
文章目录
前言
大家好,我是ice三分颜色。个人主页:ice三分颜色的博客
本文讲了有关聚合函数的知识,包含求平均值,求和,统计数量,求最大值最小值。
走过路过的小伙伴们点个赞和关注再走吧,欢迎评论区交流,努力什么时候开始都不算晚,那不如就从这篇文章开始!
大家一起成长呀!笔芯

聚合函数
单行函数一次只对一行记录进行操作,每个操作行都返回一行输出结果。聚合函数是对一批数据进行操作之后返回单个的值。这批数据可能是整个表,也可能是按某种条件把该表分成的组。聚合函数主要用于汇总统计数据。
常用聚合函数
avg(列):返回组中列数据的平均值,忽略null值
count(*|列):返回组中列的数量
max(列):返回组中列数据比较的最大值,忽略null值
min(列):返回组中列数据比较的最小值,忽略null值
sum(列):返回组中数据的和,忽略null值
**COUNT()**函数
用于统计记录数。
对于除以外的任何参数,返回所选择聚合中非null值的行的数目;对于参数,返回选择聚合所有行的数目,包含null值的行。
例子:
我的employee表如下。
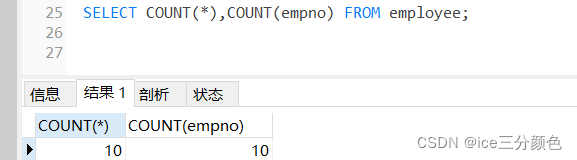
实现统计公司的员工总数(使用COUNT()与COUNT(empno)都可以实现对员工数的统计。其中COUNT()表示统计表中的所有记录行数;COUNT(empno)表示统计empno列不为NULL的记录行数。由于empno是employee表的主键(非空、不重复),因此通过此列的统计结果与使用*操作符相同。)
SELECT COUNT(*),COUNT(empno) FROM employee;
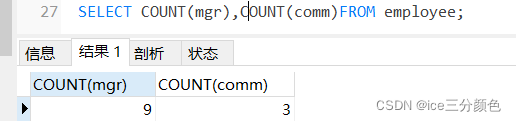
查询公司里有多少员工是由经理管理的、多少员工是有奖金的(COUNT(列)函数不对NULL值进行统计,所以统计结果mgr非空值有九行,comm非空值有3行)
SELECT COUNT(mgr),COUNT(comm)FROM employee;
**AVG(**列)函数和SUM(列)函数
前者是用于计算值为数字的列的平均值,后者是用于对值为数字的列求和。
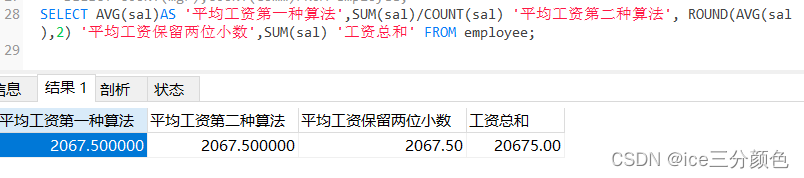
例:求公司员工的平均工资和工资总和
SELECT AVG(sal)AS '平均工资第一种算法',SUM(sal)/COUNT(sal) '平均工资第二种算法', ROUND(AVG(sal),2) '平均工资保留两位小数',SUM(sal) '工资总和' FROM employee;
**MAX(**列)和MIN(列)函数
分别用于求此列中的最大值和最小值。MIN()和MAX()函数不但可用于数字型数据,而且还可以用于字符型数据(字母按照首字母由A~Z的顺序排列,越往后的越大。汉字,也先看拼音首字母,首字母相同,则比较下一个字母)和日期型数据(日期越早的值越小)。
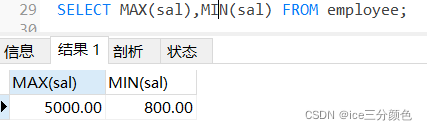
例:查找公司中员工的最高工资和最低工资。
SELECT MAX(sal),MIN(sal) FROM employee;
例:查找员工入职时间的最小值(最早时间)和最大值(最晚时间)。
SELECT MIN(hiredate),MAX(hiredate) FROM employee;

GROUP BY****子句的应用
分组函数是一次对一批数据进行操作,这批数据可能是整个表,也可能是按某种条件把该表分成的组。使用GROUP BY子句对表进行分组。
注意:
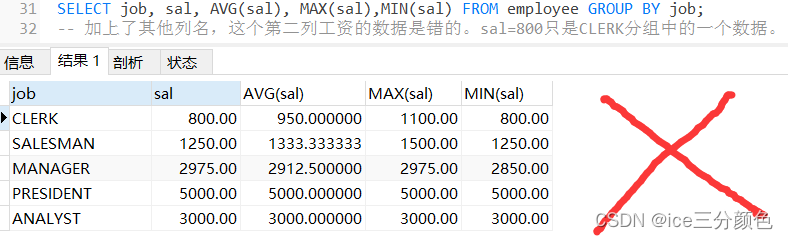
1.SELECT子句中只允许出现与GROUP BY子句中相同的分组字段和分组函数(使用了聚合函数的),也就是说不能再跟除了group by之后的列名之外的其他列名了,不然会出错(不会报错,但跟的其他列名下的数据是错误的)。
2.如果用了聚合函数,但不使用GROUP BY子句,则SELECT子句中不能出现任何其他字段(也就是列名),同样不报错,但数据会出错。
例:查询公司中按职位分类,每类员工的平均工资、最高工资和最低工资。
SELECT job, AVG(sal), MAX(sal),MIN(sal) FROM employee GROUP BY job;


GROUP BY子句还可以组成形式为"SELECT...FROM...WHERE...GROUP BY...ORDER BY...”的较为复杂的查询语句。
格式如下:
SELECT分组字段|分组函数FROM表
[WHERE条件]
[GROUP BY分组字段]
[ORDER BY排序字段ASC| DESC];
对应的此格式的SQL语句的执行顺序如下:
执行FROM子句,确定要检索的数据来源;
执行WHERE子句,使用限定条件对数据进行筛选;
执行GROUP BY子句,根据指定字段对筛选的数据分组;
执行SELECT子句,确定要查询的分组字段和分组函数;
执行ORDER BY子句,对查询的记录进行排序,默认为升序ASC,降序使用 DESC。
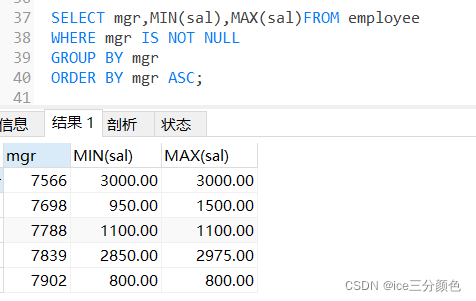
例:查询各个管理者手下员工的最低工资和最高工资,按照管理者编号由小到大排序,没有管理者的员工不计算在内。
SELECT mgr,MIN(sal),MAX(sal)FROM employee
WHERE mgr IS NOT NULL
GROUP BY mgr
ORDER BY mgr ASC;
注意:1.WHERE、GROUP BY、ORDER BY三者不是必须有的。三者之间顺序也不能颠倒。GROUP BY要在WHERE之后,ORDER BY之前。
2.WHERE语句用于数据分组前先对数据进行筛选。WHERE子句并不能对分组函数进行限定筛选。
HAVING****子句的使用
分组后对组记录进行筛选使用HAVING子句
SELECT分组字段|分组函数FROM表
[WHERE条件]
[GROUP BY分组字段][HAVING过滤条件]
[ORDER BY排序字段ASC| DESC];
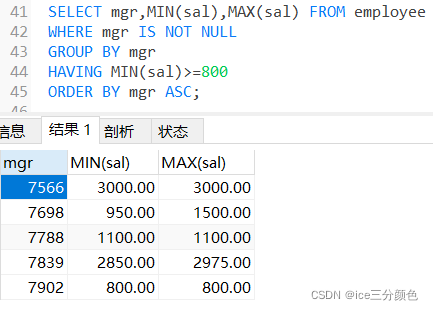
例:使用HAVING子句改进
SELECT mgr,MIN(sal),MAX(sal) FROM employee
WHERE mgr IS NOT NULL
GROUP BY mgr
HAVING MIN(sal)>=800
ORDER BY mgr ASC;
版权归原作者 ice三分颜色 所有, 如有侵权,请联系我们删除。