
文章目录
Spark三种任务提交模式
宽依赖和窄依赖
- 窄依赖(Narrow Dependency):指父RDD的每个分区只被子RDD的一个分区所使用,例如map、filter等这些算子。一个RDD,对它的父RDD只有简单的一对一的关系,也就是说,RDD的每个partition仅仅依赖于父RDD中的一个partition,父RDD和子RDD的partition之间的对应关系,是一对一的。
- 宽依赖(Shuffle Dependency):父RDD的每个分区都可能被子RDD的多个分区使用,例如groupByKey、reduceByKey,sortBykey等算子,这些算子其实都会产生shuffle操作。也就是说,每一个父RDD的partition中的数据都可能会传输一部分到下一个RDD的每个partition中。此时就会出现,父RDD和子RDD的partition之间,具有错综复杂的关系,那么,这种情况就叫做两个RDD之间是宽依赖,同时,他们之间会发生shuffle操作。
下面来看图具体分析一个案例,以单词计数案例来分析
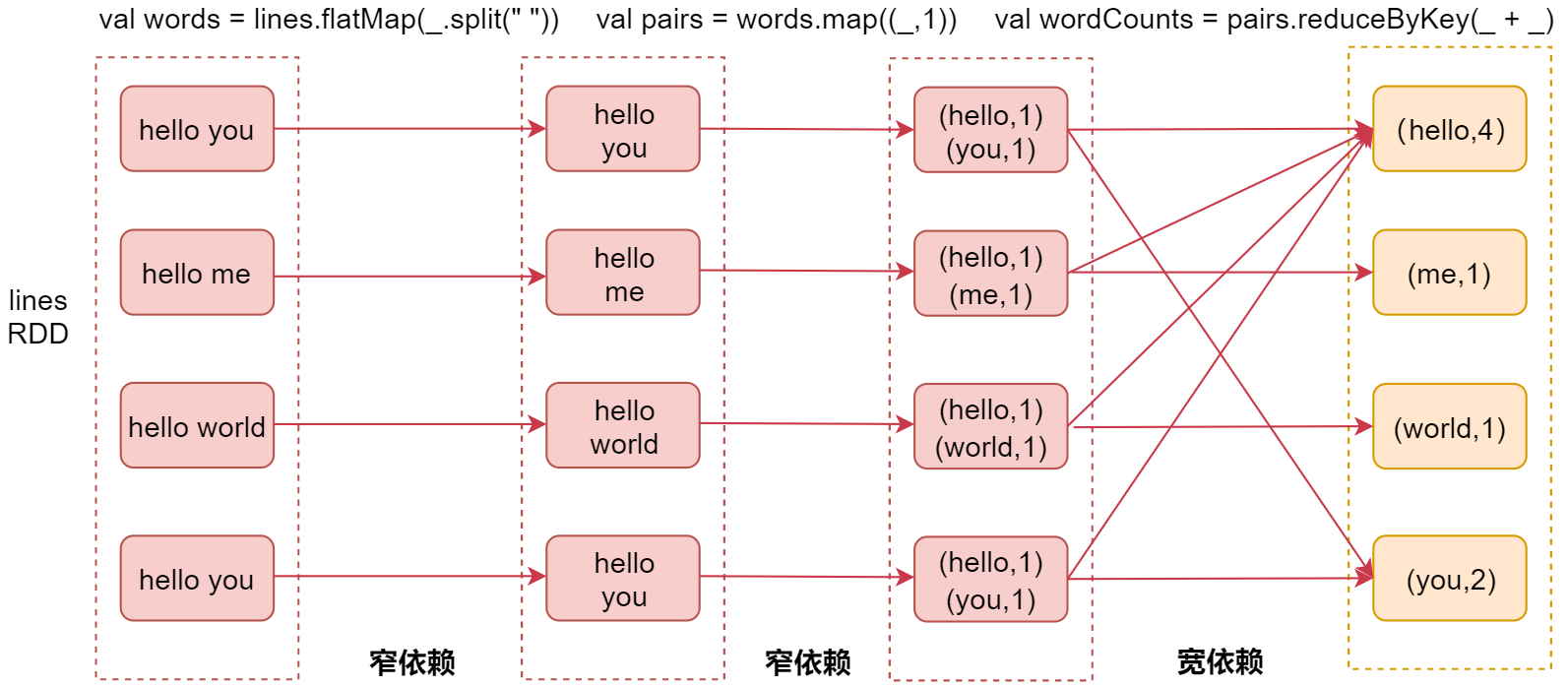
最左侧是linesRDD,这个表示我们通过textFile读取文件中的数据之后获取的RDD。
接着是我们使用flatMap算子,对每一行数据按照空格切开,然后可以获取到第二个RDD,这个RDD中包含的是切开的每一个单词。在这里这两个RDD就属于一个窄依赖,因为父RDD的每个分区只被子RDD的一个分区所使用,也就是说他们的分区是一对一的,这样就不需要经过shuffle了。接着是使用map算子,将每一个单词转换成(单词,1)这种形式,此时这两个RDD也是一个窄依赖的关系,父RDD的分区和子RDD的分区也是一对一的。
最后我们会调用reduceByKey算子,此时会对相同key的数据进行分组,分到一个分区里面,并且进行聚合操作,此时父RDD的每个分区都可能被子RDD的多个分区使用,那这两个RDD就属于宽依赖了。
Stage
spark job是根据action算子触发的,遇到action算子就会起一个job
Spark Job会被划分为多个Stage,每一个Stage是由一组并行的Task组
注意:stage的划分依据就是看是否产生了shuflle(即宽依赖),遇到一个shuffle操作就划分为前后两个stage
stage是由一组并行的task组成,stage会将一批task用TaskSet来封装,提交给TaskScheduler进行分配,最后发送到Executor执行
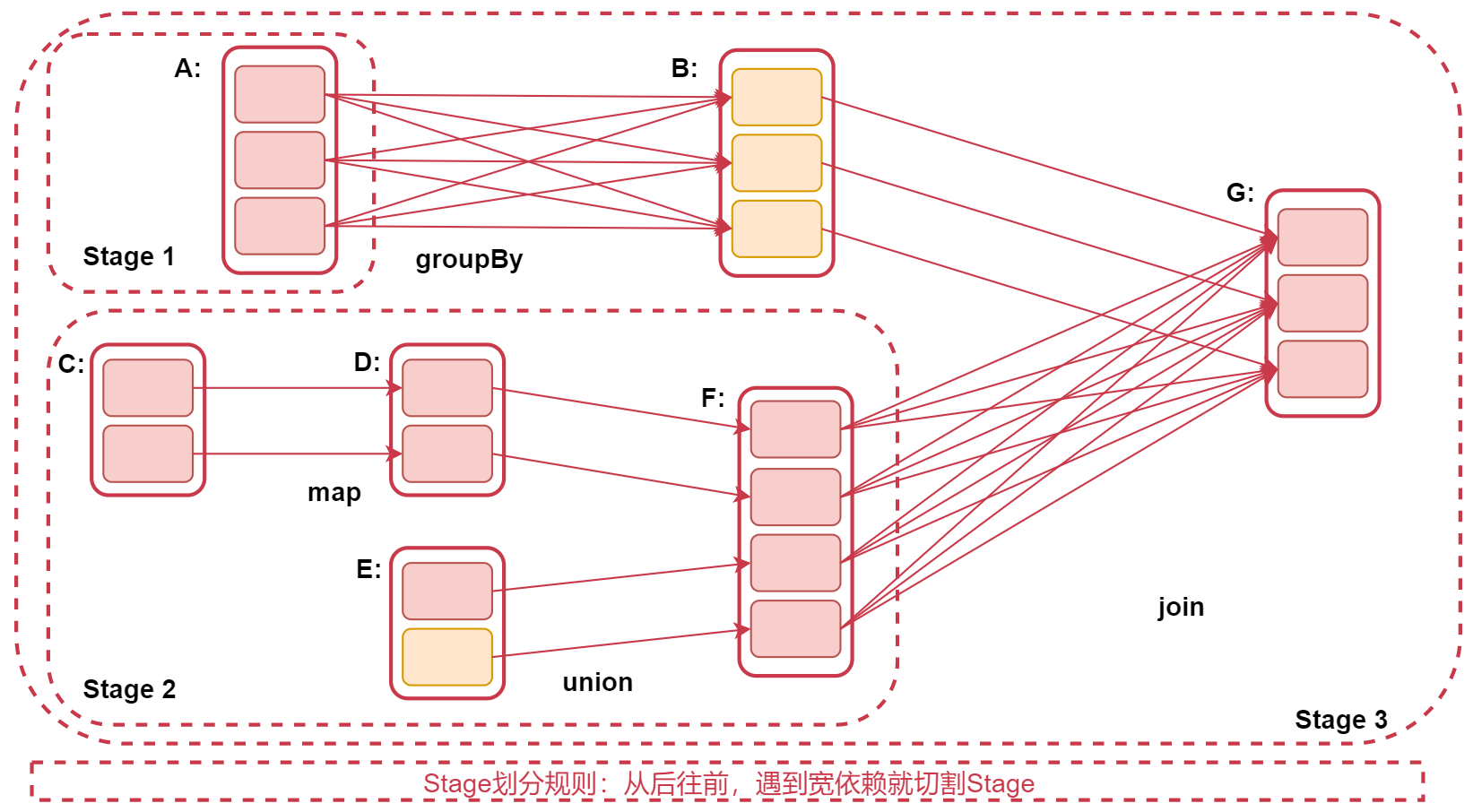
注意:Stage的划分规则:从后往前,遇到宽依赖就划分Stage
为什么是从后往前呢?因为RDD之间是有血缘关系的,后面的RDD依赖前面的RDD,也就是说后面的RDD要等前面的RDD执行完,才会执行。所以从后往前遇到宽依赖就划分为两个stage,shuffle前一个,shuffle后一个。如果整个过程没有产生shuffle那就只会有一个stage。
看这个图
RDD G 往前推,到RDD B的时候,是窄依赖,所以不切分Stage,再往前到RDD A,此时产生了宽依赖,所以RDD A属于一个Stage、RDD B 和 G属于一个Stage。再看下面,RDD G到RDD F,产生了宽依赖,所以RDD F属于一个Stage,因为RDD F和 RDD C、D、E这几个RDD没有产生宽依赖,都是窄依赖,所以他们属于一个Stage。所以这个图中,RDD A 单独一个stage1,RDD C、D、E、F被划分在stage2中,最后RDD B和RDD G划分在了stage3 里面.
注意:Stage划分是从后往前划分,但是stage执行时从前往后的,这就是为什么后面先切割的stage为什么编号是3.
Spark Job的三种提交模式
- 第一种,standalone模式,基于Spark自己的standalone集群。 指定–master spark://bigdata01:7077
- 第二种,是基于YARN的client模式。指定–master yarn --deploy-mode client 这种方式主要用于测试,查看日志方便一些,部分日志会直接打印到控制台上面,因为driver进程运行在本地客户端,就是提交Spark任务的那个客户端机器,driver负责调度job,会与yarn集群产生大量的通信,一般情况下Spark客户端机器和Hadoop集群的机器是无法内网通信,只能通过外网,这样在大量通信的情况下会影响通信效率,并且当我们执行一些action操作的时候数据也会返回给driver端,driver端机器的配置一般都不高,可能会导致内存溢出等问题。
- 第三种,是基于YARN的cluster模式。【推荐】指定–master yarn --deploy-mode cluster 这种方式driver进程运行在集群中的某一台机器上,这样集群内部节点之间通信是可以通过内网通信的,并且集群内的机器的配置也会比普通的客户端机器配置高,所以就不存在yarn-client模式的一些问题了,只不过这个时候查看日志只能到集群上面看了,这倒没什么影响。
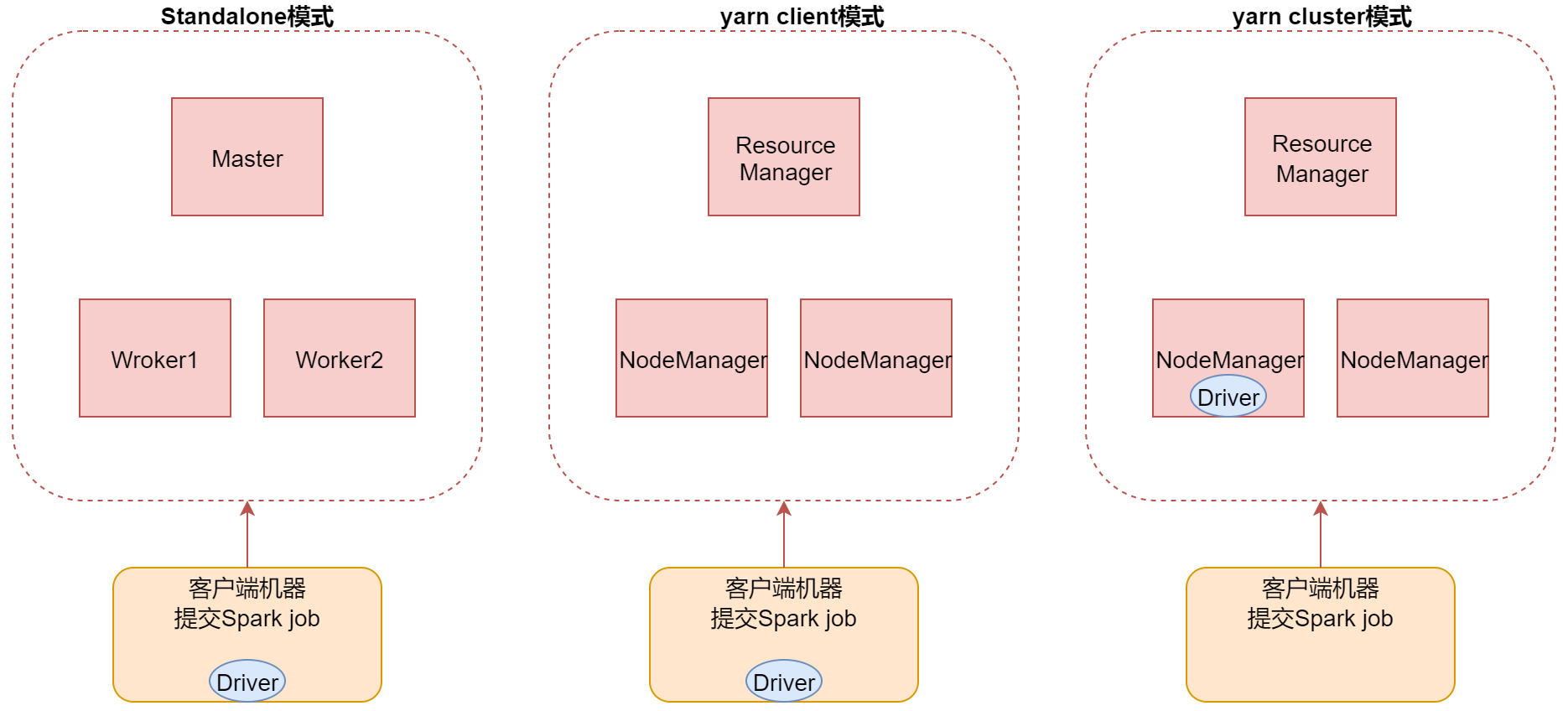
左边是standalone模式,现在我们使用的提交方式,driver进程是在客户端机器中的,其实针对standalone模式而言,这个Driver进程也是可以运行在集群中的。
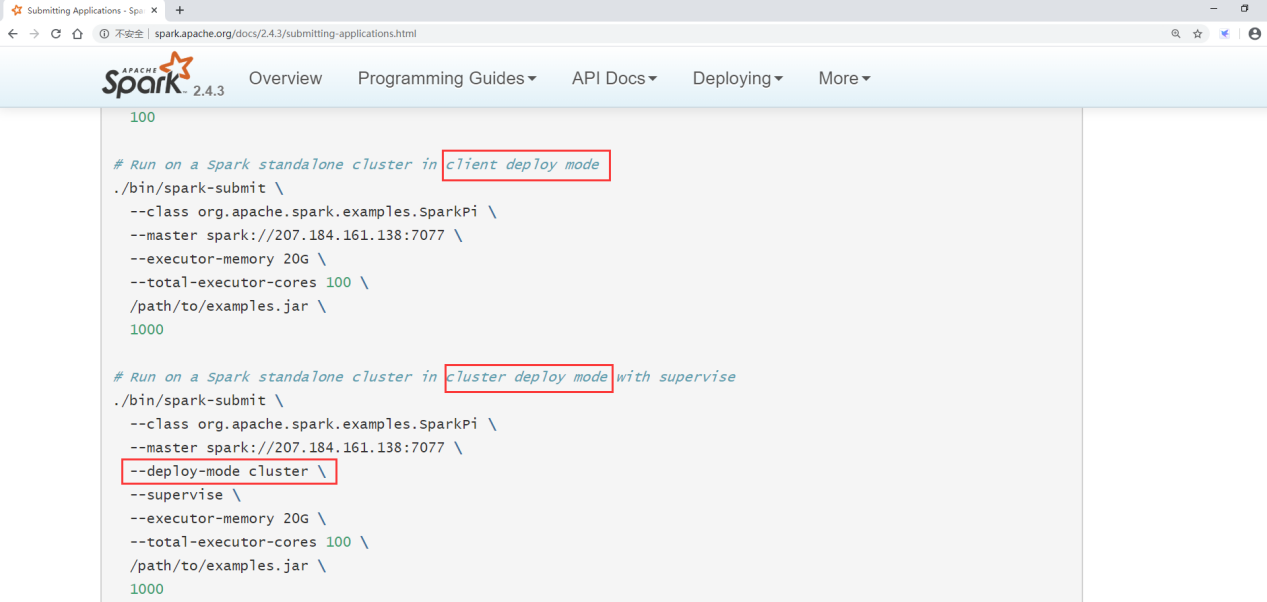
来看一下官网文档,standalone模式也是支持的,通过指定deploy-mode 为cluster即可
中间的值yarn client模式,由于是on yarn模式,所以里面是yarn集群的进程,此时driver进程就在提交spark任务的客户端机器上了。最右边这个是yarn cluster模式,driver进程就会在集群中的某一个节点上面。
Shuffle机制分析
在MapReduce框架中,Shuffle是连接Map和Reduce之间的桥梁,Map阶段通过shuffle读取数据并输出到对应的Reduce;而Reduce阶段负责从Map端拉取数据并进行计算。在整个shuffle过程中,往往伴随着大量的磁盘和网络I/O。所以shuffle性能的高低也直接决定了整个程序的性能高低。Spark也会有自己的shuffle实现过程。
我们首先来看一下
在Spark中,什么情况下,会发生shuffle?
reduceByKey、groupByKey、sortByKey、countByKey、join等操作都会产生shuffle。那下面我们来详细分析一下Spark中的shuffle过程。Spark的shuffle历经了几个过程
- Spark 0.8及以前 使用Hash Based Shuffle
- Spark 0.8.1 为Hash Based Shuffle引入File Consolidation机制
- Spark1.6之后使用Sort-Base Shuffle,因为Hash Based Shuffle存在一些不足所以就把它替换掉了。
所以Spark Shuffle 一共经历了这几个过程:
- 未优化的 Hash Based Shuffle
- 优化后的Hash Based Shuffle
- Sort-Based Shuffle
未优化的Hash Based Shuffle
来看一个图,假设我们是在执行一个reduceByKey之类的操作,此时就会产生shuffle。
shuffle里面会有两种task,一种是shuffleMapTask,负责拉取前一个RDD中的数据,还有一个ResultTask,负责把拉取到的数据按照规则汇总起来
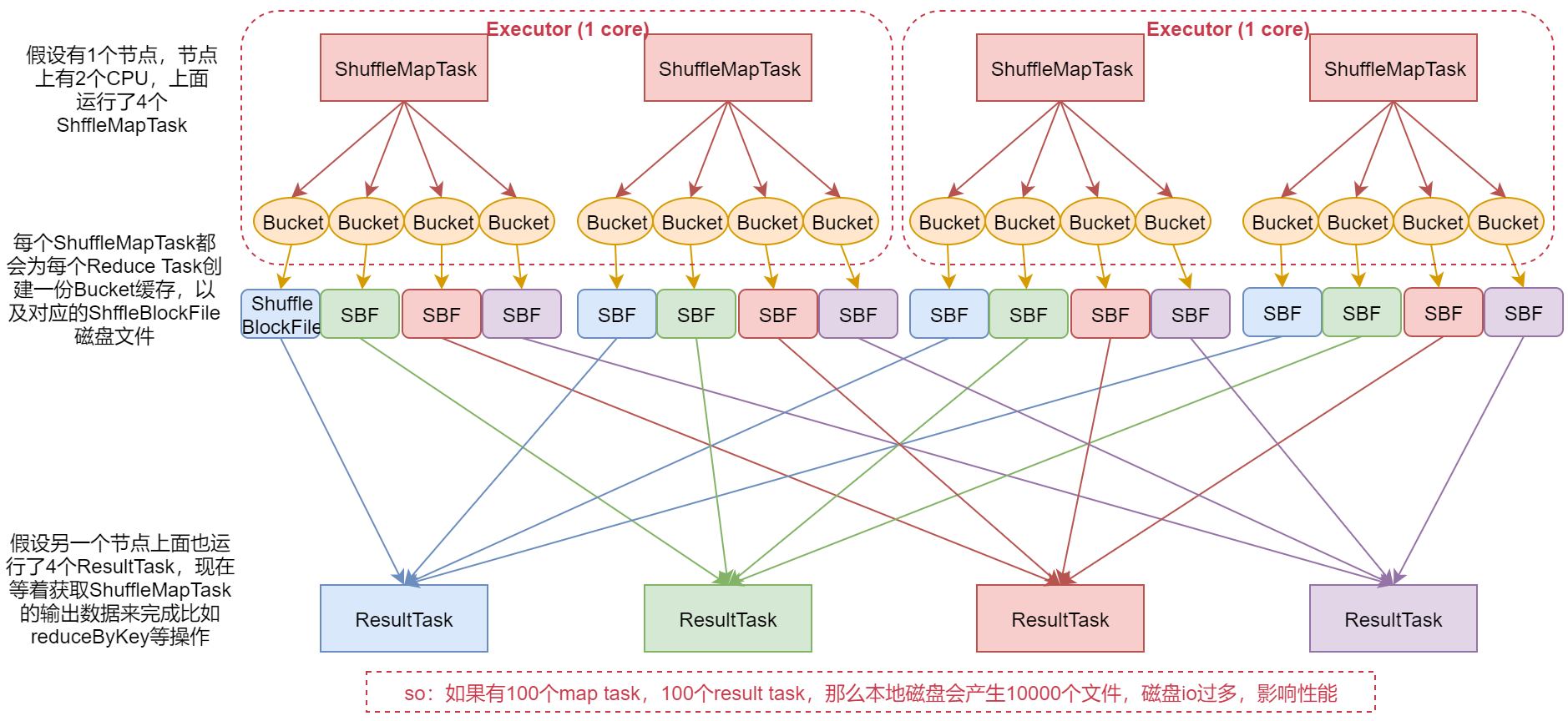
1:假设有1个节点,这个节点上有2个CPU,上面运行了4个ShuffleMapTask,这样的话其实同时只有2个ShuffleMapTask是并行执行的,因为一个cpu core同时只能执行一个ShuffleMapTask。
2:每个ShuffleMapTask都会为每个ResultTask创建一份Bucket缓存,以及对应的ShuffleBlockFile磁盘文件这样的话,每一个ShuffleMapTask都会产生4份Bucket缓存和对应的4个ShuffleBlockFile文件,分别对应下面的4个ResultTask
3:假设另一个节点上面运行了4个ResultTask现在等着获取ShuffleMapTask的输出数据,来完成比如ReduceByKey的操作。
这是这个流程,注意了,如果有100个MapTask,100个ResultTask,那么会产生10000个本地磁盘文件,这样需要频繁的磁盘IO,是比较影响性能的。
注意,那个bucket缓存是非常重要的,ShuffleMapTask会把所有的数据都写入Bucket缓存之后,才会刷写到对应的磁盘文件中,但是这就有一个问题,如果map 端数据过多,那么很容易造成内存溢出,所以spark在优化后的Hash Based Shuffle中对这个问题进行了优化,默认这个内存缓存是100kb,当Bucket中的数据达到了阈值之后,就会将数据一点一点地刷写到对应的ShuffleBlockFile磁盘中了。这种操作的优点,是不容易发生内存溢出。缺点在于,如果内存缓存过小的话,那么可能发生过多的磁盘io操作。所以,这里的内存缓存大小,是可以根据实际的业务情况进行优化的。
优化后的Hash Based Shuffle
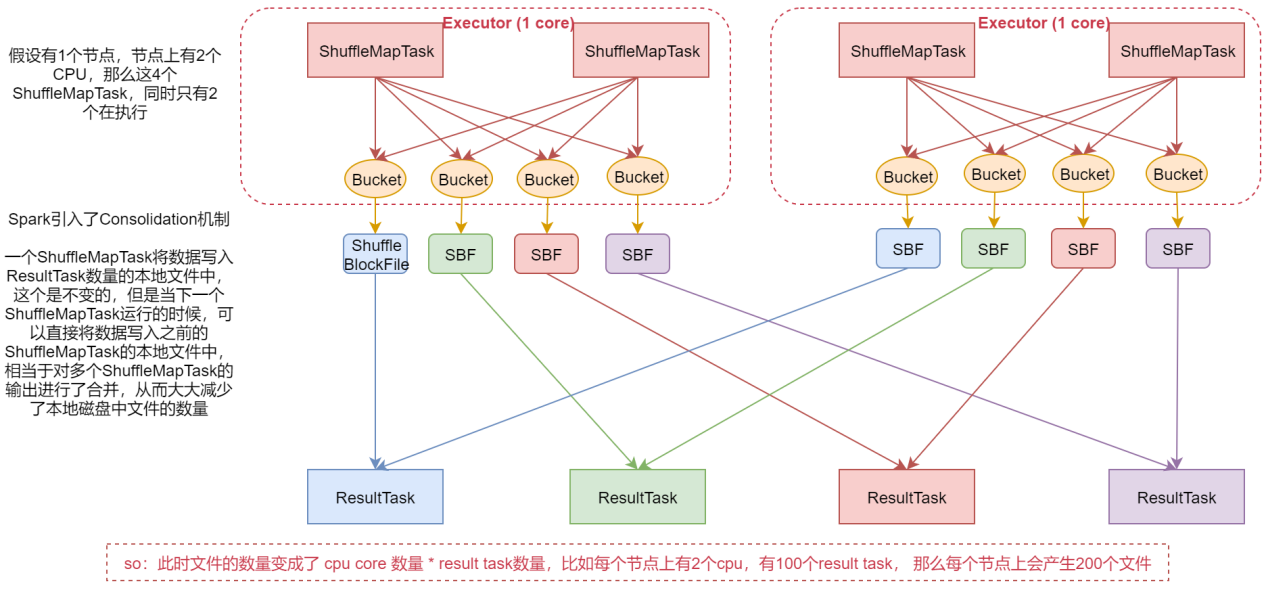
看这个优化后的shuffle流程
1:假设机器上有2个cpu,4个shuffleMaptask,这样同时只有2个在并行执行
2:在这个版本中,Spark引入了consolidation机制,一个ShuffleMapTask将数据写入ResultTask数量的本地文件中,这个是不变的,但是当下一个ShuffleMapTask运行的时候,可以直接将数据写入之前产生的本地文件中,相当于对多个ShuffleMapTask的输出进行了合并,从而大大减少了本地磁盘中文件的数量。
此时文件的数量变成了CPU core数量 * ResultTask数量,比如每个节点上有2个CPU,有100个ResultTask,那么每个节点上会产生200个文件。这个时候文件数量就变得少多了。但是如果 ResultTask端的并行任务过多的话则 CPU core * Result Task 依旧过大,也会产生很多小文件
Sort-Based Shuffle
引入 Consolidation 机制虽然在一定程度上减少了磁盘文件数量,但是不足以有效提高 Shuffle 的性能,这种情况只适合中小型数据规模的数据处理。为了让 Spark 能在更大规模的集群上高性能处理大规模的数据,因此 Spark 引入了 Sort-Based Shuffle。
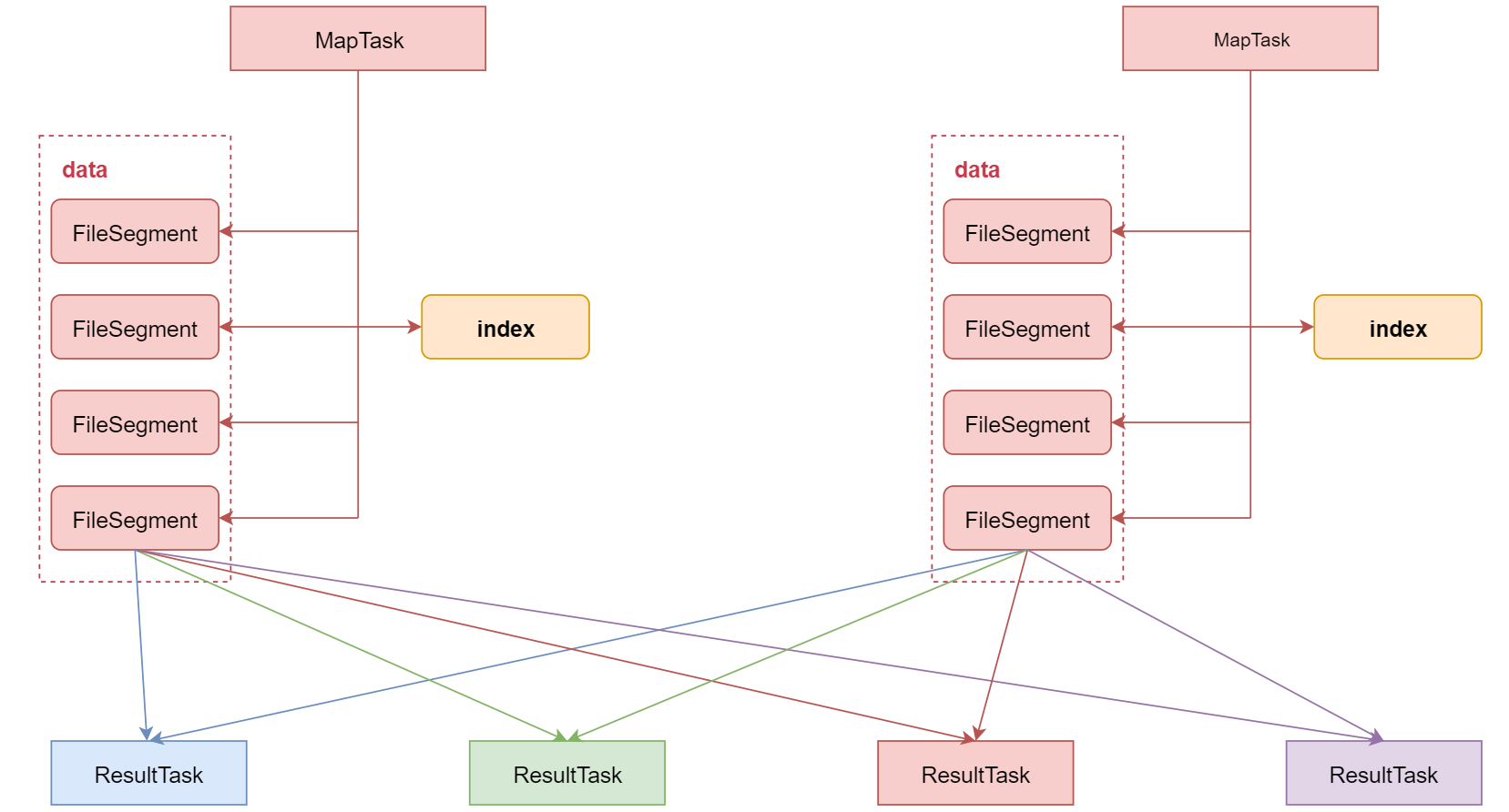
该机制针对每一个 ShuffleMapTask 都只创建一个文件,将所有的 ShuffleMapTask 的数据都写入同一个文件,并且对应生成一个索引文件。
以前的数据是放在内存中,等到数据写完了再刷写到磁盘,现在为了减少内存的使用,在内存不够用的时候,可以将内存中的数据溢写到磁盘,结束的时候,再将这些溢写的文件联合内存中的数据一起进行归并,从而减少内存的使用量。一方面文件数量显著减少,另一方面减少缓存所占用的内存大小,而且同时避免 GC 的风险和频率。
Spark之checkpoint
checkpoint概述
checkpoint是Spark提供的一个比较高级的功能。有时候,我们的Spark任务,比较复杂,从初始化RDD开始,到最后整个任务完成,有比较多的步骤,比如超过10个transformation算子。而且,整个任务运行的时间也特别长,比如通常要运行1~2个小时。在这种情况下,就比较适合使用checkpoint功能了。
因为对于特别复杂的Spark任务,有很高的风险会出现某个要反复使用的RDD因为节点的故障导致丢失,虽然之前持久化过,但是还是导致数据丢失了。那么也就是说,出现失败的时候,没有容错机制,所以当后面的transformation算子,又要使用到该RDD时,就会发现数据丢失了,此时如果没有进行容错处理的话,那么就需要再重新计算一次数据了。所以针对这种Spark Job,如果我们担心某些关键的,在后面会反复使用的RDD,因为节点故障导致数据丢失,那么可以针对该RDD启动checkpoint机制,实现容错和高可用
那如何使用checkPoint呢?
首先要调用SparkContext的setCheckpointDir()方法,设置一个容错的文件系统的目录,比如HDFS;然后,对RDD调用checkpoint()方法。最后,在RDD所在的job运行结束之后,会启动一个单独的job,将checkpoint设置过的RDD的数据写入之前设置的文件系统中。这是checkpoint使用的基本步骤,很简单,那我们下面先从理论层面分析一下当我们设置好checkpoint之后,Spark底层都做了哪些事情
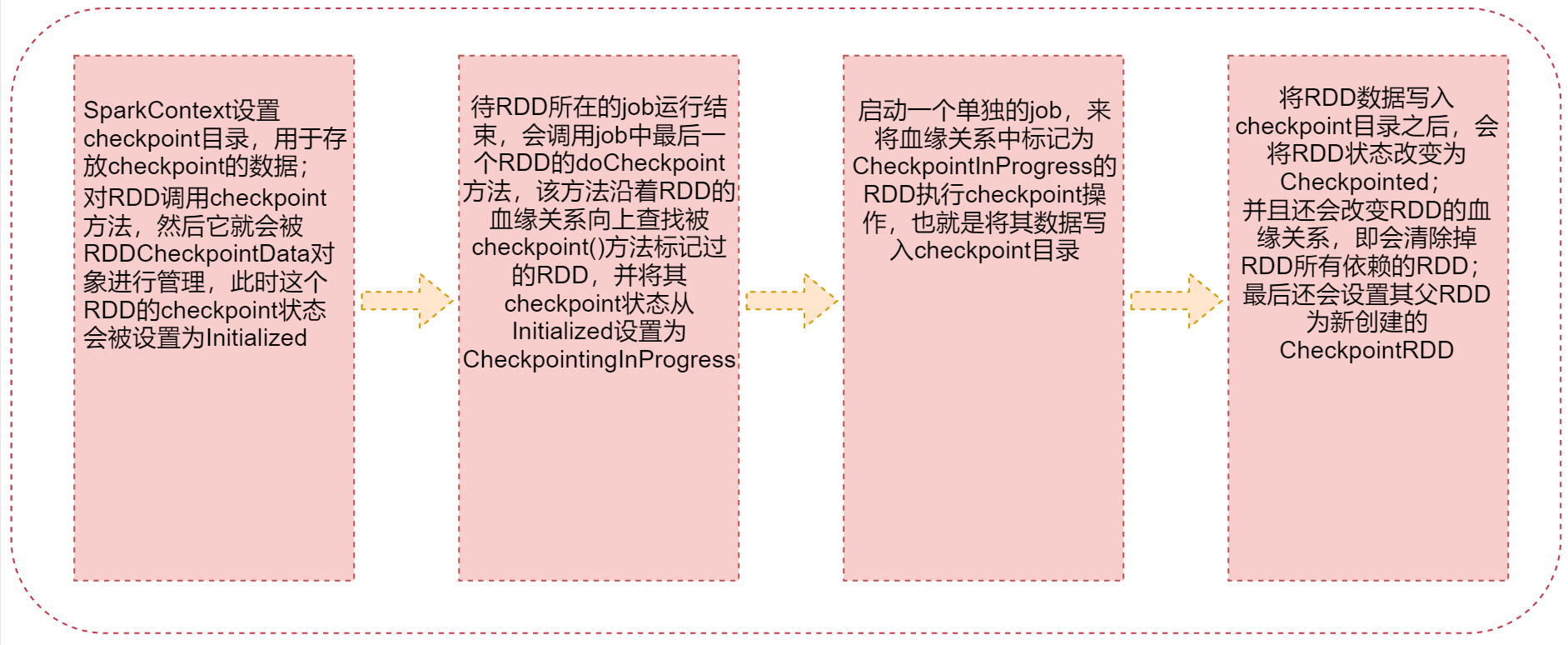
1:SparkContext设置checkpoint目录,用于存放checkpoint的数据;对RDD调用checkpoint方法,然后它就会被RDDCheckpointData对象进行管理,此时这个RDD的checkpoint状态会被设置为Initialized
2:待RDD所在的job运行结束,会调用job中最后一个RDD的doCheckpoint方法,该方法沿着RDD的血缘关系向上查找被checkpoint()方法标记过的RDD,并将其checkpoint状态从Initialized设置为
CheckpointingInProgress
3:启动一个单独的job,来将血缘关系中标记为CheckpointInProgress的RDD执行checkpoint操作,也就是将其数据写入checkpoint目录
4:将RDD数据写入checkpoint目录之后,会将RDD状态改变为Checkpointed;并且还会改变RDD的血缘关系,即会清除掉RDD所有依赖的RDD;最后还会设置其父RDD为新创建的CheckpointRDD
checkpoint与持久化的区别
这里所说的checkpoint和我们之前讲的RDD持久化有什么区别吗?
- lineage是否发生改变 linage(血缘关系)说的就是RDD之间的依赖关系 持久化,只是将数据保存在内存中或者本地磁盘文件中,RDD的lineage(血缘关系)是不变的;Checkpoint执行之后,RDD就没有依赖的RDD了,也就是它的lineage改变了
- 丢失数据的可能性 持久化的数据丢失的可能性较大,如果采用 persist 把数据存在内存中的话,虽然速度最快但是也是最不可靠的,就算放在磁盘上也不是完全可靠的,因为磁盘也会损坏。Checkpoint的数据通常是保存在高可用文件系统中(HDFS),丢失的可能性很低
建议:对需要checkpoint的RDD,先执行persist(StorageLevel.DISK_ONLY) 为什么呢?
因为默认情况下,如果某个RDD没有持久化,但是设置了checkpoint,那么这个时候,本来Spark任务已经执行结束了,但是由于中间的RDD没有持久化,在进行checkpoint的时候想要将这个RDD的数据写入外部存储系统的话,就需要重新计算这个RDD的数据,再将其checkpoint到外部存储系统中。
如果对需要checkpoint的rdd进行了基于磁盘的持久化,那么后面进行checkpoint操作时,就会直接从磁盘上读取rdd的数据了,就不需要重新再计算一次了,这样效率就高了。那在这能不能使用基于内存的持久化呢?当然是可以的,不过没那个必要。
checkPoint的使用
演示一下:将一个RDD的数据持久化到HDFS上面
scala代码如下:
packagecom.imooc.scalaimportorg.apache.spark.{SparkConf, SparkContext}/**
* 需求:checkpoint的使用
*/object CheckPointOpScala {def main(args: Array[String]):Unit={val conf =new SparkConf()
conf.setAppName("CheckPointOpScala")val sc =new SparkContext(conf)if(args.length==0){
System.exit(100)}val outputPath = args(0)//1:设置checkpint目录
sc.setCheckpointDir("hdfs://bigdata01:9000/chk001")val dataRDD = sc.textFile("hdfs://bigdata01:9000/hello_10000000.dat")//2:对rdd执行checkpoint操作
dataRDD.checkpoint()
dataRDD.flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _).saveAsTextFile(outputPath)
sc.stop()}}
下面我们把这个任务打包提交到集群上运行一下,看一下效果。先确保hadoop集群是正常运行的,以及hadoop中的historyserver进程和spark的historyserver进程也是正常运行的。测试数据之前已经上传到了hdfs上面,如果没有则需要上传
[root@bigdata01 soft]# hdfs dfs -ls /hello_10000000.dat
-rw-r--r--2 root supergroup 18601000002020-04-2822:15/hello_10000000.dat
将pom.xml中的spark-core的依赖设置为provided,然后编译打包
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>2.4.3</version><scope>provided</scope></dependency>
将打包的jar包上传到bigdata04的/data/soft/sparkjars目录,创建一个新的spark-submit脚本
[root@bigdata04 sparkjars]# cp wordCountJob.sh checkPointJob.sh[root@bigdata04 sparkjars]# vi checkPointJob.sh
spark-submit \--class com.imooc.scala.CheckPointOpScala \--masteryarn\
--deploy-mode cluster \
--executor-memory 1G \
--num-executors 1\
db_spark-1.0-SNAPSHOT-jar-with-dependencies.jar \
/out-chk001
提交任务
[root@bigdata04 sparkjars]# sh -x checkPointJob.sh
执行成功之后可以到 setCheckpointDir 指定的目录中查看一下,可以看到目录中会生成对应的文件保存rdd中的数据,只不过生成的文件不是普通文本文件,直接查看文件中的内容显示为乱码。
接下来进到YARN的8088界面查看
点击Tracking UI进入spark的ui界面
看第一个界面jobs
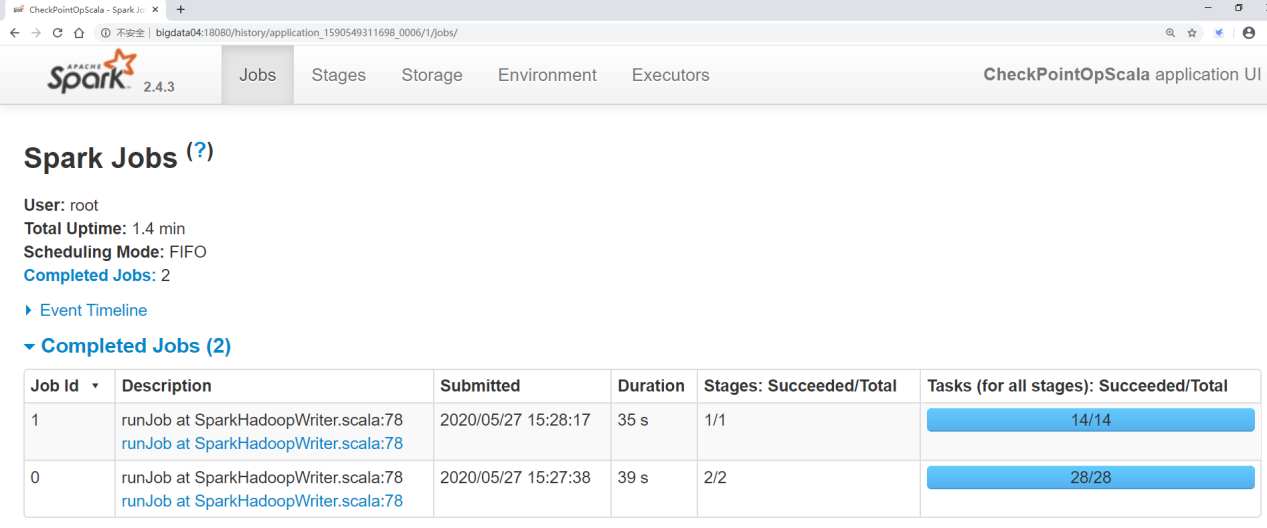
在这可以看出来产生了2个job,
第一个job是我们正常的任务执行,执行了39s,一共产生了28个task任务
第二个job是checkpoint启动的job,执行了35s,一共产生了14个task任务
stage id:stage的编号,从0开始
Duration:stage执行消耗的时间
Tasks:Successed/Total:task执行成功数量/task总量
Input:输入数据量
ouput:输出数据量
shuffle read/shuffle read:shuffle过程传输数据量
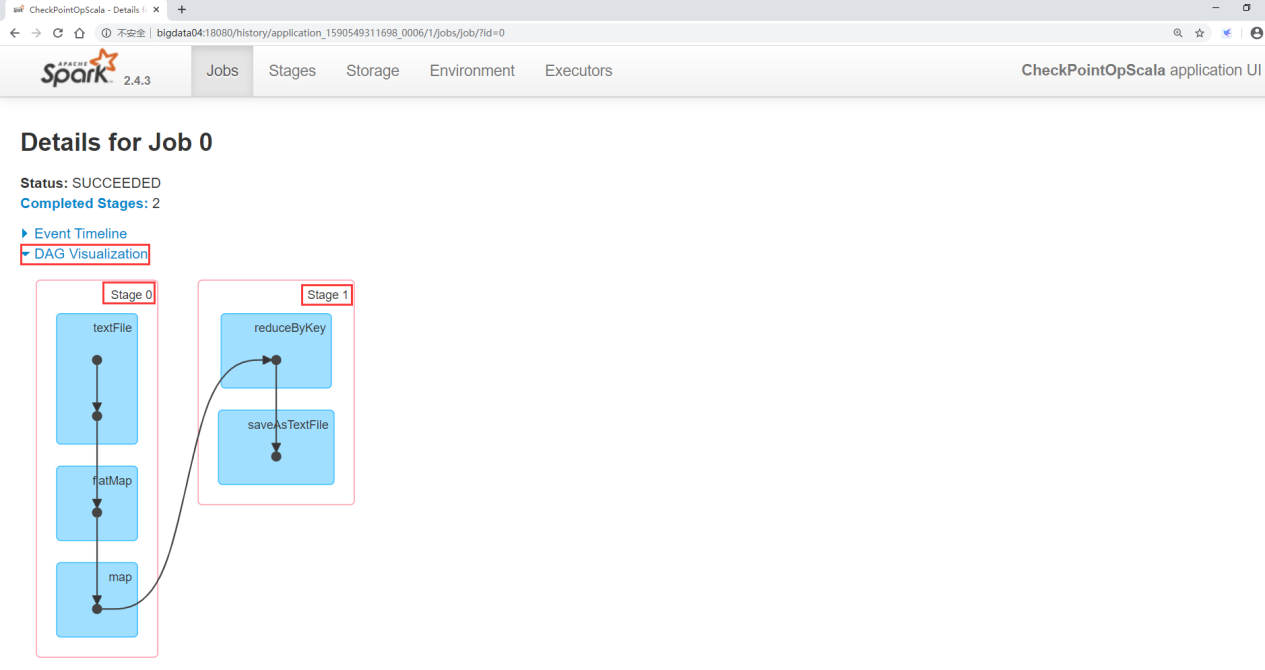
点击这个界面中的DAG Visualization可以看到当前这个任务stage的划分情况,可以看到每个Stage包含哪些算子
checkpoint源码分析
前面我们通过理论层面分析了checkpoint的原理,以及演示了checkpoint的使用。下面我们通过源码层面来对我们前面分析的理论进行验证。先下载spark源码,下载流程和下载spark安装包的流程一样
把下载的安装包解压到idea项目目录中
打开spark-2.4.3源码目录,进入core目录,这个是spark的核心代码,我们要查看的checkpoint的源码就在这个项目中。在idea中打开core这个子项目
下面我们就来分析一下RDD的checkpoint功能:
checkpoint功能可以分为两块
1:checkpoint的写操作
将指定RDD的数据通过checkpoint存储到指定外部存储中
2:checkpoint的读操作
任务中RDD数据在使用过程中丢失了,正好这个RDD之前做过checkpoint,所以这时就需要通过checkpoint来恢复数据
先看checkpoint的写操作
1.1 : 当 我 们 在 自 己 开 发 的 spark 任 务 中 先 调 用 sc.setCheckpointDir 时 , 底 层 其 实 就 会 调 用SparkContext中的 setCheckpointDir 方法
def setCheckpointDir(directory:String){// If we are running on a cluster, log a warning if the directory is local.// Otherwise, the driver may attempt to reconstruct the checkpointed RDD fr// its own local file system, which is incorrect because the checkpoint fil// are actually on the executor machines.if(!isLocal && Utils.nonLocalPaths(directory).isEmpty){
logWarning("Spark is not running in local mode, therefore the checkpoint
s"must not be on the local filesystem. Directory '$directory' "+"appears to be on the local filesystem.")}//根据我们传过来的目录,后面再拼上一个子目录,子目录使用一个UUID随机字符串//使用HDFS的javaAPI 在HDFS上创建目录
checkpointDir = Option(directory).map { dir =>val path =new Path(dir, UUID.randomUUID().toString)val fs = path.getFileSystem(hadoopConfiguration)
fs.mkdirs(path)
fs.getFileStatus(path).getPath.toString
}}
1.2:接着我们会调用 RDD.checkpoint 方法,此时会执行RDD这个class中的 checkpoint 方法
//这里相当于是checkpoint的一个标记,并没有真正执行checkpointdef checkpoint():Unit= RDDCheckpointData.synchronized {// NOTE: we use a global lock here due to complexities downstream with ensu// children RDD partitions point to the correct parent partitions. In the f// we should revisit this consideration.//如果SparkContext没有设置checkpointDir,则抛出异常if(context.checkpointDir.isEmpty){thrownew SparkException("Checkpoint directory has not been set in the Sp
}elseif(checkpointData.isEmpty){//如果设置了,则创建RDDCheckpointData的子类,这个子类主要负责管理RDD的checkpoi//并且会初始化checkpoint状态为Initialized
checkpointData = Some(new ReliableRDDCheckpointData(this))}}
这个checkpoint方法执行完成之后,这个流程就结束了。
1.3:剩下的就是在这个设置了checkpint的RDD所在的job执行结束之后,Spark会调用job中最后一个RDD的 doCheckpoint 方法。
这个逻辑是在SparkContext这个class的runJob方法中,当执行到Spark中的action算子时,这个runJob方法会被触发,开始执行任务。
这个runJob的最后一行会调用rdd中的 doCheckpoint 方法
//在有action动作时,会触发sparkcontext对runJob的调用def runJob[T, U: ClassTag](
rdd: RDD[T],
func:(TaskContext, Iterator[T])=> U,
partitions: Seq[Int],
resultHandler:(Int, U)=>Unit):Unit={if(stopped.get()){thrownew IllegalStageException("SparkContext has been shutdown")}val callSite = getCallSite
val cleanedFunc = clean(func)
logInfo("Starting job: "+ callSite.shortForm)if(conf.getBoolean("spark.logLineage",false)){
logInfo("RDD's recursive dependencies:\n"+ rdd.toDebugString)}
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler,
progressBar.foreach(_.finishAll())//在这里会执行doCheckpoint()
rdd.doCheckpoint()}
1.4:接着会进入到RDD中的 doCheckpoint 方法
这里面最终会调用 RDDCheckpointData 的 checkpoint 方法
checkpointData.get.checkpoint()
1.5:接下来进入到 RDDCheckpointData 的 checkpoint 方法中
这里面会调用子类 ReliableCheckpointRDD 中的 doCheckpoint() 方法
finaldef checkpoint():Unit={// Guard against multiple threads checkpointing the same RDD by// atomically flipping the Stage of this RDDCheckpointData将checkpoint的状态从Initialized置为CheckpointingInProgress
RDDCheckpointData.synchronized {if(cpStage == Initialized){
cpStage = CheckpointingInProgress
}else{return}}//调用子类的doCheckpoint,默认会使用ReliableCheckpointRDD子类,创建一个新的Checval newRDD = doCheckpoint()// Update our Stage and truncate the RDD lineage//将checkpoint状态置为Checkpointed状态,并且改变rdd之前的依赖,设置父rdd为新创建
RDDCheckpointData.synchronized {
cpRDD = Some(newRDD)
cpStage = Checkpointed
rdd.markCheckpointed()}}
1.6:接着来进入 ReliableCheckpointRDD 中的 doCheckpoint() 方法。
这里面会调用 ReliableCheckpointRDD 中的 writeRDDToCheckpointDirectory 方法将rdd的数据写入HDFS中的 checkpoint 目录,并且返回创建的 CheckpointRDD
1.7:接下来进入 ReliableCheckpointRDD 的writeRDDToCheckpointDirectory 方法
这里面最终会启动一个job,将checkpoint的数据写入到指定的HDFS目录中
Spark程序性能优化
性能优化分析
一个计算任务的执行主要依赖于CPU、内存、带宽。Spark是一个基于内存的计算引擎,所以对它来说,影响最大的可能就是内存,一般我们的任务遇到了性能瓶颈大概率都是内存的问题,当然了CPU和带宽也可能会影响程序的性能,这个情况也不是没有的,只是比较少。
Spark性能优化,其实主要就是在于对内存的使用进行调优。通常情况下,如果你的Spark程序计算的数据量比较小,并且你的内存足够使用,那么只要网络不至于卡死,一般是不会有大的性能问题的。但是Spark程序的性能问题往往出现在针对大数据量进行计算(比如上亿条数的数据,或者上T规模的数据),这个时候如果内存分配不合理就会比较慢,所以,Spark性能优化,主要是对内存进行优化。
内存都去哪了
- 每个Java对象,都有一个对象头,会占用16个字节,主要是包括了一些对象的元信息,比如指向它的类的指针。如果一个对象本身很小,比如就包括了一个int类型的field,那么它的对象头实际上比对象自身还要大。
- Java的String对象的对象头,会比它内部的原始数据,要多出40个字节。因为它内部使用char数组来保存内部的字符序列,并且还要保存数组长度之类的信息。
- Java中的集合类型,比如HashMap和LinkedList,内部使用的是链表数据结构,所以对链表中的每一个数据,都使用了Entry对象来包装。Entry对象不光有对象头,还有指向下一个Entry的指针,通常占用8个字节。
所以把原始文件中的数据转化为内存中的对象之后,占用的内存会比原始文件中的数据要大。那我如何预估程序会消耗多少内存呢?
通过cache方法,可以看到RDD中的数据cache到内存中之后占用多少内存,这样就能看出了
代码如下:这个测试代码就只写一个scala版本的了
packagecom.imooc.scalaimportorg.apache.spark.{SparkConf, SparkContext}/**
* 需求:测试内存占用情况
*/object TestMemoryScala {def main(args: Array[String]):Unit={val conf =new SparkConf()
conf.setAppName("TestMemoryScala").setMaster("local")val sc =new SparkContext(conf)val dataRDD = sc.textFile("hdfs://bigdata01:9000/hello_10000000.dat").cache()val count = dataRDD.count()
println(count)//while循环是为了保证程序不结束,方便在本地查看4040页面中的storage信息while(true){;}}}
执行代码,访问localhost的4040端口界面
这个界面其实就是spark的任务界面,在本地运行任务的话可以直接访问4040界面查看。
点击stages可以看到任务的原始输入数据是多大
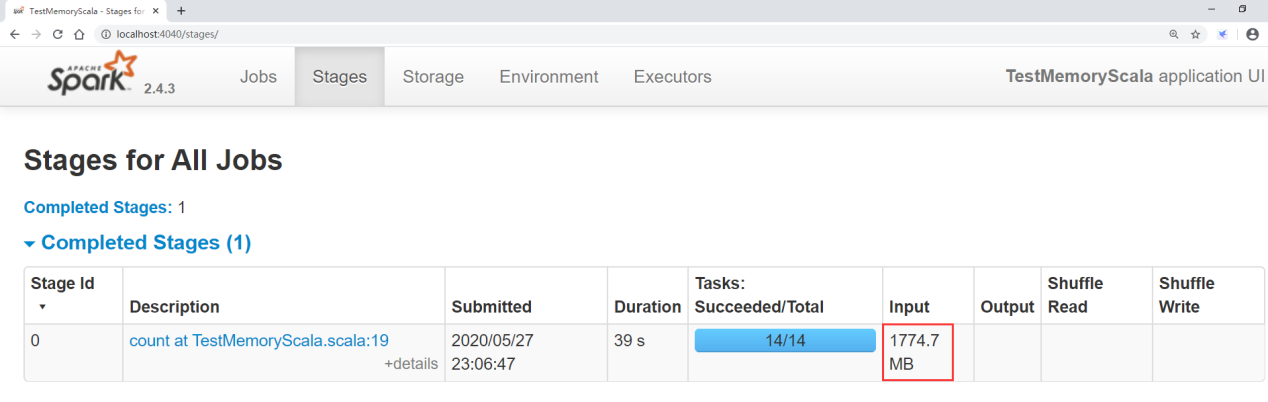
点击storage可以看到将数据加载到内存,生成RDD之后的大小
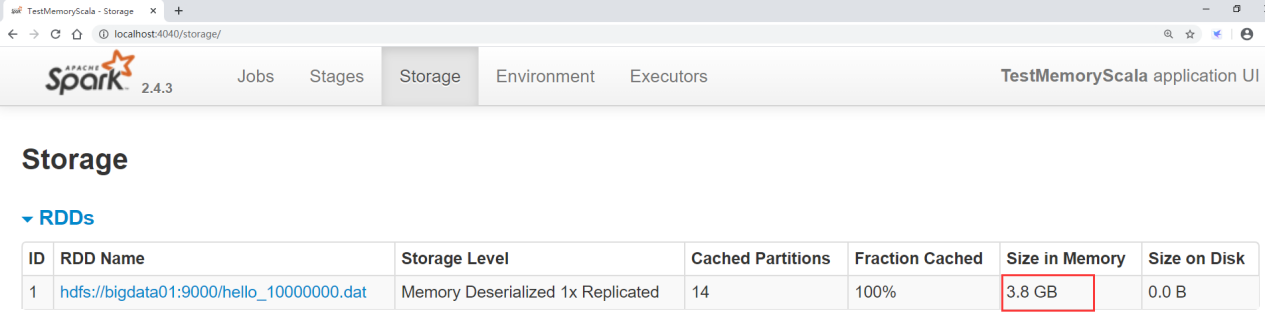
这样我们就能知道这一份数据在RDD中会占用多少内存了,这样在使用的时候,如果想要把数据全部都加载进内存,就需要给这个任务分配这么多内存了,当然了你分配少一些也可以,只不过这样计算效率会变低,因为RDD中的部分数据内存放不下就会放到磁盘了。
性能优化方案
下面我们通过这几个方式来实现对Spark程序的性能优化
- 高性能序列化类库
- 持久化或者checkpoint
- JVM垃圾回收调优
- 提高并行度
- 数据本地化
- 算子优化
高性能序列化类库
在任何分布式系统中,序列化都是扮演着一个重要的角色的。
如果使用的序列化技术,在执行序列化操作的时候很慢,或者是序列化后的数据还是很大,那么会让分布式应用程序的性能下降很多。所以,进行Spark性能优化的第一步,就是进行序列化的性能优化。Spark默认会在一些地方对数据进行序列化,如果我们的算子函数使用到了外部的数据(比如Java中的自定义类型),那么也需要让其可序列化,否则程序在执行的时候是会报错的,提示没有实现序列化,这个一定要注意。
原因是这样的:
因为Spark的初始化工作是在Driver进程中进行的,但是实际执行是在Worker节点的Executor进程中进行的;当Executor端需要用到Driver端封装的对象时,就需要把Driver端的对象通过序列化传输到Executor端,这个对象就需要实现序列化。否则会报错,提示对象没有实现序列化
注意了,其实遇到这种没有实现序列化的对象,解决方法有两种
- 如果此对象可以支持序列化,则将其实现Serializable接口,让它支持序列化
- 如果此对象不支持序列化,针对一些数据库连接之类的对象,这种对象是不支持序列化的,所以可以把这个代码放到算子内部,这样就不会通过driver端传过去了,它会直接在executor中执行。
Spark对于序列化的便捷性和性能进行了一个取舍和权衡。默认情况下,Spark倾向于序列化的便捷性,使用了Java自身提供的序列化机制——基于 ObjectInputStream 和 ObjectOutputStream 的序列化机制,因为这种方式是Java原生提供的,使用起来比较方便,但是Java序列化机制的性能并不高。序列化的速度相对较慢,而且序列化以后的数据,相对来说还是比较大,比较占空间。所以,如果你的Spark应用程序对内存很敏感,那默认的Java序列化机制并不是最好的选择。
Spark实际上提供了两种序列化机制:
Java序列化机制和Kryo序列化机制
Spark只是默认使用了java这种序列化机制
- Java序列化机制:默认情况下,Spark使用Java自身的ObjectInputStream和ObjectOutputStream机制进行对象的序列化。只要你的类实现了Serializable接口,那么都是可以序列化的。Java序列化机制的速度比较慢,而且序列化后的数据占用的内存空间比较大,这是它的缺点
- Kryo序列化机制:Spark也支持使用Kryo序列化。Kryo序列化机制比Java序列化机制更快,而且序列化后的数据占用的空间更小,通常比Java序列化的数据占用的空间要小10倍左右。
Kryo序列化机制之所以不是默认序列化机制的原因:
- 第一点:因为有些类型虽然实现了Seriralizable接口,但是它也不一定能够被Kryo进行序列化;
- 第二点:如果你要得到最佳的性能,Kryo还要求你在Spark应用程序中,对所有你需要序列化的类型都进行手工注册,这样就比较麻烦了
如果要使用Kryo序列化机制
首先要用 SparkConf 设置 spark.serializer 的值为 org.apache.spark.serializer.KryoSerializer ,就是将Spark的序列化器设置为 KryoSerializer 。这样,Spark在进行序列化时,就会使用Kryo进行序列化了。使用Kryo时针对需要序列化的类,需要预先进行注册,这样才能获得最佳性能——如果不注册的话,Kryo也能正常工作,只是Kryo必须时刻保存类型的全类名,反而占用不少内存。
Spark默认对Scala中常用的类型在Kryo中做了注册,但是,如果在自己的算子中,使用了外部的自定义类型的对象,那么还是需要对其进行注册。
注册自定义的数据类型格式:
conf.registerKryoClasses(...)
注意:如果要序列化的自定义的类型,字段特别多,此时就需要对Kryo本身进行优化,因为Kryo需要调用 SparkConf.set() 方法,设置 spark.kryoserializer.buffer.mb 参数的值,将其调大,默认值为 2 ,单位是 MB ,也就是说最大能缓存 2M 的对象,然后进行序列化。可以在必要时将其调大。
什么场景下适合使用Kryo序列化?
一般是针对一些自定义的对象,例如我们自己定义了一个对象,这个对象里面包含了几十M,或者上百M的数据,然后在算子函数内部,使用到了这个外部的大对象。
如果默认情况下,让Spark用java序列化机制来序列化这种外部的大对象,那么就会导致序列化速度比较慢,并且序列化以后的数据还是比较大。所以,在这种情况下,比较适合使用Kryo序列化类库,来对外部的大对象进行序列化,提高序列化速度,减少序列化后的内存空间占用。
用代码实现一个案例:
scala代码如下:
`
packagecom.imooc.scalaimportcom.esotericsoftware.kryo.Kryo
importorg.apache.spark.serializer.KryoRegistrator
importorg.apache.spark.storage.StorageLevel
importorg.apache.spark.{SparkConf, SparkContext}/**
* 需求:Kryo序列化的使用
*/object KryoSerScala {def main(args: Array[String]):Unit={val conf =new SparkConf()
conf.setAppName("KryoSerScala").setMaster("local")//指定使用kryo序列化机制,注意:如果使用了registerKryoClasses,其实这一行设置.set("spark.serializer","org.apache.spark.serializer.KryoSerializer").registerKryoClasses(Array(classOf[Person]))//注册自定义的数据类型val sc =new SparkContext(conf)val dataRDD = sc.parallelize(Array("hello you","hello me"))val wordsRDD = dataRDD.flatMap(_.split(" "))val personRDD = wordsRDD.map(word=>Person(word,18)).persist(StorageLevel.M
personRDD.foreach(println(_))//while循环是为了保证程序不结束,方便在本地查看4040页面中的storage信息while(true){;}}}caseclass Person(name:String,age:Int)extends Serializable
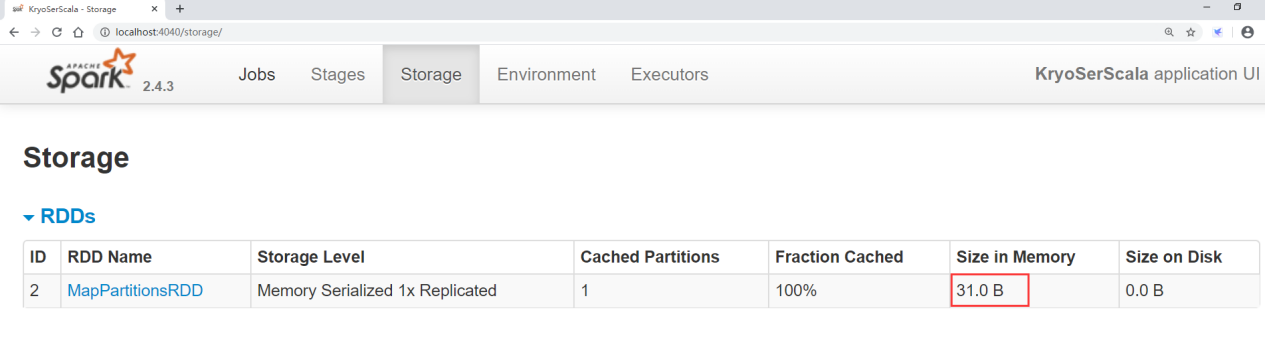
执行任务,然后访问localhost的4040界面
在界面中可以看到cache的数据大小是 31 字节。
那我们把kryo序列化设置去掉,使用默认的java序列化看一下效果
修改代码,注释掉这两行代码即可
//.set("spark.serializer","org.apache.spark.serializer.KryoSerializer")//.registerKryoClasses(Array(classOf[Person]))
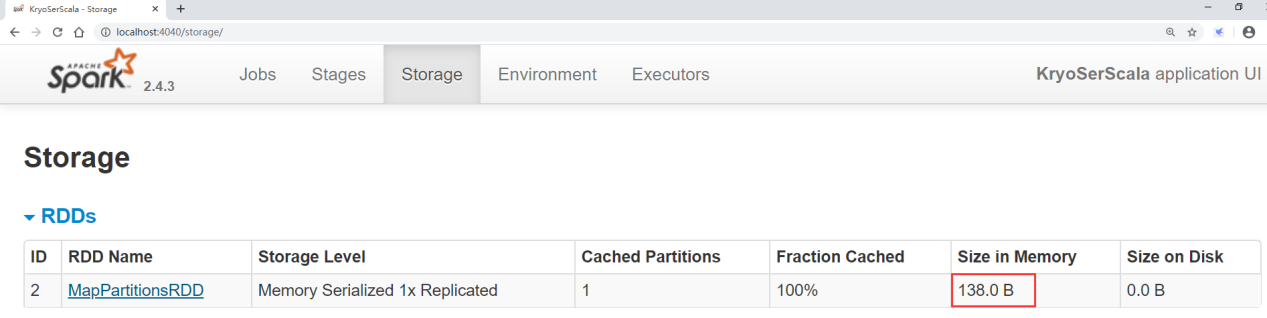
运行任务,再访问4040界面
发现此时占用的内存空间是 138 字节,比使用kryo的方式内存空间多占用了将近5倍。
所以从这可以看出来,使用 kryo 序列化方式对内存的占用会降低很多。
持久化或者checkpoint
针对程序中多次被transformation或者action操作的RDD进行持久化操作,避免对一个RDD反复进行计算,再进一步优化,使用Kryo序列化的持久化级别,减少内存占用。为了保证RDD持久化数据在可能丢失的情况下还能实现高可靠,则需要对RDD执行Checkpoint操作
JVM垃圾回收调优
由于Spark是基于内存的计算引擎,RDD缓存的数据,以及算子执行期间创建的对象都是放在内存中的,所以针对Spark任务如果内存设置不合理会导致大部分时间都消耗在垃圾回收上。
对于垃圾回收来说,最重要的就是调节RDD缓存占用的内存空间,和算子执行时创建的对象占用的内存空间的比例。默认情况下,Spark使用每个 executor 60% 的内存空间来缓存RDD,那么只有 40% 的内存空间来存放算子执行期间创建的对象。在这种情况下,可能由于内存空间的不足,并且算子对应的task任务在运行时创建的对象过大,那么一旦发现 40% 的内存空间不够用了,就会触发Java虚拟机的垃圾回收操作。因此在极端情况下,垃圾回收操作可能会被频繁触发。在这种情况下,如果发现垃圾回收频繁发生。那么就需要对这个比例进行调优了spark.storage.memoryFraction 参数的值默认是 0.6 。使用 SparkConf().set(“spark.storage.memoryFraction”, “0.5”) 可以进行修改,就是将RDD缓存占用内存空间的比例降低为 50% ,从而提供更多的内存空间来保存task运行时创建的对象。
因此,对于RDD持久化而言,完全可以使用Kryo序列化,加上降低其executor内存占比的方式,来减少其内存消耗。给task提供更多的内存,从而避免task在执行时频繁触发垃圾回收。我们可以对task的垃圾回收进行监测,在spark的任务执行界面,可以查看每个task执行消耗的时间,以及task gc消耗的时间。
重新向集群中提交checkpoint的代码,查看spark任务的task指标信息
确保Hadoop集群、yarn的historyserver进程以及spark的historyserver进程是正常运行的删除checkpoint任务的输出目录
[root@bigdata04 sparkjars]# hdfs dfs -rm -r /out-chk001
提交任务
[root@bigdata04 sparkjars]# sh -x checkPointJob.sh
点击生成的第一个job,再点击进去查看这个job的stage,进入第一个stage,查看task的执行情况,看这里面的GC time的数值会不会比较大,最直观的就是如果gc time这里标红了,则说明gc时间过长。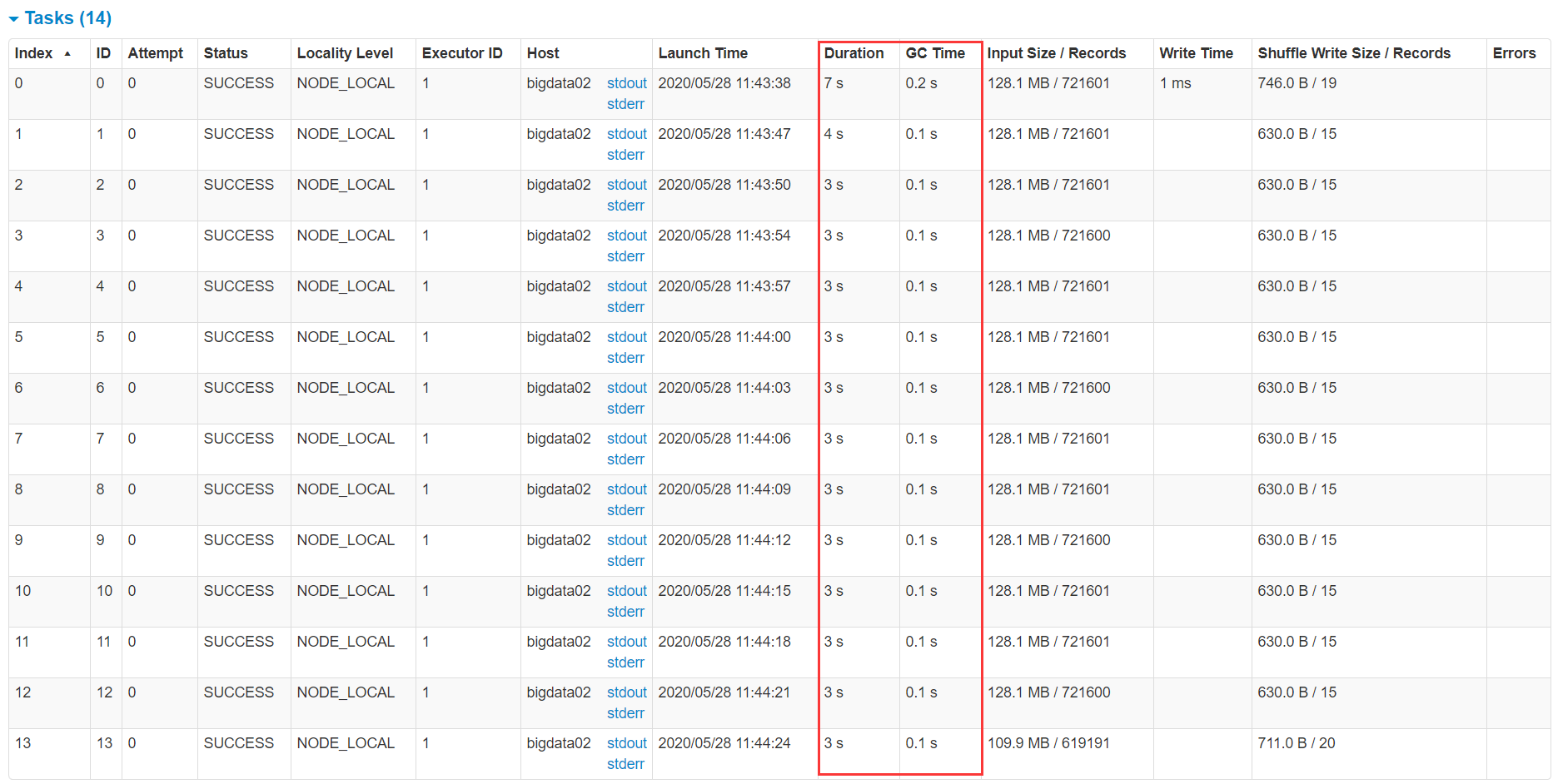
上面这个是分任务查看,其实还可以查看全局的,看Executor进程中整个任务执行总时间和gc的消耗时间。
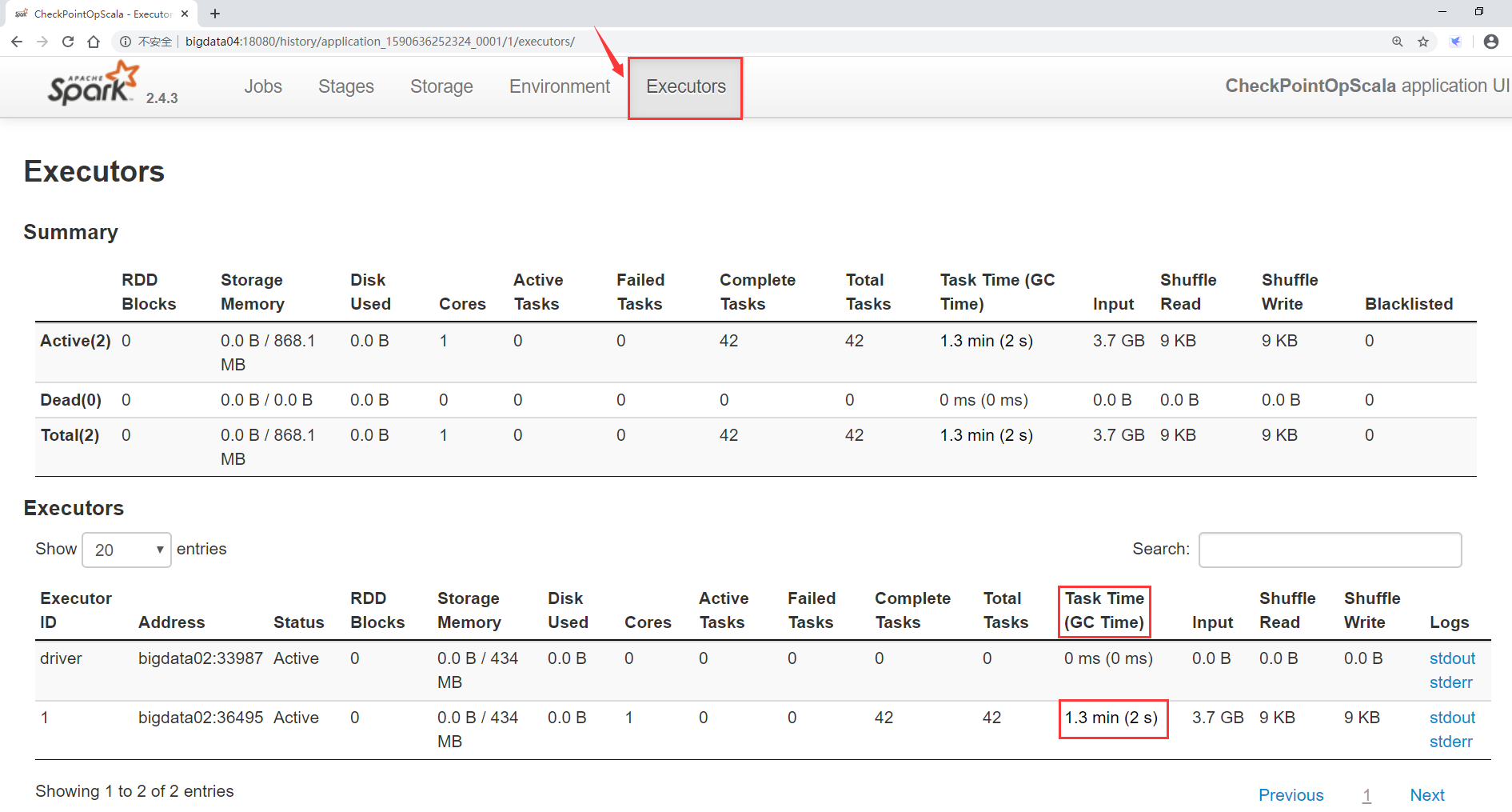
既然说到了Java中的GC,那我们就需要说道说道了。
Java堆空间被划分成了两块空间:一个是年轻代,一个是老年代。
年轻代放的是短时间存活的对象
老年代放的是长时间存活的对象。
年轻代又被划分了三块空间, Eden、Survivor1、Survivor2
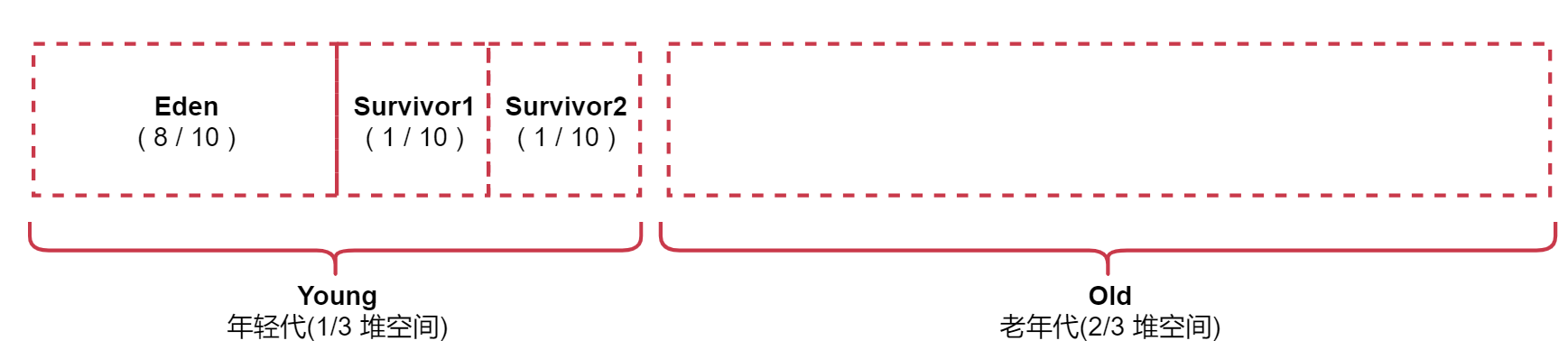
年轻代占堆内存的1/3,老年代占堆内存的2/3
其中年轻代又被划分了三块, Eden,Survivor1,Survivor2 的比例为 8:1:1
Eden区域和Survivor1区域用于存放对象,Survivor2区域备用。
我们创建的对象,首先会放入Eden区域,如果Eden区域满了,那么就会触发一次Minor GC,进行年轻代的垃圾回收(其实就是回收Eden区域内没有人使用的对象),然后将存活的对象存入Survivor1区域,再创建对象的时候继续放入Eden区域。第二次Eden区域满了,那么Eden和Survivor1区域中存活的对象,当第三次Eden区域再满了的时候,Eden和Survivor2区域中存活的对象,会一块被移动到Survivor1区域中,按照这个规律进行循环。
注意了,Full GC是一个重量级的垃圾回收,Full GC执行的时候,程序是处于暂停状态的,这样会非常影响性能。
1:最直接的就是提高Executor的内存
在spark-submit中通过参数指定executor的内存
--executor-memory 1G
2:调整Eden与s1和s2的比值【一般情况下不建议调整这块的比值】
- -XX:NewRatio=4:设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代).设置为4,则年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5
- -XX:SurvivorRatio=4:设置年轻代中Eden区与Survivor区的大小比值.设置为4,则两个Survivor区与一个Eden区的比值为2:4,一个Survivor区占整个年轻代的1/6
具体使用的时候在 spark-submit 脚本中通过 --conf 参数设置即可
--conf "spark.executor.extraJavaOptions= -XX:SurvivorRatio=4 -XX:NewRatio=4"
其实最直接的就是增加Executor的内存,如果这个内存上不去,其它的修改都是徒劳。举个例子就是说,一个20岁的成年人和一个3岁的小孩。3岁的小孩掌握再多的格斗技巧都没有用,在绝对的实力面前一切都是花架子。所以说我们一般很少需要去调整Eden、s1、s2的比值,一般都是直接增加Executor的内存比较靠谱。
提高并行度
实际上Spark集群的资源并不一定会被充分利用到,所以要尽量设置合理的并行度,来充分地利用集群的资源,这样才能提高Spark程序的性能。
Spark会自动设置以文件作为输入源的RDD的并行度,依据其大小,比如HDFS,就会给每一个block创建一个partition,也依据这个设置并行度。对于reduceByKey等会发生shuffle操作的算子,会使用并行度最大的父RDD的并行度。可以手动使用 textFile()、parallelize() 等方法的第二个参数来设置并行度;也可以使用 spark.default.parallelism 参数,来设置统一的并行度。Spark官方的推荐是,给集群中的每个cpu core设置 2~3 个
下面来举个例子
我在 spark-submit 脚本中给任务设置了5 个executor,每个executor,设置了2个cpu core
spark-submit \
--master yarn \
--deploy-mode cluster \
--executor-memory 1G \
--num-executors 5 \
--executor-cores 2 \
.....
此时,如果我在代码中设置了默认并行度为5
conf.set("spark.default.parallelism","5")
这个参数设置完了以后,也就意味着所有RDD的partition都被设置成了5个,针对RDD的每一个partition,spark会启动一个task来进行计算,所以对于所有的算子操作,都只会创建5个task来处理对应的RDD中的数据。
但是注意了,我们前面在spark-submit脚本中设置了5个executor,每个executor 2个cpu core,所以这个时候spark其实会向yarn集群申请10个cpu core,但是我们在代码中设置了默认并行度为5,只会产生5个task,一个task使用一个cpu core,那也就意味着有5个cpu core是空闲的,这样申请的资源就浪费了一半。
其实最好的情况,就是每个cpu core都不闲着,一直在运行,这样可以达到资源的最大使用率,其实让一个cpu core运行一个task都是有点浪费的,官方也建议让每个cpu core运行2~3个task,这样可以充分压榨CPU的性能。
是这样的,因为每个task执行的顺序和执行结束的时间很大概率是不一样的,如果正好有10个cpu,运行10个taks,那么某个task可能很快就执行完了,那么这个CPU就空闲下来了,这样资源就浪费了。所以说官方推荐,给每个cpu分配2~3个task是比较合理的,可以充分利用CPU资源,发挥它最大的价值。下面我们来实际写个案例看一下效果
Scala代码如下:
packagecom.imooc.scalaimportorg.apache.spark.{SparkConf, SparkContext}/**
* 需求:设置并行度
* 1:可以在textFile或者parallelize等方法的第二个参数中设置并行度
* 2:或者通过spark.default.parallelism参数统一设置并行度
*/object MoreParallelismScala {def main(args: Array[String]):Unit={val conf =new SparkConf()
conf.setAppName("MoreParallelismScala")//设置全局并行度
conf.set("spark.default.parallelism","5")val sc =new SparkContext(conf)val dataRDD = sc.parallelize(Array("hello","you","hello","me","hehe","hel
dataRDD.map((_,1)).reduceByKey(_ + _).foreach(println(_))
sc.stop()}}
对代码编译打包
spark-submit脚本内容如下:
[root@bigdata04 sparkjars]# vi moreParallelismJob.sh
spark-submit \--class com.imooc.scala.MoreParallelismScala \--masteryarn\
--deploy-mode cluster \
--executor-memory 1G \
--num-executors 5\
--executor-cores 2\
db_spark-1.0-SNAPSHOT-jar-with-dependencies.jar
任务提交到集群运行之后,查看spark的任务界面
先看executors,这里显示了4个executor和1个driver进程,为什么不是5个executor进程呢?
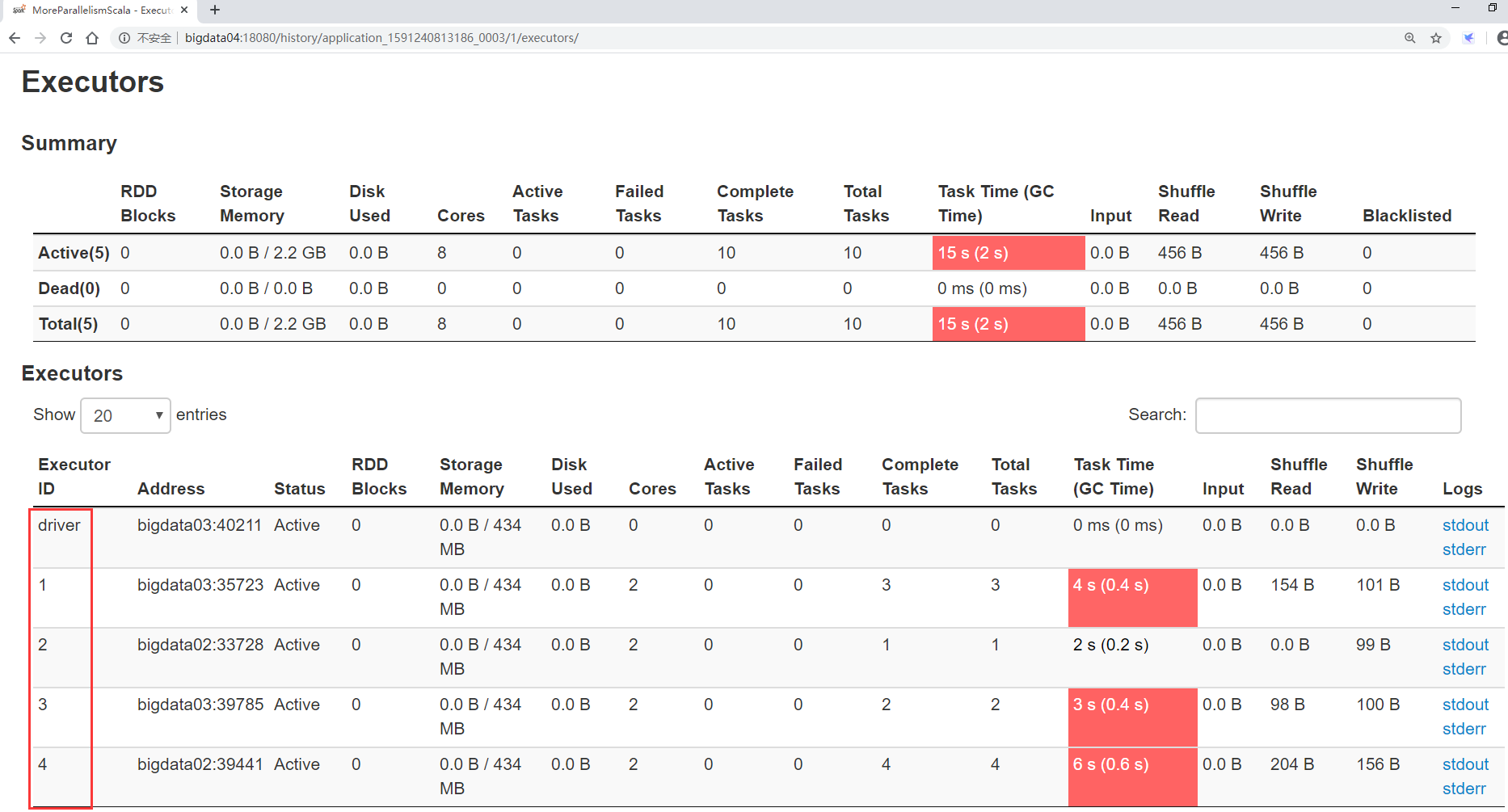
是因为我们现在使用的是yarn-cluster模式,driver进程运行在集群内部,所以它占了一个executor,如果使用的是yarn-client模式,就会产生5个executor和1个单独的driver进程。
然后去看satges界面,两个Stage都是5个task并行执行,这5个task会使用5个cpu,但是我们给这个任务申请了10个cpu,所以就有5个是空闲的了。
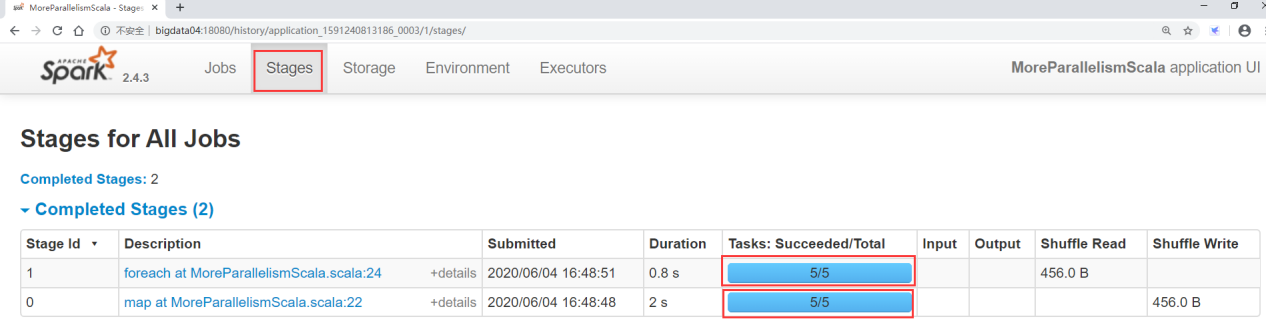
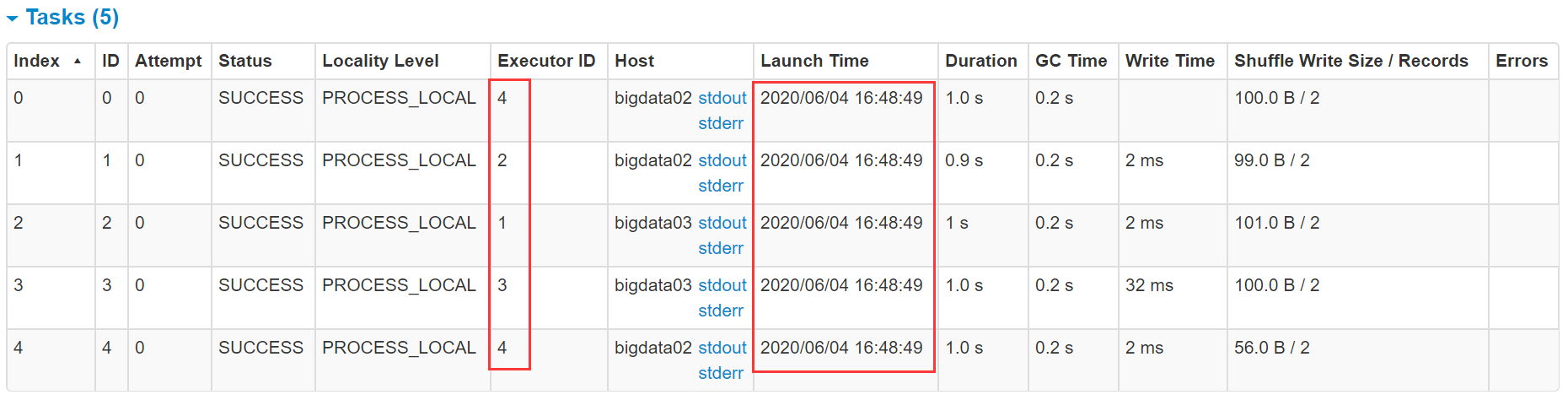
如果想要最大限度利用CPU的性能,至少将 spark.default.parallelism 的值设置为10,这样可以实现一个cpu运行一个task,其实官方推荐是设置为20或者30。
其实这个参数也可以在spark-submit脚本中动态设置,通过 --conf 参数设置,这样就比较灵活了。
这就是并行度相关的设置
接下来我们来看一个图,加深一下理解
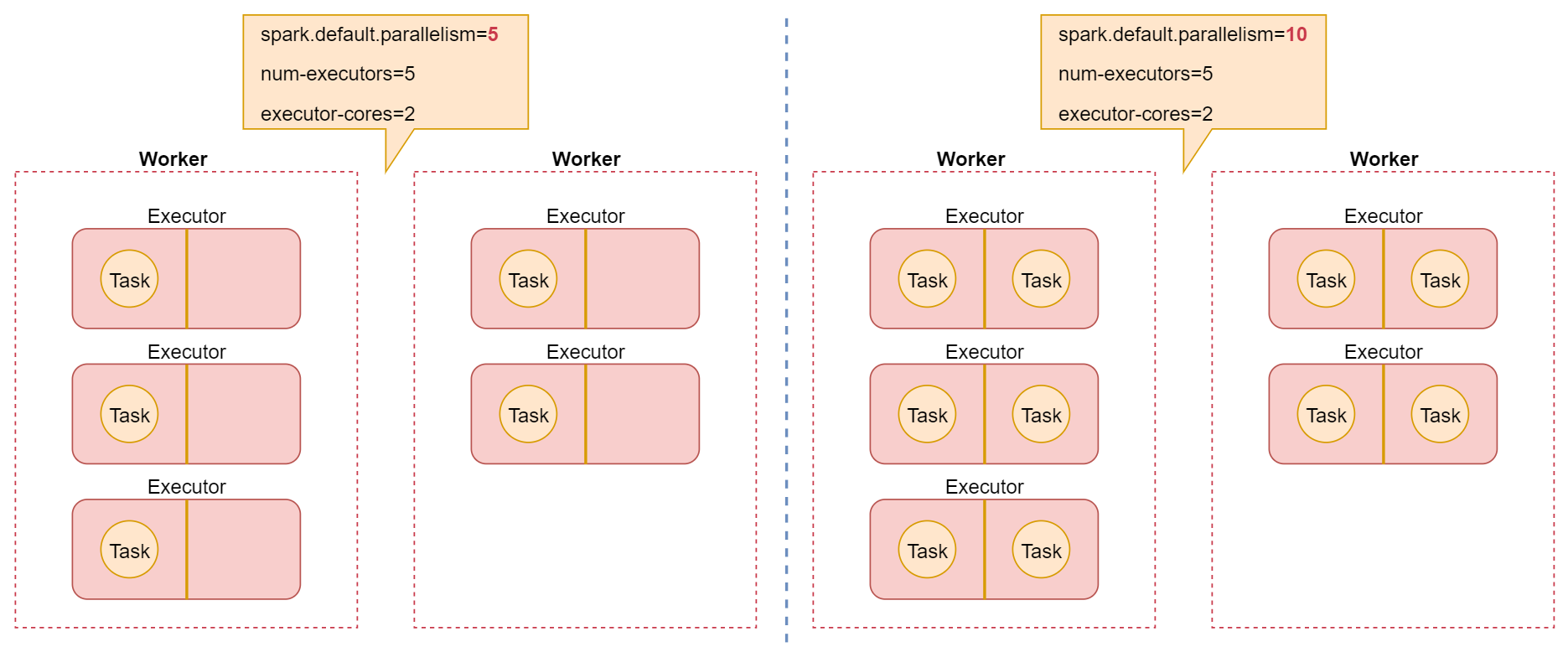
这个图中描述的就是刚才我们演示的两种情况下Executor和Task之间的关系。
最后我们来分析总结一下spark-submit脚本中经常配置的一些参数
--name mySparkJobName:指定任务名称
--class com.imooc.scala.xxxxx :指定入口类
--masteryarn :指定集群地址,on yarn模式指定yarn
--deploy-mode cluster :client代表yarn-client,cluster代表yarn-cluster
--executor-memory 1G :executor进程的内存大小,实际工作中设置2~4G即可
--num-executors 2 :分配多少个executor进程
--executor-cores 2: 一个executor进程分配多少个cpu core
--driver-cores 1 :driver进程分配多少cpu core,默认为1即可
--driver-memory 1G:driver进程的内存,如果需要使用类似于collect之类的action算子向
--jars fastjson.jar,abc.jar 在这里可以设置job依赖的第三方jar包【不建议把第三方依赖
--conf"spark.default.parallelism=10":可以动态指定一些spark任务的参数,指定多个参
最后注意一点:针对 --num-executors 和 --executor-cores 的设置
看这两种方式设置有什么区别:
第一种方式:
--num-executors 2--executor-cores 1
第二种方式:
--num-executors 1
--executor-cores 2
这两种设置最终都会向集群申请2个cpu core,可以并行运行两个task,但是这两种设置方式有什么区别呢?
- 第一种方法:多executor模式 由于每个executor只分配了一个cpu core,我们将无法利用在同一个JVM中运行多个任务的优点。 我们假设这两个executor是在两个节点中启动的,那么针对广播变量这种操作,将在两个节点的中都复制1份,最终会复制两份
- 第二种方法:多core模式 此时一个executor中会有2个cpu core,这样可以利用同一个JVM中运行多个任务的优点,并且针对广播变量的这种操作,只会在这个executor对应的节点中复制1份即可。 那是不是我可以给一个executor分配很多的cpu core,也不是的,因为一个executor的内存大小是固定的,如果在里面运行过多的task可能会导致内存不够用,所以这块一般在工作中我们会给一executor分配 2
4G 内存,对应的分配 24 个cpu core。
数据本地化
数据本地化对于Spark Job性能有着巨大的影响。如果数据以及要计算它的代码是在一起的,那么性能当然会非常高。但是,如果数据和计算它的代码是分开的,那么其中之一必须到另外一方的机器上。通常来说,移动代码到其它节点,会比移动数据到代码所在的节点,速度要得多,因为代码比较小。Spark也正是基于这个数据本地化的原则来构建task调度算法的。
数据本地化,指的是,数据离计算它的代码有多近。基于数据距离代码的距离,有几种数据本地化级别:
数据本地化级别 解释
PROCESS_LOCAL 进程本地化,性能最好:数据和计算它的代码在同一个JVM进程中
NODE_LOCAL 节点本地化:数据和计算它的代码在一个节点上,但是不在一个JVM进程
NO_PREF 数据从哪里过来,性能都是一样的,比如从数据库中获取数据,对于task
RACK_LOCAL 数据和计算它的代码在一个机架上,数据需要通过网络在节点之间进行传
ANY 数据可能在任意地方,比如其它网络环境内,或者其它机架上,性能最差
Spark倾向使用最好的本地化级别调度task,但这是不现实的
如果目前我们要处理的数据所在的executor上目前没有空闲的CPU,那么Spark就会放低本地化级别。这时有两个选择:
第一,等待,直到executor上的cpu释放出来,那么就分配task过去;
第二,立即在任意一个其它executor上启动一个task。
Spark默认会等待指定时间,期望task要处理的数据所在的节点上的executor空闲出一个cpu,从而将task分配过去,只要超过了时间,那么Spark就会将task分配到其它任意一个空闲的executor上可以设置参数, spark.locality 系列参数,来调节Spark等待task可以进行数据本地化的时间
spark.locality.wait(3000毫秒):默认等待3秒
spark.locality.wait.process:等待指定的时间看能否达到数据和计算它的代码在同一个JVM
spark.locality.wait.node:等待指定的时间看能否达到数据和计算它的代码在一个节点上执行
spark.locality.wait.rack:等待指定的时间看能否达到数据和计算它的代码在一个机架上
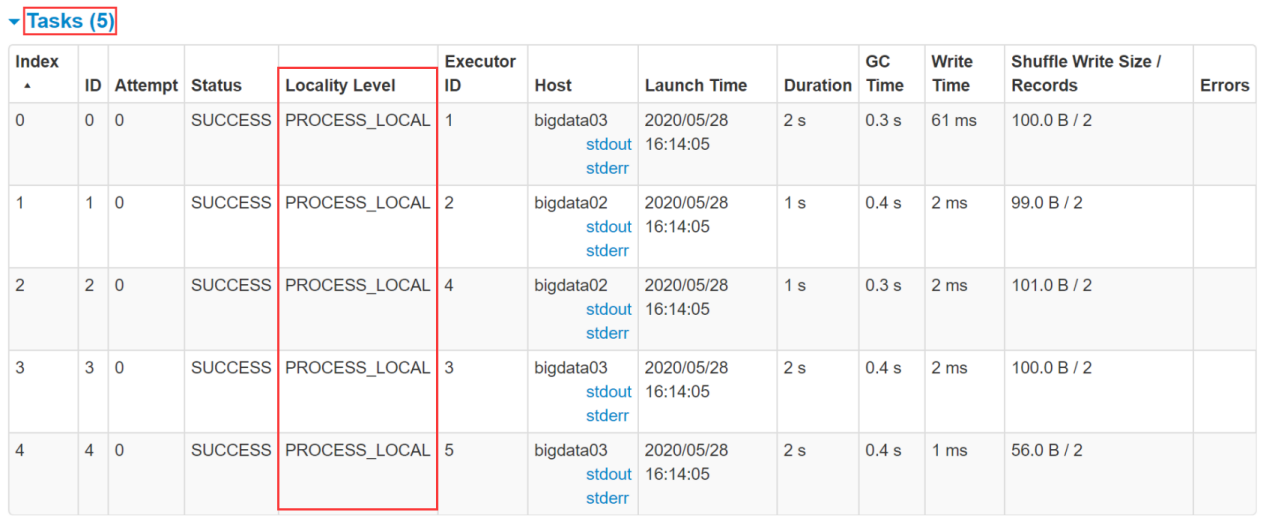
看这个图里面的task,此时的数据本地化级别是最优的 PROCESS_LOCAL
Spark性能优化之算子优化
map vs mapPartitions
- map 操作:对 RDD 中的每个元素进行操作,一次处理一条数据
- mapPartitions 操作:对 RDD 中每个 partition 进行操作,一次处理一个分区的数据所以:
- map 操作: 执行 1 次 map算子只处理 1 个元素,如果 partition 中的元素较多,假设当前已经处理了 1000 个元素,在内存不足的情况下,Spark 可以通过GC等方法回收内存(比如将已处理掉的1000 个元素从内存中回收)。因此, map 操作通常不会导致OOM异常;
- mapPartitions 操作: 执行 1 次map算子需要接收该 partition 中的所有元素,因此一旦元素很多而内存不足,就容易导致OOM的异常,也不是说一定就会产生OOM异常,只是和map算子对比的话,相对来说容易产生OOM异常
不过一般情况下,mapPartitions 的性能更高;初始化操作、数据库链接等操作适合使用 mapPartitions操作。
这是因为:假设需要将 RDD 中的每个元素写入数据库中,这时候就应该把创建数据库链接的操作放置在mapPartitions 中,创建数据库链接这个操作本身就是个比较耗时的,如果该操作放在 map 中执行,将会频繁执行,比较耗时且影响数据库的稳定性。
scala代码实现如下
packagecom.imooc.scalaimportorg.apache.spark.{SparkConf, SparkContext}importscala.collection.mutable.ArrayBuffer
/**
* 需求:mapPartitons的使用
*/object MapPartitionsOpScala {def main(args: Array[String]):Unit={val conf =new SparkConf()
conf.setAppName("MapPartitionsOpScala").setMaster("local")val sc =new SparkContext(conf)//设置分区数量为2val dataRDD = sc.parallelize(Array(1,2,3,4,5),2)//map算子一次处理一条数据/*val sum = dataRDD.map(item=>{
println("==============")
item * 2
}).reduce( _ + _)
*///mapPartitions算子一次处理一个分区的数据val sum = dataRDD.mapPartitions(it=>{//建议针对初始化链接之类的操作,使用mapPartitions,放在mapPartitions内部//例如:创建数据库链接,使用mapPartitions可以减少链接创建的次数,提高性能//注意:创建数据库链接的代码建议放在次数,不要放在Driver端或者it.foreach内部//数据库链接放在Driver端会导致链接无法序列化,无法传递到对应的task中执行,所以//数据库链接放在it.foreach()内部还是会创建多个链接,和使用map算子的效果是一样
println("==================")val result =new ArrayBuffer[Int]()//这个foreach是调用的scala里面的函数
it.foreach(item=>{
result.+=(item *2)})//关闭数据库链接
result.toIterator
}).reduce(_ + _)
println("sum:"+sum)
sc.stop()}}
foreach vs foreachPartition
foreach:一次处理一条数据
foreachPartition:一次处理一个分区的数据
foreachPartition的特性和mapPartitions 的特性是一样的,唯一的区别就是mapPartitions 是 transformation 操作(不会立即执行),foreachPartition是 action 操作(会立即执行)
Scala代码如下:
packagecom.imooc.scalaimportorg.apache.spark.{SparkConf, SparkContext}/**
* 需求:foreachPartition的使用
*/object ForeachPartitionOpScala {def main(args: Array[String]):Unit={val conf =new SparkConf()
conf.setAppName("ForeachPartitionOpScala").setMaster("local")val sc =new SparkContext(conf)//设置分区数量为2val dataRDD = sc.parallelize(Array(1,2,3,4,5),2)//foreachPartition:一次处理一个分区的数据,作用和mapPartitions类似//唯一的区是mapPartitions是transformation算子,foreachPartition是action算子
dataRDD.foreachPartition(it=>{//在此处获取数据库链接
println("===============")
it.foreach(item=>{//在这里使用数据库链接
println(item)})//关闭数据库链接})
sc.stop()}}
repartition的使用
对RDD进行重分区,repartition主要有两个应用场景:
- 可以调整RDD的并行度 针对个别RDD,如果感觉分区数量不合适,想要调整,可以通过repartition进行调整,分区调整了之后,对应的并行度也就可以调整了
- 可以解决RDD中数据倾斜的问题 如果RDD中不同分区之间的数据出现了数据倾斜,可以通过repartition实现数据重新分发,可以均匀分发到不同分区中
packagecom.imooc.scalaimportorg.apache.spark.{SparkConf, SparkContext}/**
* 需求:repartition的使用
* */object RepartitionOpScala {def main(args: Array[String]):Unit={val conf =new SparkConf()
conf.setAppName("RepartitionOpScala").setMaster("local")val sc =new SparkContext(conf)//设置分区数量为2val dataRDD = sc.parallelize(Array(1,2,3,4,5),2)//重新设置RDD的分区数量为3,这个操作会产生shuffle//也可以解决RDD中数据倾斜的问题
dataRDD.repartition(3).foreachPartition(it=>{
println("=========")
it.foreach(println(_))})//通过repartition可以控制输出数据产生的文件个数
dataRDD.saveAsTextFile("hdfs://bigdata01:9000/rep-001")
dataRDD.repartition(1).saveAsTextFile("hdfs://bigdata01:9000/rep-002")
sc.stop()}}
reduceByKey和groupByKey的区别
在实现分组聚合功能时这两个算子有什么区别?
看这两行代码
val counts = wordCountRDD.reduceByKey(_ + _)val counts = wordCountRDD.groupByKey().map(wc =>(wc._1, wc._2.sum))
这两行代码的最终效果是一样的,都是对wordCountRDD中每个单词出现的次数进行聚合统计。
那这两种方式在原理层面有什么区别吗?
首先这两个算子在执行的时候都会产生shuffle
但是:
1:当采用reduceByKey时,数据在进行shuffle之前会先进行局部聚合
2:当使用groupByKey时,数据在shuffle之间不会进行局部聚合,会原样进行shuffle
这样的话reduceByKey就减少了shuffle的数据传送,所以效率会高一些。
下面来看这个图,加深一下理解
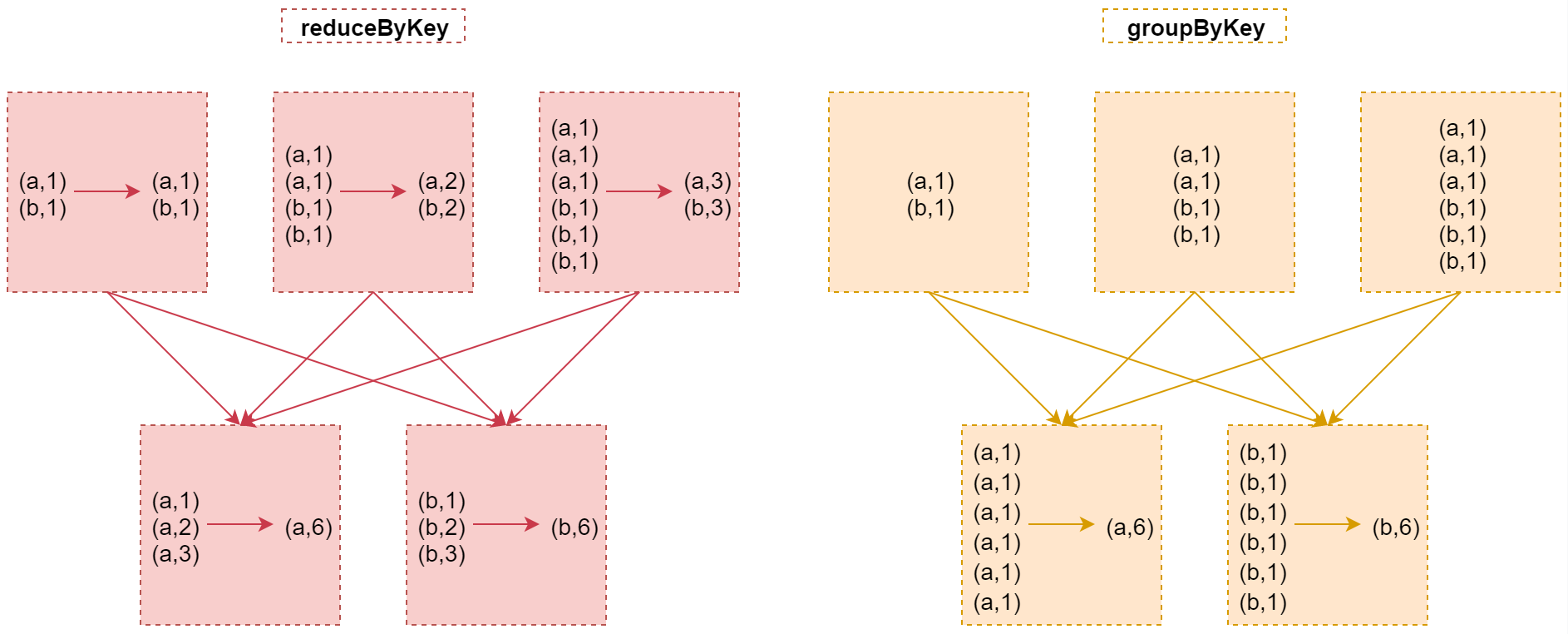
从图中可以看出来reduceByKey在shuffle之前会先对数据进行局部聚合,而groupByKey不会,所以在实现分组聚合的需求中,reduceByKey性能略胜一筹。
版权归原作者 小崔的技术博客 所有, 如有侵权,请联系我们删除。