
相信大家都很头疼安装hbase环境吧,开始我也一样,搞了一天才安装成功,为了让第一次安装的朋友少走些弯路,我决定把自己当时总结的文档分析给大家,希望可以帮助到需要的人。话不多说,下面就是安装的详细步骤:
一、下载安装包
首先,我们需要下载图中红色标记的三个压缩包:apache-zookeeper-3.6.3.tar、hadoop-3.3.1.tar、hbase-2.2.7-bin.tar,为了避免出现意想不到的问题,建议下载和我一样的版本,我是将下载好的安装包统一放在/opt/apps下,apps是我新建的目录

Hadoop 与 Hbase 版本必须对应,可以去官网下载或着私信找我拷贝
二、修改hostname
- vi /etc/hosts 添加如下内容,名字随便起个就行,但是后续都是这个名字

2.vi /etc/hostname 添加如下内容

3.改完立即生效:执行 sysctl kernel.hostname=apsm131
4.执行完后 输入hostname,看是否是apsm131
三、安装步骤
3.1.安装zookeeper
1.进入下载目录:cd /opt/apps/
2.解压zookeeper:tar -zxf /root/apache-zookeeper-3.6.3-bin.tar.gz
3.解压完成后进入conf目录:cd apache-zookeeper-3.6.3-bin/conf/
4.重命名cfg文件:mv zoo_sample.cfg zoo.cfg
5.进入bin目录并执行脚本:cd ../bin
./zkServer.sh
6.jps查看启动状态:jps
3.2.安装hadoop
1.解压hadoop-3.3.1.tar.gz
2. cd /opt/apps/hadoop-3.1.1/etc/hadoop
vi hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_211 (注:java_home在/etc/profile下可以找到)
3.namenode机器的位置 ,hdfs-site.xml
vi hdfs-site.xml ,将下面的内容复制到文件中,需要修改成上面设置的hostname,我设置的hostname是apsm131,你们只需要将apsm131替换成自己的就可,其余不需要修改。
<configuration>
<!-- 集群的namenode的位置 datanode能通过这个地址注册,端口号不使用9000,使用8020,9000后续会和其他软件默认端口冲突.配置的域名个人建议最好和ip地址最后一段或者2段同名,这样方便做关联-->
<property>
<name>dfs.namenode.rpc-address</name>
<value>apsm131:8020</value>
</property>
<!-- namenode存储元数据的位置 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hdpdata/name</value>
</property>
<!-- datanode存储数据的位置 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hdpdata/data</value>
</property>
<!-- secondary namenode机器的位置-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>apsm131:50090</value>
</property>
</configuration>
4.配置默认的文件系统 core-site.xml
vi core-site.xml,将下面的内容复制到文件中,需要修改成上面设置的hostname,我设置的hostname是apsm131,你们只需要将apsm131替换成自己的就可,其余不需要修改。
<property>
<name>fs.defaultFS</name>
<value>hdfs://apsm131:8020</value>
</property>
5.初始化namenode
注:如果hostname没有生效的话,初始化会报错
去hadoop安装目录下的bin中,调用以下指令
./hadoop namenode -format
指令执行结束后,检查:ll /opt/hdpdata/name
初始化的元数据目录存在的话,证明初始化成功了
6.单节点启动HDFS
去到namenode所在机器,去安装目录下的sbin中
(1)先启动namenode(顺序不能乱,因为datanode启动后需要去向namenode注册,所以namenode必须先启动)
./hadoop-daemon.sh start namenode 单个启动namenode
(2)再启动datanode
./hadoop-daemon.sh //datanode单个启动datanode
jps查看
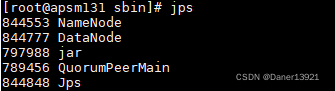
3.3安装Hbase
1.解压hbase-2.2.7-bin.tar.gz
2.先编辑conf目录下的hbase-env.sh文件:设置jdk安装路径以及设置hbase自带的zookeeper失效而使用外部配置的zookeeper
vi hbase-env.sh 修改下面两处,java_home上面提到过
export JAVA_HOME=/opt/apps/jdk1.8.0_251
export HBASE_MANAGES_ZK=false
3. vi hbase-site.xml,将下面的内容复制到文件中,需要修改成上面设置的hostname,我设置的hostname是apsm131,你们只需要将apsm131替换成自己的就可,其余不需要修改。
<configuration>
<property>
<name>hbase.tmp.dir</name>
<value>./tmp</value>
</property>
<!-- 指定hbase在HDFS上存储的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://apsm131:8020/hbase</value>
</property>
<!-- 指定hbase是分布式的 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<!-- 指定zk的地址,多个用“,”分割 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>apsm131:2181</value>
</property>
</configuration>
4. vi regionservers
改成上面设置的hostname
5.启动HBase
单节点启动(这里和Hdfs一样可以单节点和集群方式启动)
cd到hbase安装目录的bin目录下,执行以下命令。如果去/etc/profile中配置了HBASE_HOME环境变量(注意配置好之后source一下),不需要的话就cd到bin目录
执行 ./hbase-daemon.sh start master
6.启动存储服务
还是在当前目录下执行 ./hbase-daemon.sh start regionserver
7. jps 如果下面进程都有,证明安装成功,至此整个安装就完成了
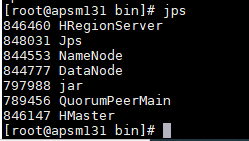
注:HBase启动时报错:/bin/java: No such file or directory,原因是配置环境时hbase-2.2.7/conf/目录下的hbase-env.sh中JAVA_HOME出错
希望可以对大家有所帮助,感谢大家的阅览,喜欢的朋友不妨点个关注,我会不定时的更新学到的内容,大家一起进步,愿永无bug。
本文转载自: https://blog.csdn.net/Daner13921/article/details/123370608
版权归原作者 Daner13921 所有, 如有侵权,请联系我们删除。
版权归原作者 Daner13921 所有, 如有侵权,请联系我们删除。