
一:首先要完成以下两步骤
1,安装虚拟机:安装虚拟机
2,连接XShell:连接xshell
注:一定要关闭防火墙:systemctl stop firewalld,systemctl disable firewalld
二:设置免密登陆,远程登陆,同步时间,启动定时任务,修改计算机名
可以先安装vim工具,方便后面使用:yum install -y vim
1,设置免密登陆:ssh-keygen -t rsa -P ""

2,远程登陆:
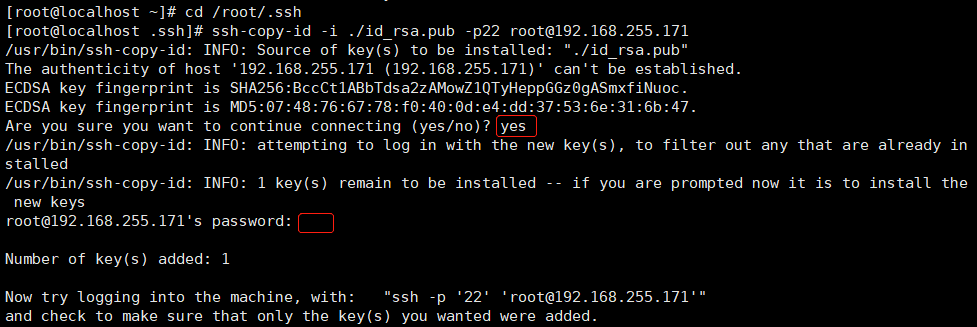
[root@localhost ~]# cd /root/.ssh
开启:[root@localhost .ssh]# ssh-copy-id -i ./id_rsa.pub -p22 root@192.168.255.171
登陆:[root@localhost .ssh]# ssh -p22 root@192.168.255.171

3,同步时间和定时更新时间
[root@localhost ~]# yum install -y ntpdate
[root@localhost ~]# crontab -e
输入以下内容(每5分钟更新一次时间):
*/5 * * * * /usr/sbin/ntpdate -u
time.windows.com
4,启动定时任务
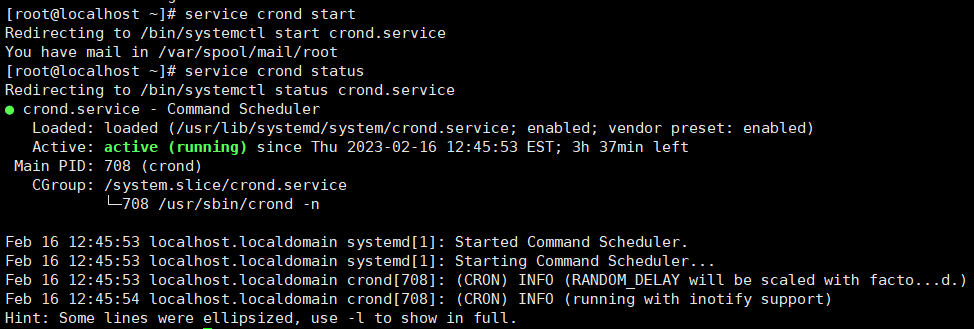
开启定时任务:[root@localhost ~]# service crond start
查看定时任务的状态:[root@localhost ~]# service crond status
5,修改计算机名
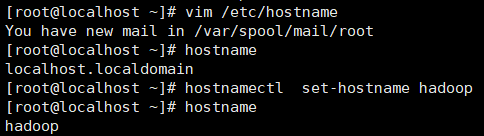
第一步:[root@localhost ~]# vim /etc/hostname
进入修改名字
第二步:[root@localhost ~]# hostnamectl set-hostname hadoop
然后就修改成功啦
三:配置hosts文件,解压文件到指定目录,修改文件名字
1,配置hosts文件:[root@hadoop ~]# vim /etc/hosts

输入以下内容:
2,解压文件到指定目录
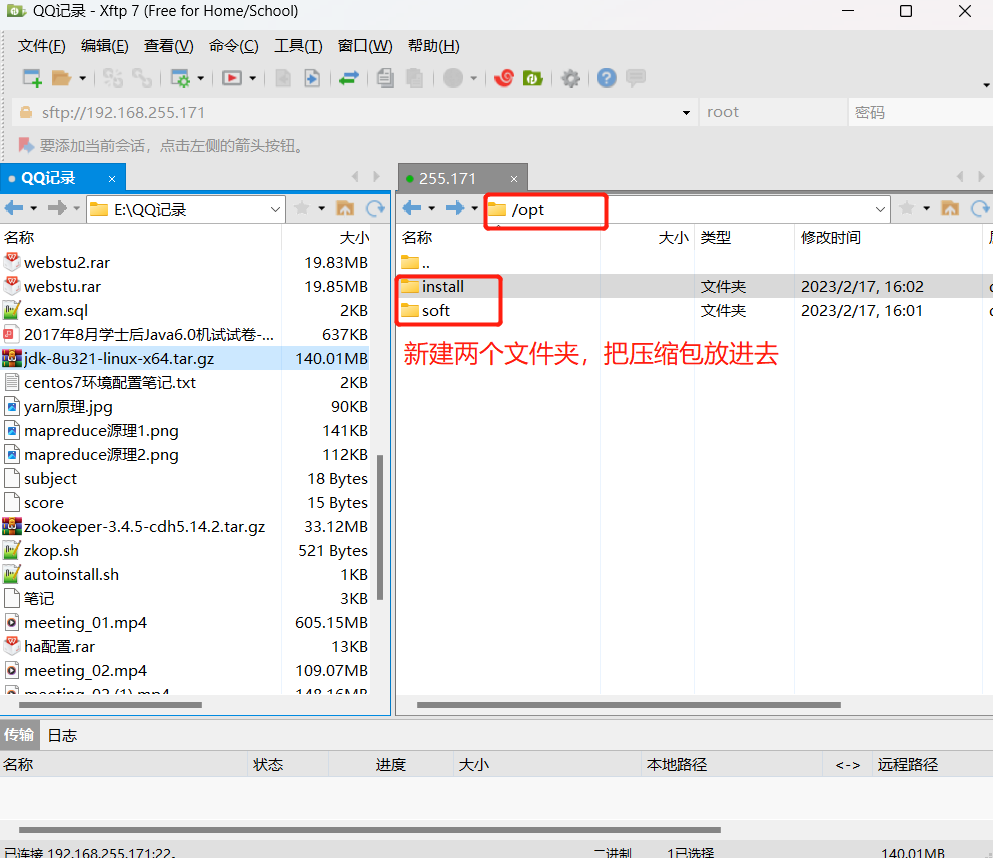
先用xftp,在/opt下新建install和soft文件夹,把压缩包放进install文件夹中
再把两个压缩包都解压到soft文件夹下
[root@hadoop ~]# cd /opt/install
[root@localhost install]# tar -zxvf ./jdk-8u321-linux-x64.tar.gz -C ../soft/
[root@localhost install]# tar -zxvf ./hadoop-3.1.3.tar.gz -C ../soft/

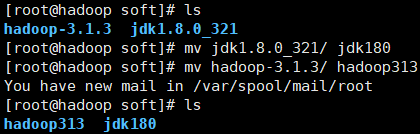
3,修改文件名字
[root@localhost soft]# mv jdk1.8.0_321/ jdk180
[root@localhost soft]# mv hadoop-3.1.3/ hadoop313
四:配置JDK环境变量,刷新配置文件,测试
1,配置jdk环境变量:[root@hadoop soft]# vim /etc/profile
在最后输入以下内容:
#JAVA_HOME
export JAVA_HOME=/opt/soft/jdk180
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
2,刷新配置文件:[root@localhost soft]# source /etc/profile
3,测试:[root@localhost soft]# java -version,可以查看到版本号
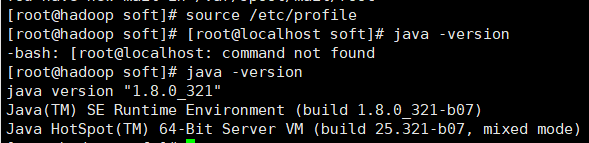
以上jdk配置好了,接下来配置Hadoop
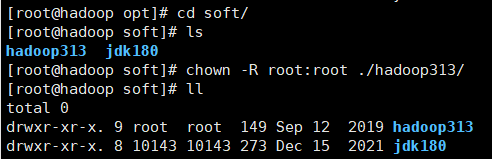
五:修改hadoop313目录的权限
[root@hadoop soft]# chown -R root:root ./hadoop313/
六:配置五个xml文件内容
1,配置core-site.xml
[root@hadoop hadoop313]# cd /opt/soft/hadoop313/etc/hadoop/
[root@hadoop hadoop]# vim ./core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/soft/hadoop313/data</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
<description>读写队列缓存:128K</description>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
2,配置hadoop-env.sh
[root@hadoop hadoop]# vim ./hadoop-env.sh

3,配置hdfs-site.xml
[root@hadoop hadoop]# vim ./hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>hadoop中每一个block文件的备份数量</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/soft/hadoop313/data/dfs/name</value>
<description>namenode上存储hdfsq名字空间元数据的目录</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/soft/hadoop313/data/dfs/data</value>
<description>datanode上数据块的物理存储位置目录</description>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
<description>关闭权限验证</description>
</property>
</configuration>
4,配置mapred-site.xml
[root@hadoop hadoop]# vim ./mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>job执行框架: local, classic or yarn</description>
<final>true</final>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/opt/soft/hadoop313/etc/hadoop:/opt/soft/hadoop313/share/hadoop/common/lib/*:/opt/soft/hadoop313/share/hadoop/common/*:/opt/soft/hadoop313/share/hadoop/hdfs/*:/opt/soft/hadoop313/share/hadoop/hdfs/lib/*:/opt/soft/hadoop313/share/hadoop/mapreduce/*:/opt/soft/hadoop313/share/hadoop/mapreduce/lib/*:/opt/soft/hadoop313/share/hadoop/yarn/*:/opt/soft/hadoop313/share/hadoop/yarn/lib/*</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop:19888</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>1024</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>1024</value>
</property>
</configuration>
5,配置yarn-site.xml
[root@hadoop hadoop]# vim ./yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>20000</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.nodemanager.localizer.address</name>
<value>hadoop:8040</value>
</property>
<property>
<name>yarn.nodemanager.address</name>
<value>hadoop:8050</value>
</property>
<property>
<name>yarn.nodemanager.webapp.address</name>
<value>hadoop:8042</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/opt/soft/hadoop313/yarndata/yarn</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/opt/soft/hadoop313/yarndata/log</value>
</property>
</configuration>
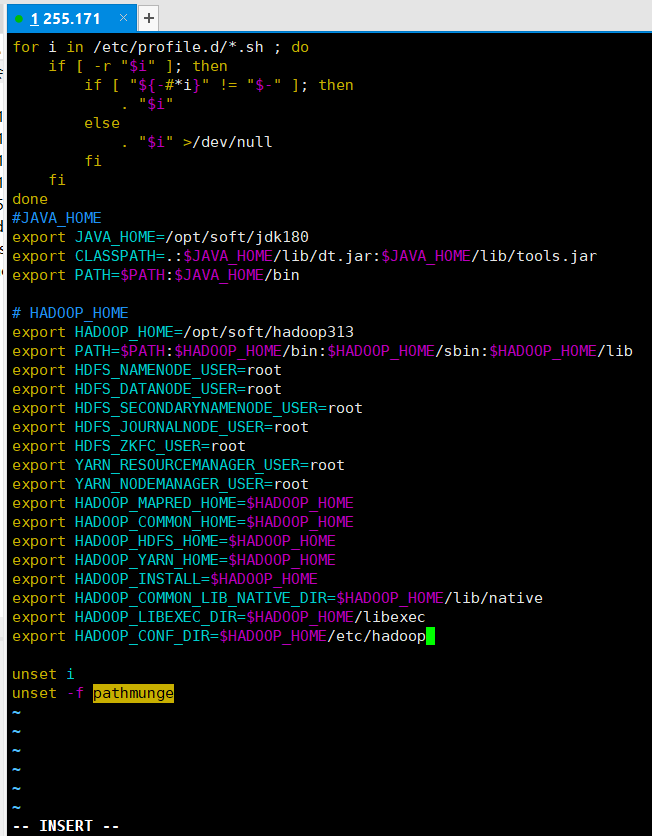
七:配置profile文件内容
[root@hadoop hadoop]# vim /etc/profile
# HADOOP_HOME
export HADOOP_HOME=/opt/soft/hadoop313
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/lib
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_LIBEXEC_DIR=$HADOOP_HOME/libexec
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
八:刷新配置文件,初始化,启动并应用
1,刷新当前的shell环境
[root@hadoop hadoop]# source /etc/profile
2,初始化
[root@hadoop hadoop]# hdfs namenode -format
3,启动
[root@hadoop hadoop]# start-all.sh
[root@hadoop hadoop]# jps
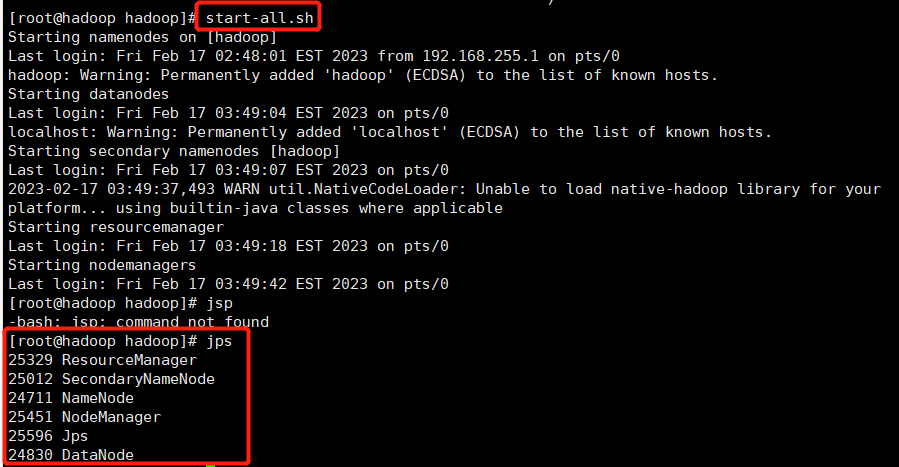
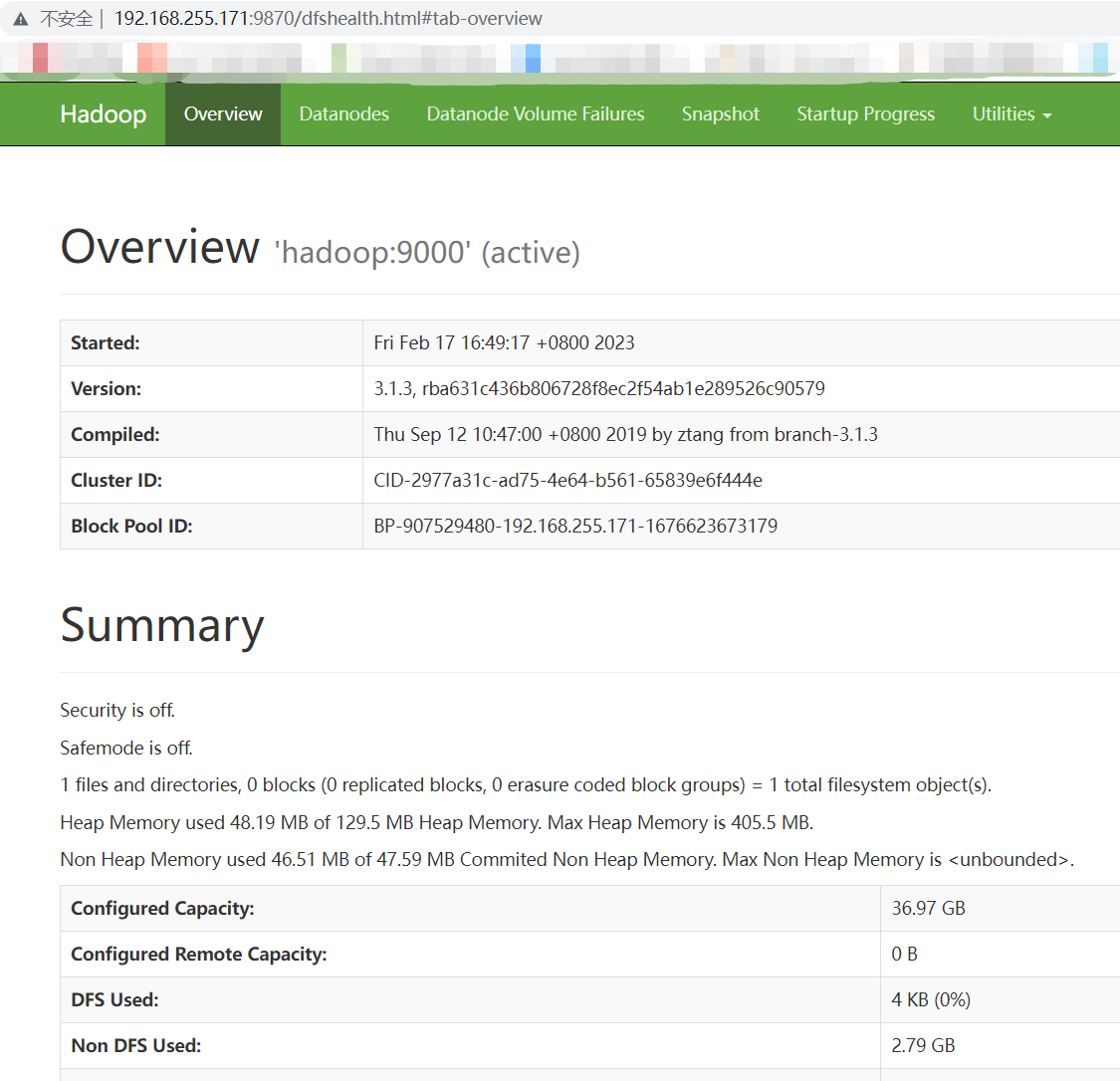
4,可视化应用
网页输入:192.168.255.171:9870 回车
版权归原作者 思达滴 所有, 如有侵权,请联系我们删除。