
点击↑上方↑蓝色“编了个程”关注我~

这是Yasin的第 88 篇原创文章

打字机效果
最近在搭建chat gpt代理的时候,发现自己的配置虽然能够调通接口,返回数据,但是结果是一次性显示出来的,不像之前的chat gpt的官网demo那样实现了打字机效果,一个字一个字出来。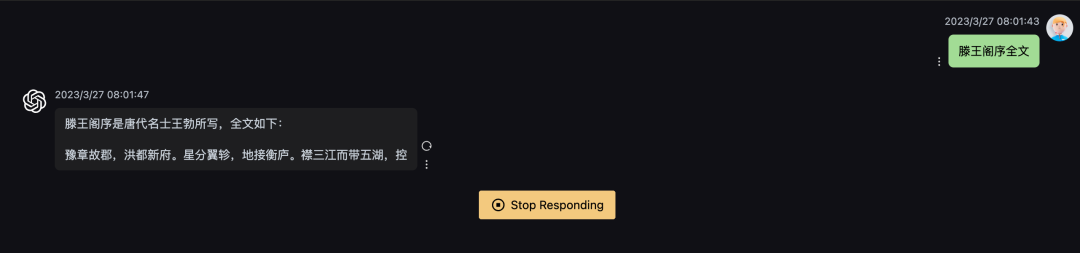
所以研究了一下chat gpt打字机效果的原理,后续如果要实现类似的效果可以借鉴。
纯前端实现打字机效果
最开始我搜索打字机效果时,出现的结果大多数是纯前端的方案。其原理也很简单,通过js定时把内容输出到屏幕。下面是chat gpt的答案:
前端实现打字机效果可以通过以下步骤:
- 将文本内容嵌入到 HTML 元素中,如
div或span。 - 通过 CSS 样式设置元素的显示方式为隐藏(如
display: none;)。 - 使用 JavaScript 获取该元素,并逐个显示其中的字符。
- 使用定时器(如
setInterval()函数)控制每个字符的出现时间间隔,从而实现逐个逐个显示的效果。 - 当所有字符都被显示后,停止定时器以避免不必要的计算开销。
下面是一个简单的示例代码:
HTML:
<div id="typewriter">Hello World!</div>
CSS:
#typewriter {
display: none;
}
JS:
const element = document.getElementById('typewriter');
let i = 0;
const interval = setInterval(() => {
element.style.display = 'inline';
element.textContent = element.textContent.slice(0, i++) + '_';
if (i > element.textContent.length) {
clearInterval(interval);
element.textContent = element.textContent.slice(0, -1);
}
}, 100);
该代码会将
id
为
typewriter
的元素中的文本逐个显示,每个字符之间相隔 100 毫秒。最终显示完毕后,会将最后一个字符的下划线去除。
流式输出
后面我抓包以及查看了chat gpt的官方文档之后,发现事情并没有这么简单。chat gpt的打字机效果并不是后端一次性返回后,纯前端的样式。而是后端通过流式输出不断向前端输出内容。
在chat gpt官方文档中,有一个参数可以让它实现流式输出:
这是一个叫“event_stream_format”的协议规范。
event_stream_format(简称 ESF)是一种基于 HTTP/1.1 的、用于实现服务器推送事件的协议规范。它定义了一种数据格式,可以将事件作为文本流发送给客户端。ESF 的设计目标是提供简单有效的实时通信方式,以及支持众多平台和编程语言。
ESF 数据由多行文本组成,每行用
\n
(LF)分隔。其中,每个事件由以下三部分组成:
- 事件类型(event)
- 数据(data)
- 标识符(id)
例如:
event: message
data: Hello, world!
id: 123
这个例子表示一个名为
message
的事件,携带着消息内容
Hello, world!
,并提供了一个标识符为
123
的可选参数。
ESF 还支持以下两种特殊事件类型:
- 注释(comment):以冒号开头的一行,只做为注释使用。
- 重传(retry):指定客户端重连的时间间隔,以毫秒为单位。
例如:
: This is a comment
retry: 10000
event: update
data: {"status": "OK"}
ESF 协议还支持
Last-Event-ID
头部,它允许客户端在断线后重新连接,并从上次连接中断处恢复。当客户端连接时,可以通过该头部将上次最新的事件 ID 传递给服务器,以便服务器根据该 ID 继续发送事件。
ESF 是一种简单的、轻量级的协议,适用于需要实时数据交换和多方通信的场景。由于其使用了标准的 HTTP/1.1 协议,因此可以轻易地在现有的 Web 基础设施上实现。
抓包可以发现这个响应长这样: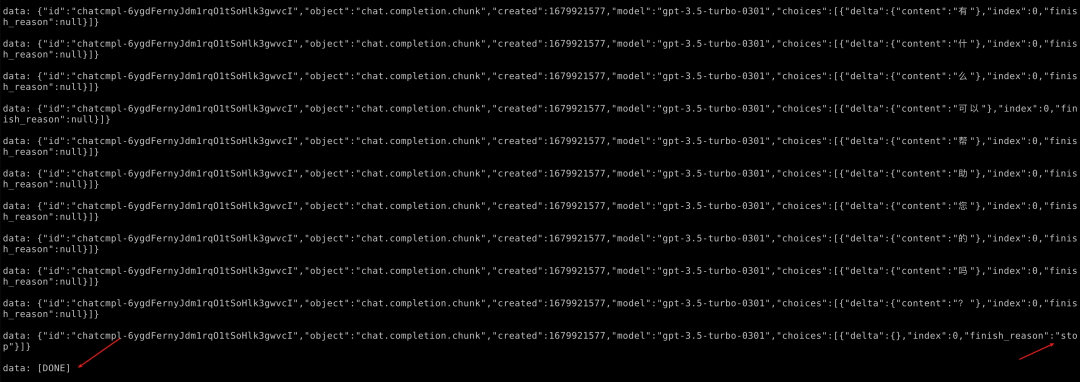

可以看到是data: 加上一个json,每次的流式数据在delta里面。
http response中有几个重要的头: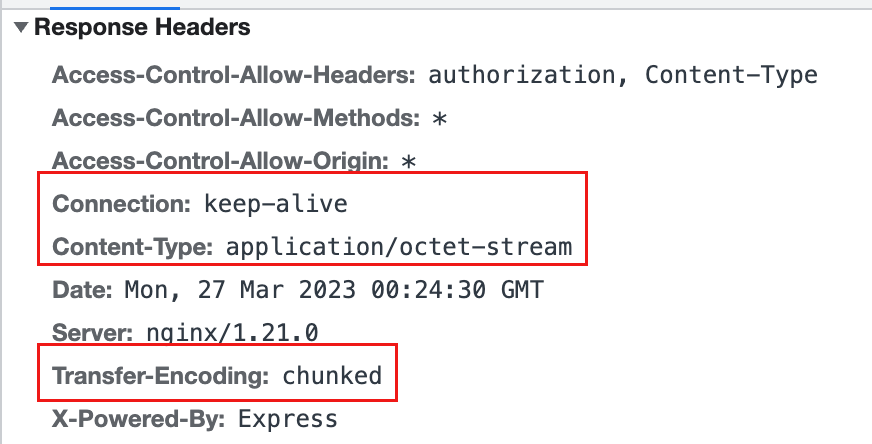
其中,keep-alive是保持客户端和服务端的双向通信,这个大家应该都比较了解。下面解释一下另外两个头.
这里其实openai返回的是
text/event-stream
,
text/event-stream
是一种流媒体协议,用于在 Web 应用程序中推送实时事件。它的内容是文本格式的,每个事件由一个或多个字段组成,以换行符(
\n
)分隔。这个 MIME 类型通常用于服务器到客户端的单向通信,例如服务器推送最新的新闻、股票报价等信息给客户端。
我这里使用的开源项目chatgpt-web抓的包,请求被nodejs包了一层,返回了
application/octet-stream
(不太清楚这么做的动机是什么),它是一种 MIME 类型,通常用于指示某个资源的内容类型为二进制文件,也就是未知的二进制数据流。该类型通常不会执行任何自定义处理,并且可以由客户端根据需要进行下载或保存。
Transfer-Encoding: chunked
是一种 HTTP 报文传输编码方式,用于指示报文主体被分为多个等大小的块(chunks)进行传输。每个块包含一个十六进制数字的长度字段,后跟一个 CRLF(回车换行符),然后是实际的数据内容,最后以另一个 CRLF 结束。
使用 chunked 编码方式可以使服务器在发送未知大小的数据时更加灵活,同时也可以避免一些限制整个响应主体大小的限制。当接收端收到所有块后,会将它们组合起来,解压缩(如果需要),并形成原始的响应主体。
总之,
Transfer-Encoding: chunked
允许服务器在发送 HTTP 响应时,动态地生成报文主体,而不必事先确定其大小,从而提高了通信效率和灵活性。
服务端的实现
作为chat gpt代理
如果写一个golang http服务作为chat gpt的代理,只需要循环扫描chat gpt返回的每行结果,每行作为一个事件输出给前端就行了。核心代码如下:
// 设置Content-Type标头为text/event-stream
w.Header().Set("Content-Type", "text/event-stream")
// 设置缓存控制标头以禁用缓存
w.Header().Set("Cache-Control", "no-cache")
w.Header().Set("Connection", "keep-alive")
w.Header().Set("Keep-Alive", "timeout=5")
// 循环读取响应体并将每行作为一个事件发送到客户端
scanner := bufio.NewScanner(resp.Body)
for scanner.Scan() {
eventData := scanner.Text()
if eventData == "" {
continue
}
fmt.Fprintf(w, "%s\n\n", eventData)
flusher, ok := w.(http.Flusher)
if ok {
flusher.Flush()
} else {
log.Println("Flushing not supported")
}
}
自己作为服务端
这里模仿openai的数据结构,自己作为服务端,返回流式输出:
const Text = `
proxy_cache:通过这个模块,Nginx 可以缓存代理服务器从后端服务器请求到的响应数据。当下一个客户端请求相同的资源时,Nginx 可以直接从缓存中返回响应,而不必去请求后端服务器。这大大降低了代理服务器的负载,同时也能提高客户端访问速度。需要注意的是,使用 proxy_cache 模块时需要谨慎配置缓存策略,避免出现缓存不一致或者过期的情况。
proxy_buffering:通过这个模块,Nginx 可以将后端服务器响应数据缓冲起来,并在完整的响应数据到达之后再将其发送给客户端。这种方式可以减少代理服务器和客户端之间的网络连接数,提高并发处理能力,同时也可以防止后端服务器过早关闭连接,导致客户端无法接收到完整的响应数据。
综上所述, proxy_cache 和 proxy_buffering 都可以通过缓存技术提高代理服务器性能和安全性,但需要注意合理的配置和使用,以避免潜在的缓存不一致或者过期等问题。同时, proxy_buffering 还可以通过缓冲响应数据来提高代理服务器的并发处理能力,从而更好地服务于客户端。
`
type ChatCompletionChunk struct {
ID string `json:"id"`
Object string `json:"object"`
Created int64 `json:"created"`
Model string `json:"model"`
Choices []struct {
Delta struct {
Content string `json:"content"`
} `json:"delta"`
Index int `json:"index"`
FinishReason *string `json:"finish_reason"`
} `json:"choices"`
}
func handleSelfRequest(w http.ResponseWriter, r *http.Request) {
// 设置Content-Type标头为text/event-stream
w.Header().Set("Content-Type", "text/event-stream")
// 设置缓存控制标头以禁用缓存
w.Header().Set("Cache-Control", "no-cache")
w.Header().Set("Connection", "keep-alive")
w.Header().Set("Keep-Alive", "timeout=5")
w.Header().Set("Transfer-Encoding", "chunked")
// 生成一个uuid
uid := uuid.NewString()
created := time.Now().Unix()
for i, v := range Text {
eventData := fmt.Sprintf("%c", v)
if eventData == "" {
continue
}
var finishReason *string
if i == len(Text)-1 {
temp := "stop"
finishReason = &temp
}
chunk := ChatCompletionChunk{
ID: uid,
Object: "chat.completion.chunk",
Created: created,
Model: "gpt-3.5-turbo-0301",
Choices: []struct {
Delta struct {
Content string `json:"content"`
} `json:"delta"`
Index int `json:"index"`
FinishReason *string `json:"finish_reason"`
}{
{ Delta: struct {
Content string `json:"content"`
}{
Content: eventData,
},
Index: 0,
FinishReason: finishReason,
},
},
}
fmt.Println("输出:" + eventData)
marshal, err := json.Marshal(chunk)
if err != nil {
return
}
fmt.Fprintf(w, "data: %v\n\n", string(marshal))
flusher, ok := w.(http.Flusher)
if ok {
flusher.Flush()
} else {
log.Println("Flushing not supported")
}
if i == len(Text)-1 {
fmt.Fprintf(w, "data: [DONE]")
flusher, ok := w.(http.Flusher)
if ok {
flusher.Flush()
} else {
log.Println("Flushing not supported")
}
} time.Sleep(100 * time.Millisecond)
}
}
核心是每次写进一行数据
data: xx \n\n
,最终以
data: [DONE]
结尾。
前端的实现
前端代码参考https://github.com/Chanzhaoyu/chatgpt-web的实现。
这里核心是使用了axios的onDownloadProgress钩子,当stream有输出时,获取chunk内容,更新到前端显示。
await fetchChatAPIProcess<Chat.ConversationResponse>({
prompt: message,
options,
signal: controller.signal,
onDownloadProgress: ({ event }) => {
const xhr = event.target
const { responseText } = xhr
// Always process the final line
const lastIndex = responseText.lastIndexOf('\n')
let chunk = responseText
if (lastIndex !== -1)
chunk = responseText.substring(lastIndex)
try {
const data = JSON.parse(chunk)
updateChat(
+uuid,
dataSources.value.length - 1,
{
dateTime: new Date().toLocaleString(),
text: lastText + data.text ?? '',
inversion: false,
error: false,
loading: false,
conversationOptions: { conversationId: data.conversationId, parentMessageId: data.id },
requestOptions: { prompt: message, options: { ...options } },
},
)
if (openLongReply && data.detail.choices[0].finish_reason === 'length') {
options.parentMessageId = data.id
lastText = data.text
message = ''
return fetchChatAPIOnce()
}
scrollToBottom()
}
catch (error) {
//
}
},
})
在底层的请求代码中,设置对应的header和参数,监听data内容,回调onProgress函数。
const responseP = new Promise((resolve, reject) => {
const url = this._apiReverseProxyUrl;
const headers = {
...this._headers,
Authorization: `Bearer ${this._accessToken}`,
Accept: "text/event-stream",
"Content-Type": "application/json"
};
if (this._debug) {
console.log("POST", url, { body, headers });
}
fetchSSE(
url,
{
method: "POST",
headers,
body: JSON.stringify(body),
signal: abortSignal,
onMessage: (data) => {
var _a, _b, _c;
if (data === "[DONE]") {
return resolve(result);
}
try {
const convoResponseEvent = JSON.parse(data);
if (convoResponseEvent.conversation_id) {
result.conversationId = convoResponseEvent.conversation_id;
}
if ((_a = convoResponseEvent.message) == null ? void 0 : _a.id) {
result.id = convoResponseEvent.message.id;
}
const message = convoResponseEvent.message;
if (message) {
let text2 = (_c = (_b = message == null ? void 0 : message.content) == null ? void 0 : _b.parts) == null ? void 0 : _c[0];
if (text2) {
result.text = text2;
if (onProgress) {
onProgress(result);
}
}
}
} catch (err) {
}
}
},
this._fetch
).catch((err) => {
const errMessageL = err.toString().toLowerCase();
if (result.text && (errMessageL === "error: typeerror: terminated" || errMessageL === "typeerror: terminated")) {
return resolve(result);
} else {
return reject(err);
}
});
});
nginx配置
在搭建过程中,我还遇到另一个坑。因为自己中间有一层nginx代理,而「nginx默认开启了缓存,所以导致流式输出到nginx这个地方被缓存了」,最终前端拿到的数据是缓存后一次性输出的。同时gzip也可能有影响。
这里可以通过nginx配置,把gzip和缓存都关掉。
gzip off;
location / {
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_cache off;
proxy_cache_bypass $http_pragma;
proxy_cache_revalidate on;
proxy_http_version 1.1;
proxy_buffering off;
proxy_pass http://xxx.com:1234;
}
proxy_cache
和
proxy_buffering
是 Nginx 的两个重要的代理模块。它们可以显著提高代理服务器的性能和安全性。
proxy_cache:通过这个模块,Nginx 可以缓存代理服务器从后端服务器请求到的响应数据。当下一个客户端请求相同的资源时,Nginx 可以直接从缓存中返回响应,而不必去请求后端服务器。这大大降低了代理服务器的负载,同时也能提高客户端访问速度。需要注意的是,使用proxy_cache模块时需要谨慎配置缓存策略,避免出现缓存不一致或者过期的情况。proxy_buffering:通过这个模块,Nginx 可以将后端服务器响应数据缓冲起来,并在完整的响应数据到达之后再将其发送给客户端。这种方式可以减少代理服务器和客户端之间的网络连接数,提高并发处理能力,同时也可以防止后端服务器过早关闭连接,导致客户端无法接收到完整的响应数据。
实测只配置
proxy_cache
没有用,配置了
proxy_buffering
后流式输出才生效。

关于作者
我是Yasin,一个爱写博客的技术人
微信公众号:编了个程(blgcheng)
欢迎关注这个公众号

版权归原作者 编了个程 所有, 如有侵权,请联系我们删除。