
文末给出了一些笔者积累的优化小知识,如果感觉文章还凑合,欢迎点赞。本文出现的任何案例均不针对个人,如有雷同纯属巧合。
写在前面的话
这个夏天疫情还在肆虐,本文经历了两瓶红牛才写完。要知道真正写完一篇有关性能优化的书可能需要十几万字,我也仅仅是将这几年书中所读、工作所做,以及在研发过程中的一些思考,在这个夏天写一部分出来分享给大家。同时也在翻译一本新书,书在国内还没上市,期待早一天能和大家见面。
消费者或使用者不在乎你到底是不是新的技术,而是能够带来好的体验或收益才最有价值。
用户体验数据、产品性能分析之你糊弄我我糊弄你
当前产品体验大多都还停留感知层面,用户体验数据的收集更是仅仅停留在初级阶段,停留在产品PPT概念层面左拼右凑出来的刀耕火种的年代的数据分析不是寥寥无几便是苍白无力,根本无法解释会话跳出率为何居高不下,市场需要教育、客户不买账乃至客户不懂产品逻辑的借口一遍又一遍的自欺欺人,牛气哄哄的前景预测与未来估值也在一个接一个的bug面前瑟瑟发抖,一句又一句口口声声的钱都花在了研发的刀刃上买不来投资人的信服。
产品数据≠用户体验数据
性能分析数据≠后端性能数据
通俗的说,当前真正把钱花在产品上公司或者部门屈指可数,实打实的做好产品体验的公司更是凤毛麟角。站在风口上飞起来的猪不会把偷偷卷市场、卷营销的千万花费告诉你。以十年为周期来看产品进化,精益数据分析一下互联网产品的进化又有多少公司把钱花在了产品体验分析上? 看一下当前研发的分配比例就能尤为说明这个问题。当前互联网产品主要倾向于后端性能提升,而不是产品在前端的体验,当然更不是产品的体验上(这里和传统的体验店要分开)。这里禁不住发问:难道只有后端性能重要,前端不会瓶颈?
只有后端才会有性能瓶颈?躲在墙角饥寒交迫的前端和运维
吐槽一番之后,说到产品资源投入的话题。面向未来的业务架构、海量的分布式存储系统,弹性伸缩的缓存集群或者分布式消息队列,高可用的网络秒杀系统架构,在岁月涤荡中给产品体验提升带来的收益有几层楼?收益肯定是有的,不然互联网IT民工如何成了新贵和相亲排行榜的头条。常常听到大促、秒杀下的百亿级流量架构是如何实现的,难道前端就只能是切图仔,div的堆砌工?研发资源倾向的投入本身意味着产品结构的等级,不重视前端用户体验的研发结果也是能是十人成虎式的随波逐流“业界最佳实践”OR“业界都这么做”
性能优化只关乎优化首屏加载?行百里半九十者大有人在
说到前端性能优化,大多想到的都是首屏加载,如果以加载时间为梯队估计500ms以内寥寥无几。其实优化不只在于首页的加载,虽然这个也很重要,本文也会在后半部分做详细的阐述,但是毋庸置疑的是前端性能优化应该体现在方方面面,这里先举两个例子,然后再重点阐述一下。
例子1,长耗时任务了解一下?找不到也要了解一下
长耗时任务一般是超过50ms的任务。有关长耗时任务的解释可以查看这个网址:https://developer.mozilla.org/en-US/docs/Web/API/Long_Tasks_API
网上对于long-task的解释遍地都是,在百度搜索long task js。
百度为您找到相关结果约20,900,000个
例子2,web-vitals了解一下?用不上也要偷偷卷一下
这个概念估计很多研发都了解过,也算难能可贵的小小的前端性能标准,这里简单列三个出来,分别加单的话描述是
- LCP:主要内容出现的时间,越短越好
- FID:输入延迟的时间,低于100ms越好
- CLS:页面变化的积累量,低于0.1越好
有关这些详细内容可以在https://www.npmjs.com/package/web-vitals上进行查看,稍微懂点前端的同学都可以引用将数据进行上报整理成页面的数据出来。如下:
npm install web-vitals
import {getLCP, getFID, getCLS} from 'web-vitals';
getCLS(console.log);
getFID(console.log);
getLCP(console.log);
通常将得到的结果,加上常见的performance Api就能比较浅显的了解前端大概系统的性能。本来想把掘金的performance.getEntries()的结果拷贝出来,结果掘金出现了最大字数的限制,只好贴图了。
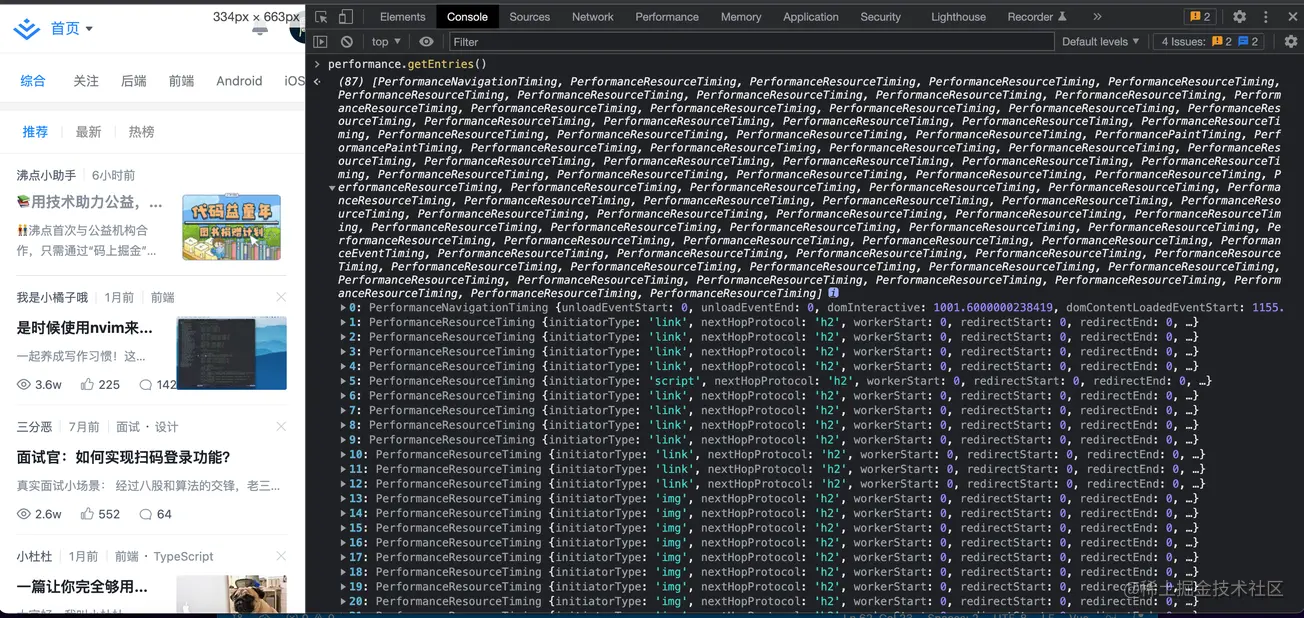
如果将web-vitals和performance进行结合,基本就能看出一个网站的性能数据,其中performance中内容简介如下:
performance timing api 主要包含三个部分navigation timing:页面加载过程的性能数据resource timing:脚本样式等资源加载的性能数据user timing:记录不同代码片段的执行时间提供的apiwindow.performance.getEntriesByType("resource") 获取资源相关的性能信息
然并卵这远远不是开始,真正的性能优化在于建立数据基线,选定关键指标、****制定性能预算、以及设定目标值。
纸上谈兵没有数据的都是耍流氓,升职加薪的都是写PPT的?
管理学大师彼得·德鲁克:If you can't measure it, you can't improve it.“如果你不能够衡量,那你就不能有效的增长。”
如果仅仅只是本地看看web-vitals和performance,产品经理笑话只会ctrl+c和ctrl+v的前端程序员还真的一点也不冤枉。建立数据基线进行分析总结从而各个击破才能王者无敌。
uploadDataToServer(performance Data)
.then(analyze)
以long-tasks为例子,至少需要long-task的时序数据、页面分布
任何一处代码的优化都是有益的,研发也不能看到一行优化一行代码,寻找最有益的切入点就显得尤为重要,首先研发要知道用户在一定时间段内的长耗时任务的分布情况。
图1 长耗时任务时序分布,据此可以得到可以得到优化的一点点基线数据而不是简简单单的PPT。
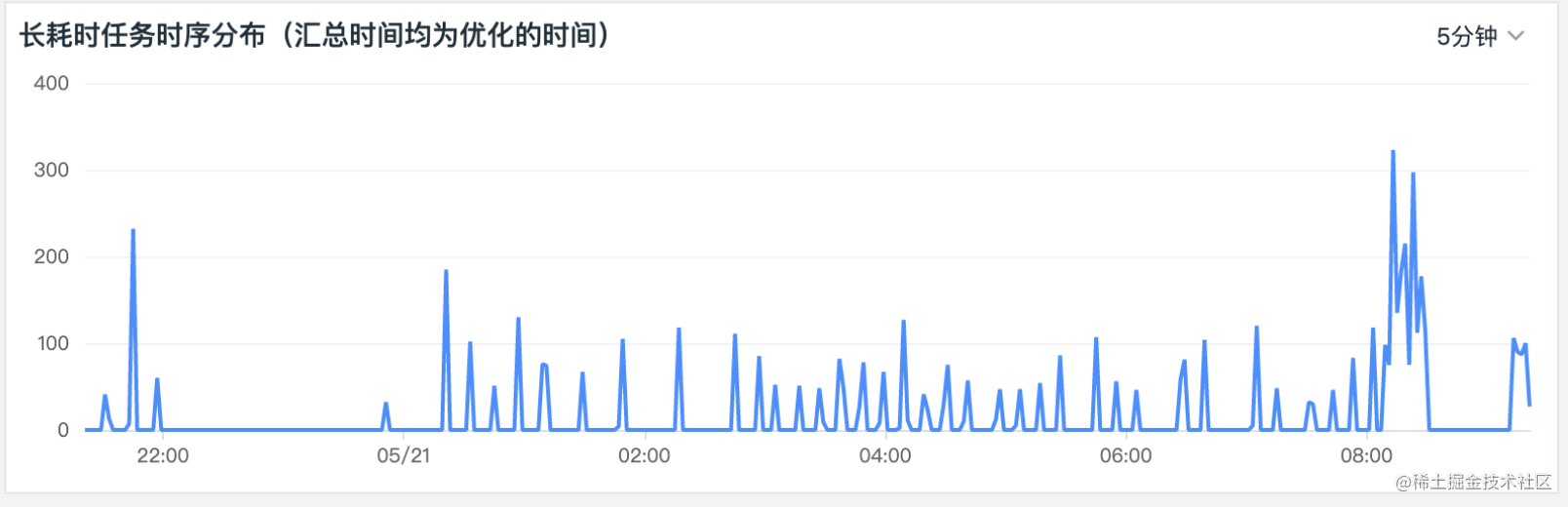
图2长耗时任务在不同页面的时序分布,可以针对页面进行优化排等级,如/statics页面出现的长耗时任务较多,可能需要优化的优先级就可能会靠前
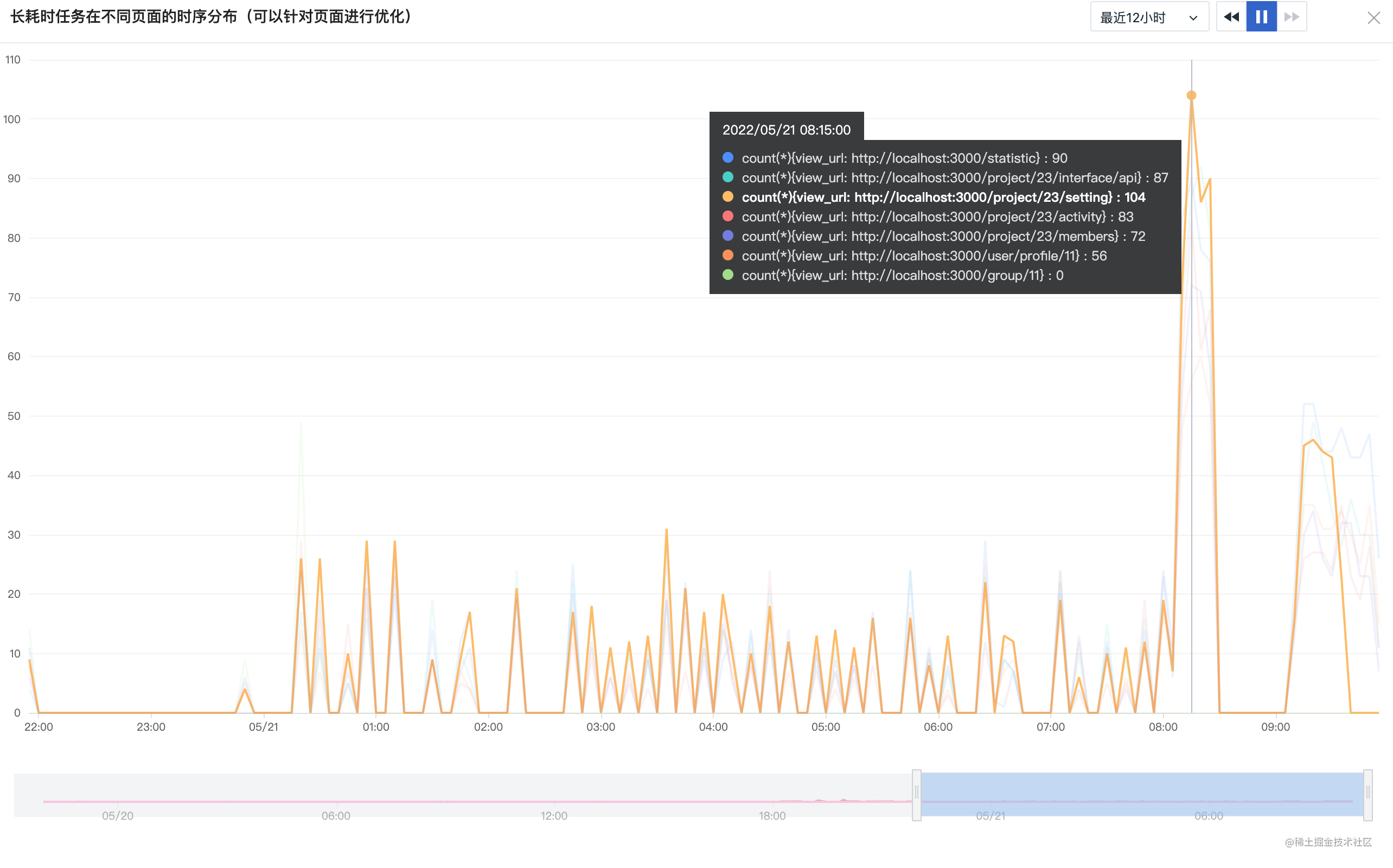
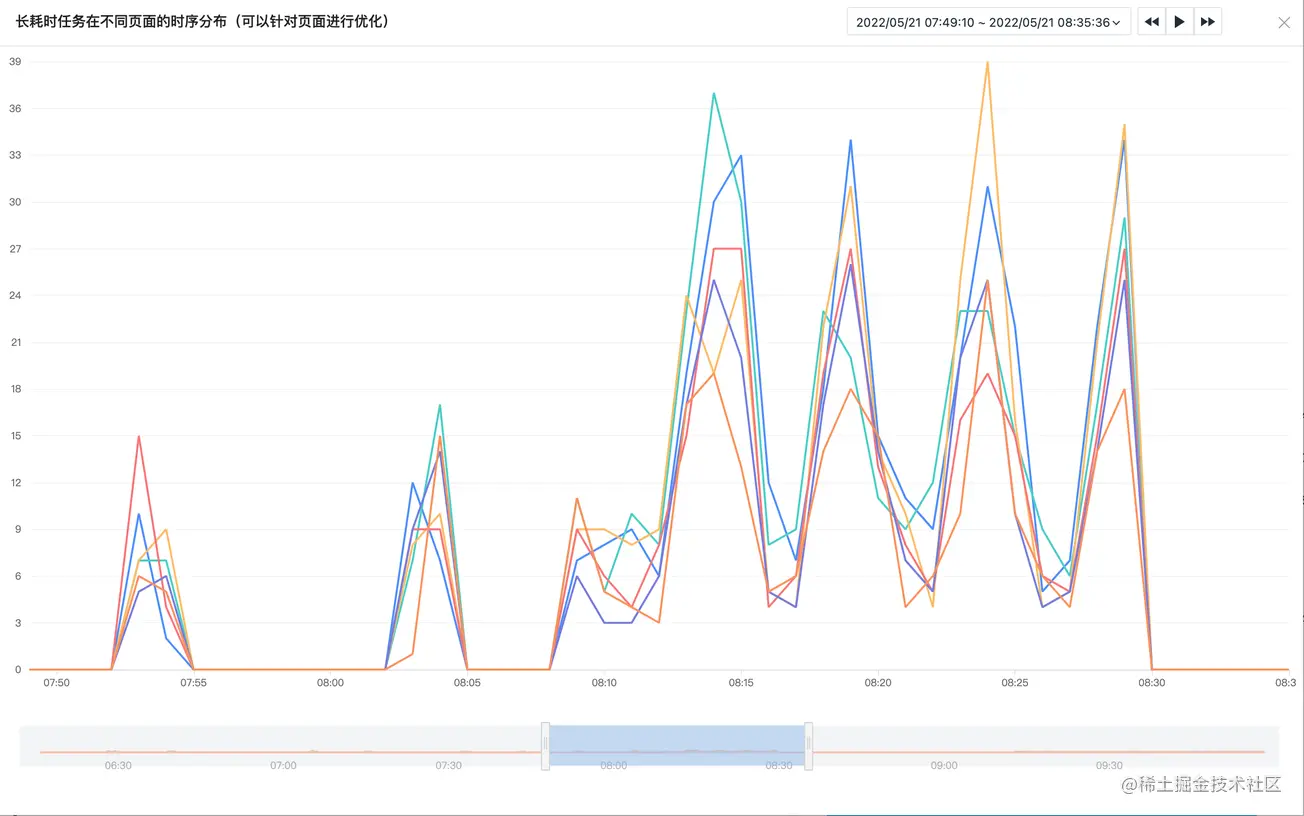
图3 长耗时任务在不同页面的时序分布,可以针对页面进行筛选来安排优化任务。
当然以上的图也有可能是多种多样,比如长耗时页面排行或者TOPN长耗时页面来有针对性的进行优化。
图4 长耗时任务页面分布排行
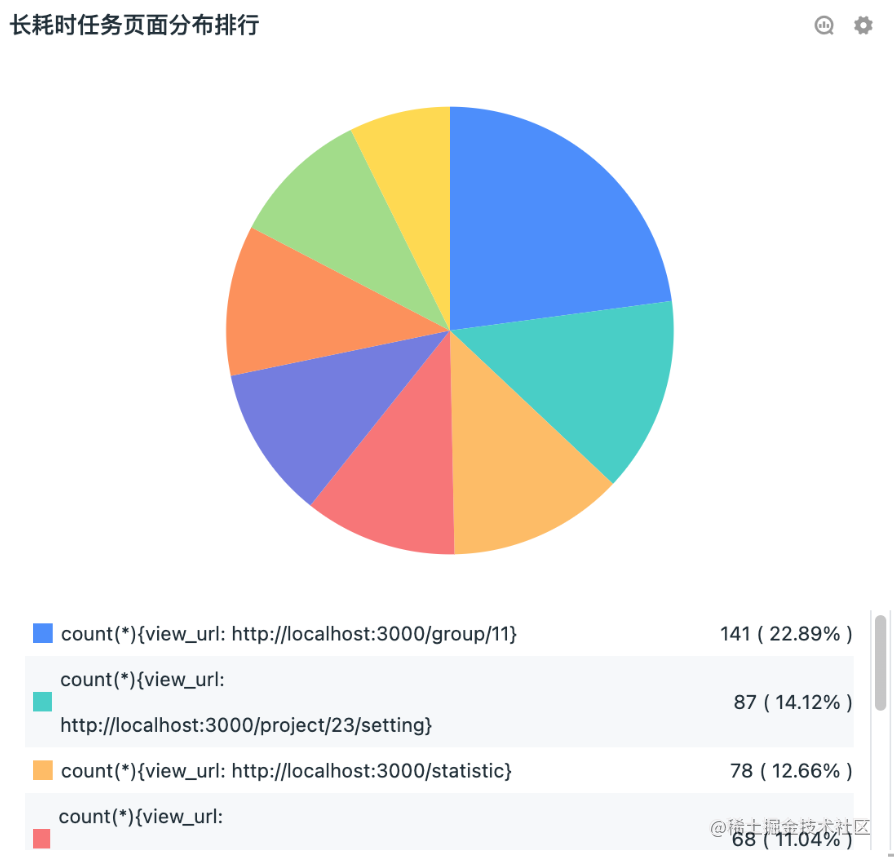
图5 TopN 长耗时页面,如果看了TopN还不知道性能优化从哪里入手,也就只有孙悟空才能拯救你的系统,让他72变吧。
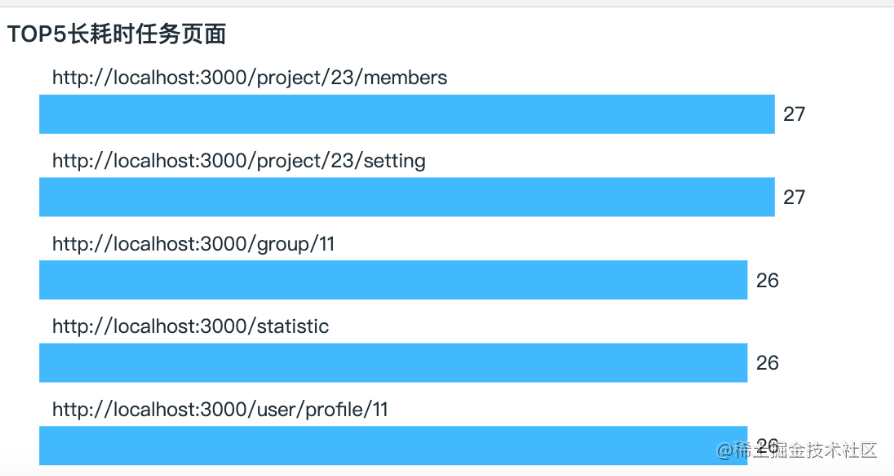
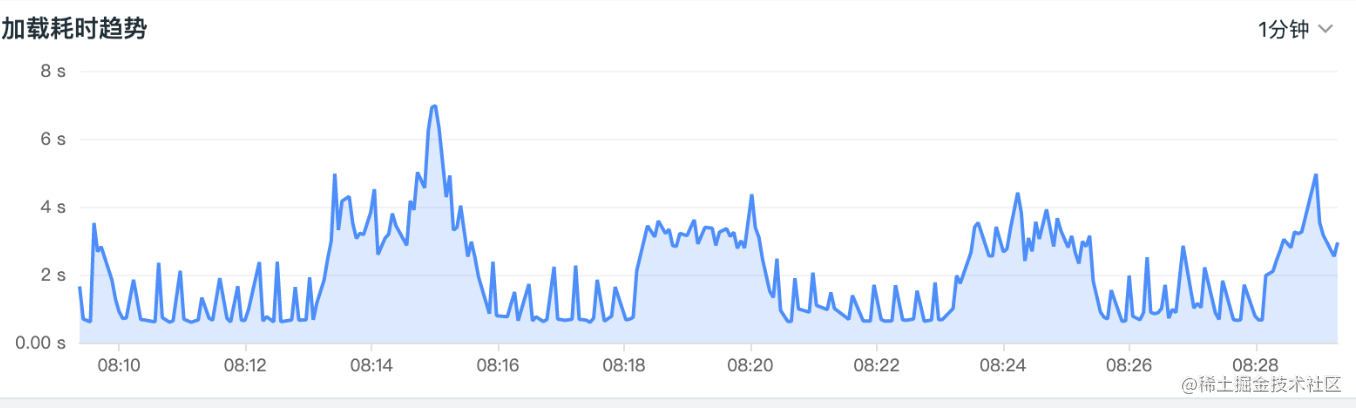
以上仅仅是两个简单的例子来说明前端性能优化的一些可以进行的点,业界更多是对首屏加载耗时的统计,数据可能如下
图6 加载耗时统计
前端优化能做哪些?
根据上图前端整体的优化一般可以划分为建立连接、请求响应两个阶段,从建立连接阶段前端多是对dns-prefetch or Cdn的就近获取;在请求响应阶段,以http协议头为基准对文件进行按需加载、预加载为代表或service woker式或server push式的策略。
以chrome为例,在建立连接阶段客户端最多与主机建立6个tcp连接,通过划分子域方式,将多个资源分布在不同子域上,减少请求队列的等待时间可算得上一种优化的方式,然而划分子域并不是一劳永逸的方式,毕竟更多子域意味着更多的DNS查询时间。所以有了提前建立dns的伪命题出现(为什么是伪命题?),如下所示
<link rel="dns-prefetch" href="protocol://cdndomain/">
技术非静止,性能优化高度依赖技术加持和流程消减。反复建立连接耗时对于毫秒必争的前端来说达到了锱铢必较的程度,一切以headers为至上的资源加载,有了keep-alive能够使得通信仍然保持一定时间,减少在一个单独连接结束后再次进行tcp连接,但keep-alive以及增加link节点距离真正的资源(css/js/image/fonts)节省之间还不是天差地别,gzip曾一度照亮整个前端世界,keep-alive和dns-prefetch节省的几ms在gzip对整个网络以百分比减小的激流下杀出了几十ms乃至几百ms,再后来http2更是仿佛一道光带给前端同学希望,头部压缩、cookies服用、多路复用乃至server push在一定程度缓解了建立连接和请求响应的阻塞状态。
#gzip的相关介绍 https://developer.mozilla.org/en-US/docs/Glossary/GZip_compression
#http2的相关介绍 https://developer.mozilla.org/en-US/docs/Glossary/HTTP_2
然而遗憾的说从整体来说,前端仍然没有突破以网络和资源为限定的性能瓶颈。资源加载整阶段仍然停留在500ms以上。
资源加载完了就可以高枕无忧啦?
1.页面渲染了多少节点,dom节点有多重要?
稍微写过几行div的同学都知道页面是基于DOM树的构建和CSS树的结合构成的Render树。这里引用一本种有关性能优化用一个简单但非完全准确的公式来表现这个过程的复杂度
M:代表Dom节点的数量
N:代表Css节点的数量
Z:遍历循环的次数
Z=M*N
随附一段计算页面节点的方法如下,可以用这段代码来检查页面中的node节点的数量。
function countNodes(node) {
let count = 1;
// 判断是否存在子节点
if(node.hasChildNodes()) {
// 获取子节点
var cnodes = node.childNodes;
// 对子节点进行递归统计
for(var i=0,len=cnodes.length; i<len; i++) {
count += countNodes(cnodes.item(i))
}
}
return count;
}
// 统计body的节点数量
countNodes(document.body)
我们随机选择了70家网站来统计首屏dom节点数量,包含头条、掘金、蓝湖、哔哩哔哩、天猫、火山引擎、京东商城等,详细公司网站清单如下
网易云音乐、好看视频、凤凰资讯、思否、天猫首页、拼多多、知乎首页、懂车帝 西瓜视频、华为商城、优酷网、瓜子二手车、抖音网页版、驴妈妈、腾讯新闻、贝壳网 头条首页、当当网、唯品会、企查查、豆瓣音乐、掘金、京东商城首页、新华网、马蜂窝 爱企查、携程、东方网、百度小说、中国日报、斗鱼TV、网易公开课、美团、人民网、前程无忧 蓝湖、csdn、中国体彩、火山引擎、qq音乐、纵横中文网、光明网、聚划算、雪球首页 hao123、2345导航、链家二手房、北航、飞猪、苏宁易购、驴妈妈旅游、58同城、58二手车 中金在线、天眼查、我爱我家、小米商城、爱奇艺、拉勾招聘、同花顺财经、芒果tv、新浪体育 腾讯体育、搜狐、转转、哔哩哔哩、途牛、安居客、boss直聘、房天下、新浪新闻、东方财富、 易车、腾讯视频、汽车之家
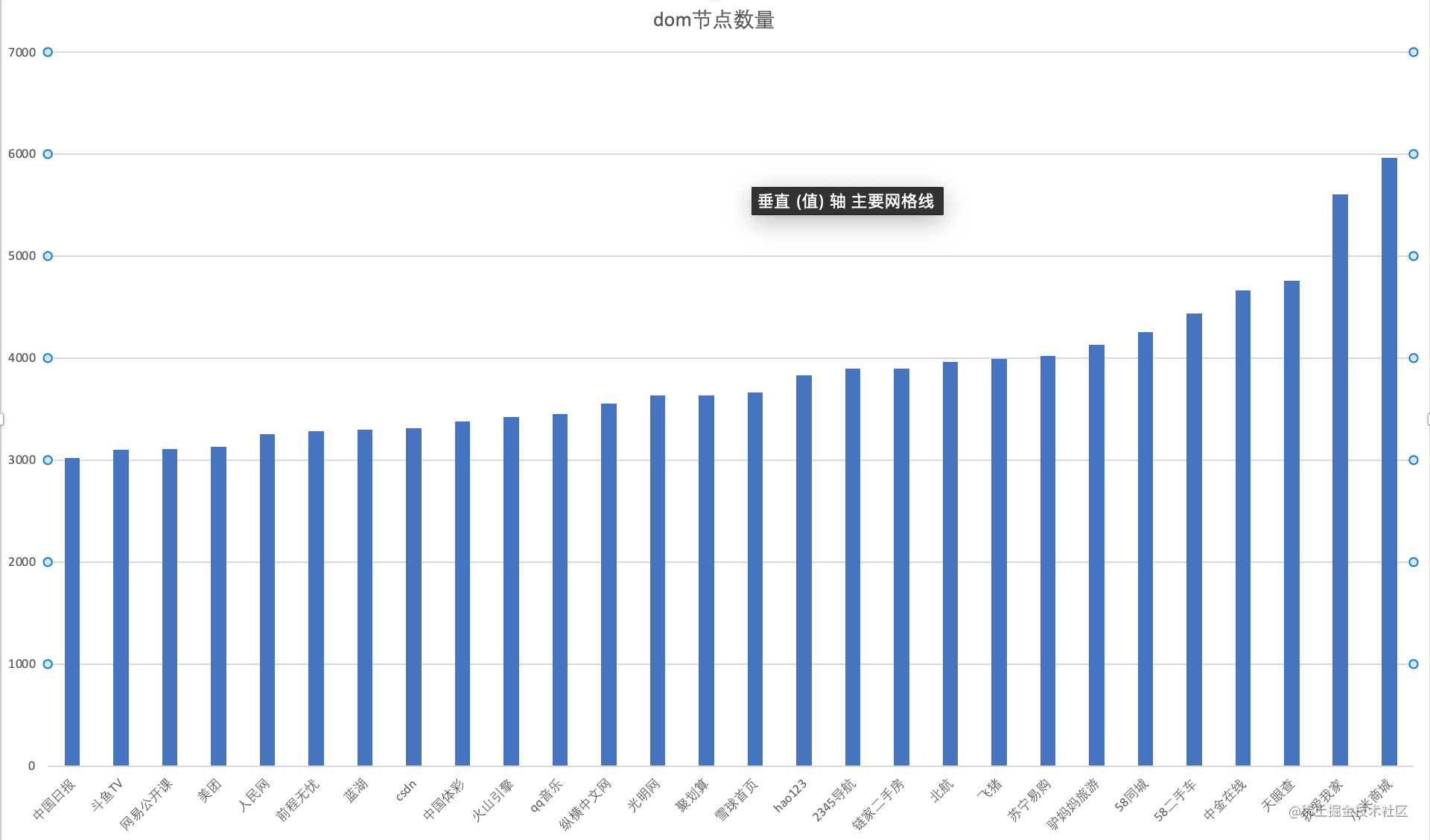
在3000个节点以下的公司有:
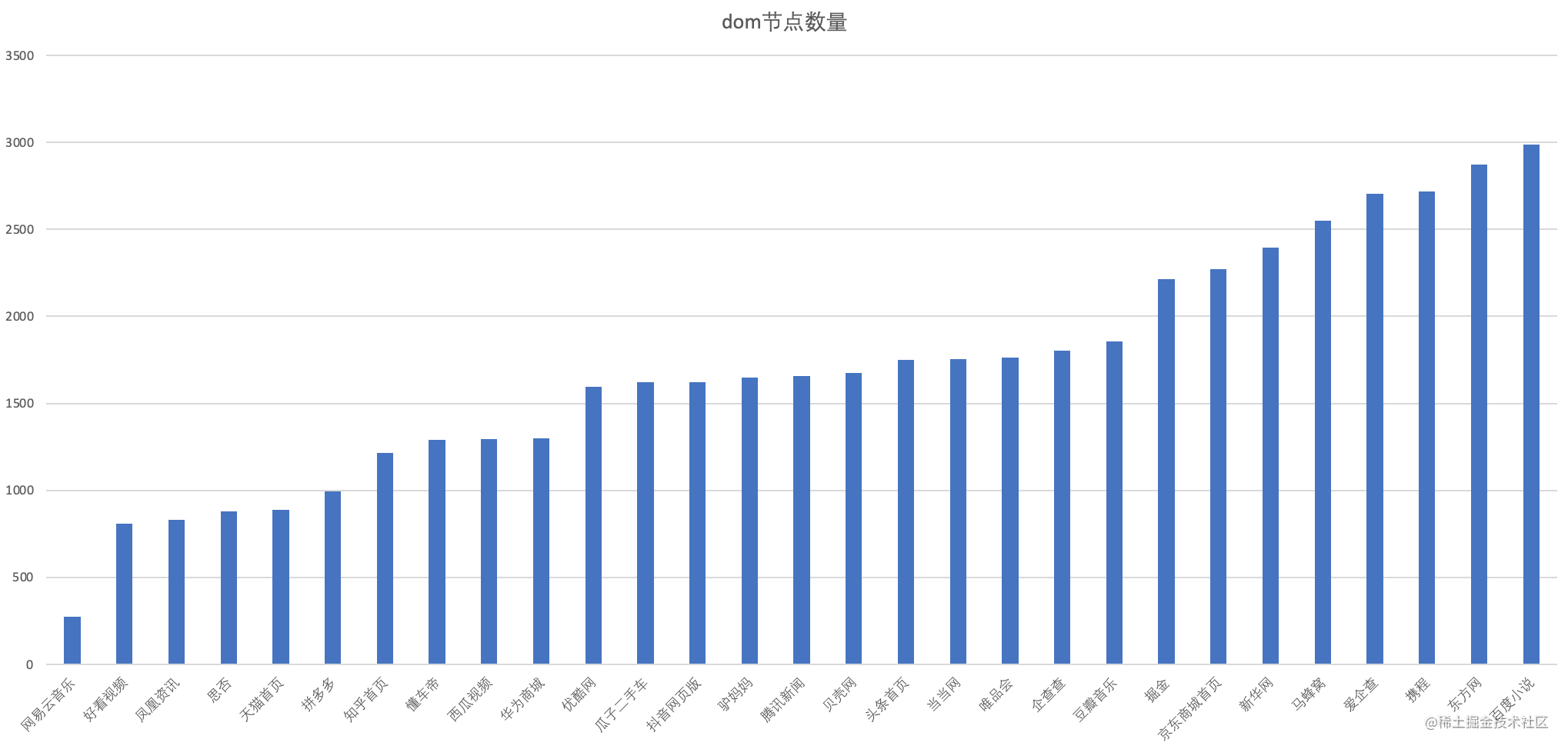
3000-6000个节点以内的公司数据如下
dom节点数量超过6000以上的公司如下,其中汽车之家dom节点最多,有21010个dom节点。
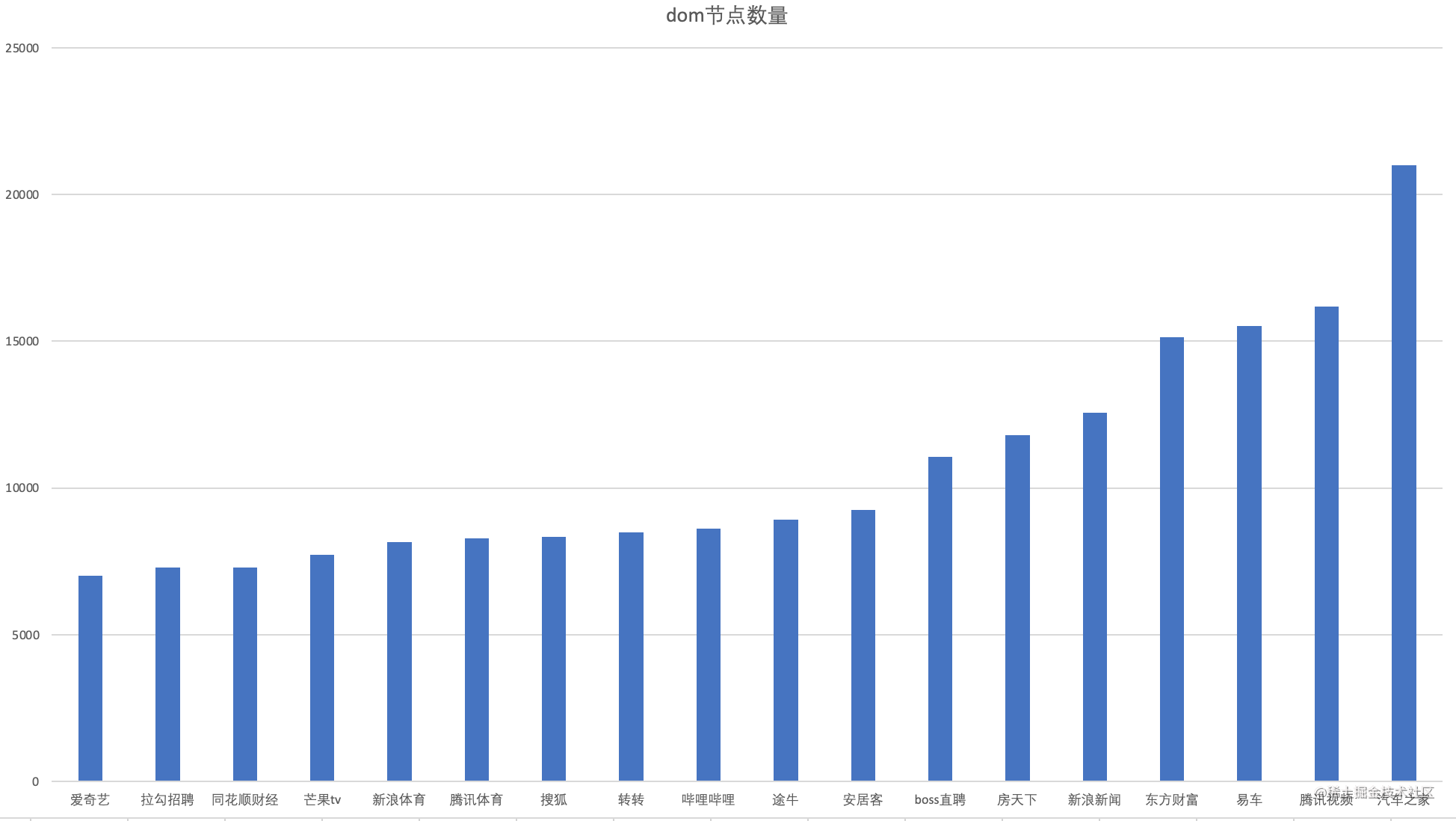
注: 1.dom节点的排名并不代表公司网站性能,仅仅是为估算大概页面节点数量来做一个评估 2.仅考虑首页也就是一级页面。(未做下滑加载更多或者分页的有点吃亏) 3.首页dom节点可不是整个屏幕的节点数量,也包含用户不可见的dom节点
以上70家公司节点在一千和两万之间,平均数为4661,中位数为3881。我们姑且以3800个Dom节点,2000个css节点来计算页面渲染时需要的遍历次数:
z=3800*2000=720万
我们为什么要统计dom节点和css节点数量呢?因为目前dom节点数量与页面渲染息息相关。
dom节点在渲染树中至少存在一个对应的帧节点,这个帧节点有宽高、内外边距和坐标。一旦渲染树构建完成,浏览器便会开始绘制页面。
每当页面出现:dom删除或增加、元素位置或尺寸的属性、元素内容乃至浏览器窗口变化,都会出现重排,大多数浏览器都通过队列和批量执行优化重排。
以汽车之家2万的dom节点为例见下图,如果切换tab效果如下所见(也许本来就是空白,谁让你节点最多)
以上切换均在网络状况良好下进行,如果在惠新西街南口、望京地铁换乘期间(以前上下班在此处换成时基本无网或者网络条件超级差),打开汽车之家的网站,用户体验得有多差。所以为了性能,减少dom节点或者对dom的操作,有的网站甚至有了使用伪元素、批量操作dom(fragment 或者其他)、虚拟dom等的优化方法。
虽然Dom是个独立语言,也就是HTML标签但实际中基本上来源于动态创建,可能来源于php或者后端语言,也可能来自于ajax从后端获取在前端进行拼接。
比如php
<?php foreach ($row as $num => $info) { ?> <div> <div data-label="id"> <?= $num+1 ?> </div> <div data-label="username"> <?= $info["username"] ?> </div> <div data-label="password"> <?= $info["password"] ?> </div> <div data-label="phone"> <?= $info["phone"] ?> </div> </div> <?php } ?>
比如vue
<template> <div class="demo"> <div v-for="(item,index) in list" :key="index"> <img :src="item.src" alt=""> </div> </div></template>
比如react
render() { const getItem = this.props.breadcrumb.map((item, index) => { if (item.href) { return ( <Breadcrumb.Item key={index}> <Link to={item.href}>{item.name}</Link> </Breadcrumb.Item> ); } else { return <Breadcrumb.Item key={index}>{item.name}</Breadcrumb.Item>; } }); return ( <div className="breadcrumb-container"> <Breadcrumb>{getItem}</Breadcrumb> </div> ); }
但无论是通过什么语言进行创建,浏览器都需要对dom进行解析和渲染。
2.页面加载的性能数据有哪些
我们上面收集的dom数量就跟浏览器渲染的时间段息息相关,但在dom出现之前能收集到的技术性能指标数据还有很多。
网络层的:页面域名解析时间、tcp时间、ttfb时间、download时间
浏览器渲染:页面开始的时间、domready的时间、Pageload 时间
页面加载详细数据:css、js、image、fonts等消耗的时间
根据以上我们基本能总结出来一些性能优化的方式和手段,我结合雅虎14条军规做了以下总结
- 使用分子域名加载资源
- 使用较近的CDN或dns预解析
- 使用高性能传输方式或方法,http2,quic,gzip...
- 减少http请求的数量,合并公共资源、使用雪碧图、合并代码块、按需加载资源
- 减少传输总量或加快传输速度
- 优化图片的加载展示策略,根据网络状况加载图片、图片格式优化、图片展示位置优化
- 减少cookie体积
- 使用更有效的缓存策略,keep-alive,expiration,max-age...
- 使用良好的页面布局
- 10合理安排路由策略
- 减少反复操作dom
- 减少重绘和重排
- 异步加载资源
- 公用css类
- 使用GPU渲染初始动画和图层的合成
- 高效的js代码
- 使用防抖和节流对UI进行优化
- 使用web worker加载资源
- 减少301 302
- 试试缓存数据的方法localStorage/sessionStorage/indexedDB
- 无阻塞加载js,减少并发下载或请求
- 减少插件中的多语言版本内容
- 减少布局上的颠簸,减少对临近元素的影响
- 减少同时的动画
- 制定弱网精简策略
- 针对设备制定精简策略
- 减少页面图层
- js、css命名尽量简短
- 减少js全局查找
- 减少循环和循环嵌套以减少js执行时间
- 减少事件绑定
- 组件提取、样式提取、函数提取
- 按照页面变更频率安排资源
- 减少iframe
- 注意页面大小,特别是canvas的大小和占用内存
写在最后的话
本文没有章法,想到哪里写到哪里,本来还打算写几个标题:
性能度量会改变被观测者的性能?
呼之欲出的web 3.0能拯救500ms的限制?
信息架构什么时候能应用到前端领域?
但是掘金的写作体验真的是太差了,而且在写作过程中bug频出。不过目前掘金确是难得的几种传播方式之一。
点名婚贝网站.朋友发来婚礼邀请,打开之后是这个样子

点名掘金页面.滚屏出现了什么鬼
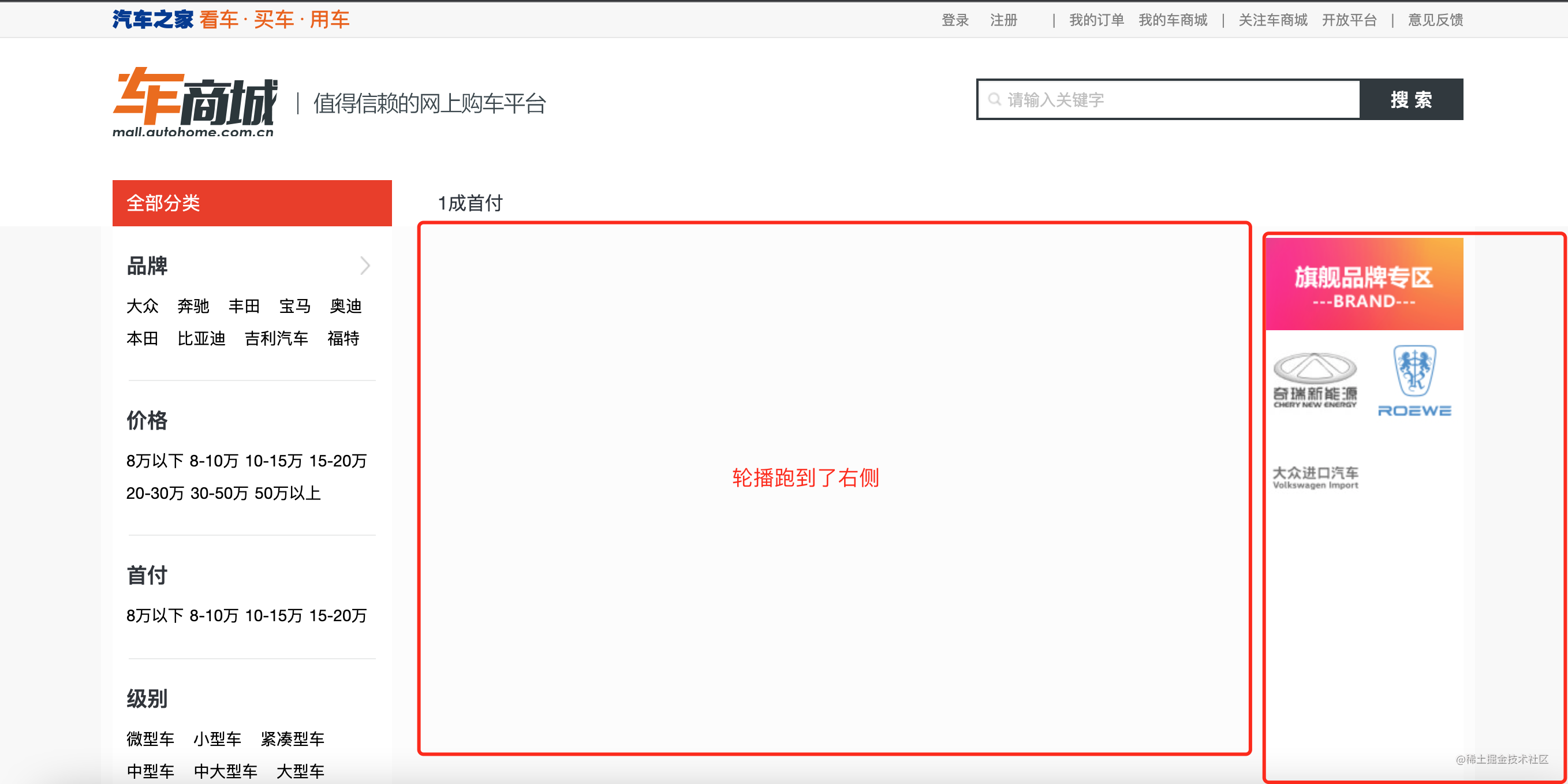
点名汽车之家 这里空白是什么产品体验?
版权归原作者 liugang0605 所有, 如有侵权,请联系我们删除。