
p67 课程介绍

p68概述




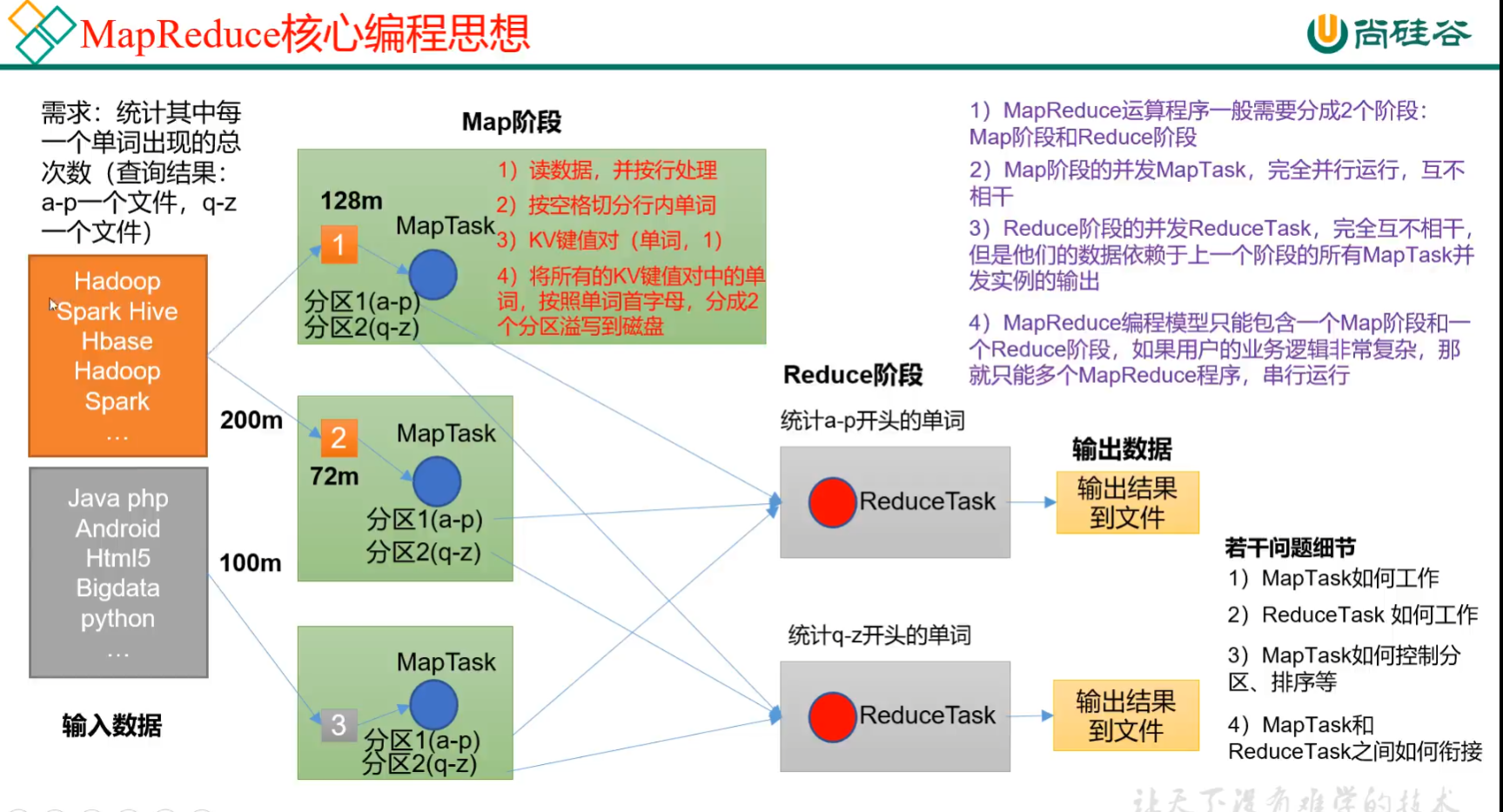
p69 mapreduce核心思想
p70 wordcount源码 序列化类型
mapReduce三类进程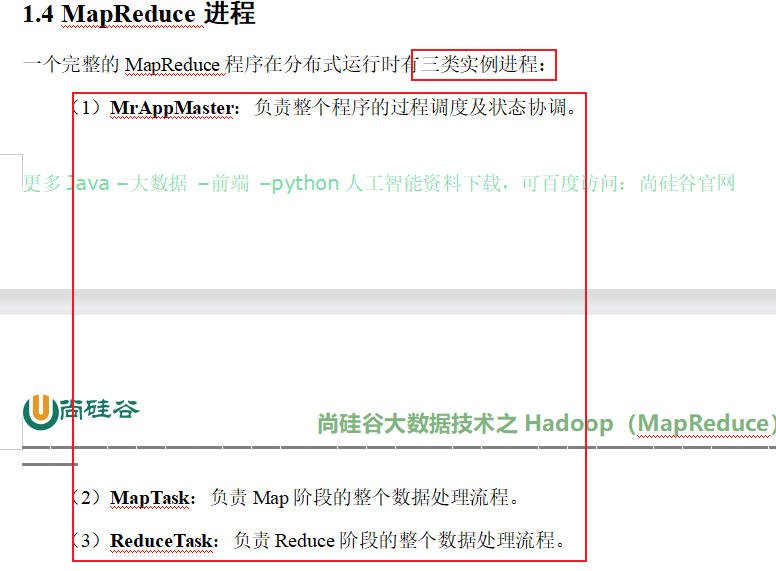

p71 编程规范
用户编写的程序分成三个部分:Mapper、Reducer和Driver。

P72 wordcount需求案例分析

p 73 -78 案例环境准备
(1)创建maven工程,MapReduceDemo
(2)在pom.xml文件中添加如下依赖
<dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.30</version></dependency></dependencies>
(2)在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入。
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
(3)创建包名:com.atguigu.mapreduce.wordcount
4)编写程序
(1)编写Mapper类
packagecom.atguigu.mapreduce.wordcount;importjava.io.IOException;importorg.apache.hadoop.io.IntWritable;importorg.apache.hadoop.io.LongWritable;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Mapper;publicclassWordCountMapperextendsMapper<LongWritable,Text,Text,IntWritable>{Text k =newText();IntWritable v =newIntWritable(1);@Overrideprotectedvoidmap(LongWritable key,Text value,Context context)throwsIOException,InterruptedException{// 1 获取一行String line = value.toString();// 2 切割String[] words = line.split(" ");// 3 输出for(String word : words){
k.set(word);
context.write(k, v);}}}
(2)编写Reducer类
packagecom.atguigu.mapreduce.wordcount;importjava.io.IOException;importorg.apache.hadoop.io.IntWritable;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Reducer;publicclassWordCountReducerextendsReducer<Text,IntWritable,Text,IntWritable>{int sum;IntWritable v =newIntWritable();@Overrideprotectedvoidreduce(Text key,Iterable<IntWritable> values,Context context)throwsIOException,InterruptedException{// 1 累加求和
sum =0;for(IntWritable count : values){
sum += count.get();}// 2 输出
v.set(sum);
context.write(key,v);}}
(3)编写Driver驱动类
packagecom.atguigu.mapreduce.wordcount;importjava.io.IOException;importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.fs.Path;importorg.apache.hadoop.io.IntWritable;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Job;importorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;importorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat;publicclassWordCountDriver{publicstaticvoidmain(String[] args)throwsIOException,ClassNotFoundException,InterruptedException{// 1 获取配置信息以及获取job对象Configuration conf =newConfiguration();Job job =Job.getInstance(conf);// 2 关联本Driver程序的jar
job.setJarByClass(WordCountDriver.class);// 3 关联Mapper和Reducer的jar
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);// 4 设置Mapper输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);// 5 设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);// 6 设置输入和输出路径FileInputFormat.setInputPaths(job,newPath(args[0]));FileOutputFormat.setOutputPath(job,newPath(args[1]));// 7 提交jobboolean result = job.waitForCompletion(true);System.exit(result ?0:1);}}
本地测试
(1)需要首先配置好HADOOP_HOME变量以及Windows运行依赖
(2)在IDEA/Eclipse上运行程序
提交到集群测试
集群上测试
(1)用maven打jar包,需要添加的打包插件依赖
<build><plugins><plugin><artifactId>maven-compiler-plugin</artifactId><version>3.6.1</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>
(2)将程序打成jar包
(3)修改不带依赖的jar包名称为 wc.jar,并拷贝该jar包到Hadoop集群的 /opt/module/hadoop-3.1.3 路径。
(4)启动Hadoop集群
[atguigu@hadoop102 hadoop-3.1.3]sbin/start-dfs.sh
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
(5)执行WordCount程序
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop jar wc.jar
com.atguigu.mapreduce.wordcount.WordCountDriver /user/atguigu/input /user/atguigu/output
p79-86 序列化案例


编写MapReduce程序
packagecom.atguigu.mapreduce.writable;importorg.apache.hadoop.io.Writable;importjava.io.DataInput;importjava.io.DataOutput;importjava.io.IOException;publicclassFlowBeanimplementsWritable{privatelong upFlow;privatelong downFlow;privatelong sumFlow;publicFlowBean(){}publiclonggetUpFlow(){return upFlow;}publicvoidsetUpFlow(long upFlow){this.upFlow = upFlow;}publiclonggetDownFlow(){return downFlow;}publicvoidsetDownFlow(long downFlow){this.downFlow = downFlow;}publiclonggetSumFlow(){return sumFlow;}publicvoidsetSumFlow(){
sumFlow= upFlow+downFlow;}@Overridepublicvoidwrite(DataOutput out)throwsIOException{
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);}@OverridepublicvoidreadFields(DataInput in)throwsIOException{
upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();}@OverridepublicStringtoString(){return upFlow +"\t"+ downFlow +"\t"+ sumFlow;}}
packagecom.atguigu.mapreduce.writable;importcom.sun.org.apache.bcel.internal.generic.NEW;importorg.apache.hadoop.io.LongWritable;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Mapper;importjavax.sound.sampled.Line;importjava.io.IOException;publicclassFlowMapperextendsMapper<LongWritable,Text,Text,FlowBean>{FlowBean flowBean =newFlowBean();Text keyPhone =newText();@Overrideprotectedvoidmap(LongWritable key,Text value,Context context)throwsIOException,InterruptedException{String line = value.toString();String[] arr = line.split("\t");String phone=arr[1];String up=arr[arr.length-3];String down=arr[arr.length-2];
keyPhone.set(phone);
flowBean.setUpFlow(Long.parseLong(up));
flowBean.setDownFlow(Long.parseLong(down));
flowBean.setSumFlow();
context.write(keyPhone,flowBean);}}
packagecom.atguigu.mapreduce.writable;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Reducer;importjava.io.IOException;publicclassFlowReducerextendsReducer<Text,FlowBean,Text,FlowBean>{privateFlowBean reduceFlowBean=newFlowBean();@Overrideprotectedvoidreduce(Text key,Iterable<FlowBean> values,Context context)throwsIOException,InterruptedException{long up=0;long down=0;for(FlowBean flowBean: values){
up+=flowBean.getUpFlow();
down+=flowBean.getDownFlow();}
reduceFlowBean.setUpFlow(up);
reduceFlowBean.setDownFlow(down);
reduceFlowBean.setSumFlow();
context.write(key,reduceFlowBean);}}
packagecom.atguigu.mapreduce.writable;importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.fs.Path;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Job;importorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;importorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat;importjava.io.IOException;publicclassFlowDriver{publicstaticvoidmain(String[] args)throwsIOException,ClassNotFoundException,InterruptedException{Configuration config =newConfiguration();Job job =Job.getInstance(config);
job.setJarByClass(FlowDriver.class);
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);FileInputFormat.setInputPaths(job,newPath("D:\\inputFlow"));FileOutputFormat.setOutputPath(job,newPath("D:\\outputFlow"));boolean completion = job.waitForCompletion(true);System.exit(completion?0:1);}}
p87 88 切片机制与并行度决定机制
1)问题引出
MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度。
思考:1G的数据,启动8个MapTask,可以提高集群的并发处理能力。那么1K的数据,也启动8个MapTask,会提高集群性能吗?MapTask并行任务是否越多越好呢?哪些因素影响了MapTask并行度?
2)MapTask并行度决定机制
数据块:Block是HDFS物理上把数据分成一块一块。数据块是HDFS存储数据单位。
数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。数据切片是MapReduce程序计算输入数据的单位,一个切片会对应启动一个MapTask。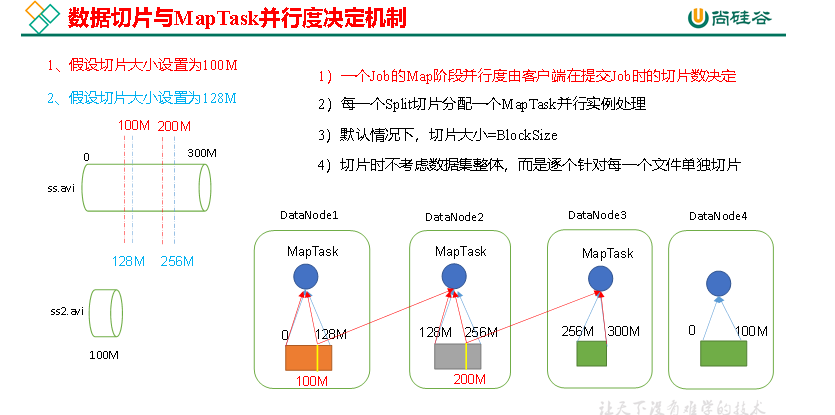

生成临时目录 ,split文件和xml配置,如果是集群模式还要上传jar包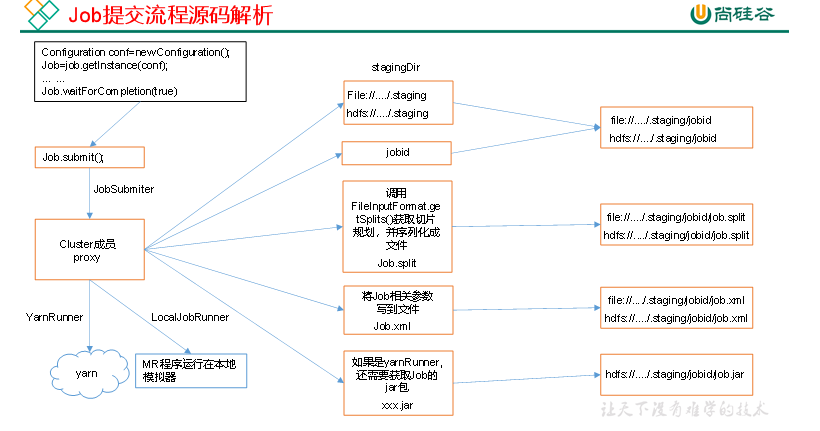
p89-91 切片源码



92 TextInputFormat

p92 93 CombineTextInputFormat切片机制



CombineTextInputFormat案例实操


p94 mapreduce工作流程
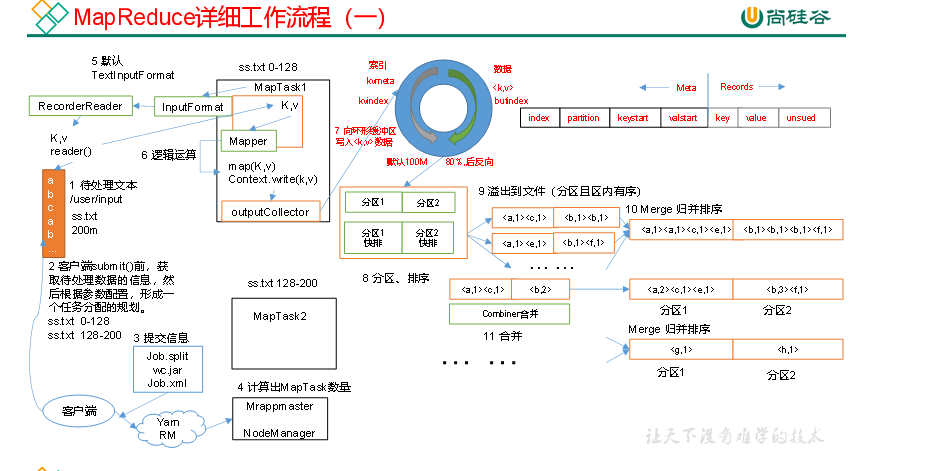
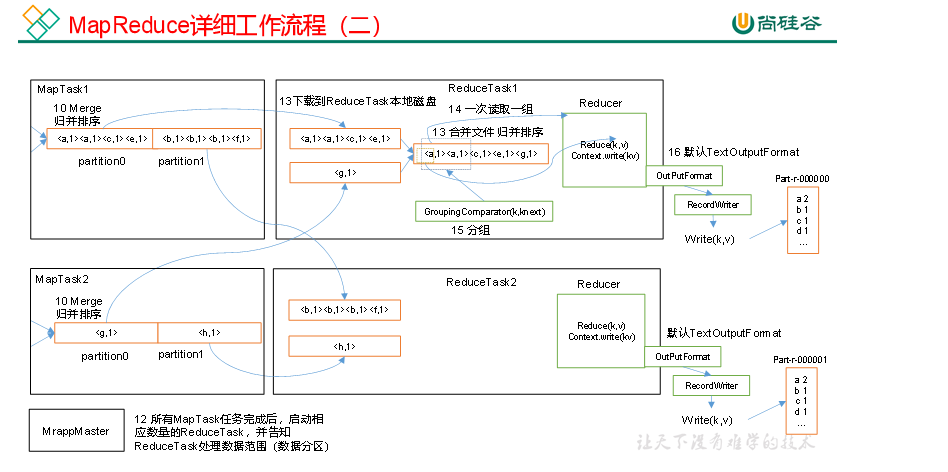
上面的流程是整个MapReduce最全工作流程,但是Shuffle过程只是从第7步开始到第16步结束,具体Shuffle过程详解,如下:
(1)MapTask收集我们的map()方法输出的kv对,放到内存缓冲区中
(2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
(3)多个溢出文件会被合并成大的溢出文件
(4)在溢出过程及合并的过程中,都要调用Partitioner进行分区和针对key进行排序
(5)ReduceTask根据自己的分区号,去各个MapTask机器上取相应的结果分区数据
(6)ReduceTask会抓取到同一个分区的来自不同MapTask的结果文件,ReduceTask会将这些文件再进行合并(归并排序)
(7)合并成大文件后,Shuffle的过程也就结束了,后面进入ReduceTask的逻辑运算过程(从文件中取出一个一个的键值对Group,调用用户自定义的reduce()方法)
注意:
(1)Shuffle中的缓冲区大小会影响到MapReduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快。
(2)缓冲区的大小可以通过参数调整,参数:mapreduce.task.io.sort.mb默认100M。
p95 shuffle工作机制
版权归原作者 莫等闲 白了少年头 所有, 如有侵权,请联系我们删除。