
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌感兴趣的可以先收藏起来,点赞、关注不迷路✌
毕业设计:2023-2024年计算机毕业设计1000套(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕业设计选题汇总
1、项目介绍
技术栈:
Python语言、Flask框架、selenium爬虫 、sqlite数据库、Echarts可视化大屏 后台数据管理
2、项目界面
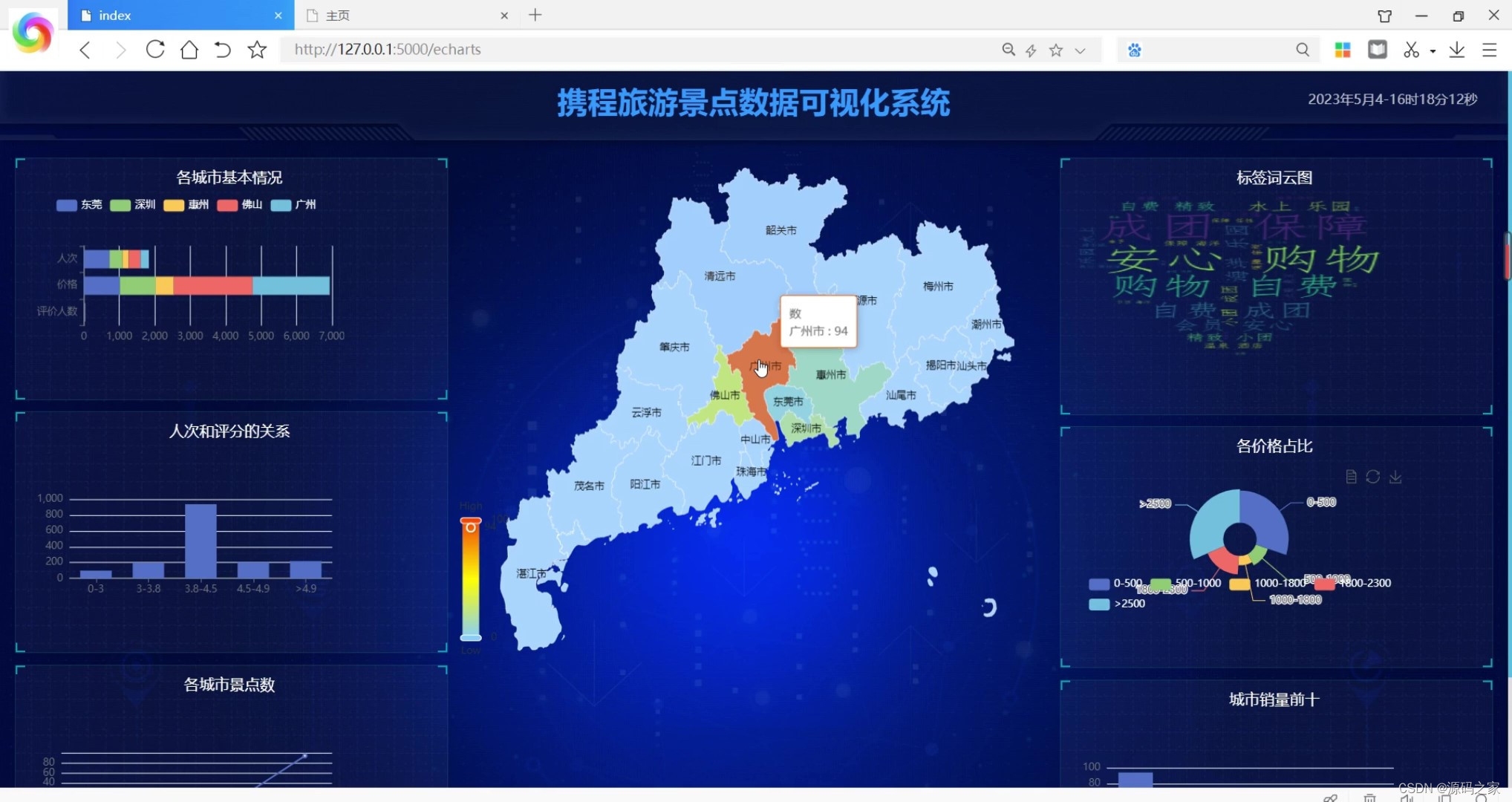
(1)可视化大屏
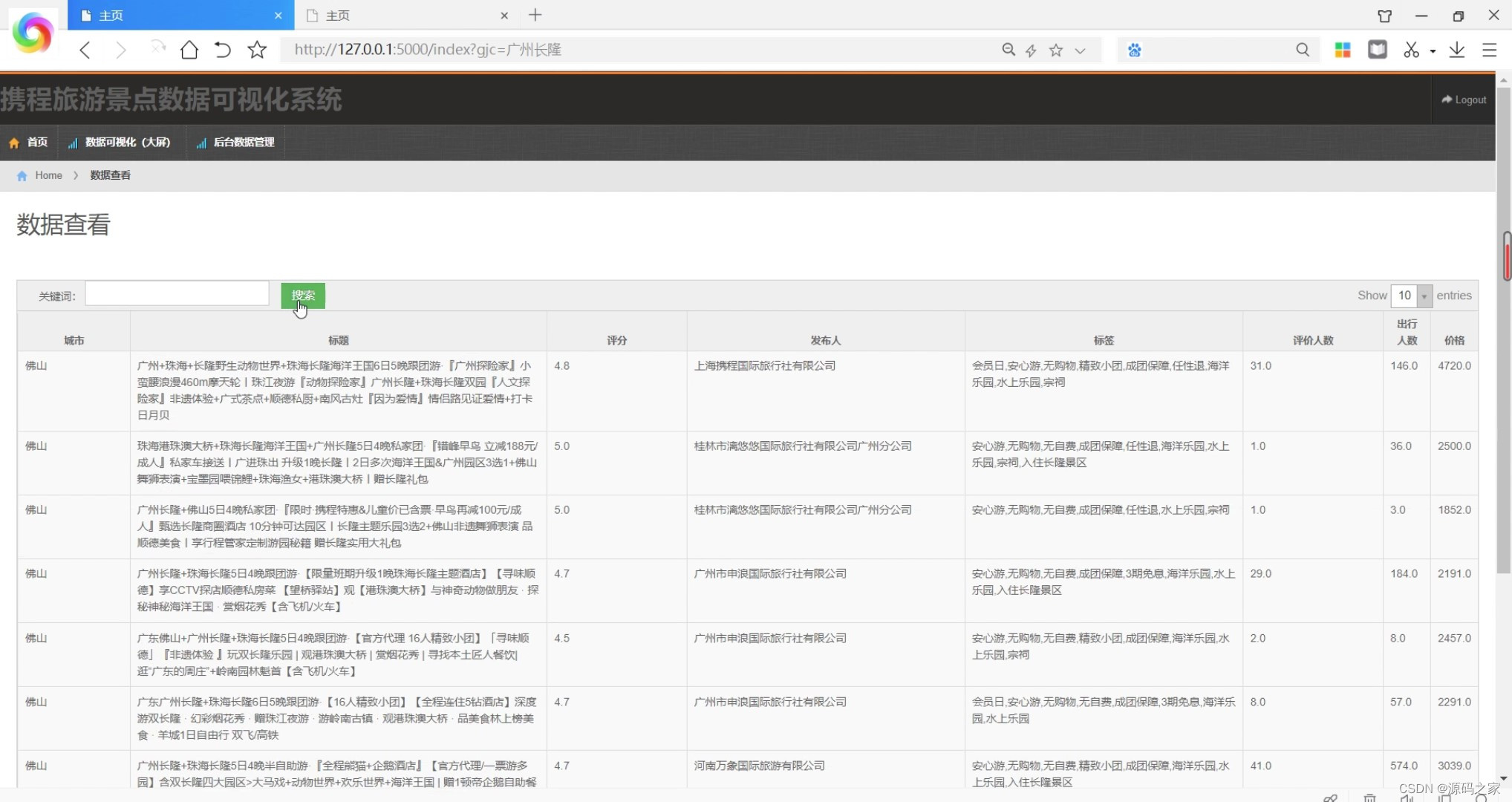
(2)旅游景点数据
(3)数据采集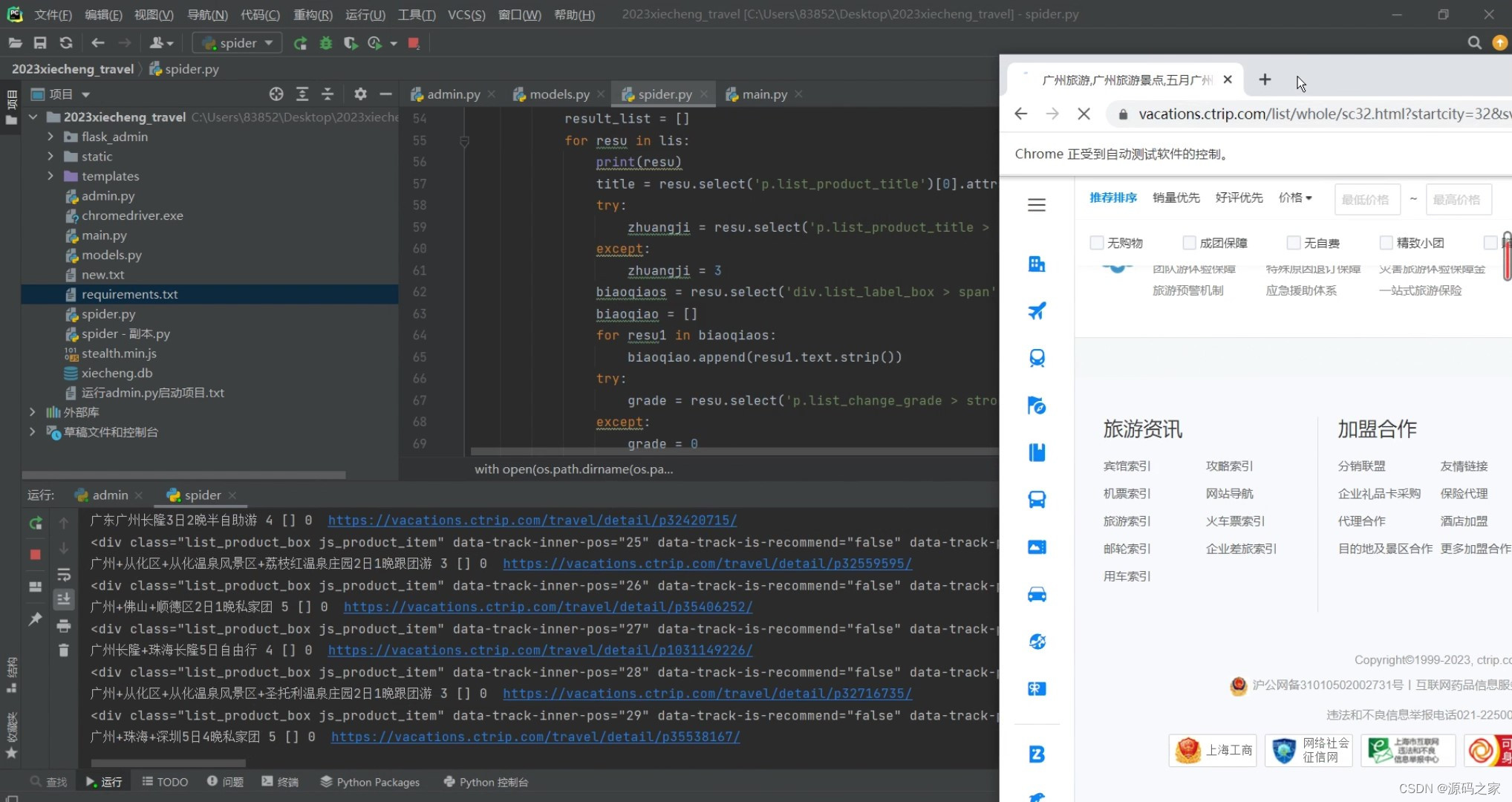
(4)后台数据管理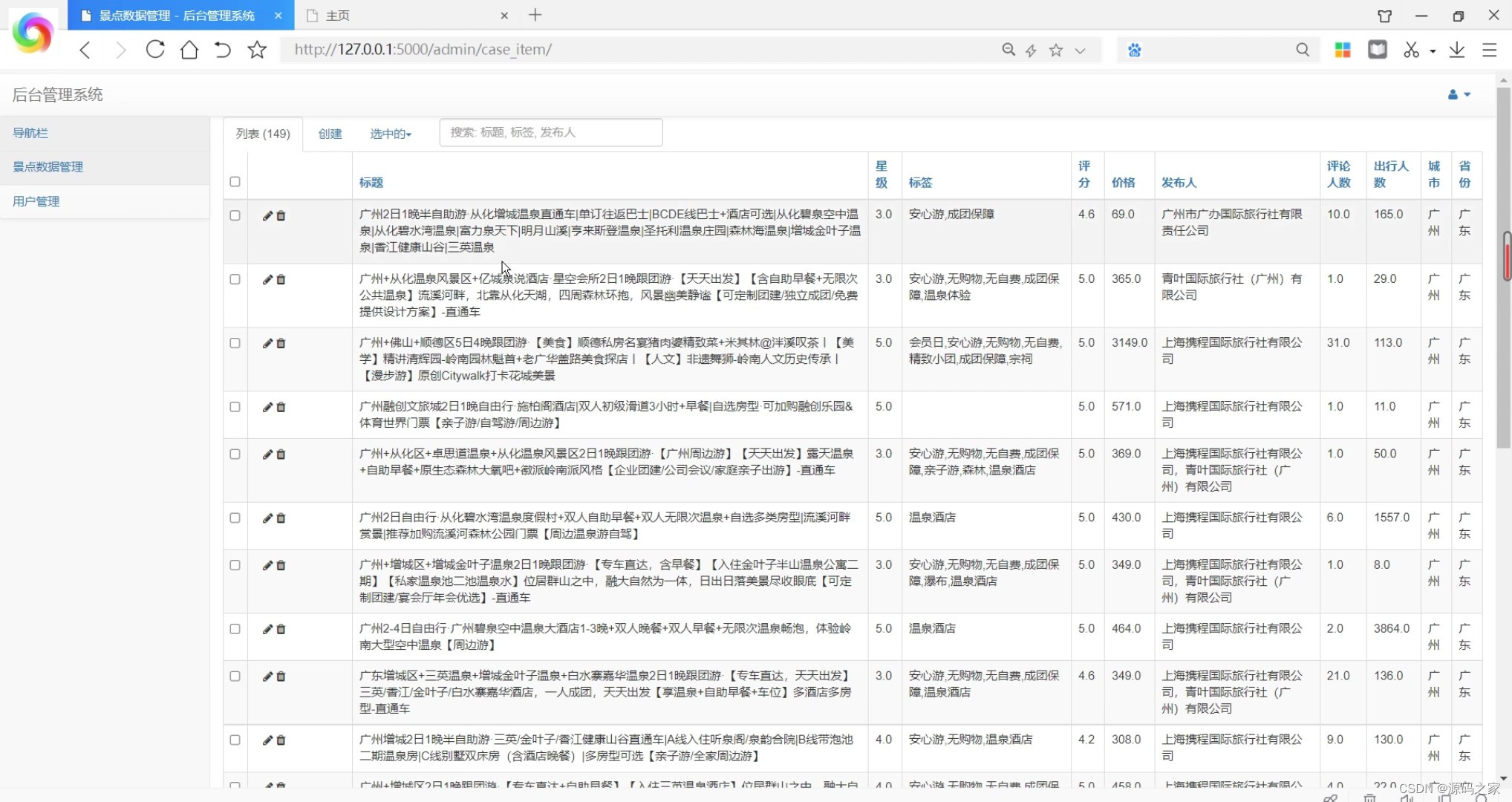
(5)注册登录界面
3、项目说明
携程旅游数据采集分析可视化系统是基于Python语言开发的一套旅游数据处理系统。系统采用Flask框架作为后台开发框架,利用selenium爬虫技术实现对携程网站的数据采集,将采集到的数据存储到sqlite数据库中。
系统主要由三个模块组成:数据采集模块、数据分析模块和可视化大屏展示模块。
数据采集模块使用selenium爬虫技术,模拟浏览器操作,自动登录携程网站,通过搜索和浏览等操作采集所需的旅游数据,然后将数据保存到sqlite数据库中。
数据分析模块对采集到的数据进行处理和分析,包括数据清洗、数据统计、数据挖掘等操作。通过Python的数据分析库,对数据进行处理和挖掘,提取出有用的信息和结论。
可视化大屏展示模块使用Echarts可视化库,将数据分析结果以图表的形式展示在大屏上,方便用户直观地了解旅游数据的情况。用户可以通过大屏上的交互功能,选择不同的数据维度和时间范围,实时查看旅游数据的变化和趋势。
系统还提供后台数据管理功能,管理员可以通过后台管理界面对数据库中的数据进行增删改查操作,方便管理和维护系统的数据。
携程旅游数据采集分析可视化系统可以帮助旅游从业者更好地了解市场需求和竞争情况,为旅游决策提供数据支持和参考。同时,系统的可视化展示功能也方便用户直观地了解旅游数据的情况,提高数据的可理解性和可操作性。
4、核心代码
# -*- coding: UTF-8 -*-import datetime
import time
import traceback
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.wait import WebDriverWait
from bs4 import BeautifulSoup
import os
import re
import models
from sqlalchemy import or_,and_
driver.get('https://vacations.ctrip.com/')for shengfen,_value in dict_item.items():for city,_results in _value.items():for i inrange(1,5):#设置页数
url = _results +str(i)
driver.get(url)
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
html = driver.page_source
soup = BeautifulSoup(html,'html.parser')
lis = soup.select('div.list_product_box.js_product_item')
result_list =[]for resu in lis:print(resu)
title = resu.select('p.list_product_title')[0].attrs.get('title').strip()try:
zhuangji = resu.select('p.list_product_title > img')[0].attrs.get('alt').strip().replace('钻','')except:
zhuangji =3
biaoqiaos = resu.select('div.list_label_box > span')
biaoqiao =[]for resu1 in biaoqiaos:
biaoqiao.append(resu1.text.strip())try:
grade = resu.select('p.list_change_grade > strong')[0].text.strip()except:
grade =0#注释# price = resu.select('div.list_sr_price > strong')[0].text.strip()try:
retail = resu.select('p.list_product_retail')[0].attrs.get('title').strip()except:
retail =''
product_id = resu.attrs.get('data-track-product-id').strip()
url ='https://vacations.ctrip.com/travel/detail/p{}/'.format(product_id)
result_list.append([title,zhuangji,biaoqiao,grade,retail,url])print(title,zhuangji,biaoqiao,grade,retail,url)for resu in result_list:try:
driver.get(resu[-1])
html = driver.page_source
soup = BeautifulSoup(html,'html.parser')
num = soup.select('span.score_s.score_dp')[0].text.strip().replace('条点评','')
renshu = soup.select('div.score_inf > span')[-1].text.strip().replace('人出游','')
pm_rec = soup.select('dd.pm_rec')[0].text.strip()print(num,renshu,pm_rec)ifnot models.Case_item.query.filter(models.Case_item.url == resu[-1]).all():
models.db.session.add(
models.Case_item(
title=resu[0],
zhuanji=resu[1],
biaoqian=','.join(resu[2]),
pingfen=resu[3],
price=resu[4],
fabu=resu[5],
url=resu[6],
pinglun=num,
chuxing=renshu,
jieshao=pm_rec,
city=city,
shengfen=shengfen,))
models.db.session.commit()except:continue
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻
版权归原作者 源码之家 所有, 如有侵权,请联系我们删除。