
Doris框架
大规模并行处理的分析型数据库产品。使用场景:一般先将原始数据经过清洗过滤转换后,再导入doris中使用。主要实现的功能有:
- 实时看板 - 面向企业内部分析师和管理者的报表- 面向用户或者客户的高并发报表分析
- 即席查询
- 统一数仓构建:替换了原来由Spark, Hive,Kudu, Hbase等旧框架
- 数据湖联邦查询:通过外表的方式联邦分析位于Hive,IceBerg,Hudi中的数据
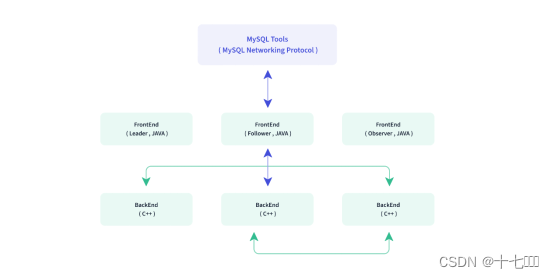
Doris架构
- 后端:C语言编写的,用于数据查询
- 前端:Leader, Follower, Oberserver
部署注意事项
- 磁盘空间按用户总数据量x3副本计算,然后再预留额外40%的空间。
- 所有部署节点关闭swap
- FE节点数据至少为1。一个Follower和一个Observer时,可以实现高可用

参数修改
- 最大同时打开文件个数
- 设置最大虚拟块,sudo reboot重启后生效
- 根据自己需求下载对应的安装包,如果是苹果电脑下载arm包,否则选择x64. https://doris.apache.org/download/
- 解压安装fe, be,以及其他依赖,也就是下载的安装包里面的三个文件。
- 由于虚拟机有多张网卡,因此需要修改对应的网段信息,和NAT模式里面的网段对应。
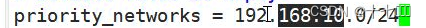
- 如果参数配置错误,导致无法成功启动,直接删掉已经安装的文件,直接重新解压。
配置BE
- 修改web_server的端口号,改为7040
- 修改网段地址为NAT的网段
- 添加单台后端BE
ALTER SYSTEM ADD BACKEND "hadoop102:9050"; /opt/module/doris/be/bin/start_be.sh --daemon启动后端SHOW PROC '/backends'\G查看后端状态
BE后台节点变更
- 建议直接分发BE压缩包,因为Doris解压启动后就会产生底层数据,直接使用新的压缩包扩容会更为方便。在MySQL客户端,通过
ALTER SYSTEM ADD BACKEND - 减少节点时需要先移动数据,然后再删除。
ALTER SYSTEM DECOMMISSION BACKEND "be_host:be_heartbeat_service_port";
FE节点的变更
- 分发fe文件,注意删除元数据。hadoop102 发过来的元数据
rm -rf /opt/module/doris/fe/doris-meta/* - 启动FE:
/opt/module/doris/fe/bin/start_fe.sh --daemon --helper hadoop102:9010 - 查看FE状态:
show proc '/frontends'; - FE的缩容:
ALTER SYSTEM DROP FOLLOWER[OBSERVER] "fe_host:edit_log_port";
群启群关脚本
- 创建脚本为doris.sh
#!/bin/bash
case $1 in
"start")for host in hadoop102 hadoop103 hadoop104 ;do
echo "========== 在 $host 上启动 fe ========="
ssh $host "source /etc/profile; /opt/module/doris/fe/bin/start_fe.sh --daemon"
done
for host in hadoop102 hadoop103 hadoop104 ;do
echo "========== 在 $host 上启动 be ========="
ssh $host "source /etc/profile; /opt/module/doris/be/bin/start_be.sh --daemon"
done
;;"stop")for host in hadoop102 hadoop103 hadoop104 ;do
echo "========== 在 $host 上停止 fe ========="
ssh $host "source /etc/profile; /opt/module/doris/fe/bin/stop_fe.sh "
done
for host in hadoop102 hadoop103 hadoop104 ;do
echo "========== 在 $host 上停止 be ========="
ssh $host "source /etc/profile; /opt/module/doris/be/bin/stop_be.sh "
done
;;*)
echo "你启动的姿势不对"
echo " start 启动doris集群"
echo " stop 停止stop集群";;
esac
- chmod +x doris.sh 添加脚本执行权限
数据表设计
- row: 用户的一行数据
- column:描述一行数据中的不同字段 - key: 维度列- value:指标列
- 分区分片 - Tablet:数据分片,数据划分的最小逻辑单元- Partition:最小的管理单元,数据的导入与删除,都只能针对一个partition进行
- 数据模型 - Aggregate聚合模型 - 一般用来存放事实表- 副本数不能高于be的个数- 没有幂等性,如果sum求和,多次插入同样数据时,结果会加起来- Unique唯一性模型 - 使用unique key(k1, k2)来保证key的唯一- 底层其实也是使用聚合模型,非主键使用replace关键字- Duplicate重复模型 - 一般用于收集日志- 数据会自动排序
建表语法
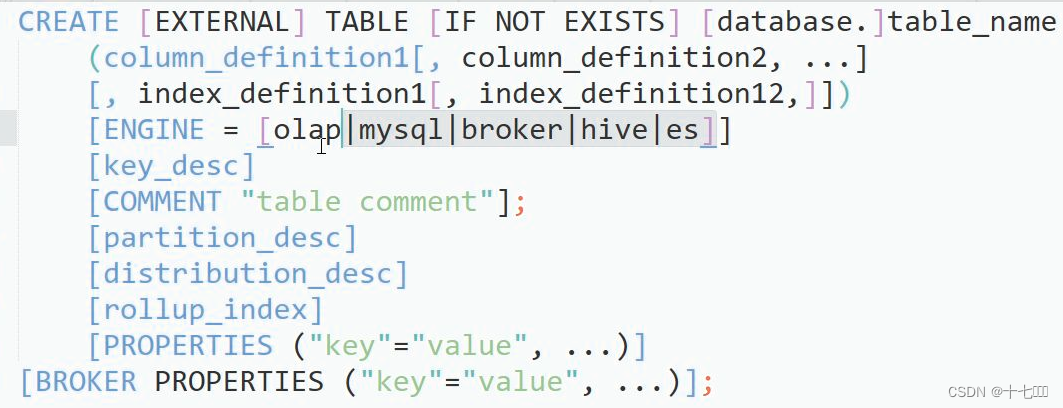
- olap是默认引擎,字段可以设置引擎,如果是其他的引擎,就表示远程连接其他数据库
- 尽量选择整型类型,整型长度遵循够用即可
- 分区方式,如果不分区时,会默认创建一个跟表名一致的分区 - range分区,一般按照天数划分。一般使用value less than 的方式来指定上界,区间都是左闭右开的- list分区,一般按照城市划分。使用value in(一般是城市名称列表)
- 分桶:分桶字段一般是join时使用的关键字字段。建议桶的个数等于离线时划分的个数。一般为10~20.
- propertities属性 - 副本数- 设定到期时间,到期后作为冷数据放到机械硬盘
动态分区
动态分区只支持Range分区,动态分区功能启动时,FE会启动一个后台进程,根据用户指定的规则创建或删除分区。
- 查看分区详情:
show partition from 表名 - 如果分区不存在,则无法插入数据。并且会报错
no partition for this tuple
上卷
- desc 表名 all :查询表格的全部信息
- 上卷类似MR中的预聚合,提前创建好要查询的指标。后期查询该数据时,直接返回即可。也可以对于部分数据做排序。
物化视图
预先计算定义好的数据集,存储在Doris中的一个特殊的表。加快对固定维度进行分析查询。
- 适用场景: - 查询仅涉及表中的很小一部分列或行- 查询包含一些耗时处理操作,比如,事件很久的聚合操作- 查询需要匹配不同的前缀索引
- 使用 - 创建物化视图- 检查物化视图是否构建完成
desc sales_records all;- 检验当前查询是否匹配到了合适的物化视图EXPLAIN SELECT store_id, sum(sale_amt) FROM sales_records GROUP BY store_id;
create materialized view store_amt asselect
store_id,sum(sale_amt)from sales_records
groupby store_id;
本文转载自: https://blog.csdn.net/qq_44273739/article/details/135213409
版权归原作者 十七✧ᐦ̤ 所有, 如有侵权,请联系我们删除。
版权归原作者 十七✧ᐦ̤ 所有, 如有侵权,请联系我们删除。