
文章目录
基于Flink 1.14.4
源码
入口
publicstatic<T>SinkFunction<T>sink(String sql,JdbcStatementBuilder<T> statementBuilder,JdbcExecutionOptions executionOptions,JdbcConnectionOptions connectionOptions){returnnewGenericJdbcSinkFunction<>(newJdbcOutputFormat<>(// 批量写出处理类newSimpleJdbcConnectionProvider(connectionOptions),// JdbcConnectionOptions
executionOptions,// 执行参数 重试次数、批次大小、最大等待时间
context ->JdbcBatchStatementExecutor.simple(sql, statementBuilder,Function.identity()),JdbcOutputFormat.RecordExtractor.identity()));}
● GenericJdbcSinkFunction
publicclassGenericJdbcSinkFunction<T>extendsRichSinkFunction<T>implementsCheckpointedFunction,InputTypeConfigurable{privatefinalJdbcOutputFormat<T,?,?> outputFormat;@Overridepublicvoidopen(Configuration parameters)throwsException{super.open(parameters);RuntimeContext ctx =getRuntimeContext();
outputFormat.setRuntimeContext(ctx);// 1.调用 JdbcOutputFormat#open
outputFormat.open(ctx.getIndexOfThisSubtask(), ctx.getNumberOfParallelSubtasks());}// 数据每来一条处理处理一条@Overridepublicvoidinvoke(T value,Context context)throwsIOException{// 2.调用 JdbcOutputFormat#writeRecord
outputFormat.writeRecord(value);}@OverridepublicvoidinitializeState(FunctionInitializationContext context){}@OverridepublicvoidsnapshotState(FunctionSnapshotContext context)throwsException{// 3.barrier到达 出发ck 时调用JdbcOutputFormat#flush
outputFormat.flush();}@Overridepublicvoidclose(){
outputFormat.close();}
● JdbcOutputFormat
@Overridepublicvoidopen(int taskNumber,int numTasks)throwsIOException{try{
connectionProvider.getOrEstablishConnection();}catch(Exception e){thrownewIOException("unable to open JDBC writer", e);}
jdbcStatementExecutor =createAndOpenStatementExecutor(statementExecutorFactory);// todo 如果 配置输出到jdbc最小间隔不等于0 且最小条数不是1 就创建一个固定定时线程池if(executionOptions.getBatchIntervalMs()!=0&& executionOptions.getBatchSize()!=1){this.scheduler =Executors.newScheduledThreadPool(1,newExecutorThreadFactory("jdbc-upsert-output-format"));this.scheduledFuture =// 周期调度执行器this.scheduler.scheduleWithFixedDelay(()->{synchronized(JdbcOutputFormat.this){if(!closed){try{flush();// 执行任务}catch(Exception e){
flushException = e;}}}},
executionOptions.getBatchIntervalMs(),// 用户设置的withBatchIntervalMs参数
executionOptions.getBatchIntervalMs(),TimeUnit.MILLISECONDS);}}
● scheduleWithFixedDelay 说明:
Java中的 scheduleWithFixedDelay 是 java.util.concurrent.ScheduledExecutorService
接口的一个方法,它用于创建一个周期性执行任务的调度器
Runnable task =/* 你要执行的任务 */;// 第一个参数为要执行的任务// 第二个参数为初始延迟时间(单位为时间单位)// 第三个参数为两次任务执行之间的延迟时间(单位为时间单位)
scheduler.scheduleWithFixedDelay(task, initialDelay, delay,TimeUnit.SECONDS)
小结:我们可以看出,程序会根据BatchIntervalMs、BatchSize设置的值,创建一个周期任务调度器,按照BatchIntervalMs执行flush任务。
我们看下flush方法干了什么
@Override// 同步方法publicsynchronizedvoidflush()throwsIOException{checkFlushException();for(int i =0; i <= executionOptions.getMaxRetries(); i++){try{attemptFlush();// 调用attemptFlush
batchCount =0;// 初始值为0break;}...}protectedvoidattemptFlush()throwsSQLException{// JdbcBatchStatementExecutor 为接口,得看他的实现类
jdbcStatementExecutor.executeBatch();}
● 实现类 SimpleBatchStatementExecutor
说到这个还得往上找,SinkFunction#sink方法,看那个lambda表达式
// SinkFunction<T> sink 中调用的JdbcBatchStatementExecutor.simple(sql, statementBuilder,Function.identity()->returnnewSimpleBatchStatementExecutor<>(sql, paramSetter, valueTransformer);->// 初始化 SimpleBatchStatementExecutor SimpleBatchStatementExecutor(String sql,JdbcStatementBuilder<V> statementBuilder,Function<T,V> valueTransformer){this.sql = sql;this.parameterSetter = statementBuilder;this.valueTransformer = valueTransformer;this.batch =newArrayList<>();//空集合}
● SimpleBatchStatementExecutor#executeBatch
JdbcOutputFormat#attemptFlush 的实际执行方法
publicvoidexecuteBatch()throwsSQLException{if(!batch.isEmpty()){// 这个batch实际是上面的ArrayListfor(V r : batch){
parameterSetter.accept(st, r);
st.addBatch();}
st.executeBatch();//批量执行
batch.clear();// 清空这批数据}}
flush方法至此走完了,但是什么时机写入的数据呐?
我们看到GenericJdbcSinkFunction#invoke中调用了,JdbcOutputFormat#writeRecord来处理数据。
● writeRecord
@Override// 同步方法publicfinalsynchronizedvoidwriteRecord(Inrecord)throwsIOException{checkFlushException();try{In recordCopy =copyIfNecessary(record);// 数据添加进缓冲区addToBatch(record, jdbcRecordExtractor.apply(recordCopy));
batchCount++;// 初始值为0// 这里有个情况,就是BatchSize = 1时,就会来一条写一条if(executionOptions.getBatchSize()>0&& batchCount >= executionOptions.getBatchSize()){flush();// 调用flush }}catch(Exception e){thrownewIOException("Writing records to JDBC failed.", e);}}protectedvoidaddToBatch(In original,JdbcIn extracted)throwsSQLException{// 最终调用的是下面的
jdbcStatementExecutor.addToBatch(extracted);}// SimpleBatchStatementExecutor的 addToBatch@OverridepublicvoidaddToBatch(Trecord){// batch就是上面的ArrayList,往集合里面攒批
batch.add(valueTransformer.apply(record));}
补充
关于batchIntervalMs、batchSize、maxRetries三者的默认值,可以看JdbcExecutionOptions类
publicclassJdbcExecutionOptionsimplementsSerializable{publicstaticfinalint DEFAULT_MAX_RETRY_TIMES =3;privatestaticfinalint DEFAULT_INTERVAL_MILLIS =0;publicstaticfinalint DEFAULT_SIZE =5000;privatefinallong batchIntervalMs;privatefinalint batchSize;privatefinalint maxRetries;privateJdbcExecutionOptions(long batchIntervalMs,int batchSize,int maxRetries){Preconditions.checkArgument(maxRetries >=0);this.batchIntervalMs = batchIntervalMs;this.batchSize = batchSize;this.maxRetries = maxRetries;}
总结:
sink方法,如果设置了JdbcExecutionOptions参数,batchIntervalMs != 0,大概流程图如下:
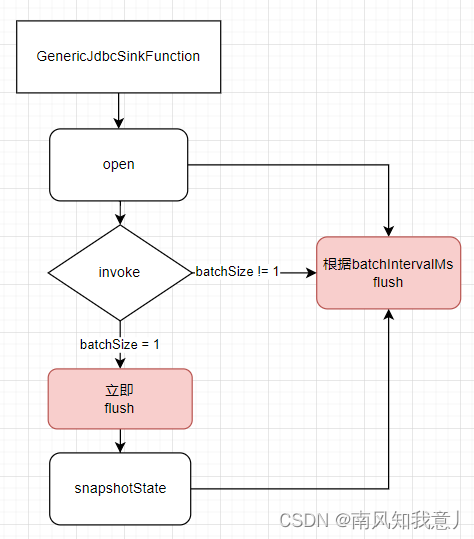
常见问题
1. 为什么会出现JdbcSink.sink方法插入Mysql无数据的情况?
原因:
batchSize默认大小是5000,数据量未达到或者未开启ck都有可能会导致数据"丢失"问题的。
解决:
batchSize设为1
2. JdbcSink.sink写Phoenix无数据问题
原因:
Phoenix默认手动管理commit,Phoenix使用commit()而不是executeBatch()来控制批量更新。看源码可以了解到,JdbcSink使用的是executeBatch(),未调用commit方法!
解决:
// 连接参数加 AutoCommit=true"jdbc:phoenix:192.168.xx.xx:2181;AutoCommit=true"
参考
http://124.221.225.29/archives/flinkjdbcsink-shi-yong-ji-yuan-ma-jie-xi
https://blog.51cto.com/u_15064630/4148244
https://codeantenna.com/a/KBFBolba25
版权归原作者 南风知我意丿 所有, 如有侵权,请联系我们删除。