
作者:周克勇,花名一锤,阿里巴巴计算平台事业部EMR团队技术专家,大数据领域技术爱好者,对Spark有浓厚兴趣和一定的了解,目前主要专注于EMR产品中开源计算引擎的优化工作。
背景和动机
SparkSQL多年来的性能优化集中在Optimizer和Runtime两个领域。前者的目的是为了获得最优的执行计划,后者的目的是针对既定的计划尽可能执行的更快。
相比于Runtime,Optimizer是更加通用的、跟实现无关的优化。无论是Java世界(Spark, Hive)还是C++世界(Impala, MaxCompute),无论是Batch-Based(Spark, Hive)还是MPP-Based(Impala, Presto),甚至无论是大数据领域还是传统数据库领域亦或HTAP领域(HyPer, ADB),在Optimizer层面考虑的都是非常类似的问题: Stats收集,Cost评估以及计划选择;采用的优化技术也比较类似,如JoinReorder, CTE, GroupKey Elimination等。尽管因为上下文不同(如是否有索引)在Cost Model的构造上会有不同,或者特定场景下采用不同的空间搜索策略(如遗传算法 vs. 动态规划),但方法大体是相同的。
长期以来,Runtime的优化工作基本聚焦在解决当时的硬件瓶颈。如MapReduce刚出来时网络带宽是瓶颈,所以Google做了很多Locality方面的优化;Spark刚出来时解决的问题是磁盘IO,内存缓存的设计使得性能相比MapReduce有了数量级的提升;后来CPU成为了新的瓶颈[1],因此提升CPU性能成了近年来Runtime领域重要的优化方向。
提升CPU性能的两个主流技术是以MonetDB/X1002为代表的向量化(Vectorized Processing)技术和以HyPer[5][6]为代表的代码生成(CodeGen)技术(其中Spark跟进的是CodeGen[9])。简单来说,向量化技术沿用了火山模型,但与其让SQL算子每次计算一条Record,向量化技术会积攒一批数据后再执行。逐批计算相比于逐条计算有了更大的优化空间,例如虚函数的开销分摊,SIMD优化,更加Cache友好等。这个技术的劣势在于算子之间传递的数据从条变成了批,因此增大了中间数据的物化开销。CodeGen技术从另外一个角度解决虚函数开销和中间数据物化问题:算子融合。简单来说,CodeGen框架通过打破算子之间的界限把火山模型“压平”了,把原来迭代器链压缩成了大的for循环,同时生成语义相同的代码(Java/C++/LLVM),紧接着用对应的工具链编译生成的代码,最后用编译后的class(Java)或so(C++,LLVM)去执行,从而把解释执行转变成了编译执行。此外,尽管还是逐条执行,由于抹去了函数调用,一条Record从(Stage内的)初始算子一直执行到结束算子都基本处于寄存器中,不会物化到内存。CodeGen技术的劣势在于难以应用SIMD等优化。
两个门派相爱相杀,在经历了互相发论文验证自家优于对方后[4][8]两家走向了合作,合作产出了一系列项目和论文,而目前学界的主流看法也是两者融合是最优解,一些采用融合做法的项目也应运而生,如进化版HyPer[6], Pelonton[7]等。
尽管学界已走到了融合,业界主流却没有很强的动力往融合的路子走,探究其主要原因一是目前融合的做法相比单独的优化并没有质的提升;二是融合技术目前没有一个广为接受的最优做法,还在探索阶段;三是业界在单一的技术上还没有发挥出最大潜力。以SparkSQL为例,从2015年SparkSQL首次露面自带的Expression级别的Codegen,到后来参考HyPer实现的WholeStage Codegen,再经过多年的打磨,SparkSQL的Codegen技术已趋成熟,性能也获得了两次数量级的跃升。然而,也许是出于可维护性或开发者接受度的考虑,SparkSQL的Codegen一直限制在生成Java代码,并没有尝试过NativeCode(C/C++, LLVM)。尽管Java的性能已经很优,但相比于Native Code还是有一定的Overhead,并缺乏SIMD(Java在做这方面feature),Prefetch等语义,更重要的是,Native Code直接操作裸金属,易于极致压榨硬件性能,对一些加速器(如GPU)或新硬件(如AEP)的支持也更方便。
基于以上动机,EMR团队探索并开发了SparkSQL Native Codegen框架,为SparkSQL换了引擎,新引擎带来20%左右的性能提升,为EMR再次获取世界第一立下汗马功劳,本文将详细介绍Native Codegen框架。
核心问题
做Native Codegen,核心问题有三个:
1.生成什么?
2.怎么生成?
3.如何集成到Spark?
生成什么
针对生成什么代码,结合调研的结果以及开发同学的技术栈,有三个候选项:C/C++, LLVM, Weld IR。C/C++的优势是实现相对简单,只需对照Spark生成的Java代码逻辑改写即可,劣势是编译时间过长,下图是HyPer的测评数据,C++的编译时间比LLVM高了一个数量级。

编译时间过长对小query很不友好,极端case编译时间比运行时间还要长。基于这个考虑,我们排除了C/C++选项。上图看上去LLVM的编译时间非常友好,而且很多Native CodeGen的引擎,如HyPer, Impala, 以及阿里云自研大数据引擎MaxCompute,ADB等,均采用了LLVM作为目标代码。LLVM对我们来说(对你们则不一定:D)最大的劣势就是过于底层,语法接近于汇编,试想用汇编重写SparkSQL算子的工作量会有多酸爽。大多数引擎也不会用LLVM写全量代码,如HyPer仅把算子核心逻辑用LLVM生成,其他通用功能(如spill,复杂数据结构管理等)用C++编写并提前编译好。即使LLVM+C++节省了不少工作量,对我们来说依然不可接受,因此我们把目光转向了第三个选项: Weld IR(Intermediate Representation)。
首先简短介绍以下Weld。Weld的作者Shoumik Palkar是 Matei Zaharia的学生,后者大家一定很熟悉,Spark的作者。Weld最初想解决的问题是不同lib之间互相调用时数据传输的开销,例如要在pandas里调用numpy的接口,首先pandas把数据写入内存,然后numpy读取内存进行计算,对于极度优化的lib来说,内存的写入和读取的时间可能会远超计算本身。针对这个问题,Weld开发了Common Runtime并配套提供了一组IR,再加上惰性求值的特性,只需(简单)修改lib使其符合Weld的规范,便可以做到不同lib共用Weld Runtime,Weld Runtime利用惰性求值实现跨lib的Pipeline,从而省去数据物化的开销。Weld Runtime还做了若干优化,如循环融合,循环展开,向量化,自适应执行等。此外,Weld支持调用C代码,可以方便调用三方库。
我们感兴趣的是Weld提供的IR和对应的Runtime。Weld IR面向数据分析进行设计,因此语义上跟SQL非常接近,能较好的表达算子。数据结构层面,Weld IR最核心的数据结构是vec和struct,能较好地表达SparkSQL的UnsafeRow Batch;基于struct和vec可以构造dict,能较好的表达SQL里重度使用的Hash结构。操作层面,Weld IR提供了类函数式语言的语义,如map, filter, iterator等,配合builder语义,能方便的表达Project, Filter, Agg, BroadCastJoin等算子语义。例如,以下IR表达了Filter + Project语义,具体含义是若第二列大于10,则返回第一列:
|v: vec[{i32,i32}]| for(v,appender,|b,i,n| if(n.$1 > 10, merge(b,n.$0), b))
以下IR表达了groupBy的语义,具体含义是按照第一列做groupBy来计算第二列的sum:
|v: vec[{i32,i32}]| for(v,dictmerger[i32,i32,+],|b,i,n| merge(b,{n.$0,n.$1}))
具体的语法定义请参考Weld文档(https://github.com/weld-project/weld/blob/master/docs/language.md)。
Weld 开发者API提供了两个核型接口:
- weld_module_compile, 把Weld IR编译成可执行模块(module)。
- weld_module_run, 执行编译好的模块。
基本流程如下图所示,最终也是生成LLVM代码。

由此,Weld IR的优势就显然易见了,既兼顾了性能(最终生成LLVM代码),又兼顾了易用性(CodeGen Weld IR相比LLVM, C++方便很多)。基于这些考虑,我们最终选择Weld IR作为目标代码。
怎么生成
SparkSQL原有的CodeGen框架之前简单介绍过了,详见https://developer.aliyun.com/article/727277。我们参考了Spark原有的做法,支持了表达式级别,算子级别,以及WholeStage级别的Codegen。复用Producer-Consumer框架,每个算子负责生成自己的代码,最后由WholeStageCodeGenExec负责组装。
这个过程有两个关键问题:
1.算子之间传输的介质是什么?
2.如何处理Weld不支持的算子?
传输介质
不同于Java,Weld IR不提供循环结构,取而代之的是vec结构和其上的泛迭代器操作,因此Weld IR难以借鉴Java Codegen在Stage外层套个大循环,然后每个算子处理一条Record的模式,取而代之的做法是每个算子处理一批数据,IR层面做假物化,然后依赖Weld的Loop-Fusion优化去消除物化。例如前面提到的Filter后接Project,Filter算子生成的IR如下,过滤掉第二列<=10的数据:
|v:vec[{i32,i32}]| let res_fil = for(v,appender,|b,i,n| if(n.$1>10, merge(b,n), b)
Project算子生成的IR如下,返回第一列数据:
let res_proj = for(res_fil,appender,|b,i,n| merge(b,n.$0))
表面上看上去Filter算子会把中间结果做物化,实际上Weld的Loop-Fusion优化器会消除此次物化,优化后代码如下:
|v: vec[{i32,i32}]| for(v,appender,|b,i,n| if(n.$1 > 10, merge(b,n.$0), b))
尽管依赖Weld的Loop-Fusion优化可以极大简化CodeGen的逻辑,但开发中我们发现Loop-Fusion过程非常耗时,对于复杂SQL(嵌套3层以上)甚至无法在有限时间给出结果。当时面临两个选择:修改Weld的实现,或者修改CodeGen直接生成Loop-Fusion之后的代码,我们选择了后者。重构后生成的代码如下,其中1,2,11行由Scan算子生成,3,4,5,6,8,9,10行由Filter算子生成,7行由Project算子生成。
|v: vec[{i32,i32}]|
for(v,appender,|b,i,n|
if(
n.$1 > 10,
merge(
b,
n.$0
),
b
)
)
这个优化使得编译时间重回亚秒级别。
Fallback机制
受限于Weld当前的表达能力,一些算子无法用Weld实现,例如SortMergeJoin,Rollup等。即使是原版的Java CodeGen,一些算子如Outter Join也不支持CodeGen,因此如何做好Fallback是保证正确性的前提。我们采用的策略很直观:若当前算子不支持Native CodeGen,则由Java CodeGen接管。这里涉及的关键问题是Fallback的粒度:是算子级别还是Stage级别?
抛去实现难度不谈,虽然直观上算子粒度的Fallback更加合理,但实际上却会导致更严重的问题:Stage内部Pipeline的断裂。如上文所述,CodeGen的一个优势是把整个Stage的逻辑Pipeline化,打破算子之间的界限,单条Record从初始算子执行到结束算子,整个过程不存在物化。而算子粒度的Fallback则会导致Stage内部一部分走Native Runtime,另一部分走Java Runtime,则两者连接处无可避免存在中间数据物化,这个开销通常会大于Native Runtime带来的收益。
基于以上考虑,我们选择了Stage级别的Fallback,在CodeGen阶段一旦遇到不支持的算子,则整个Stage都Fallback到Java CodeGen。统计显示,整个TPCDS Benchmark,命中Native CodeGen的Stage达到80%。
Spark集成
完成了代码生成和Fallback机制,最后的问题就是如何跟Spark集成了。Spark的WholeStageCodegenExec的执行可以理解为一个黑盒,无论上游是Table Scan,Shuffle Read,还是BroadCast,给到黑盒的输入类型只有两种: RowBatch(上游是Table Scan)或Row Iterator(上游非Table Scan),而黑盒的输出固定为Row Iterator,如下图所示:
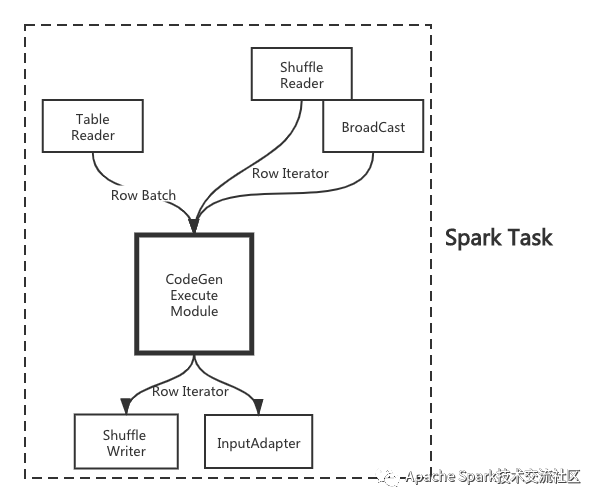
上文介绍我们选择了Stage级别的Fallback,也就决定了黑盒要么是Java Runtime,要么是Native Runtime,不存在混合的情况,因此我们只需要关心如何把Row Batch/Row Iterator转化为Weld认识的内存布局,以及如何把Weld的输出转化成Row Iterator即可。为了进一步简化问题,我们注意到,尽管Shuffle Reader/BroadCast的输入是Row Iterator,但本质上远端序列化的数据结构是Row Batch,只不过Spark反序列化后转换成Row Iterator后再喂给CodeGen Module,RowBatch包装成Row Iterator非常简易。因此Native Runtime的输入输出可以统一成RowBatch。
解决办法呼之欲出了:把RowBatch转换成Weld vec!但我们更进了一步,何不直接把Row Batch喂给Weld从而省去内存转换呢?本质上Row Batch也是满足某种规范的字节流而已,Spark也提供了OffHeap模式把内存直接存堆外(仅针对Scan Stage。Shuffle数据和Broadcast数据需要读到堆外),Weld可以直接访问。Spark UnsafeRow的内存布局大致如下:
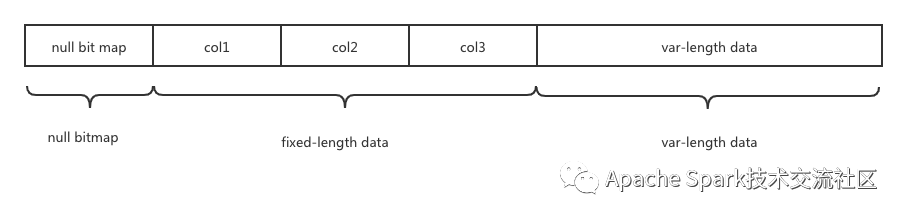
针对确定的schema,null bitmap和fixed-length data的结构是固定的,可以映射成struct,而针对var-length data我们的做法是把这些数据copy到连续的内存地址中。如此一来,针对无变长数据的RowBatch,我们直接把内存块喂给Weld;针对有变长部分的数据,我们也只需做大粒度的内存拷贝(把定长部分和变长部分分别拷出来),而无需做列级别的细粒度拷贝转换。
继续举前文的Filter+Project的例子,一条Record包含两个int列,其UnsafeRow的内存布局如下(为了对齐,Spark里定长部分最少使用8字节)。
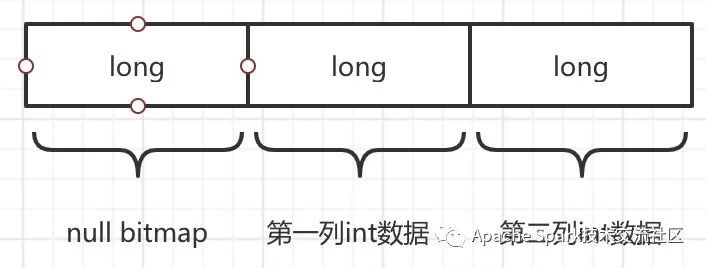
显而易见,这个结构可以很方便映射成Weld struct:
{i64,i64,i64}
而整个Row Batch便映射成Weld vec:
vec[{i64,i64,i64}]
如此便解决了Input的问题。而Weld Output转RowBatch本质是以上过程的逆向操作,不再赘述。
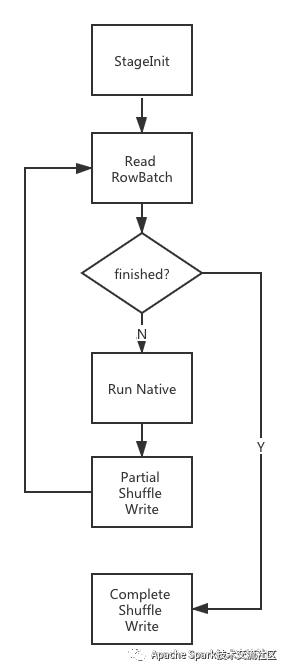
解决了Java和Native之间的数据转换问题,剩下的就是如何执行了。首先我们根据当前Stage的Mode来决定走Java Runtime还是Native Runtime。在Native分支,首先会执行StageInit做Stage级别的初始化工作,包括初始化Weld,加载编译好的Weld Module,拉取Broadcast数据(若有)等;接着是一个循环,每个循环读取一个RowBatch(来自Scan或Shuffle Reader)喂给Native Runtime执行,Output转换并喂给Shuffle Writer。如下图所示:
总结
本文介绍了EMR团队在Spark Native Codegen方向的探索实践,限于篇幅若干技术点和优化没有展开,后续可另开文详解,例如:
1.极致Native算子优化
2.数据转换详解
3.Weld Dict优化
大家感兴趣的任何内容欢迎沟通: )
[1] Making Sense of Performance in Data Analytics Frameworks. Kay Ousterhout
[2] MonetDB/X100: Hyper-Pipelining Query Execution. Peter Boncz
[3] Vectorwise: a Vectorized Analytical DBMS. Marcin Zukowski
[4] Efficiently Compiling Efficient Query Plans for Modern Hardware. Thomas Neumann
[5] HyPer: A Hybrid OLTP&OLAP Main Memory Database System Based on Virtual Memory Snapshots. Alfons Kemper
[6] Data Blocks: Hybrid OLTP and OLAP on Compressed Storage using both Vectorization and Compilation. Harald Lang
[7] Relaxed Operator Fusion for In-Memory Databases: Making Compilation, Vectorization, and Prefetching Work Together At Last. Prashanth Menon
[8] Vectorization vs. Compilation in Query Execution. Juliusz Sompolski
[9] https://databricks.com/blog/2016/05/23/apache-spark-as-a-compiler-joining-a-billion-rows-per-second-on-a-laptop.html
查看更多内容,欢迎访问天池技术圈官方地址:EMR Spark-SQL性能极致优化揭秘 Native Codegen Framework_天池技术圈-阿里云天池
版权归原作者 阿里云天池 所有, 如有侵权,请联系我们删除。