
目录
文章目录
应用架构设计模式(Application Architecture Patterns)
应用架构设计模式是经过验证的、针对特定场景的,具有良好设计结构的、通用的、可重用的解决方案。
软件开发有时可以看作是选择,定制和组合架构模式的过程。软件架构师必须决定如何采用哪几种架构模式,如何使这些架构模式与软件系统特定的上下文相适应。
分层模式(Layered Pattern)
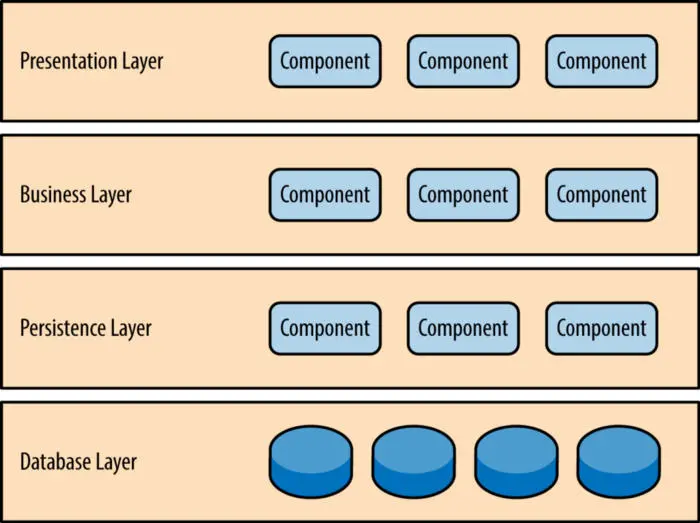
分层模式是最常见的架构模式,用于分解结构化程序的子任务,每个子任务都位于特定的抽象层级,每一层都为上一层提供服务,特定层中的组件仅处理与该层有关的逻辑。
分层模式的每一层在应用程序中都有特定的角色和职责,这意味着所有组件都是互连的,每个分区暴露一个公开接口,但彼此之间不依赖。
分层模式是一个技术性的分区架构,而非一个领域性的分区架构。它们是由组件组成的,而不是领域。
尽管对于层的数量和类型没有具体限制,但大部分分层架构主要由 4 层组成:
- 表示层(也称为 UI 层)
- 应用层(也称为服务层)
- 业务逻辑层(也称为领域层)
- 数据访问层(也称为持久层)
优点:
- 高可测试性,每一层都可以单独测试。
- 易于开发,因为这种模式众所周知,并且实现起来并不太复杂,而且大多数公司都通过逐层分离技能来开发应用程序,这种模式已经成为大多数业务应用程序开发的自然选择。
- 可维护性。
- 易于单独更新某一层。
缺点:
- 分层会导致性能下降。这种模式不适合高性能应用程序,因为经过架构中的多层来实现一个业务请求的效率是不高的。
- 分层还会增加系统的前期成本和复杂性。
应用场景:
- 分层架构通常应用于小型简单的应用程序或网站。对于预算和时间非常紧张的场景,这是一个不错的选择。
- 标准业务线应用程序,其功能不只是 CRUD 操作。
- 需要快速构建的新应用程序。
- 适用于经验不足的开发团队。
- 需要严格的可维护性和可测试性的应用。
事件驱动模式(Event-based Pattern)
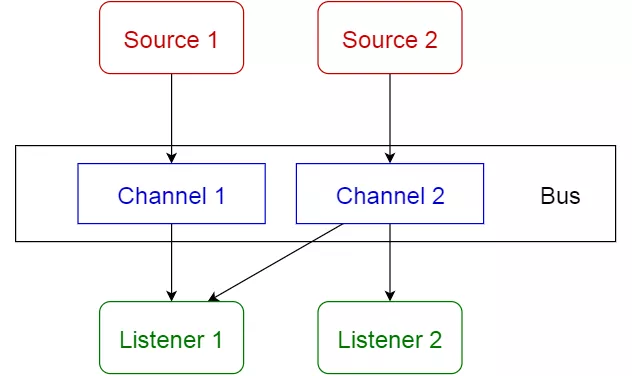
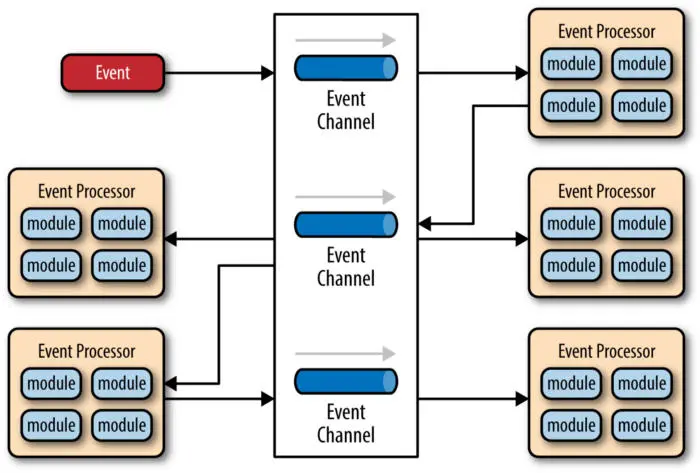
事件驱动模式用于开发高度可扩展的系统,常见于分布式异步架构系统。该模式由用于监听并异步处理事件的一系列组件组成,包括 4 个主要组件:
- 事件源
- 事件监听器
- 通道
- 事件总线
事件驱动的架构模式构建了一个接收所有数据的中央单元,然后将其委托给处理特定类型的单独模块。消息源将消息发布到事件总线上的特定通道上。侦听器订阅特定的通道。侦听器会被通知消息,这些消息被发布到它们之前订阅的一个通道上。
为事件处理部署独立的事件处理进程。当事件到达时先进入队列,然后调度程序根据调度策略从队列中拉取事件并将它们分配到合适的事件处理进程。这种模式背后的思想是将应用逻辑解耦为单一用途的事件处理组件,以异步方式接收和处理事件。
优点:
- 容易适应复杂的环境。
- 弹性伸缩。
- 当出现新的事件类型时,很容易扩展。
缺点:
- 性能和错误恢复方面。
应用场景:
- 具有异步数据流的异步系统。
- 用户界面交互。
- 通知服务。
- 注册中心。
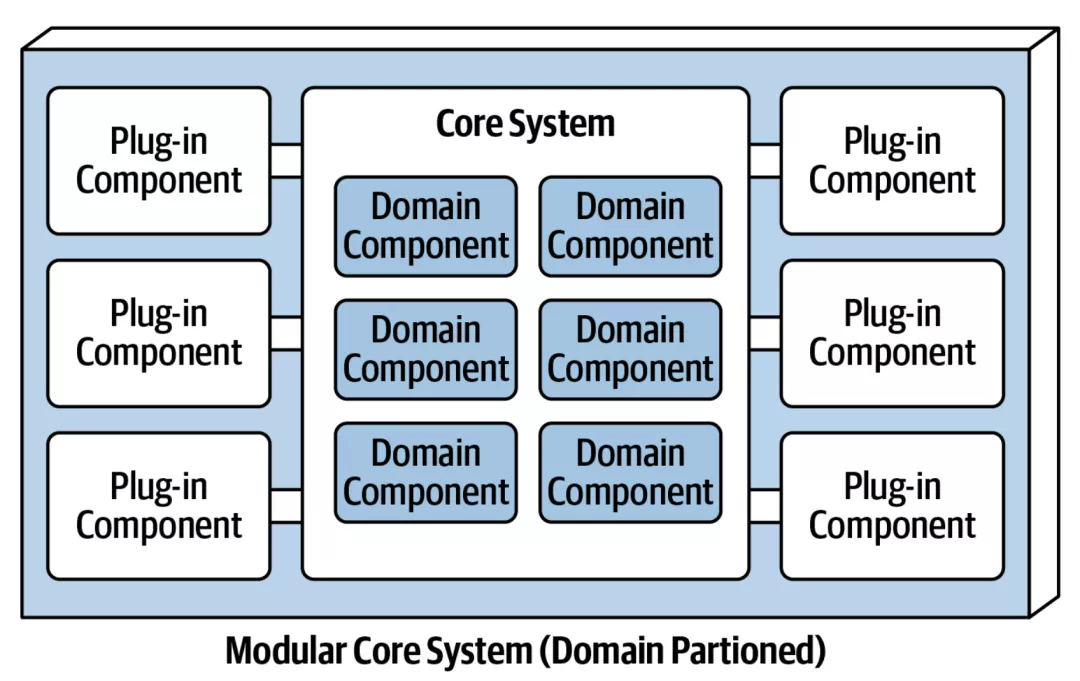
微内核模式(Microkernel Pattern,插件化模式)
微内核模式,也称插件模式,这种模式允许你将其他应用程序功能作为插件添加到核心应用程序,从而提供可扩展性以及功能分离。
微内核模式包含 2 大部分:
- 核心系统:仅包含使系统运行所需的最小功能。例如:负责管理各种插件,如插件注册管理、插件生命周期管理、插件之间的通讯、插件动态替换等。
- 插件模块:提供应用程序功能和自定义处理逻辑的可扩展性,灵活性和隔离性。考虑到隔离性,插件可能是以独立进程的方式运行。也可以以动态函数注册的方式运行。
微内核模式的范例有 Eclipse IDE 和 Web 浏览器。Eclipse 本身只为你提供一个编辑器功能,但是一旦开始添加插件,它就会成为高度可定制和功能强大的产品。同样的,Web 浏览器可以让你无限地安装扩展插件。
优点:
- 极大的灵活性和可扩展性。
- 一些插件允许在应用程序运行时添加。
- 良好的便携性。
- 易于部署。
- 能够快速响应不断变化的环境。
- 插件模块可以单独进行测试。
- 高性能,因为你可以自定义和简化应用程序以仅包括所需的那些功能。
应用场景:
- 从不同来源获取数据,转换数据并将其输出到不同地方的应用程序。
- 工作流应用程序。
- 任务类应用程序。
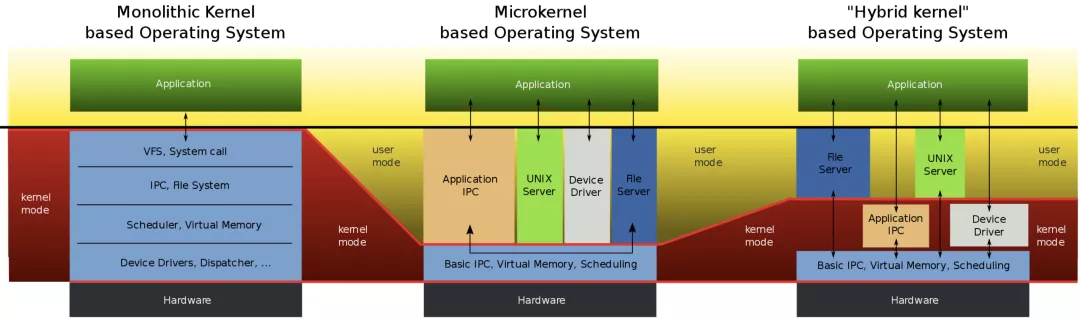
微内核是相对宏内核而言的,宏内核是一个包含非常多功能的底层程序,它干的事情非常多,而且不是可插拔的,修改一些小的功能,都会涉及到整个程序的重新编译等,比如一个功能出现了一个小 Bug,可能导致整个内核都出问题。Linux Kernel 是一个典型的宏内核程序,或被称为 Monolithic OS。
而微内核只负责最核心的功能,其他功能都是通过用户态独立进程以插件方式加入进来,然后微内核负责进程的管理、调度和进程之间通讯,从而完成整个内核需要的功能。基本一个功能出现问题,但是该功能是以独立进程方式存在的,不会对其他进程有什么影响从而导致内核不可用,最多就是内核某一功能现在不可用而已。
相对的,微内核通过进程间通信来协调各个系统进程间的合作,这就需要系统调用,而系统调用需要切换堆栈以及保护进程现场,比较耗费时间;而宏内核则是通过简单的函数调用来完成各个模块之间的合作,所以理论上宏内核效率要比微内核高。
宏内核有一个最大的问题就是定制和维护陈本。现在的移动设备和 IoT 设备越来越多,如果要把一个庞大复杂的内核适配到某一设备上,是一件非常复杂的事情。因此我们更需要一个微内核的架构设计,方便定制,而且非常小,可以实现功能的热替换或者在线更新等,这就是微内核被提出来的核心需求。但是微内核有一个运行的效率问题,所以在微内核和宏内核之间,又有了 Hybrid 内核,主要是想拥有微内核的灵活性,同时在关键点上有宏内核的性能。
管道/过滤器模式(Pipe-filter pattern)
管道/过滤器模式用于构造生成和处理数据流的系统,每个处理步骤都包含一个过滤器组件。要处理的数据通过管道传递,这些管道可用于缓冲或同步目的。
一方面,为了可复用各种 “转换” 的逻辑,可以将它们封装为一个个 Filters。另一方面,为了可以松耦合的组织不同的 Filters 之间的过滤顺序,可以将它们交由一个个 Pipeline 来处理,组件之间拥有简单通用的交互机制。
这样它们就可以灵活地相互结合,这些通用松耦合的组件就很容易复用,独立的组件也可以并行执行。这种架构中的 Pipe 就构成了 Filters 之间的通信通道。
通常的,在该架构中,有如下 4 种过滤器。
- Producer(source):一个过程的起点。
- Transformer (map):对一些或所有数据进行转换。
- Tester (reduce):测试一个或多个条件。
- Consumer (sink):终点。
不足:
- 不适合交互性的系统,因为它们的转换特性。
- 过多的解析和反解析会导致性能损失,也会增加编写过滤器本身的复杂性。
应用场景:
- 编译器。连续过滤器执行词法分析、词法解析、语义分析和代码生成。
- 生物信息学的工作流。
- 工具链式的应用程序。
- 网络数据面处理软件。

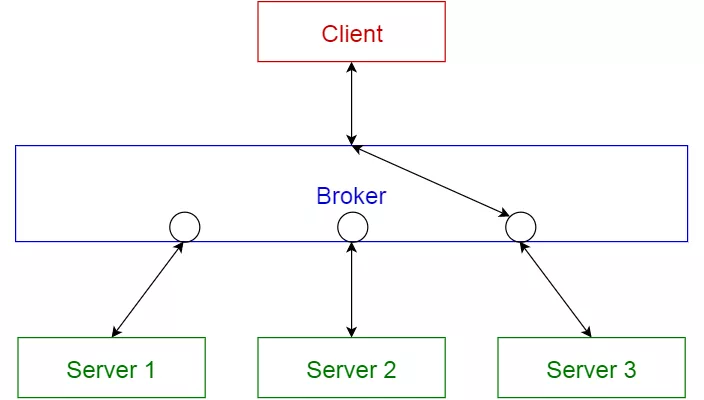
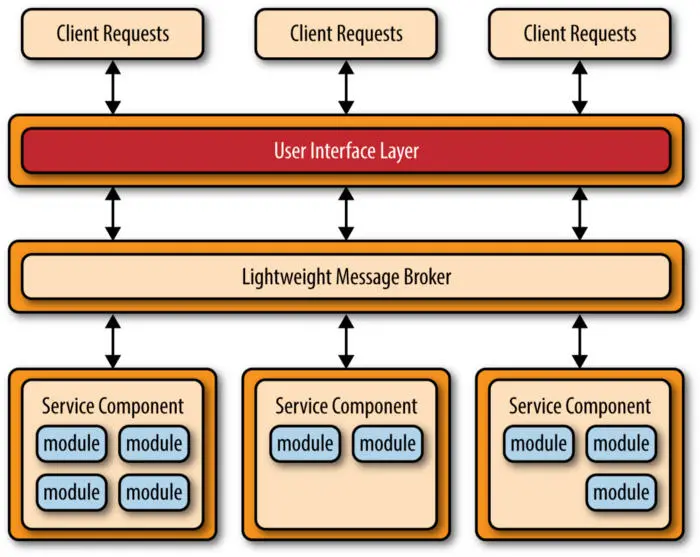
消息代理模式(Message broker pattern)
这种模式通过解耦组件来构造分布式系统,这些组件可以通过远程服务调用彼此交互,代理组件负责协调组件之间的通信。
服务器将其功能(服务和特征)发布给代理,客户端从代理请求服务,然后代理将客户端重定向到其注册中心的适当服务。
注意:Broker,Agent,Proxy 以及 Delegate 之间的的区别。
应用场景:
- 消息代理软件,例如:Apache ActiveMQ、Apache Kafka、RabbitMQ 和 JBoss 消息传递。
- 网络传输中的代理软件。
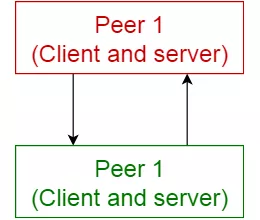
点对点模式(Peer-to-peer pattern)
在这种模式中,单个组件被称为对等点。对等点可以作为客户端,从其他对等点请求服务,作为服务器,为其他对等点提供服务。对等点可以充当客户端或服务器或两者的角色,并且可以随时间动态地更改其角色。
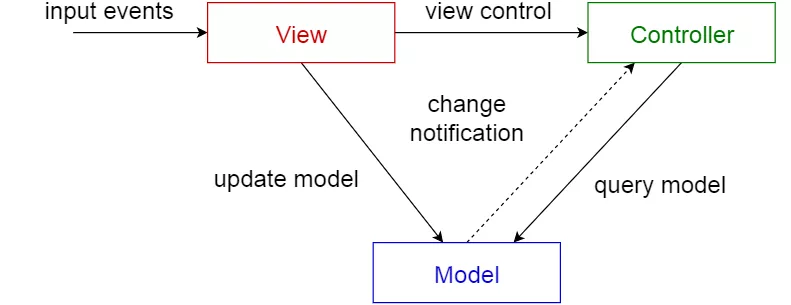
MVC 模式(Model-view-controller pattern)
MVC 模式把一个交互式应用程序划分为 3 个部分:
- 模型:包含核心功能和数据。
- 视图:将信息显示给用户(可以定义多个视图)。
- 控制器:处理用户输入的信息。
这样做是为了将信息的内部表示与信息的呈现方式分离开来,并接受用户的请求。它分离了组件,并允许有效的代码重用。
CQRS 模式
CQS(Command Query Separation,命令查询分离)最早来自于 Betrand Meyer(Eiffel 语言之父,OCP 提出者)提出的概念。其基本思想在于,任何一个对象的方法可以分为两大类:
- 命令(Command):不返回任何结果,但会改变对象的状态。
- 查询(Query):返回结果,但是不会改变对象的状态,对系统没有副作用。
对于涉及数据存储的现代应用程序来说,CQRS 是一种非常有用的模式,其基本原则是将数据存储中的读(查询)和写 / 更新(命令)操作分开。
假设你正在构建一个应用程序,它需要你将数据存储在 MySQL / PostgreSQL 等数据库中。众所周知,在将数据写入数据存储时,一个操作需要几个步骤,比如:验证、建模和持久化。因此,典型的写 / 更新操作要比简单的读操作花费更长的时间。
当你使用单个数据存储同时执行大规模的读取和写入操作时,可能会开始遇到性能问题。
在这种情况下,CQRS 模式建议对读和写操作使用不同的数据模型。该模式的一些变体还建议为这些模型使用单独的数据存储。目前大多数 PaaS 数据库都提供了创建数据存储读副本(Google Cloud SQL、Azure SQL DB、Amazon RDS 等)的能力,这让数据复制更容易实现。
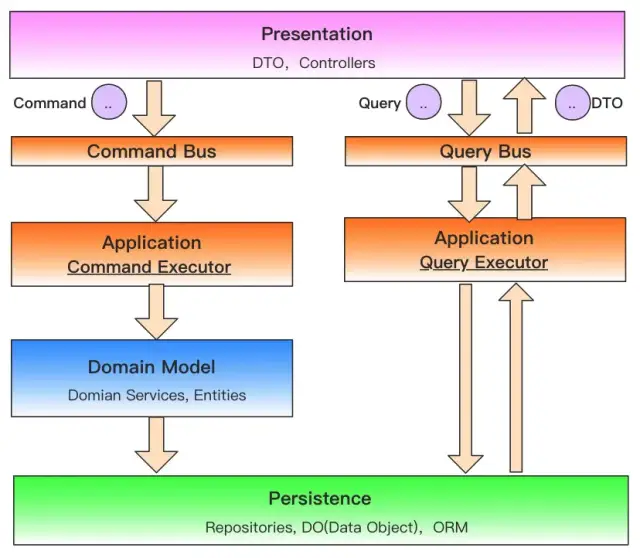
如果你正在使用本地数据库,那么许多企业级数据库也提供了这种功能。现在有些人也喜欢将读副本实现为速度快和性能高的 NoSQL 数据库,像 MongoDB 和 Elasticsearch。
什么时候使用这种模式:
- 当你考虑扩展一个需要大量读写操作的应用程序时;
- 当你希望分别对读和写操作进行性能调优时;
- 当你的读操作可以接受近实时或最终一致时。
什么时候不使用这种模式:
- 当你构建一个常规的 CRUD 应用程序,而它不需要同时进行大量的读写操作时。
断路器模式
分布式系统的设计应该考虑故障。
分布式系统中的组件,这些服务大多依赖于其他远程服务。由于网络、应用程序负载等各种原因,这些远程服务可能无法及时响应。在大多数情况下,实现重试应该就能够解决问题。
但有时候,可能会出现诸如服务降级或服务本身完全失败等重大问题。在这种情况下,不断地重试是没有意义的。这就用到断路器模式了。
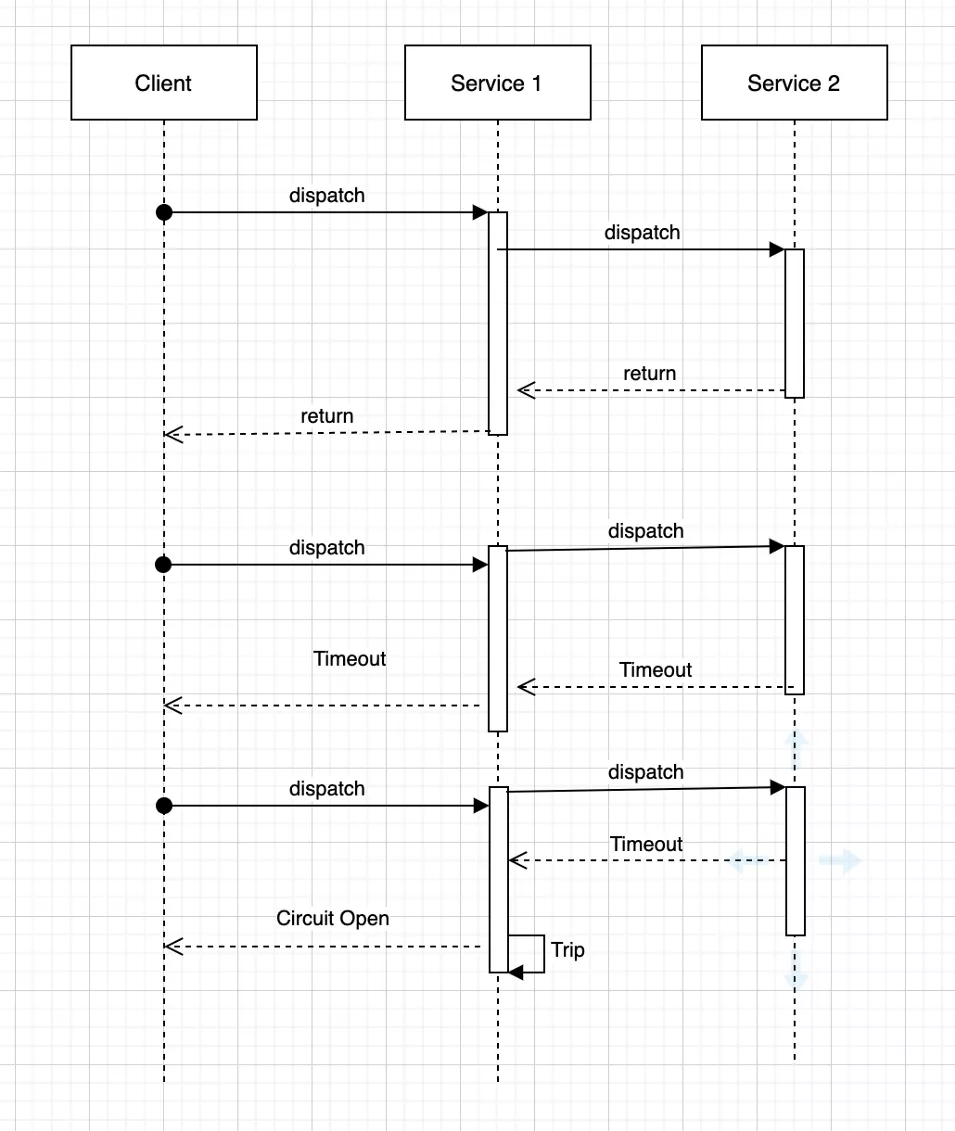
上图展示了断路器模式的实现,其中,当服务 1 识别出服务 2 被调用时存在连续故障 / 超时时,服务 1 将自动断开服务 2 的调用并返回回退响应,而不是重试。
有一些流行的开源库,比如 Netflix 的 Hystrix,可以用来非常轻松地实现这种模式。如果你正在使用 API 网关或像 Envoy 这样的挎斗代理,那么这可以在代理层本身实现。
注意:非常重要的一点是,在断开时,要实现足够的日志记录和告警,以便跟踪在此期间收到的请求,并让运营团队知道。
你还可以实现一个半开断路器,继续使用降级服务为客户端提供服务。
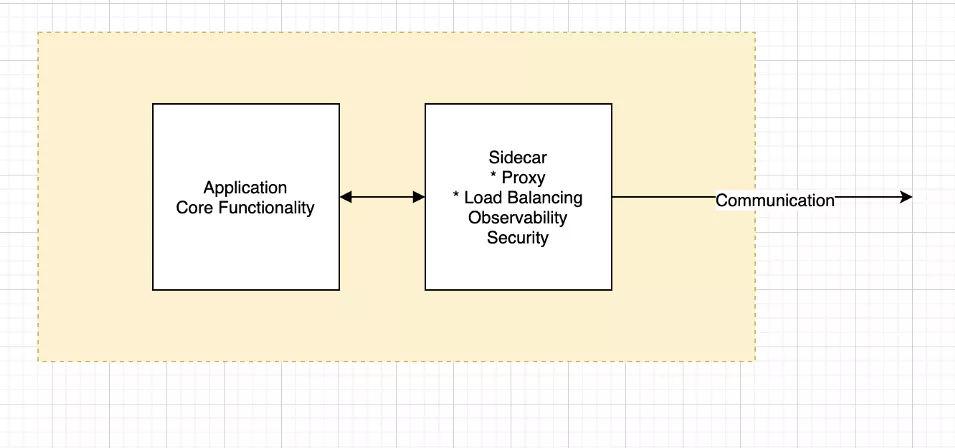
挎斗模式
挎斗模式随着微服务的兴起而流行开来。在此模式中,应用程序的组件被部署到单独的流程或容器中。这有助于实现抽象和封装。
Envoy Proxy 是最常用的挎斗代理之一,应用非常广泛。它有助于保持应用程序核心功能的独立性,使用挎斗来分离网络、可观察性和安全性等常见特性。
这种挎斗可以帮助抽象 L4/L7 层通信。像 Envoy Proxies 这样的挎斗甚至通过实现 Mutual TLS 来帮助实现更高的安全性。你可以将其与服务网格结合使用,在各种微服务之间实现更好的通信和安全性。
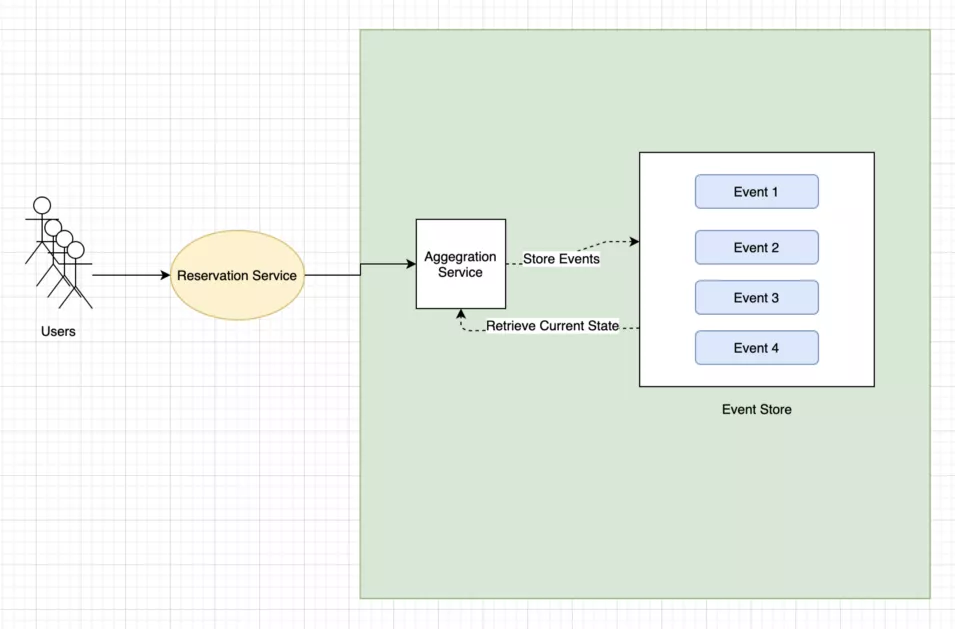
事件源模式
事件源模式将一系列域事件存储为日志,日志的聚合视图提供应用程序的当前状态。
这种模式通常用于无法提供数据存储锁并且需要维护事件的审计和历史记录的系统,例如:酒店 / 会议 / 座位预订之类的应用程序。
考虑用户预订或取消预订的酒店房间预订系统。在这里,你需要将预订和取消存储为一系列事件。在每次预订之前,聚合视图通过查看事件日志显示可用房间。
注意:大多数云服务提供商支持像谷歌 Pub/Sub、Azure 服务总线、AWS SQS 这样的消息传递服务。这些服务,结合强一致性数据存储,可实现此模式。
版权归原作者 范桂飓 所有, 如有侵权,请联系我们删除。