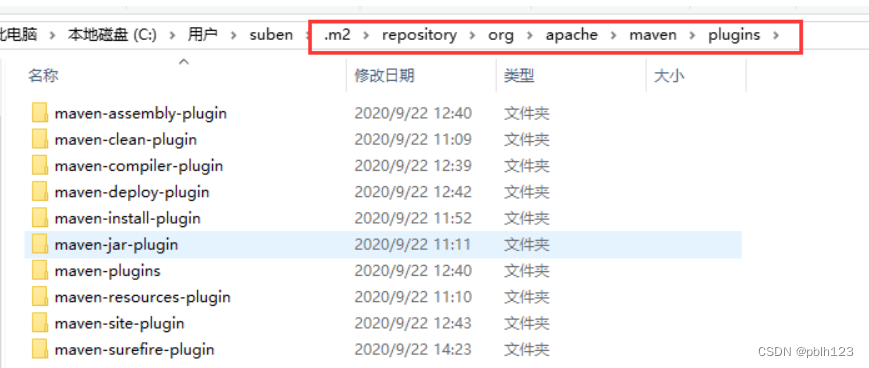
2、将下载的spark依赖spark.rar解压,并复制spark文件夹到你本地maven仓库下,如下图所示:

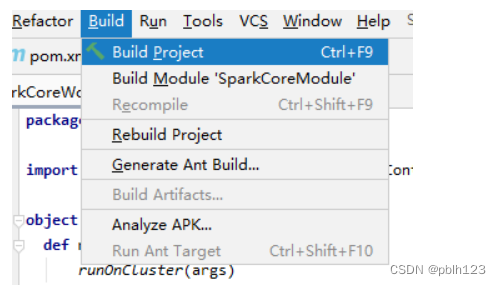
3、重启idea,重新build下工程
本文转载自: https://blog.csdn.net/pblh123/article/details/133079910
版权归原作者 pblh123 所有, 如有侵权,请联系我们删除。
版权归原作者 pblh123 所有, 如有侵权,请联系我们删除。