
kafka的架构和流程
⾸先Kafka从架构上说分为⽣产者Broker和消费者,每⼀块都进⾏了单独的优化,⽐如⽣产者快是因为数据的批量发送,Broker快是因为分区,分区解决了并发度的问题,⽽且⽂件是采取的顺序写的形式。顺序写就可以有效的减少磁盘寻址的时间其次它还采⽤了分段的概念,就是所谓的Segment,每⼀个Segment⼜包含⼀个索引⽂件和⼀个数据⽂件,通过这样的机制就保证写⼊速度是⾮常的快的。
还有⼀个就是最重要的零拷⻉技术的应⽤,零拷⻉其实是OS层⾯的⼀个技术,就是操作系统的PageCache利⽤这个操作系统的缓存⻚在加上调⽤操作系统的SendFile函数实现了对数据的处理提⾼了性能,所以采⽤零拷⻉技术之后就直接把进程之间的流拷⻉直接省略了,使⽤操作系统的Buffer从⽽⼤幅的提升了性能,因为数据传输的过程中省了⼀层,其实零拷⻉也是⽐较复杂的
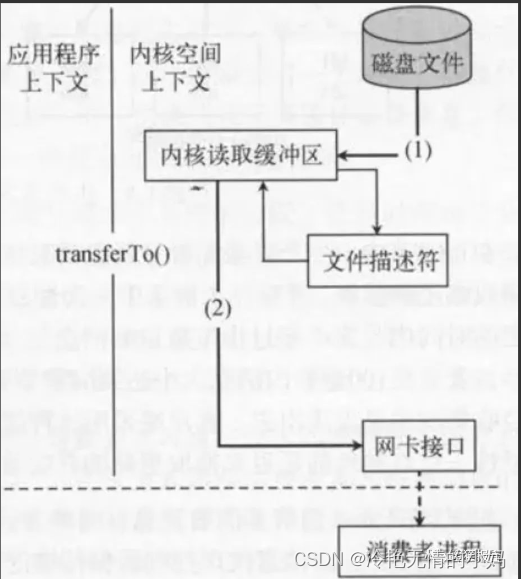
因为Kafka的性能⽐较⾼所以当时我们数仓系统中,先通过Flume采集数据然后通过KafkaChannel放⼊Kafka中,下游使⽤Flume来做为消费者消费Kafka数据并存⼊HDFS中。
小文件对HDFS影响:
在Flume做消费者往HDFS上传输数据的时候遇到了很多问题,其中最重要的问题就是⼩⽂件的问题。因为它会从两个⽅⾯影响HDFS。1、针对NameNode来说,⾸先它会占⽤⼤量的存储空间,影响NameNode的存储性能,2、针对于MR来说,它会影响计算的性能,因为每⼀个⼩⽂件都会单独的⽣成⼀个Map任务,⼩⽂件过多就会导致MapTask任务过多从⽽影响计算的性能。
当时我们团队研究了一下,最后解决了这个问题,我们通过配置Flume的HDFS Sink来解决的:
首先Flume默认是根据event的数量来生成文件的,也就是说有多少个event就会有多少个文件,这样就会产生大量的小文件,每个event的数据大小是不一样的(有的大,有的小)
其次,我们通过查询官网上的解决办法最终找到了几个参数:
解决办法:
**1、rollInterval:**这个参数是配置HDFSSink按照时间来滚动生成一个一个的文件,通过配置这个参数可以解决一段时间内生产的数据,但是有一个问题当时我们设置的是一个小时滚动生成一个文件,通常情况下都是符合预期的但是业务高峰期的时候只配置一个维度就不行了,所以我们还需要结合其他维度的配置才行。
**2、rollSize:**这个参数是配置HDFS Sink按照文件大小来进行滚动生成文件的,我们当时设置的是128M,因为设置128M这个大小主要是对应了HDFS上边的快大小来设置的。HDFS上边每一个数据块的大小128M,所以这样设置是符合HDFS的存储习惯的,后期进行切片处理的时候操作也比较方便的。
** 3、rollCount:**对于这个参数我们当时设置的0,因为HDFSSInk默认是根据event个数来生成文件的,设置为0的意思就是禁用掉的逻辑,是Flume不能按照event个数据来生成文件。

版权归原作者 冷艳无情的小妈 所有, 如有侵权,请联系我们删除。