
目录
一、MySQL服务器逻辑架构
MySQL核心部分包括查询解析、分析、优化、缓存以及内置函数,所有跨存储引擎的功能,存储过程、触发器、视图等。
存储引擎负责MySQL中数据的存储和提取。服务器通过API和存储引擎进行通信。存储引擎API包含几十个底层函数,用于执行诸如“开始一个事务”或“根据主键查询数据”等操作,但存储引擎不会去解析SQL,不同存储引擎之间也不会相互通信,而只是简单地响应上层服务器的请求。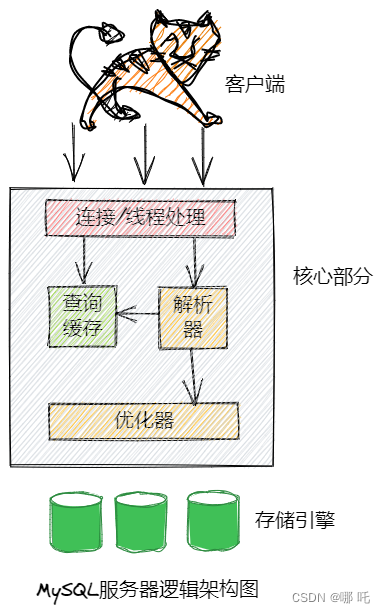
二、并发控制
1、读写锁
读锁是共享的,或者说是互不阻塞的,多个用户在同一时刻可以同时读取同一个资源,而互不打扰。
写锁则是排它锁,写锁会阻塞其它的写锁和读锁。
2、锁粒度
获取锁、检查锁是否被占用、释放锁等操作,都会增加系统的开销。
锁策略的意思就是在锁的开销和数据的安全性之间寻求平衡。
3、表锁
表锁是开销最小的锁,表锁 = 锁住整张表。
一个用户在对表进行写操作前,需要先获得写锁,这会阻塞其它用户对该表的读写操作。没有写锁时,其它用户会获取读锁,读锁之间互不阻塞。
尽管存储引擎可以管理自己的锁,MySQL还是会使用各种高效的表锁来实现不同的目的。比如,
ALTER TABLE
语句使用的就是表锁,而忽略存储引擎的锁机制。
4、行级锁
行级锁可以最大程度的支持并发处理,但也带来了最大的锁开销。
三、事务
事务内的语句,要么全执行,要么全不执行。事务具有ACID特性,ACID表示原子性(atomicity)、一致性(consistency)、隔离性(isolation)、持久性(durability)。
1、原子性(atomicity)
一个事务必须被视为一个不可分割的最小工作单元,整个事务中的所有操作要么全执行提交成功,要么全不失败回滚。
2、一致性(consistency)
数据库总是从一个一致性的状态转换到另一个一致性的状态。
3、隔离性(isolation)
一个事务所做的修改在最终提交以前,对其它事务是不可见的。
4、持久性(durability)
事务一旦提交,则七所做的修改就会永久的保存在数据库中。
四、隔离级别
1、未提交读 read uncommited
在read uncommited级别,事务中的修改,即使没有提交,对其他事务也都是可见的。事务可以读取未提交的数据,这也被称为脏读(Dirty Read)。这会导致很多问题,实际应用中很少使用。
2、提交读 read commited
大多数数据库系统的默认隔离级别都是 read commited,但MySQL不是, read commited满足前面提到的隔离性,一个事务开始时,只能看见已经提交的事务所做的修改。也称为不可重复读,因为两次执行同样的查询,可能会得到不一样的结果。
3、可重复读 repeatable read
repeatable read 解决了脏读的问题,该级别保证了在同一个事务中多次读取同样的记录的结果是一致的。但还是解决不了幻读的问题,幻读指的是当某个事务在读取某个范围内的记录时,另一个事务又在该氛围内插入了新的记录,档之前的事务再次读取该范围的记录时,会产生幻行。
可重复读是MySQL的默认事务隔离级别。
4、可串行化 serializable
serializable是最高级别的锁,它通过强事务串行执行,避免了之前说的幻读问题,serializable会在读取的每一行数据上都加锁,可能会导致大量的超时和锁争用问题,实际应用中很少使用这个隔离级别。
五、死锁
死锁是指两个或多个事务在同一个资源上相互占用,并请求锁定对方占用的资源,从而导致恶性循环的现象。当多个事务视图以不同的顺序锁定资源时,就可能会产生死锁。如果两个事务都尝试去执行一条相同的update语句,却发现该行已经被对方锁定,然后两个事务都等待对方释放锁,同时又持有对方需要的锁,则陷入死锁。
为了解决死锁问题,比如MySQL的InnoDB存储引擎,如果检测到死锁的循环依赖,InnoDB会将持有最少行级锁的事务进行回滚。
六、事务日志
存储引擎在修改表的数据时只需修改其内存拷贝,再把该修改行为记录在磁盘的事务日志中,而不是每次都将修改的数据本身持久到磁盘。
事务日志采用的是追加方式,事务日志在持久化之后,内存中被修改的数据会在后台慢慢的存入磁盘,但如果此时发生了异常,存储引擎在重启后,也会根据事务日志,将数据存到磁盘中。
七、多版本并发控制MVCC
MySQL的大多数事务型存储引擎实现的都不是简单的行级锁。基于提升并发性能的考虑,它们一般都同时实现了多版本并发控制MVCC,可以认为MVCC是行级锁的一个变种,但MVCC在很多情况下避免了加锁操作,开销比行级锁要低的多。
MVCC是通过保存某个时间点的快照实现的,不管需要执行多长时间,每个事物看到的数据都是一致的。根据事务开始的时间不同,每个事物对同一张表,同一时刻看到的数据可能是不一致的。
InnoDB的MVCC是通过在每行记录后面保存两个隐藏的列实现的,一个保存了行的创建时间,一个保存行的删除时间。存储的并不是实际的时间值,而是系统版本号。每开始一个新的事务,系统版本号都会自动递增。事务开始时刻的系统版本号会作为事务的版本号,用来和查询到的每行记录的版本号进行对比。
MVCC只在提交读 read commited、可重复读 repeatable read两个隔离级别中使用。
分别分析增删改查时,MVCC的使用。
1、select
InnoDB会根据以下两个条件检查每行记录:
- InnoDB只查找版本早于当前事务版本的数据行,这样保证事务读取的行,要么是在事务开始前就存在的,要么是事务自身插入或修改的;
- 行的删除版本要么未定义,要么大于当前事务版本号,这样保证事务读取的行,在事务开始前未被删除;
2、insert
InnoDB为新插入的每一行保存当前系统版本号作为行版本号。
3、update
InnoDB会插入一行新纪录,保存当前系统版本号作为行版本号,同时保存当前系统版本号到原来的行作为行删除表示。
4、delete
InnoDB为删除的每一行保存当前系统版本号作为行删除标识。
保存这两个额外的系统版本号,使大多数读操作都可以不用加锁,MVCC的设计是的读数据很简单,性能很好,并且也能保证只会读到符合要求的行,不足之处是每行记录都需要额外的存储空间,需要做更多的行检查工作,以及一些额外的维护工作。
MySQL进阶实战系列文章
MySQL进阶实战1,数据类型与三范式
SQL性能优化的21个小技巧
mysql索引详解
MySql基础知识总结(SQL优化篇)
哪吒精品系列文章
Java学习路线总结,搬砖工逆袭Java架构师
10万字208道Java经典面试题总结(附答案)
Java基础教程系列
Spring Boot 进阶实战
版权归原作者 哪 吒 所有, 如有侵权,请联系我们删除。