
大数据-Hadoop是什么,如何部署
1.是什么?
大数据计算平台-批量计算
各个版本发展变化:主要是区分yarn是资源管理的部分,HDFS是数据存储的部分

2.架构
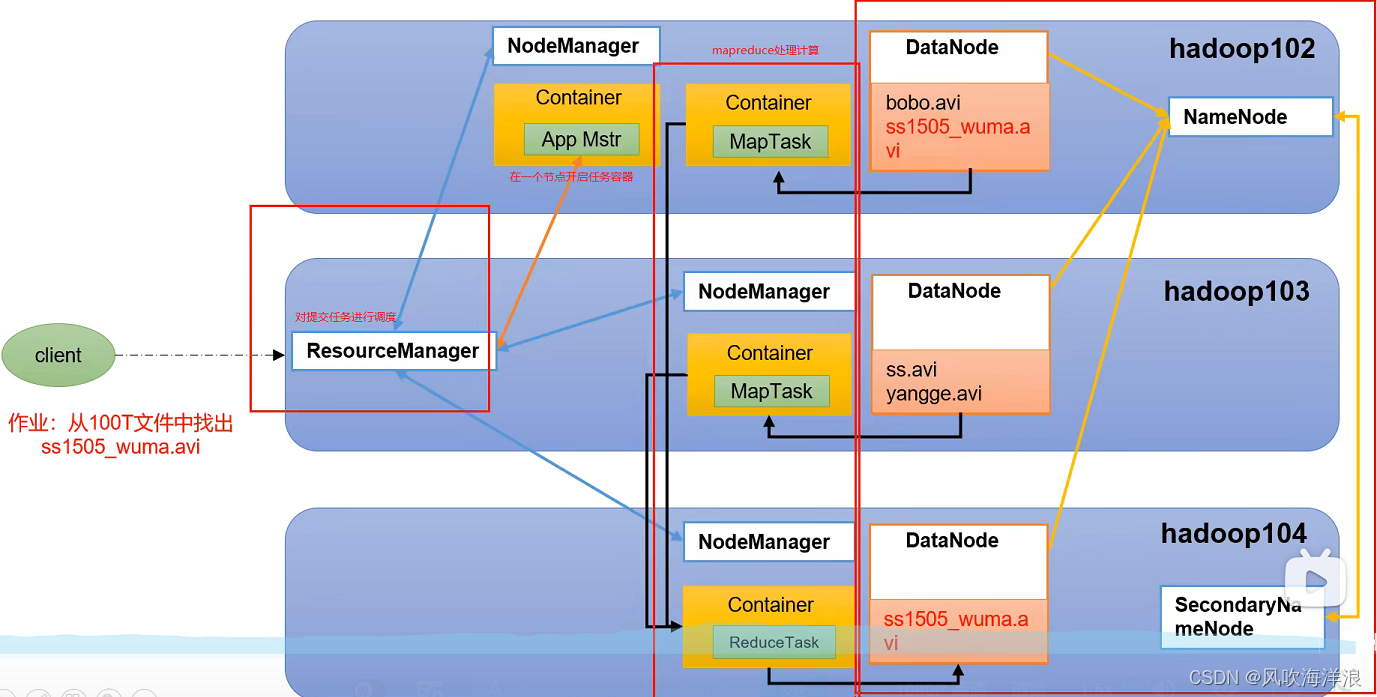
2.1 HDFS(分布式文件系统)
解决问题:首先对于海量数据需要先进行存储。
如何存储?(海量数据一台机器存储不够,分布式存到多台机器)
namenode:管理数据存储在什么位置的组件,例如某一部分数据存储在那一台机器。
2NN:万一namenode挂了,数据存在什么位置就不知道了,所以为了防止这种情况进行设置2NN组件,辅助namenode工作的
datanode:具体进行存储数据的组件
2.1.1NameNode(简称nn)
存储文件的元数据(文件名,目录,属性(包括生成时间、副本数以及文件权限),每个存储在Datanode中文件的块列表)
2.1.2DataNode(dn)
具体存储数据的组件,存储文件块数据、以及块数据的校验和
2.1.3Secondary NameNode(2NN)
为了防止Namenode挂了,每隔一段时间对Namenode进行元数据备份
2.2 YARN(资源管理器/协调者)
yarn主要管理的就是cpu、内存。
组件:Resource Manager、NodeManager
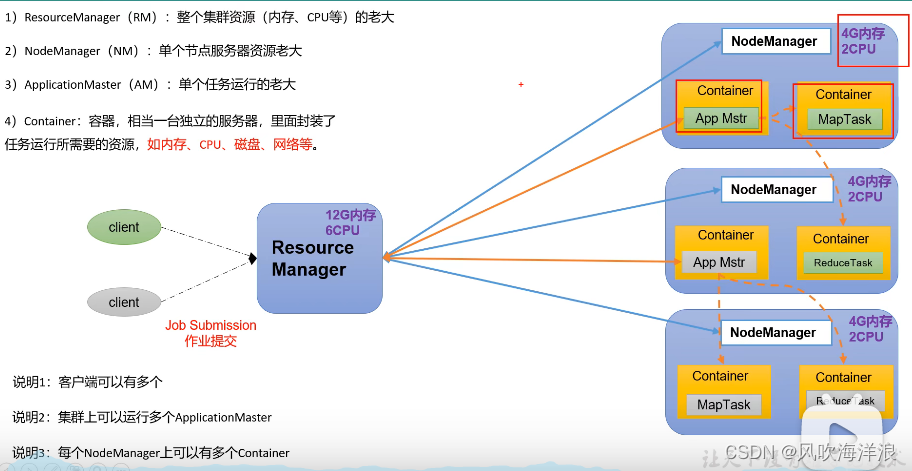
2.2.1 Resource Manager
整个集群的资源管理者,管理所有节点总共的cpu以及内存等资源
2.2.2 NodeManager
自己管理自己节点机器上的资源
2.2.3 AppllicationMaster
当用户提交一个作业后,Resource Manager管理资源分配将作业分配到某一个NodeManager中,会启动一个容器(相当于资源隔离,里面封装了运行任务所需要的资源)来执行该任务。
AppllicationMaster管理单个运行的任务,向Resource Manager申请资源,如果还有后续的任务需要执行,就再申请资源。
容器默认是1-8g内存,1个cpu
2.3 MapReduce(计算)
将计算过程分为两个部分:
map阶段:并行处理输入数据
reduce阶段:对map结果进行汇总
3.Hadoop目录结构
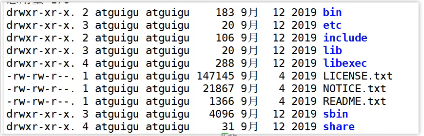
3.1bin
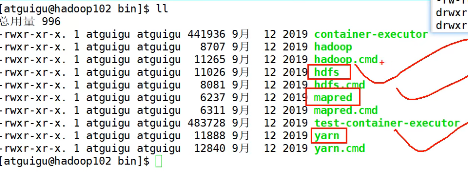
重点关于存储、计算、资源管理命令各一个:hdfs、mapred、yarn
3.2etc(配置文件)
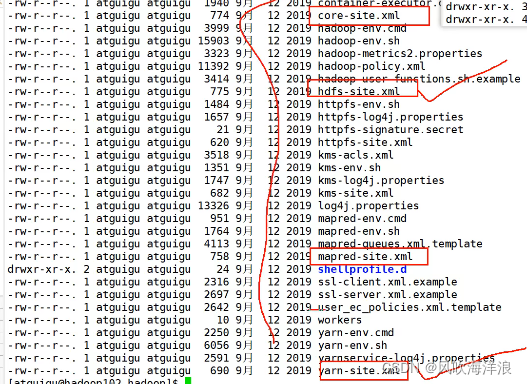
3.3sbin(启动关闭命令)
3.4share(说明文档、运行例子)
4.如何运行部署?
运行模式分为:本地模式(测试)(本地(linux)存储数据)、伪分布式(hdfs存储数据,但是只在一个机器上)、分布式(在集群的hdfs中存储数据)
4.1软件准备、配置文件
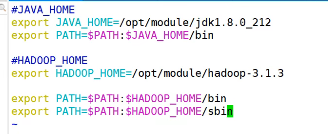
source /etc/profile
4.2模式
本地模式
采用share文件中的官方例子
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-xx.jar wordcount (输入路径) (输出路径(必须指定的文件夹不存在))
输入路径中创建一个里面是单词的文件txt
执行后生成文件,生成的

分布式
注:记录两个知识点:
scp命令
rsync远程同步(可以只拷贝差异性内容)
scp安全拷贝,用于拷贝文件或者文件夹
scp -r(递归) 要拷贝的文件或者文件夹 目的文件夹
rsync -av(a归档拷贝 v显示过程) 要拷贝的文件或者文件夹 目的文件夹
集群配置规划

配置文件
hadoop/etc/hadoop

参考链接:
https://zhuanlan.zhihu.com/p/25472769
core-site.xml
<configuration><!-- 指定HDFS(namenode内部之间的)的通信地址 常用地址8020。9820--><property><name>fs.defaultFS</name><value>hdfs://locahost:9000</value></property><!-- 指定hadoop运行时产生文件的存储路径 --><property><name>hadoop.tmp.dir</name><value>/cloud/hadoop/tmp</value></property></configuration>
hdfs-site.xml
<configuration>//设置nn的web端访问路径,就是需要让用户访问到,所以设置web界面<property><name>dfs.namenode.http-address</name><value>cloud01:9870</value></property>//设置2NN的地址<property><name>dfs.namenode.secondary.http-address</name><value>cloud01:9860</value></property><property><name>dfs.namenode.name.dir</name><value>file:/home/hduser/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/home/hduser/dfs/data</value></property>//<!-- 设置hdfs副本数量 --><property><name>dfs.replication</name><value>2</value></property></configuration>
mapred-site.xml
<configuration><property>//指定mapreduce运行在yarn上<name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
yarn-site.xml
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property>//指定resourcemanager地址<property><name>yarn.resourcemanager.hostname</name><value>cloud01</value></property></configuration>
workers
//配置运行的一些集群ip或者别名(不能有空格或者空行)
启动集群
初始运行需要初始化

只在namenode节点上进行初始化
hdfs namenode -format
初始化后会生成一个data和log
启动hdfs(在namenode节点上)
sbin/start-dfs.sh
访问web界面配置namenode的ip:9870
(配置hdfs-site.xml文件中设置的客户端访问的端口)
启动yarn(在resourcemanager节点上)
sbin/start-yarn.sh
访问web界面yarn的resourcemanager;
ip:8088
启动历史服务器
对于完成的任务已经结束运行了,在想查看历史信息需要历史服务器
配置文件mapred-site.yaml
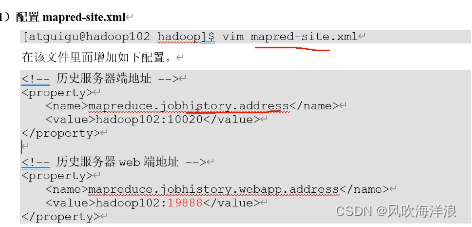
在配置文件中指定的地址的那个节点上运行该命令
mapred --deomon start historyserver
本文转载自: https://blog.csdn.net/Taylor_Ocean/article/details/123414523
版权归原作者 风吹海洋浪 所有, 如有侵权,请联系我们删除。
版权归原作者 风吹海洋浪 所有, 如有侵权,请联系我们删除。