
目录:
前言
打怪升级:第81天
提前声明:
- SQL中的语法不区分大小写,下方博主为了书写方便,并没有刻意去将关键字大写,希望不会对大家带来干扰。
- 本篇文章为博主为了期末考试,考前一周临时学习时进行的自我总结,由于时间精力有限,并没有写的足够全面,如果各位在学习过程中发现问题或有所疑问都可以在评论区提出,
 会及时查看,感激不尽。
会及时查看,感激不尽。
希望本篇文章可以为有需要的朋友提供帮助。
一、CREATE – 创建
创建数据库与表
CREATEDATABASE testdb-- 创建 数据库 数据库名称use testdb
CREATETABLE T1(
CID INTNOTNULLPRIMARYKEY,
CNAME VARCHAR(20),
CAGE INT);CREATETABLE T2(...);CREATETABLE T3(...);
go
创建一个名为TEST14的数据库,创建三个表T1、T2、T3,
表T1有三个列,分别为 ID、NUME、AGE,且ID列为主键,非空。
二、INSERT INTO + VALUES – 插入数据
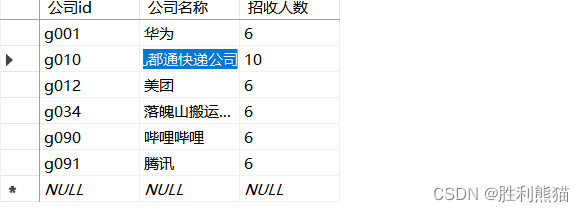
insertinto 公司
values('g010','哪儿都通快递公司',10)
go
插入操作可以同时插入多行数据,通过逗号分割,示例:
insertinto table1
values(data1, data1),(data2, data2),(data3, data3)
go
三、SELECT + FROM – 查找数据
1.SEKECT简单了解
查找操作也是数据库中十分重要的一个功能,可以根据用户的需求,进行各种各样的查找。
以下为最基本的查找模板:
SELECT 属性1, 属性2,...FROM table1, table2,...WHERE 查找条件 -- 可选
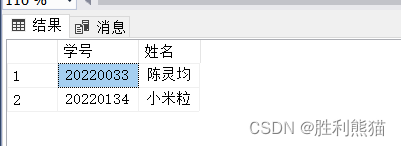
查找学生表中,学号大于等于陈灵均同学的学号的同学。
select 学号, 姓名
from 学生
where 学号 >=(select 学号 -- 小括号-子查询from 学生
where 姓名 ='陈灵均')
2.函数的使用
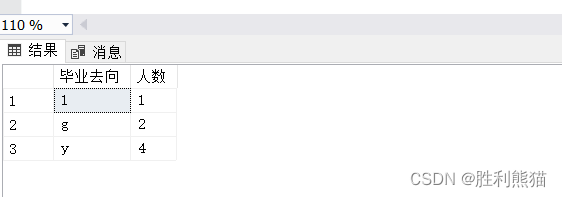
目标:
统计不同毕业去向的人数。
实现:
使用group by 按照毕业去向分组,使用 count函数,统计各个分组的行数,并且给该列起一个新的列名 – 人数
SELECT 毕业去向,COUNT(*)AS 人数
FROM 学生
GROUPBY 毕业去向
3.选择列表与group by子句的对应
选择列表就是 select 后面跟着的一堆列名、表达式、聚合函数等。
select cid,count(*)as scount
from sc
groupby cid
在这段代码中,选择列表中的表达式是 “cid, count( * ) as scount”,而 GROUP BY 子句中的表达式是 “cid”,它们不完全相同。但是这是合法的 SQL 查询,因为 “cid” 是 GROUP BY 子句中的唯一列,而 “count( * ) as scount” 是一个聚合函数,它将对每个分组计算 “cid” 列中的唯一值数量,并将结果命名为 “scount”。
在这个查询中,“cid” 列用于确定分组,而 “count(*) as scount” 列用于显示每个分组中 “cid” 列的唯一值数量。因此,这个查询将返回每个 “cid” 值及其对应的唯一值数量。
总之,虽然选择列表和 GROUP BY 子句中的表达式不完全相同,但它们的含义是一致的,因此这个查询是合法的。
4.exists子查询
如果子查询需要返回多个列,你可以使用
EXISTS子查询来解决这个问题。
EXISTS子查询只需要返回一个布尔值,因此可以用于检查一个表中是否存在符合条件的记录。下面是一个使用
EXISTS子查询的示例查询:
SELECT*FROM c
WHEREEXISTS(SELECT1FROM sc
WHERE sc.cid = c.cid
GROUPBY sc.cid
HAVINGCOUNT(*)>=3);
在这个查询中,子查询返回一个布尔值,指示是否存在至少 3 个学生选修了每个课程。如果子查询返回
TRUE
,则
EXISTS
子句将返回
TRUE
,否则将返回
FALSE
。因此,这个查询将返回选修人数不少于 3 人的课程信息。
[ 注 ] :select这部分写的有些混乱,在最后的《小小示例》中,有许多查找样例参考。
四、UPDATE + SET – 更改数据
在 SQL Server 中,UPDATE 语句用于更新表中的现有记录。它允许您更改表中的一行或多行数据。
下面是一些使用 UPDATE 语句的示例:
- 更新单个记录:
UPDATE 表名
SET 列名 = 新值
WHERE 条件;
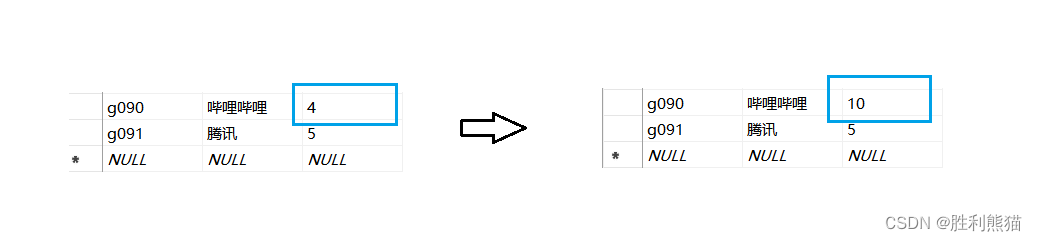
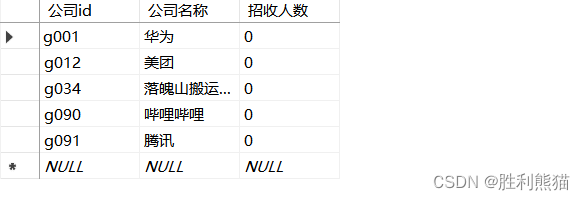
例如,如果您要将公司表中一个公司的招收人数改为10,则可以使用以下语法:
use 大学生毕业去向
update 公司
set 招收人数 =10where 公司id ='g090';
- 更新多个记录:
UPDATE 表名
SET 列名 = 新值
WHERE 条件;
例如,如果您要将客户表中的所有客户的邮政编码更改为新邮政编码,则可以使用以下语法:
use 大学生毕业去向
update 公司
set 招收人数 =0
- 更新多个列:
UPDATE 表名
SET 列1= 新值1, 列2= 新值2, …
WHERE 条件;
例如,如果您要将客户表中的某个客户的电话号码和邮政编码同时更改,则可以使用以下语法:
UPDATE Customers
SET Phone ='123-456-7890', PostalCode ='12345'WHERE CustomerID =1;
五、ALTER + DROP、ADD-- 修改属性
ALTER 是 SQL 中用于修改已经存在的数据库对象(如表、列、索引等)的关键字。常见的使用场景包括:
- 修改表的结构:可以使用 ALTER TABLE 语句来添加、修改或删除表的列、约束(如主键、外键、唯一性约束等)等。
- 修改列的定义:可以使用 ALTER TABLE 语句来修改列的数据类型、长度、默认值等属性。
- 修改索引:可以使用 ALTER INDEX 语句来修改已经存在的索引的属性,例如添加或删除索引列、更改索引类型等。
- 修改视图:可以使用 ALTER VIEW 语句来修改已经存在的视图的定义,例如更改视图的查询语句、视图的列名等。
- 修改存储过程、触发器等:可以使用 ALTER PROCEDURE、ALTER TRIGGER 等语句来修改已经存在的存储过程、触发器等对象的定义。
总之,ALTER 在 SQL 中是一个非常常用的关键字,用于修改已经存在的数据库对象,以满足不同的需求。
- 添加列
ALTERTABLE STU
ADD ID INT, SEX VARCHAR(10), SCH VARCHAR(50), TOTO VARCHAR(50)-- 逗号分割,创建多个列
GO
- 删除列
USE TEST14
ALTERTABLE STU
DROPCOLUMN SWA
GO
- 修改列属性
USE TEST14
ALTERTABLE STU
ALTERCOLUMN ID VARCHAR(50)NOTNULL;-- 修改列属性ADDCONSTRAINT pk_STU PRIMARYKEY(ID);-- 设置为主键 pk_表名
GO
六、JOIN + ON-- 链接多个表
1. join初始
JOIN是 SQL 中用于连接多个表的关键字。它将两个或多个表中的行基于一个共同的列进行匹配,从而生成一个新的结果集。
JOIN通常需要指定连接条件,以确定哪些行应该被连接在一起。
常用的
JOIN类型包括:
INNER JOIN:返回两个表中匹配的行。LEFT JOIN:返回左表中的所有行和右表中匹配的行。RIGHT JOIN:返回右表中的所有行和左表中匹配的行。FULL OUTER JOIN:返回左右两个表中的所有行和匹配的行。
JOIN
的语法如下:
SELECT 列1, 列2,...FROM 表1JOIN 表2ON 连接条件
[JOIN 表3ON 连接条件 ...]WHERE 筛选条件
其中,
JOIN关键字后面跟着要连接的表名,
ON关键字后面指定连接条件,多个表之间可以使用多个
JOIN进行连接。
最后使用WHERE子句对结果进行筛选。
需要注意的是,使用
JOIN进行表连接时,应该确保连接条件是准确的,否则可能会得到不正确的结果。
示例:
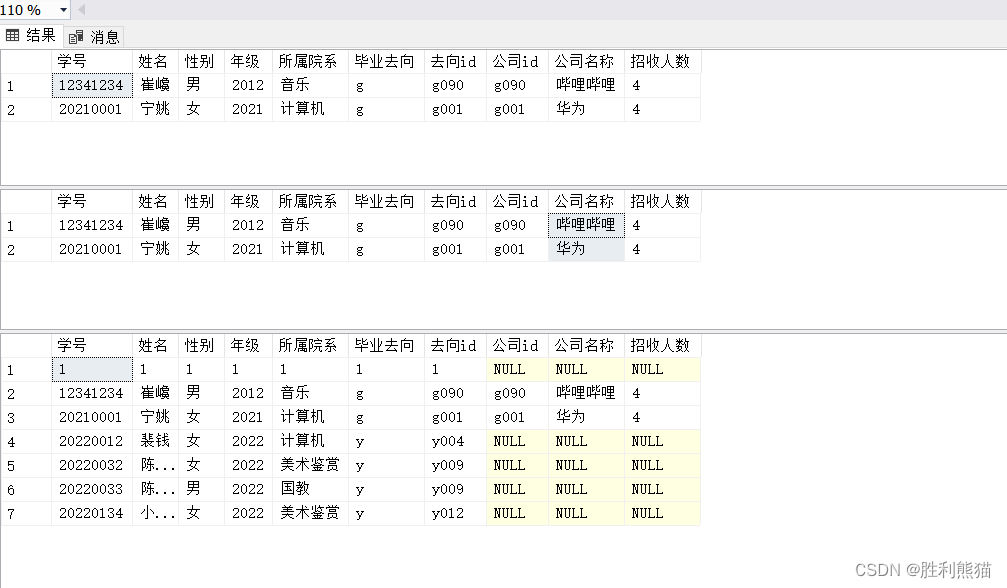
USE 大学生毕业去向
select*from 学生, 公司
where 去向id = 公司id
GO
USE 大学生毕业去向
select*from 学生
leftjoin 公司 on 去向id = 公司id
where 公司id isnotnull-- 筛选出第三个表中有对应公司的学生和公司信息
go
USE 大学生毕业去向
select*from 学生
leftjoin 公司 on 去向id = 公司id
go
2.inner join
Inner Join 和 Join 是 SQL 语言中的两种 Join 操作,它们的区别在于:
- Inner Join 只返回两个表中共有的记录,而 Join 返回两个表中所有的记录。
- Inner Join 只返回满足连接条件的记录,而 Join 则返回所有记录,其中未匹配的记录将以 NULL 值填充。
因此,Inner Join 可以看作是 Join 的一种特殊情况,它只返回两个表中共有的记录,而 Join 则返回两个表中所有的记录。
在实际应用中,Inner Join 更常用,因为通常我们只需要查询两个表中共有的记录。
而 Join则需要在后续的数据处理中进行额外的过滤和处理,比较繁琐。
七、分支语句
1.IF
IF 关键字用于控制流程,根据条件执行不同的代码块。
IF语句的基本语法如下:
IF condition
BEGIN-- code to be executed if condition is trueENDELSEBEGIN-- code to be executed if condition is falseEND
其中,condition是一个布尔表达式,如果为true,则执行第一个BEGIN和END之间的代码块,否则执行第二个BEGIN和END之间的代码块。您还可以使用ELSE IF子句来添加更多的条件分支。
以下是一个简单的示例,演示如何在SQL Server中使用IF语句:
DECLARE@scoreINT=80;IF@score>=90BEGINPRINT'A';ENDELSEIF@score>=80BEGINPRINT'B';ENDELSEIF@score>=70BEGINPRINT'C';ENDELSEBEGINPRINT'F';END
在这个例子中,我们声明了一个变量@score,并使用IF语句根据不同的分数范围打印不同的成绩等级。如果@score大于或等于90,则打印’A’,否则检查下一个条件分支,以此类推。
2.CASE
CASE是 SQL 中的一种条件表达式,用于在查询中根据条件返回不同的结果。
它的语法如下:
CASEWHEN condition1 THEN result1
WHEN condition2 THEN result2
...ELSE default_result
END
其中,
condition1
、
condition2
等是条件表达式,
result1
、
result2
等是对应条件成立时返回的结果,
default_result
是所有条件都不成立时返回的默认结果。在
CASE
表达式中,可以包含多个
WHEN
子句,每个子句都可以有不同的条件和返回结果。
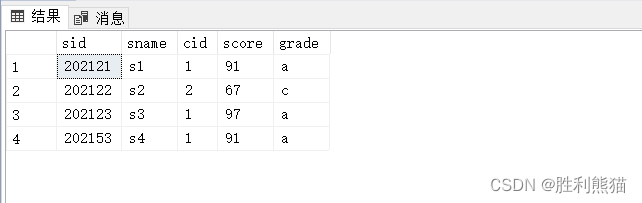
栗子1:获取学生学号、姓名、考试科目以及考试成绩,并且根据考试成绩划分等级。
select s.sid, sname, cid, score,casewhen score >=90then'a'when score >=80then'b'else'c'endas grade
from s innerjoin sc on s.sid = sc.sid
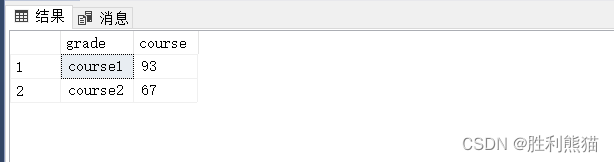
栗子2:因为课程号不方便我们查看,要求通过课程号为各个科目命名(假设sc表没有存课程名)求各科平均成绩
selectcasewhen cid =1then'course1'when cid =2then'course2'else'other_course'endas grade,avg(score)as course -- 求均值from sc
groupbycasewhen cid =1then'course1'when cid =2then'course2'else'other_course'end
3.IF 与 CASE 对比
CASE
表达式和
IF
语句虽然都是用于条件判断和流程控制,但它们的语法和使用场景是不同的。
IF
语句通常用于程序中的控制流程,例如在编写存储过程或函数时,可以使用
IF
语句来判断输入参数的值,以便执行不同的逻辑。而
CASE
表达式则是用于查询语句中的条件判断,可以根据不同的条件返回不同的结果集。
八、循环语句
1.WHILE
WHILE 循环是 SQL Server 中一种基于条件的循环结构,它可以在满足指定条件的情况下重复执行一段代码块。
WHILE 循环的语法如下:
WHILE condition
BEGIN-- Code block to be executed while condition is trueEND
其中,
condition
是一个逻辑表达式,用于指定循环的条件。只要
condition
的值为真,就会重复执行
BEGIN
和
END
之间的代码块。
在 WHILE 循环中,需要注意以下几点:
- 必须在代码块中修改循环条件,否则循环会一直执行下去,导致死循环。
- 可以在代码块中使用 BREAK 语句来提前结束循环。
- 可以在代码块中使用 CONTINUE 语句来跳过当前循环,直接进入下一次循环。
- WHILE 循环通常与游标一起使用,用于处理从数据库中检索的记录。
下面是一个简单的 WHILE 循环示例,用于计算 1 到 10 的和:
DECLARE@iINT=1DECLARE@sumINT=0WHILE@i<=10BEGINSET@sum=@sum+@iSET@i=@i+1ENDSELECT@sum-- 输出结果为 55
在这个例子中,我们首先定义了两个变量
@i
和
@sum
,分别用于存储计数器和累加器的值。然后使用 WHILE 循环重复执行累加操作,直到计数器的值达到 10。最后输出累加器的值,即 1 到 10 的和。
- 变量 在 SQL Server 中,变量可以用来存储临时数据,以便在查询或存储过程中使用。变量必须在使用之前声明,并且必须指定变量的数据类型。以下是一个声明和使用变量的示例:
DECLARE@myVariableINT;SET@myVariable=10;SELECT@myVariable;
在上面的示例中,我们声明了一个名为 @myVariable 的整数类型变量,并将其设置为 10。然后,我们使用 SELECT 语句检索变量的值。
2.FOR + TO
在 SQL Server 中,
for通常用于循环语句的控制,可以与
while一起使用。
for循环包括三个部分:初始化、循环条件和循环迭代。
其基本语法结构如下:
DECLARE@counterINT=0FOR@counter=1TO10BEGIN-- 循环体END
其中,
@counter
变量被初始化为 0,然后在
for
循环中被设置为 1,循环条件为
@counter <= 10
,循环迭代为
@counter = @counter + 1
。在每次循环中,
@counter
的值都会自动递增,直到循环条件不再满足为止。需要注意的是,
for
循环仅在 SQL Server 2016 及以上版本中才支持,如果使用早期版本,则需要使用
while
循环来实现类似的功能。
FOR 循环和 WHILE 循环是 SQL Server 中两种不同的循环结构,它们的用法和使用场景有所不同。
FOR 循环是一种基于计数器的循环,通常用于执行已知次数的循环操作。FOR
循环在执行前需要明确指定循环次数,然后在每次循环中递增计数器的值,直到计数器达到指定的循环次数为止。FOR
循环通常用于处理固定数量的数据,例如数组或表格。WHILE 循环则是一种基于条件的循环,通常用于执行未知次数的循环操作。WHILE
循环在执行前不需要指定循环次数,而是在每次循环中检查一个条件,只要条件为真,就会继续执行循环操作。WHILE
循环通常用于处理不确定数量的数据,例如从数据库中检索的记录。总的来说,FOR 循环适合处理已知数量的数据,
而 WHILE循环适合处理未知数量的数据。在实际应用中,需要根据具体的需求选择合适的循环结构。
九、DECLARE + CURSOR-- 游标
1.初识游标
游标是一种用于在 SQL Server 中遍历结果集的机制。游标可以让我们逐行地读取结果集中的数据,并对每一行数据进行处理。在 SQL
Server 中,使用游标需要以下步骤:
- 声明游标:使用
DECLARE语句声明游标,并指定要遍历的结果集。- 打开游标:使用
OPEN语句打开游标,准备开始遍历结果集。- 读取数据:使用
FETCH语句读取游标当前指向的行,并将数据存储到变量中。- 处理数据:对于每一行数据,可以进行相应的处理,例如输出、更新等操作。
- 关闭游标:使用
CLOSE语句关闭游标,释放资源。- 释放游标:使用
DEALLOCATE语句释放游标占用的内存空间。
2.游标的定义
最简单的游标声明语法如下:
DECLARE cursor_name CURSORFORSELECT column1, column2,...FROM table_name
其中,
cursor_name
是游标的名称,
table_name
是要查询的表名,
column1
、
column2
等是要查询的列名。这条语句将创建一个游标,将查询结果集中的所有行放入游标中,游标的指针初始位置为第一行。
3.见见猪跑
以下是一个示例代码,用于读取 student 表中的女生信息,并将第二个女同学的年龄改为 20:
(略看即可)
DECLARE female_cursor CURSORFORSELECT name, age FROM student WHERE gender='female'OPEN female_cursor
DECLARE@nameVARCHAR(50),@ageINTFETCHNEXTFROM female_cursor INTO@name,@ageWHILE @@FETCH_STATUS=0BEGIN-- 处理数据PRINT'Name: '+@name+', Age: '+ CAST(@ageASVARCHAR(10))IF @@CURSOR_ROWS=2BEGIN-- 修改第二个女同学的年龄为 20UPDATE student SET age =20WHERECURRENTOF female_cursor
PRINT'Age updated to 20'ENDFETCHNEXTFROM female_cursor INTO@name,@ageENDCLOSE female_cursor
DEALLOCATE female_cursor
在上面的示例代码中,我们使用
DECLARE
语句声明了一个名为
female_cursor
的游标,用于遍历
student
表中的女生信息。然后使用
OPEN
语句打开游标,使用
FETCH
语句读取第一行数据,并将数据存储到
@name
和
@age
变量中。在循环中,我们对每一行数据进行相应的处理,包括输出、更新等操作。在读取完所有数据后,使用
CLOSE
语句关闭游标,使用
DEALLOCATE
语句释放游标占用的内存空间。
4.吃“猪肉”
在 SQL Server 中,使用
FOR关键字声明游标时,它是用来指定游标的循环方式的。在
FOR关键字后面指定了游标的循环方式,可以是
FORWARD_ONLY,
SCROLL或
STATIC,默认情况下为FORWARD_ONLY。
FORWARD_ONLY:指定游标只能向前滚动,不能回滚。这是最快的游标类型,因为它不需要额外的资源来维护游标位置。SCROLL:指定游标可以向前和向后滚动,可以随意定位到表中的任何位置。这种类型的游标需要额外的资源来维护游标的位置,因此比FORWARD_ONLY类型的游标慢。STATIC:指定游标是静态的,它不会随着表的修改而改变。这种类型的游标可以提供一致的结果,但是需要较多的资源来维护游标。
例如,以下代码声明了一个
FORWARD_ONLY
类型的游标:
DECLARE myCursor CURSOR FORWARD_ONLY FORSELECT column1, column2, column3
FROM myTable
5.FETCH使用细节
**
@@FETCH_STATUS** 是一个系统变量,用于检查最近一次
FETCH语句的执行结果。
如果FETCH语句成功读取了一行数据,则
@@FETCH_STATUS的值为 0。
如果FETCH语句没有读取到数据,则
@@FETCH_STATUS的值为 -1。
如果FETCH语句执行出错,则
@@FETCH_STATUS的值为-2。
在使用游标时,通常需要在循环中检查@@FETCH_STATUS的值,以便在读取完所有数据后正确地退出循环。
在 SQL Server 中,可以使用
FETCH
语句来从游标中检索数据,并且可以使用 关键字来显式地移动游标指针。
`FETCH` 语句有多种形式,可以使用 `FETCH NEXT` 语句来检索下一行数据,例如:
FETCHNEXTFROM cursor_name;-- 如不显示声明,默认为 NEXT
可以使用 `FETCH PRIOR` 语句来检索上一行数据,例如:
FETCH PRIOR FROM cursor_name;
可以使用 `FETCH FIRST` 语句来检索第一行数据,例如:
FETCHFIRSTFROM cursor_name;
可以使用 `FETCH LAST` 语句来检索最后一行数据,例如:
FETCHLASTFROM cursor_name;
此外,还可以使用 `FETCH ABSOLUTE` 和 `FETCH RELATIVE` 语句来检索指定行号或相对位置的数据,例如:
FETCH ABSOLUTE 5FROM cursor_name;FETCH RELATIVE 2FROM cursor_name;
需要注意的是,游标的移动是有限制的,当游标移动到结果集的第一行或最后一行时,再次移动游标将不会有任何效果。此外,在使用游标时,还应该注意游标的关闭和释放,以免占用过多的系统资源。
十、CREATE VIEW – 视图
视图(View)是一种虚拟的表,它不像物理表一样存储数据,而是基于一个或多个物理表的查询结果集来创建的。视图可以看作是一个“虚拟表格”,它包含了从一个或多个表中查询出来的数据,并且可以像表一样被查询、过滤、排序等。
视图的创建方式类似于查询语句,它是基于一个或多个表的查询结果集来创建的,可以包含任意的 SQL 语句,例如
SELECT、FROM、WHERE、GROUP BY、HAVING、ORDER BY 等。
视图可以使用 CREATE VIEW 语句来创建,语法如下:
CREATEVIEW view_name ASSELECT column1, column2,...FROM table_name
WHERE condition;
其中,
view_name
是视图的名称,
column1, column2, ...
是要查询的列,
table_name
是要查询的物理表,
condition
是查询条件。
创建视图后,可以像查询普通表一样使用视图。例如,可以使用以下语法来查询视图:
SELECT*FROM view_name;
在查询视图时,实际上是执行了视图定义中的
SELECT语句,并返回结果集。
可以使用视图来简化复杂查询,提高查询效率,增强数据安全性等。视图可以多次使用,也可以在其他查询语句中嵌套使用。
创建一个保存sc表中前两名同学所有信息的视图:
createview top_tow_sc
asselecttop(2)*from sc orderby score desc-- 降序
视图的使用:
select*from top_tow_sc;select s.sid, s.sname, score from s join top_tow_sc on s.sid = top_tow_sc.sid;
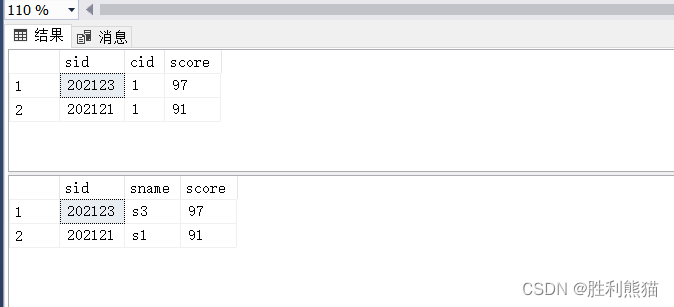
一个视图创建后可以当做实际的表来使用,并且可以多次使用。
十一、CREATE PROCEDURE – 存储过程
存储过程是一种预编译的数据库对象,可以在数据库中创建和保存,由一组 SQL语句和流程控制语句组成。存储过程可以接收参数,执行一系列操作,返回结果集或输出参数。存储过程通常用于实现复杂的业务逻辑,可以提高数据库的性能和安全性,减少网络传输的数据量。存储过程还可以被其他程序或存储过程调用,提高代码的重用性和可维护性。
在SQL Server 数据库系统中,存储过程可以使用 Transact-SQL 语言编写,并使用 SQL Server ManagementStudio 工具进行管理和调试。
CREATEPROCEDURE get_score -- 创建存储过程@idint-- 一个变量asbeginselect score from sc where sid =@id-- 存储过程执行的操作endexec get_score @id=202121;-- 调用存储过程
上方创建一个存储过程,来查找学号为 @id的学生的成绩。
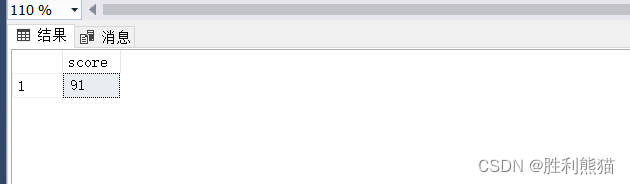
存储过程不管是定义还是使用都很类似于C语言等计算机语言的函数调用。
EXEC – 执行
在SQL Server中,
EXEC是一个用于执行存储过程、函数和动态SQL语句的关键字。
它的语法如下:
EXEC procedure_name [parameter1, parameter2,...]
其中,
procedure_name是要执行的存储过程或函数的名称,
parameter1, parameter2, ...是可选的输入参数。如果存储过程或函数没有参数,则可以省略方括号中的参数部分。
EXEC关键字还可以用于执行动态SQL语句,即在运行时动态构建SQL语句并执行。
例如:
DECLARE@sql NVARCHAR(MAX);-- 声明变量 变量名 数据类型SET@sql='SELECT * FROM my_table';-- 变量赋值EXEC(@sql);-- 执行
这里,我们首先声明一个变量
@sql
来存储SQL语句,然后使用
EXEC
关键字来执行该语句。请注意,在执行动态SQL语句时,需要非常小心,以避免SQL注入等安全问题。
示例:
USE TEST14
--CREATE TABLE [STU](aaa INT); -- 创建表,一列,列名为 aaaEXEC sp_rename 'STU.aaa','S','COLUMN';-- 更改列明 '旧名' , '新名', '列'
十二、CREATE FUNCTION – 函数
在 SQL Server中,函数(Function)是一种特殊的存储过程,用于在查询中返回一个标量值或表格。函数可以接受一个或多个输入参数,并根据这些参数计算结果。函数可以用于简化复杂的查询和数据处理操作,提高查询性能和代码重用性。
SQL Server 中有三种类型的函数:标量函数(Scalar Function)、表值函数(Table-Valued Function)和聚合函数(Aggregate Function)。其中,标量函数返回一个标量值(例如整数、字符串或日期),表值函数返回一个表格,而聚合函数返回一个聚合值(例如总和、平均值或计数)。
下面是一个标量函数的定义示例:
CREATEFUNCTION GetSLen(@targetSVARCHAR(1000))RETURNSINTASBEGINRETURNLEN(@targetS);END
该函数名为 GetSLen,接受一个 VARCHAR 类型的参数 @targetS,返回参数字符串的长度。在函数体中,使用 RETURN 语句返回计算结果。
函数调用:
select dbo.GetSLen('helloworld')-- 注意使用调用模式
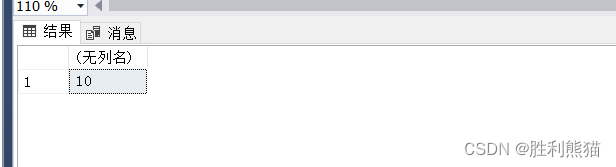
在 SQL Server中,每个对象都必须属于某个模式(Schema),模式是数据库对象的逻辑容器,用于对数据库对象进行分类和组织。
如果在创建 UDF时没有指定模式,则 SQL Server 会将其分配给默认模式 dbo。因此,当调用 UDF 时,需要使用函数名前缀 dbo.,以指定UDF 的所有者模式。如果使用的是 SQL Server 的默认模式,则可以省略 dbo. 前缀,直接使用函数名调用UDF。但是,为了避免可能的歧义,建议始终在函数名前面加上 dbo. 前缀。
十三、小小示例
该样例从建库开始,所有操作都可以直接复制运行,并且带有部分注释,希望对大家有所帮助。
-- 1.建数据库createdatabase ssc
go
-- 2.建表use ssc
createtable s -- 学号,姓名,性别(
sid intnotnullprimarykey,-- 非空 主键
sname varchar(50),
sex char(10),);createtable c -- 课程号,课程名,教师(
cid intnotnullprimarykey,
cname varchar(50),
teacher varchar(50));createtable sc -- 学号,课程号,成绩(
sid intnotnull,
cid intnotnull,
score int,constraint pk_sc primarykey(sid, cid))
GO
-- 3.插入数据use ssc
insertinto s
values(202121,'s1','man'),(202122,'s2','man'),(202123,'s3','woman'),(202153,'s4','man');
go
use ssc
insertinto c
values(01,'s1','tea1'),(02,'s2','tea2'),(07,'s7','tea7');
go
use ssc
insertinto sc
values(202121,01,91),(202122,02,67),(202123,01,97),(202153,01,91);
go
-- 4.查找练习use ssc
select s.sid , sname, score -- 查看学生成绩from s join sc on s.sid = sc.sid
go
use ssc
select s.sid , sname, score -- 同上from s, sc
where s.sid = sc.sid
go
use ssc
select*-- 查找学生学号中含有 212 的学生信息from s
where sid like'%212%'use ssc
select*from c join sc on c.cid = sc.cid -- 筛选有学生选修的课程信息
go
use ssc
select teacher,count(*)as 报课人数
from c join sc on c.cid = sc.cid
groupby teacher -- 按照老师分组,开始统计报课人数
go
use ssc
select*-- 查找有学生报名的课程的信息 -- 去重from c
where teacher IN-- 判断 teacher是否在子查询中(select c.teacher -- 子查询,查找所有学生选课的信息from sc
where sc.cid = c.cid
)
go
use ssc -- 同上select*from c
whereexists(select1from sc
where sc.cid = c.cid
)
go
-- 查找不学习课程s7的学生select sid, sname
from s
where sid notin-- 查找不在的(select sid -- 子查询:查找在的from sc
where cid =1)-- 查询选修人数不少于3人的课程信息 select*from c
where cid in(select cid
from sc
groupby cid
havingcount(*)>=3-- 判断人数)-- 查询选修人数不少于3人的课程信息 -- 同上select*from c
whereexists-- 使用 exists子查询(select1from sc
where c.cid = sc.cid
groupby cid
havingcount(*)>=3-- 判断人数)-- 查询选修人数不少于3人的课程信息 -- 同上 -- 返回结果略有不同,会带上子查询的结果select*from c innerjoin-- 链接子查询返回的结果集(select cid,count(*)as scount
from sc
groupby cid
havingcount(*)>=3-- 判断人数)as tmp -- 起个名字,便于下方使用on c.cid = tmp.cid
-- 5. 修改数据use ssc
update c
set cid =06, cname ='c6', teacher ='newtea'-- 没有人报名的课,更换老师,跟换新课程-- 按照教师分组,并统计各个教师所教课程的报课人数,等于0就替换wherenotexists(select1from sc
where c.cid = sc.cid
)
go
-- 6.修改属性use ssc
altertable sc
altercolumn score int;
go
-- 7.while循环的使用,print函数只能打印字符串-- 使用循环中的print语句,打印学生信息以及它的成绩use ssc
declare@minidint=(selectmin(sid)from s);declare@maxidint=(selectmax(sid)from s);declare@iint=@minid;while@i<=@maxidbeginifexists(select1from s where sid =@i)-- 判断学生是否存在begindeclare@namevarchar(50)=(select sname from s where sid =@i)declare@scoreint=(select score from sc where sid =@i)print'sname: '+@name+', score: '+ cast (@scoreasvarchar(10));-- 使用cast函数,将整形score转换为varchar,以便于字符串连接endset@i=@i+1;end-- 8.游标-- 使用游标,查找第二个成绩大于90分的同学的姓名与成绩DECLARE S_CURSOR CURSOR FORWARD_ONLY FORSELECT SNAME, SCORE FROM SC JOIN S ON SC.SID = S.SID
WHERE SCORE >=90OPEN S_CURSOR
DECLARE@NAMEVARCHAR(50),@SCOREINT;FETCHFROM S_CURSOR INTO@NAME,@SCOREWHILE @@FETCH_STATUS=0BEGINPRINT@NAME+': '+ CAST(@SCOREASVARCHAR(10));FETCHFROM S_CURSOR INTO@NAME,@SCOREENDCLOSE S_CURSOR
DEALLOCATE S_CURSOR
总结
- SQL关键字不区分大小写。
- 在 SQL 中,引号用于表示字符串类型的值。如果公司id是字符串类型的话,那么需要使用引号将其括起来。如果招收人数是数值类型的话,就不需要使用引号。所以,需要根据数据类型来决定是否使用引号。
- 子查询是指在一个 SQL 语句中嵌套另一个完整的 SQL 语句,用于查询嵌套查询中所需要的数据。子查询返回的是一个结果集,这个结果集可以是一个标量值、一个行或多行数据。 子查询的结果可以作为另一个 SQL 语句的一部分,用于过滤、排序、分组等操作。例如,我们可以使用子查询来查询某个表中满足某个条件的记录数,或者查询某个表中的最大或最小值等。
- 在 SQL Server 中,变量名前面必须加上 “**@**” 符号,这是为了区分变量名和列名或表名。
- 游标通过declare声明。
- 视图是一种虚拟表,通过create创建,一个视图创建后可以当做实际的表来使用,并且可以多次使用。
- CREATE 和 DECLARE 是 SQL Server 中用于创建对象的两个关键字,它们的使用场景和语法有所不同。CREATE 用于创建新的数据库对象,例如表、视图、存储过程、函数等。CREATE 语句通常需要指定对象名称、列定义、约束、索引等详细信息,以及必要的权限和选项。CREATE 语句的语法通常比较复杂,需要考虑多种因素,例如数据类型、长度、精度、性能等。DECLARE 用于声明变量、游标、表变量等临时对象,这些对象通常只在当前会话中存在,并且不会被持久化保存。DECLARE 语句通常只需要指定对象名称、数据类型、长度等基本信息,不需要考虑复杂的约束和索引。 关于为什么游标使用 DECLARE 而视图和存储过程使用 CREATE,主要是因为它们的作用和使用场景不同。游标是一种临时对象,通常只在当前会话中使用,并且不需要被其他程序或会话调用,因此使用 DECLARE 更加合适。而视图和存储过程是一种可重用的数据库对象,可以在多个查询或程序中使用,并且需要被持久化保存,因此使用 CREATE 更加合适。
版权归原作者 胜利熊猫 所有, 如有侵权,请联系我们删除。