
当数据库中存量数据较多时,或者是在批量插入操作时,很容易出现插入重复数据的问题。
一、三种方法
在 mysql 中,当存在主键冲突或唯一键冲突的情况下,根据插入策略不同,一般有以下三种避免方法:
insert ignore into:若没有则插入,若存在则忽略
replace into:若没有则正常插入,若存在则先删除后插入
insert into ... on duplicate key update:若没有则正常插入,若存在则更新
注意,使用以上方法的前提是表中有一个 PRIMARY KEY 或 UNIQUE 约束/索引,否则,使用以上三个语句没有特殊意义,与使用单纯的 INSERT INTO 效果相同。
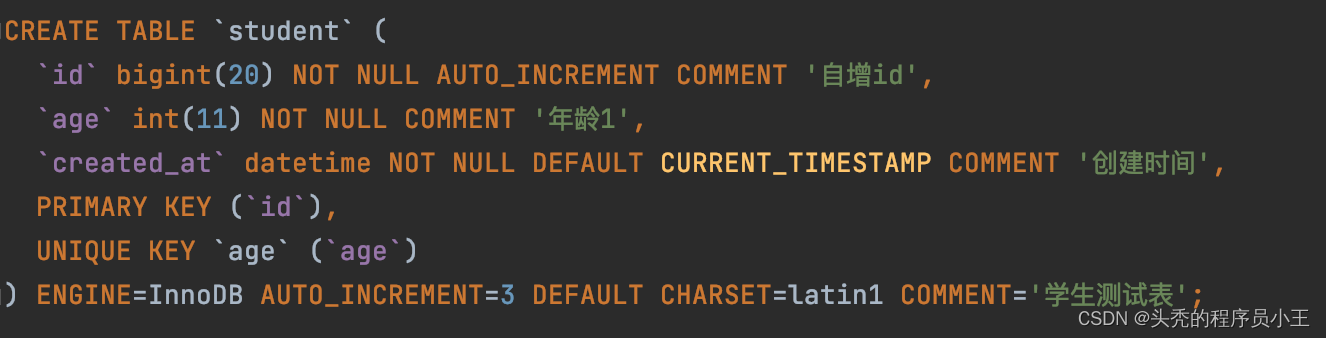
测试表结构:
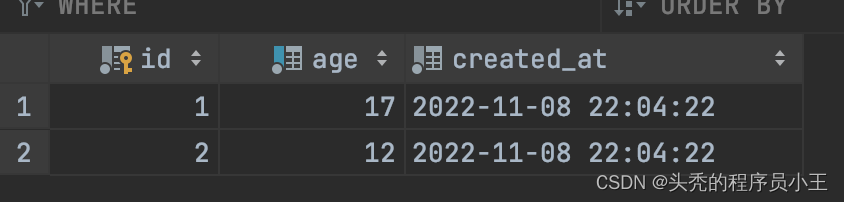
测试表数据:
二、细节
2.1、insert ignore into
insert ignore 会根据主键或者唯一键判断,忽略数据库中已经存在的数据,若数据库没有该条数据,就插入为新的数据,跟普通的 insert into 一样。若数据库有该条数据,就忽略这条插入语句,不执行插入操作。
insert ignore into student(age) values (12),(13);
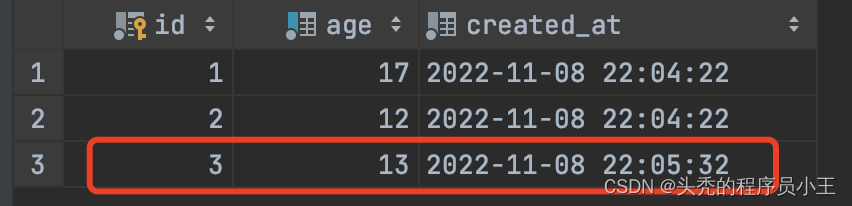
age=12的数据已存在,因此未插入(根据创建时间可得),age=13的数据不存在,因此成功插入
2.2 、insert into ... on duplicate key update
在 insert into 语句末尾指定 on duplicate key update,会根据主键或者唯一键判断:若数据库有该条数据,则直接更新原数据,相当于 update,若数据库没有该条数据,则插入为新的数据,跟普通的 insert into 一样。
insert into student(age) values (12),(13)
ON DUPLICATE KEY UPDATE student.created_at = '2022-01-01 00:00:00';
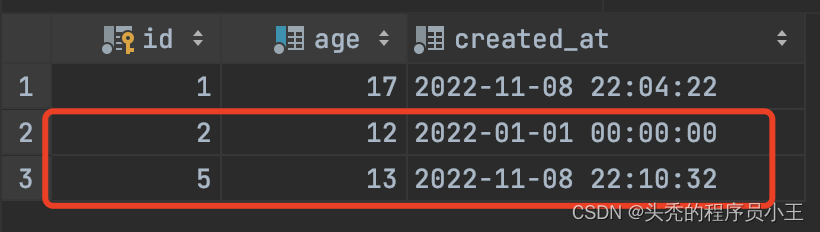
age=12的记录已存在,因此created_at字段被更新。age=13的记录不存在,因此成功插入
2.3、replace into
replace into student(age) values (12),(13);
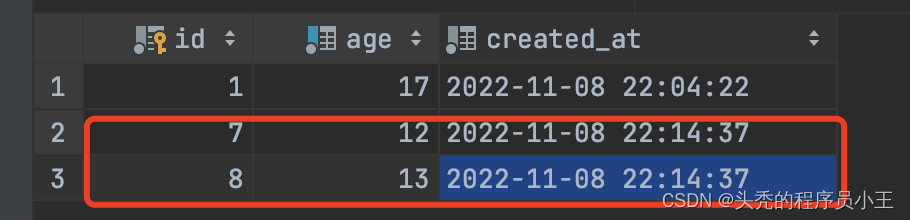
age=12的记录已存在,因此被删除重新插入(由createdAt值可知)。age=13的记录不存在,因此成功插入
replace into 会根据主键或者唯一键判断:
- 若表中已存在该数据,则先删除此行数据,然后插入新的数据,相当于 delete + insert
- 可能会丢失数据、主从服务器的 AUTO_INCREMENT 不一致。
- 若表中不存在该数据,则直接插入新数据,跟普通的 insert into 一样
三、总结
1)在主键冲突情况下,三种方法都可以使用
2)在唯一键冲突情况下,且有自增主键时:三种方法都会出现 AUTO_INCREMENT 不连续问题,且这种不连续不会同步更新到 slave 的 AUTO_INCREMENT。当 master 被 kill,且 slave 升级为 master 时,就会出现主键冲突问题。(因为事务原因,即使没有插入成功,也会占用一个自增id。row模式binlog下,主从的数据同步是一致的,主键也一致。有没有影响取决于主从同步模式)
- statement格式:binlog记录的是实际执行的sql语句
- row格式:binlog记录的是变化前后的数据(涉及所有列),形如update table_a set col1=value1, col2=value2 ... where col1=condition1 and col2=condition2 ...
- mixed格式:默认选择statement格式,只在需要时改用row格式
3)replace into 方法可能会导致部分数据丢失。
版权归原作者 头秃的程序员小王 所有, 如有侵权,请联系我们删除。