
HashMap
HashMap介绍
数据结构是一门组织联系数据的学科,其中一种数据结构就是 HashMap,它是一种以键值对的形式存储数据的数据结构,时间复杂度可以达到 O(1)
HashMap常用方法
HashMap 的方法有很多,这里介绍几个常用的:
以下代码均使用该实例:
Map<T, T> map =newHashMap<>();
- put()方法 用于将键值对存入 map 中
map.put("zhangsan",20);
map.put("lisi",22);
注意: (1)map 中不允许存在相同的 K 值,所以当使用 put 函数放入键值对时,如果此时 map 中已经有了当前 K 值,则会将原有 K 所对应的 V 值覆盖。
(2)HashMap 中的 put()方法允许使用 null 作为 K
- get()方法 用于获取 map 中已存放的键值对中指定 K 值对应的 V 值。
map.get("zhangsan");
map.get("zhangsan2");
此时的输出结果分别对应 20,null
- remove()方法 用于删除 map 中存放的键值对
map.remove("zhangsan");
此时 map 中只剩下 <“lisi”, 20> 这组键值对
- keySet()方法 用于获取 map 中所有不重复 K 值集合,返回一个 Set
Set set = map.keySet();
set 中的所有元素的是不重复的。
- EntrySet()方法 用于获取 map 中所有键值对的映射关系
Set<Map.Entry<String, Integer>> setEntry = map.EntrySet();
其 setEntry 中存放的就是若干个 Map.Entry<String, Integer> 类型的键值对
哈希表
HashMap 的底层实现就是一张哈希表,或者叫哈希桶(HashBuck)
哈希表的存取都通过哈希函数来进行映射,得到相应的映射关系,找到对应的哈希地址来进行存储,从而其时间复杂度达到O(1)
哈希表的存取
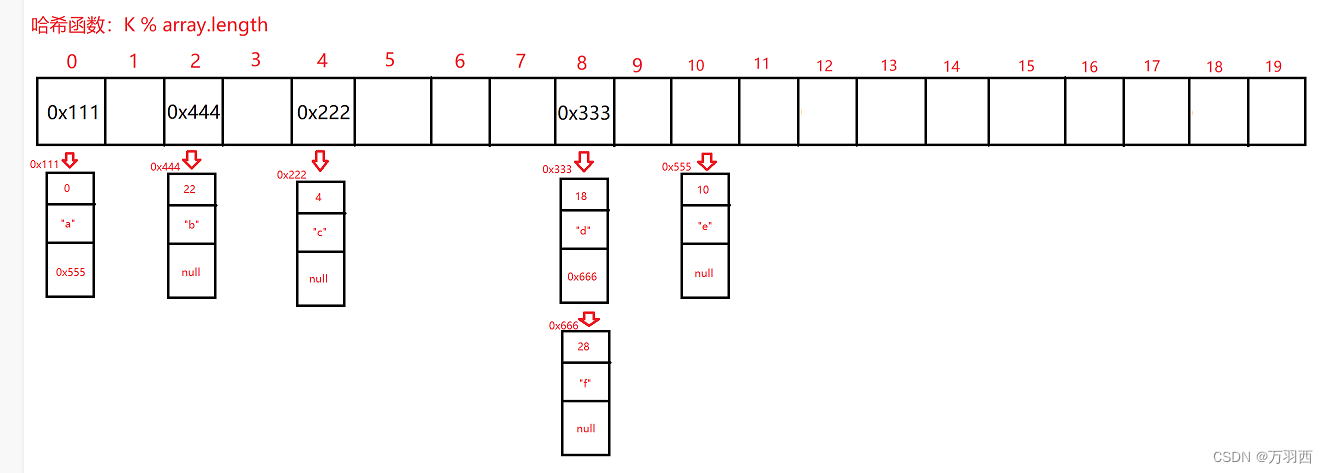
举个栗子来描述哈希表的存取
假设 K 值为 Integer 类型的
哈希函数:K % array.length
那么对应的存取将都由这个哈希函数进行映射
比如以下有 4 个数据:0, 4, 18, 22
以及一个 array 数组(大小为 10)
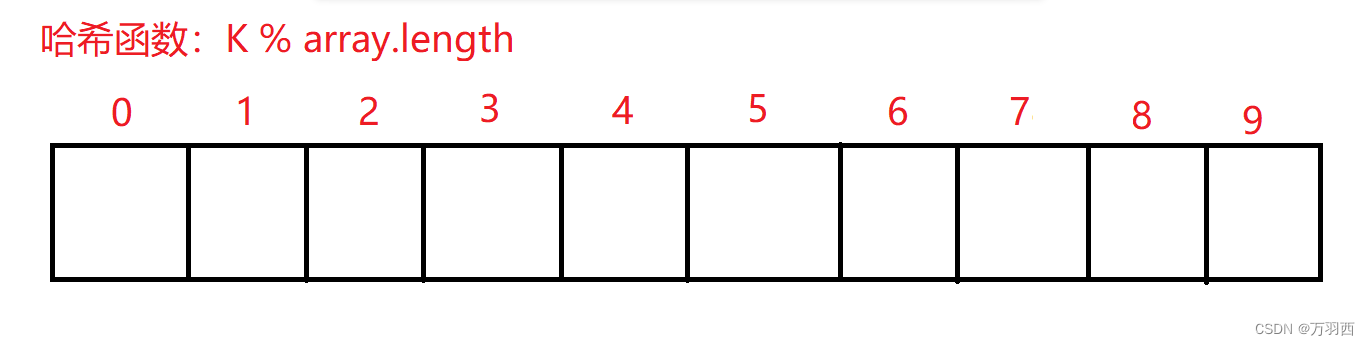
将这四个数据分别代入哈希函数求得哈希地址为:0,4,8,2
将其对应存放进 array 数组里
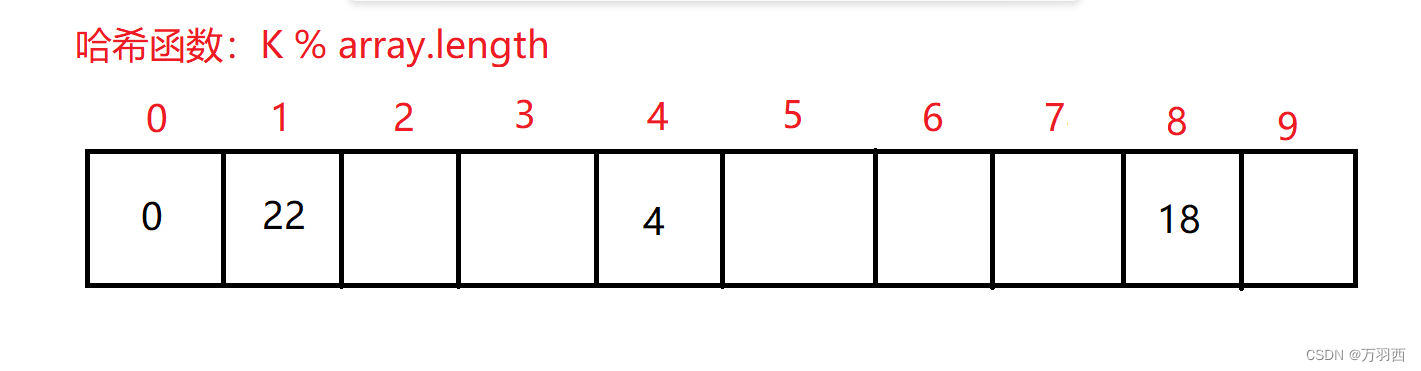
如果要取元素,也同样通过哈希函数进行映射拿到对应哈希地址取出元素。
但是这样的存取,就必然会存在一个问题,那就是 “哈希冲突”
哈希冲突
当哈希函数确定之后,如果存入大量的数据,都通过这个哈希函数进行映射,那必然会出现哈希地址重复的情况,这就是哈希冲突。
如果一味的不管哈希冲突,就会导致新的数据将旧的数据覆盖,为了解决这个问题,可以采用增加数组长度的方式,但是因为数据个数一定是远远大于数组长度的,也就导致哈希冲突是无法避免的,
所以哈希表采用的方法是开链法
所谓开链法,就是将所有的数据通过数组 + 链表的形式进行组织
每一个链表节点必须有 3 个域,分别是 next 域,K 域,V 域
而数组中存放的每个元素是引用类型,存放链表第一个节点的地址。
如下图,将 4 个键值对存入哈希表
<0, “a”> <4, “c”> <18, “d”> <22, “b”>
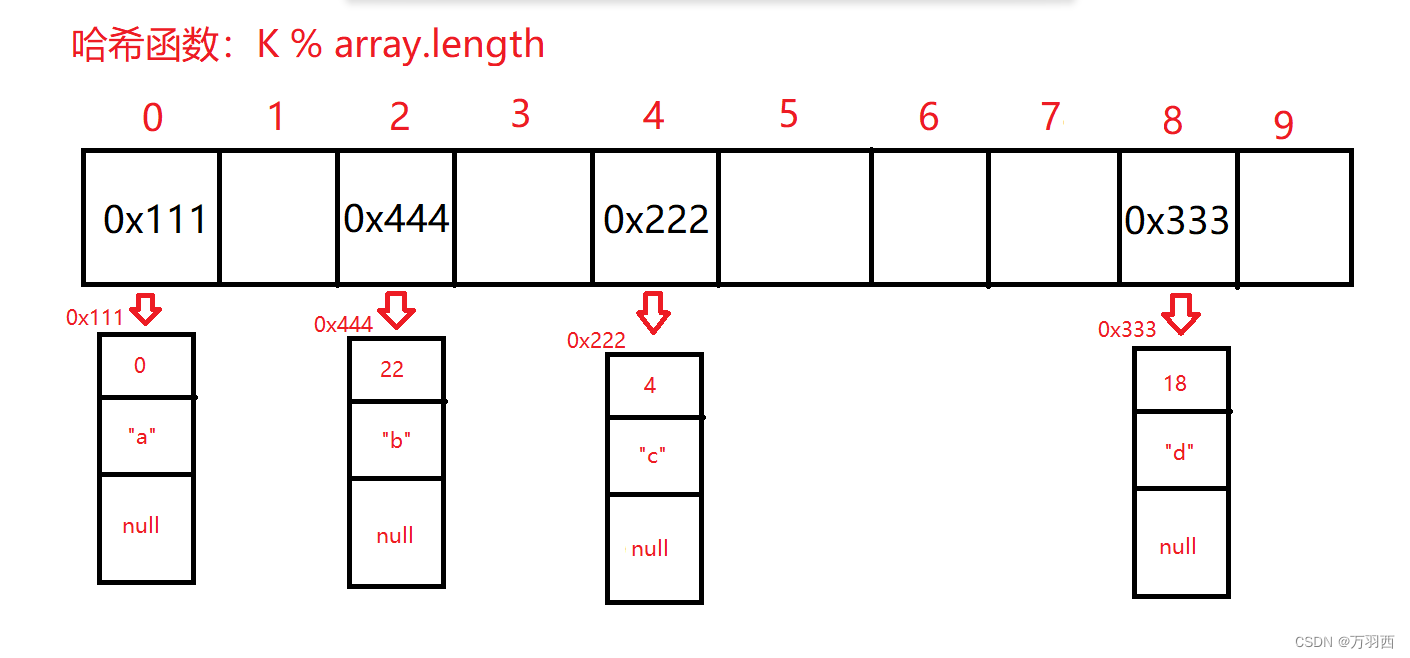
使用开链法的方式进行存储将是以上形式,这样可以有效的避免哈希冲突带来的麻烦。
比如现在又要插入几个键值对:<10,“e”>,<28,“f”>
结果如下:
注:哈希表中的链表采用的是头插法,我这里为了方便画图采用了尾插法,请见谅~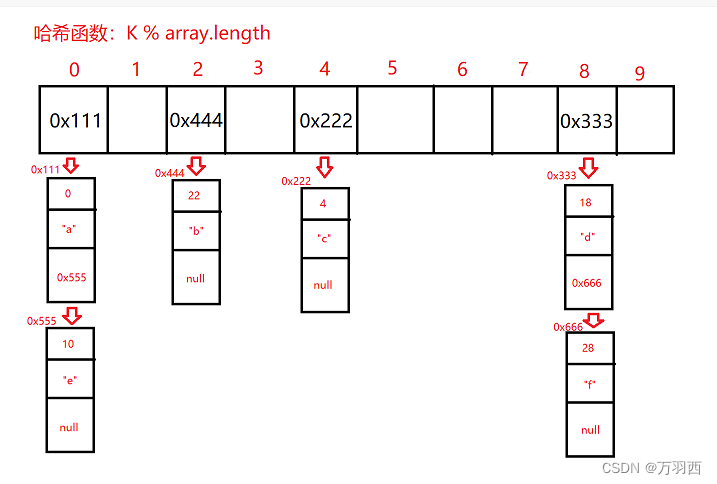
以上就是哈希桶进行存取数据的方式,但是现在又有了新的问题,哈希表的存取需要让时间复杂度达到 O(1),如果链表的长度过长,那么就会导致存取的时间复杂度达不到 O(1)。
这里就提出了一个概念,叫做负载因子
负载因子
在哈希表中,数据的个数是无法确定已经更改的,为了避免链表的长度过长而降低时间复杂度,只能通过增加数组长度的方式来解决。
而负载因子 = 数据的个数 / 数组的长度
我们知道,数据的个数是不可控的,而当我们增加数组的长度,就可以降低负载因子,从而负载因子就可以作为我们评判数组是否扩容的标准。
在源码中,默认的负载因子大小为 0.75,也就意味着,当存入的数据太多,导致负载因子超过 0.75 时,数组就会进行扩容。
通过负载因子的控制,链表的长度就不会很长,可以控制在常数范围内
扩容机制
在哈希表中,除了给定了默认的负载因子大小为 0.75,还给定了一个 1 << 30 作为哈希表的最大默认容量,每一次存储数据之后会计算对应的负载因子是否超过了 0.75,如果超过了 0.75,将会判断当前容量的两倍有没有超过 1 << 30,如果没有超过,则进行二倍扩容,如果超过了,则将 1 << 30 作为新的容量大小。
在每一次数组进行扩容之后,原来存放的数据必须进行重新哈希,因为此时的数组长度已经发生了变化,这样就能够达到我们想要缩短链表长度的目的,如下:
这样即可降低哈希表中链表的长度,达到提高效率的目的。
其他机制
由上文已经了解到了几个简单的机制,譬如默认负载因子大小为 0.75,最大容量为1 << 30,超过默认负载因子将出发扩容机制等等。。
接下来还有几个比较重要的机制。
哈希表容量问题
首先,如果在实例化时不指定哈希表的容量,则哈希表的默认容量为 16,但并非是构造出 map 对象的那一时刻就给定容量,在 JDK 8 中,实例化 map 之后其实他的容量依然是为 0 的,如果我们不指定 map 大小,那么将在第一次 put()元素时为其开辟大小为 16 的容量。
如果指定了哈希表的容量,如:
Map<String, Integer> map =newHashMap<>(20);
则同理,在实例化之后,并不分配容量,而是在第一次 put()元素时为其分配大小,但值得一说的是,这里给它分配的容量大小并不是 20,而是 32,具体原因看完第二点便可知道。
哈希函数问题
哈希表的容量大小必须是 2 的次幂,其原因是为了提高哈希表的效率,降低哈希冲突。
在源码中,计算并不是使用 hash(K)% array.length 来进行计算的,取而代之的是 hash(K)&(array.length - 1)。
因为按位与运算比取模运算的效率要高很多,而 & 运算存在一个问题,hash(K)的值可能为 1 也可能为 0,而如果(array.length - 1)的值也可奇可偶的话,那么运算出来是偶数的概率则会特别大,为了解决这个问题,就采用了让 array.length - 1,并且保证数组长度是偶数的方法来确保 array.length - 1 是奇数,这样计算的结果奇偶概率分散,即可大大降低哈希冲突的概率。
树化问题
就算哈希表有了负载因子,有了开链法,有了扩容机制,但还是架不住数据量的庞大,这就导致链表长度随时会过长,为了不让这种现象影响哈希表的性能,在哈希桶中会在每一次 put()元素之后进行判断,如果当前链表长度超过 8 则会将链表转换成一种查找效率极高的数据结构 - - 红黑树(这里不介绍),以此来保证其时间复杂度达到O(1)。
当变成红黑树之后,如果哈希表中使用 remove()方法删除元素,导致链表长度小于 6,则又会将红黑树进行链化,变成原来的链表。
hashcode 问题
上文讲的例子中,K 的值是 Integer 类型的,但我们在使用 HashMap 的时候极有可能用到的 K 值是 String 类型或者其他类型的数据,那该如何进行计算呢?
答案就是重写 hashcode()方法,使用 hashcode()方法可以将不是整型的数据转化为一个合法的整型数据,从而方便进行哈希映射。
那么,就又引出了一个新的问题,举一个栗子,如果要存放用户对应的身份证信息,那就需要不管是几个实例的 map,只要存放的 K 值相同,查找到的身份证信息就应该相同,但是 hashcode()方法就出问题了:
classPerson{public String name;publicPerson(String name){this.name = name;}@OverridepublicinthashCode(){return Object.hash(name);}}
Map<String, Integer> map =newHashMap<>();
map.put("zhangsan",123);
Person person1 =newPerson("zhangsan");
Person person2 =newPerson("zhangsan");
person1.hashcode();
person2.hashcode();
此时的 person1 和 person2 的 hash 值将会不相等,因为这是针对两个不同对象的 hashcode,所以对应的值会不相等,但他们的 name 都是 “zhangsan”,所以我们希望他们拿到的哈希值是一样的。
这就需要 “hashcode and equals” 来解决这个问题了。
我们只需要在 Person 类中同时重写 hashcode()方法和 equals()方法。
classPerson{public String name;publicPerson(String name){this.name = name;}@Overridepublicbooleanequals(Object o){if(this== o)returntrue;if(o == null ||getClass()!= o.getClass())returnfalse;
Person person =(Person) o;return Object.equals(name, person.name);}@OverridepublicinthashCode(){return Object.hash(name);}@Overridepublic String toString(){return"Person{"+"name='"+ name +'\''+'}'";}}
Person person1 =newPerson("123");
Person person2 =newPerson("123");
System.out.println(person1.hashcode());
System.out.println(person2.hashcode());
此时拿到的哈希值就会是相等的了,重写的 equals()方法会帮助我们判断对象是否相等,如果相等,就会返回 TRUE,在 hashcode()时返回一个相同的值。
相当于如果我们在查字典,要查 “二” 这个字
equals()方法就帮我们找到了 E 所对应的位置
而hashcode()方法则帮我们找到 “er”
所以,在使用哈希表存放自定义类型数据类型的时候,一定要重写 hashcode()方法和 equals()方法。
总结
以上就是本文的全部内容,首先是 hashmap 的常用方法:put,get,keySet等等。
然后是哈希表的底层是一个哈希桶,使用链表 + 数组的形式进行组织。
接下来是哈希表中的一些机制,比如何时开辟内存,超过负载因子进行二倍扩容并重新哈希,链表长度超过阈值树化,哈希桶容量必须是 2 的幂次等等。
希望本文可以给大家带来帮助~ 感谢~~
版权归原作者 万羽西 所有, 如有侵权,请联系我们删除。