
大数据面试之hive重点(四)
Hive如何优化join操作
问过的一些公司:作业帮,池鹜,米哈游参考答案:
1、在map端产生join
mapJoin的主要意思就是,当链接的两个表是一个比较小的表和一个特别大的表的时候,我们把比较小 的table直接放到内存中去,然后再对比较大的表格进行map操作。join就发生在map操作的时候,每当 扫描一个大的table中的数据,就要去去查看小表的数据,哪条与之相符,继而进行连接。这里的join并 不会涉及reduce操作。map端join的优势就是在于没有shuffle,真好。在实际的应用中设置如下:
set hive.auto.convert.join=true; 2
这样设置,hive就会自动的识别比较小的表,继而用mapJoin来实现两个表的联合。看看下面的两个表 格的连接。这里的dept相对来讲是比较小的。我们看看会发生什么,如图所示:
注意看,这里的第一句话就是运行本地的map join任务,继而转存文件到XXX.hashtable下面,在给这个文件里面上传一个文件进行map join,之后才运行了MR代码去运行计数任务。说白了,在本质上mapjoin根本就没有运行MR进程,仅仅是在内存就进行了两个表的联合。具体运行如下图:
2、common join
common join也叫做shuffle join,reduce join操作。这种情况下生再两个table的大小相当,但是又不是很大的情况下使用的。具体流程就是在map端进行数据的切分,一个block对应一个map操作,然后进行shuffle操作,把对应的block shuffle到reduce端去,再逐个进行联合,这里优势会涉及到数据的倾斜,大幅度的影响性能有可能会运行speculation,这块儿在后续的数据倾斜会讲到。因为平常我们用到的数据 量小,所以这里就不具体演示了。
3、SMB Join
smb是sort merge bucket操作,首先进行排序,继而合并,然后放到所对应的bucket中去,bucket是hive 中和分区表类似的技术,就是按照key进行hash,相同的hash值都放到相同的buck中去。在进行两个表 联合的时候。我们首先进行分桶,在join会大幅度的对性能进行优化。也就是说,在进行联合的时候, 是table1中的一小部分和table1中的一小部分进行联合,table联合都是等值连接,相同的key都放到了同 一个bucket中去了,那么在联合的时候就会大幅度的减小无关项的扫描。
Hive的map join
问过的一些公司:58,米哈游参考答案:
1、什么是MapJoin?
MapJoin顾名思义,就是在Map阶段进行表之间的连接。而不需要进入到Reduce阶段才进行连接。这样 就节省了在Shuffle阶段时要进行的大量数据传输。从而起到了优化作业的作用。
2、MapJoin的原理
通常情况下,要连接的各个表里面的数据会分布在不同的Map中进行处理。即同一个Key对应的Value可 能存在不同的Map中。这样就必须等到Reduce中去连接。
要使MapJoin能够顺利进行,那就必须满足这样的条件:除了一份表的数据分布在不同的Map中外,其 他连接的表的数据必须在每个Map中有完整的拷贝。
3、MapJoin适用的场景
通过上面分析可以有发现,并不是所有的场景都适合用MapJoin。它通常会用在如下的一些情景:在二 个要连接的表中,有一个很大,有一个很小,这个小表可以存放在内存中而不影响性能。
这样我们就把小表文件复制到每一个Map任务的本地,再让Map把文件读到内存中待用。
4、MapJoin的实现方法:
在Map-Reduce的驱动程序中使用静态方法 DistributedCache.addCacheFile() 增加要拷贝的小表文件。JobTracker在作业启动之前会获取这个URI列表,并将相应的文件拷贝到各个TaskTracker的本地磁盘 上。
在Map类的setup方法中使用DistributedCache.getLocalCacheFiles()方法获取文件目录,并使用标准的文件 读写API读取相应的文件。
5、Hive内置提供的优化机制之一就包括MapJoin
在Hive v0.7之前,需要使用hint提示 /*+ mapjoin(table) */才会执行MapJoin。Hive v0.7之后的版本已经不需要给出MapJoin的指示就进行优化。它是通过如下配置参数来控制的:
1 hive> set hive.auto.convert.join=true; 2
Hive还提供另外一个参数–表文件的大小作为开启和关闭MapJoin的阈值。
hive.mapjoin.smalltable.filesize=25000000
– 即25M
Hive语句的运行机制,例如包含where、having、group by、order by,整个的执行过程?
问过的一些公司:小米参考答案:
1、Hive语句运行机制
- 架构图
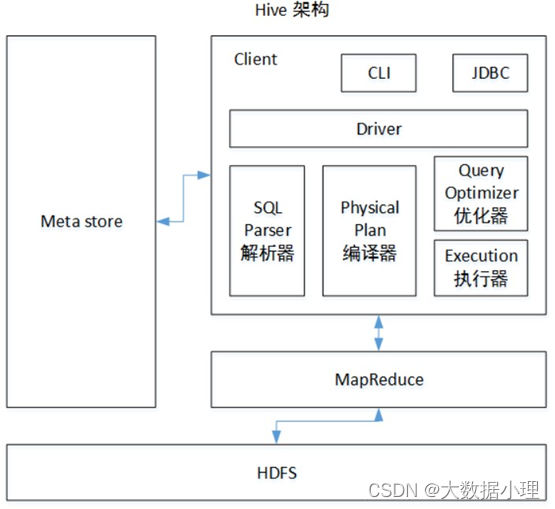
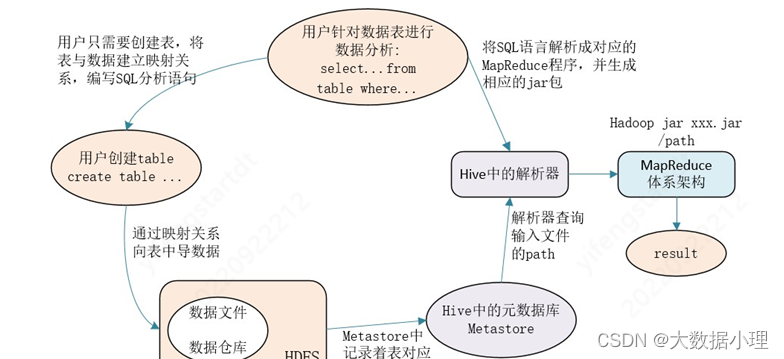
- 用户提交查询等任务给Driver。
- 编译器获得该用户的任务Plan。
- 编译器Compiler根据用户任务去MetaStore中获取需要的Hive的元数据信息。
- 编译器Compiler得到元数据信息,对任务进行编译,先将HiveQL转换为抽象语法树,然后将抽象语 法树转换成查询块,将查询块转化为逻辑的查询计划,重写逻辑查询计划,将逻辑计划转化为物理的计 划(MapReduce), 最后选择最佳的策略。
- 将最终的计划提交给Driver。
- Driver将计划Plan转交给ExecutionEngine去执行,获取元数据信息,提交给JobTracker或者SourceManager执行该任务,任务会直接读取HDFS中文件进行相应的操作。
- 获取执行的结果。
- 取得并返回执行结果。创建表时: 解析用户提交的Hive语句–>对其进行解析–>分解为表、字段、分区等Hive对象。根据解析到的信息构建 对应的表、字段、分区等对象,从SEQUENCE_TABLE中获取构建对象的最新的ID,与构建对象信息(名 称、类型等等)一同通过DAO方法写入元数据库的表中,成功后将SEQUENCE_TABLE中对应的最新ID+5. 实际上常见的RDBMS都是通过这种方法进行组织的,其系统表中和Hive元数据一样显示了这些ID信息。 通过这些元数据可以很容易的读取到数据。 2、Hive语句执行顺序
- Hive语句书写顺序
- (1)select
- (2)from
- (3)join on
- (4) where
- (5)group by
- (6)having
- (7)distribute by/cluster by
- (8) sort by
- (9) order by
- (10) limit
- (11) union(去重不排序)/union all(不去重不排序) 12
- Hive语句执行顺序
1 (1)from
2 (2)on
- (3)join
- (4)where
- (5)group by
- (6)having
- (7)select
- (8)distinct
- (9)distribute by /cluster by
- (10)sort by
- (11) order by
- (12) limit
- (13) union /union all 14
Hive使用的时候会将数据同步到HDFS,小文件问题怎么解决的?
问过的一些公司:360,陌陌(2021.10) 参考答案:
首先,我们要弄明白两个问题:
62 哪里会产生小文件
源数据本身有很多小文件动态分区会产生大量小文件
reduce个数越多, 小文件越多
按分区插入数据的时候会产生大量的小文件, 文件个数= maptask个数* 分区数
63 小文件太多造成的影响
从Hive的角度看,小文件会开很多map,一个map开一个JVM去执行,所以这些任务的初始化,启 动,执行会浪费大量的资源,严重影响性能。
HDFS存储太多小文件, 会导致namenode元数据特别大, 占用太多内存, 制约了集群的扩展
小文件解决方案:
方法一:通过调整参数进行合并
- 在Map输入的时候, 把小文件合并
- – 每个Map最大输入大小,决定合并后的文件数
- set mapred.max.split.size=256000000;
- – 一个节点上split的至少的大小 ,决定了多个data node上的文件是否需要合并
- set mapred.min.split.size.per.node=100000000;
- – 一个交换机下split的至少的大小,决定了多个交换机上的文件是否需要合并
- set mapred.min.split.size.per.rack=100000000;
- – 执行Map前进行小文件合并
- set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; 9
- 在Reduce输出的时候, 把小文件合并
- – 在map-only job后合并文件,默认true
- set hive.merge.mapfiles = true;
- – 在map-reduce job后合并文件,默认false
- set hive.merge.mapredfiles = true; 5 – 合并后每个文件的大小,默认256000000
- set hive.merge.size.per.task = 256000000;
- – 平均文件大小,是决定是否执行合并操作的阈值,默认16000000
- set hive.merge.smallfiles.avgsize = 100000000; 9 方法二:针对按分区插入数据的时候产生大量的小文件的问题,可以使用DISTRIBUTE BY rand() 将数据随机分配给Reduce,这样可以使得每个Reduce处理的数据大体一致。
– 设置每个reducer处理的大小为5个G
set hive.exec.reducers.bytes.per.reducer=5120000000;
– 使用distribute by rand()将数据随机分配给reduce, 避免出现有的文件特别大, 有的文件特别小
insert overwrite table test partition(dt) select * from iteblog_tmp
DISTRIBUTE BY rand();
方法三:使用Sequencefile作为表存储格式,不要用textfile,在一定程度上可以减少小文件
方法四:使用hadoop的archive归档
– 用来控制归档是否可用
set hive.archive.enabled=true;
– 通知Hive在创建归档时是否可以设置父目录
set hive.archive.har.parentdir.settable=true;
– 控制需要归档文件的大小
set har.partfile.size=1099511627776;
– 使用以下命令进行归档
ALTER TABLE srcpart ARCHIVE PARTITION(ds=‘2008-04-08’, hr=‘12’);
– 对已归档的分区恢复为原文件
ALTER TABLE srcpart UNARCHIVE PARTITION(ds=‘2008-04-08’, hr=‘12’);
– 注意,归档的分区不能够INSERT OVERWRITE,必须先unarchive
Hadoop自带的三种小文件处理方案
Hadoop Archive
Hadoop Archive或者HAR,是一个高效地将小文件放入HDFS块中的文件存档工具,它能够将多个小文件打包成一个HAR文件,这样在减少namenode内存使用的同时,仍然允许对文件进行 透明的访问。
Sequence file
sequence file由一系列的二进制key/value组成,如果为key小文件名,value为文件内容,则可以将大批小文件合并成一个大文件。
CombineFileInputFormat
它是一种新的inputformat,用于将多个文件合并成一个单独的split,另外,它会考虑数据的 存储位置。
Hive ShuGle的具体过程
问过的一些公司:竞技世界参考答案:
Shuffle其实就是“洗牌”,整个过程也就是清洗重发的过程,map方法后,reduce方法之前。
首先是inputsplit,每个切片对应一个map(可以通过yarn去观察),map端首先对读入数据做按不同数 据类型做分区,之后根据不同分区做排序(这里采用的快速排序),map过程中会有内存缓冲区(环形 缓冲区),它的作用是在数据写入过程中,将数据存入内存从而达到减少IO开启的资源消耗,提高分 区,排序的资源量(hive优化中提到map join小表在前存入内存也源于此处),当缓冲区的写入达到默认的0.8(80mb,可更改设置),将开启溢写将内容写入临时文件同时剩下的写入会继续写入到剩余0.2。
这整个过程中会产生大量临时文件,通过merge最后合并成一个文件,分区且有序(归并排序), 到这map端基本结束。(写入内存前可以通过开启 combine ,一般公司都会在map开启来达到减小数据量提高效率,实现的效果 : map的输出是 (key,value ),combine 后输出自然减少了)。
reduce端是通过http协议抓取数据(fetch),map跑完reduce开始抓数,这里涉及到数据倾斜的问题(需 要注意),reduce对数据同样通过partition,sort (归并排序),整理好的数据最后进入reduce操作。
Hive有哪些保存元数据的方式,都有什么特点?
问过的一些公司:冠群驰骋参考答案:
内嵌模式:将元数据保存在本地内嵌的derby数据库中,内嵌的derby数据库每次只能访问一个数据文 件,也就意味着它不支持多会话连接。
本地模式:将元数据保存在本地独立的数据库中(一般是mysql),这可以支持多会话连接。
远程模式:把元数据保存在远程独立的mysql数据库中,避免每个客户端都去安装mysql数据库。
三种配置方式区别
内嵌模式使用的是内嵌的Derby数据库来存储元数据,也不需要额外起Metastore服务。这个是默认 的,配置简单,但是一次只能一个客户端连接,适用于用来实验,不适用于生产环境。不常用。 本地元存储和远程元存储都采用外部数据库来存储元数据,目前支持的数据库有:MySQL、Postgres、Oracle、MS SQL Server。MySQL较常用。
本地元存储和远程元存储的区别是:本地元存储不需要单独起metastore服务,用的是跟hive在同一 个进程里的metastore服务。远程元存储需要单独起metastore服务,然后每个客户端都在配置文件 里配置连接到该metastore服务。远程元存储的metastore服务和hive运行在不同的进程。不常用。
Hive SQL实现查询用户连续登陆,讲讲思路
问过的一些公司:美团参考答案:
这里连续活跃登陆的用户指至少连续2天都活跃登录的用户
解决类似场景的问题创建数据
CREATE TABLE test5active( dt string,
user_id string, age int)
ROW format delimited fields terminated BY ‘,’;
INSERT INTO TABLE test5active VALUES
(‘2019-02-11’,‘user_1’,23),(‘2019-02-11’,‘user_2’,19),
(‘2019-02-11’,‘user_3’,39),(‘2019-02-11’,‘user_1’,23),
(‘2019-02-11’,‘user_3’,39),(‘2019-02-11’,‘user_1’,23),
(‘2019-02-12’,‘user_2’,19),(‘2019-02-13’,‘user_1’,23),
(‘2019-02-15’,‘user_2’,19),(‘2019-02-16’,‘user_2’,19);
1、因为每天用户登录次数可能不止一次,所以需要先将用户每天的登录日期去重。
思路一
2、再用row_number() over(partition by _ order by _)函数将用户id分组,按照登陆时间进行排序。3、计算登录日期减去第二步骤得到的结果值,用户连续登陆情况下,每次相减的结果都相同。
4、按照id和日期分组并求和,筛选大于等于2的即为连续活跃登陆的用户。
第一步:用户登录日期去重
1 select DISTINCT dt,user_id from test5active; 2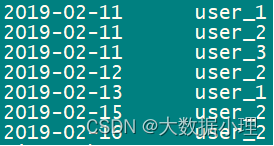
- select
- t1.user_id,t1.dt,
- row_number() over(partition by t1.user_id order by t1.dt) day_rank
- from 5 ( 6 select DISTINCT dt,user_id from test5active 7 )t1; 第三步:日期减去计数值得到结果

- select
- t2.user_id,t2.dt,date_sub(t2.dt,t2.day_rank) as dis
- from 4 (
- select
- t1.user_id,t1.dt,
- row_number() over(partition by t1.user_id order by t1.dt) day_rank
- from 9 ( 10 select DISTINCT dt,user_id from test5active 11 )t1)t2;
第四步:根据id和结果分组并计算总和,大于等于2的即为连续登陆的用户,得到 用户id,开始日期, 结束日期 ,连续登录天数
思路二
- select
- t3.user_id,min(t3.dt),max(t3.dt),count(1)
- from 4 (
- select
- t2.user_id,t2.dt,date_sub(t2.dt,t2.day_rank) as dis
- from 8 (
- select
- t1.user_id,t1.dt,
- row_number() over(partition by t1.user_id order by t1.dt) day_rank
- from 13 ( 14 select DISTINCT dt,user_id from test5active 15 )t1 16 )t2 17 )t3 group by t3.user_id,t3.dis having count(1)>1; 18 结果:
1
2
3
4
用户id
user_2 user_2
开始日期
2019-02-11
2019-02-15
结束日期
2019-02-12
2019-02-16
连续登录天数
2
2
第五步:连续登陆的用户
- select distinct t4.user_id
- from 3 (
- select
- t3.user_id,min(t3.dt),max(t3.dt),count(1)
- from 7 (
- select
- t2.user_id,t2.dt,date_sub(t2.dt,t2.day_rank) as dis
- from 11 (
- select
- t1.user_id,t1.dt,
- row_number() over(partition by t1.user_id order by t1.dt) day_rank
- from 16 ( 17 select DISTINCT dt,user_id from test5active 18 )t1 19 )t2 20 )t3 group by t3.user_id,t3.dis having count(1)>1 21 )t4; 22 最后结果:
:使用lag(向后)或者lead(向前)
- select
- user_id,t1.dt,
- lead(t1.dt) over(partition by user_id order by t1.dt) as last_date_id
- from 5 ( 6 select DISTINCT dt,user_id from test5active 7 )t1; 8
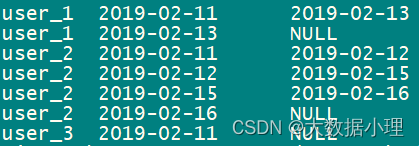
- select
- distinct t2.user_id
- from 4 (
- select
- user_id,t1.dt,
- lead(t1.dt) over(partition by user_id order by t1.dt) as last_date_id
- from 9 ( 10 select DISTINCT dt,user_id from test5active 11 )t1 12 )t2 where datediff(last_date_id,t2.dt)=1; 13 最后结果:
 Hive的开窗函数有哪些 问过的一些公司:北京元安物联社招,京东(2021.09) 参考答案: 分析函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是:对于每个组返回多行,而聚合函 数对于每个组只返回一行。 开窗函数指定了分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化! 基础结构如下: 分析函数(如:sum(),max(),row_number()…) + 窗口子句(over函数)
Hive的开窗函数有哪些 问过的一些公司:北京元安物联社招,京东(2021.09) 参考答案: 分析函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是:对于每个组返回多行,而聚合函 数对于每个组只返回一行。 开窗函数指定了分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化! 基础结构如下: 分析函数(如:sum(),max(),row_number()…) + 窗口子句(over函数)
1、SUM函数
求和,窗口函数和聚合函数的不同,sum()函数可以根据每一行的窗口返回各自行对应的值,有多少行 记录就有多少个sum值,而group by只能计算每一组的sum,每组只有一个值。sum()计算的是分区内排序后一个个叠加的值,和order by有关。
2、NTILE函数
NTILE(n),用于将分组数据按照顺序切分成n片,返回当前切片值 注意:
如果切片不均匀,默认增加第一个切片的分布
NTILE不支持ROWS BETWEEN
3、ROW_NUMBER 函数
ROW_NUMBER():从1开始,按照顺序,生成分组内记录的序列
ROW_NUMBER():的应用场景非常多,比如获取分组内排序第一的记录、获取一个session中的第一条
refer等:
4、RANK 和 DENSE_RANK 函数
RANK():生成数据项在分组中的排名,排名相等会在名次中留下空位
DENSE_RANK():生成数据项在分组中的排名,排名相等会在名次中不会留下空位
5 、 CUME_DIST 函 数cume_dist:返回小于等于当前值的行数/分组内总行数 6、PERCENT_RANK 函数
percent_rank:分组内当前行的RANK值-1/分组内总行数-1
注意:一般不会用到该函数,可能在一些特殊算法的实现中可以用到吧
7、LAG 和 LEAD 函数
LAG(col,n,DEFAULT):用于统计窗口内往上第n行值
第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行 为NULL时候,取默认值,如不指定,则为NULL)
LEAD 函数则与 LAG 相反:
LEAD(col,n,DEFAULT):用于统计窗口内往下第n行值
第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行 为NULL时候,取默认值,如不指定,则为NULL)
8、FIRST_VALUE 和 LAST_VALUE 函数
FIRST_VALUE:取分组内排序后,截止到当前行,第一个值LAST_VALUE 函 数 则 相 反 : LAST_VALUE:取分组内排序后,截止到当前行,最后一个值
这两个函数还是经常用到的(往往和排序配合使用),比较实用!
Hive存储数据吗
问过的一些公司:vivo(2021.06) 参考答案:
Hive本身不存储数据。
Hive的数据分为表数据和元数据,表数据是Hive中表格(table)具有的数据;而元数据是用来存储表的名 字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
Hive建表后,表的元数据存储在关系型数据库中(如:mysql),表的数据(内容)存储在hdfs中,这 些数据是以文本的形式存储在hdfs中(关系型数据库是以二进制形式存储的),既然是存储在hdfs上, 那么这些数据本身也是有元数据的(在NameNode中),而数据在DataNode中。这里注意两个元数据的 不同。
Hive的SQL转换为MapReduce的过程?
问过的一些公司:远景智能(2021.08),美团买菜(2021.09),京东(2021.09) 参考答案:
HiveSQL ->AST(抽象语法树) -> QB(查询块) ->OperatorTree(操作树)->优化后的操作树->mapreduce任务树->优化后的mapreduce任务树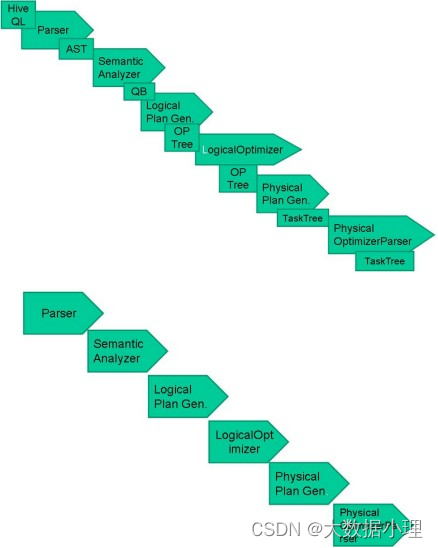
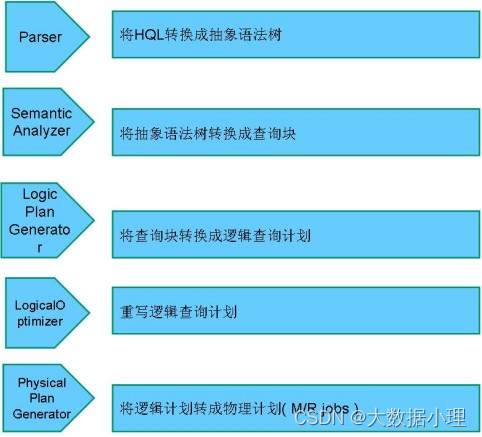
过程描述如下:
SQL Parser:Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象 语法树AST Tree
Semantic Analyzer:遍历AST Tree,抽象出查询的基本组成单元QueryBlock
Logical plan:遍历QueryBlock,翻译为执行操作树OperatorTree
Logical plan optimizer:逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少
shuffle数据量
Physical plan:遍历OperatorTree,翻译为MapReduce任务
Logical plan optimizer:物理层优化器进行MapReduce任务的变换,生成最终的执行计划
Hive的函数:UDF、UDAF、UDTF的区别?
问过的一些公司:好未来(2021.08),字节(2021.08) 参考答案:
UDF: 单行进入,单行输出UDAF: 多行进入,单行输出UDTF: 单行输入,多行输出
UDF是怎么在Hive里执行的
问过的一些公司:携程(2021.09)
参考答案:
打包成jar上传到集群,注册自定义函数,通过类加载器载入系统,在sql解析的过程中去调用函数
Hive优化
问过的一些公司:货拉拉(2021.07),字节(2021.08)-(2021.09),京东(2021.09)x3,蔚来(2021.09) 参考答案:
Fetch抓取
Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算。例如:SELECT * FROM employees;在这种情况下,Hive可以简单地读取employee对应的存储目录下的文件,然后输出查询结果 到控制台
在hive-default.xml.template文件中hive.fetch.task.conversion默认是more,老版本hive默认是minimal,该 属性修改为more以后,在全局查找、字段查找、limit查找等都不走mapreduce
本地模式
大多数的Hadoop Job是需要Hadoop提供的完整的可扩展性来处理大数据集的。不过,有时Hive的输入数据量是非常小的。在这种情况下,为查询触发执行任务时消耗可能会比实际job的执行时间要多的
多。对于大多数这种情况,Hive可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行 时间可以明显被缩短
用户可以通过设置hive.exec.mode.local.auto的值为true,来让Hive在适当的时候自动启动这个优化
表的优化
- 小表、大表join 将key相对分散,并且数据量小的表放在join的左边,这样可以有效减少内存溢出错误发生的几率;再进 一步,可以使用Group让小的维度表(1000条以下的记录条数)先进内存。在map端完成reduce 实际测试发现:新版的hive已经对小表JOIN大表和大表JOIN小表进行了优化。小表放在左边和右边已经 没有明显区别 64 大表Join小表 空KEY过滤 有时join超时是因为某些key对应的数据太多,而相同key对应的数据都会发送到相同的reducer上,从而 导致内存不够。此时我们应该仔细分析这些异常的key,很多情况下,这些key对应的数据是异常数据, 我们需要在SQL语句中进行过滤。例如key对应的字段为空 65 Group By 默认情况下,Map阶段同一Key数据分发给一个reduce,当一个key数据过大时就倾斜了 并不是所有的聚合操作都需要在Reduce端完成,很多聚合操作都可以先在Map端进行部分聚合,最后在 Reduce端得出最终结果 1)开启Map端聚合参数设置
- 是否在Map端进行聚合,默认为True
1 hive.map.aggr = true 2
- 在Map端进行聚合操作的条目数目
1 hive.groupby.mapaggr.checkinterval = 100000 2
- 有数据倾斜的时候进行负载均衡(默认是false)
1 hive.groupby.skewindata = true 2
当选项设定为 true,生成的查询计划会有两个MR Job。第一个MR Job中,Map的输出结果会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MR Job再根据预处理的数据结果按照Group By Key分布到Reduce中(这个过程可以保证相同的Group By Key被分布到同一个Reduce中),最后完成最终的聚合操作
66 Count(Distinct) 去重统计
数据量小的时候无所谓,数据量大的情况下,由于COUNT DISTINCT操作需要用一个Reduce Task来完成,这一个Reduce需要处理的数据量太大,就会导致整个Job很难完成,一般COUNT DISTINCT使用先GROUP BY再COUNT的方式替换
67 笛卡尔积
尽量避免笛卡尔积,join的时候不加on条件,或者无效的on条件,Hive只能使用1个reducer来完成笛卡 尔积
68 行列过滤
列处理:在SELECT中,只拿需要的列,如果有,尽量使用分区过滤,少用SELECT *。
行处理:在分区剪裁中,当使用外关联时,如果将副表的过滤条件写在Where后面,那么就会先全表关 联,之后再过滤
数据倾斜部分就参考前面的题目就行
row_number,rank,dense_rank的区别
问过的一些公司:美团(2021.09) 参考答案:
row_number():从1开始,按照顺序,生成分组内记录的序列,row_number()的值不会存在重复,当排序 的值相同时,按照表中记录的顺序进行排列;通常用于获取分组内排序第一的记录;获取一个session中的第 一条refer等。
rank():生成数据项在分组中的排名,排名相等会在名次中留下空位。dense_rank():生成数据项在分组中的排名,排名相等会在名次中不会留下空位。 注意: rank和dense_rank的区别在于排名相等时会不会留下空位
Hive count(distinct)有几个reduce,海量数据会有什么问题
问过的一些公司:字节(2021.07) 参考答案:
count(distinct)只有1个reduce。
为什么只有一个reducer呢,因为使用了distinct和count(full aggreates),这两个函数产生的mr作业只会产生一个reducer,而且哪怕显式指定set mapred.reduce.tasks=100000也是没用的。
当使用count(distinct)处理海量数据(比如达到一亿以上)时,会使得运行速度变得很慢,熟悉mr原理的 就明白这时sql跑的慢的原因,因为出现了很严重的数据倾斜。
案例分析:
做去重统计时,一般都这么写:
- select
- count(distinct (bill_no)) as visit_users
- from
- i_usoc_user_info_d
- where 6 p_day = ‘20210508’
- and bill_no is not null
- and bill_no != ‘’ 9 其实看起来,这没有任务毛病,但我们需要注意的是,此时写的是hql,它的底层引擎是MapReduce,是 分布式计算的,所以就会出现数据倾斜这种分布式计算的典型问题,比如上面的使用数仓中一张沉淀了 所有用户信息的融合模型来统计所有的手机号码的个数,这种写法肯定是能跑出结果的,但运行时长可 能就会有点长。 我们去查下,就会发现记录数至少上亿,去hdfs中查看文件会发现这个分区很大,并且此时,我们通过 查看执行计划和日志可以发现只有一个stage。也就是说最后只有一个reduce。 熟悉mr原理的已经明白了这条sql跑的慢的原因,因为出现了很严重的数据倾斜,几百个mapper,1个 reducer,所有的数据在mapper处理过后全部只流向了一个reducer,逻辑计划大概如下:
为什么只有一个reducer呢,因为使用了distinct和count(full aggreates),这两个函数产生的mr作业只会产生一个reducer,而且哪怕显式指定set mapred.reduce.tasks=100000也是没用的。
所以对于这种去重统计,如果在数据量够大,一般是一亿记录数以上(视公司的集群规模,计算能力而 定),建议选择使用count加group by去进行统计:
- select
- count(a.bill_no)
- from 4 (
- select
- bill_no
- from
- dwfu_hive_db.i_usoc_user_info_d
- where p_day = ‘20200408’ and bill_no is not null and bill_no != ‘’ group by bill_no ) a 这时候再测试,会发现速度会快很多,查看执行计划和日志,会发现启动了多个stage,也就是多个mr 作业,这是因为引入了group by将数据分组到了多个reducer上进行处理。逻辑执行图大致如下:
总结:在数据量很大的情况下,使用count+group by替换count(distinct)能使作业执行效率和速度得到很大的提升,一般来说数据量越大提升效果越明显。
注意:开发前最好核查数据量,别什么几万条几十万条几十M数据去重统计就count加groupby就咔咔往 上写,最后发现速度根本没有直接count(distinct)快,作业还没起起来人家count(distinct)就完事结果出来 了,所以优化还得建立在一个数据量的问题上,这也是跟其他sql的区别。
版权归原作者 大数据小理 所有, 如有侵权,请联系我们删除。