
八大元素和下拉列表的定位
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
例如:python 自动化----1、元素定位+下拉列表的定位
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
本章节主要介绍八大元素定位和下拉列表的定位,这里我就不介绍环境的安装了,我们直接开始
提示:这里可以添加本文要记录的大概内容:
提示:以下是本篇文章正文内容,下面案例可供参考
一、八大元素定位
1、id
2、name
3、class name
4、tagname
5、link text
6、partial link text
7、xpath
8、css selector
这里简单的总结一下
id、name、class name 、tagname 这个四个根据元素标签和元素数据进行定位
link text、partial link text 这两个根据链接文本进行定位(a标签)
xpath:元素路径的定位
css:css选择器定位(样式定位)
下面我结合代码,进行讲解
我先讲解一下如何再网页中查看元素
1、首先我们打开一个网站,以百度为例
2、选择需要定位元素,鼠标右击,再点击检查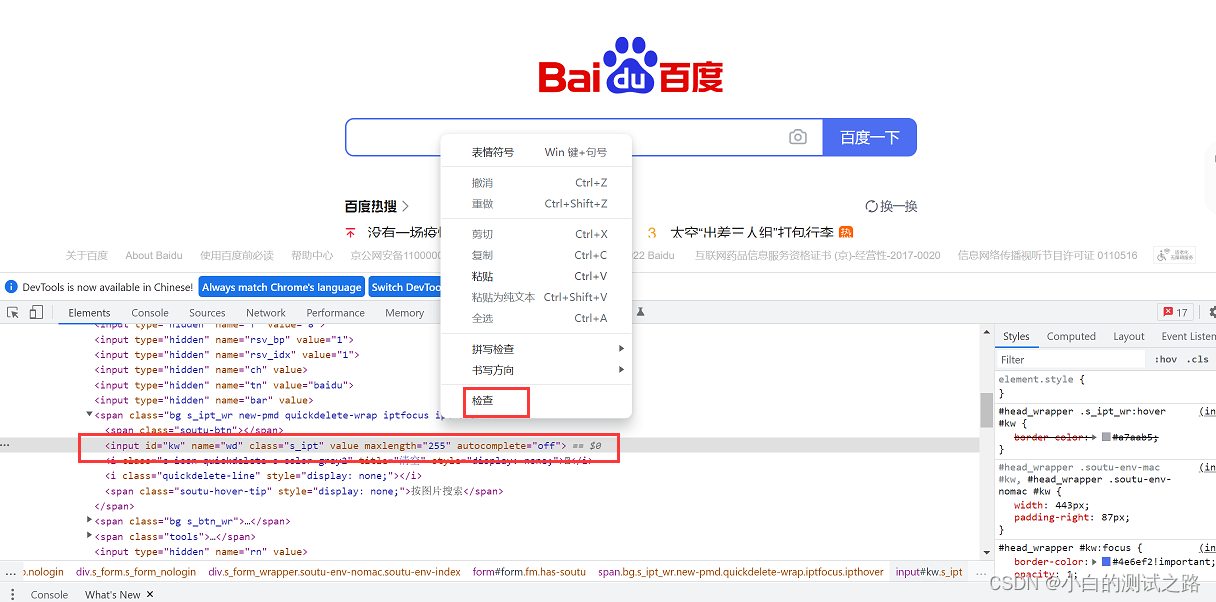
这就这个元素的属性。然后根据他的id值或者classname值进行定位。
还有一种方法就是,按F12 进入,然后如下图进行操作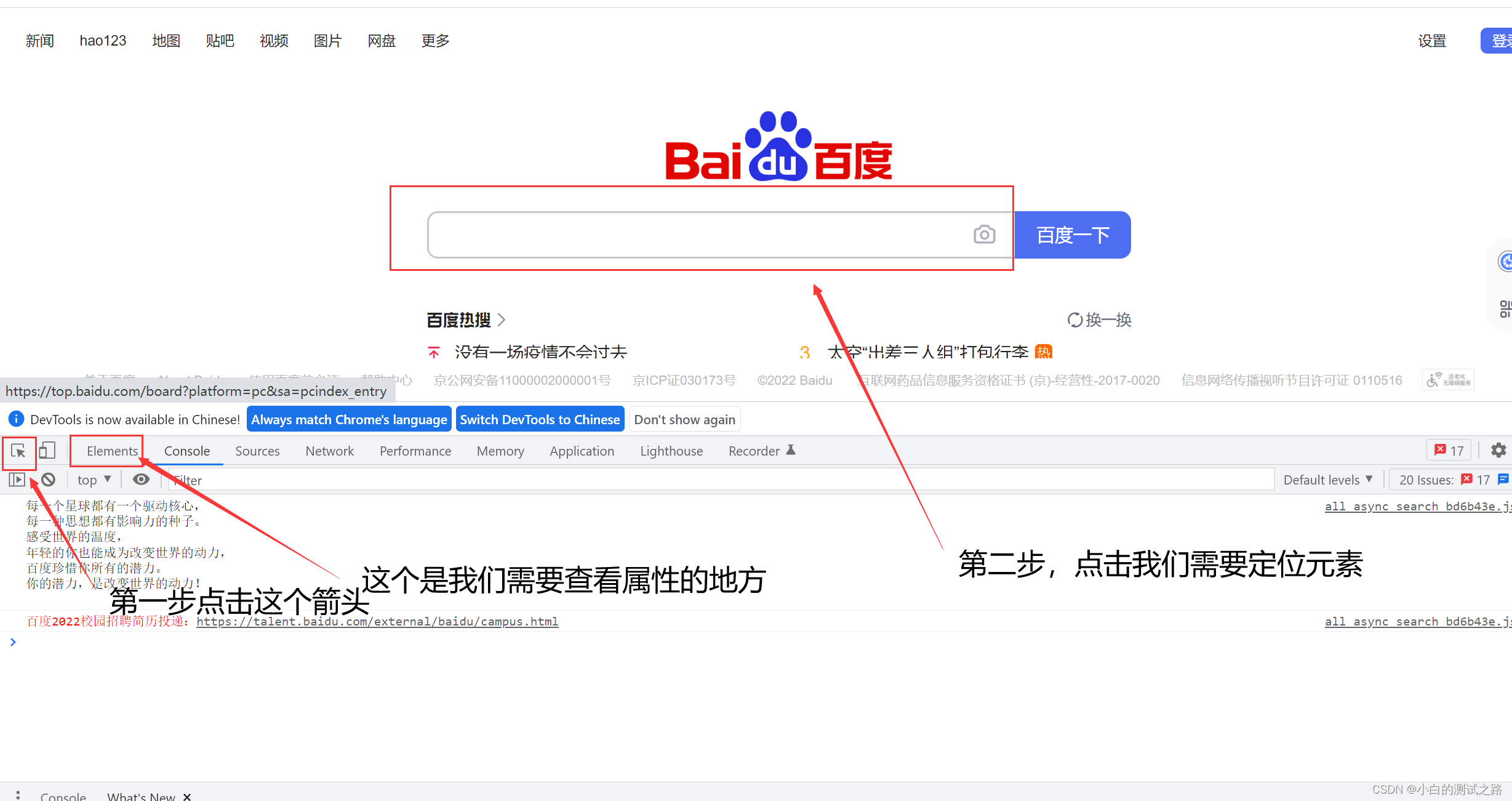
1.环境的安装和注意点
注意点。1、谷歌的版本必须和驱动的版本一致,否则运行就会报错。
谷歌的驱动链接地址我放这里了谷歌驱动下载
有些小伙伴下载驱动的时候,发现只有window32的,没有64的,就不知道盖下载哪一个了。其实直接下载32的就行了,下载好后,放在python安装目录下
如何查看谷歌当前版本,如图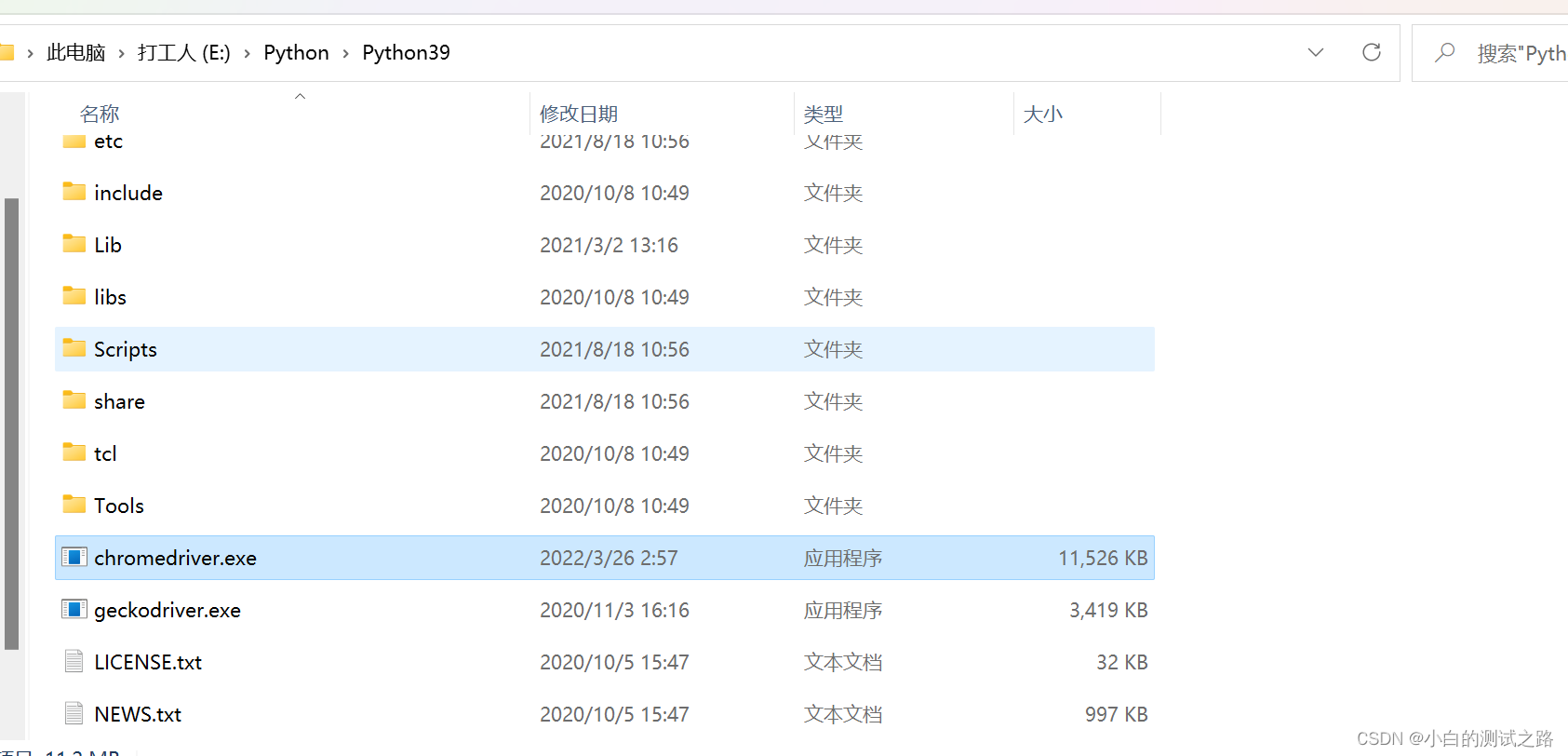
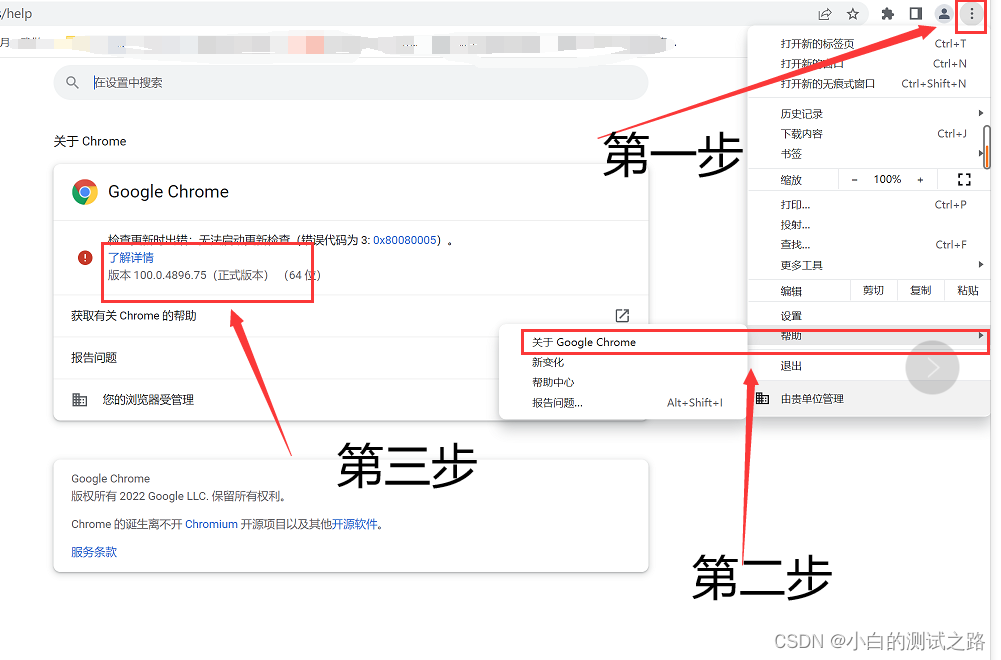
2、建议关闭谷歌自动更。关闭方式可以看这篇博客,
https://blog.csdn.net/weixin_48502426/article/details/122955721
id元素定位
前提有id属性
from selenium import webdriver
# 使用谷歌浏览器,当然也可FireFox和Safari
driver=webdriver.Chrome()
# 打开百度浏览器
driver.get('https:www.baidu.com')
# 定位到百度搜索栏,并输入python
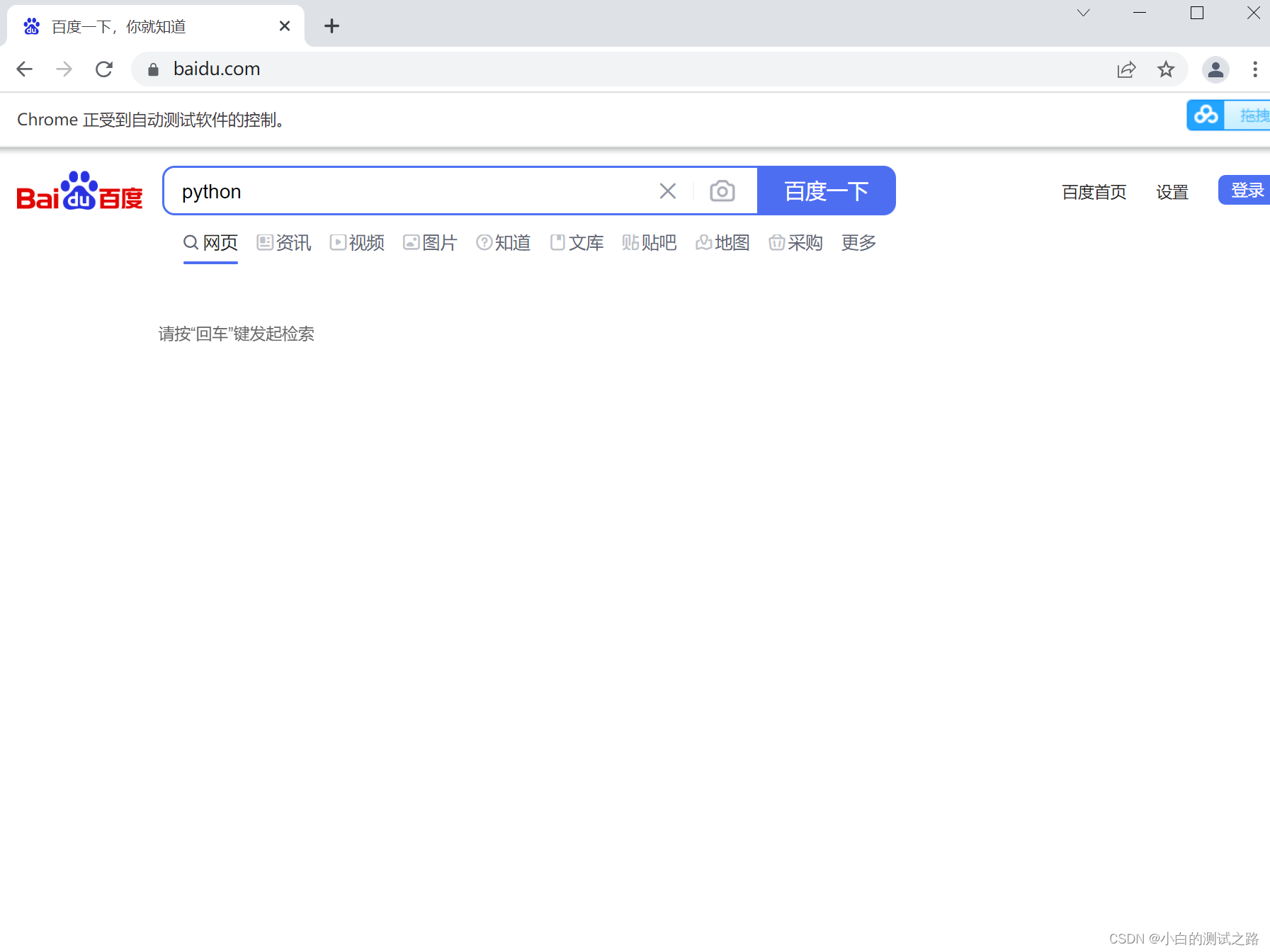
driver.find_element_by_id('kw').send_keys('python')
# 关闭浏览器,运行
driver.close()
如何想看运行效果可以注释,关闭浏览器,这里教大家一个py注释一行的快捷键Ctrl + / 。因为运行块,肉眼难以察觉到。下节我将三种等待时间,小伙伴们可以加入试试效果的。
执行后的效果如图
name元素定位
前提有name属性
from selenium import webdriver
# 使用谷歌浏览器,当然也可FireFox和Safari
driver=webdriver.Chrome()
# 打开百度浏览器
driver.get('https:www.baidu.com')
# 定位到百度搜索栏,并输入python
driver.find_element_by_name('wd').send_keys('python')
# 关闭浏览器,运行
driver.close()
执行结果
classname元素定位
前提有class属性
from selenium import webdriver
# 使用谷歌浏览器,当然也可FireFox和Safari
driver=webdriver.Chrome()
# 打开百度浏览器
driver.get('https:www.baidu.com')
# 定位到百度搜索栏,并输入python
driver.find_element_by_class_name('s_ipt').send_keys('python')
# 关闭浏览器,运行
driver.close()
tagname元素定位
tagname 通过input标签来定位,一般不使用,因为效率毕竟低
定位方式和前三个类似,因为没有找到较好的列子,我这里就不用代码演示了。方式就是find_element_by_tag_name()
link text元素定位
link text 是通过a标签进行定位的
如图中的红框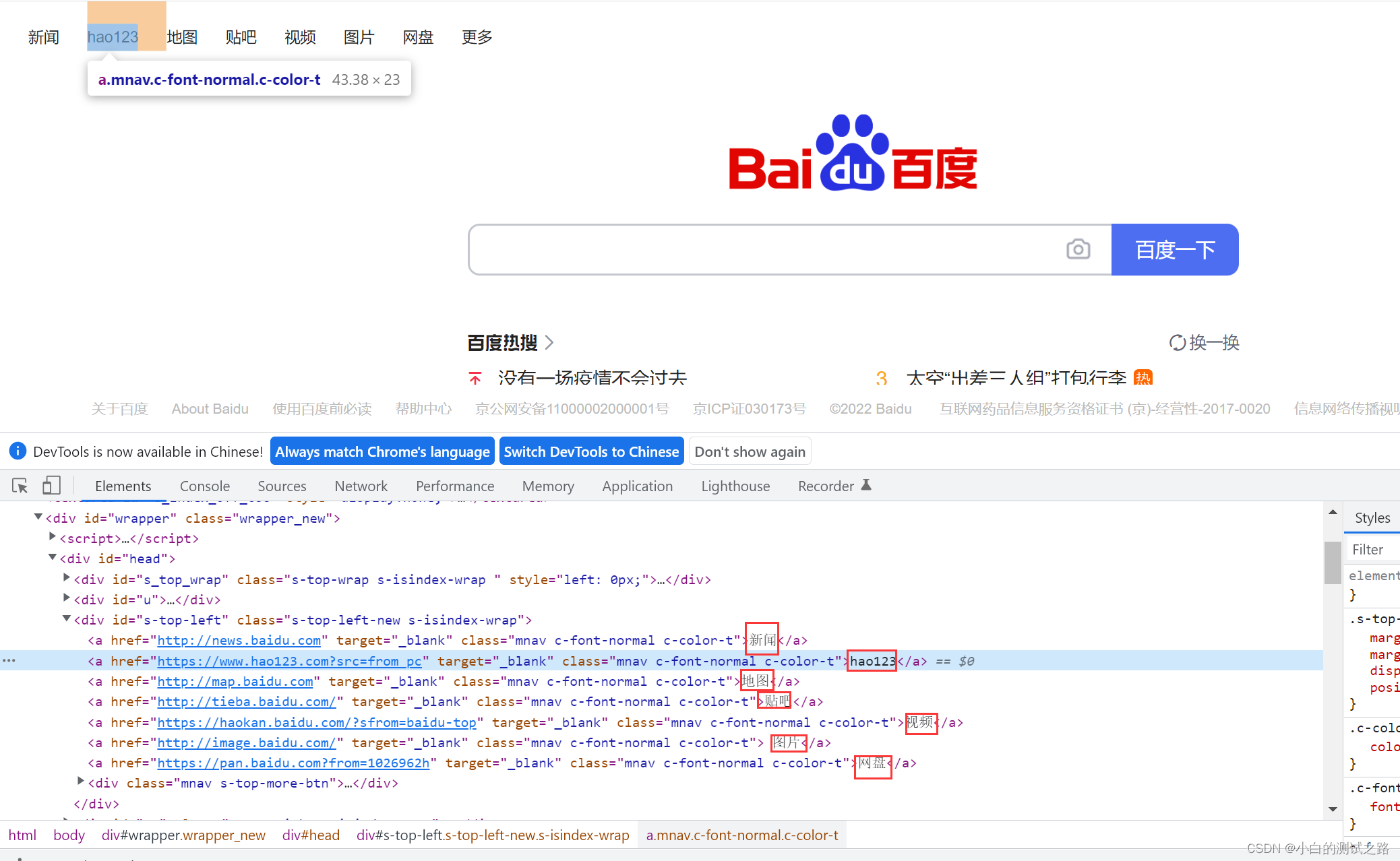
from selenium import webdriver
# 使用谷歌浏览器,当然也可FireFox和Safari
driver=webdriver.Chrome()
# 打开百度浏览器
driver.get('https:www.baidu.com')
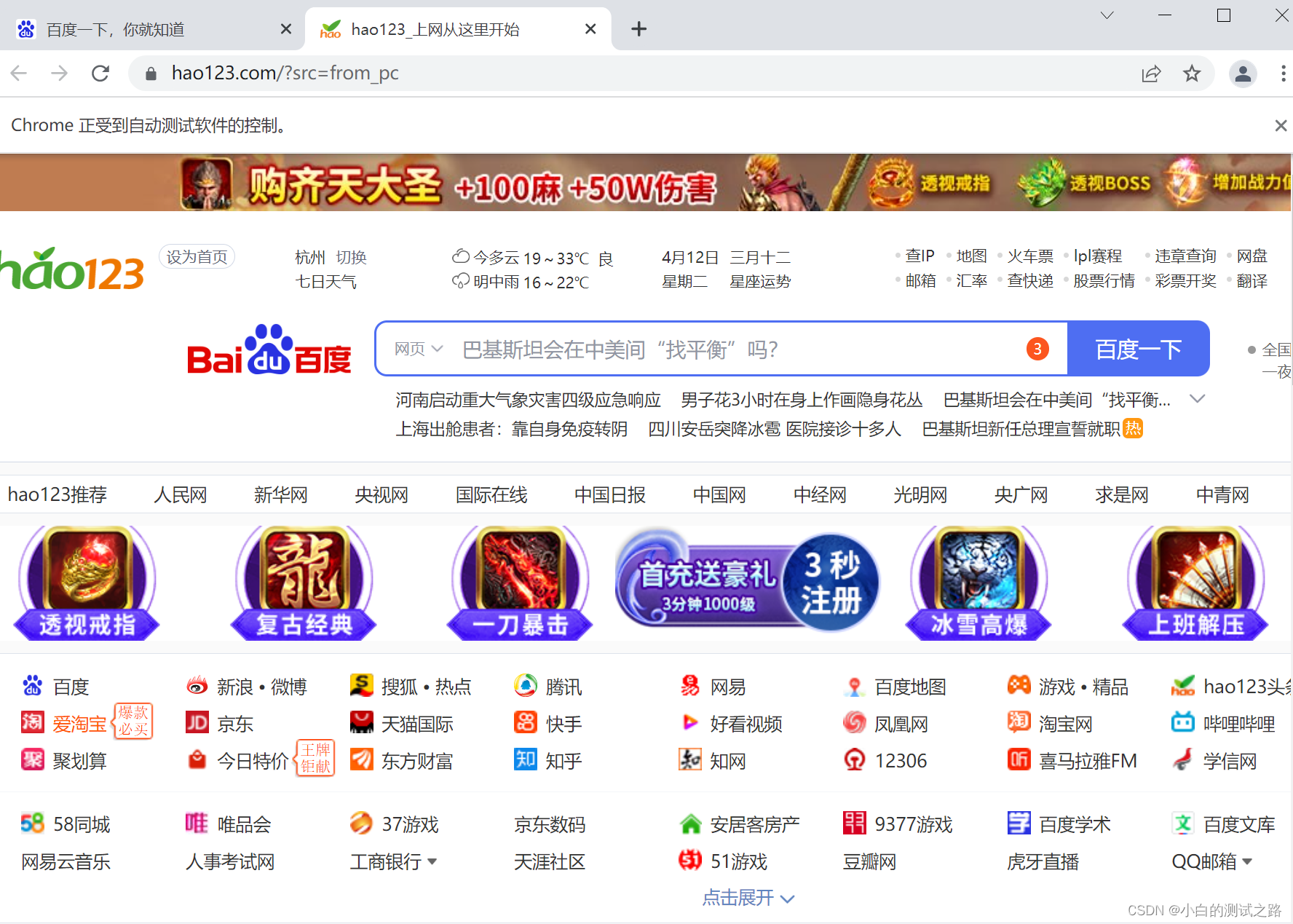
# 定位到hao123 并进行点击
driver.find_element_by_link_text('hao123').click()
# 关闭浏览器,运行
#driver.close()
partial_link_text元素定位
partial_link_text也是通过a标签进行一个模糊的匹配
from selenium import webdriver
# 使用谷歌浏览器,当然也可FireFox和Safari
driver=webdriver.Chrome()
# 打开百度浏览器
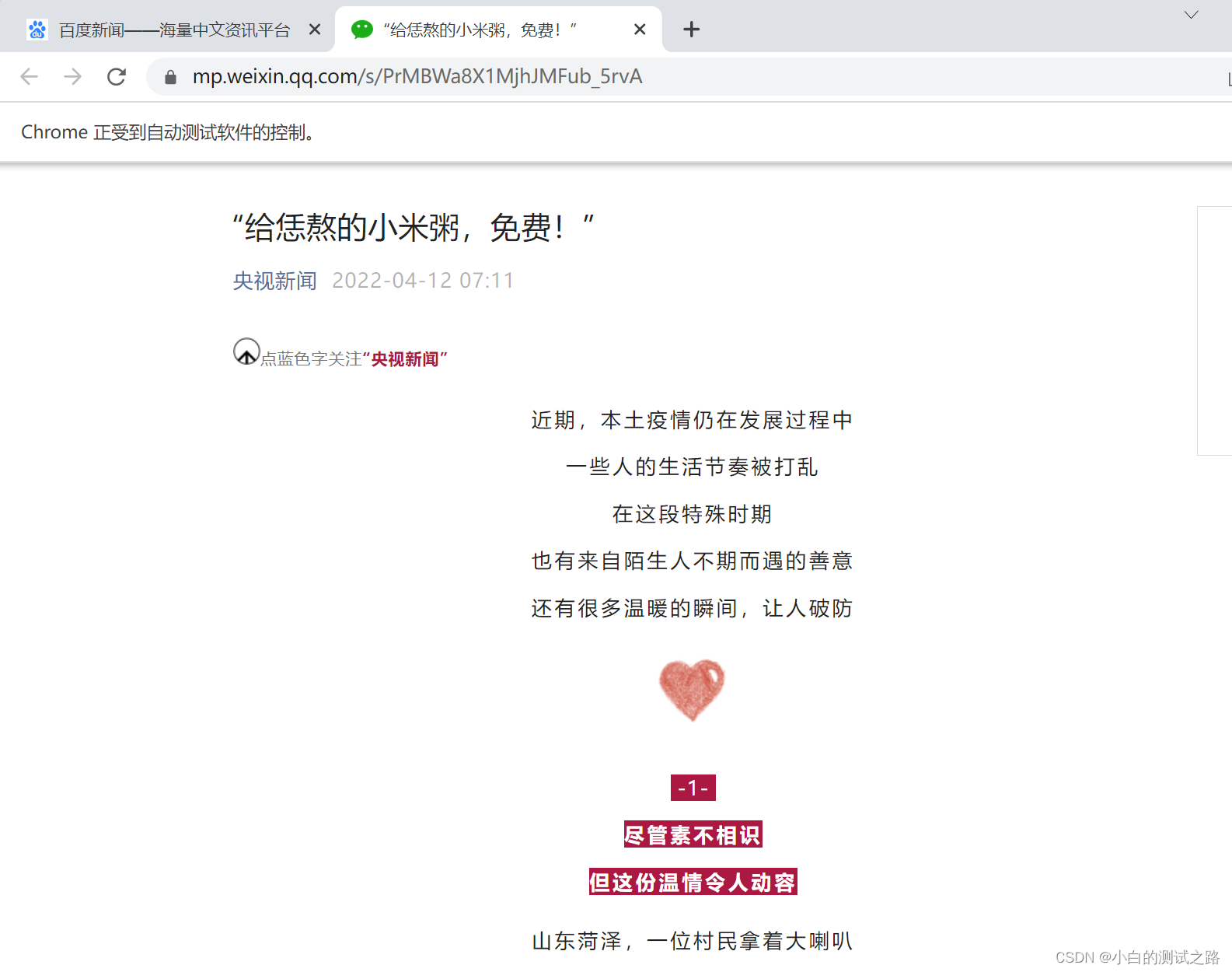
driver.get('https:news.baidu.com')
# 定位到小米粥链接并进行点击
driver.find_element_by_partial_link_text('小米粥').click()
# 关闭浏览器,运行
#driver.close()
xpath定位
xpath定位方式
1、路径定位 绝对路径和相对路径
2、元素属性定位
3、层级与属性定位
4、属性与逻辑定位结合
1、绝对路径的定位,最外层到指定元素之间的所有层级 如/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input
可以鼠标右击,查看定位的元素属性,然后点击copy–full copy XPath
相对路径的定位 从符合的第一个元素开始,如//input[@id=“kw”]
也可以鼠标右击,查看定位的元素属性,然后点击copy-- copy XPath
2、元素属性定位 利用元素的唯一属性值,//*[@id=“kw”] 如下面代码
from selenium import webdriver
# 使用谷歌浏览器,当然也可FireFox和Safari
driver=webdriver.Chrome()
# 打开百度浏览器
driver.get('https:www.baidu.com')
# 定位到编辑框并输入python
# 相对路径
driver.find_element_by_xpath('<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">').send_keys('python')
# 绝对路径
driver.find_element_by_xpath('//input[@id="kw"]').send_keys('python')
# 属性定位
driver.find_element_by_xpath('//*[@id="kw"]').send_keys('python')
# 关闭浏览器,运行
#driver.close()
3、层级定位
找的元素没有唯一值,但父级是唯一值
//*[@id=‘p1’]/input
4、属性与逻辑重合
解决元素之间相同属性重名问题
//*[@id=‘telA’ and @class=‘telA’]
CSS定位
css定位方式比xpath速度更快,建议平常使用css定位方式,之前一个面试官就有问道我,八大元素中你一般用什么方式定位,为什么。
定位方式
1、id选择器
2、class选择器
3、元素选择器
4、属性选择器
5、层级选择器
id选择器 格式:#id属性值
class选择器 格式:.class属性值
元素选择器 格式:input(选择所有input元素)
属性选择器 格式:如[name=‘name’]不推荐在属性中用id或者class
层级选择器 格式:element>element 如:p>input(返还所有p元素下所有的input元素) 其中 > 可以用空格替代
from selenium import webdriver
# 使用谷歌浏览器,当然也可FireFox和Safari
driver=webdriver.Chrome()
# 打开百度浏览器
driver.get('https:www.baidu.com')
# 定位到编辑框并输入python
# 通过id定位
driver.find_element_by_css_selector('#kw').send_keys('python')
# 通过class定位
driver.find_element_by_css_selector('.s_ipt').send_keys('python')
# 通过属性定位
driver.find_element_by_css_selector('name="wd"').send_keys('python')
# 关闭浏览器,运行
#driver.close()
元素组定位方式
find_elements_by_xxx 和单个不同的是element多了个s
1、定位到后查找所有符合的函数
2、返还的定位元素为列表形式
3、如果未定位到元素,会返回为空值
By的定位方式
导包
from selenium.webdriver.comm.by import By
这个教小伙伴一个快速导包的办法,可以输入
find_element(By.ID,‘userA’) 点击By.ID,然后按alt+enter
需要两个参数,一个定位类型一个是定位具体方式
二、下拉列表定位
1.Select+OPtion和ul+li
代码如下(示例):
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
2.、下拉列表的定位
先介绍Select的方法
import time
from selenium import webdriver
from selenium.webdriver.support.ui import Select
# 使用谷歌浏览器,当然也可FireFox和Safari
from selenium.webdriver.common.by import By
driver=webdriver.Chrome()
# 打开12306
driver.get('https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc&fs=%E5%8E%A6%E9%97%A8,XMS&ts=%E5%8D%97%E6%98%8C,NCG&date=2022-04-12&flag=N,N,Y')
#定位到下拉框
els=driver.find_element_by_css_selector('#cc_start_time')
# 三种方式选择下拉属性
# 方式一
Select(els).select_by_value('00000600')#使用select中的方法定位value的值
#time.sleep(2) 等待两秒
# 方式二
Select(els).select_by_index(4)#定位元素所在的位置
time.sleep(2)
# 方式三
Select(els).select_by_visible_text('06:00--12:00') #定位元素的文本值
time.sleep(2)
# 关闭浏览器,运行
driver.close()
这里我结合图片来和小伙伴解释一下value 、index、visible_text这三个值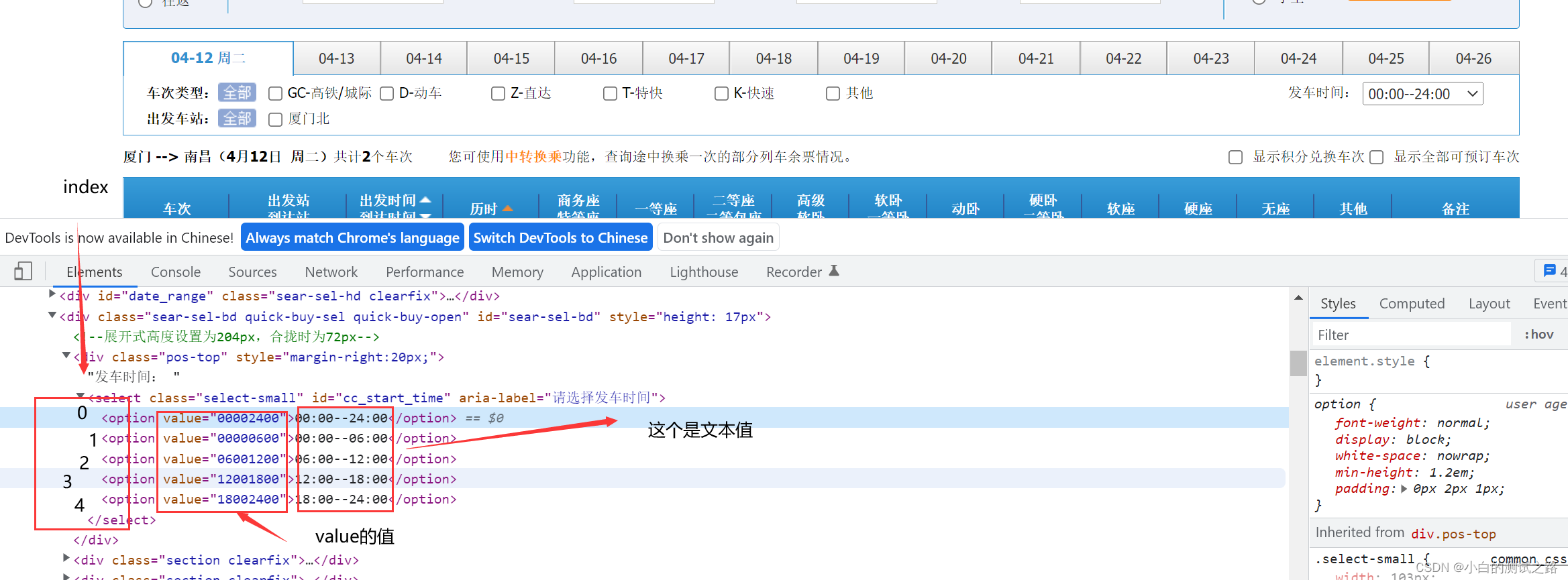
大家运行代码可以观看右上角的时间变化,
2、ul+li 定位方式
- 先定位到ul,并且将定位到的值赋给变量a a=driver.find_element_by_id(“ul的id”)
- 再用变量a去找到li a.find_element_by_id(“li的id”).click()
总结
提示:这里对文章进行总结:
这个文章主要讲解了八个定位元素和元素组定位的介绍。中间也有一点知识点的补充,下篇文章我会介绍自动化中的三种时间等待,强制等待,隐性等待和强制等待。在下拉框定位中我就使用到了强制等待,大家可以执行一下程序看一下效果。欢迎各位留言、点赞。
版权归原作者 小白的测试之路 所有, 如有侵权,请联系我们删除。