
欢迎来到我们的技术博客!今天,我们要探讨的主题是Apache Spark的一个核心组件——Structured Streaming。作为一个可扩展且容错的流处理引擎,Structured Streaming使得处理实时数据流变得更加高效和简便。
什么是Structured Streaming?
Structured Streaming是基于Apache Spark SQL引擎构建的高级流处理框架。它允许用户使用SQL查询语言以及DataFrame和DataSet API来操作流数据,从而简化了复杂数据流的处理。
核心概念
Structured Streaming的核心在于将实时数据流视为动态表(即DataFrame或Dataset)。这意味着你可以使用熟悉的Spark SQL操作来处理这些数据流,并定义输出接收器来持续接收处理结果。随着新数据的不断到来,Spark SQL引擎会实时更新结果表。
输入表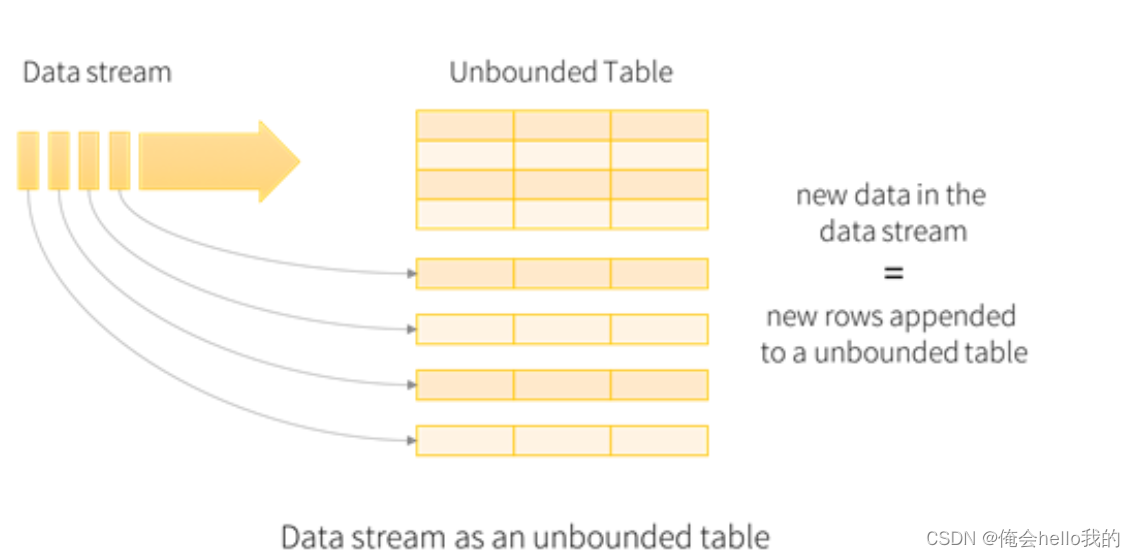
输出表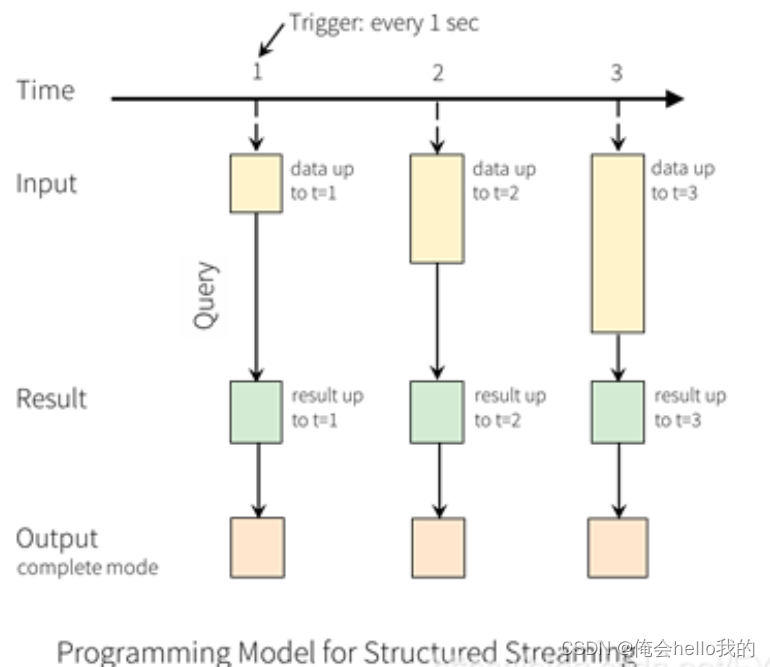
关键特性
- DataFrame表示:- 流数据在Structured Streaming中被视为动态变化的DataFrame。- 支持多种数据源,如Kafka、文件系统、TCP套接字等。
- 流式计算:- 数据实时到达即处理,区别于传统的批处理。- 支持对DataFrame进行各种转换操作(如
map、filter、join等)。 - 触发器:- 控制数据输出的时机,可以基于时间或数据量设置。
- 输出模式:- 提供多种输出模式,包括完整模式(Complete)、更新模式(Update)和附加模式(Append)。
- 容错机制:- 结合检查点和预写日志实现强大的容错能力。
- 事件时间和水印:- 支持基于事件时间的处理,有效处理延迟数据。
应用示例
以下是一个Structured Streaming应用的简单示例。该程序从TCP套接字读取实时文本数据,并计算每个单词的出现频率。
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode, split
# 创建Spark会话
spark = SparkSession.builder.appName("StructuredNetworkWordCount").getOrCreate()# 创建代表来自localhost:9999的输入文本流的DataFrame
lines = spark.readStream.format("socket").option("host","localhost").option("port",9999).load()# 将行拆分为单词
words = lines.select(explode(split(lines.value," ")).alias("word"))# 计算每个单词的出现次数
wordCounts = words.groupBy("word").count()# 启动查询并将结果打印到控制台
query = wordCounts.writeStream.outputMode("complete").format("console").start()
query.awaitTermination()
结语
Structured Streaming为处理复杂的实时数据流提供了一个强大、灵活且易于使用的解决方案。无论是初学者还是有经验的Spark开发者,都可以从中受益,高效地构建实时数据处理应用。
本文转载自: https://blog.csdn.net/weixin_53285092/article/details/134692935
版权归原作者 俺会hello我的 所有, 如有侵权,请联系我们删除。
版权归原作者 俺会hello我的 所有, 如有侵权,请联系我们删除。