
目录
基本概念
LSM树(log-structed-merge-tree):
日志结构的:系统日志是不会出错的,只需要在后面追加。所以日志结构就代指追加型结构。
原理:把磁盘看做一个日志,在日志中存放永久性数据及其索引,每次都添加到日志的末尾。文件传输(存取)大多是顺序的,提高磁盘带宽利用率。
LSM-tree是专门为key-value存储系统设计的,主要业务是查找和插入。
LSM的特点是利用磁盘的顺序写,写入速度比随机写入的B-树更快。
LSM 树的思想是使用顺序写代替随机写来提高写性能,与此同时会略微降低读性能。HBase、 Cassandra、 LevelDB、 RocksDB 以及 ClickHouse MergeTree 等流行的 NoSQL 数据库均采用 LSM 存储结构。
LSM树(Log Structured Merged Tree)的名字往往给人一个错误的印象, 实际上LSM树并没有严格的树状结构。
LSM 树的思想是使用顺序写代替随机写来提高写性能,与此同时会略微降低读性能。
LSM 的高速写入能力与读缓存技术带来的高速读能力结合受到了需要处理大规模数据的开发者的青睐,成为了非常流行的存储结构。
HBase、 Cassandra、 LevelDB、 RocksDB 以及 ClickHouse MergeTree 等流行的 NoSQL 数据库均采用 LSM 存储结构。
读写流程
具体来说 LSM 的数据更新是日志式的,修改数据时直接追加一条新记录(为被修改数据创建一个新版本),而使用 B/B+ 树的数据库则需要找到数据在磁盘上的位置并在原地进行修改。

这张经典图片来自 Flink PMC 的 Stefan Richter 在Flink Forward 2018演讲的PPT
写入
在执行写操作时,首先写入 active memtable 和预写日志(Write Ahead Logging, WAL)。因为内存中 memtable 会断电丢失数据,因此需要将记录写入磁盘中的 WAL 保证数据不会丢失。
顾名思义 MemTable是一个内存中的数据结构,它保存了落盘之前的数据。SkipList 是最流行的 Memtable 实现方式,Hbase 和 RocksDB 均默认使用 SkipList 作为 MemTable。
当 Active MemTable 写满后会被转换为不可修改的 Immutable MemTable,并创建一个新的空 Active MemTable。后台线程会将 Immutable MemTable 写入到磁盘中形成一个新的 SSTable 文件,并随后销毁 Immutable MemTable。
SSTable (Sorted String Table) 是 LSM 树在磁盘中持久化存储的数据结构,它是一个有序的键值对文件。
LSM 不会修改已存在的 SSTable, LSM 在修改数据时会直接在 MemTable 中写入新版本的数据,并等待 MemTable 落盘形成新的 SSTable。因此,虽然在同一个 SSTable 中 key 不会重复,但是不同的 SSTable 中仍会存在相同的 Key。
读取
因为最新的数据总是先写入 MemTable,所以在读取数据时首先要读取 MemTable 然后从新到旧搜索 SSTable,找到的第一个版本就是该 Key 的最新版本。
根据局部性原理,刚写入的数据很有可能被马上读取。因此, MemTable 在充当写缓存之外也是一个有效的读缓存。
为了提高读取效率 SSTable 通常配有 BloomFilter 和索引来快速判断其中是否包含某个 Key 以及快速定位它的位置。
因为读取过程中需要查询多个 SSTable 文件,因此理论上 LSM 树的读取效率低于使用 B 树的数据库。为了提高读取效率,RocksDB 中内置了块缓存(Block Cache)将频繁访问磁盘块缓存在内存中。而 LevelDB 内置了 Block Cache 和 Table Cache 来缓存热点 Block 和 SSTable。
Compact
随着不断的写入 SSTable 数量会越来越多,数据库持有的文件句柄(FD)会越来越多,读取数据时需要搜索的 SSTable 也会越来越多。另一方面对于某个 Key 而言只有最新版本的数据是有效的,其它记录都是在白白浪费磁盘空间。因此对 SSTable 进行合并和压缩(Compact)就十分重要。
在介绍 Compact 之前, 我们先来了解 3 个重要的概念:
- 读放大:读取数据时实际读取的数据量大于真正的数据量。例如 LSM 读取数据时需要扫描多个 SSTable.
- 写放大:写入数据时实际写入的数据量大于真正的数据量。例如在 LSM 树中写入时可能触发Compact操作,导致实际写入的数据量远大于该key的数据量。
- 空间放大:数据实际占用的磁盘空间比数据的真正大小更多。例如上文提到的 SSTable 中存储的旧版数据都是无效的。 Compact 策略需要在三种负面效应之间进行权衡以适应使用场景。
Size Tiered Compaction Strategy
Size Tiered Compaction Strategy (STCS) 策略保证每层 SSTable 的大小相近,同时限制每一层 SSTable 的数量。当某一层 SSTable 数量达到阈值后则将它们合并为一个大的 SSTable 放入下一层。
STCS 实现简单且 SSTable 数量较少,缺点是当层数较深时容易出现巨大的 SSTable。此外,即使在压缩后同一层的 SSTable 中仍然可能存在重复的 key,一方面存在较多无效数据即空间放大较严重,另一方面读取时需要从旧到新扫描每一个 SSTable 读放大严重。通常认为与下文介绍的 Leveled Compaction Strategy 相比, STCS 的写放大较轻一些[1][2]。
STCS 是 Cassandra 的默认压缩策略[3]。Cassandra 认为在插入较多的情况下 STCS 有更好的表现。
Tiered压缩算法在RocksDB的代码里被命名为 Universal Compaction。
Leveled Compaction Strategy
Leveled Compaction Strategy (LCS)策略也是采用分层的思想,每一层限制总文件的大小。
LCS 会将每一层切分成多个大小相近的SSTable, 且 SSTable 是在层内是有序的,一个key在每一层至多只有1条记录,不存在冗余记录。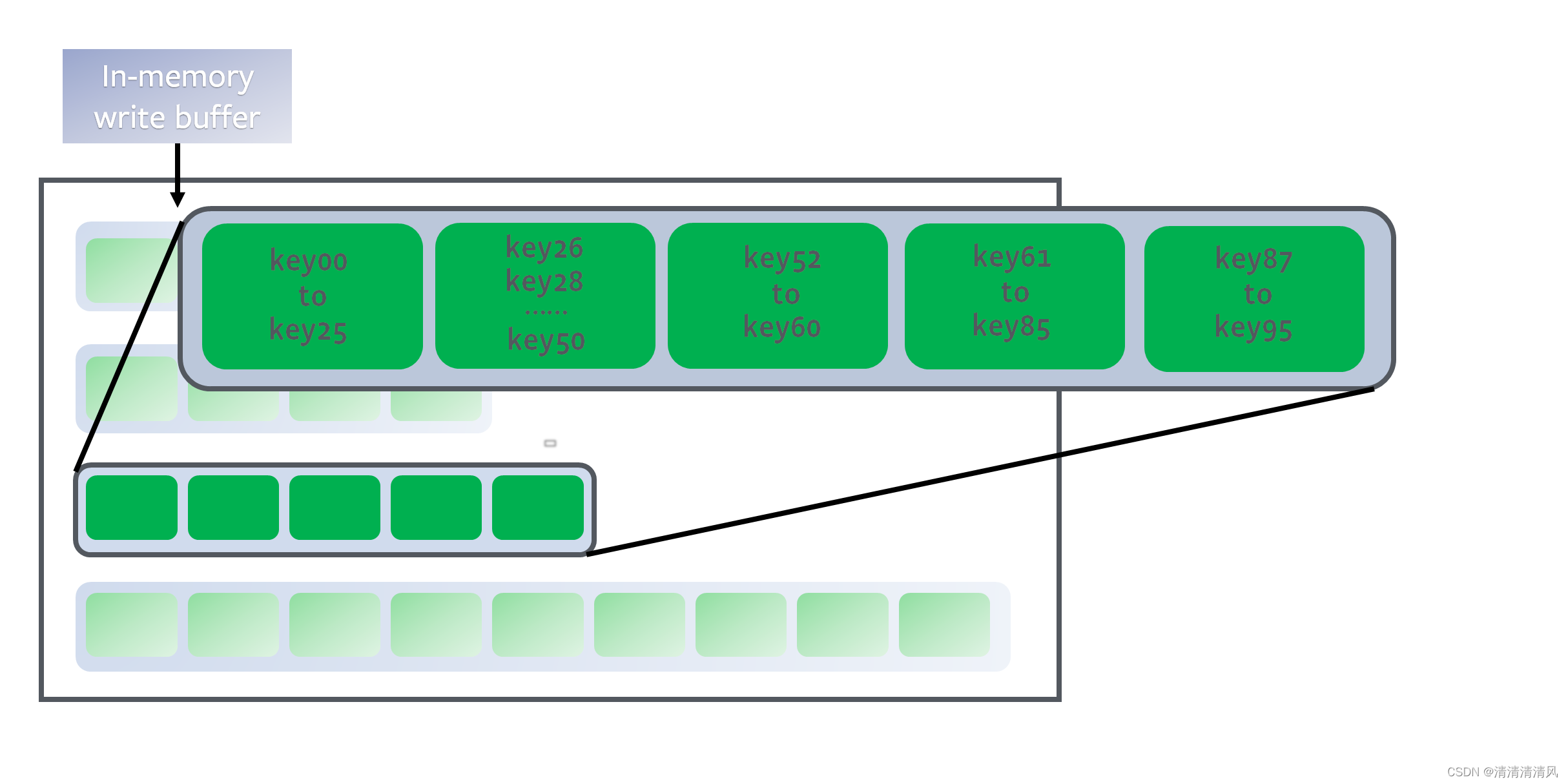
LCS 层内不存在冗余所以空间放大比较小。因为层内有序, 所以在读取时每一层最多读取一个 SSTable 所以读放大较小。在读取和更改较多的场景下 LCS 压缩策略有着显著优势。
当某一层的总大小超过阈值之后,LCS 会从中选择一个 SSTable 与下一层中所有和它有交集的 SSTable合并,并将合并后的 SSTable 放在下一层。请注意与所有有交集的 SSTable 合并保证了 compact 之后层内仍然是有序且无冗余的。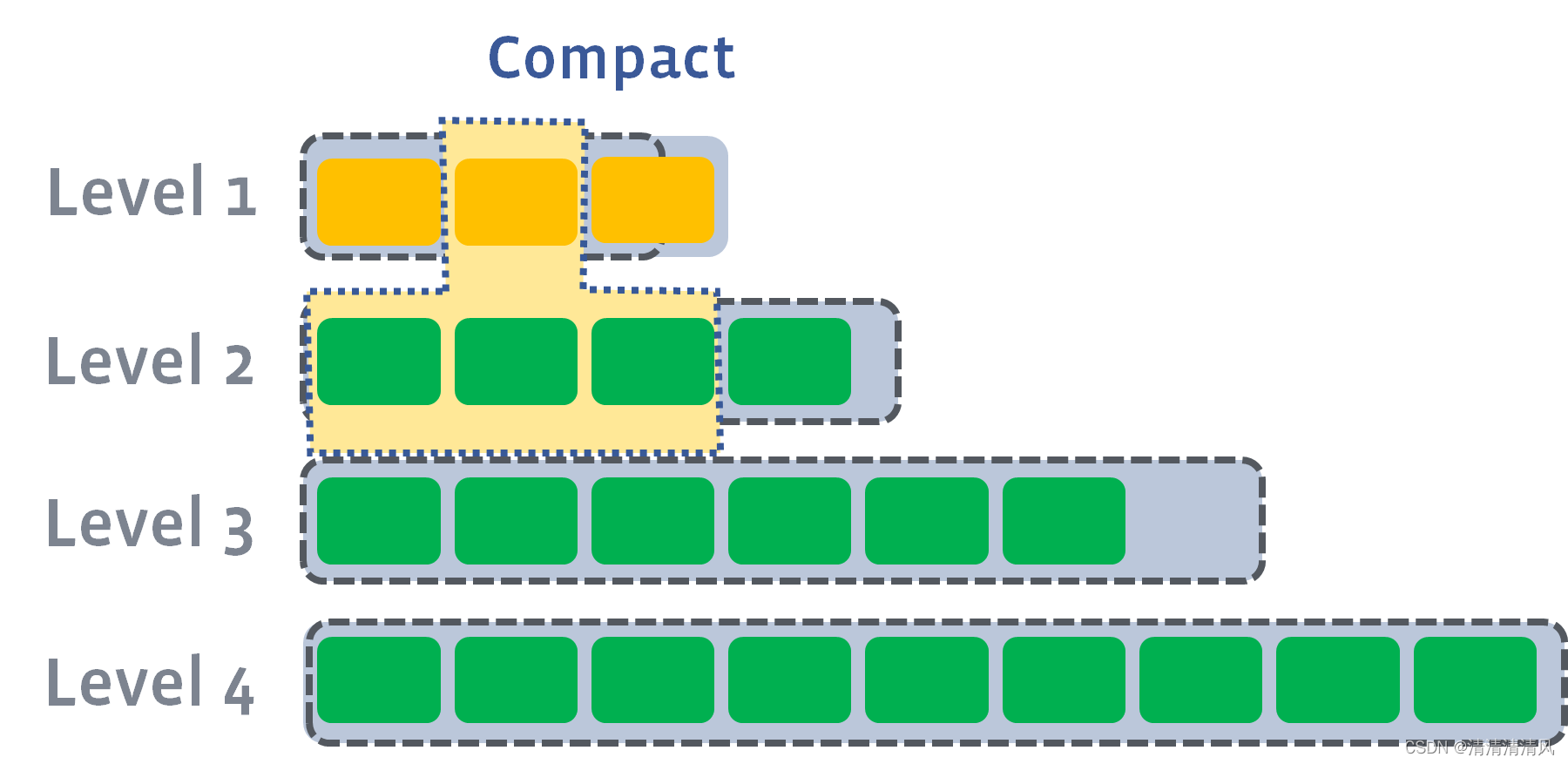
LCS 下多个不相关的合并操作是可以并发执行的。
LCS 有一个变体称为 Leveled-N 策略,它将每一层分为 N 个区块,层内不再全局有序只在区块内保证有序。它是 LCS 与 STCS 的中间状态,与 LCS 相比拥有更小的写放大,与 STCS 相比拥有更小的读放大与空间放大。
RocksDB 的压缩策略
RocksDB 默认采用的是 Size Tiered 与 Leveled 混合的压缩策略。在 RocksDB 中存在一个 Active MemTable 和多个 Immutable MemTable。
MemTable 被写入磁盘后被称为 Level-0 (L0)。L0 是无序的,也就是说 L0 的 SSTable 允许存在重叠。除 L0 外的层都是全局有序的,且采用 Leveled 策略进行压缩。
当 L0 中文件个数超过阈值(level0_file_num_compaction_trigger)后会触发压缩操作,所有的 L0 文件都将被合并进 L1。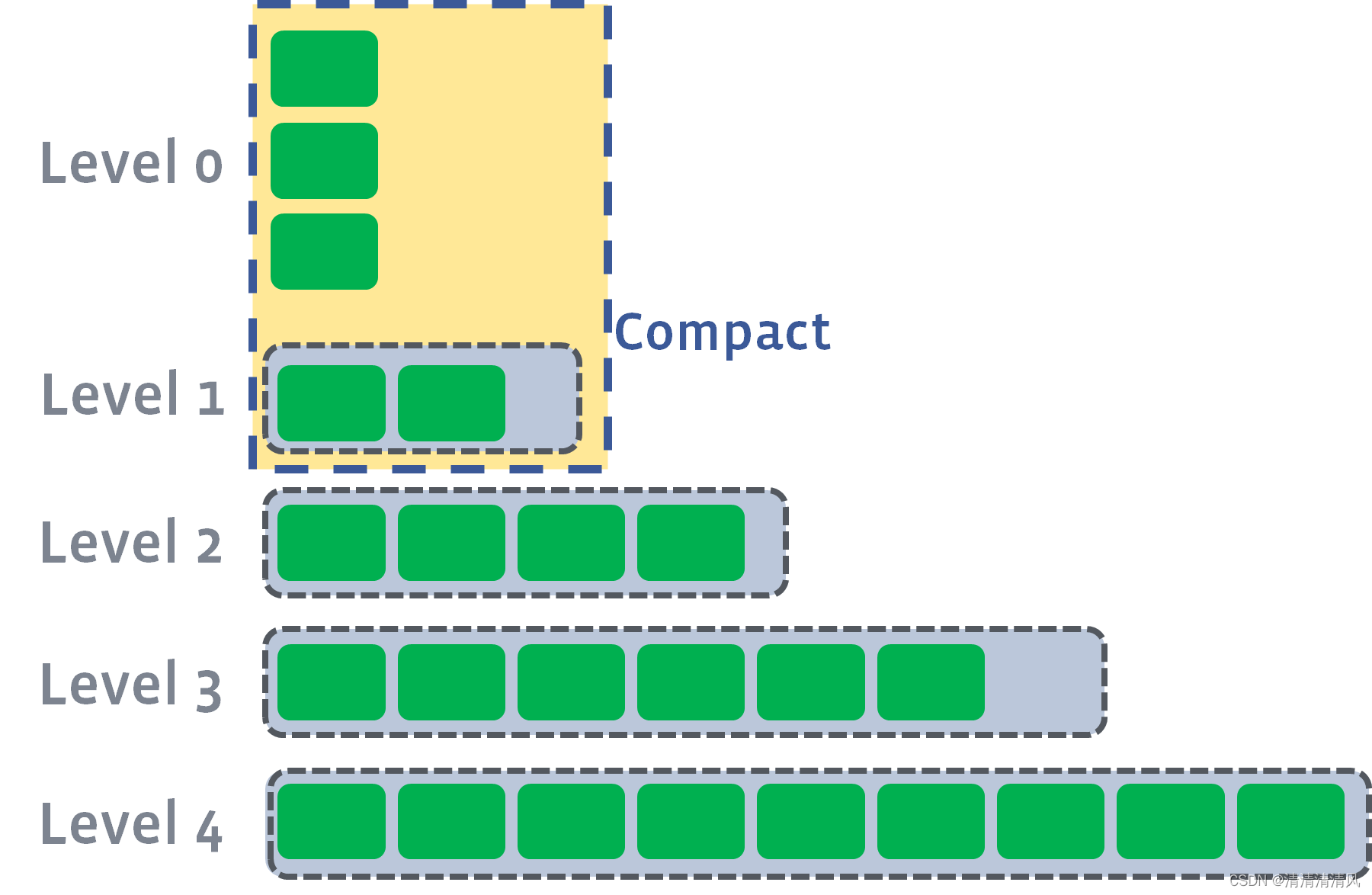
因为 L0 是 MemTable 直接落盘后的结果,而热点 key 的更新可能存在于多个 MemTable 中,所以 L0 的 SSTable 中极易因为热点 key 而出现交集。
版权归原作者 清清清清风 所有, 如有侵权,请联系我们删除。